文章目录
-
-
- 1.环境准备
- [1. 分词器代码](#1. 分词器代码)
-
Hugging Face 是一个开源的 AI 社区网站,站内几乎囊括了所有常见的 AI 开源模型,号称:一网打尽,应有尽有,全部开源
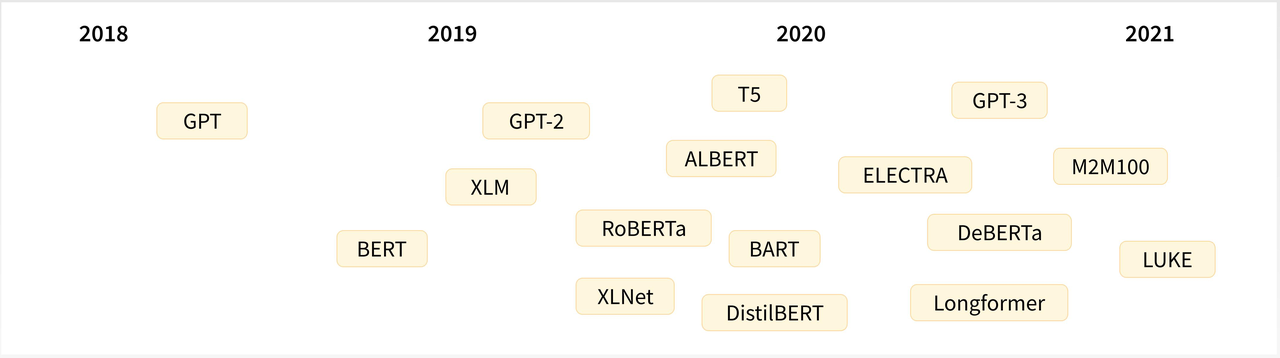
常用模型类型介绍
1 编码器模型 (Encoder-only)
-
代表: BERT, RoBERTa, DistilBERT
-
用途: 文本分类、命名实体识别、情感分析
-
特点: 理解文本含义
2 解码器模型 (Decoder-only)
-
代表: GPT系列
-
用途: 文本生成、对话系统
-
特点: 生成连贯文本
3 编码器-解码器模型 (Encoder-Decoder)
-
代表: T5, BART
-
用途: 翻译、文本摘要
-
特点: 序列到序列任务
核心组件
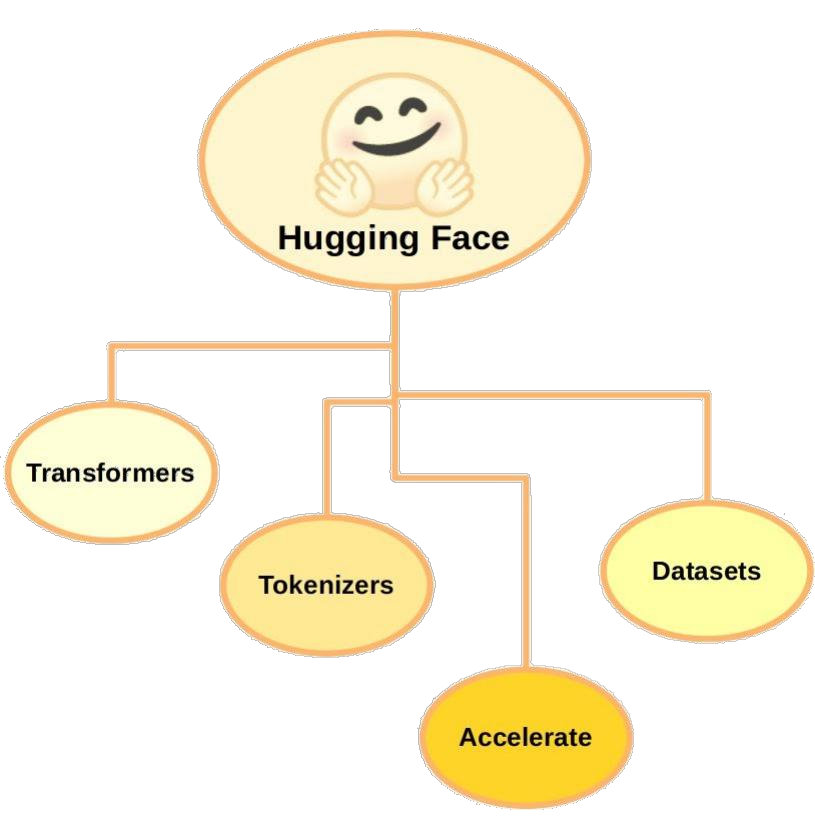
Hugging Face生态:
transformers: 核心模型库datasets: 数据集管理tokenizers: 分词器accelerate: 分布式训练
与Hugging Face区别ModelScope 🏮:概览 · 魔搭社区
- 定位: 阿里巴巴推出的中文AI模型社区
- 核心价值: 专注于中文场景,提供丰富的中文预训练模型
- 特点: 对中文用户更友好,文档和模型更适合中文任务
ModelScope生态:
modelscope: 核心库transformers(兼容): 可以无缝使用
1.环境准备
bash
# 安装Hugging Face核心库 (安装这个就行)
pip install transformers datasets tokenizers
# 或者安装ModelScope核心库
pip install modelscope
# 如果使用GPU,还需要安装PyTorch(需要这个,不然环境运行不起来,或者直接安装pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple/)
pip install torch torchvision torchaudio如果网络不通,就国内镜像源 pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple/
1. 分词器代码
python
##Hugging 链接不同,用镜像源访问,也可以全局配置,这里直接导入
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 1. 导入必要的库
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from datasets import load_dataset
# 2. 定义数据集名称和任务类型:使用的是 imdb 影评数据集
dataset_name = "imdb"
task = "sentiment-analysis"
# 3. 下载数据集并打乱数据
dataset = load_dataset(dataset_name)
dataset = dataset.shuffle()
# 4. 初始化分词器和模型
model_name = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# 5. 将文本编码为模型期望的张量格式
inputs = tokenizer(dataset["train"]["text"][:10], padding=True, truncation=True, return_tensors="pt")
# 6. 将编码后的张量输入模型进行预测
outputs = model(**inputs)
# 7. 获取预测结果和标签
predictions = outputs.logits.argmax(dim=-1)
labels = dataset["train"]["label"][:10]
# 8. 打印预测结果和标签
for i, (prediction, label) in enumerate(zip(predictions, labels)):
prediction_label = "正面评论" if prediction == 1 else "负面评论"
true_label = "正面评论" if label == 1 else "负面评论"
print(f"Example {i+1}: Prediction: {prediction_label}, True label: {true_label}")
##输出结果
Example 1: Prediction: 正面评论, True label: 正面评论
Example 2: Prediction: 正面评论, True label: 负面评论
Example 3: Prediction: 正面评论, True label: 负面评论
Example 4: Prediction: 正面评论, True label: 正面评论
Example 5: Prediction: 正面评论, True label: 负面评论
Example 6: Prediction: 正面评论, True label: 负面评论
Example 7: Prediction: 正面评论, True label: 负面评论
Example 8: Prediction: 正面评论, True label: 正面评论
Example 9: Prediction: 正面评论, True label: 负面评论
Example 10: Prediction: 正面评论, True label: 正面评论模型对10个样本进行了预测
预测准确率约为60%(6个正确,4个错误)
所有预测结果都偏向正面评论,这可能是因为模型未经针对性训练