前言:一行代码引发的思考
今天在刷 LeetCode 146. LRU 缓存机制 时,我遇到了一个看似简单的需求:在 JavaScript 的 Map 中,如何以 O(1) 的时间复杂度拿到最早插入的那个 Key?
我们知道,ES6 的 Map 是有序的(按插入顺序)。我的第一反应是这样写:
js
// ❌ 常见写法
// 为了拿第一个元素,把整个 Map 遍历一遍转成数组
const keys = Array.from(map.keys());
const firstKey = keys[0];如果 Map 里存了 100 万条数据,这行代码意味着要开辟一个存 100 万元素的数组,不仅内存飙升,时间复杂度也变成了 O(N)。这在高性能要求的 LRU 算法里是不可接受的。
后来我看到了一种"极客"写法,直接把复杂度降到了 O(1):
js
// ✅ 高手写法
const firstKey = map.keys().next().value;这行代码里的 .next() 到底是什么?为什么它能精准地"只取一个"?
这就触及到了 JavaScript 中一个平时容易被忽略,但极其强大的概念------迭代器协议 (Iterator Protocol) 。
什么是迭代器?
在《JavaScript 高级程序设计》中,对迭代器的定义比较晦涩。其实在工程实践中,我们只需要理解两个核心概念: "工厂" 和 "工人" 。
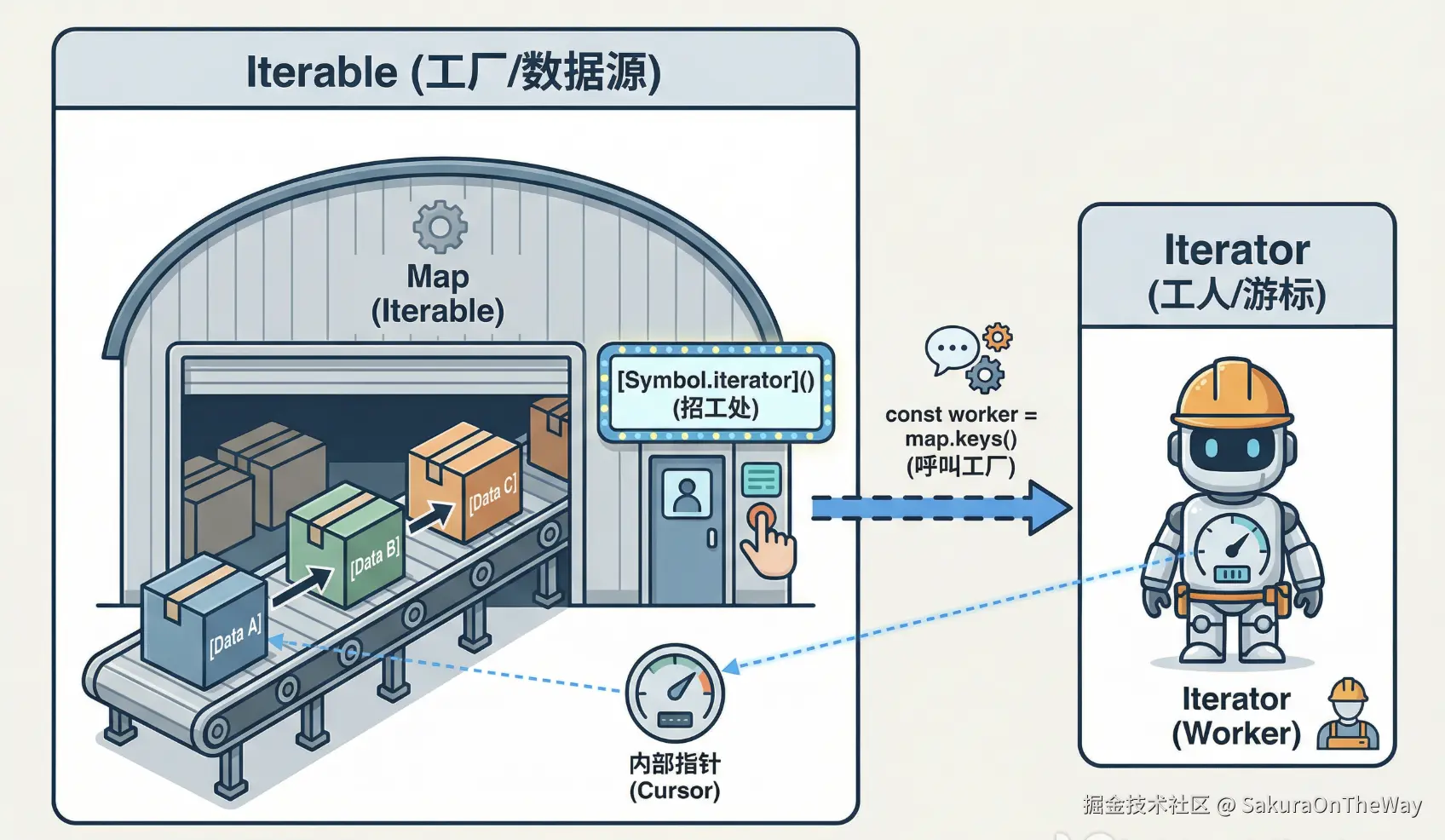
可迭代对象 (Iterable) ------ "工厂"
只要一个对象实现了 [Symbol.iterator] 接口,它就是"可迭代的"。 这意味着,除了本身的存储功能外,它还额外承担了一项职责:定义如何生产一个迭代器。 当我们需要遍历它时,就是调用这个接口,派出一个"工人"来。
- 谁是工厂?
Array,Map,Set,String,NodeList等。 - 怎么生产?
const iterator = map.keys()(这里keys()方法底层就调用了工厂方法)。
迭代器 (Iterator) ------ "工人"
这就是上面生成的那个对象。它像一个游标 (Cursor) ,用来遍历数据。它必须有一个 next() 方法。
-
怎么工作? 每次调用
.next(),工人就会往后走一步,并汇报当前的情况。 -
汇报格式 :
{ value: 当前值, done: 是否结束 }。
回到开头的代码
map.keys()已经指派了一名工人站在传动带的起始位置,这是瞬间完成 ( O(1)) 的,因为不管仓库里有 10 个货还是 100 万个货,派一个人过去这个动作的时间是完全一样的。此时,工人手里是空的,货物也还在传送带上,什么资源都没浪费。Array.from(map.keys())像是暴力搬仓,"先把传送带上这 100 万个货物,全部搬下来,按顺序装到辆新卡车(Array)上去!"这需要动用大量人力(CPU 算力),需要一辆巨大的卡车来装货(内存暴涨),最重要的是,在搬完最后一个货物之前,你连第一个货物都拿不到 ,这就叫阻塞。时间复杂度 : O(N),货物越多,搬的时间越长。.next()就像是给工人下达了一个命令:"把你眼前的货物拿给我",工人把当前的value给你,然后向后走了一步。如果不继续执行.next(),那工人就不会继续执行,不浪费资源。

这就是惰性求值 (Lazy Evaluation) 的魅力:我不需要知道后面还有多少数据,我只需要迈出第一步。
实战:让自定义对象支持 for...of
理解了原理,我们来看看怎么用。
平时我们能用 for...of 遍历数组,是因为数组内置了迭代器。如果我们自己写一个 Class,怎么让它也能被遍历呢?
假设我们要管理一个"开发小组":
js
class Team {
constructor(members) {
this.members = members;
}
// 1. 部署 [Symbol.iterator] 接口
[Symbol.iterator]() {
let index = 0;
// 2. 返回一个迭代器对象(必须有 next 方法)
return {
// 使用箭头函数锁定 this
next: () => {
if (index < this.members.length) {
// 3. 还有数据,返回 value 和 done: false
return { value: this.members[index++], done: false };
} else {
// 4. 没数据了,返回 done: true
return { value: undefined, done: true };
}
}
};
}
}
// 测试一下
const myTeam = new Team(['Alice', 'Bob', 'Charlie']);
// 成功!自定义对象支持 for...of 了
for (const member of myTeam) {
console.log(member);
}
// 输出: Alice, Bob, Charlie进阶:生成器 (Generator)
手动写 next() 和维护 index 状态太麻烦了?ES6 提供了一个王炸语法:生成器函数 (function*) 。
它让函数变成了"可以暂停"的迭代器。用 yield 关键字,我们可以把上面的代码简化成这样:
js
class Team {
constructor(members) {
this.members = members;
}
// * 表示这是一个生成器工厂
*[Symbol.iterator]() {
for (const member of this.members) {
// yield 会暂停函数执行,把值"吐"给外部
// 下次再调 next() 时,从这里继续
yield member;
}
}
}代码量减少了一半,逻辑却更加清晰。
为什么我们需要关注迭代器?
除了在 LRU 算法中做性能优化,迭代器还有很多应用场景:
A. 处理无限序列
如果我们想要一个无限自增的 ID 生成器,用数组存显然会内存溢出。但用迭代器,用一个生成一个 ,内存占用永远是 O(1)。
js
function* generateId() {
let id = 0
while (true) {
yield id++ // 先吐值,再加1
}
}
const gen = generateId()
console.log(gen.next().value) // 0
console.log(gen.next().value) // 1B. 掌控海量数据:Node.js 流与异步迭代
在处理超大文件(GB 级别)时,我们不能一次性 readFile 到内存。Node.js 的 Stream (流) 本质上就是一种异步迭代器,读一行,处理一行,扔掉一行 。为了讲清楚,我们需要引入一个新的概念:异步迭代器 (Async Iterator)
想象你有一台只有 8GB 内存 的服务器。 现在你要处理一个 20GB 的日志文件(比如分析访问量)。
❌ 传统做法:fs.readFile (及早求值)
js
const fs = require('fs');
// 试图把 20GB 的文件一次性读入 8GB 的内存
// 结果:Error: heap out of memory (程序崩溃)
const data = fs.readFileSync('./big.log');
console.log(data.toString());✅流式做法:Stream (惰性求值)
Node.js 的 Stream 模块,利用了迭代器的思想: 我不关心文件有多大,我只关心这一口(Chunk)。
技术原理:从 Iterator 到 Async Iterator
我们在前几节讲的迭代器是同步的:
iterator.next()-> 立马返回{ value, done }。
但在文件读取中,硬盘读取速度慢,数据不是立马就有的。所以我们需要异步迭代器:
- Symbol :
[Symbol.asyncIterator] - 动作 :
iterator.next()-> 返回一个 Promise ,解析后才是{ value, done }。 - 语法 :
for await (const chunk of stream)
处理 20GB 文件只需 64KB 内存
我们需要用到 Node.js 的 readline 模块,它封装了 Stream,让我们可以按行迭代。
js
const fs = require('fs');
const readline = require('readline');
async function processBigFile() {
// 1. 创建一个流,接在文件上
const fileStream = fs.createReadStream('./20gb_server.log');
// 2. 创建一个逐行读取接口(这是个异步可迭代对象)
const rl = readline.createInterface({
input: fileStream,
crlfDelay: Infinity
});
// 3. 开始执行
// 这里的 for await...of 就是异步迭代器的语法糖
for await (const line of rl) {
// 在这一刻,内存里只有这一行字符串!
// 上一行已经被垃圾回收(GC)了,下一行还在硬盘里。
if (line.includes('ERROR')) {
console.log('找到错误:', line);
}
// 这一行处理完,立马扔掉,释放内存
}
}
processBigFile();总结:在灵活性与性能之间寻找平衡
回到文章开头的那个 LRU 算法题,一行简单的 .next().value 背后,其实藏着 JavaScript 语言设计的哲学。
通过这次对迭代器协议的深挖,我们可以得出两个看似矛盾、实则统一的结论:
JavaScript 的上限极高
很多开发者认为 JS 只是脚本语言,缺乏底层控制力。但迭代器协议向我们展示了 JS 硬核的一面:
- 它赋予了我们手动控制内存和 CPU 的能力(惰性求值)。
- 它让我们可以像 C++ 指针一样精准操作数据,也可以像 Haskell 一样处理无限序列。
- 从简单的数组遍历,到 Node.js 处理 TB 级文件的 Stream,迭代器贯穿始终,支撑起了 JS 处理复杂工程问题的骨架。
灵活性的代价
1. 隐形杀手:语法糖背后的开销
Array.from(map.keys()或者[...map.keys] 写起来比 map.keys().next() 优雅得多,但它悄无声息地引入了 O(N) 的时空复杂度。JS 引擎太聪明了,帮我们处理了太多事情,以至于我们容易忘记:每一行优雅的代码背后,都有 CPU 在负重前行。
2. 禁区:不要触碰原型链
学会了 Symbol.iterator 后,很多人会产生一种危险的冲动:
"既然 Object 不能遍历,那我直接给 Object.prototype 加上一个迭代器接口不就行了?"
千万不要这样做!
JavaScript 给了你修改世界的能力,但优秀的工程师懂得克制。