概述
事务和锁是MySQL并发控制的核心机制。本文从ACID特性出发,深入剖析四种事务隔离级别与并发问题,详解MVCC多版本并发控制的实现原理(隐藏列、版本链、Read View可见性判断),全面讲解InnoDB锁机制(记录锁、间隙锁、Next-Key Lock),结合电商库存扣减、死锁排查等实战案例,帮助读者彻底理解MySQL事务与锁的底层原理,在高并发场景下游刃有余。
一、理论知识与核心概念
1.1 什么是事务?为什么需要事务?
**事务(Transaction)**是数据库操作的最小工作单元,由一组SQL语句组成的逻辑处理单元。事务中的所有操作,要么全部成功提交(COMMIT),要么全部失败回滚(ROLLBACK),不存在中间状态。
为什么需要事务?
考虑一个经典的转账场景:
sql
-- 账户A扣款100元
UPDATE account SET balance = balance - 100 WHERE user_id = 'A';
-- 账户B加款100元
UPDATE account SET balance = balance + 100 WHERE user_id = 'B';如果第一条SQL执行成功,第二条SQL因为系统崩溃执行失败,会导致:
- 账户A扣款成功,余额减少100元
- 账户B加款失败,余额未增加
- 结果: 系统凭空少了100元,数据不一致!
使用事务保证原子性:
sql
BEGIN; -- 开启事务
UPDATE account SET balance = balance - 100 WHERE user_id = 'A';
UPDATE account SET balance = balance + 100 WHERE user_id = 'B';
COMMIT; -- 提交事务事务保证两条UPDATE要么全部成功,要么全部回滚,数据一致性得到保证。
1.2 ACID四大特性详解
事务具有四个核心特性,通常简称为ACID:
1. 原子性(Atomicity)
- 定义: 事务是一个不可分割的工作单元,要么全部执行,要么全部不执行
- 实现机制 : Undo Log(回滚日志)
- 每个事务执行前,InnoDB会在Undo Log中记录修改前的旧值
- 事务回滚时,通过Undo Log恢复到修改前的状态
- 示例: 转账场景,A扣款和B加款必须同时成功或同时失败
2. 一致性(Consistency)
- 定义: 事务执行前后,数据库必须从一个一致性状态转换到另一个一致性状态
- 约束保证 :
- 数据完整性约束(主键、外键、唯一约束、非空约束)
- 业务规则约束(如余额不能为负数)
- 示例: 转账前后,A和B账户余额之和保持不变
3. 隔离性(Isolation)
- 定义: 多个事务并发执行时,一个事务的执行不应被其他事务干扰
- 实现机制: MVCC + 锁机制
- 隔离级别: 读未提交、读已提交、可重复读、串行化(详见第二章)
- 示例: 事务A在查询账户余额时,不应看到事务B未提交的修改
4. 持久性(Durability)
- 定义: 事务一旦提交,对数据的修改是永久性的,即使系统故障也不会丢失
- 实现机制 : Redo Log(重做日志) + 双写缓冲(Doublewrite Buffer)
- 事务提交前,先将修改写入Redo Log并刷盘(WAL机制)
- 系统崩溃恢复时,通过Redo Log重做已提交的事务
- 示例: 事务提交后,即使数据库服务器断电,数据也不会丢失
1.3 并发事务带来的问题
多个事务并发执行时,如果没有适当的隔离机制,会导致以下问题:
1. 脏写(Dirty Write / Lost Update)
- 定义: 两个事务同时修改同一行数据,后提交的事务覆盖了前面事务的修改
- 示例 :
- 事务A: UPDATE account SET balance = 900 WHERE id = 1; (未提交)
- 事务B: UPDATE account SET balance = 800 WHERE id = 1; (未提交)
- 事务A回滚,balance恢复到1000
- 问题: 事务B的修改丢失了!
- 解决: 所有隔离级别都能防止脏写(InnoDB通过行锁实现)
2. 脏读(Dirty Read)
- 定义: 事务A读取到了事务B已修改但未提交的数据
- 示例 :
- 事务B: UPDATE account SET balance = 500 WHERE id = 1; (未提交)
- 事务A: SELECT balance FROM account WHERE id = 1; -- 读到500
- 事务B回滚,balance恢复到1000
- 问题: 事务A读到的500是"脏数据"
- 危害: 基于脏数据做决策,可能导致严重的业务错误
- 解决: READ COMMITTED及以上隔离级别可防止脏读
3. 不可重复读(Non-Repeatable Read)
- 定义: 事务A内多次读取同一行数据,结果不一致(其他事务UPDATE并提交)
- 示例 :
- 事务A: SELECT balance FROM account WHERE id = 1; -- 读到1000
- 事务B: UPDATE account SET balance = 500 WHERE id = 1; COMMIT;
- 事务A: SELECT balance FROM account WHERE id = 1; -- 读到500
- 问题: 同一事务内两次查询结果不同
- 场景: 统计报表,查询两次金额不同,数据不一致
- 解决: REPEATABLE READ及以上隔离级别可防止不可重复读
4. 幻读(Phantom Read)
- 定义: 事务A内多次查询,结果集的行数不一致(其他事务INSERT/DELETE并提交)
- 示例 :
- 事务A: SELECT COUNT(*) FROM orders WHERE status = 1; -- 结果100条
- 事务B: INSERT INTO orders VALUES (101, 1, ...); COMMIT;
- 事务A: SELECT COUNT(*) FROM orders WHERE status = 1; -- 结果101条
- 问题: 同一事务内两次查询结果集不同,出现"幻影"数据
- 与不可重复读区别 :
- 不可重复读: 针对UPDATE操作,数据内容变化
- 幻读: 针对INSERT/DELETE操作,数据行数变化
- 解决: SERIALIZABLE隔离级别或REPEATABLE READ + Next-Key Lock
二、事务隔离级别详解
2.1 四种隔离级别
SQL标准定义了四种事务隔离级别,从低到高分别是:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 实现方式 | 并发性能 |
|---|---|---|---|---|---|
| 读未提交 (Read Uncommitted) | ✅ 可能 | ✅ 可能 | ✅ 可能 | 无锁 | 最高 |
| 读已提交 (Read Committed) | ❌ 不可能 | ✅ 可能 | ✅ 可能 | MVCC(每次SELECT生成新Read View) | 高 |
| 可重复读 (Repeatable Read) | ❌ 不可能 | ❌ 不可能 | ⚠️ 部分解决 | MVCC + Next-Key Lock | 中 |
| 串行化 (Serializable) | ❌ 不可能 | ❌ 不可能 | ❌ 不可能 | 表锁/行锁 + 间隙锁 | 最低 |
MySQL InnoDB默认隔离级别: REPEATABLE READ
2.2 隔离级别详解与示例
2.2.1 读未提交 (Read Uncommitted)
特点: 事务可以读取其他事务未提交的数据(脏读)
示例:
sql
-- 会话A: 设置隔离级别为读未提交
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
BEGIN;
SELECT * FROM account WHERE id = 1; -- balance = 1000
-- 会话B: 修改数据但不提交
BEGIN;
UPDATE account SET balance = 500 WHERE id = 1;
-- 会话A: 再次查询
SELECT * FROM account WHERE id = 1; -- balance = 500 (脏读!)
-- 会话B: 回滚
ROLLBACK;
-- 会话A: 再次查询
SELECT * FROM account WHERE id = 1; -- balance = 1000 (数据不一致!)使用场景: 几乎不使用,数据一致性无法保证
2.2.2 读已提交 (Read Committed)
特点: 只能读取已提交的数据,解决脏读,但存在不可重复读
示例:
sql
-- 会话A
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
BEGIN;
SELECT balance FROM account WHERE id = 1; -- 1000
-- 会话B
BEGIN;
UPDATE account SET balance = 500 WHERE id = 1;
COMMIT;
-- 会话A: 再次查询
SELECT balance FROM account WHERE id = 1; -- 500 (不可重复读!)使用场景: Oracle、PostgreSQL默认隔离级别,适合对一致性要求不高但性能要求高的场景
2.2.3 可重复读 (Repeatable Read)
特点: 同一事务内多次读取结果一致,解决脏读和不可重复读
实现机制: MVCC(快照读) + Next-Key Lock(当前读)
示例:
sql
-- 会话A
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
BEGIN;
SELECT balance FROM account WHERE id = 1; -- 1000
-- 会话B
BEGIN;
UPDATE account SET balance = 500 WHERE id = 1;
COMMIT;
-- 会话A: 再次查询
SELECT balance FROM account WHERE id = 1; -- 仍然是1000 (可重复读!)
-- 会话A: UPDATE会使用当前值
UPDATE account SET balance = balance - 100 WHERE id = 1;
SELECT balance FROM account WHERE id = 1; -- 400 (500 - 100,使用当前读)幻读问题:
sql
-- 会话A
BEGIN;
SELECT * FROM account WHERE id > 10; -- 假设0条
-- 会话B
INSERT INTO account VALUES (15, 'test', 100);
COMMIT;
-- 会话A: 快照读
SELECT * FROM account WHERE id > 10; -- 仍然0条 (MVCC,看不到新插入的行)
-- 会话A: 当前读
SELECT * FROM account WHERE id > 10 FOR UPDATE; -- 1条 (Next-Key Lock,能看到)
-- 会话A: UPDATE触发当前读
UPDATE account SET balance = balance + 100 WHERE id > 10; -- 影响1行 (幻读!)使用场景: MySQL InnoDB默认级别,适合大多数业务场景
2.2.4 串行化 (Serializable)
特点: 事务串行执行,完全避免脏读、不可重复读、幻读,但并发性能最差
实现: 所有SELECT自动加共享锁(LOCK IN SHARE MODE)
sql
-- 会话A
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN;
SELECT * FROM account WHERE id = 1; -- 自动加S锁
-- 会话B
UPDATE account SET balance = 500 WHERE id = 1; -- 阻塞等待,直到会话A提交使用场景: 极少使用,通常用于金融等对一致性要求极高的场景
2.3 隔离级别设置
sql
-- 查看当前隔离级别 (MySQL 5.7+)
SELECT @@transaction_isolation;
-- 查看当前隔离级别 (MySQL 5.7以前)
SELECT @@tx_isolation;
-- 设置会话级别隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- 设置全局隔离级别 (重启后失效)
SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- 永久设置 (修改my.cnf)
[mysqld]
transaction-isolation = READ-COMMITTED三、MVCC多版本并发控制
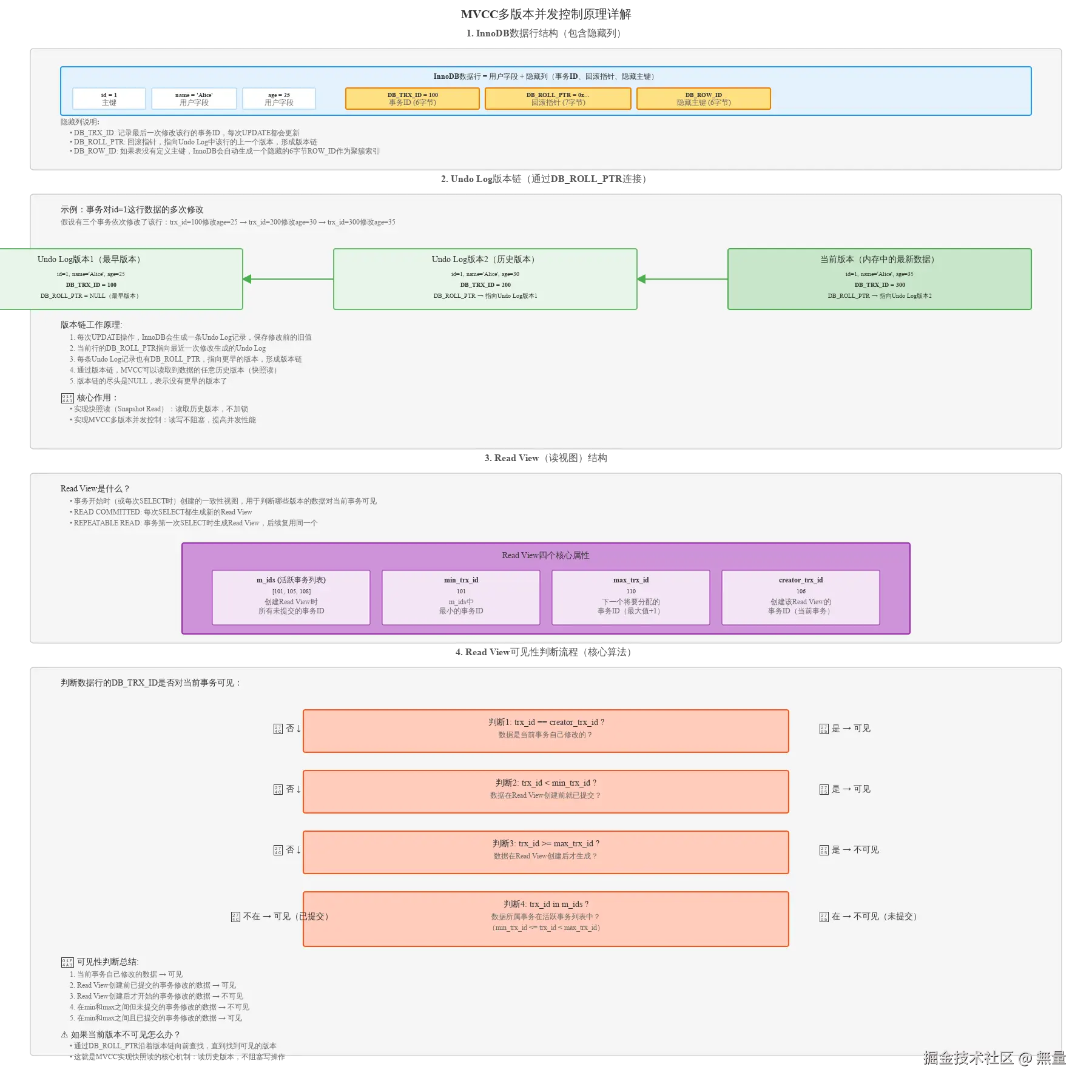
3.1 MVCC核心原理
**MVCC(Multi-Version Concurrency Control)**是InnoDB实现高并发读写的核心机制:
- 核心思想: 为每行数据保存多个版本,读取数据时根据事务隔离级别返回合适的版本
- 优势: 读写不阻塞,读不加锁,大幅提升并发性能
- 适用场景: 只在READ COMMITTED和REPEATABLE READ隔离级别下生效
传统锁机制 vs MVCC:
| 维度 | 传统锁机制 | MVCC机制 |
|---|---|---|
| 读写并发 | 读写互斥(读加S锁,写加X锁) | 读写不互斥(快照读) |
| 性能 | 读写阻塞,并发性能差 | 读写并发,性能高 |
| 实现复杂度 | 简单(加锁即可) | 复杂(版本链、Read View) |
| 适用场景 | SERIALIZABLE隔离级别 | RC、RR隔离级别 |
3.2 MVCC实现机制
3.2.1 隐藏列
InnoDB为每行数据自动添加三个隐藏列(详见上图):
| 隐藏列 | 大小 | 含义 |
|---|---|---|
| DB_TRX_ID | 6字节 | 最后一次修改该行的事务ID |
| DB_ROLL_PTR | 7字节 | 回滚指针,指向Undo Log中的旧版本 |
| DB_ROW_ID | 6字节 | 隐藏主键(表没有主键时自动生成) |
示例数据行结构:
ini
| id=1 | name='Alice' | age=25 | DB_TRX_ID=100 | DB_ROLL_PTR=0x... | DB_ROW_ID=... |3.2.2 Undo Log版本链
Undo Log作用:
- 事务回滚时恢复数据
- MVCC读取历史版本数据
版本链形成过程:
假设id=1这行数据经历了三次修改:
ini
1. trx_id=100: INSERT (age=25)
2. trx_id=200: UPDATE age=30
3. trx_id=300: UPDATE age=35版本链结构 (详见上图):
ini
当前版本: (age=35, DB_TRX_ID=300, DB_ROLL_PTR→版本2)
↓
版本2 (Undo Log): (age=30, DB_TRX_ID=200, DB_ROLL_PTR→版本1)
↓
版本1 (Undo Log): (age=25, DB_TRX_ID=100, DB_ROLL_PTR=NULL)通过版本链,MVCC可以读取到数据的任意历史版本。
3.2.3 Read View(读视图)
Read View定义: 事务开始时(或每次SELECT时)创建的一致性视图,用于判断哪些版本对当前事务可见。
Read View四个核心属性:
| 属性 | 含义 |
|---|---|
| m_ids | 创建Read View时所有活跃(未提交)的事务ID列表 |
| min_trx_id | m_ids中最小的事务ID |
| max_trx_id | 下一个将要分配的事务ID (最大值+1) |
| creator_trx_id | 创建该Read View的事务ID (当前事务) |
示例:
假设当前有5个事务:
ini
已提交事务: trx_id = 95, 98
活跃事务: trx_id = 101, 105, 108 (未提交)
当前事务: trx_id = 106则Read View为:
ini
m_ids = [101, 105, 108]
min_trx_id = 101
max_trx_id = 110 (下一个分配的ID)
creator_trx_id = 1063.3 可见性判断规则
核心问题: 数据行的DB_TRX_ID是否对当前事务可见?
判断流程 (详见上图):
markdown
1. trx_id == creator_trx_id?
→ 是: 可见 (当前事务自己修改的数据)
2. trx_id < min_trx_id?
→ 是: 可见 (在Read View创建前就已提交)
3. trx_id >= max_trx_id?
→ 是: 不可见 (在Read View创建后才开始的事务)
4. min_trx_id <= trx_id < max_trx_id?
→ trx_id in m_ids?
- 在: 不可见 (活跃事务,未提交)
- 不在: 可见 (已提交)示例:
假设当前Read View:
ini
m_ids = [101, 105, 108]
min_trx_id = 101
max_trx_id = 110
creator_trx_id = 106判断以下数据行是否可见:
| DB_TRX_ID | 判断 | 结果 |
|---|---|---|
| 106 | == creator_trx_id | ✅ 可见 (自己的修改) |
| 98 | < min_trx_id | ✅ 可见 (已提交) |
| 112 | >= max_trx_id | ❌ 不可见 (未来事务) |
| 101 | in m_ids | ❌ 不可见 (未提交) |
| 103 | not in m_ids && < max_trx_id | ✅ 可见 (已提交) |
如果当前版本不可见怎么办?
通过DB_ROLL_PTR沿着版本链向前查找,直到找到可见的版本。
3.4 不同隔离级别的Read View生成时机
READ COMMITTED:
- 生成时机: 每次SELECT都生成新的Read View
- 结果: 每次SELECT都能读到最新已提交的数据
- 问题: 导致不可重复读
示例:
sql
-- 事务A (RC隔离级别)
BEGIN;
SELECT * FROM account WHERE id = 1; -- Read View 1: balance=1000
-- 事务B
UPDATE account SET balance = 500 WHERE id = 1; COMMIT;
-- 事务A
SELECT * FROM account WHERE id = 1; -- Read View 2: balance=500 (不可重复读!)REPEATABLE READ:
- 生成时机: 事务第一次SELECT时生成Read View,后续SELECT复用同一个
- 结果: 同一事务内多次SELECT结果一致
- 优势: 保证可重复读
示例:
sql
-- 事务A (RR隔离级别)
BEGIN;
SELECT * FROM account WHERE id = 1; -- Read View 1: balance=1000
-- 事务B
UPDATE account SET balance = 500 WHERE id = 1; COMMIT;
-- 事务A
SELECT * FROM account WHERE id = 1; -- 复用Read View 1: balance=1000 (可重复读!)3.5 MVCC + 锁解决幻读
MVCC只能解决快照读的幻读,不能解决当前读的幻读
- 快照读(Snapshot Read): 普通SELECT,使用MVCC,读取历史版本
- 当前读(Current Read): SELECT ... FOR UPDATE、UPDATE、DELETE,加锁,读取最新版本
示例:
sql
-- 事务A (RR隔离级别)
BEGIN;
-- 快照读: MVCC,读取历史版本
SELECT * FROM orders WHERE status = 1; -- 假设100条
-- 事务B
INSERT INTO orders VALUES (101, 1, ...); COMMIT;
-- 事务A: 快照读
SELECT * FROM orders WHERE status = 1; -- 仍然100条 (MVCC,看不到新插入的行)
-- 事务A: 当前读
SELECT * FROM orders WHERE status = 1 FOR UPDATE; -- 101条 (Next-Key Lock,能看到,幻读!)
-- 事务A: UPDATE触发当前读
UPDATE orders SET amount = amount + 100 WHERE status = 1; -- 影响101行 (幻读!)Next-Key Lock解决当前读的幻读 (详见第四章)
四、InnoDB锁机制详解

4.1 锁的分类
4.1.1 按粒度分类
表锁 (Table Lock)
-
特点: 锁定整张表,开销小,加锁快,不会出现死锁
-
缺点: 锁粒度大,并发度低
-
使用场景: MyISAM引擎,整表数据迁移
-
示例 :
sqlLOCK TABLE orders READ; -- 读锁 LOCK TABLE orders WRITE; -- 写锁 UNLOCK TABLES; -- 释放锁
行锁 (Row Lock)
-
特点: 锁定单行或多行,开销大,加锁慢,可能出现死锁
-
优点: 锁粒度小,并发度高
-
使用场景: InnoDB引擎默认
-
示例 :
sqlSELECT * FROM orders WHERE id = 10 FOR UPDATE; -- 锁定id=10这一行
4.1.2 按模式分类
共享锁 (Shared Lock, S锁)
-
特点: 读锁,多个事务可同时持有同一行的S锁
-
兼容性: S锁与S锁兼容,S锁与X锁互斥
-
加锁方式 :
sqlSELECT * FROM orders WHERE id = 10 LOCK IN SHARE MODE;
排他锁 (Exclusive Lock, X锁)
-
特点: 写锁,只有一个事务可持有X锁
-
兼容性: X锁与所有锁互斥
-
加锁方式 :
sqlSELECT * FROM orders WHERE id = 10 FOR UPDATE; UPDATE orders SET status = 1 WHERE id = 10; -- 自动加X锁 DELETE FROM orders WHERE id = 10; -- 自动加X锁
锁兼容性矩阵:
| S锁 | X锁 | |
|---|---|---|
| S锁 | ✅ 兼容 | ❌ 互斥 |
| X锁 | ❌ 互斥 | ❌ 互斥 |
4.2 InnoDB行锁类型
4.2.1 记录锁 (Record Lock)
定义: 锁定单个索引记录,不锁定记录之间的间隙
示例 (详见上图):
sql
-- 假设account表有主键索引 id = [3, 10, 20, 30]
SELECT * FROM account WHERE id = 10 FOR UPDATE;锁定范围: 只锁定id=10这一条记录
特点:
- ✅ 其他事务可以在间隙(3, 10)、(10, 20)中插入新记录
- ❌ 其他事务无法UPDATE/DELETE id=10的记录
4.2.2 间隙锁 (Gap Lock)
定义: 锁定索引记录之间的间隙,不锁定记录本身,防止其他事务插入数据(防止幻读)
示例 (详见上图):
sql
-- REPEATABLE READ隔离级别
SELECT * FROM account WHERE id > 10 AND id < 20 FOR UPDATE;锁定范围: 锁定间隙(10, 20),不包括id=10和id=20
特点:
- ✅ 防止在(10, 20)范围内插入新记录
- ❌ 其他事务无法执行
INSERT INTO account VALUES(15, ...) - ✅ 其他事务可以UPDATE/DELETE id=10或id=20的记录
⚠️ 重要: 间隙锁只在REPEATABLE READ隔离级别下生效
4.2.3 Next-Key Lock(临键锁)
定义: 记录锁 + 间隙锁的组合,锁定一个范围并锁定记录本身
InnoDB默认行锁类型: Next-Key Lock
示例 (详见上图):
sql
-- REPEATABLE READ隔离级别
SELECT * FROM account WHERE id >= 10 AND id < 20 FOR UPDATE;锁定范围: [10, 20),包括id=10(记录锁) + 间隙(10, 20)(间隙锁)
特点:
- ❌ 其他事务无法UPDATE/DELETE id=10的记录
- ❌ 其他事务无法在(10, 20)范围内插入新记录
Next-Key Lock范围计算规则:
假设索引值为 3, 10, 20, 30,查询条件 id >= 10 AND id < 20:
vbnet
Next-Key Lock范围: (3, 10] + (10, 20) = (3, 20)4.2.4 插入意向锁 (Insert Intention Lock)
定义: 特殊的间隙锁,多个事务可在同一间隙并发插入(不同位置)
示例:
sql
-- 事务A
INSERT INTO account VALUES (15, ...); -- 在间隙(10, 20)中插入
-- 事务B
INSERT INTO account VALUES (18, ...); -- 在同一间隙(10, 20)中插入,不阻塞4.3 意向锁 (Intention Lock)
定义: 表级锁,由InnoDB自动添加,用于快速判断表是否被锁定
两种意向锁:
- IS锁(Intention Shared Lock): 事务想要获取表中某些行的S锁
- IX锁(Intention Exclusive Lock): 事务想要获取表中某些行的X锁
作用: 避免在加表锁时逐行检查是否有行锁
锁兼容性矩阵:
| IS | IX | S | X | |
|---|---|---|---|---|
| IS | ✅ | ✅ | ✅ | ❌ |
| IX | ✅ | ✅ | ❌ | ❌ |
| S | ✅ | ❌ | ✅ | ❌ |
| X | ❌ | ❌ | ❌ | ❌ |
4.4 锁的加锁规则
1. 唯一索引等值查询
sql
-- 记录存在
SELECT * FROM account WHERE id = 10 FOR UPDATE;
-- 加锁: 记录锁 (只锁id=10)
-- 记录不存在
SELECT * FROM account WHERE id = 15 FOR UPDATE;
-- 加锁: 间隙锁 (10, 20)2. 唯一索引范围查询
sql
SELECT * FROM account WHERE id > 10 AND id < 20 FOR UPDATE;
-- 加锁: Next-Key Lock (10, 20]3. 非唯一索引等值查询
sql
-- 假设name字段有非唯一索引
SELECT * FROM account WHERE name = 'Alice' FOR UPDATE;
-- 加锁: Next-Key Lock + 间隙锁4. 非唯一索引范围查询
sql
SELECT * FROM account WHERE name >= 'Alice' AND name < 'Bob' FOR UPDATE;
-- 加锁: Next-Key Lock5. 无索引查询
sql
-- balance字段无索引
SELECT * FROM account WHERE balance > 1000 FOR UPDATE;
-- 加锁: 全表扫描,锁定所有记录 (相当于表锁)⚠️ 重要: 无索引行锁会升级为表锁,严重影响并发性能!
4.5 死锁问题

4.5.1 死锁产生的四个必要条件
- 互斥条件: 资源不能被多个事务同时使用
- 请求与保持条件: 事务持有部分资源,同时请求新资源
- 不剥夺条件: 已获得的资源在未使用完前不能被强行剥夺
- 循环等待条件: 事务形成环路,每个事务都在等待下一个事务释放资源
4.5.2 死锁示例
场景: 两个事务以不同顺序锁定资源(详见上图)
sql
-- 事务1
BEGIN;
UPDATE orders SET status = 1 WHERE id = 10; -- 持有id=10的锁
UPDATE orders SET status = 1 WHERE id = 20; -- 等待id=20的锁 (阻塞)
COMMIT;
-- 事务2
BEGIN;
UPDATE orders SET status = 2 WHERE id = 20; -- 持有id=20的锁
UPDATE orders SET status = 2 WHERE id = 10; -- 等待id=10的锁 (阻塞) → 死锁!
COMMIT;死锁检测: InnoDB自动检测到循环等待,选择回滚代价小的事务(事务2)
4.5.3 如何避免死锁
1. 统一锁定顺序
java
// ❌ 错误: 不同顺序锁定
// 线程A
updateOrder(10);
updateOrder(20);
// 线程B
updateOrder(20);
updateOrder(10);
// ✅ 正确: 统一顺序锁定
List<Long> orderIds = Arrays.asList(10L, 20L);
Collections.sort(orderIds); // 排序,保证顺序一致
for (Long id : orderIds) {
updateOrder(id);
}2. 尽量使用索引访问数据
sql
-- ❌ 无索引,锁全表
UPDATE orders SET status = 1 WHERE user_name = 'Alice';
-- ✅ 有索引,只锁部分行
ALTER TABLE orders ADD INDEX idx_user_name (user_name);
UPDATE orders SET status = 1 WHERE user_name = 'Alice';3. 缩短事务持续时间
java
// ❌ 错误: 事务中包含RPC调用
@Transactional(rollbackFor = Exception.class)
public void processOrder(Long orderId) {
orderMapper.updateStatus(orderId, OrderStatus.PAID);
// RPC调用,耗时长,长时间持有锁!
inventoryService.deduct(orderId);
pointsMapper.add(orderId);
}
// ✅ 正确: RPC调用移到事务外
public void processOrder(Long orderId) {
// 事务外调用RPC
InventoryResult result = inventoryService.deduct(orderId);
// 事务内快速提交
updateOrderInTransaction(orderId, result);
}
@Transactional(rollbackFor = Exception.class)
private void updateOrderInTransaction(Long orderId, InventoryResult result) {
orderMapper.updateStatus(orderId, OrderStatus.PAID);
pointsMapper.add(orderId);
}4. 设置锁等待超时时间
sql
-- 查看锁等待超时时间 (默认50秒)
SHOW VARIABLES LIKE 'innodb_lock_wait_timeout';
-- 设置锁等待超时时间
SET innodb_lock_wait_timeout = 10; -- 10秒4.5.4 查看死锁日志
sql
-- 查看最近一次死锁信息
SHOW ENGINE INNODB STATUS\G;
-- 输出示例
------------------------
LATEST DETECTED DEADLOCK
------------------------
2024-10-21 10:30:15 0x7f8b8c0c9700
*** (1) TRANSACTION:
TRANSACTION 12345, ACTIVE 5 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 2 lock struct(s), heap size 1136, 1 row lock(s)
MySQL thread id 10, OS thread handle 140237, query id 1000 localhost root updating
UPDATE orders SET status = 1 WHERE id = 20
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 100 page no 3 n bits 72 index PRIMARY of table `test`.`orders` trx id 12345 lock_mode X locks rec but not gap waiting
Record lock, heap no 5 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
*** (2) TRANSACTION:
TRANSACTION 12346, ACTIVE 3 sec starting index read
mysql tables in use 1, locked 1
2 lock struct(s), heap size 1136, 1 row lock(s)
MySQL thread id 11, OS thread handle 140238, query id 1001 localhost root updating
UPDATE orders SET status = 2 WHERE id = 10
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 100 page no 3 n bits 72 index PRIMARY of table `test`.`orders` trx id 12346 lock_mode X locks rec but not gap
Record lock, heap no 5 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 100 page no 3 n bits 72 index PRIMARY of table `test`.`orders` trx id 12346 lock_mode X locks rec but not gap waiting
Record lock, heap no 4 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
*** WE ROLL BACK TRANSACTION (2)五、实战场景应用
5.1 场景1: 电商库存扣减并发问题
业务背景: 订单下单时扣减库存,高并发下可能超卖
方案对比:
方案A: 悲观锁 (SELECT ... FOR UPDATE)
java
@Transactional(rollbackFor = Exception.class)
public void createOrder(Long skuId, Integer quantity) {
// 1. 悲观锁查询库存
Product product = productMapper.selectForUpdate(skuId);
// 2. 检查库存
if (product.getStock() < quantity) {
throw new BusinessException("库存不足");
}
// 3. 扣减库存
productMapper.deductStock(skuId, quantity);
// 4. 创建订单
orderMapper.insert(order);
}
sql
-- productMapper.selectForUpdate
SELECT * FROM product WHERE id = #{skuId} FOR UPDATE;
-- productMapper.deductStock
UPDATE product SET stock = stock - #{quantity} WHERE id = #{skuId};优点:
- ✅ 强一致性,绝对不会超卖
- ✅ 实现简单,逻辑清晰
缺点:
- ❌ 并发性能差,所有请求串行执行
- ❌ 高并发下大量请求阻塞
方案B: 乐观锁 (version字段)
java
@Transactional(rollbackFor = Exception.class)
public void createOrder(Long skuId, Integer quantity) {
int retryCount = 0;
while (retryCount < 3) {
// 1. 查询库存和版本号
Product product = productMapper.selectById(skuId);
// 2. 检查库存
if (product.getStock() < quantity) {
throw new BusinessException("库存不足");
}
// 3. 乐观锁扣减库存
int rows = productMapper.deductStockWithVersion(
skuId, quantity, product.getVersion()
);
if (rows > 0) {
// 4. 创建订单
orderMapper.insert(order);
return;
}
// 版本号不匹配,重试
retryCount++;
Thread.sleep(10);
}
throw new BusinessException("库存扣减失败,请重试");
}
sql
-- productMapper.deductStockWithVersion
UPDATE product
SET stock = stock - #{quantity}, version = version + 1
WHERE id = #{skuId} AND version = #{version} AND stock >= #{quantity};优点:
- ✅ 并发性能好,无阻塞
- ✅ 适合冲突不频繁的场景
缺点:
- ❌ 需要重试机制,实现复杂
- ❌ 高并发下重试次数多,性能下降
方案C: 数据库约束 (stock >= 0)
java
@Transactional(rollbackFor = Exception.class)
public void createOrder(Long skuId, Integer quantity) {
// 1. 直接扣减库存
int rows = productMapper.deductStock(skuId, quantity);
// 2. 检查更新行数
if (rows == 0) {
throw new BusinessException("库存不足");
}
// 3. 创建订单
orderMapper.insert(order);
}
sql
-- productMapper.deductStock
UPDATE product
SET stock = stock - #{quantity}
WHERE id = #{skuId} AND stock >= #{quantity};优点:
- ✅ 实现简单,性能好
- ✅ 无需SELECT,减少一次查询
缺点:
- ❌ 需要检查更新影响行数
- ❌ 无法提前判断库存是否充足
三种方案性能对比:
| 方案 | TPS (1000并发) | 超卖风险 | 实现复杂度 | 推荐度 |
|---|---|---|---|---|
| 悲观锁 | 500 TPS | ❌ 无 | 简单 | ⭐⭐⭐ |
| 乐观锁 | 3000 TPS | ❌ 无 | 复杂 | ⭐⭐⭐⭐ |
| 数据库约束 | 5000 TPS | ❌ 无 | 简单 | ⭐⭐⭐⭐⭐ |
推荐: 优先使用方案C(数据库约束),实现简单,性能最优
5.2 场景2: 订单状态更新的事务控制
业务背景: 订单支付成功,需要更新订单状态、扣减库存、增加积分
完整代码示例:
java
@Service
public class OrderServiceImpl implements OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private OrderItemMapper orderItemMapper;
@Autowired
private InventoryMapper inventoryMapper;
@Autowired
private PointsMapper pointsMapper;
@Transactional(rollbackFor = Exception.class, isolation = Isolation.REPEATABLE_READ)
public void updateOrderAfterPay(Long orderId, PayDTO payDTO) {
// 1. 查询订单
Order order = orderMapper.selectById(orderId);
if (order == null) {
throw new BusinessException("订单不存在");
}
// 2. 检查订单状态
if (order.getStatus() != OrderStatus.UNPAID) {
throw new BusinessException("订单状态异常");
}
// 3. 更新订单状态
orderMapper.updateStatus(orderId, OrderStatus.PAID, payDTO.getPayTime());
// 4. 扣减库存
List<OrderItem> items = orderItemMapper.selectByOrderId(orderId);
for (OrderItem item : items) {
int rows = inventoryMapper.deduct(item.getSkuId(), item.getQuantity());
if (rows == 0) {
throw new BusinessException("库存不足: SKU=" + item.getSkuId());
}
}
// 5. 增加积分
int points = (int) (payDTO.getAmount() / 10); // 每消费10元增加1积分
pointsMapper.add(payDTO.getUserId(), points);
log.info("订单支付成功处理完成, orderId={}, userId={}, amount={}, points={}",
orderId, payDTO.getUserId(), payDTO.getAmount(), points);
}
}关键点:
-
@Transactional配置:
rollbackFor = Exception.class: 所有异常都回滚(包括非RuntimeException)isolation = Isolation.REPEATABLE_READ: 使用可重复读隔离级别
-
事务边界控制:
- 事务内只包含数据库操作
- RPC调用、文件操作移到事务外
-
异常处理:
- 库存不足抛出异常,触发事务回滚
- 所有操作要么全部成功,要么全部回滚
六、生产案例与故障排查
6.1 案例1: 死锁导致的订单处理失败
故障现象:
- 订单支付后,状态未更新
- 应用日志出现大量DeadlockLoserDataAccessException
- 用户投诉订单支付成功但显示未支付
排查步骤:
步骤1: 查看应用日志
vbnet
2024-10-21 10:30:15 ERROR OrderService - 订单更新失败, orderId=12345
org.springframework.dao.DeadlockLoserDataAccessException:
PreparedStatementCallback; SQL [UPDATE orders SET status=? WHERE id=?];
Deadlock found when trying to get lock; try restarting transaction步骤2: 查看MySQL死锁日志
sql
SHOW ENGINE INNODB STATUS\G;分析死锁日志,定位到两条SQL:
ini
事务1: UPDATE orders SET status=1 WHERE id=100;
UPDATE order_items SET status=1 WHERE order_id=100;
事务2: UPDATE order_items SET status=1 WHERE order_id=100;
UPDATE orders SET status=1 WHERE id=100;问题分析:
- 两个事务以不同顺序锁定resources
- 事务1先锁orders,再锁order_items
- 事务2先锁order_items,再锁orders
- 形成循环等待,产生死锁
解决方案:
统一锁定顺序,先锁orders,再锁order_items:
java
// ✅ 正确: 统一锁定顺序
@Transactional(rollbackFor = Exception.class)
public void updateOrderStatus(Long orderId, Integer status) {
// 1. 先锁orders
orderMapper.updateStatus(orderId, status);
// 2. 再锁order_items
orderItemMapper.updateStatusByOrderId(orderId, status);
}效果: 死锁频率从每小时100次降到0
6.2 案例2: 长事务导致的锁等待
故障现象:
- 订单列表查询变慢,大量超时
- 应用CPU和内存正常,但响应慢
- 数据库连接池耗尽
排查步骤:
步骤1: 查看慢查询日志
ini
# Time: 2024-10-21T10:30:15.123456Z
# Query_time: 30.521234 Lock_time: 30.000123
SELECT * FROM orders WHERE user_id = 100;Lock_time=30秒,说明在等待锁!
步骤2: 查看当前事务和锁
sql
-- 查看当前活跃事务
SELECT * FROM information_schema.innodb_trx\G;
*************************** 1. row ***************************
trx_id: 12345
trx_state: RUNNING
trx_started: 2024-10-21 10:25:00
trx_requested_lock_id: NULL
trx_wait_started: NULL
trx_weight: 0
trx_mysql_thread_id: 100
trx_query: NULL
trx_operation_state: NULL
trx_tables_in_use: 0
trx_tables_locked: 1
trx_lock_structs: 1
trx_lock_memory_bytes: 1136
trx_rows_locked: 100
trx_rows_modified: 0
trx_concurrency_tickets: 0
trx_isolation_level: REPEATABLE READ
trx_unique_checks: 1
trx_foreign_key_checks: 1
trx_last_foreign_key_error: NULL
trx_adaptive_hash_latched: 0
trx_adaptive_hash_timeout: 0
trx_is_read_only: 0
trx_autocommit_non_locking: 0
trx_schedule_weight: NULL发现一个事务已运行5分钟(10:25:00 - 10:30:00),未提交!
步骤3: 查看锁等待
sql
SELECT * FROM information_schema.innodb_lock_waits\G;
*************************** 1. row ***************************
requesting_trx_id: 12346
requested_lock_id: 12346:100:3:5
blocking_trx_id: 12345
blocking_lock_id: 12345:100:3:5事务12346被事务12345阻塞。
步骤4: 查看阻塞线程的SQL
sql
SHOW FULL PROCESSLIST;
+-----+------+-----------+------+---------+------+-------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+-----+------+-----------+------+---------+------+-------+------------------+
| 100 | root | localhost | test | Sleep | 300 | | NULL |
+-----+------+-----------+------+---------+------+-------+------------------+线程100处于Sleep状态,已运行300秒!
问题分析:
- 开发人员在测试环境手动BEGIN,执行UPDATE后未COMMIT
- 长时间持有锁,阻塞其他查询
- 连接池被耗尽,新请求无法获取连接
解决方案:
临时方案: KILL掉长事务
sql
KILL 100;永久方案:
- 设置锁等待超时时间:
sql
SET GLOBAL innodb_lock_wait_timeout = 10; -- 10秒- 监控长事务,自动告警:
sql
-- 查询运行超过10秒的事务
SELECT
trx_id,
trx_state,
trx_started,
TIMESTAMPDIFF(SECOND, trx_started, NOW()) AS running_seconds,
trx_mysql_thread_id,
trx_query
FROM information_schema.innodb_trx
WHERE TIMESTAMPDIFF(SECOND, trx_started, NOW()) > 10;- 代码Review,确保事务及时提交:
java
// ❌ 错误: 手动BEGIN未COMMIT
public void badExample() {
jdbcTemplate.execute("BEGIN");
jdbcTemplate.update("UPDATE ...");
// 忘记COMMIT!
}
// ✅ 正确: 使用@Transactional
@Transactional(rollbackFor = Exception.class)
public void goodExample() {
jdbcTemplate.update("UPDATE ...");
// 自动COMMIT或ROLLBACK
}效果: 锁等待时间从30秒降到0,查询响应时间从30秒降到50ms
七、常见问题与避坑指南
7.1 什么情况下会发生幻读?InnoDB如何解决?
幻读发生条件:
- 隔离级别为REPEATABLE READ
- 使用当前读(SELECT ... FOR UPDATE、UPDATE、DELETE)
- 其他事务INSERT新数据并提交
InnoDB解决方案: Next-Key Lock
sql
-- 事务A
BEGIN;
SELECT * FROM orders WHERE status = 1 FOR UPDATE; -- 加Next-Key Lock
-- 事务B
INSERT INTO orders VALUES (101, 1, ...); -- 阻塞,无法插入
-- 事务A
SELECT * FROM orders WHERE status = 1 FOR UPDATE; -- 结果一致,无幻读7.2 为什么REPEATABLE READ是MySQL默认隔离级别?
原因:
- 性能平衡: RC级别性能高但有不可重复读,SERIALIZABLE级别无并发,RR级别折中
- 主从复制: MySQL binlog默认使用STATEMENT格式,RC级别下可能导致主从不一致
- 兼容性: MySQL历史原因,保持向后兼容
Oracle为什么用READ COMMITTED?
- Oracle使用Redo Log实现主从复制,不依赖binlog
- Oracle MVCC实现更完善,RC级别下也能保证一致性
7.3 MVCC在什么隔离级别下生效?
生效级别: READ COMMITTED、REPEATABLE READ
不生效级别:
- READ UNCOMMITTED: 无隔离,直接读最新数据
- SERIALIZABLE: 所有SELECT自动加S锁,无需MVCC
7.4 什么是快照读和当前读?区别是什么?
| 维度 | 快照读 (Snapshot Read) | 当前读 (Current Read) |
|---|---|---|
| 定义 | 读取历史版本数据 | 读取最新版本数据 |
| SQL | SELECT (普通) | SELECT ... FOR UPDATE UPDATE DELETE |
| 实现 | MVCC(Read View + 版本链) | 加锁(S锁或X锁) |
| 是否加锁 | ❌ 不加锁 | ✅ 加锁 |
| 读写阻塞 | 读写不阻塞 | 读写互斥 |
| 幻读 | MVCC解决快照读的幻读 | Next-Key Lock解决当前读的幻读 |
7.5 为什么无索引查询会锁全表?
原因: InnoDB行锁是加在索引上的,无索引则全表扫描,锁定所有记录
示例:
sql
-- balance字段无索引
UPDATE account SET status = 1 WHERE balance > 1000;执行计划:
vbnet
type: ALL (全表扫描)
rows: 1000000
Extra: Using where加锁: 锁定所有100万行记录(相当于表锁)
优化: 添加索引
sql
ALTER TABLE account ADD INDEX idx_balance (balance);7.6 间隙锁在什么情况下会加?
加锁条件:
- 隔离级别为REPEATABLE READ
- 范围查询(>、<、BETWEEN)或等值查询但记录不存在
示例:
sql
-- RR隔离级别,索引值 [3, 10, 20, 30]
-- 1. 范围查询 → 加间隙锁
SELECT * FROM account WHERE id > 10 AND id < 20 FOR UPDATE;
-- 锁定: (10, 20)
-- 2. 等值查询但记录不存在 → 加间隙锁
SELECT * FROM account WHERE id = 15 FOR UPDATE;
-- 锁定: (10, 20)
-- 3. 等值查询且记录存在 → 加记录锁
SELECT * FROM account WHERE id = 10 FOR UPDATE;
-- 锁定: id=10 (记录锁)7.7 如何查看当前事务和锁信息?
sql
-- 查看当前活跃事务
SELECT * FROM information_schema.innodb_trx;
-- 查看当前锁
SELECT * FROM information_schema.innodb_locks;
-- 查看锁等待
SELECT * FROM information_schema.innodb_lock_waits;
-- 查看InnoDB状态 (包含死锁日志)
SHOW ENGINE INNODB STATUS\G;
-- 查看进程列表
SHOW FULL PROCESSLIST;
-- KILL掉阻塞的事务
KILL <thread_id>;7.8 @Transactional注解的rollbackFor为什么要设置?
原因: Spring默认只回滚RuntimeException和Error,不回滚受检异常(Exception)
示例:
java
// ❌ 错误: 受检异常不回滚
@Transactional
public void badExample() throws Exception {
orderMapper.insert(order);
if (someCondition) {
throw new Exception("业务异常"); // 不会回滚!
}
}
// ✅ 正确: 所有异常都回滚
@Transactional(rollbackFor = Exception.class)
public void goodExample() throws Exception {
orderMapper.insert(order);
if (someCondition) {
throw new Exception("业务异常"); // 会回滚
}
}7.9 事务失效的N种场景
1. 同类调用
java
// ❌ 错误: 同类调用,@Transactional失效
public class OrderService {
public void createOrder() {
this.insertOrder(); // 同类调用,事务失效!
}
@Transactional(rollbackFor = Exception.class)
public void insertOrder() {
orderMapper.insert(order);
}
}
// ✅ 正确: 注入自己,通过代理调用
@Service
public class OrderService {
@Autowired
private OrderService self;
public void createOrder() {
self.insertOrder(); // 通过代理调用,事务生效
}
@Transactional(rollbackFor = Exception.class)
public void insertOrder() {
orderMapper.insert(order);
}
}2. 方法非public
java
// ❌ 错误: private方法,事务失效
@Transactional(rollbackFor = Exception.class)
private void insertOrder() {
orderMapper.insert(order);
}
// ✅ 正确: public方法
@Transactional(rollbackFor = Exception.class)
public void insertOrder() {
orderMapper.insert(order);
}3. 异常被catch
java
// ❌ 错误: 异常被catch,事务不回滚
@Transactional(rollbackFor = Exception.class)
public void insertOrder() {
try {
orderMapper.insert(order);
} catch (Exception e) {
log.error("插入失败", e);
// 异常被吞了,事务不回滚!
}
}
// ✅ 正确: 重新抛出异常
@Transactional(rollbackFor = Exception.class)
public void insertOrder() {
try {
orderMapper.insert(order);
} catch (Exception e) {
log.error("插入失败", e);
throw new BusinessException("订单创建失败", e);
}
}八、最佳实践与总结
8.1 事务使用原则
-
事务应尽可能短
- ✅ 事务内只包含数据库操作
- ❌ 事务内不要包含RPC调用、文件操作、HTTP请求
-
合理设置隔离级别
- 大多数场景: REPEATABLE READ (MySQL默认)
- 对一致性要求不高: READ COMMITTED (性能更好)
- 金融等强一致性场景: SERIALIZABLE
-
正确使用@Transactional注解
- 必须设置
rollbackFor = Exception.class - 方法必须是public
- 避免同类调用
- 异常不要被catch
- 必须设置
8.2 锁使用原则
-
优先使用乐观锁
- 冲突不频繁的场景: 乐观锁(version字段)
- 冲突频繁的场景: 悲观锁(SELECT ... FOR UPDATE)
-
避免长时间持有锁
- 缩短事务持续时间
- RPC调用移到事务外
-
统一锁定顺序,避免死锁
- 按主键顺序锁定
- 先锁父表,再锁子表
-
尽量使用索引,避免锁全表
- WHERE条件必须使用索引
- 避免在非索引字段上UPDATE
8.3 性能优化建议
- 尽量使用索引,避免全表扫描
- 批量操作拆分为小事务
- 读多写少场景使用MVCC(快照读)
- 定期分析死锁日志,优化SQL
8.4 监控指标
sql
-- 1. 死锁频率
SHOW STATUS LIKE 'Innodb_deadlocks';
-- 2. 锁等待统计
SHOW STATUS LIKE 'Innodb_row_lock%';
-- 3. 长事务监控
SELECT
trx_id,
trx_state,
trx_started,
TIMESTAMPDIFF(SECOND, trx_started, NOW()) AS running_seconds
FROM information_schema.innodb_trx
WHERE TIMESTAMPDIFF(SECOND, trx_started, NOW()) > 10;告警阈值:
- 死锁频率 > 10次/小时
- 平均锁等待时间 > 1秒
- 长事务(>10秒) > 5个
8.5 事务设计Checklist
- ✅ 事务内只包含数据库操作
- ✅ 设置
rollbackFor = Exception.class - ✅ 方法是public
- ✅ 异常不被catch或重新抛出
- ✅ WHERE条件使用索引
- ✅ 统一锁定顺序
- ✅ 事务持续时间 < 1秒
- ✅ 批量操作拆分为小事务
8.6 核心要点总结
事务ACID特性:
- 原子性(Undo Log)、一致性(约束)、隔离性(MVCC+锁)、持久性(Redo Log)
四种隔离级别:
- RU(性能最高,无隔离) < RC(防脏读) < RR(防不可重复读,MySQL默认) < SERIALIZABLE(完全隔离)
MVCC原理:
- 隐藏列(DB_TRX_ID、DB_ROLL_PTR) + Undo Log版本链 + Read View可见性判断
- RC级别每次SELECT生成新Read View,RR级别复用同一个
InnoDB锁类型:
- 记录锁(锁单行)、间隙锁(锁间隙)、Next-Key Lock(锁行+间隙,防幻读)
- 间隙锁只在RR级别存在
死锁避免:
- 统一锁定顺序、使用索引、缩短事务、设置超时时间
快照读vs当前读:
- 快照读(普通SELECT,MVCC,不加锁) vs 当前读(FOR UPDATE,加锁,读最新版本)
掌握MySQL事务与锁机制,是高并发系统开发的核心能力。通过深入理解MVCC原理、锁的类型与加锁规则,结合电商库存扣减、死锁排查等实战案例,能够在生产环境中游刃有余地处理并发问题,构建高性能、高可靠的数据库系统。
参考资料:
- 《高性能MySQL》(第4版) - Baron Schwartz等
- 《MySQL技术内幕: InnoDB存储引擎》(第2版) - 姜承尧
- MySQL官方文档: dev.mysql.com/doc/refman/...
- 《深入理解MySQL事务隔离级别与锁机制》- 阿里云数据库团队