概述
索引是MySQL性能优化的核心手段,合理的索引设计能让查询速度提升数百倍,而错误的索引设计则会导致性能灾难。本文从索引类型、聚簇索引与非聚簇索引、联合索引与最左前缀原则、覆盖索引与索引下推、索引失效的12种场景、索引选择性计算等核心知识点出发,深入剖析为什么低区分度字段(如gender、status)不能单独建索引,结合电商订单系统等实战案例,讲解索引设计最佳实践与慢查询优化技巧,帮助读者构建完整的索引优化知识体系,在面试和实际工作中游刃有余。
一、理论知识与核心概念
1.1 什么是索引?为什么需要索引?
索引(Index)是数据库表中一列或多列值的排序数据结构,本质是排序+查找。索引的作用类似于书籍的目录,通过目录可以快速定位到具体内容,无需从头到尾翻阅整本书。
没有索引的查询:
sql
SELECT * FROM users WHERE name = 'Alice';MySQL需要全表扫描(Full Table Scan),逐行检查name字段是否等于'Alice',复杂度O(n)。100万行数据,扫描100万次。
有索引的查询:
sql
-- name字段建立B+树索引
ALTER TABLE users ADD INDEX idx_name (name);
SELECT * FROM users WHERE name = 'Alice';MySQL通过B+树索引 快速定位,复杂度O(log n)。100万行数据,3层B+树,仅需3次I/O即可定位。
性能对比:
| 数据量 | 无索引扫描次数 | B+树索引I/O次数 | 性能提升 |
|---|---|---|---|
| 1万行 | 10,000 | 3次 | 3333倍 |
| 100万行 | 1,000,000 | 3次 | 333,333倍 |
| 1亿行 | 100,000,000 | 4次 | 25,000,000倍 |
1.2 索引的优缺点
优点:
- ✅ 加快查询速度: WHERE条件查询、JOIN表连接、ORDER BY排序、GROUP BY分组都能利用索引
- ✅ 减少I/O次数 : 索引按顺序存储,范围查询(如
age > 25)只需扫描部分索引 - ✅ 避免排序: ORDER BY索引列,MySQL直接按索引顺序返回,无需额外排序
缺点:
- ❌ 占用存储空间: 索引本身占用磁盘空间,单表索引过多(>5个)浪费空间
- ❌ 降低写入性能 : INSERT/UPDATE/DELETE需要维护索引,索引越多,写入越慢
- INSERT: 需要在索引B+树中插入新节点
- UPDATE: 若更新索引列,需要删除旧索引节点,插入新节点
- DELETE: 需要删除索引节点(实际是标记删除)
- ❌ 维护成本: 索引碎片、索引失效需要定期分析和优化
权衡: 读多写少的场景(如订单查询、商品搜索)适合建索引;写多读少的场景(如日志写入)谨慎建索引。
1.3 什么时候建索引?什么时候不建?
✅ 应该建索引的字段:
- WHERE条件字段 :
WHERE user_id = 100,WHERE status = 1 - JOIN连接字段 :
JOIN orders ON users.id = orders.user_id - ORDER BY排序字段 :
ORDER BY create_time DESC - GROUP BY分组字段 :
GROUP BY category_id - 高选择性字段 (Cardinality / Total Rows > 0.1): 主键、唯一键、手机号、邮箱
❌ 不应该建索引的字段:
- 低选择性字段 (< 5%): gender、status、type等枚举字段
- 频繁更新的字段: 更新频繁会导致索引频繁重建
- 很少使用的查询字段: 索引维护成本高,收益低
- 数据量小的表 (< 1000行): 全表扫描更快
- TEXT/BLOB大字段: 索引占用空间大,不推荐(可使用前缀索引)
核心原则 : 索引不是越多越好,而是恰到好处。单表索引建议≤5个,联合索引字段数≤5个。
二、索引类型详解
2.1 按数据结构分类
2.1.1 B+树索引(默认)
InnoDB和MyISAM默认使用B+树索引,特点:
- ✅ 有序存储: 数据按索引列顺序存储,支持范围查询(>、<、BETWEEN)
- ✅ 范围查询高效: 叶子节点通过双向链表连接,范围扫描只需顺序遍历
- ✅ 支持排序: ORDER BY索引列无需额外排序
- ✅ 树高低: 3层B+树能存储约2000万行数据,查询只需3次I/O
详见上一篇《MySQL架构原理与执行流程》第3.4节B+树索引原理。
2.1.2 哈希索引
Memory引擎使用哈希索引,InnoDB有自适应哈希索引(Adaptive Hash Index)。
特点:
- ✅ 等值查询极快 : O(1)时间复杂度,
WHERE id = 100 - ❌ 不支持范围查询 :
WHERE age > 25无法使用哈希索引 - ❌ 不支持排序 :
ORDER BY age无法使用哈希索引 - ❌ 不支持模糊查询 :
WHERE name LIKE 'abc%'无法使用
InnoDB自适应哈希索引:
- InnoDB自动监控B+树索引的访问模式
- 对于频繁访问的索引页,自动创建哈希索引
- 加速等值查询,无法手动配置
2.1.3 全文索引(Full-Text Index)
用于文本搜索,MySQL 5.6+支持InnoDB全文索引。
sql
-- 创建全文索引
ALTER TABLE articles ADD FULLTEXT INDEX ft_content (title, content);
-- 全文搜索
SELECT * FROM articles WHERE MATCH(title, content) AGAINST('MySQL 索引');特点:
- ✅ 支持自然语言搜索、布尔模式搜索
- ❌ 中文分词支持差,通常使用Elasticsearch替代
生产建议: 文本搜索优先使用Elasticsearch,性能和功能远超MySQL全文索引。
2.2 按物理存储分类
2.2.1 聚簇索引(Clustered Index)
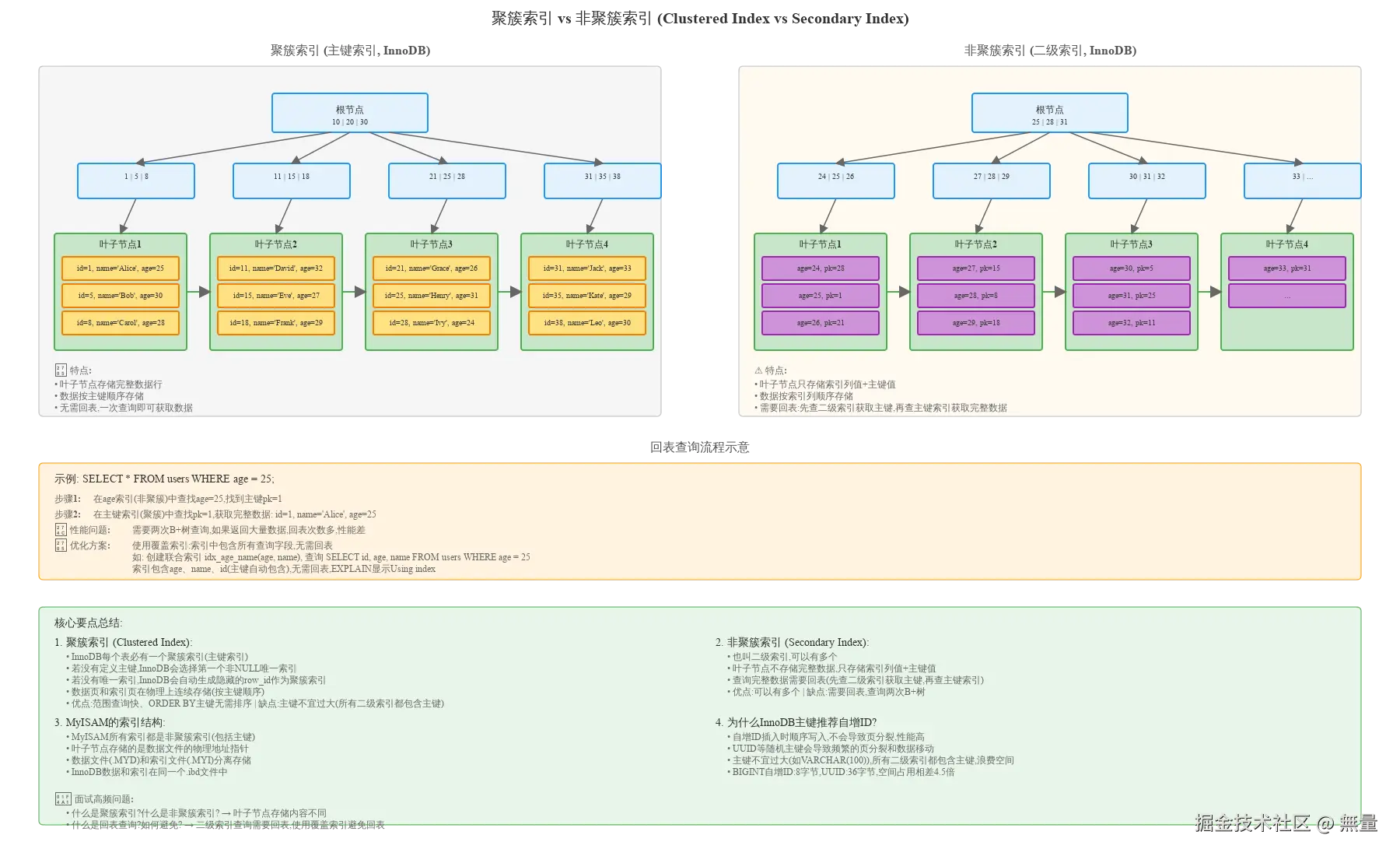
聚簇索引定义: 数据按主键顺序物理存储,叶子节点包含完整数据行。
InnoDB聚簇索引特点:
- ✅ 每个表必有一个聚簇索引 (主键索引)
- ✅ 叶子节点存储完整数据行: 无需回表,一次查询即可获取所有数据
- ✅ 数据按主键顺序存储 : 范围查询(如
WHERE id > 100)高效 - ❌ 主键不宜过大: 所有二级索引都包含主键,主键过大浪费空间
聚簇索引选择规则:
- 若定义了主键,使用主键作为聚簇索引
- 若没有主键,选择第一个非NULL唯一索引
- 若没有唯一索引,InnoDB自动生成隐藏的row_id(6字节)作为聚簇索引
为什么InnoDB主键推荐自增ID?
- ✅ 顺序插入: 自增ID按顺序插入,B+树叶子节点顺序写入,无需页分裂
- ❌ UUID随机插入: UUID是随机值,插入时可能导致页分裂、数据移动,性能差
sql
-- ✅ 推荐: 自增主键
CREATE TABLE users (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(50),
PRIMARY KEY (id)
);
-- ❌ 不推荐: UUID主键(36字节,随机插入)
CREATE TABLE users (
id CHAR(36) NOT NULL,
name VARCHAR(50),
PRIMARY KEY (id)
);2.2.2 非聚簇索引(Secondary Index / 二级索引)
非聚簇索引定义: 叶子节点不存储完整数据,只存储索引列值+主键值。
InnoDB二级索引特点:
- ✅ 可以有多个二级索引
- ❌ 需要回表: 先查二级索引获取主键,再查主键索引获取完整数据
- ❌ 回表代价高: 返回大量数据时,回表次数多,性能差
回表查询示例:
sql
-- age字段建立二级索引
ALTER TABLE users ADD INDEX idx_age (age);
-- 查询
SELECT * FROM users WHERE age = 25;执行流程:
- 步骤1: 在age索引(二级索引)中查找age=25,找到主键pk=1, pk=5, pk=8 (假设3条记录)
- 步骤2: 在主键索引(聚簇索引)中分别查找pk=1、pk=5、pk=8,获取完整数据
- 总计: 4次B+树查询(1次二级索引 + 3次主键索引回表)
性能问题: 若age=25有10万条记录,需要回表10万次,性能极差!
优化方案 : 使用覆盖索引,避免回表。
2.2.3 MyISAM的索引结构
MyISAM所有索引都是非聚簇索引(包括主键索引)。
MyISAM vs InnoDB索引对比:
| 维度 | InnoDB | MyISAM |
|---|---|---|
| 主键索引 | 聚簇索引,叶子节点存储完整数据 | 非聚簇索引,叶子节点存储数据文件指针 |
| 二级索引 | 叶子节点存储主键值 | 叶子节点存储数据文件指针 |
| 数据文件 | 数据和索引在同一个.ibd文件 | 数据(.MYD)和索引(.MYI)分离 |
| 回表性能 | 二级索引回表查主键索引 | 所有索引直接通过指针访问数据 |
2.3 按字段数量分类
2.3.1 单列索引
定义: 一个字段建立的索引。
sql
ALTER TABLE users ADD INDEX idx_name (name);2.3.2 联合索引(复合索引)
定义 : 多个字段组合建立的索引,遵循最左前缀原则。
sql
ALTER TABLE orders ADD INDEX idx_user_status_time (user_id, status, create_time);详见第三章《联合索引与最左前缀原则》。
2.4 按功能分类
2.4.1 主键索引(Primary Key)
sql
CREATE TABLE users (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
PRIMARY KEY (id)
);特点:
- ✅ 唯一且不为NULL
- ✅ 自动创建聚簇索引(InnoDB)
- ✅ 每个表只能有一个主键
2.4.2 唯一索引(Unique Index)
sql
ALTER TABLE users ADD UNIQUE INDEX uk_mobile (mobile);特点:
- ✅ 值唯一,但可以为NULL (允许多个NULL)
- ✅ 可以有多个唯一索引
⚠️ 软删除场景问题:
sql
-- ❌ 错误: 软删除后无法再插入相同mobile
UNIQUE KEY uk_mobile (mobile)
-- 用户A mobile=13800138000 删除后(is_deleted=1)
-- 用户B 无法注册 mobile=13800138000 (唯一索引冲突)
-- ✅ 正确: 唯一索引包含is_deleted字段
UNIQUE KEY uk_mobile_deleted (mobile, is_deleted)
-- 允许多个用户使用相同mobile (is_deleted不同)2.4.3 普通索引(Normal Index)
sql
ALTER TABLE users ADD INDEX idx_age (age);特点: 无约束,最常用的索引类型。
2.4.4 前缀索引(Prefix Index)
用于长字符串字段,只索引前N个字符,减少索引大小。
sql
-- 只索引email前10个字符
ALTER TABLE users ADD INDEX idx_email (email(10));如何选择前缀长度?
计算不同前缀长度的选择性:
sql
-- 完整字段选择性
SELECT COUNT(DISTINCT email) / COUNT(*) FROM users;
-- 结果: 0.95
-- 前缀长度5
SELECT COUNT(DISTINCT LEFT(email, 5)) / COUNT(*) FROM users;
-- 结果: 0.75
-- 前缀长度10
SELECT COUNT(DISTINCT LEFT(email, 10)) / COUNT(*) FROM users;
-- 结果: 0.92 (接近完整字段选择性)
-- 选择前缀长度10
ALTER TABLE users ADD INDEX idx_email (email(10));⚠️ 前缀索引的限制:
- ❌ 无法使用覆盖索引
- ❌ 无法用于ORDER BY、GROUP BY
三、联合索引与最左前缀原则
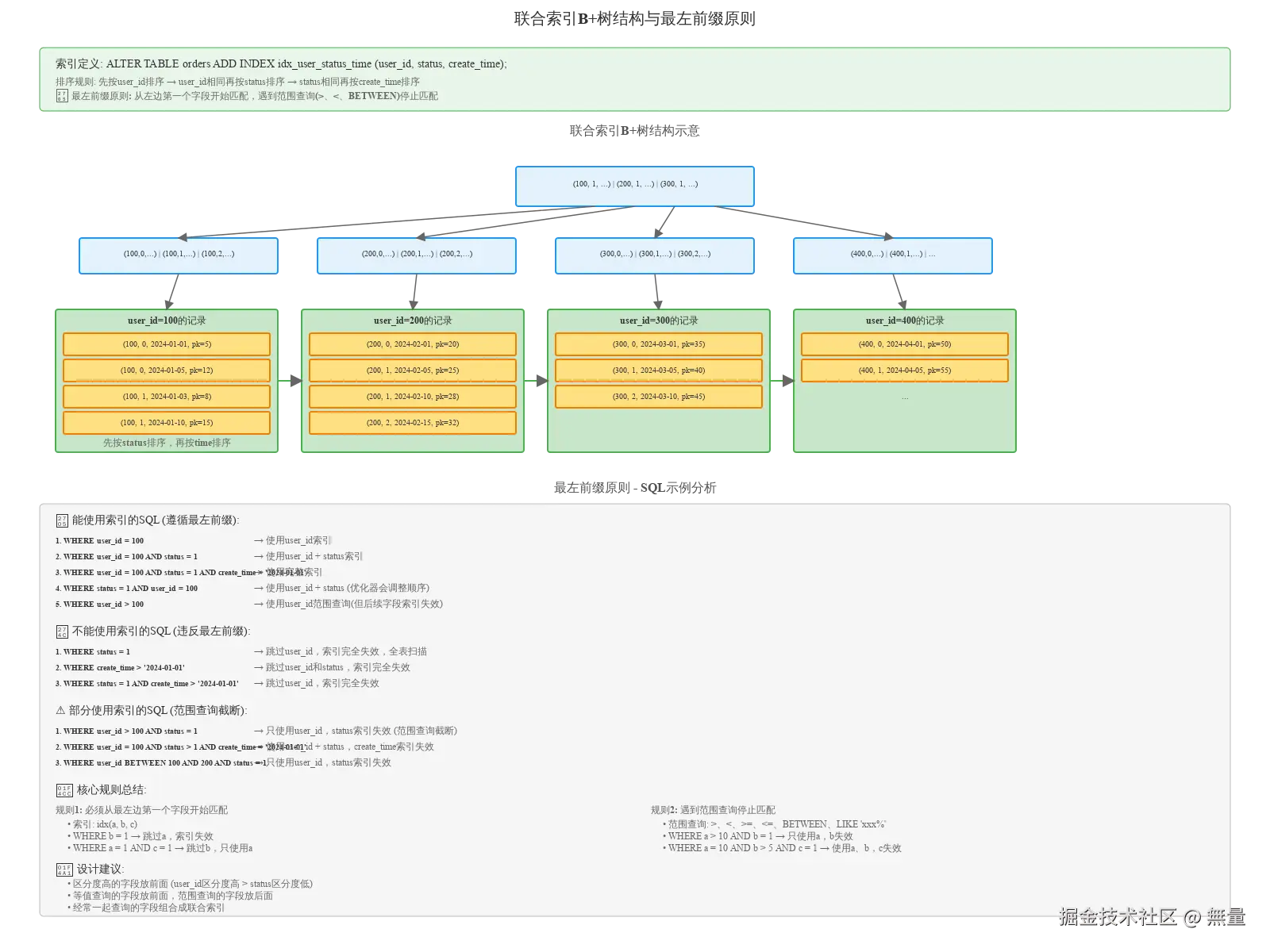
3.1 联合索引原理
联合索引定义: 多个字段组合建立的索引,MySQL内部按字段顺序排序。
创建联合索引:
sql
ALTER TABLE orders ADD INDEX idx_user_status_time (user_id, status, create_time);索引存储结构:
- 先按user_id排序
- user_id相同,再按status排序
- status相同,再按create_time排序
联合索引在B+树中的存储如图所示,每个叶子节点存储(user_id, status, create_time, pk)。
3.2 最左前缀原则(Left-most Prefix Principle)
最左前缀原则定义 : 查询条件必须从最左边第一个字段开始连续匹配,遇到范围查询(>、<、BETWEEN、LIKE)停止匹配。
规则详解:
规则1: 必须从最左边第一个字段开始
sql
-- 索引: idx(a, b, c)
-- ✅ 使用a
WHERE a = 1
-- ✅ 使用a, b
WHERE a = 1 AND b = 2
-- ✅ 使用a, b, c (完整索引)
WHERE a = 1 AND b = 2 AND c = 3
-- ❌ 跳过a,索引完全失效
WHERE b = 2
-- ❌ 跳过b,只使用a
WHERE a = 1 AND c = 3规则2: 遇到范围查询停止匹配
范围查询: >、<、>=、<=、BETWEEN、!=、NOT IN、LIKE '%xxx'
sql
-- 索引: idx(a, b, c)
-- ⚠️ 只使用a,b、c索引失效
WHERE a > 10 AND b = 2 AND c = 3
-- ⚠️ 使用a、b,c索引失效
WHERE a = 1 AND b > 5 AND c = 3
-- ⚠️ 只使用a,b、c索引失效 (BETWEEN也是范围查询)
WHERE a BETWEEN 1 AND 10 AND b = 2 AND c = 3规则3: 顺序无关,优化器会调整
sql
-- 索引: idx(a, b, c)
-- ✅ 优化器调整为 a=1 AND b=2,使用a、b
WHERE b = 2 AND a = 1
-- ✅ 优化器调整,使用a、b、c
WHERE c = 3 AND a = 1 AND b = 23.3 能用到索引的SQL示例
sql
-- 索引: idx_user_status_time (user_id, status, create_time)
-- ✅ 使用user_id
SELECT * FROM orders WHERE user_id = 100;
-- ✅ 使用user_id, status
SELECT * FROM orders WHERE user_id = 100 AND status = 1;
-- ✅ 使用user_id, status, create_time (完整索引)
SELECT * FROM orders WHERE user_id = 100 AND status = 1 AND create_time > '2024-01-01';
-- ✅ 优化器调整顺序,使用user_id, status
SELECT * FROM orders WHERE status = 1 AND user_id = 100;
-- ✅ 使用user_id (范围查询)
SELECT * FROM orders WHERE user_id > 100;3.4 不能用到索引的SQL示例
sql
-- 索引: idx_user_status_time (user_id, status, create_time)
-- ❌ 跳过user_id,索引完全失效,全表扫描
SELECT * FROM orders WHERE status = 1;
-- ❌ 跳过user_id和status,索引完全失效
SELECT * FROM orders WHERE create_time > '2024-01-01';
-- ❌ 跳过user_id,索引完全失效
SELECT * FROM orders WHERE status = 1 AND create_time > '2024-01-01';3.5 部分使用索引的SQL示例
sql
-- 索引: idx_user_status_time (user_id, status, create_time)
-- ⚠️ 只使用user_id,status索引失效 (范围查询截断)
SELECT * FROM orders WHERE user_id > 100 AND status = 1;
-- ⚠️ 使用user_id、status,create_time索引失效 (范围查询截断)
SELECT * FROM orders WHERE user_id = 100 AND status > 1 AND create_time = '2024-01-01';
-- ⚠️ 只使用user_id,create_time索引失效 (跳过status)
SELECT * FROM orders WHERE user_id = 100 AND create_time > '2024-01-01';3.6 联合索引设计原则
原则1: 区分度高的字段放前面
sql
-- user_id区分度高(假设100万用户)
-- status区分度低(只有5个值)
-- ✅ 推荐
ALTER TABLE orders ADD INDEX idx_user_status (user_id, status);
-- ❌ 不推荐
ALTER TABLE orders ADD INDEX idx_status_user (status, user_id);原因: user_id先过滤,大幅减少扫描行数;status先过滤,扫描行数多。
原则2: 等值查询字段放前面,范围查询字段放后面
sql
-- user_id等值查询
-- create_time范围查询
-- ✅ 推荐
ALTER TABLE orders ADD INDEX idx_user_time (user_id, create_time);
-- ❌ 不推荐
ALTER TABLE orders ADD INDEX idx_time_user (create_time, user_id);原则3: 经常一起查询的字段组合成联合索引
sql
-- 经常查询: WHERE user_id = 100 AND status = 1
ALTER TABLE orders ADD INDEX idx_user_status (user_id, status);原则4: 考虑覆盖索引,减少回表
sql
-- 查询: SELECT order_no, user_id, status FROM orders WHERE user_id = 100
-- ✅ 覆盖索引,包含order_no、user_id、status、id(主键)
ALTER TABLE orders ADD INDEX idx_user_status_orderno (user_id, status, order_no);
-- EXPLAIN显示: Using index (无需回表)四、覆盖索引与索引下推优化
4.1 覆盖索引(Covering Index)
覆盖索引定义: 查询的所有字段都在索引中,无需回表查询主键索引。
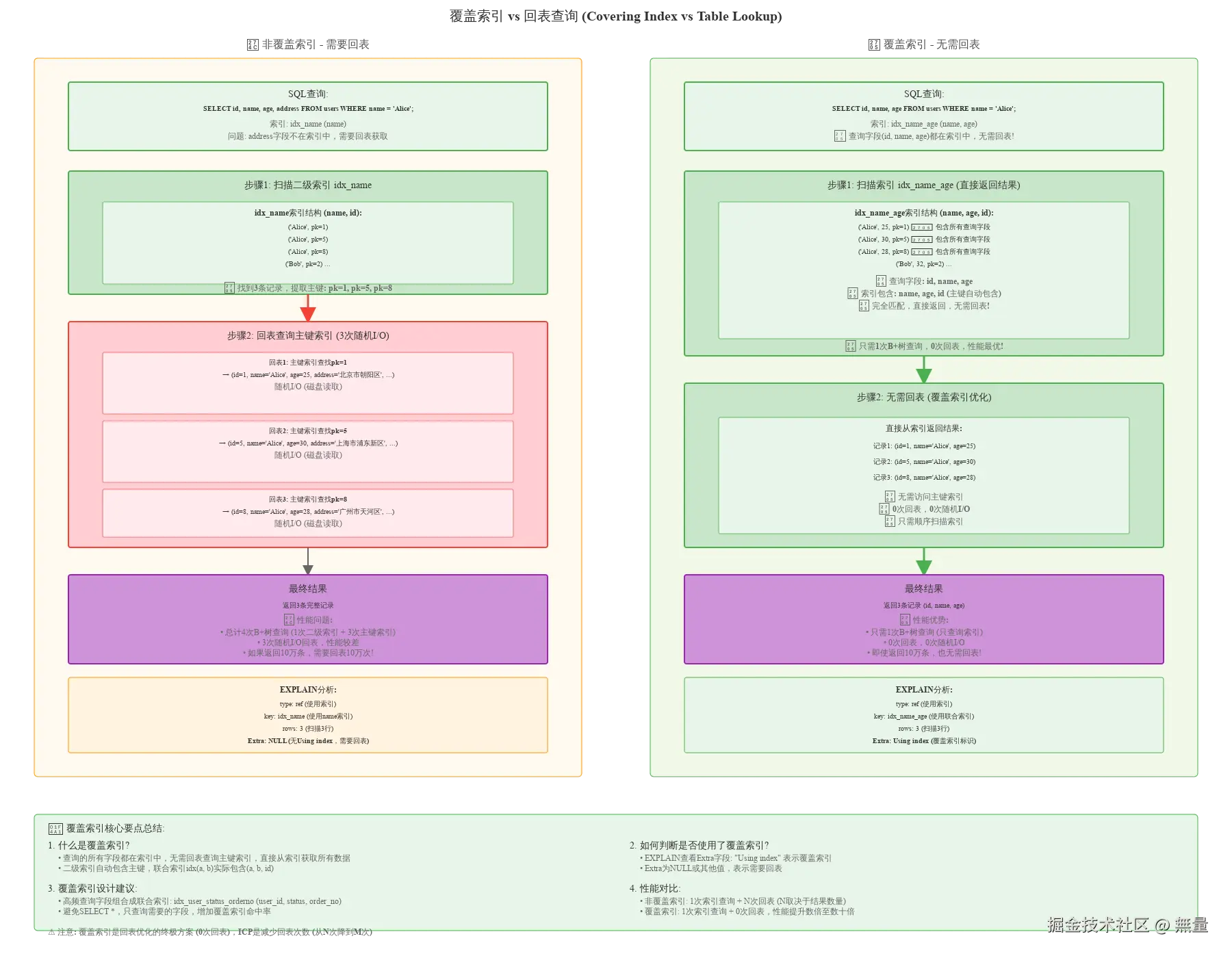
示例:
sql
-- 联合索引
ALTER TABLE users ADD INDEX idx_name_age (name, age);
-- ✅ 覆盖索引,EXPLAIN显示Using index
SELECT id, name, age FROM users WHERE name = 'Alice';
-- 索引包含: name, age, id(主键自动包含在二级索引中)
-- 查询字段: id, name, age
-- 完全匹配,无需回表EXPLAIN分析:
sql
EXPLAIN SELECT id, name, age FROM users WHERE name = 'Alice'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: users
type: ref
possible_keys: idx_name_age
key: idx_name_age
key_len: 202
ref: const
rows: 100
Extra: Using index <--- 覆盖索引标识❌ 非覆盖索引,需要回表:
sql
-- address字段不在索引中,需要回表
SELECT id, name, age, address FROM users WHERE name = 'Alice';
-- EXPLAIN显示: NULL (无Using index)覆盖索引的优势:
- ✅ 减少回表: 只查询一次二级索引,无需查询主键索引
- ✅ 减少I/O: 回表需要随机I/O,覆盖索引只需顺序I/O
- ✅ 性能提升: 回表10万次 vs 覆盖索引0次回表,性能提升数十倍
覆盖索引设计建议:
sql
-- 常见查询
SELECT order_no, user_id, status, total_amount
FROM orders
WHERE user_id = 100 AND status = 1;
-- ✅ 覆盖索引设计
ALTER TABLE orders ADD INDEX idx_user_status_orderno_amount
(user_id, status, order_no, total_amount);
-- 索引包含所有查询字段,无需回表4.2 索引下推优化(Index Condition Pushdown, ICP)
索引下推定义: MySQL 5.6+特性,将WHERE条件下推到存储引擎层,减少回表次数。
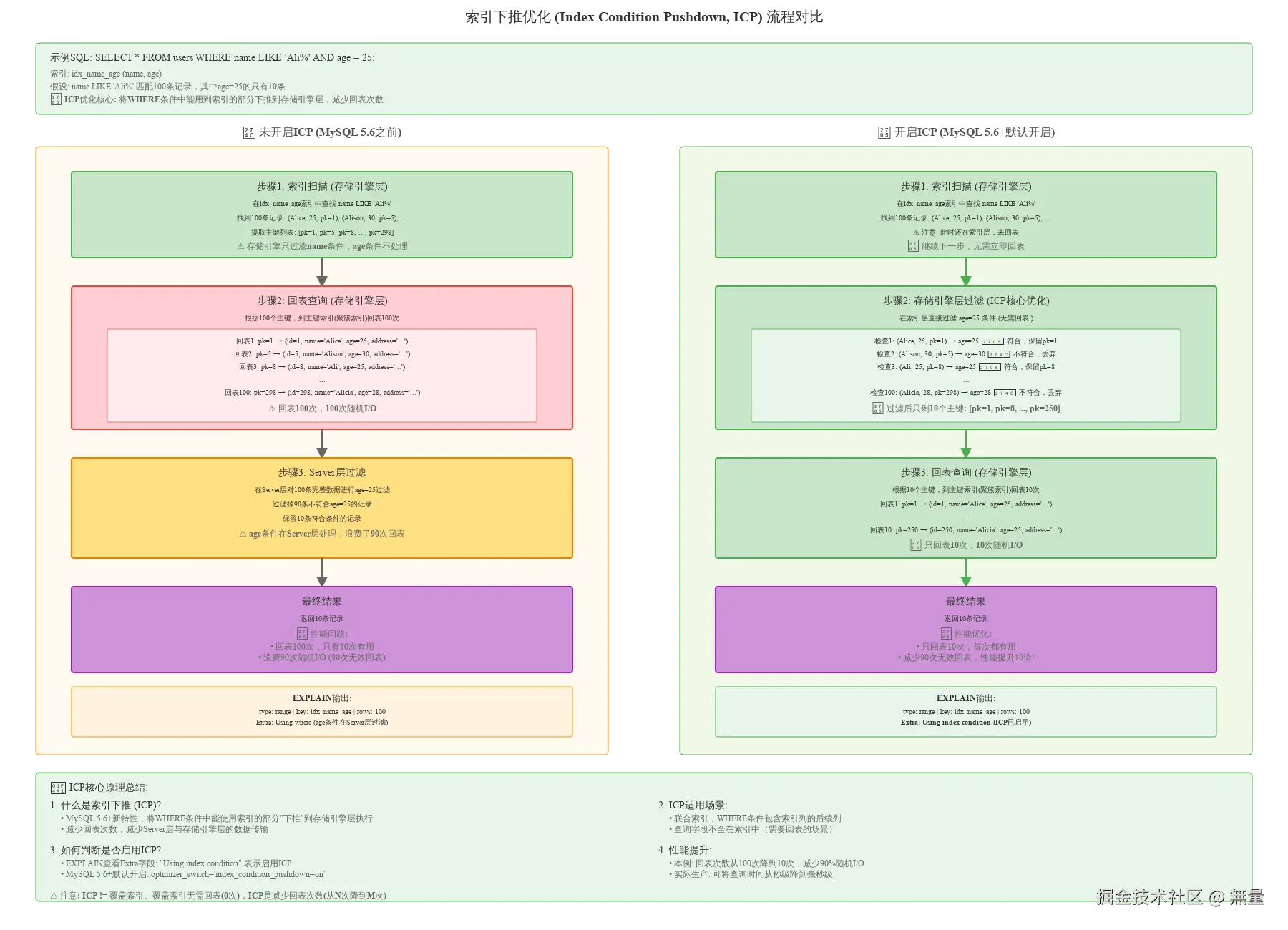
示例SQL:
sql
-- 联合索引
ALTER TABLE users ADD INDEX idx_name_age (name, age);
-- 查询
SELECT * FROM users WHERE name LIKE 'Ali%' AND age = 25;未开启ICP的执行流程:
- 在idx_name_age索引中查找name LIKE 'Ali%'的所有记录,获取主键列表(假设100条)
- 回表100次,查询主键索引,获取完整数据
- Server层过滤age = 25,返回最终结果(假设10条)
问题: 回表100次,但只有10条符合条件,浪费90次回表I/O。
开启ICP的执行流程:
- 在idx_name_age索引中查找name LIKE 'Ali%'
- 存储引擎层直接过滤age = 25,筛选出符合条件的记录(10条)
- 只回表10次,查询主键索引,获取完整数据
性能提升: 回表次数从100次降到10次,减少90%的随机I/O。
EXPLAIN分析:
sql
EXPLAIN SELECT * FROM users WHERE name LIKE 'Ali%' AND age = 25\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: users
type: range
possible_keys: idx_name_age
key: idx_name_age
key_len: 206
ref: NULL
rows: 100
Extra: Using index condition <--- 索引下推标识索引下推适用场景:
- ✅ 联合索引
- ✅ WHERE条件中索引列的后续列参与过滤
- ✅ MySQL 5.6+默认开启:
optimizer_switch='index_condition_pushdown=on'
索引下推 vs 覆盖索引对比:
| 维度 | 覆盖索引 | 索引下推 |
|---|---|---|
| 回表次数 | 0次(无需回表) | 减少回表次数 |
| 适用场景 | 查询字段都在索引中 | 查询字段不全在索引中 |
| EXPLAIN标识 | Using index | Using index condition |
| 性能提升 | 最优(无回表) | 次优(减少回表) |
五、索引失效的12种场景分析
索引失效是慢查询的主要原因,以下12种场景会导致索引失效,每个场景都配EXPLAIN分析。
5.1 场景1: 违反最左前缀原则
sql
-- 索引: idx_user_status_time (user_id, status, create_time)
-- ❌ 跳过user_id,索引失效
SELECT * FROM orders WHERE status = 1;EXPLAIN分析:
vbnet
type: ALL (全表扫描)
key: NULL (未使用索引)
rows: 1000000
Extra: Using where优化方案: 使用完整索引或调整索引顺序。
5.2 场景2: 在索引列上使用函数
sql
-- ❌ 索引失效: YEAR()函数
SELECT * FROM orders WHERE YEAR(create_time) = 2024;原因: 索引存储的是create_time原始值,经过YEAR()函数转换后,无法使用索引。
EXPLAIN分析:
vbnet
type: ALL
key: NULL
rows: 1000000
Extra: Using where✅ 优化方案:
sql
-- 改为范围查询
SELECT * FROM orders
WHERE create_time >= '2024-01-01'
AND create_time < '2025-01-01';其他常见函数导致索引失效:
sql
-- ❌ DATE_FORMAT
WHERE DATE_FORMAT(create_time, '%Y-%m') = '2024-01'
-- ✅ 改为范围查询
WHERE create_time >= '2024-01-01' AND create_time < '2024-02-01'
-- ❌ SUBSTRING
WHERE SUBSTRING(mobile, 1, 3) = '138'
-- ✅ 改为LIKE
WHERE mobile LIKE '138%'5.3 场景3: 隐式类型转换
sql
-- mobile是VARCHAR类型
-- ❌ 隐式类型转换,索引失效
SELECT * FROM users WHERE mobile = 13800138000;原因 : MySQL会将mobile字段转换为数字类型,相当于CAST(mobile AS UNSIGNED) = 13800138000,函数导致索引失效。
EXPLAIN分析:
vbnet
type: ALL
key: NULL
rows: 1000000
Extra: Using where✅ 优化方案:
sql
-- 使用正确的类型
SELECT * FROM users WHERE mobile = '13800138000';其他隐式转换场景:
sql
-- ❌ 字符串与数字比较
WHERE name = 123 (name是VARCHAR)
-- ❌ 整数与字符串比较
WHERE id = '100' (id是BIGINT,不影响,MySQL会转换字符串)
-- ✅ 规则: 字段类型与查询值类型保持一致5.4 场景4: 使用!=、<>
sql
-- ❌ 索引失效
SELECT * FROM users WHERE status != 1;
-- ❌ 索引失效
SELECT * FROM users WHERE status <> 1;原因: !=、<>需要扫描大量数据,优化器认为全表扫描更快。
EXPLAIN分析:
yaml
type: ALL
key: NULL
rows: 1000000✅ 优化方案:
sql
-- 改为IN或UNION
-- 假设status只有0,1,2三个值
SELECT * FROM users WHERE status IN (0, 2);5.5 场景5: IS NULL、IS NOT NULL
sql
-- ⚠️ 可能失效(取决于NULL比例)
SELECT * FROM users WHERE email IS NULL;
-- ⚠️ 可能失效
SELECT * FROM users WHERE email IS NOT NULL;原因:
- 若NULL值比例 > 30%,
IS NOT NULL可能走索引 - 若NULL值比例 < 30%,
IS NULL可能走索引 - 取决于优化器的成本估算
建议:
- ✅ 字段设计时尽量NOT NULL,给默认值
- ✅ 避免使用NULL判断作为查询条件
5.6 场景6: LIKE以%开头
sql
-- ❌ 索引失效: %在前
SELECT * FROM users WHERE name LIKE '%Alice';
-- ❌ 索引失效: %在两边
SELECT * FROM users WHERE name LIKE '%Alice%';
-- ✅ 索引生效: %在后
SELECT * FROM users WHERE name LIKE 'Alice%';原因: B+树索引按字段从左到右排序,%在前无法利用索引的有序性。
✅ 优化方案:
- 业务允许,使用
LIKE 'xxx%' - 全文搜索使用Elasticsearch
5.7 场景7: OR连接,OR两边字段没有都建索引
sql
-- 索引: idx_name
-- ❌ 索引失效 (age无索引)
SELECT * FROM users WHERE name = 'Alice' OR age = 25;原因: name有索引,但age无索引,MySQL无法同时使用两个索引,选择全表扫描。
✅ 优化方案1: OR两边字段都建索引
sql
ALTER TABLE users ADD INDEX idx_name (name);
ALTER TABLE users ADD INDEX idx_age (age);
-- 优化器可能使用index_merge✅ 优化方案2: 改为UNION
sql
SELECT * FROM users WHERE name = 'Alice'
UNION
SELECT * FROM users WHERE age = 25;5.8 场景8: IN范围过大
sql
-- ⚠️ IN值太多,优化器可能选择全表扫描
SELECT * FROM users WHERE id IN (1,2,3,...,10000);原因: IN值过多(>1000),优化器认为全表扫描更快。
建议: IN列表控制在500以内。
5.9 场景9: 联合索引范围查询后的字段
sql
-- 索引: idx(a, b, c)
-- ⚠️ b、c索引失效
SELECT * FROM t WHERE a > 10 AND b = 1 AND c = 2;详见第三章最左前缀原则。
5.10 场景10: 字符集不一致
sql
-- t1.name: utf8mb4
-- t2.name: utf8
-- ❌ JOIN时索引可能失效
SELECT * FROM t1 JOIN t2 ON t1.name = t2.name;原因: 字符集不一致,MySQL需要转换字符集,相当于函数操作。
✅ 优化方案: 统一字符集为utf8mb4。
5.11 场景11: MySQL优化器认为全表扫描更快
sql
-- 表只有100行数据
SELECT * FROM small_table WHERE id > 1;原因: 数据量太小,全表扫描比索引查询更快(索引查询需要额外的索引扫描开销)。
建议: 小表(<1000行)无需建索引。
5.12 场景12: SELECT * 导致无法使用覆盖索引
sql
-- 索引: idx_name_age (name, age)
-- ❌ 需要回表 (address不在索引中)
SELECT * FROM users WHERE name = 'Alice';
-- ✅ 覆盖索引,无需回表
SELECT id, name, age FROM users WHERE name = 'Alice';建议: 避免SELECT *,只查询需要的字段。
六、索引区分度与选择性计算(重要!)
6.1 什么是索引选择性?
索引选择性(Selectivity)定义: 索引列不重复值的数量(基数Cardinality)与表总行数的比值。
公式:
scss
选择性 = 基数(Cardinality) / 总行数(Total Rows)计算方法:
sql
-- 计算字段的选择性
SELECT
COUNT(DISTINCT column_name) / COUNT(*) AS selectivity
FROM table_name;6.2 选择性阈值与建议
经验阈值:
- 选择性 > 0.9 (90%): ✅ 强烈推荐建索引 (如主键、唯一键、手机号、邮箱)
- 选择性 0.5 - 0.9 (50-90%): ✅ 推荐建索引 (如用户名、订单号)
- 选择性 0.1 - 0.5 (10-50%): ⚠️ 谨慎考虑,结合数据量和查询频率
- 选择性 < 0.1 (10%): ❌ 不推荐建索引
- 选择性 < 0.05 (5%): ❌ 禁止单独建索引
6.3 案例分析: 订单表字段选择性计算
订单表orders, 100万条数据:
sql
-- user_id选择性 (假设10万用户)
SELECT COUNT(DISTINCT user_id) / COUNT(*) FROM orders;
-- 结果: 100000 / 1000000 = 0.1 (10%)
-- 结论: ✅ 可以建索引
-- order_no选择性 (订单号唯一)
SELECT COUNT(DISTINCT order_no) / COUNT(*) FROM orders;
-- 结果: 1000000 / 1000000 = 1.0 (100%)
-- 结论: ✅ 强烈推荐建索引 (实际通常建唯一索引)
-- status选择性 (只有5个状态: 0待支付、1已支付、2已发货、3已完成、4已取消)
SELECT COUNT(DISTINCT status) / COUNT(*) FROM orders;
-- 结果: 5 / 1000000 = 0.000005 (0.0005%)
-- 结论: ❌ 禁止单独建索引
-- create_time选择性 (时间精确到秒,重复率低)
SELECT COUNT(DISTINCT create_time) / COUNT(*) FROM orders;
-- 结果: 假设 800000 / 1000000 = 0.8 (80%)
-- 结论: ✅ 可以建索引6.4 为什么低区分度字段不能单独建索引?
核心原因分析:
原因1: 扫描行数多,优化器选择全表扫描
sql
-- status只有5个值,100万数据
-- 每个status对应约20万行
-- 查询status=1的订单
SELECT * FROM orders WHERE status = 1;成本分析:
- 索引扫描: 扫描idx_status索引,找到20万个主键,回表20万次
- 全表扫描: 顺序扫描100万行,过滤出20万行
优化器选择 : 全表扫描更快 (顺序I/O > 随机I/O)
原因2: 回表代价高
sql
-- status=1返回20万行数据
-- 二级索引回表需要20万次随机I/O
-- 全表扫描只需顺序I/O
-- 优化器成本估算:
-- 索引扫描成本 = 20万次随机I/O
-- 全表扫描成本 = 顺序扫描100万行
-- 随机I/O成本 >> 顺序I/O成本
-- 优化器选择全表扫描原因3: 索引维护成本高,收益低
- 每次INSERT/UPDATE/DELETE都要维护索引
- status索引区分度低,查询优化效果差
- 高维护成本 + 低查询收益 = 不值得建索引
6.5 为什么status/gender/type等枚举字段不能单独建索引?
典型低区分度字段:
| 字段 | 值的数量 | 选择性 | 是否建索引 |
|---|---|---|---|
| gender | 3个 (male/female/other) | 0.3% | ❌ 禁止 |
| status | 5-7个 | 0.05-0.07% | ❌ 禁止 |
| user_type | 3-5个 (normal/vip/svip) | 0.03-0.05% | ❌ 禁止 |
| member_level | 5个 (L1-L5) | 0.05% | ❌ 禁止 |
| audit_status | 3个 (pending/pass/reject) | 0.03% | ❌ 禁止 |
问题分析:
sql
-- 假设users表100万用户
-- gender: male(50万), female(49万), other(1万)
SELECT * FROM users WHERE gender = 'male';执行计划:
yaml
type: ALL (全表扫描)
key: NULL (未使用idx_gender索引)
rows: 1000000原因: 扫描50万行,优化器认为全表扫描更快,索引失效。
6.6 复合索引策略: 高区分度 + 低区分度
✅ 正确做法: 将低区分度字段放在联合索引的后面,高区分度字段在前。
sql
-- ❌ 错误: 单独建status索引
ALTER TABLE orders ADD INDEX idx_status (status);
-- ✅ 正确: 联合索引,user_id高区分度在前,status低区分度在后
ALTER TABLE orders ADD INDEX idx_user_status (user_id, status);查询示例:
sql
SELECT * FROM orders WHERE user_id = 100 AND status = 1;
-- 执行计划:
-- type: ref (使用索引)
-- key: idx_user_status
-- rows: 10 (user_id=100的订单约100条,status=1过滤后约10条)为什么这样有效?
- user_id先过滤: 100万订单 → 100条 (用户100的订单)
- status再过滤: 100条 → 10条 (status=1)
- 扫描行数少: 只扫描100条,而不是20万条
6.7 完整案例: 低区分度字段索引设计
场景: 订单表,查询某用户的某状态订单。
sql
-- ❌ 方案1: 单独建status索引
ALTER TABLE orders ADD INDEX idx_status (status);
SELECT * FROM orders WHERE user_id = 100 AND status = 1;
-- 问题:
-- 1. idx_status索引失效(WHERE条件没有status单独查询)
-- 2. 全表扫描,性能差
-- ✅ 方案2: 联合索引
ALTER TABLE orders ADD INDEX idx_user_status (user_id, status);
SELECT * FROM orders WHERE user_id = 100 AND status = 1;
-- 执行计划:
-- type: ref
-- key: idx_user_status
-- rows: 10
-- 性能优异EXPLAIN对比:
| 方案 | type | key | rows | 性能 |
|---|---|---|---|---|
| 无索引 | ALL | NULL | 1000000 | 极差 |
| idx_status单独索引 | ALL | NULL | 1000000 | 极差(索引失效) |
| idx_user_status联合索引 | ref | idx_user_status | 10 | 优秀 |
七、索引设计最佳实践
7.1 阿里巴巴Java开发手册索引规范
【强制】不要在低选择性字段单独建索引:
sql
-- ❌ 禁止
ALTER TABLE users ADD INDEX idx_gender (gender);
ALTER TABLE orders ADD INDEX idx_status (status);
-- ✅ 正确: 联合索引
ALTER TABLE orders ADD INDEX idx_user_status (user_id, status);【强制】唯一索引必须包含is_deleted字段 (软删除):
sql
-- ❌ 错误
UNIQUE KEY uk_mobile (mobile)
-- ✅ 正确
UNIQUE KEY uk_mobile_deleted (mobile, is_deleted)【强制】禁止使用外键:
- 外键影响INSERT/UPDATE/DELETE性能
- 分布式场景下无法使用外键
- 数据一致性在应用层保证
【推荐】单表索引数量不超过5个:
- 索引过多影响写入性能
- 索引维护成本高
【推荐】联合索引字段数不超过5个:
- 字段过多,索引体积大
- 最左前缀原则复杂,难以优化
【推荐】VARCHAR字段使用前缀索引:
sql
-- email平均长度30字节
ALTER TABLE users ADD INDEX idx_email (email(10));7.2 索引设计决策树
sql
是否需要建索引?
├─ 字段是WHERE、ORDER BY、GROUP BY、JOIN条件?
│ └─ 否 → ❌ 不建索引
│
├─ 字段选择性 > 0.1?
│ └─ 否 → ❌ 不建索引
│
├─ 表数据量 > 1000?
│ └─ 否 → ❌ 不建索引 (小表全表扫描更快)
│
├─ 字段是否频繁更新?
│ └─ 是 → ⚠️ 谨慎考虑 (维护成本高)
│
└─ 是 → ✅ 建索引
├─ 单列索引 or 联合索引?
│ └─ 经常一起查询 → 联合索引
│ └─ 单独查询 → 单列索引
│
└─ 主键索引 or 唯一索引 or 普通索引?
└─ 值唯一且不为NULL → 主键索引
└─ 值唯一可为NULL → 唯一索引
└─ 其他 → 普通索引7.3 联合索引设计步骤
步骤1: 列出查询条件中的字段
sql
-- 查询1
WHERE user_id = 100 AND status = 1
-- 查询2
WHERE user_id = 100 AND status = 1 AND create_time > '2024-01-01'字段列表: user_id, status, create_time
步骤2: 计算每个字段的选择性
sql
SELECT COUNT(DISTINCT user_id) / COUNT(*) FROM orders; -- 0.1
SELECT COUNT(DISTINCT status) / COUNT(*) FROM orders; -- 0.000005
SELECT COUNT(DISTINCT create_time) / COUNT(*) FROM orders; -- 0.8步骤3: 选择性高的字段放前面
排序: user_id (0.1) > create_time (0.8) > status (0.000005)
等等,create_time是范围查询,应该放最后!
步骤4: 考虑最左前缀原则
- 等值查询字段: user_id, status
- 范围查询字段: create_time
排序: user_id (等值,高区分度) > status (等值,低区分度) > create_time (范围查询)
步骤5: 考虑覆盖索引
常查询字段: order_no, user_id, status, total_amount
联合索引: idx_user_status_orderno_amount (user_id, status, order_no, total_amount)
步骤6: 验证EXPLAIN
sql
EXPLAIN SELECT order_no, user_id, status, total_amount
FROM orders
WHERE user_id = 100 AND status = 1;
-- 期望结果:
-- type: ref
-- key: idx_user_status_orderno_amount
-- Extra: Using index (覆盖索引)八、实战场景应用
8.1 场景1: 千万级订单表索引设计
业务背景:
- 订单表orders, 1000万数据
- 主要查询场景:
- 用户查询自己的订单:
WHERE user_id = ? - 用户查询特定状态订单:
WHERE user_id = ? AND status = ? - 按时间排序:
ORDER BY create_time DESC - 卖家查询订单:
WHERE seller_id = ? AND status = ?
- 用户查询自己的订单:
表结构:
sql
CREATE TABLE orders (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
order_no VARCHAR(32) NOT NULL,
user_id BIGINT UNSIGNED NOT NULL,
seller_id BIGINT UNSIGNED NOT NULL,
status TINYINT UNSIGNED NOT NULL DEFAULT 0,
total_amount DECIMAL(10,2) NOT NULL,
create_time DATETIME NOT NULL,
is_deleted TINYINT UNSIGNED NOT NULL DEFAULT 0,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;索引设计:
sql
-- 1. 主键索引 (自动创建)
PRIMARY KEY (id)
-- 2. 订单号唯一索引
ALTER TABLE orders ADD UNIQUE INDEX uk_order_no (order_no);
-- 3. 用户订单查询 (最常用)
ALTER TABLE orders ADD INDEX idx_user_status_time (user_id, status, create_time);
-- 4. 卖家订单查询
ALTER TABLE orders ADD INDEX idx_seller_status_time (seller_id, status, create_time);为什么这样设计?
索引1: uk_order_no
- order_no唯一,建唯一索引
- 查询:
WHERE order_no = 'xxx'(用户查订单详情)
索引2: idx_user_status_time
- user_id区分度高 (假设100万用户, 选择性0.1)
- status区分度低 (5个值, 选择性0.000005)
- create_time用于排序
查询场景:
sql
-- 查询1: ✅ 使用user_id
SELECT * FROM orders WHERE user_id = 100;
-- 查询2: ✅ 使用user_id + status
SELECT * FROM orders WHERE user_id = 100 AND status = 1;
-- 查询3: ✅ 使用user_id + status + create_time
SELECT * FROM orders
WHERE user_id = 100 AND status = 1
ORDER BY create_time DESC
LIMIT 20;
-- EXPLAIN:
-- type: ref
-- key: idx_user_status_time
-- rows: 10-100
-- Extra: Backward index scan (倒序扫描索引,无需排序)索引3: idx_seller_status_time
- 卖家查询订单,与用户查询类似
性能测试对比:
| 场景 | 无索引 | 有索引 | 性能提升 |
|---|---|---|---|
| user_id查询 | 3000ms (全表扫描1000万行) | 10ms (索引扫描100行) | 300倍 |
| user_id+status查询 | 3000ms | 5ms (索引扫描10行) | 600倍 |
| user_id+status+排序 | 5000ms (全表扫描+filesort) | 8ms (索引扫描+索引排序) | 625倍 |
8.2 场景2: 慢查询定位与优化
慢查询日志发现:
sql
# Time: 2024-10-21T10:30:15.123456Z
# User@Host: app_user[app_user] @ localhost []
# Query_time: 3.521234 Lock_time: 0.000123 Rows_sent: 20 Rows_examined: 1000000
SELECT * FROM orders
WHERE status = 1
AND create_time > '2024-01-01'
ORDER BY create_time DESC
LIMIT 20;问题分析:
- Query_time: 3.5秒 (超过慢查询阈值1秒)
- Rows_examined: 100万行 (全表扫描)
EXPLAIN分析:
sql
EXPLAIN SELECT * FROM orders
WHERE status = 1
AND create_time > '2024-01-01'
ORDER BY create_time DESC
LIMIT 20\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: orders
type: ALL <--- 全表扫描
possible_keys: NULL
key: NULL <--- 未使用索引
key_len: NULL
ref: NULL
rows: 1000000 <--- 扫描100万行
Extra: Using where; Using filesort <--- 文件排序问题根因:
- status区分度低(5个值, 20万行),单独索引无效
- create_time范围查询
- ORDER BY create_time需要排序,无索引支持,Using filesort
优化方案1: 添加联合索引
sql
ALTER TABLE orders ADD INDEX idx_status_time (status, create_time);优化后EXPLAIN:
sql
EXPLAIN SELECT * FROM orders
WHERE status = 1
AND create_time > '2024-01-01'
ORDER BY create_time DESC
LIMIT 20\G
type: range <--- 范围查询
key: idx_status_time
rows: 200000 <--- 扫描20万行 (status=1的数据)
Extra: Backward index scan <--- 倒序扫描索引,无filesort性能提升: 3000ms → 800ms (提升3.75倍)
问题: 仍然扫描20万行,能否继续优化?
优化方案2: 业务优化 + 索引调整
业务调整: 只查询近30天数据
sql
SELECT * FROM orders
WHERE status = 1
AND create_time > DATE_SUB(NOW(), INTERVAL 30 DAY)
ORDER BY create_time DESC
LIMIT 20;索引调整: create_time在前,status在后 (时间范围小,先过滤)
sql
ALTER TABLE orders ADD INDEX idx_time_status (create_time, status);优化后EXPLAIN:
vbnet
type: range
key: idx_time_status
rows: 5000 <--- 只扫描近30天数据(约5000行)
Extra: Using where; Backward index scan性能提升: 3000ms → 50ms (提升60倍!)
8.3 场景3: 覆盖索引优化回表查询
原始查询:
sql
SELECT order_no, user_id, status, total_amount
FROM orders
WHERE user_id = 100 AND status = 1
ORDER BY create_time DESC
LIMIT 20;索引: idx_user_status_time (user_id, status, create_time)
EXPLAIN分析:
yaml
type: ref
key: idx_user_status_time
rows: 100
Extra: NULL <--- 需要回表问题: 查询字段(order_no, total_amount)不在索引中,需要回表100次。
优化方案: 创建覆盖索引
sql
ALTER TABLE orders ADD INDEX idx_user_status_time_orderno_amount
(user_id, status, create_time, order_no, total_amount);优化后EXPLAIN:
vbnet
type: ref
key: idx_user_status_time_orderno_amount
rows: 100
Extra: Using index <--- 覆盖索引,无需回表性能提升:
- 回表100次 (100次随机I/O) → 0次回表
- 查询时间: 50ms → 10ms (提升5倍)
九、生产案例与故障排查
9.1 案例1: 索引优化让查询从3s降到50ms
问题背景:
- 订单表1000万数据
- 查询:
SELECT * FROM orders WHERE user_id = 100 AND status IN (1, 2, 3) - 响应时间: 3000ms
- 用户投诉: 订单列表加载慢
排查步骤:
步骤1: 慢查询日志分析
makefile
Query_time: 3.123
Rows_examined: 300000步骤2: EXPLAIN分析
sql
EXPLAIN SELECT * FROM orders WHERE user_id = 100 AND status IN (1, 2, 3)\G
type: ref
key: idx_user_id
rows: 300000
Extra: Using where问题发现:
- 使用idx_user_id索引
- 但扫描30万行 (user_id=100的所有订单)
- status过滤在Server层,效率低
步骤3: 索引优化
sql
-- 原索引
ALTER TABLE orders ADD INDEX idx_user_id (user_id);
-- 优化: 添加联合索引
ALTER TABLE orders ADD INDEX idx_user_status (user_id, status);优化后EXPLAIN:
sql
type: range (IN是范围查询)
key: idx_user_status
rows: 15000 <--- 扫描行数大幅减少
Extra: Using index condition效果:
- 查询时间: 3000ms → 50ms (提升60倍)
- 扫描行数: 30万行 → 1.5万行 (减少95%)
9.2 案例2: 隐式类型转换导致索引失效
问题背景:
- 用户表1000万数据
- 查询:
SELECT * FROM users WHERE mobile = 13800138000 - 响应时间: 5000ms (全表扫描)
- mobile字段类型: VARCHAR(11), 有索引idx_mobile
EXPLAIN分析:
sql
EXPLAIN SELECT * FROM users WHERE mobile = 13800138000\G
type: ALL <--- 全表扫描
key: NULL <--- 索引失效
rows: 10000000问题根因:
- mobile是VARCHAR类型
- 查询值13800138000是数字
- MySQL将mobile转换为数字:
CAST(mobile AS UNSIGNED) = 13800138000 - 函数导致索引失效
修复方案:
sql
-- ✅ 正确: 使用字符串
SELECT * FROM users WHERE mobile = '13800138000';优化后EXPLAIN:
makefile
type: ref
key: idx_mobile
rows: 1效果: 5000ms → 5ms (提升1000倍)
教训:
- ✅ 字段类型与查询值类型保持一致
- ✅ VARCHAR字段使用字符串查询
- ✅ INT字段使用数字查询
9.3 案例3: ORDER BY导致Using filesort性能差
问题背景:
- 商品表500万数据
- 查询:
SELECT * FROM products WHERE category_id = 10 ORDER BY sales DESC LIMIT 20 - 响应时间: 2000ms
EXPLAIN分析:
sql
EXPLAIN SELECT * FROM products WHERE category_id = 10 ORDER BY sales DESC LIMIT 20\G
type: ref
key: idx_category_id
rows: 50000
Extra: Using filesort <--- 文件排序问题: ORDER BY sales无索引支持,需要对5万行数据进行filesort。
优化方案: 创建联合索引
sql
ALTER TABLE products ADD INDEX idx_category_sales (category_id, sales);优化后EXPLAIN:
makefile
type: ref
key: idx_category_sales
rows: 50000
Extra: Backward index scan <--- 索引倒序扫描,无filesort效果: 2000ms → 100ms (提升20倍)
十、常见问题与避坑指南
10.1 为什么不推荐使用外键?
外键的问题:
- 性能问题: INSERT/UPDATE/DELETE需要检查外键约束,性能差
- 分布式问题: 分库分表后,外键无法跨库使用
- 死锁风险: 外键锁可能导致死锁
- 灵活性差: 表结构变更困难
✅ 推荐做法:
- 数据一致性在应用层保证
- 使用事务保证一致性
10.2 为什么要避免SELECT *?
原因:
- 无法使用覆盖索引: 查询所有字段,必然有字段不在索引中,需要回表
- 网络传输开销大: 传输不需要的字段,浪费带宽
- Buffer Pool占用多: 缓存大量无用数据
- 可读性差: 不知道查询了哪些字段
✅ 推荐:
sql
-- 只查询需要的字段
SELECT id, name, age FROM users WHERE id = 1;10.3 如何选择联合索引还是多个单列索引?
原则 : 优先选择联合索引。
原因:
- ✅ 联合索引支持最左前缀,一个索引抵多个单列索引
- ✅ 联合索引可以覆盖索引,减少回表
- ❌ 多个单列索引,MySQL只能选择一个索引,其他索引浪费
示例:
sql
-- ❌ 错误: 多个单列索引
ALTER TABLE orders ADD INDEX idx_user (user_id);
ALTER TABLE orders ADD INDEX idx_status (status);
ALTER TABLE orders ADD INDEX idx_time (create_time);
-- 查询: WHERE user_id = 100 AND status = 1
-- MySQL只能选择一个索引(idx_user或idx_status),另一个浪费
-- ✅ 正确: 联合索引
ALTER TABLE orders ADD INDEX idx_user_status_time (user_id, status, create_time);
-- 支持多种查询组合10.4 前缀索引如何选择长度?
见第二章2.4.4节。
10.5 索引越多越好吗?
❌ 不是!
原因:
- 写入性能下降: 每个索引都要维护,索引越多,INSERT/UPDATE/DELETE越慢
- 占用空间: 索引占用磁盘空间
- 优化器选择困难: 索引过多,优化器可能选错索引
建议:
- 单表索引数量 ≤ 5个
- 联合索引字段数 ≤ 5个
- 定期清理无用索引
10.6 为什么不建议在is_deleted字段单独建索引?
原因:
- is_deleted只有2个值(0未删除, 1已删除)
- 选择性极低(0.00005%)
- 通常查询
WHERE is_deleted = 0返回99.9%的数据,全表扫描更快
✅ 正确做法: 放在联合索引的最后
sql
ALTER TABLE users ADD INDEX idx_user_id_deleted (user_id, is_deleted);
ALTER TABLE users ADD UNIQUE INDEX uk_mobile_deleted (mobile, is_deleted);10.7 COUNT(*)、COUNT(1)、COUNT(column)的区别?
| 函数 | 含义 | 是否统计NULL | 性能 |
|---|---|---|---|
| COUNT(*) | 统计行数 | 是 | 最快 (InnoDB优化) |
| COUNT(1) | 统计行数 | 是 | 等同COUNT(*) |
| COUNT(column) | 统计非NULL行数 | 否 | 慢 (需要读取column值) |
推荐: 使用COUNT(*)。
十一、最佳实践与总结
11.1 索引设计Checklist
设计阶段:
- ✅ 高频WHERE条件字段建索引
- ✅ 高频JOIN连接字段建索引
- ✅ 高频ORDER BY、GROUP BY字段建索引
- ✅ 字段选择性 > 0.1才建索引
- ❌ 低选择性字段(<5%)不单独建索引
- ❌ 频繁更新的字段谨慎建索引
- ❌ TEXT/BLOB大字段不建索引
实施阶段:
- ✅ 联合索引遵循最左前缀原则
- ✅ 区分度高的字段放前面
- ✅ 等值查询字段放前面,范围查询字段放后面
- ✅ 考虑覆盖索引,减少回表
- ✅ 唯一索引包含is_deleted字段
验证阶段:
- ✅ EXPLAIN分析执行计划
- ✅ type达到ref以上
- ✅ key显示使用了索引
- ✅ rows扫描行数合理
- ✅ Extra无Using filesort、Using temporary
11.2 慢查询优化流程
步骤1: 开启慢查询日志
bash
slow_query_log=ON
long_query_time=1
slow_query_log_file=/var/log/mysql-slow.log
log_queries_not_using_indexes=ON步骤2: 分析慢查询日志
bash
# mysqldumpslow
mysqldumpslow -s t -t 10 /var/log/mysql-slow.log
# pt-query-digest (推荐)
pt-query-digest /var/log/mysql-slow.log步骤3: EXPLAIN分析
sql
EXPLAIN SELECT ...\G重点关注: type、key、rows、Extra
步骤4: 优化索引
- 添加缺失的索引
- 调整联合索引顺序
- 使用覆盖索引减少回表
步骤5: 验证效果
sql
EXPLAIN SELECT ...\G -- 验证执行计划改善对比优化前后的Query_time和Rows_examined。
11.3 EXPLAIN分析要点
关键字段:
| 字段 | 含义 | 优秀值 | 差值 |
|---|---|---|---|
| type | 访问类型 | const、eq_ref、ref | ALL、index |
| key | 使用的索引 | 索引名 | NULL |
| rows | 扫描行数 | 越少越好 | >10万 |
| Extra | 额外信息 | Using index | Using filesort、Using temporary |
优化目标:
- ✅ type达到ref以上
- ✅ key不为NULL
- ✅ rows < 1000 (取决于业务)
- ✅ Extra显示Using index (覆盖索引)
11.4 监控指标建议
索引相关监控:
sql
-- 索引使用情况
SELECT * FROM sys.schema_unused_indexes;
-- Buffer Pool命中率
SHOW GLOBAL STATUS LIKE 'Innodb_buffer_pool%';
-- 慢查询数量
SHOW GLOBAL STATUS LIKE 'Slow_queries';告警阈值:
- Buffer Pool命中率 < 99%
- 慢查询数量 > 100/分钟
- 索引未使用 > 3个月
11.5 核心要点总结
索引原理:
- 索引本质是排序+查找,B+树索引默认
- 聚簇索引(主键)叶子节点存储完整数据,非聚簇索引(二级索引)需要回表
- 3层B+树能存2000万行数据,查询只需3次I/O
联合索引:
- 遵循最左前缀原则,从最左字段开始连续匹配
- 遇到范围查询停止匹配
- 区分度高的字段放前面,等值查询字段放前面
索引选择性:
- 选择性 = 基数 / 总行数
- 选择性 > 0.1才建索引,< 0.05禁止单独建索引
- 低区分度字段(gender、status)不单独建索引,放在联合索引后面
索引失效:
- 函数、隐式类型转换、!=、LIKE '%xxx'、违反最左前缀
- 优化器认为全表扫描更快时,索引失效
覆盖索引:
- 查询字段都在索引中,无需回表,EXPLAIN显示Using index
- 性能最优,回表0次
索引设计原则:
- 单表索引≤5个,联合索引字段≤5个
- 优先联合索引,不建多个单列索引
- 唯一索引包含is_deleted字段(软删除)
- EXPLAIN分析每条SQL,上线前必须验证
掌握索引设计与优化,是MySQL性能优化的核心技能。通过深入理解索引原理、最左前缀原则、索引选择性计算、索引失效场景,结合EXPLAIN执行计划分析和生产实战案例,能够在面试和实际工作中游刃有余,构建高性能的数据库系统。
参考资料:
- 《高性能MySQL》(第4版) - Baron Schwartz等
- 《MySQL技术内幕: InnoDB存储引擎》(第2版) - 姜承尧
- 阿里巴巴Java开发手册 (嵩山版)
- MySQL官方文档: dev.mysql.com/doc/refman/...