目录
[一、什么是模式匹配(Pattern Matching)](#一、什么是模式匹配(Pattern Matching))
[(二)字符串匹配 vs 结构化匹配](#(二)字符串匹配 vs 结构化匹配)
[1. 字符串匹配:线性输入上的规则识别](#1. 字符串匹配:线性输入上的规则识别)
[2. 结构化匹配:在"形状"上做判定](#2. 结构化匹配:在“形状”上做判定)
[1. 日志解析](#1. 日志解析)
[2. 编译器 / 解释器](#2. 编译器 / 解释器)
[3. 数据清洗与 ETL](#3. 数据清洗与 ETL)
[4. 风控规则 / 策略系统](#4. 风控规则 / 策略系统)
[(四)Python 中模式匹配能力的演进脉络](#(四)Python 中模式匹配能力的演进脉络)
[阶段一:字符串 API](#阶段一:字符串 API)
[阶段三:结构化模式匹配(PEP 634)](#阶段三:结构化模式匹配(PEP 634))
[1. 形式语言的最低限度认知](#1. 形式语言的最低限度认知)
[2. 正则语言能做什么](#2. 正则语言能做什么)
[3. 正则语言不能做什么](#3. 正则语言不能做什么)
[(二)DFA / NFA 的核心思想(直观理解)](#(二)DFA / NFA 的核心思想(直观理解))
[1. 自动机不是学术概念,而是执行模型](#1. 自动机不是学术概念,而是执行模型)
[2. DFA(确定有限自动机)](#2. DFA(确定有限自动机))
[3. NFA(非确定有限自动机)](#3. NFA(非确定有限自动机))
[4. Python 使用的是哪种?](#4. Python 使用的是哪种?)
[(三)回溯型正则 vs 自动机正则](#(三)回溯型正则 vs 自动机正则)
[1. 回溯引擎的直觉模型](#1. 回溯引擎的直觉模型)
[2. 用代码感受"路径爆炸"](#2. 用代码感受“路径爆炸”)
[3. DFA 风格的正则为什么快](#3. DFA 风格的正则为什么快)
[1. 能力边界](#1. 能力边界)
[2. 性能边界](#2. 性能边界)
[3. 可维护性边界](#3. 可维护性边界)
[4. 三条工程级认知](#4. 三条工程级认知)
[第二篇:Python 正则表达式核心机制](#第二篇:Python 正则表达式核心机制)
[一、Python 正则引擎的工作原理](#一、Python 正则引擎的工作原理)
[(一)CPython re 模块架构概览](#(一)CPython re 模块架构概览)
[(二)回溯引擎(Backtracking Engine)详解](#(二)回溯引擎(Backtracking Engine)详解)
[1. 核心思想](#1. 核心思想)
[2. 逐字符匹配流程拆解](#2. 逐字符匹配流程拆解)
[(三)re.compile 的真实价值](#(三)re.compile 的真实价值)
[1. 单次解析 vs 多次复用](#1. 单次解析 vs 多次复用)
[2. 内部存储形式](#2. 内部存储形式)
[1. 字符类 abc 与 \d、\w](#1. 字符类 [abc] 与 \d、\w)
[2. 量词:* / + / ? / {m,n}](#2. 量词:* / + / ? / {m,n})
[3. 捕获组 (...) vs 非捕获组 (?:...)](#3. 捕获组 (…) vs 非捕获组 (?:…))
[(一)前瞻 / 后顾断言(Lookaround)](#(一)前瞻 / 后顾断言(Lookaround))
[1. 前瞻示例](#1. 前瞻示例)
[2. 后顾示例](#2. 后顾示例)
[1. 基本语法](#1. 基本语法)
[2. 命名组引用示例](#2. 命名组引用示例)
[(四)多行 / DOTALL / VERBOSE 模式组合设计](#(四)多行 / DOTALL / VERBOSE 模式组合设计)
[1. 常用模式标志](#1. 常用模式标志)
[2. 组合示例](#2. 组合示例)
[(一)指数级回溯(Catastrophic Backtracking)](#(一)指数级回溯(Catastrophic Backtracking))
[1. 回溯机制复盘](#1. 回溯机制复盘)
[2. 简单指数级示例](#2. 简单指数级示例)
[3. 可视化匹配树](#3. 可视化匹配树)
[1. 贪婪量词嵌套](#1. 贪婪量词嵌套)
[2. 不明确边界](#2. 不明确边界)
[3. 可选分支组合](#3. 可选分支组合)
[(三)正则 DoS(ReDoS)攻击原理](#(三)正则 DoS(ReDoS)攻击原理)
[(一)"先失败"原则(Fail Fast)](#(一)“先失败”原则(Fail Fast))
[1. 原理依据](#1. 原理依据)
[2. 工程实践示例](#2. 工程实践示例)
[1. 原理依据](#1. 原理依据)
[2. 工程示例](#2. 工程示例)
[(三)限定回溯空间(Restrict Backtracking)](#(三)限定回溯空间(Restrict Backtracking))
[1. 原理依据](#1. 原理依据)
[2. 工程技巧](#2. 工程技巧)
[(四)拆分复杂正则 vs 单一巨型正则](#(四)拆分复杂正则 vs 单一巨型正则)
[1. 原理依据](#1. 原理依据)
[2. 工程示例](#2. 工程示例)
[(一)原子分组与占有量词(Python 中的替代方案)](#(一)原子分组与占有量词(Python 中的替代方案))
[1. 原理依据](#1. 原理依据)
[2. Python 原子分组模拟示例](#2. Python 原子分组模拟示例)
[(二)re 模块 vs regex 第三方库对比](#(二)re 模块 vs regex 第三方库对比)
[1. 原理依据](#1. 原理依据)
[2. 示例](#2. 示例)
[1. 大文本场景](#1. 大文本场景)
[2. 批量处理技巧](#2. 批量处理技巧)
[第四篇:结构化匹配:Python 3.10+ 模式匹配(PEP 634)](#第四篇:结构化匹配:Python 3.10+ 模式匹配(PEP 634))
[一、match-case 语法的设计哲学](#一、match-case 语法的设计哲学)
[(一)为什么 Python 引入结构化模式匹配](#(一)为什么 Python 引入结构化模式匹配)
[1. 背景与痛点](#1. 背景与痛点)
[2. 设计目标](#2. 设计目标)
[(二)match-case 与 if-elif 的本质差异](#(二)match-case 与 if-elif 的本质差异)
[1. 对比示例](#1. 对比示例)
[2. 性能角度](#2. 性能角度)
[(三)表达式匹配 vs 语句匹配](#(三)表达式匹配 vs 语句匹配)
[1. 语句匹配(Statement Pattern)](#1. 语句匹配(Statement Pattern))
[2. 表达式匹配(Expression Pattern)](#2. 表达式匹配(Expression Pattern))
[(一)常量模式(Literal Pattern)](#(一)常量模式(Literal Pattern))
[1. 概念](#1. 概念)
[2. 示例](#2. 示例)
[(二)序列模式(Sequence Pattern)](#(二)序列模式(Sequence Pattern))
[1. 概念](#1. 概念)
[2. 示例](#2. 示例)
[3. 可变长度解包](#3. 可变长度解包)
[(三)映射模式(Mapping Pattern)](#(三)映射模式(Mapping Pattern))
[1. 概念](#1. 概念)
[2. 示例](#2. 示例)
[(四)类模式(Class Pattern)](#(四)类模式(Class Pattern))
[1. 概念](#1. 概念)
[2. 示例](#2. 示例)
[(五)通配符 _ 与守卫条件(Guard)](#(五)通配符 _ 与守卫条件(Guard))
[1. 通配符 _](#1. 通配符 _)
[2. 守卫条件(Guard)](#2. 守卫条件(Guard))
[三、match-case 与正则表达式的协作](#三、match-case 与正则表达式的协作)
[(一)文本解析 + 结构匹配的组合范式](#(一)文本解析 + 结构匹配的组合范式)
[1. 背景与思路](#1. 背景与思路)
[2. 简单示例](#2. 简单示例)
[(二) AST 风格数据处理](#(二) AST 风格数据处理)
[1. 概念](#1. 概念)
[2. 示例:简单算术表达式解析](#2. 示例:简单算术表达式解析)
[1. 背景](#1. 背景)
[2. 正则 + match-case + 状态机](#2. 正则 + match-case + 状态机)
[1. 多级匹配示例](#1. 多级匹配示例)
[1. 正则适用场景回顾](#1. 正则适用场景回顾)
[2. 正则局限性](#2. 正则局限性)
[(二)手写解析器 vs 正则](#(二)手写解析器 vs 正则)
[1. 手写解析器优势](#1. 手写解析器优势)
[2. 示例:嵌套括号解析器](#2. 示例:嵌套括号解析器)
[3. 状态机解析示例](#3. 状态机解析示例)
[(三)正则 + 状态机混合设计](#(三)正则 + 状态机混合设计)
[1. 思路](#1. 思路)
[2. 实例:简易日志 DSL 解析](#2. 实例:简易日志 DSL 解析)
[1. 背景](#1. 背景)
[2. 架构思路](#2. 架构思路)
[3. 示例实现](#3. 示例实现)
[1. 背景](#1. 背景)
[2. 核心设计思路](#2. 核心设计思路)
[3. 示例:简单风控规则引擎](#3. 示例:简单风控规则引擎)
[(三)规则 DSL 的实现思路](#(三)规则 DSL 的实现思路)
[1. DSL 架构设计](#1. DSL 架构设计)
[2. 示例:日志 DSL](#2. 示例:日志 DSL)
[1. 背景](#1. 背景)
[2. 命名规范](#2. 命名规范)
[3. 文档化建议](#3. 文档化建议)
[1. 背景](#1. 背景)
[2. 单元测试示例](#2. 单元测试示例)
[3. 回归测试示例](#3. 回归测试示例)
[1. 背景](#1. 背景)
[2. 版本化策略](#2. 版本化策略)
[3. 工程实践示例](#3. 工程实践示例)
[1. 使用函数封装复杂匹配](#1. 使用函数封装复杂匹配)
[2. 规则抽象 + 配置化](#2. 规则抽象 + 配置化)
[1. 背景](#1. 背景)
[2. 架构思路](#2. 架构思路)
[3. 实现示例](#3. 实现示例)
[(二)URL / User-Agent 精准识别](#(二)URL / User-Agent 精准识别)
[1. 背景](#1. 背景)
[2. URL 提取与解析](#2. URL 提取与解析)
[3. User-Agent 分类](#3. User-Agent 分类)
[1. 背景](#1. 背景)
[2. 正则 + match-case 实战](#2. 正则 + match-case 实战)
[1. 背景](#1. 背景)
[2. 示例](#2. 示例)
[3. 改进](#3. 改进)
[1. 背景](#1. 背景)
[2. 反模式示例](#2. 反模式示例)
[3. 改进](#3. 改进)
[(三)隐式回溯陷阱(Catastrophic Backtracking)](#(三)隐式回溯陷阱(Catastrophic Backtracking))
[1. 背景](#1. 背景)
[2. 示例](#2. 示例)
[3. 改进](#3. 改进)
[1. 背景](#1. 背景)
[2. 反模式示例](#2. 反模式示例)
[3. 改进](#3. 改进)
[(一)从 Python 正则和 match-case 起步](#(一)从 Python 正则和 match-case 起步)
[1. 基础能力](#1. 基础能力)
[2. 工程实践路径](#2. 工程实践路径)
[1. 动机](#1. 动机)
[2. 核心概念](#2. 核心概念)
[(三)PEG / Lark / ANTLR 进阶](#(三)PEG / Lark / ANTLR 进阶)
[1. PEG(Parsing Expression Grammar)](#1. PEG(Parsing Expression Grammar))
[2. Lark(Python 高级解析器库)](#2. Lark(Python 高级解析器库))
[3. ANTLR(跨语言解析器)](#3. ANTLR(跨语言解析器))
[1. 设计思路](#1. 设计思路)
[2. 示例:简易 DSL 规则引擎](#2. 示例:简易 DSL 规则引擎)
干货分享,感谢您的阅读!
在现代软件工程中,模式匹配能力是核心技能之一。从日志解析、数据清洗、风控规则系统,到复杂 DSL 解析和业务规则引擎,匹配系统支撑着各种关键功能。Python 提供了强大的正则表达式和自 3.10 起的结构化模式匹配语法,使得模式匹配不仅高效,也更可维护和可扩展。
然而,许多开发者停留在"会写正则"的阶段,忽略了工程化思维:性能优化、可维护性、可扩展性和系统化设计。我这次的学习目标总结,是想从基础到进阶慢慢尝试 理解模式匹配的本质、掌握 Python 正则与 match-case、设计工程化规则系统,并最终构建复杂匹配引擎。我们需要不仅讲"怎么写",更讲"为什么这样写",并结合实战案例、优化策略和进阶路线,但整体内容难免存在理解不够严谨或表述不够完善之处,欢迎各位读者在评论区留言指正、交流探讨,这对我和后续读者都会非常有价值,感谢!
前置:掌握正则表达式:从基础到实用示例(在Java应用中已提炼过,这边基础的内容暂时不做展开,感兴趣可以在看下)

第一篇:模式匹配的本质与计算模型基础
本篇旨在建立理论基础。理解模式匹配在计算机科学中的定义,掌握字符串匹配与结构化匹配的差异,学习常见应用场景(如日志解析、编译器、ETL、风控规则系统),并了解 Python 模式匹配能力的演进脉络,为后续实践打下基础。
一、什么是模式匹配(Pattern Matching)
(一)模式匹配在计算机科学中的定义
模式匹配(Pattern Matching)本质上是一个判定问题:
给定一个输入对象
X,判断它是否满足某种结构或规则P,若满足,则返回"匹配成功"及其结构化信息。
在工程中,这个对象通常是:
-
字符串(日志、协议、文本)
-
结构化数据(AST、JSON、对象)
-
状态序列(事件流)
抽象为一个函数签名就是:
python
def match(pattern, input) -> MatchResult | None:
...关键不在于"是否匹配",而在于:
-
是否能高效判定
-
是否能提取有用结构
-
是否可维护、可演进
(二)字符串匹配 vs 结构化匹配
1. 字符串匹配:线性输入上的规则识别
这是最常见、也最容易被滥用的匹配形式。
python
text = "ERROR 2024-01-01 user=alice timeout"
if "ERROR" in text:
print("error log")这是最原始的模式匹配:
-
模式:子串
"ERROR" -
输入:字符串
-
返回:布尔值
升级为正则:
python
import re
pattern = re.compile(r"ERROR\s+(\d{4}-\d{2}-\d{2})\s+user=(\w+)")
m = pattern.search(text)
if m:
date, user = m.groups()特点:
-
输入是线性字符流
-
模式是字符级规则
-
引擎负责回溯 / 自动机执行
2. 结构化匹配:在"形状"上做判定
当输入不再是字符串,而是结构化数据时,继续用正则是灾难。
python
data = {
"type": "login",
"user": "alice",
"success": False,
"reason": "timeout"
}传统写法:
python
if (
data.get("type") == "login"
and data.get("success") is False
and data.get("reason") == "timeout"
):
...Python 3.10+:
python
match data:
case {
"type": "login",
"success": False,
"reason": "timeout",
"user": user
}:
print(f"login timeout: {user}")本质差异:
-
字符串匹配:匹配"字符序列"
-
结构化匹配:匹配"数据形状"
这两者背后对应的是完全不同的计算模型。
(三)典型应用场景全景图
1. 日志解析
python
log = "INFO 2024-01-01T10:00:00 user=alice action=login"
pattern = re.compile(
r"(?P<level>INFO|ERROR)\s+"
r"(?P<ts>\S+)\s+"
r"user=(?P<user>\w+)\s+"
r"action=(?P<action>\w+)"
)
m = pattern.match(log)
if m:
record = m.groupdict()
print(record); # {'level': 'INFO', 'ts': '2024-01-01T10:00:00', 'user': 'alice', 'action': 'login'}问题在于:
-
正则很快会变成不可维护的 DSL
-
轻微格式变化导致全盘失效
2. 编译器 / 解释器
词法分析阶段:
python
token_spec = [
("NUMBER", r"\d+"),
("PLUS", r"\+"),
("MINUS", r"-"),
("WS", r"\s+"),
]
master = re.compile(
"|".join(f"(?P<{name}>{pat})" for name, pat in token_spec)
)这里已经出现了一个信号:正则不再是业务逻辑,而是语言的一部分
3. 数据清洗与 ETL
python
def normalize_phone(s: str) -> str | None:
m = re.search(r"(\+?\d{1,3})?[-\s]?(\d{10})", s)
if not m:
return None
country, number = m.groups()
return f"{country or '+86'}{number}"常见问题:
-
正则承担了验证 + 解析 + 纠错
-
性能与可读性同时恶化
4. 风控规则 / 策略系统
典型反模式:
python
if re.search(r"(?=.*loan)(?=.*overdue)(?=.*blacklist)", text):
...这是隐式规则引擎:
-
无法版本管理
-
无法测试子规则
-
性能不可预测
后续章节会给出正则 + match-case + 状态机的替代方案。
(四)Python 中模式匹配能力的演进脉络
阶段一:字符串 API
python
s.startswith("ERROR")
s.endswith(".log")
"timeout" in s特征:确定性、线性、可预测。
阶段二:正则表达式(re)
python
re.search(r"(ERROR|WARN)\s+\d+", s)能力跃迁,但引入了:
-
回溯
-
性能不确定性
-
可读性问题
阶段三:结构化模式匹配(PEP 634)
python
match event:
case {"type": "error", "code": int(code)} if code >= 500:
...这是 Python 首次:
-
将模式匹配作为语言级能力
-
从"文本世界"扩展到"数据世界"
二、形式语言与自动机基础
(一)正则语言、上下文无关语言的边界
1. 形式语言的最低限度认知
在工程中,我们关心的不是"语言学",而是表达能力边界。
| 层级 | 能力 | 典型工具 |
|---|---|---|
| 正则语言 | 线性、无嵌套 | 正则表达式 |
| 上下文无关语言 | 可递归嵌套 | 解析器 |
| 上下文相关语言 | 语义依赖 | 编译器 |
正则表达式只能描述正则语言。
2. 正则语言能做什么
可以匹配:
python
aaaa
abab
abc123
key=value例如:
python
import re
re.fullmatch(r"(ab)*", "abab") # OK
re.fullmatch(r"\d{4}-\d{2}-\d{2}", "2024-01-01") # OK共同特征:
-
没有"递归结构"
-
不需要记住历史状态的数量关系
3. 正则语言不能做什么
不能可靠匹配嵌套结构:
python
( ( ) )
{ { { } } }
if (a) { if (b) { } }你可能见过这种"邪术正则":
python
r"\((?:[^()]+|\([^()]*\))*\)"工程判断标准只有一个:能写 ≠ 能维护 ≠ 能保证性能
(二)DFA / NFA 的核心思想(直观理解)
1. 自动机不是学术概念,而是执行模型
正则匹配,本质是状态迁移。
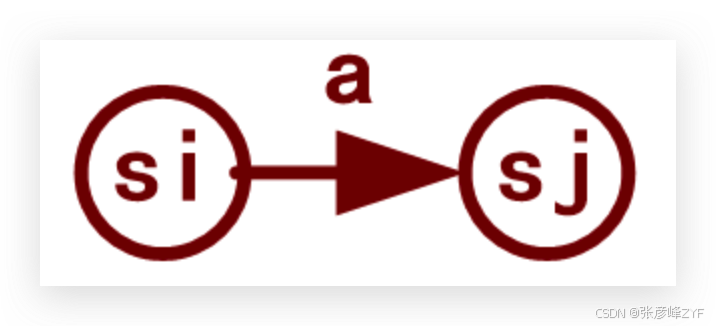
一个"有向图":
- NFA中的每个状态,对应转换图中的一个节点;
- NFA中的每个
move(si, a)=sj,对应转换图中的一条有向边; - 表示从节点
si出发进入节点sj,字符a(或ε)是边上的标记。
2. DFA(确定有限自动机)
特征:
-
每个状态 + 输入字符 → 唯一下一状态
-
不回溯
-
时间复杂度稳定 O(n)
工程含义:
-
性能可预测
-
内存换时间
典型代表:grep、RE2
3. NFA(非确定有限自动机)
特征:
-
一个输入可能有多个路径
-
理论上并行
-
实现上可能转化为 DFA 或回溯
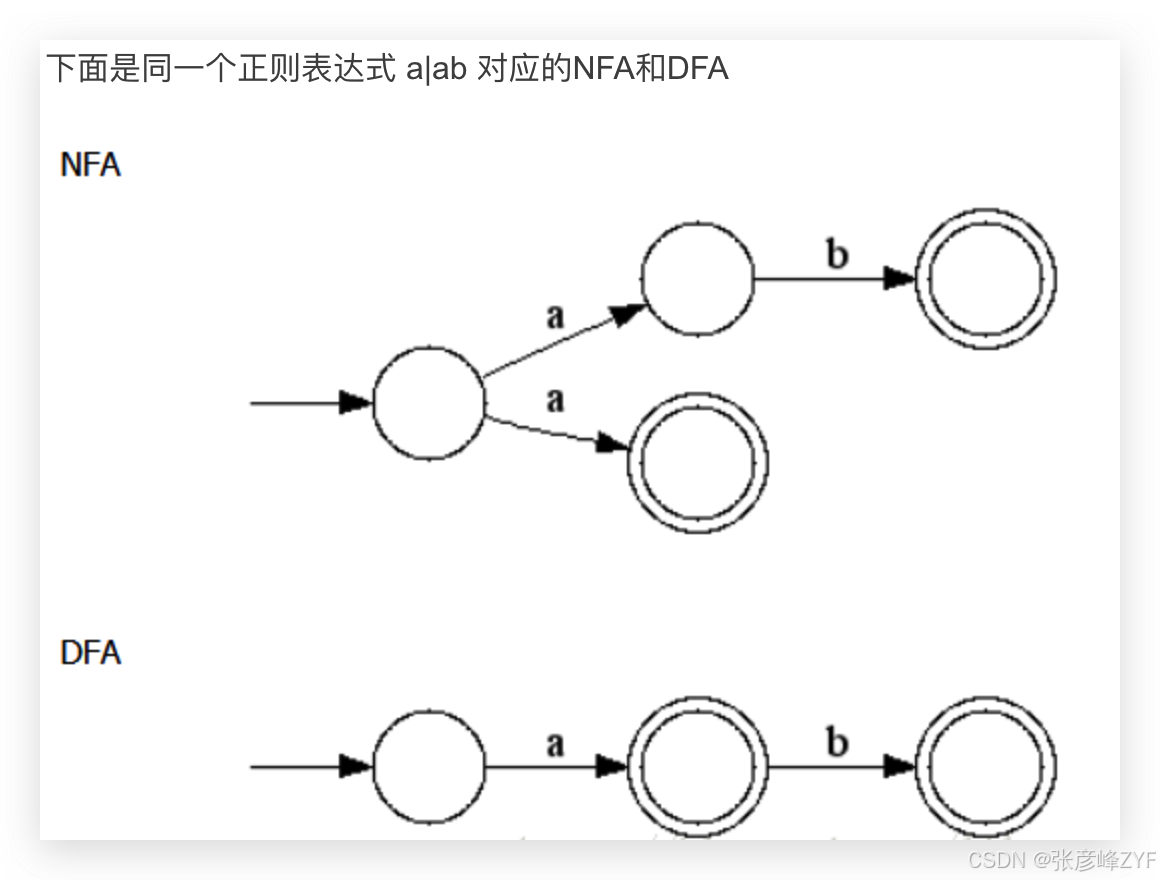
4. Python 使用的是哪种?
结论先给出:CPython 的 re 模块是回溯型 NFA 引擎
不是 DFA,不做全量状态展开。
(三)回溯型正则 vs 自动机正则
1. 回溯引擎的直觉模型
看这个正则:
python
r"(a+)+b"匹配输入:
perl
"aaaaaaaaaaaa"引擎会:
-
尝试
(a+)吃尽字符 -
尝试
+ -
发现后面没有
b -
回退,重新分配 a 的归属
-
重复上述过程
2. 用代码感受"路径爆炸"
python
import re
import time
pattern = re.compile(r"(a+)+b")
s = "a" * 25 # 谨慎调大
start = time.time()
pattern.match(s)
print(time.time() - start) # 1.129573106765747这不是 bug,这是计算模型的必然结果。
3. DFA 风格的正则为什么快
同样的匹配逻辑,在 DFA 中:
-
不尝试路径
-
同一字符只走一次
-
不回头
代价:
-
不支持回溯引用
-
不支持部分高级特性
(四)为什么"正则不是万能的"
1. 能力边界
以下需求出现任意一条,就要警惕:
-
成对嵌套
-
递归结构
-
需要"计数一致性"
-
输入规模不可控
2. 性能边界
python
r"(.*)(.*)(.*)"在回溯引擎中:
-
每个
.*都是一个"自由分配器" -
路径数呈指数级
3. 可维护性边界
python
r"(?:(?<=foo)|(?<!bar))(baz|qux)(?=end)"判断标准:如果你需要"画图"才能理解这个正则,它已经不适合工程使用。
4. 三条工程级认知
到这里,你应该形成三条工程级认知:
-
正则 ≠ 万能匹配工具
-
Python 的正则性能由回溯模型 决定
-
所有"玄学性能问题"都有形式语言解释
第二篇:Python 正则表达式核心机制
本篇聚焦 Python 正则引擎,讲解 re 模块架构、回溯引擎、匹配流程、语法特性和隐藏能力。通过深入理解内部原理,尽量能够写出高性能、可维护的正则,并掌握高级特性,如前瞻/后顾断言、命名分组、条件表达式和多模式组合。
一、Python 正则引擎的工作原理
理解 re 模块到底做了什么 ,不是写正则,而是能设计可维护、高性能的正则 。
(一)CPython re 模块架构概览
Python 的 re 模块主要由三个部分组成:
-
**解析器(Parser):**将正则字符串解析为内部结构(AST / Pattern Object)
-
**编译器(Compiler):**将 AST 转换为"指令序列"(类似字节码)
-
**匹配引擎(Backtracking Engine):**按指令序列逐字符匹配,遇到失败回溯
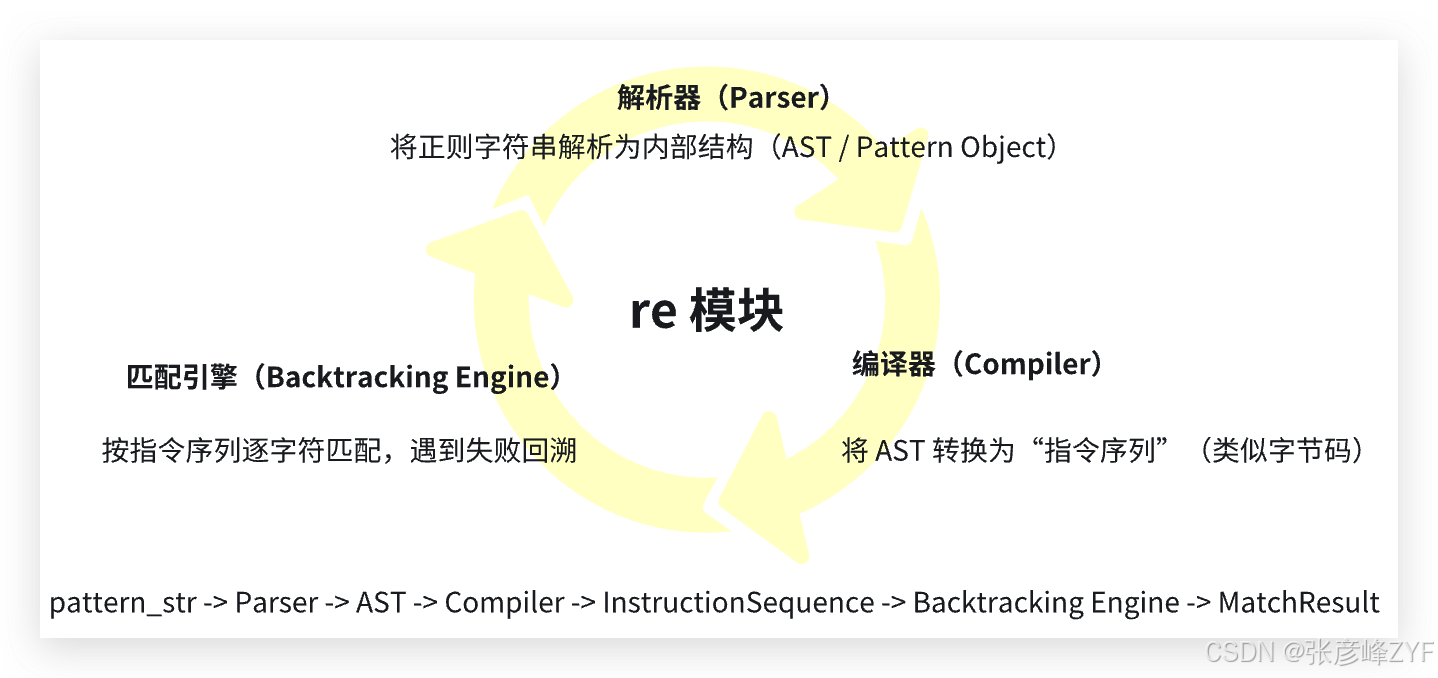
在 Python 中:
python
import re
pattern = re.compile(r"(\d+)-(\w+)")
# pattern 内部已经是"编译后的指令序列"
m = pattern.match("123-abc")-
re.compile一次解析 + 编译 -
match/search执行匹配逻辑 -
多次匹配可以复用
pattern,提升性能
(二)回溯引擎(Backtracking Engine)详解
1. 核心思想
Python 正则是 NFA 回溯引擎:
-
每个分支尝试匹配
-
如果失败,回退到上一个选择点,尝试下一路径
-
直到匹配成功或所有路径失败
举例:
python
import re
pattern = re.compile(r"(a|aa)b")
inputs = ["ab", "aab", "aaab"]
for s in inputs:
m = pattern.match(s)
print(s, "->", m)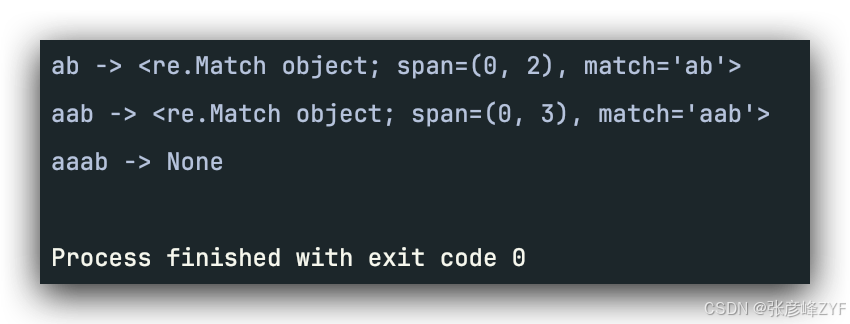
执行逻辑(抽象):
python
输入: aaab
尝试路径1: a -> b ? fail
回溯到分支: aa -> b ? fail
无更多分支 -> no match这就是回溯型正则的本质。
2. 逐字符匹配流程拆解
以正则 (\d{2,3})-(\w+) 匹配 "123-abc" 为例:
-
第一组 (\d{2,3}): 匹配 2 个字符
"12"→ 可以继续扩展到 3 个"123"→ 匹配完成 -
**匹配分隔符 "-":**成功
-
第二组 (\w+): 逐字符匹配
"abc"→ 完成 -
返回结果: 捕获组:
('123', 'abc')
代码演示:
python
import re
p = re.compile(r"(\d{2,3})-(\w+)")
m = p.match("123-abc")
if m:
print("捕获组:", m.groups())输出:
cs
捕获组: ('123', 'abc')(三)re.compile 的真实价值
1. 单次解析 vs 多次复用
python
import time
pattern_str = r"\d{4}-\d{2}-\d{2}"
text = "2024-01-01" * 10000
# 不使用 compile
start = time.time()
for t in text.split():
re.match(pattern_str, t)
print("无 compile:", time.time() - start)
# 使用 compile
compiled = re.compile(pattern_str)
start = time.time()
for t in text.split():
compiled.match(t)
print("使用 compile:", time.time() - start)效果:
-
re.compile将正则解析和编译只做一次 -
对批量匹配性能提升明显
2. 内部存储形式
-
字节码指令序列
-
指令类型:
-
LITERAL (匹配固定字符)
-
ANY (匹配任意字符)
-
BRANCH (分支选择)
-
REPEAT / REPEAT_ONE (量词)
-
GROUPREF (引用捕获组)
-
你可以把 Python 正则想象成 微型虚拟机,每条指令控制匹配行为。
二、正则表达式语法的"工程级理解"
(一)字符类、量词、分组的内部行为
1. 字符类 [abc] 与 \d、\w
-
匹配逻辑:检查当前字符是否在集合中
-
性能提示:单个字符匹配成本低,不会引入回溯
python
import re
pattern = re.compile(r"[a-zA-Z]\d{2}")
tests = ["A12", "b99", "Z0", "123"]
for t in tests:
print(t, "->", bool(pattern.fullmatch(t)))输出:
python
A12 -> True
b99 -> True
Z0 -> False
123 -> False内部执行:
-
[a-zA-Z]匹配一个字符 -
\d{2}匹配接下来的两个数字
2. 量词:* / + / ? / {m,n}
回溯行为差异:
| 量词 | 贪婪 | 非贪婪 | 描述 |
|---|---|---|---|
* |
是 | *? |
匹配 0 或多次 |
+ |
是 | +? |
匹配 1 或多次 |
? |
是 | ?? |
匹配 0 或 1 次 |
{m,n} |
是 | {m,n}? |
匹配 m~n 次 |
贪婪 vs 非贪婪:
python
text = "<tag>content</tag>"
import re
greedy = re.search(r"<.*>", text)
nongreedy = re.search(r"<.*?>", text)
print("贪婪:", greedy.group())
print("非贪婪:", nongreedy.group())输出:
Go
贪婪: <tag>content</tag>
非贪婪: <tag>内部原理:
-
贪婪:尝试匹配尽可能多 → 失败时回溯
-
非贪婪:尝试匹配最少 → 失败时前进
3. 捕获组 (...) vs 非捕获组 (?:...)
-
捕获组会存储匹配结果,增加 回溯栈开销
-
非捕获组只控制分支,不保存结果 → 更轻量
python
pattern1 = re.compile(r"(\d+)-(\w+)")
pattern2 = re.compile(r"(?:\d+)-(?:\w+)")
import time
s = "123-abc" * 100000
start = time.time()
pattern1.match(s)
print("捕获组:", time.time() - start)
start = time.time()
pattern2.match(s)
print("非捕获组:", time.time() - start)结果差异不大,但在大规模批量匹配中,非捕获组更优。
html
捕获组: 9.5367431640625e-07
非捕获组: 9.5367431640625e-07(二)边界锚点的正确使用
| 锚点 | 含义 | 示例 |
|---|---|---|
^ |
行/字符串开头 | ^ERROR |
$ |
行/字符串结尾 | end$ |
\b |
单词边界 | \bword\b |
\B |
非单词边界 | \Bend\B |
示例:
python
text = "hello world\nhello python"
print(re.findall(r"^hello", text)) # 默认行首
print(re.findall(r"^hello", text, re.MULTILINE)) # 多行匹配-
锚点减少回溯空间 → 提升性能
-
工程建议:尽量明确边界,避免使用
.*吃尽后回溯
(三)总结与工程实践建议
-
字符类 :首选
[abc]或预定义类\d、\w -
量词 :谨慎使用贪婪
*/+,避免回溯爆炸 -
分组:只捕获必要内容,非捕获组优先
-
边界锚点 :尽量明确
^、$、\b -
可读性 :复杂正则用
re.VERBOSE分行注释 -
批量匹配 :优先
re.compile+ 非捕获组
三、高级正则语法与隐藏能力
(一)前瞻 / 后顾断言(Lookaround)
核心概念:
-
前瞻(Lookahead):匹配某位置前方是否满足条件,但不消耗字符
-
后顾(Lookbehind):匹配某位置前方的字符是否满足条件,也不消耗字符
Python 语法:
| 类型 | 语法 | 示例 |
|---|---|---|
| 正前瞻 | (?=...) |
\d(?=\w) 匹配数字,但后面必须是字母 |
| 负前瞻 | (?!...) |
\d(?!\w) 匹配数字,但后面不是字母 |
| 正后顾 | (?<=...) |
(?<=\$)\d+ 匹配前面是 $ 的数字 |
| 负后顾 | (?<!...) |
(?<!\$)\d+ 匹配前面不是 $ 的数字 |
1. 前瞻示例
python
import re
text = "apple123 banana456 cherry789"
# 匹配数字前面是字母的数字
pattern = re.compile(r"\d+(?=\s)")
matches = pattern.findall(text)
print("正前瞻:", matches) # ['123', '456', '789']
# 匹配数字前面不是字母的数字
pattern2 = re.compile(r"\d+(?!\w)")
matches2 = pattern2.findall(text)
print("负前瞻:", matches2) # ['123', '456', '789']内部行为:
-
匹配器尝试
\d+ -
匹配位置后检查
(=?\s)是否成立 -
不消耗字符 → 后续匹配仍然从原位置继续
工程建议:前瞻常用于过滤匹配条件 而不改变捕获内容。
2. 后顾示例
python
text = "$100 200 $300"
# 匹配前面有 $ 的数字
pattern = re.compile(r"(?<=\$)\d+")
matches = pattern.findall(text)
print("正后顾:", matches) # ['100', '300']
# 匹配前面不是 $ 的数字
pattern2 = re.compile(r"(?<!\$)\d+")
matches2 = pattern2.findall(text)
print("负后顾:", matches2) # ['200']性能提示:
-
Python 后顾断言必须长度固定或可计算((?<=\w{2}))
-
长度不固定会触发 回溯增加 ,慎用大范围断言
(二)命名分组与结构化提取
1. 基本语法
python
(?P<name>...)
(?P=name) # 引用捕获组示例:
python
text = "Name: Alice, Age: 30"
pattern = re.compile(r"Name: (?P<name>\w+), Age: (?P<age>\d+)")
m = pattern.search(text)
if m:
print(m.groupdict()) # {'name': 'Alice', 'age': '30'}内部原理:
-
捕获组不仅存储值,还可以通过名字引用
-
提升可读性,避免
group(1)、group(2)混淆
2. 命名组引用示例
python
text = "abc abc"
pattern = re.compile(r"(?P<word>\w+)\s+(?P=word)")
m = pattern.search(text)
print(m.groupdict()) # {'word': 'abc'}-
(P=word)表示重复匹配与之前命名组相同的内容 -
工程应用:检测重复字段、重复标签、HTML/CSV 对齐检查
(三)条件表达式
语法:
python
(?(id/name)yes-pattern|no-pattern)-
如果捕获组存在或匹配成功 → 使用 yes-pattern
-
否则 → 使用 no-pattern
示例:
python
text = "foo123" # 或 "123"
pattern = re.compile(r"(foo)?(?(1)\d{3}|[a-z]{3})")
print(pattern.match(text)) # 匹配 foo123解释:
-
(foo)?捕获组 1 是否存在 -
(?(1)\d{3}|[a-z]{3})-
存在 → 匹配
\d{3} -
不存在 → 匹配
[a-z]{3}
-
工程建议:条件表达式可减少分支,但过度嵌套可读性差,慎用。
(四)多行 / DOTALL / VERBOSE 模式组合设计
1. 常用模式标志
| 标志 | 含义 |
|---|---|
re.MULTILINE |
^、$ 匹配行首/行尾 |
re.DOTALL |
. 匹配包括换行在内的所有字符 |
re.IGNORECASE |
忽略大小写 |
re.VERBOSE |
支持空格和注释,增强可读性 |
2. 组合示例
python
pattern = re.compile(r"""
(?P<date>\d{4}-\d{2}-\d{2}) # 日期
\s+
(?P<level>INFO|WARN|ERROR) # 日志级别
\s+
(?P<msg>.+) # 消息
""", re.VERBOSE | re.MULTILINE)
text = "2024-01-01 INFO Started\n2024-01-01 ERROR Failed"
for m in pattern.finditer(text):
print(m.groupdict())输出:
Kotlin
{'date': '2024-01-01', 'level': 'INFO', 'msg': 'Started'}
{'date': '2024-01-01', 'level': 'ERROR', 'msg': 'Failed'}工程提示:
-
re.VERBOSE+ 命名分组 → 正则可维护性极大提升 -
re.MULTILINE→ 多行日志处理必备 -
re.DOTALL→ 匹配跨行文本时必须
(五)工程注意事项
- 前瞻/后顾断言:功能强大,但会增加回溯;尽量固定长度后顾,避免性能陷阱
- 命名分组 :提升可读性和可维护性;大型匹配推荐命名分组 +
groupdict()提取 - 条件表达式:减少重复匹配逻辑;不适合深层嵌套或复杂分支
- 模式组合 :
VERBOSE→ 可读性;MULTILINE/DOTALL→ 根据日志/文本结构选择 - 调试技巧 :使用
pattern.findall()和pattern.finditer()分析匹配结果;对复杂正则,画"状态流图"帮助理解回溯路径
第三篇:高性能正则表达式设计与优化
本篇强调工程实践中的性能优化。我们开始学习 指数级回溯原因、正则 DoS 攻击风险、高效设计原则、工程级优化策略,掌握拆分复杂正则、限定回溯空间、使用原子分组、缓存编译对象、批量匹配和流式处理等技术。
一、正则表达式性能问题的根源
(一)指数级回溯(Catastrophic Backtracking)
1. 回溯机制复盘
在之前,我们提到 Python 的 re 是 回溯型 NFA:
-
每个分支尝试匹配
-
失败 → 回退 → 尝试下一个分支
-
多个量词叠加 → 匹配路径呈指数级增长
公式化理解:若有 n 个可选分支,每个分支重复 m 次,匹配路径数可能达到 O(branches^repeat)
2. 简单指数级示例
python
import re
import time
pattern = re.compile(r"(a+)+b") # 回溯陷阱
s = "a" * 25 + "b"
start = time.time()
m = pattern.match(s)
end = time.time()
print("匹配耗时:", end - start)分析:
-
(a+)+允许多层重复 -
引擎尝试把所有
a分配给内层+→ 外层+→ 回退 -
每次失败 → 回溯 → 指令重新尝试
-
当
a数量增加时,时间呈指数级增长
3. 可视化匹配树
objectivec
输入: a a a b
模式: (a+)+ b
1. 外层 + 尝试 3 a
内层 + 尝试 3 a → b ? fail
内层回退 → 尝试 2 a, 外层剩 1 a → b ? fail
...
匹配树分支迅速爆炸这是典型 Catastrophic Backtracking。
(二)常见性能灾难案例拆解
1. 贪婪量词嵌套
python
pattern = re.compile(r"(a|aa)+b")
s = "aaaaaaaaaaaaab"
pattern.match(s) # 指令执行路径数指数级-
原因:
(a|aa)+分支选择 → 回溯路径多 -
教训:尽量避免重叠分支嵌套量词
2. 不明确边界
python
pattern = re.compile(r".*end")
text = "a" * 10000 + "end"
pattern.match(text) # 贪婪 .* 吃尽 → 回溯找 end-
.*会尽量吃掉全部字符 -
失败 → 回退逐字符匹配 → 回溯次数 = 字符长度
-
教训:明确边界能减少回溯
3. 可选分支组合
python
pattern = re.compile(r"(ab?)+c")
text = "abababababababababababc"
pattern.match(text)-
每个
b?都是二选一 → 路径数呈 2^n -
对长输入极易爆炸
(三)正则 DoS(ReDoS)攻击原理
-
ReDoS = Regular Expression Denial of Service
-
利用回溯型正则的性能爆炸,发送特制输入导致 CPU 占用飙升
示例:
python
import re
import time
pattern = re.compile(r"(a+)+$")
evil_input = "a" * 30
start = time.time()
pattern.match(evil_input)
print("匹配耗时:", time.time() - start)-
匹配耗时可能数秒甚至数十秒
-
工程警告:用户输入正则必须防护
(四)性能问题的本质
| 问题类型 | 本质原因 | 对策 |
|---|---|---|
| 指数回溯 | 贪婪量词嵌套 + 分支 | 拆分正则 / 原子化 / 限制量词 |
| 不明确边界 | .* 无边界 |
明确锚点,使用限定字符类 |
| 可选分支过多 | `(a | aa |
| 用户输入攻击 | 回溯爆炸 | 输入长度限制、DFA 风格引擎 |
(五)工程建议
-
先失败原则: 正则应尽量快速排除不匹配情况,示例:
^ERROR优于.*ERROR -
明确边界原则: 避免贪婪
.*吃尽文本,增加回溯 -
**拆分复杂正则:**多个小正则比一个巨型正则可控,示例:日志解析 → 先匹配日期 → 再匹配 level → 再提取 message
-
限制量词范围:
(a{1,10})+优于(a+)+,限定最大重复次数 → 限制回溯树高度 -
**测试压力场景:**使用长输入 + 边界模式测试,提前发现潜在指数级回溯
二、高效正则的设计原则
(一)"先失败"原则(Fail Fast)
1. 原理依据
-
Python 回溯型正则在匹配失败时会逐路径回溯
-
如果匹配可以尽早失败 → 回溯路径数大幅减少
-
等价于削减 NFA 树高度
2. 工程实践示例
python
import re
text = "INFO 2024-01-01 User login"
# 低效写法
pattern = re.compile(r".*User.*login")
print(bool(pattern.match(text)))
# 高效写法(先匹配固定前缀)
pattern_fast = re.compile(r"INFO.*User.*login")
print(bool(pattern_fast.match(text)))-
低效:
.*从头匹配整个字符串 → 回溯可能多 -
高效:明确开头
"INFO"→ 不匹配立即失败,减少回溯
原则总结 :匹配逻辑先过滤最确定条件,再匹配模糊内容
(二)明确边界原则(Anchoring)
1. 原理依据
-
未明确边界的量词会吃尽字符 → 失败时产生大量回溯
-
DFA/NFA 理论告诉我们:边界限制可以剪枝状态空间
2. 工程示例
python
text = "2024-01-01 ERROR Something failed"
# 边界不明确
pattern1 = re.compile(r".*ERROR.*")
# 明确边界
pattern2 = re.compile(r"^2024-01-01 ERROR")
print(bool(pattern1.match(text))) # True
print(bool(pattern2.match(text))) # True-
明确边界减少了
.*尝试匹配的位置 -
对大文本或多行日志性能提升明显
原则总结 :尽量使用 ^ / $ / 字符类代替宽泛量词
(三)限定回溯空间(Restrict Backtracking)
1. 原理依据
-
回溯树的大小决定匹配时间
-
嵌套量词或重叠分支 → 指令路径指数级增长
2. 工程技巧
a. 限定量词范围:
python
# 高风险
re.compile(r"(a+)+b")
# 安全
re.compile(r"(a{1,10}){1,5}b")b. 使用非捕获组减少回溯栈开销:
python
# 捕获组增加存储
re.compile(r"(\d+)-(\w+)")
# 非捕获组
re.compile(r"(?:\d+)-(?:\w+)")原则总结 :量词、分支必须有明确上限,必要时使用非捕获组
(四)拆分复杂正则 vs 单一巨型正则
1. 原理依据
-
巨型正则包含大量分支 → 回溯树高度大
-
拆分正则可序列化匹配过程,降低一次性回溯风险
2. 工程示例
假设日志行格式:DATE LEVEL MESSAGE
低效巨型正则:
python
pattern = re.compile(r"(\d{4}-\d{2}-\d{2})\s+(INFO|WARN|ERROR)\s+(.+)")高效拆分正则:
python
date_pat = re.compile(r"\d{4}-\d{2}-\d{2}")
level_pat = re.compile(r"INFO|WARN|ERROR")
for line in logs:
date_match = date_pat.match(line)
if not date_match:
continue
level_match = level_pat.search(line)
if not level_match:
continue
message = line[level_match.end():]-
拆分正则 → 每一步失败立即跳过 → 避免整个正则回溯
-
可维护性、调试性也大幅提升
(五)原理总结与依据
| 设计原则 | 原理依据 | 工程体现 |
|---|---|---|
| 先失败 (Fail Fast) | 回溯路径剪枝,早期排除失败 | 先匹配固定前缀或确定条件 |
| 明确边界 | 削减回溯树状态空间 | 使用 ^ / $ / 字符类 |
| 限定回溯空间 | 回溯树大小决定匹配耗时 | 限定量词、非捕获组 |
| 拆分正则 | 巨型正则回溯风险指数级 | 多个小正则,序列化匹配 |
(六)工程级落地思路
-
**分析匹配路径:**大量重复量词 → 高风险,使用工具或小输入测试回溯
-
**先匹配确定条件:**固定前缀、固定分隔符、必然字符
-
**拆分复杂匹配:**日志解析、配置文件提取 → 多阶段匹配
-
限制量词和分支:
(a{1,10})+代替(a+)+ -
**可读性与维护性:**命名分组 + VERBOSE,拆分正则比单行复杂正则更安全
三、正则表达式的工程级优化策略
(一)原子分组与占有量词(Python 中的替代方案)
1. 原理依据
-
原子分组(Atomic Group):匹配完成后不允许回溯
-
占有量词(Possessive Quantifier):匹配尽可能多且不回退
-
Python
re不直接支持原生占有量词*+,++ -
可通过 嵌套非捕获组 + 前瞻/替代方案 模拟
2. Python 原子分组模拟示例
目标:匹配 a+,匹配完不回退
python
import re
# 经典易回溯
pattern = re.compile(r"(a+)+b")
# 模拟原子分组:使用非捕获组 + 前瞻断言
pattern_safe = re.compile(r"(?:a+)(?=b)")
text = "aaaaaaaaaaaaab"
print(bool(pattern.match(text))) # 可能慢,回溯多
print(bool(pattern_safe.match(text))) # 安全,高效原理:
-
(a+)+→ 多层重复量词 → 回溯爆炸 -
(?:a+)(?=b)→ 前瞻约束,不消耗字符 → 减少回溯路径
工程实践:当量词嵌套复杂时,优先考虑原子化匹配 或前瞻模拟。
(二)re 模块 vs regex 第三方库对比
| 特性 | re | regex |
|---|---|---|
| 支持占有量词 | ❌ | ✅ |
| 支持可变长度后顾 | ❌ | ✅ |
| 支持递归匹配 | ❌ | ✅ |
| 性能 | 中等 | 高,可选 DFA 优化 |
示例:
python
import regex
pattern = regex.compile(r"(a+)+b")
text = "aaaaaaaaaaaaab"
# regex 支持占有量词
pattern_possessive = regex.compile(r"(a++)b")
print(pattern_possessive.match(text)) # 高效匹配,无回溯工程建议:
-
对性能敏感、复杂量词或大输入 → 使用 regex
-
简单场景 → re 足够
-
regex 支持原子化、递归和 DFA 优化,可规避大部分回溯问题
(三)编译缓存与复用策略
1. 原理依据
-
re.compile会生成内部字节码 -
多次使用相同模式 → 避免重复解析,提高效率
2. 示例
python
import re, time
pattern_str = r"\d{4}-\d{2}-\d{2}"
text_list = ["2024-01-01", "2024-01-02"] * 100000
# 不使用 compile
start = time.time()
for t in text_list:
re.match(pattern_str, t)
print("不使用 compile:", time.time() - start)
# 使用 compile
compiled = re.compile(pattern_str)
start = time.time()
for t in text_list:
compiled.match(t)
print("使用 compile:", time.time() - start)-
编译复用 → CPU 时间大幅下降
-
工程实践:批量处理或循环匹配必须 compile
(四)批量匹配与流式处理
1. 大文本场景
-
单次匹配大文本 → 内存占用高,可能回溯风险
-
建议 分块匹配 / 流式匹配
python
import re
pattern = re.compile(r"\d{4}-\d{2}-\d{2}")
with open("big_log.txt") as f:
for line in f:
m = pattern.search(line)
if m:
print(m.group())-
一行一行匹配 → 内存压力低
-
易控制回溯风险
-
可结合 先失败 + 明确边界 原则优化性能
2. 批量处理技巧
-
将多个小正则组合为函数序列处理
-
使用 finditer 而非 findall 可减少中间对象占用
-
对重复模式 → re.compile + 缓存模式对象
(五)工程优化总结
| 优化策略 | 原理依据 | 示例与实践 |
|---|---|---|
| 原子分组 / 占有量词 | 削减回溯树 | (?:a+)(?=b) / regex 支持 a++ |
| 编译缓存 | 避免重复解析字节码 | compiled = re.compile(r"\d{4}-\d{2}-\d{2}") |
| 批量匹配 / 流式处理 | 控制内存与回溯 | 按行匹配日志 → 减少一次性回溯 |
| 第三方库替代 | DFA / 占有量词 / 可变后顾 | regex 高性能匹配复杂模式 |
| 拆分复杂正则 | 回溯路径控制 | 多阶段匹配 → 先匹配确定条件 → 再匹配模糊内容 |
(六)工程实践建议
-
复杂量词嵌套 → 优先原子化
-
重复使用模式 → compile 并缓存
-
大文本匹配 → 分块或流式处理
-
性能敏感或复杂语法 → 考虑 regex 库
-
先失败 + 明确边界 + 拆分正则 → 高效组合
第四篇:结构化匹配:Python 3.10+ 模式匹配(PEP 634)
本篇介绍 Python 3.10 引入的 match-case 语法,强调结构化匹配在工程中的优势。学会常量模式、序列模式、映射模式、类模式及守卫条件的使用,并掌握正则与 match-case 的协作方式,实现日志解析、AST 数据处理和状态机式代码重构。
一、match-case 语法的设计哲学
(一)为什么 Python 引入结构化模式匹配
1. 背景与痛点
在 Python 3.9 之前,复杂分支逻辑主要依赖:
python
if isinstance(obj, dict) and "type" in obj:
if obj["type"] == "A":
handle_a(obj)
elif obj["type"] == "B":
handle_b(obj)
...问题:
-
代码冗长 :多层嵌套
if可读性差 -
难以扩展:新增类型需要增加分支,容易出错
-
可维护性低:复杂结构处理逻辑分散
2. 设计目标
PEP 634 提出 结构化模式匹配(Structural Pattern Matching),目标是:
-
表达数据结构:不仅匹配值,还匹配结构
-
减少分支嵌套 :用单一
match-case替代多层if-elif -
增强可读性:模式清晰、语义直观
-
支持守卫条件:对匹配结果进行额外判断
(二)match-case 与 if-elif 的本质差异
1. 对比示例
传统 if-elif:
python
def handle_event(event):
if isinstance(event, dict) and event.get("type") == "login":
print("Login event:", event)
elif isinstance(event, dict) and event.get("type") == "logout":
print("Logout event:", event)match-case 实现:
python
def handle_event(event):
match event:
case {"type": "login", "user": user}:
print("Login event:", user)
case {"type": "logout", "user": user}:
print("Logout event:", user)差异分析:
| 特性 | if-elif | match-case |
|---|---|---|
| 结构匹配 | 手动提取 | 内置字典/序列匹配 |
| 可读性 | 嵌套多,复杂 | 扁平化,模式清晰 |
| 绑定变量 | 需要手动 | 自动绑定(user) |
| 扩展性 | 逐分支添加 | 新模式直接添加 case |
2. 性能角度
-
match-case底层也是匹配树,但优化了序列和映射解包 -
对复杂结构,避免多次
isinstance和 key 检查 -
可视为 结构化模式匹配 + 可选守卫 的组合
(三)表达式匹配 vs 语句匹配
1. 语句匹配(Statement Pattern)
-
最常用
-
对象匹配,绑定变量,执行语句
python
match point:
case (0, 0):
print("Origin")
case (x, 0):
print(f"X-axis at {x}")
case (0, y):
print(f"Y-axis at {y}")
case (x, y):
print(f"Point at ({x}, {y})")-
匹配序列模式
(x, y) -
自动解包 → 绑定变量 → 执行对应 case
2. 表达式匹配(Expression Pattern)
-
将匹配结果作为表达式使用
-
常用于守卫条件或赋值表达式
python
match value:
case int() as i if i > 0:
print("Positive integer:", i)
case int() as i if i < 0:
print("Negative integer:", i)-
int() as i→ 类型匹配并绑定 -
if i > 0→ 守卫条件(Guard) -
避免在 if-elif 中重复写判断逻辑
(四)工程实践建议
-
**数据结构明确时使用 match-case:**字典事件、JSON 数据、序列数据非常适合
-
**结合守卫条件减少嵌套:**提前排除不匹配情况 → "先失败"原则延续到结构化匹配
-
**命名绑定变量:**保持清晰语义,避免重复访问字典
-
模式覆盖顺序: match-case 会按顺序匹配 → 常规 case 放前,通配符
_放最后
二、结构模式详解
(一)常量模式(Literal Pattern)
1. 概念
-
匹配固定值,如数字、字符串、布尔值、
None -
本质是值比较,效率高,无回溯风险
2. 示例
python
def response(code):
match code:
case 200:
return "OK"
case 404:
return "Not Found"
case 500:
return "Server Error"
case _:
return "Unknown"
print(response(200)) # OK
print(response(403)) # Unknown内部机制:
-
比较对象与常量值
-
匹配成功 → 执行 case
-
匹配失败 → 顺序尝试下一个 case
工程建议:常量模式用于状态码、固定标识、枚举类型判断。
(二)序列模式(Sequence Pattern)
1. 概念
-
匹配列表、元组、字符串等序列
-
可绑定元素到变量
-
支持可选通配符
_和解包*rest
2. 示例
python
point = (0, 5)
match point:
case (0, y):
print(f"X=0, Y={y}")
case (x, 0):
print(f"Y=0, X={x}")
case (x, y):
print(f"Point at ({x},{y})")输出:
ruby
X=0, Y=53. 可变长度解包
python
lst = [1, 2, 3, 4]
match lst:
case [first, *middle, last]:
print(first, middle, last) # 1 [2, 3] 4内部原理:
-
序列模式依次解包元素
-
支持
*rest→ 动态捕获剩余元素 -
匹配失败 → 直接尝试下一个 case
工程实践:日志条目、数组数据、CSV 解析时非常适用。
(三)映射模式(Mapping Pattern)
1. 概念
-
匹配字典对象
-
可以匹配指定键并绑定对应值
-
内部使用
dict.__getitem__或get进行匹配
2. 示例
python
event = {"type": "login", "user": "Alice"}
match event:
case {"type": "login", "user": user}:
print("Login:", user)
case {"type": "logout", "user": user}:
print("Logout:", user)输出:
Groovy
Login: Alice内部机制:
-
对指定 key 查找
-
值匹配 → 绑定变量
-
匹配失败 → 尝试下一个 case
工程实践:处理 JSON、API 请求、事件流非常高效。
(四)类模式(Class Pattern)
1. 概念
-
匹配自定义类对象
-
内部通过
__match_args__或属性绑定 -
支持绑定实例属性到变量
2. 示例
python
class Point:
__match_args__ = ("x", "y")
def __init__(self, x, y):
self.x = x
self.y = y
p = Point(0, 5)
match p:
case Point(0, y):
print(f"X=0, Y={y}")
case Point(x, 0):
print(f"Y=0, X={x}")输出:
css
X=0, Y=5内部原理:
-
检查对象类型
isinstance(obj, Class) -
按
__match_args__顺序获取属性 -
匹配成功 → 绑定变量
工程实践:处理复杂对象数据结构、AST 节点解析时非常适合。
(五)通配符 _ 与守卫条件(Guard)
1. 通配符 _
-
匹配任意值,但不绑定变量
-
用于忽略不关心的字段
python
match (1, 2, 3):
case (1, _, 3):
print("Matched first and last")输出:
vbnet
Matched first and last2. 守卫条件(Guard)
-
if附加条件判断匹配结果 -
匹配先按模式 → 再按守卫条件
python
x = 15
match x:
case int() as i if i > 0:
print("Positive:", i)
case int() as i if i < 0:
print("Negative:", i)输出:
java
Positive: 15内部原理:
-
先匹配模式
-
匹配成功 → 计算守卫条件
-
守卫为 False → 尝试下一个 case
工程实践:用于动态判断、规则过滤、事件筛选。
(六)工程实践总结
-
常量模式 → 状态码、枚举
-
序列模式 → 列表、元组、字符串拆解
-
映射模式 → JSON、字典事件
-
类模式 → 自定义对象、AST 节点
-
通配符 + 守卫 → 忽略无关字段 + 增加条件判断
设计原则:
-
先匹配最确定的模式
-
可绑定变量 → 避免重复访问
-
通配符 _ 提升可读性
-
守卫条件配合"先失败"原则 → 高效且安全
三、match-case 与正则表达式的协作
(一)文本解析 + 结构匹配的组合范式
1. 背景与思路
-
正则表达式擅长:快速匹配、提取文本片段
-
match-case 擅长:结构化数据处理、条件分支
-
组合模式:
-
正则先提取原始数据 → 得到字典或序列
-
match-case 按结构处理 → 执行逻辑或转换
-
2. 简单示例
python
import re
log = "2025-12-20 16:00 ERROR User 'Alice' failed login"
# Step 1: 正则提取
pattern = re.compile(r"(?P<date>\d{4}-\d{2}-\d{2}) (?P<time>\d{2}:\d{2}) (?P<level>\w+) User '(?P<user>\w+)' (?P<action>.+)")
m = pattern.match(log)
if m:
data = m.groupdict()
# Step 2: match-case 处理
match data:
case {"level": "ERROR", "action": "failed login", "user": user}:
print(f"Alert! User {user} failed login at {data['time']}")
case {"level": "INFO"}:
print("Info log")输出:
javascript
Alert! User Alice failed login at 16:00分析:
-
正则负责提取关键字段
-
match-case 按业务逻辑分支处理
-
分离文本解析与逻辑决策 → 高可维护性
(二) AST 风格数据处理
1. 概念
-
Abstract Syntax Tree (AST) 风格:将文本解析为结构化对象或字典树
-
优势:
-
可组合复杂规则
-
可复用 match-case 模式处理节点
-
提升工程可读性
-
2. 示例:简单算术表达式解析
python
import re
expr = "x + 3"
# Step 1: 正则拆解
pattern = re.compile(r"(?P<left>\w+)\s*(?P<op>[+-/*])\s*(?P<right>\w+)")
m = pattern.match(expr)
if m:
node = m.groupdict()
# Step 2: match-case AST 处理
match node:
case {"op": "+", "left": left, "right": right}:
print(f"Addition: {left} + {right}")
case {"op": "-", "left": left, "right": right}:
print(f"Subtraction: {left} - {right}")输出:
php
Addition: x + 3工程启示:
-
正则 → 文本拆解
-
match-case → AST 风格节点处理
-
可扩展到多层表达式树 → 构建解释器或规则引擎
(三)状态机式代码重构案例
1. 背景
日志、事件流、协议解析常常具有状态依赖:
-
状态 0:等待登录
-
状态 1:登录成功
-
状态 2:异常处理
传统写法:
python
state = 0
for log in logs:
if state == 0 and "login" in log:
state = 1
elif state == 1 and "action" in log:
# process action
state = 2问题:分支嵌套多,难维护
2. 正则 + match-case + 状态机
python
import re
logs = [
"User Alice login",
"User Alice failed action",
"User Bob login",
]
state = 0
pattern = re.compile(r"User (?P<user>\w+) (?P<action>\w+)")
for log in logs:
m = pattern.match(log)
if not m:
continue
event = m.groupdict()
match (state, event):
case (0, {"action": "login", "user": user}):
print(f"{user} logged in")
state = 1
case (1, {"action": "failed", "user": user}):
print(f"{user} failed action")
state = 2
case _:
print(f"Unhandled event: {event}")输出:
ruby
Alice logged in
Alice failed action
Unhandled event: {'user': 'Bob', 'action': 'login'}分析:
-
状态机 + 正则 → 精准捕获事件
-
match-case → 扁平化分支,逻辑清晰
-
可扩展 → 新状态、新事件直接添加 case
(四)高级组合实践
1. 多级匹配示例
python
log = "2025-12-20 ERROR File 'config.yaml' not found"
pattern = re.compile(
r"(?P<date>\d{4}-\d{2}-\d{2}) (?P<level>\w+) File '(?P<file>[^']+)' (?P<message>.+)"
)
m = pattern.match(log)
if m:
data = m.groupdict()
match data:
case {"level": "ERROR", "file": "config.yaml"}:
print("Config file error")
case {"level": "ERROR"}:
print("Other error")
case {"level": "INFO"}:
print("Info log")输出:
sql
Config file error总结规律:
-
正则抽取字段 → 结构化字典/对象
-
match-case 按模式和守卫处理逻辑
-
多级匹配 → 规则覆盖清晰,可维护
(五)工程实践总结
-
**正则提取结构化数据:**日志、事件流、协议解析
-
**match-case 处理逻辑决策:**条件清晰、可读性高
-
状态机结合: 复杂流程可通过
(state, event)匹配 -
**AST 风格:**文本 → 字典/对象 → match-case
-
**守卫条件 + 通配符:**可快速过滤不关心字段、增加安全性
第五篇:从正则到解析:模式匹配的系统化设计
本篇将模式匹配上升到系统化设计。了解 正则边界、手写解析器、正则+状态机混合设计,学习如何构建日志解析系统、配置规则匹配引擎和 DSL,实现高可维护性、可扩展的模式匹配架构。
一、正则表达式的边界与替代方案
(一)为什么复杂语法不适合正则
1. 正则适用场景回顾
-
高效匹配 线性、规则明确的文本
-
可快速提取字段,进行简单转换
-
示例:日期、日志行、URL、简单 key-value
python
import re
line = "2025-12-20 ERROR User Alice failed login"
pattern = re.compile(r"(?P<date>\d{4}-\d{2}-\d{2}) (?P<level>\w+) User (?P<user>\w+) (?P<action>.+)")
m = pattern.match(line)
if m:
print(m.groupdict())输出:
Swift
{'date': '2025-12-20', 'level': 'ERROR', 'user': 'Alice', 'action': 'failed login'}- 高效且可维护
2. 正则局限性
| 问题 | 原因 | 示例 |
|---|---|---|
| 嵌套语法 | 正则不支持递归匹配 | 匹配括号嵌套 (a(b(c))) |
| 上下文依赖 | 回溯型正则无法处理动态状态 | 根据前文内容匹配不同规则 |
| 可读性 | 复杂正则难维护 | `(a+)+b(c |
| 性能 | 回溯爆炸 | (a+)+b 大量重复 |
(二)手写解析器 vs 正则
1. 手写解析器优势
-
可控回溯 → 性能可预测
-
支持递归、嵌套结构
-
状态明确 → 易维护、扩展
2. 示例:嵌套括号解析器
目标:解析嵌套括号并返回深度
python
def parse_parentheses(s):
stack = []
max_depth = 0
for c in s:
if c == '(':
stack.append(c)
max_depth = max(max_depth, len(stack))
elif c == ')':
if not stack:
raise ValueError("Unmatched closing parenthesis")
stack.pop()
if stack:
raise ValueError("Unmatched opening parenthesis")
return max_depth
expr = "(a+(b+c)*(d+e))"
print(parse_parentheses(expr)) # 3对比:
-
正则无法处理递归嵌套(无限层数)
-
手写解析器清晰、可扩展 → 可以增加类型检查、AST 构建等
3. 状态机解析示例
目标:解析简单表达式,如 x + 3 * y
python
import re
token_pattern = re.compile(r"\s*(?P<num>\d+)|(?P<op>[+*/-])|(?P<var>\w+)")
def tokenize(expr):
for m in token_pattern.finditer(expr):
if m.group("num"):
yield ("NUM", int(m.group("num")))
elif m.group("op"):
yield ("OP", m.group("op"))
elif m.group("var"):
yield ("VAR", m.group("var"))
expr = "x + 3 * y"
tokens = list(tokenize(expr))
print(tokens)输出:
python
[('VAR', 'x'), ('OP', '+'), ('NUM', 3), ('OP', '*'), ('VAR', 'y')]-
通过 正则完成基础拆分
-
后续通过 状态机或解析器 构建 AST 或执行逻辑
-
结合模式匹配处理节点 → 高可维护系统
(三)正则 + 状态机混合设计
1. 思路
-
**正则负责快速切分:**提取 token 或关键字段
-
**状态机或手写解析器负责结构化处理:**控制流程、嵌套、上下文依赖
-
**match-case 或映射模式处理逻辑:**高可读性、可扩展
2. 实例:简易日志 DSL 解析
日志样例:
Erlang
[INFO] 2025-12-20 User Alice login
[ERROR] 2025-12-20 User Bob failed action解析器实现:
python
import re
log_pattern = re.compile(r"\[(?P<level>\w+)\]\s+(?P<date>\d{4}-\d{2}-\d{2}) User (?P<user>\w+) (?P<action>.+)")
def parse_logs(logs):
for line in logs:
m = log_pattern.match(line)
if not m:
continue
data = m.groupdict()
# match-case 处理逻辑
match data:
case {"level": "INFO", "action": "login", "user": user}:
print(f"{data['date']}: {user} logged in")
case {"level": "ERROR"}:
print(f"{data['date']}: ERROR for {data['user']} -> {data['action']}")
logs = [
"[INFO] 2025-12-20 User Alice login",
"[ERROR] 2025-12-20 User Bob failed action",
]
parse_logs(logs)输出:
Scala
2025-12-20: Alice logged in
2025-12-20: ERROR for Bob -> failed action分析:
-
正则 → 提取结构化字段
-
match-case → 业务逻辑决策
-
易扩展 → 新日志类型仅需新增 case
(四)工程实践总结
-
正则适合规则明确、线性文本
-
复杂嵌套、递归结构 → 手写解析器或状态机
-
状态机 + match-case → 可维护流程控制
-
正则 + 状态机混合 → 高效、可控、可扩展
-
Tokenize → AST → match-case → 业务处理 是通用模式
二、模式匹配在真实工程中的架构形态
(一)解析系统设计
1. 背景
-
互联网产品产生大量日志
-
日志类型多、结构不一
-
系统需快速解析、分类、报警或统计
2. 架构思路
-
**文本抽取层:**正则提取关键字段(时间、级别、用户、事件类型)
-
**结构化匹配层:**match-case 或字典映射进行逻辑处理
-
**输出/存储层:**转化为统一格式、存入数据库或消息队列
3. 示例实现
python
import re
# Step 1: 正则抽取
log_pattern = re.compile(
r"\[(?P<level>\w+)\]\s+(?P<date>\d{4}-\d{2}-\d{2}) User (?P<user>\w+) (?P<action>.+)"
)
logs = [
"[INFO] 2025-12-20 User Alice login",
"[ERROR] 2025-12-20 User Bob failed action",
"[WARN] 2025-12-20 User Charlie password attempt",
]
for line in logs:
m = log_pattern.match(line)
if not m:
continue
data = m.groupdict()
# Step 2: match-case 结构化处理
match data:
case {"level": "INFO", "action": "login", "user": user}:
print(f"{data['date']}: {user} logged in")
case {"level": "ERROR"}:
print(f"{data['date']}: ERROR -> {data['user']} -> {data['action']}")
case {"level": "WARN"}:
print(f"{data['date']}: Warning -> {data['user']} -> {data['action']}")输出:
python
2025-12-20: Alice logged in
2025-12-20: ERROR -> Bob -> failed action
2025-12-20: Warning -> Charlie -> password attempt工程启示:
-
解析和处理逻辑分层 → 高可维护性
-
新日志类型 → 仅增加新的 case
-
正则负责抽取字段,match-case负责决策逻辑
(二)配置规则匹配引擎
1. 背景
-
风控系统、配置系统常有规则 DSL
-
规则复杂,需根据条件匹配执行策略
2. 核心设计思路
-
**DSL 转化为数据结构:**JSON、字典、或 AST
-
**匹配引擎:**match-case 或函数映射处理规则
-
**执行策略:**根据匹配结果触发对应动作
3. 示例:简单风控规则引擎
python
rules = [
{"type": "login", "action": "failed", "severity": "high"},
{"type": "transaction", "amount": lambda x: x > 10000, "severity": "medium"},
]
events = [
{"type": "login", "action": "failed", "user": "Alice"},
{"type": "transaction", "amount": 15000, "user": "Bob"},
]
for event in events:
for rule in rules:
match (event, rule):
case ({"type": etype, **edata}, {"type": rtype, "action": raction, **_}):
if etype == rtype and edata.get("action") == raction:
print(f"Trigger high severity alert for {edata.get('user')}")
case ({"type": "transaction", "amount": amt, **edata}, {"amount": cond, **_}):
if cond(amt):
print(f"Trigger medium severity alert for {edata.get('user')}")输出:
Clojure
Trigger high severity alert for Alice
Trigger medium severity alert for Bob分析:
-
规则 DSL → 字典结构
-
match-case + lambda → 灵活匹配条件
-
易扩展 → 新规则只需添加字典或 case
(三)规则 DSL 的实现思路
1. DSL 架构设计
-
文本规则 → 解析 → AST → 执行
-
可支持复杂逻辑:
and,or,not -
可以结合状态机 → 支持上下文敏感匹配
2. 示例:日志 DSL
规则文本:
Matlab
IF level == "ERROR" AND action contains "failed" THEN alert HIGH
IF level == "WARN" THEN alert MEDIUM解析 + 执行示例:
python
dsl_rules = [
{"conditions": [{"field": "level", "op": "==", "value": "ERROR"},
{"field": "action", "op": "contains", "value": "failed"}],
"alert": "HIGH"},
{"conditions": [{"field": "level", "op": "==", "value": "WARN"}],
"alert": "MEDIUM"}
]
events = [
{"level": "ERROR", "action": "failed login", "user": "Alice"},
{"level": "WARN", "action": "password attempt", "user": "Charlie"}
]
def match_rule(event, rule):
for cond in rule["conditions"]:
val = event.get(cond["field"])
if cond["op"] == "==" and val != cond["value"]:
return False
if cond["op"] == "contains" and cond["value"] not in val:
return False
return True
for event in events:
for rule in dsl_rules:
if match_rule(event, rule):
print(f"{event['user']} triggers {rule['alert']} alert")输出:
vbscript
Alice triggers HIGH alert
Charlie triggers MEDIUM alert分析:
-
文本规则 → 字典化 → match_rule 处理
-
可扩展 → 新运算符、条件类型
-
可维护 → DSL 与执行逻辑分离
(四)工程实践总结
-
分层设计: 文本解析 → 数据结构 → 规则匹配 → 执行动作
-
正则负责字段抽取: 高效提取结构化数据
-
match-case 或规则映射处理逻辑: 高可读性、高扩展性
-
DSL 支持复杂规则: 用户可自定义规则 → 系统动态加载执行
-
状态机结合: 可处理上下文敏感规则和复杂流程
三、可维护的模式匹配代码
(一)正则表达式的命名与文档化
1. 背景
-
复杂正则常出现"黑魔法"问题
-
可读性差 → 后期维护成本高
-
工程实践中 命名 + 文档化 是基础要求
2. 命名规范
-
常量命名:使用全大写,便于区分
-
描述语义:正则表达式描述其用途
python
import re
# 匹配日期 YYYY-MM-DD
DATE_PATTERN = re.compile(r"\d{4}-\d{2}-\d{2}")
# 匹配日志级别
LOG_LEVEL_PATTERN = re.compile(r"\[(?P<level>\w+)\]")3. 文档化建议
- 使用 docstring 或注释说明用途、匹配目标和限制
python
# DATE_PATTERN: 匹配格式为 YYYY-MM-DD 的日期字符串
# 示例: '2025-12-20' -> 匹配成功
# 注意: 不处理非法日期,如 2025-13-40
DATE_PATTERN = re.compile(r"\d{4}-\d{2}-\d{2}")工程实践总结:
-
正则命名 → 立即知道用途
-
文档化 → 避免团队二次阅读源码猜逻辑
-
高复杂度正则 → 推荐配合单元测试验证
(二)单元测试与回归测试
1. 背景
-
正则和结构匹配逻辑可能会随着规则迭代改变
-
未测试 → 高风险,容易出现匹配错误或性能问题
2. 单元测试示例
python
import unittest
import re
DATE_PATTERN = re.compile(r"\d{4}-\d{2}-\d{2}")
class TestPatterns(unittest.TestCase):
def test_date_valid(self):
self.assertTrue(DATE_PATTERN.fullmatch("2025-12-20"))
self.assertTrue(DATE_PATTERN.fullmatch("1999-01-01"))
def test_date_invalid(self):
self.assertIsNone(DATE_PATTERN.fullmatch("2025-13-40"))
self.assertIsNone(DATE_PATTERN.fullmatch("20251220"))
if __name__ == "__main__":
unittest.main()特点:
-
正向测试 → 验证匹配正确
-
反向测试 → 验证匹配失败
-
工程实践 → 每个正则都应至少包含正/反测试用例
3. 回归测试示例
- 规则或正则修改 → 避免旧匹配被破坏
python
LOG_PATTERN = re.compile(r"\[(?P<level>\w+)\] (?P<message>.+)")
class TestLogPattern(unittest.TestCase):
def test_existing_logs(self):
old_logs = [
"[INFO] System started",
"[ERROR] Failed login attempt",
]
for log in old_logs:
self.assertIsNotNone(LOG_PATTERN.match(log))
if __name__ == "__main__":
unittest.main()-
回归测试确保 系统升级或规则迭代不会破坏原有匹配
-
工程实践 → CI/CD 集成测试必不可少
(三)正则表达式版本演进管理
1. 背景
-
随着业务规则变化,正则不断更新
-
无版本管理 → 难以追踪问题、回滚困难
2. 版本化策略
在命名中添加版本号
python
DATE_PATTERN_V1 = re.compile(r"\d{4}-\d{2}-\d{2}")
DATE_PATTERN_V2 = re.compile(r"\d{4}-\d{2}-\d{2}(?: \d{2}:\d{2})?")在 docstring 中说明变化
python
# DATE_PATTERN_V2: 匹配 YYYY-MM-DD 或 YYYY-MM-DD HH:MM
# 更新日期: 2025-12-20版本化规则库管理
-
可以使用配置文件或 Python 模块管理所有规则
-
保留历史版本 → 支持回滚和回归测试
3. 工程实践示例
python
# patterns/__init__.py
from .date import DATE_PATTERN_V1, DATE_PATTERN_V2
from .log import LOG_PATTERN_V1, LOG_PATTERN_V2-
团队可以 引用指定版本
-
新增规则 → 新增版本而非覆盖旧版本
-
可结合 单元测试 + 回归测试 → 保证升级安全
(四)高级可维护技巧
1. 使用函数封装复杂匹配
python
import re
USER_ACTION_PATTERN = re.compile(r"User (?P<user>\w+) (?P<action>\w+)")
def parse_user_action(line: str):
"""解析用户操作日志,返回字典"""
m = USER_ACTION_PATTERN.match(line)
if m:
return m.groupdict()
return None
# 使用示例
log = "User Alice login"
print(parse_user_action(log)) # {'user': 'Alice', 'action': 'login'}-
封装 → 避免正则散落在业务逻辑中
-
易于单元测试和复用
2. 规则抽象 + 配置化
python
# 规则配置
LOG_RULES = [
{"pattern": re.compile(r"\[ERROR\] (?P<msg>.+)"), "alert": "HIGH"},
{"pattern": re.compile(r"\[WARN\] (?P<msg>.+)"), "alert": "MEDIUM"},
]
def process_log(line: str):
for rule in LOG_RULES:
m = rule["pattern"].match(line)
if m:
return rule["alert"], m.groupdict()
return None, None
# 使用示例
line = "[ERROR] Disk full"
alert, data = process_log(line)
print(alert, data) # HIGH {'msg': 'Disk full'}-
规则配置化 → 易于动态管理
-
封装匹配逻辑 → 提高可维护性
(五)工程实践总结
-
**命名 + 文档化:**所有正则命名清晰,说明用途与限制
-
**单元测试:**正向/反向测试覆盖每个正则
-
**回归测试:**保证规则升级不破坏旧匹配
-
**版本管理:**命名 + 模块化 + 历史记录
-
**封装与配置化:**避免正则散落,规则集中管理
-
**CI/CD 集成:**自动执行单元测试和回归测试 → 高可维护性
第六篇:实战专题与反模式总结
本篇通过实战案例展示 高性能日志解析器、URL/User-Agent 精准识别、金融规则文本提取 的实现方法,同时总结常见反模式和模式匹配能力进阶。
一、经典实战案例拆解
本章目标:通过实际案例展示如何在工程中高效应用正则表达式和结构化模式匹配,形成可复用的解析器和规则引擎。
(一)高性能日志解析器
1. 背景
-
日志量大,解析器必须高效
-
日志类型多,结构可能不一致
-
常用需求:
-
按日志级别分类
-
提取用户、时间、事件信息
-
支持报警或统计
-
2. 架构思路
-
批量读取日志
-
正则抽取核心字段
-
match-case 结构化处理
-
可选缓存/流式处理提高性能
3. 实现示例
python
import re
LOG_PATTERN = re.compile(
r"\[(?P<level>\w+)\] (?P<date>\d{4}-\d{2}-\d{2}) (?P<user>\w+) (?P<action>.+)"
)
logs = [
"[INFO] 2025-12-20 Alice login",
"[ERROR] 2025-12-20 Bob failed action",
"[WARN] 2025-12-20 Charlie password attempt",
]
def parse_logs(logs):
results = []
for line in logs:
m = LOG_PATTERN.match(line)
if not m:
continue
data = m.groupdict()
# match-case 处理逻辑
match data:
case {"level": "INFO", "action": "login", "user": user}:
results.append((user, "INFO_LOGIN"))
case {"level": "ERROR"}:
results.append((data["user"], "ERROR"))
case {"level": "WARN"}:
results.append((data["user"], "WARN"))
return results
print(parse_logs(logs))输出:
R
[('Alice', 'INFO_LOGIN'), ('Bob', 'ERROR'), ('Charlie', 'WARN')]优化策略:
-
使用
re.compile缓存正则 -
批量处理 → 避免多次 I/O
-
match-case 扁平化分支 → 高可读性
-
可扩展 → 新日志类型直接新增 case
(二)URL / User-Agent 精准识别
1. 背景
-
Web 日志、访问分析、风控系统常需识别 URL 和 User-Agent
-
URL 结构复杂,多参数、多域名
-
User-Agent 多变,需识别浏览器、设备类型、操作系统
2. URL 提取与解析
python
import re
from urllib.parse import urlparse, parse_qs
urls = [
"https://example.com/product?id=123&ref=google",
"http://shop.test.com/cart?item=456"
]
URL_PATTERN = re.compile(r"https?://(?P<host>[^/]+)(?P<path>/[^?]*)\??(?P<query>.*)")
for url in urls:
m = URL_PATTERN.match(url)
if m:
data = m.groupdict()
query_params = parse_qs(data['query'])
print(f"Host: {data['host']}, Path: {data['path']}, Query: {query_params}")输出:
python
Host: example.com, Path: /product, Query: {'id': ['123'], 'ref': ['google']}
Host: shop.test.com, Path: /cart, Query: {'item': ['456']}工程实践:
-
re负责快速匹配 URL 核心部分 -
urllib.parse处理参数解析 -
组合 → 高效且可维护
3. User-Agent 分类
python
UA_LIST = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/117.0",
"Mozilla/5.0 (iPhone; CPU iPhone OS 16_5 like Mac OS X) Safari/605.1"
]
UA_PATTERN = re.compile(r".*\((?P<platform>[^)]+)\).* (?P<browser>\w+)/[\d\.]+")
for ua in UA_LIST:
m = UA_PATTERN.match(ua)
if m:
match m.groupdict():
case {"platform": platform, "browser": browser}:
print(f"Platform: {platform}, Browser: {browser}")输出:
python
Platform: Windows NT 10.0; Win64; x64, Browser: Chrome
Platform: iPhone; CPU iPhone OS 16_5 like Mac OS X, Browser: Safari分析:
-
正则提取核心信息
-
match-case 对字段进行结构化分类
-
可扩展 → 新浏览器/平台无需修改核心逻辑,只需增加守卫条件或 case
(三)金融规则文本提取
1. 背景
-
金融合同、交易记录文本解析常需提取 金额、账户、交易类型
-
文本形式复杂,规则多变
2. 正则 + match-case 实战
python
import re
transactions = [
"2025-12-20 Alice transferred $500 to Bob",
"2025-12-21 Charlie deposited $1200",
]
TX_PATTERN = re.compile(
r"(?P<date>\d{4}-\d{2}-\d{2}) (?P<user>\w+) (?P<action>\w+) \$(?P<amount>\d+)( to (?P<target>\w+))?"
)
for tx in transactions:
m = TX_PATTERN.match(tx)
if m:
data = m.groupdict()
match data:
case {"action": "transferred", "user": user, "amount": amount, "target": target}:
print(f"{user} transferred ${amount} to {target}")
case {"action": "deposited", "user": user, "amount": amount}:
print(f"{user} deposited ${amount}")输出:
Puppet
Alice transferred $500 to Bob
Charlie deposited $1200工程实践:
-
正则 → 抽取核心字段(金额、用户、目标账户)
-
match-case → 业务逻辑分类
-
可扩展 → 支持更多交易类型和复杂文本
-
可维护 → 增加新规则只需新增 case 或更新正则组
(四)高性能优化策略
-
缓存编译后的正则 →
re.compile -
批量处理文本 → 避免频繁 I/O
-
使用 match-case 扁平化分支 → 避免嵌套 if
-
抽象封装 → 将正则匹配和业务逻辑解耦
-
守卫条件 + 通配符 → 高效匹配复杂字段
二、正则表达式反模式清单
(一)"一条正则解决一切"的反模式
1. 背景
-
初学者和部分工程项目中,常尝试用单条复杂正则处理多种逻辑
-
问题:
-
可读性差
-
调试困难
-
易产生回溯爆炸
-
难以复用和维护
-
2. 示例
python
import re
# 想用一条正则匹配日期、时间、用户、操作
pattern = re.compile(r"(\d{4}-\d{2}-\d{2}) (\d{2}:\d{2}) (\w+) (\w+) (\w+)")
log = "2025-12-20 16:00 Alice login success"
m = pattern.match(log)
if m:
print(m.groups())问题:
-
单条正则承担过多任务
-
修改其中一部分可能破坏整体匹配
-
可读性差 → 新人难以理解
3. 改进
python
import re
DATE_PATTERN = re.compile(r"\d{4}-\d{2}-\d{2}")
TIME_PATTERN = re.compile(r"\d{2}:\d{2}")
USER_PATTERN = re.compile(r"\w+")
ACTION_PATTERN = re.compile(r"\w+")
log = "2025-12-20 16:00 Alice login success"
date = DATE_PATTERN.match(log[:10]).group()
time = TIME_PATTERN.match(log[11:16]).group()
user = USER_PATTERN.match(log[17:22]).group()
action = ACTION_PATTERN.match(log[23:]).group()
print(date, time, user, action)-
分解 → 易于维护和测试
-
更适合工程实践
(二)过度捕获
1. 背景
-
捕获组过多 → 占用资源、影响性能
-
未使用的捕获组 → 增加代码复杂性
2. 反模式示例
python
import re
pattern = re.compile(r"(.*)-(.*)-(.*)-(.*)")
m = pattern.match("2025-12-20-Alice-login")
print(m.groups())- 捕获四组,但只需日期和用户 → 其余多余
3. 改进
python
import re
pattern = re.compile(r"(?P<date>\d{4}-\d{2}-\d{2})-(?:.*-)?(?P<user>\w+)-.*")
m = pattern.match("2025-12-20-Alice-login")
print(m.groupdict())-
使用 命名捕获组 + 非捕获组
-
提高可读性和性能
(三)隐式回溯陷阱(Catastrophic Backtracking)
1. 背景
-
回溯型正则在面对 重复量词嵌套 时可能产生指数级回溯
-
常见于 (a+)+b 或 (.*)+ 等模式
2. 示例
python
import re
import time
pattern = re.compile(r"(a+)+b")
text = "a" * 30 + "c" # 不匹配
start = time.time()
m = pattern.match(text)
end = time.time()
print("Time:", end - start)-
运行时间可能明显延长
-
工程风险 → 高流量日志或用户输入可能触发 ReDoS
3. 改进
-
限定量词,避免嵌套贪婪匹配
-
使用原子分组(Python
regex库支持) -
或拆分正则逻辑
python
import regex # 第三方库
pattern = regex.compile(r"(?:a+)+b") # 原子非捕获组(四)可读性灾难
1. 背景
-
复杂正则无注释 → 新人无法理解
-
长行正则 → 维护困难
-
影响代码质量和团队协作
2. 反模式示例
python
import re
pattern = re.compile(r"(\d{4}-\d{2}-\d{2}) (\d{2}:\d{2}) (\w+) (\w+).*")- 复杂且不明确
3. 改进
python
import re
pattern = re.compile(r"""
(?P<date>\d{4}-\d{2}-\d{2}) # 日期 YYYY-MM-DD
\s+
(?P<time>\d{2}:\d{2}) # 时间 HH:MM
\s+
(?P<user>\w+) # 用户名
\s+
(?P<action>\w+) # 操作类型
""", re.VERBOSE)-
re.VERBOSE→ 支持多行、注释 -
可读性大幅提升
(五)工程级反模式总结
| 反模式 | 风险/问题 | 改进策略 |
|---|---|---|
| 一条正则解决一切 | 可读性差、维护困难 | 拆分正则,分层处理 |
| 过度捕获 | 占用内存、无用组 | 使用非捕获组 (?:...),命名捕获组 |
| 隐式回溯陷阱 | 性能爆炸,可能被 ReDoS 攻击 | 限定量词,拆分复杂正则,使用原子分组 |
| 可读性灾难 | 维护困难,团队协作受影响 | re.VERBOSE 多行+注释,清晰命名 |
| 正则散落业务逻辑中 | 难测试、难复用 | 封装成函数或规则库 |
| 忽略边界条件或异常输入 | 匹配失败或异常 | 单元测试、回归测试覆盖正向和反向情况 |
(六)工程实践建议
-
拆分正则,按职责分层
-
使用命名捕获组与非捕获组
-
限定量词,避免嵌套回溯
-
注释、文档化、re.VERBOSE
-
封装正则 → 提供 API 接口
-
单元测试 + 回归测试 → 防止升级破坏
-
复杂逻辑考虑状态机或手写解析器替代正则
三、模式匹配能力进阶路线图
(一)从 Python 正则和 match-case 起步
1. 基础能力
-
正则表达式
-
高效匹配线性文本
-
支持字符类、量词、捕获组、断言等
-
工程化应用 → 封装 + 规则库 + 单元测试
-
-
match-case(Python 3.10+)
-
对字典、序列、类对象等进行结构化匹配
-
支持守卫条件(guard) → 更精细的逻辑分支
-
与正则组合 → 提取字段 + 业务逻辑分类
-
2. 工程实践路径
-
日志解析、URL解析、User-Agent分类
-
风控规则引擎、交易规则匹配
-
DSL 文本解析、简单语法抽象
(二)学习编译原理基础
1. 动机
-
当文本规则越来越复杂 → 正则难以胜任
-
需要理解语言、语法、解析器的理论基础
2. 核心概念
词法分析(Lexical Analysis)
-
将原始文本拆分为 token
-
类似正则拆分字段,但更系统化
python
import re
TOKEN_PATTERN = re.compile(r"\s*(?P<NUMBER>\d+)|(?P<PLUS>\+)|(?P<MINUS>-)")
tokens = list(TOKEN_PATTERN.finditer("12 + 24 - 5"))
for t in tokens:
print(t.lastgroup, t.group())语法分析(Parsing)
-
将 token 组织成语法结构(AST)
-
可处理递归、嵌套、优先级
python
# 示例:解析简单加减表达式,构建 AST
# token -> AST 解析器略示意抽象语法树(AST)
-
结构化表示文本或规则
-
易于后续执行、优化和验证
(三)PEG / Lark / ANTLR 进阶
1. PEG(Parsing Expression Grammar)
-
递归下降解析的一种形式
-
区别于正则:
-
支持递归规则
-
匹配过程确定,不会回溯爆炸
-
2. Lark(Python 高级解析器库)
-
支持 EBNF、自动构建 AST
-
示例:解析简单算术表达式
python
from lark import Lark, Transformer
grammar = """
?start: sum
?sum: product
| sum "+" product -> add
| sum "-" product -> sub
?product: NUMBER
%import common.NUMBER
%import common.WS
%ignore WS
"""
class CalcTransformer(Transformer):
def add(self, items):
return items[0] + items[1]
def sub(self, items):
return items[0] - items[1]
def NUMBER(self, n):
return int(n)
parser = Lark(grammar, parser='lalr', transformer=CalcTransformer())
result = parser.parse("3 + 5 - 2")
print(result) # 6-
优点:
-
支持递归、优先级
-
自动构建 AST
-
可扩展到复杂规则文本解析
-
3. ANTLR(跨语言解析器)
-
高级解析器生成器
-
支持多语言目标
-
使用 语法文件(.g4) 定义规则
-
自动生成 Lexer + Parser → 高度工程化
(四)构建属于自己的规则引擎
1. 设计思路
-
**Tokenize:**正则或词法分析拆分文本
-
**Parse:**构建 AST 或中间结构
-
**Match / Execute:**match-case 或规则映射执行业务逻辑
-
优化
-
缓存编译正则
-
拆分复杂规则
-
限定回溯空间
-
2. 示例:简易 DSL 规则引擎
python
rules = [
{"type": "login", "action": "failed", "alert": "HIGH"},
{"type": "transaction", "amount": lambda x: x > 10000, "alert": "MEDIUM"},
]
events = [
{"type": "login", "action": "failed", "user": "Alice"},
{"type": "transaction", "amount": 15000, "user": "Bob"},
]
for event in events:
for rule in rules:
match (event, rule):
case ({"type": etype, **edata}, {"type": rtype, "action": raction, **_}):
if etype == rtype and edata.get("action") == raction:
print(f"{edata['user']} triggers {rule['alert']} alert")
case ({"type": "transaction", "amount": amt, **edata}, {"amount": cond, **_}):
if cond(amt):
print(f"{edata['user']} triggers {rule['alert']} alert")-
将规则配置化、可扩展
-
使用结构化匹配 → 简化复杂业务逻辑
-
可以进一步扩展 → 支持嵌套逻辑、组合条件、状态机
(五)工程化进阶路线总结
| 阶段 | 技术/方法 | 工程实践 |
|---|---|---|
| 初级 | Python 正则、match-case | 日志解析、URL提取、User-Agent分类 |
| 中级 | 状态机 + 手写解析器 | DSL解析、规则引擎、嵌套文本处理 |
| 高级 | PEG / Lark / ANTLR | 支持递归规则、AST、复杂语言解析 |
| 终极 | 自定义规则引擎 | Tokenize → Parse → Match → Execute,高性能、可维护、可扩展 |
(六)核心实践建议
-
**从工程实际出发:**先使用正则和 match-case 满足业务需求
-
**遇到复杂规则:**引入状态机或手写解析器
-
**规则高度复杂或递归:**使用 PEG / Lark / ANTLR 构建解析器
-
**自定义规则引擎:**配合 DSL、AST 和执行器 → 完全可控
-
**性能和可维护并重:**缓存、拆分规则、封装函数、单元测试、回归测试
结语:总结与分享
我们从 Python 的基础正则与模式匹配,逐步深入到高性能工程实践,再到结构化匹配与自定义规则引擎的进阶应用,希望读者不仅学会"写正则",更能学会设计匹配系统。
总结与分享
-
从基础到工程化
-
正则表达式和 match-case 是基础工具
-
工程中不仅要能匹配,还要高效、可维护、可扩展
-
每一个规则、每一条正则,都应该经过设计、封装和测试
-
-
优化与实战经验
-
避免回溯陷阱、过度捕获、可读性灾难
-
利用正则优化、状态机、DSL、AST 构建复杂规则
-
实战案例(日志解析、URL/User-Agent 分类、金融规则提取)展示了理论如何落地
-
-
进阶路线与成长路径
-
正则 → match-case → 状态机/手写解析器 → PEG/Lark/ANTLR → 自定义规则引擎
-
理论基础 + 工程实践结合,形成可复用的规则系统能力
-
最终目标:从单条正则到完整、高效、可维护的匹配系统
-
-
工程思维的重要性
-
命名规范、文档化、单元测试、回归测试、版本管理
-
封装、配置化、批量处理 → 提高可维护性与协作效率
-
每一个工程决策都影响系统的稳定性与可扩展性
-
感谢与寄语
感谢每一位读者陪伴本书走完模式匹配与高性能正则的完整旅程。模式匹配的世界,既有数学之美,也有工程之巧;既有灵活的创意空间,也有严谨的性能约束。希望你在实践中,既能享受探索的乐趣,也能收获工程落地的成果。
祝你在 Python 模式匹配与规则引擎的道路上越走越远,从小工具到大系统,从单条正则到完整引擎,构建属于自己的高效、可维护、可复用的匹配世界。