一 什么是窗口函数
1.1 窗口函数定义
MySQL 8.0 开始支持Window Functions窗口函数,窗口函数本质是一类分析函数,窗口的意思是限定数据表的一个范围,窗口函数就是在这个范围内执行的函数,窗口函数的定义:
sql
window_fun() over(partition by 分组列
order by 排序列
rows between and
)窗口函数使用over关键字指定一个数据分析的窗口,即是窗口函数执行的范围,有三个部分:
partition by 分区列将数据表进行分区,如果数据表不需要分区,那么partition by可以不写,或是写成partition by null,窗口函数会对每个分区进行单独分析;
order by 排序列在分区范围内,指定数据根据某个字段进行排序,如果没有排序字段,那么order by可以不写,或是写成order by null;
rows between 起始行 and 终止行,用于定义滑动窗口,滑动窗口总是位于分区的范围之内,窗口函数是基于滑动窗口对每一行数据进行分析;
滑动窗口的起始位置:
unbounded preceding,表示滑动窗口从分区的第一行开始;
n preceding,表示滑动窗口从当前行的前n行开始;
current row,表示滑动窗口从当前行开始
滑动窗口的终止位置
current row,表示滑动窗口从当前行结束
n following,表示滑动窗口从当前行的后n行结束
unbounded following,表示窗口到分区的最后一行结束;
tips:
如果在order by子句后面没有写rows子句,那么滑动窗口默认是rows between unbounded preceding and current row;
如果partition by子句后面没有写order by子句和rows子句,那么滑动窗口默认是rows between unbounded preceding and unbounded following;
partition by和order by根据具体字段划出的静态窗口,针对于静态窗口的每一行,都有各自的滑动窗口,即rows关键字,对每行的小窗口内的数据执行函数并生成新的列;
窗口函数与聚合函数的区别是,窗口函数和聚合函数都是对一组数据进行分析并返回结果,聚合函数(count、sum、avg、max、min)会将分组结果聚合成一条记录,窗口函数会在分区范围内为每一行都生成一个计算结果,即保留原始行的同时新增窗口函数计算字段;
1.2 窗口函数分类
基础统计函数:count()、sum()、avg()、max()和min();
排名函数:row_number()、rank()、dense_rank()、percent_rank()、cume_dist()和ntile();
跨行函数:lag()、lead()、first_value()、last_value()和nth_value();
二 基础统计函数
常见的五种基础统计函数:
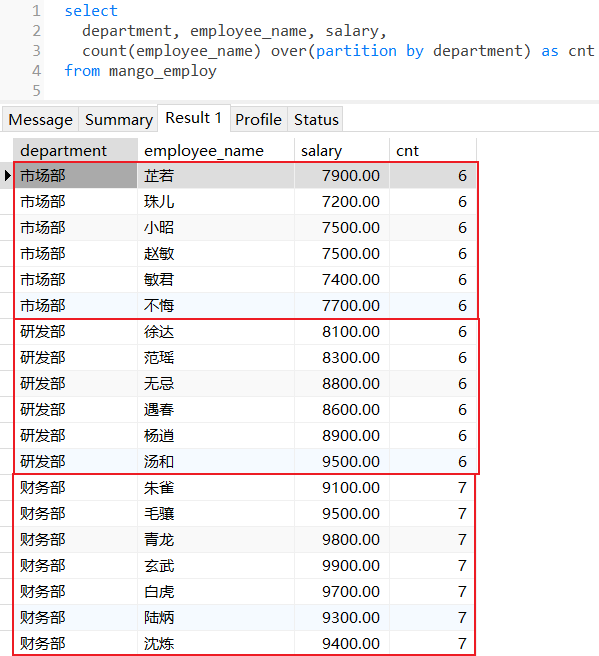
count()函数,统计满足条件的行数或列值非空的行数,count(*)统计表中所有行数(包括null值),count(column)统计指定列中非null值的行数;
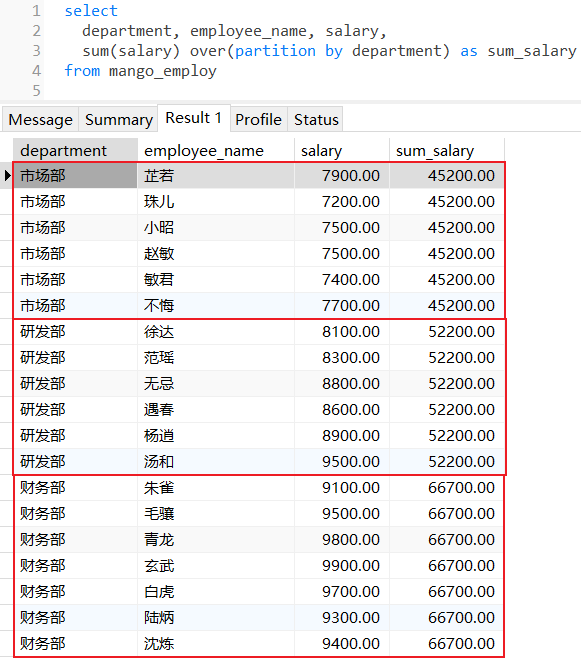
sum()函数,计算数值列的总和,忽略null值;
avg()函数,计算数值列的平均值,忽略null值;
max()函数,返回数值列或字符串列的最大值,忽略null值;
min()函数,返回数值列或字符串列的最小值,忽略null值;
所有基础统计函数都会忽略null值,除了count(*)基础统计函数会统计所有行数据,模拟一张数据表进行演示:
2.1 count()
统计每个部门下员工的数量:
2.2 sum()
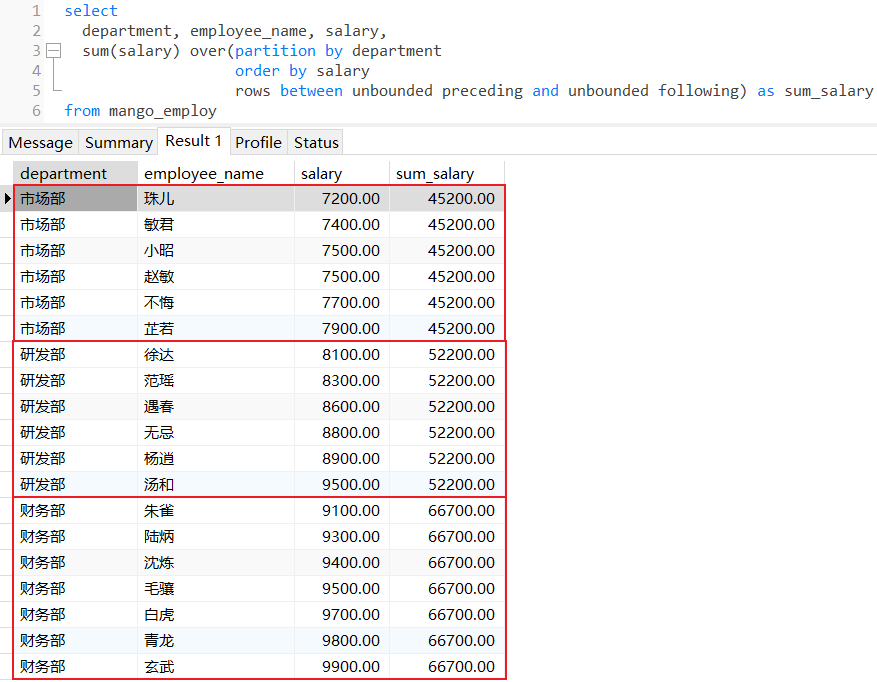
计算每个部门下所有员工薪水总和:
计算每个部门下所有员工薪水总和,并且每个部门员工薪水升序排序:
2.3 avg()
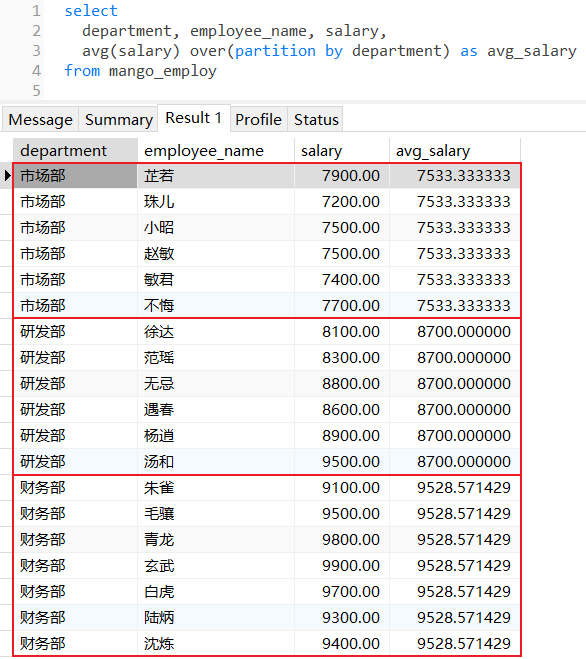
计算每个部门下所有员工薪水平均值:
2.4 max()
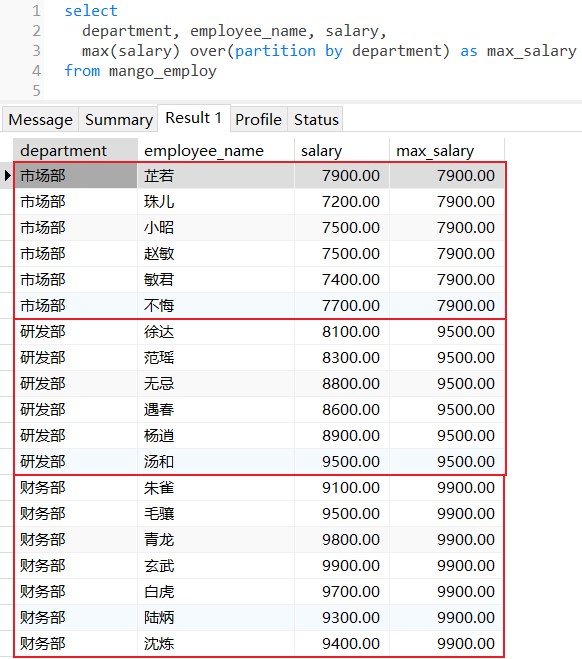
查找每个部门下员工薪水的最大值:
2.5 min()
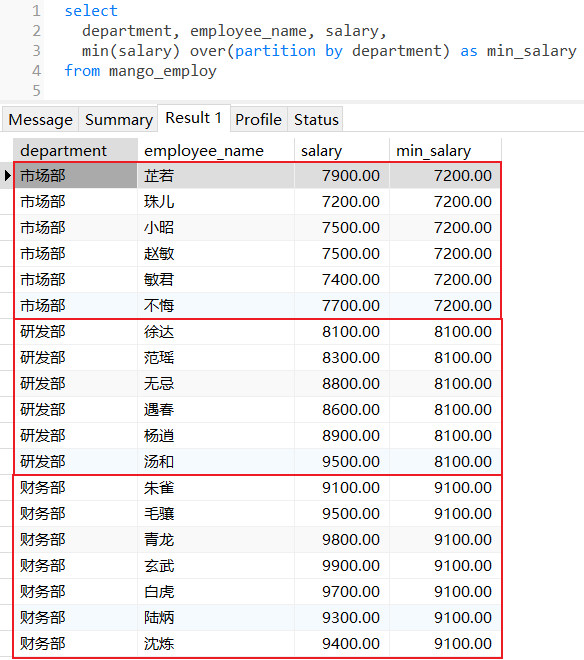
查找每个部门下员工薪水的最小值:
三 排名函数
排名窗口函数可以用来获取数据的分类排名,而且排名函数不支持滑动窗口,是以整个分区作为分析的窗口,常见的排名函数:
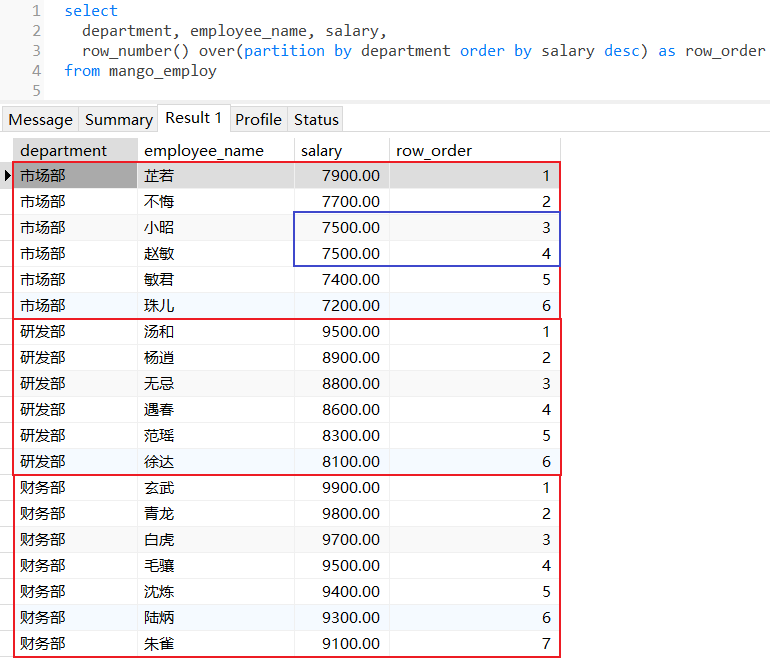
row_number():为分区范围的每行数据都分配一个序列号,序列号从1开始,没有序号重复和跳跃;
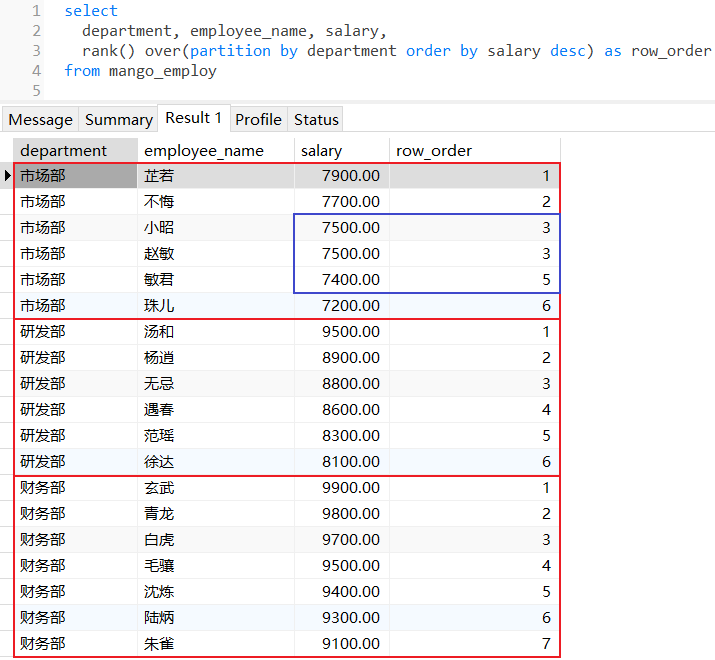
rank():为分区范围的每行数据都分配一个序列号,返回当前行在分区中的名次,如果有名次相同的数据,那么后续的排名将会产生跳跃;
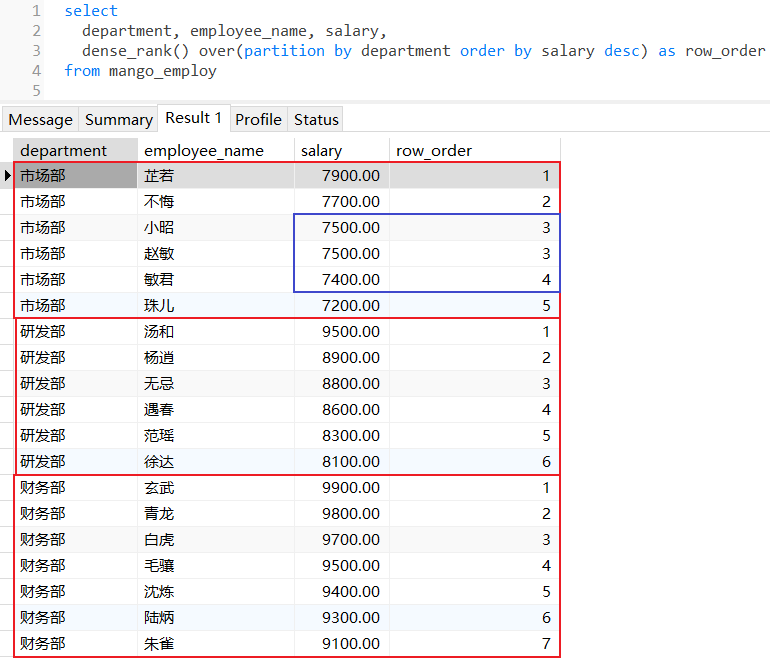
dense_rank():为分区范围的每行数据都分配一个序列号,返回当前行在分区中的名次,如果有名次相同的数据,那么后续的排名也是连续值;
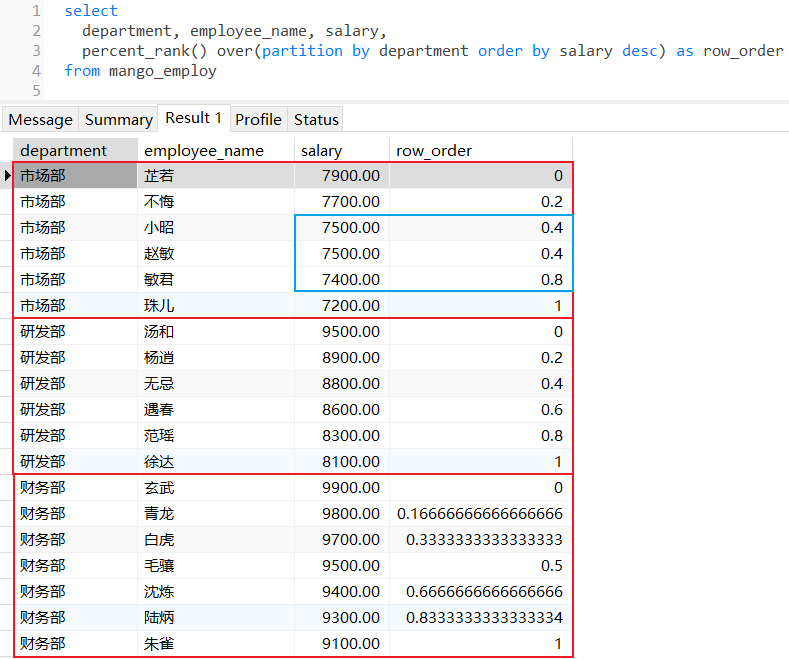
percent_rank():用于计算数据在分组内的百分比排名,结果显示当前行在排序后的相对位置,如果存在名次相同的数据,那么后续排名将会产生跳跃,函数返回值是在0.0到1.0之间的double类型数据,计算公式当前行(rank-1)除以(分区总行数-1),如果当前分区只有一行数据时,那么结果返回0.0;
cume_dist():计算当前行值在排序完成的分区范围内累积分布概率,即大于等于或是小于等于当前值的行数占比,相同值的行会得到相同的累积分布值;
ntile(n):将分区范围内的数据分为n等份,返回当前行所在分片的位置;
3.1 row_number()
3.2 rank()
3.3 dense_rank()
3.4 percent_rank()
3.5 cume_dist()
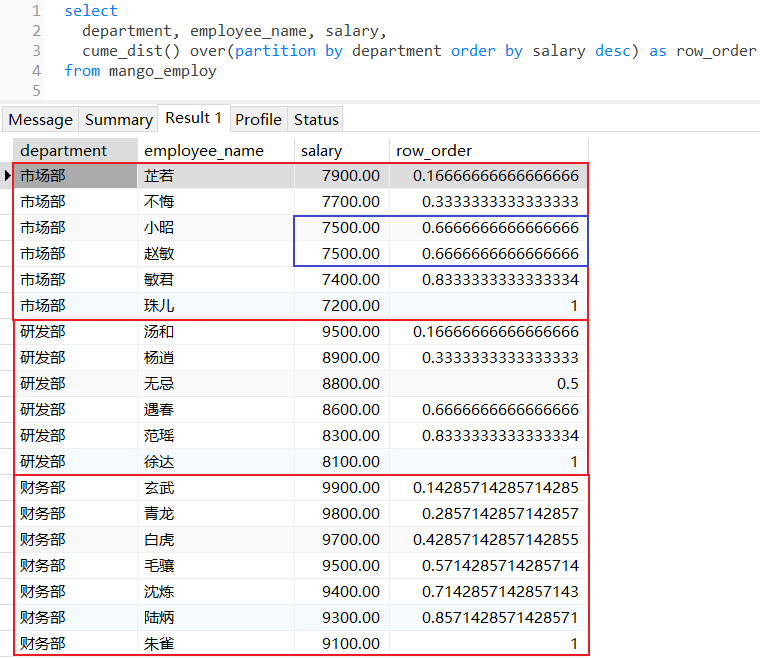
3.6 ntile()

四 跨行函数
跨行函数是用来返回窗口指定位置的数据行,常见的跨行函数:
lag():返回分区范围内当前行之前的第n行数据,不需要写rows子句,不支持滑动窗口,是以整个分区作为分析的窗口;
lead():返回窗口内当前行之后的第n行数据,不需要写rows子句,不支持滑动窗口,是以整个分区作为分析的窗口;
first_value():返回滑动窗口范围内排序后的第一行对应字段的值,如果不写rows子句,那么默认是整个分区范围,如果写了rows子句,那么是滑动窗口范围;
last_value():返回滑动窗口范围内排序后的最后一行对应字段的值,如果不写rows子句,那么默认是整个分区范围,如果写了rows子句,那么是滑动窗口范围;
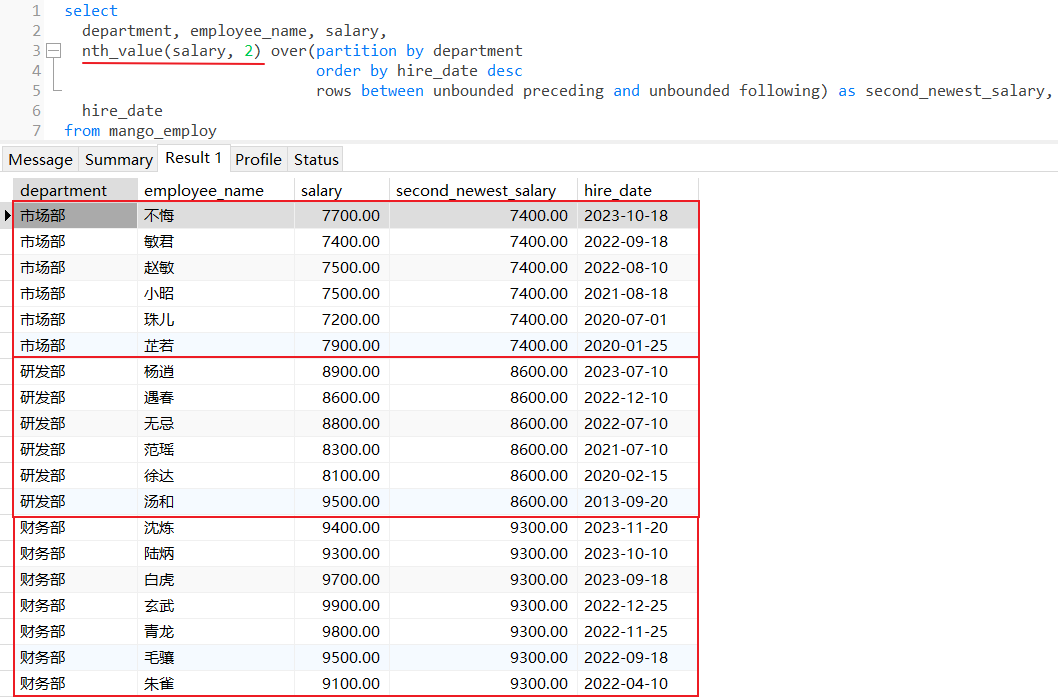
nth_value():返回滑动窗口范围内排序后的第N行对应字段的值,如果不写rows子句,那么默认是整个分区范围,如果写了rows子句,那么是滑动窗口范围;
创建一张数据表,表里面有三位员工从2023年1月份到2024年12月份的销售额,进行跨行函数演示:
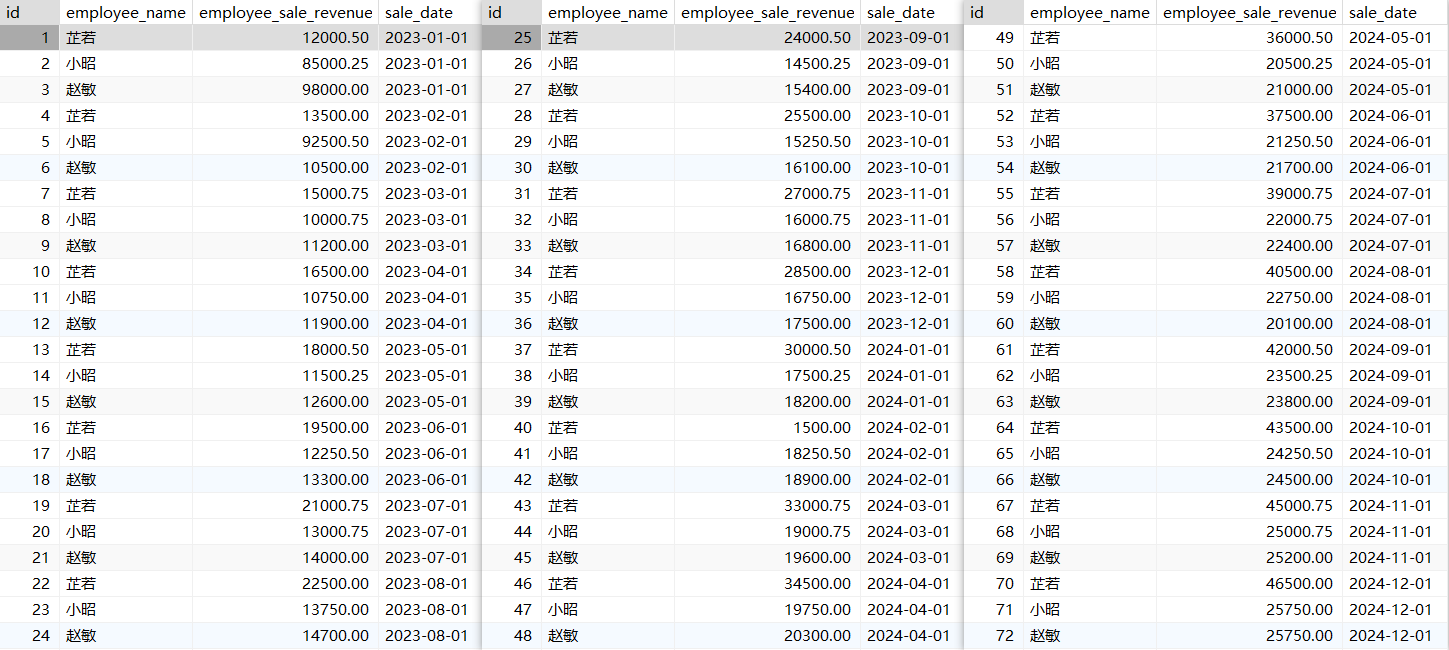
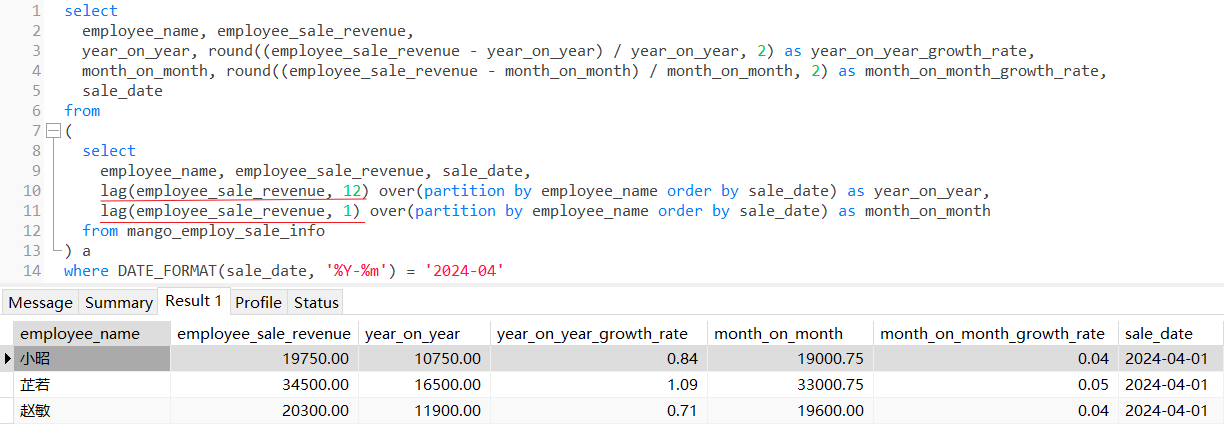
4.1 lag()
计算三位员工2024年4月份的同比增长率和环比增长率:
同比是指本期与历史同期的对比,譬如2024年4月份与2023年4月份的对比,同比增长率是(本期数-同期数) / 同期数 * 100%,应用举例是(202404 - 202304) / 202304 * 100%;
环比是指本期与相邻上一周期的对比,譬如2024年4月份与2024年3月份的对比,环比增长率是(本期数-上期数)/上期数 * 100%,应用举例是(202404 - 202403) / 202403 * 100%;
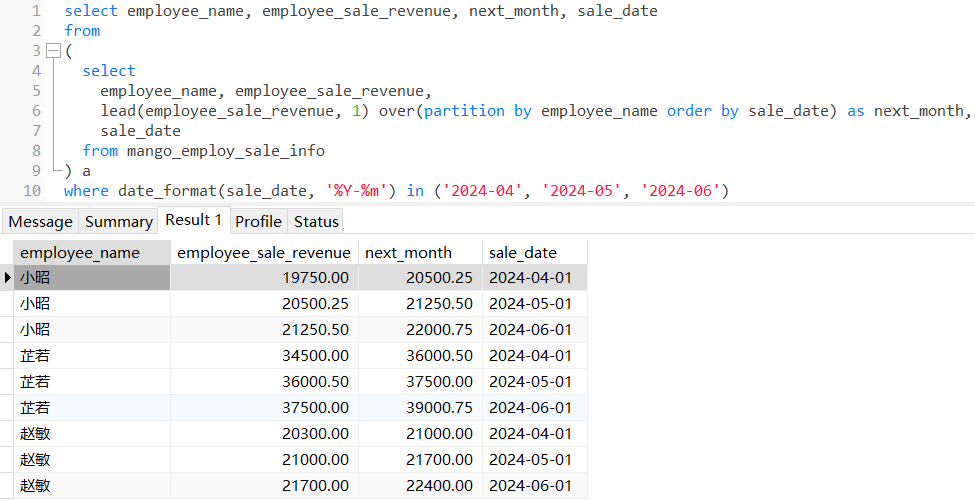
4.2 lead()
查询三位员工2024年第二季度的当前月和下一个月的数据对比:
4.3 first_value()
查询各个部门下员工薪资和最新入职员工薪资比较:
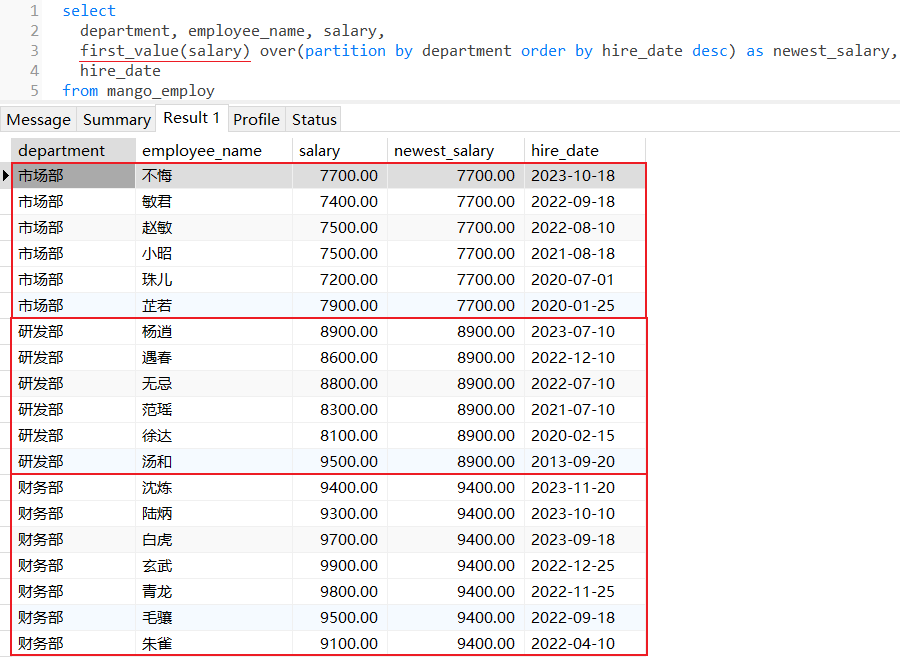
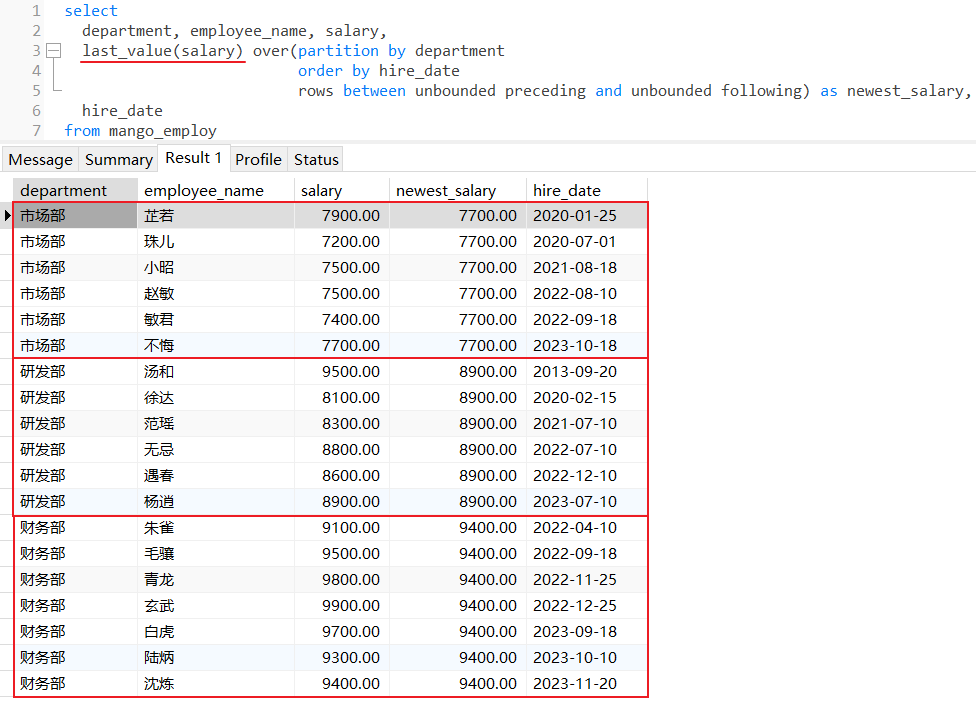
4.4 last_value()
查询各个部门下员工薪资和最新入职员工薪资比较:
4.5 nth_value()