一般都是根据菜品找食材,比方说我先想到做个小鸡炖蘑菇,下一步才去买蘑菇。
做研究也是如此,根据需求去找相关的数据。
今天不一样,我先发现了一个有意思的数据,后面想着如何去研究它。
有一个数据集叫ModelNet,里面是3d模型。比如ModelNet10是10个类别。
我们打开椅子类别中的一个文件,看看它长什么样子。
ini
import trimesh
file_path = "ModelNet10\chair\train\chair_0001.off"
mesh = trimesh.load_mesh(file_path)
points = mesh.vertices
points提示:严格来说.off是三维网格模型,为了简化,我们只看顶点坐标,暂且叫"点云"。
椅子的点云数据
里面是大量的点云数据。它是一个二维数组,有844个点,每个点有3个坐标。
ini
([[ -9.6995 , 0.06625 , -1.575088],
[ -9.6965 , -8.83705 , -18.008024],
[ -9.6995 , -9.05255 , -17.887559],
...,
[ -9.1335 , 6.38525 , -13.005878],
[ -9.1335 , 6.80925 , -12.881839],
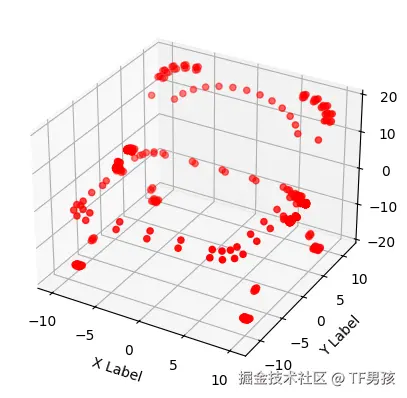
[ 9.3055 , 6.80925 , -12.881839]], shape=(844, 3))我们把这些点云数据可视化一下。
ini
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(points[:, 0], points[:, 1], points[:, 2], c='r', marker='o')
ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
ax.set_zlabel('Z Label')
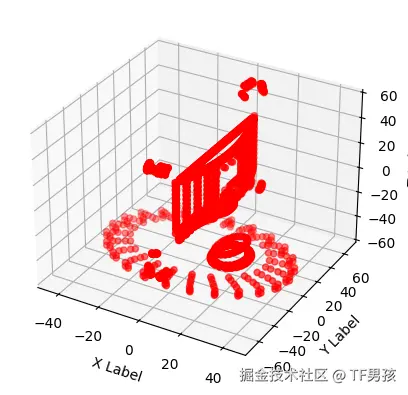
plt.show()发现这些点构成了一个椅子的形状。
如果觉得不直观,我们可以利用trimesh构建它的3D效果。
ini
mesh = trimesh.load_mesh("chair_0001.off")
mesh.show()
ModelNet10是10个类别,还有个ModelNet40是40个类别:
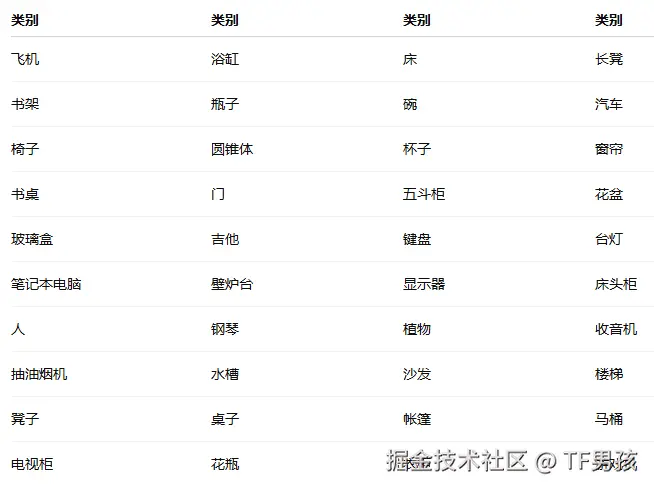

所以我说它很有意思。因此,想去研究它们的特征以及预测方式。
再回到数据,他们都是点云数据,一系列的点,每个点有x,y,z三个方向的坐标。
在2D图像中,我们已经可以通过关键点检测来分析人体姿态。

2D数据特征的提取和预测,已经非常成熟了。而在3D点云中,信息更多,建模也更复杂。
我们可以清楚地看到下面是一个椅子。

同样,如果我们变换视角,下面这些也是椅子。

不管是它摆放不同,还是你观察角度不同,都会导致它有好多种形态。而每种形态对应的点云数据,也是不同的。
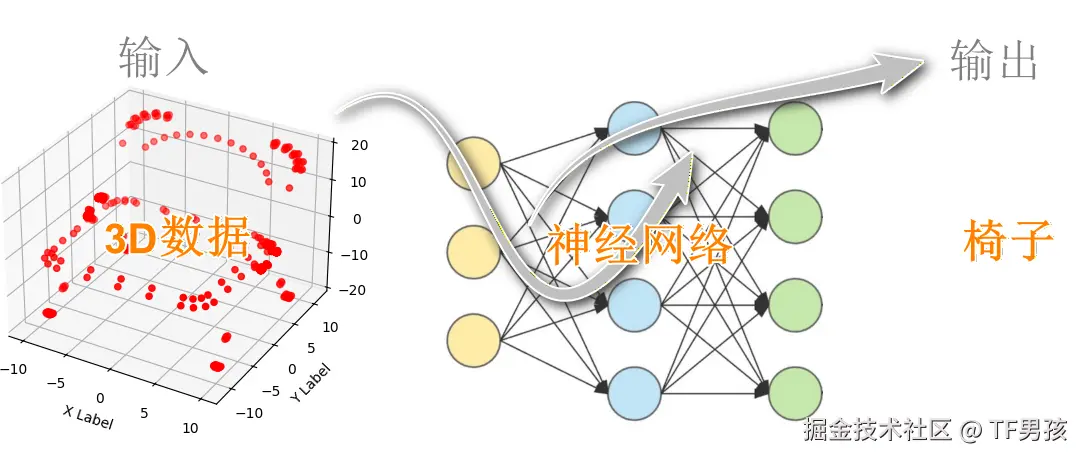
因此训练ModelNet的点云数据,让它根据一系列3D点坐标判断是什么物体,挺有意思。
我们首先想到构建一个神经网络,输入是点云数据,输出是物体类别。
模型经过训练之后,可以识别不同的3D物体。
那么,这个神经网络该如何构建?
青铜:多层感知机MLP
python
import torch
import torch.nn as nn
class SimplePointNet(nn.Module):
def __init__(self):
super(SimplePointNet, self).__init__()
self.fc1 = nn.Linear(3, 64)
self.fc2 = nn.Linear(64, 128)
self.fc3 = nn.Linear(128, 256)
self.fc4 = nn.Linear(256, 10)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = torch.relu(self.fc3(x))
x = self.fc4(x)
return x它包含4个全连接层,每一步操作都是线性变换。
我们拿椅子的点云数据,看看它的前向传播过程。
回忆一下,椅子的点云数据形状是(844,3),表示是844个点,每个点有(x, y, z)3个坐标。
ini
([[ -9.6995 , 0.06625 , -1.575088],
...,
[ -9.1335 , 6.38525 , -13.005878],
[ 9.3055 , 6.80925 , -12.881839]], shape=(844, 3))
ini
# 输入: [N, 3]
x = torch.randn(844, 3)
# 前向传播过程:
x = torch.relu(self.fc1(x)) # [844, 3] -> [844, 64]
x = torch.relu(self.fc2(x)) # [844, 64] -> [844, 128]
x = torch.relu(self.fc3(x)) # [844, 128] -> [844, 256]
x = self.fc4(x) # [844, 256] -> [844, 10]
# 输出: [844, 10]首先将这844个点,输入到第一个全连接层fc1中。每个点都与64个权重相乘,得到64个输出。
这一步就像是有64个评委,对每一个点都进行打分。于是得到(844, 64),表示有844的点,每个点包含了64个特征(评委的打分)。
后面以此类推,不断加入专家。第二层fc2,有128个专家,第三层fc3,有256个专家。
最后,开始决赛了,将844个点的特征,输入到分类层fc4中。每个点都与10个权重相乘,得到10个输出。这一步就像10个Boss最终选人。其中某个点的数据格式如下:
css
[-0.2, 1.5, 0.3, -0.8, 0.9, -0.1, 2.1, -0.5, 0.7, 1.2]这结构就类似:浴缸 -0.2 不是我;床 1.5 是我;椅子 0.3 有点像;......
于是,经过最终投票统计,这批点云数据被判断为是床。
提示:实际上,要得到物体的类别,还需要再加一步聚合(从844, 10到10),这里为了讲原理先略过。
这结构就像一个投票系统,每个点都有评委打分的一个权重。最后,根据这些权重,得到一个最终的判断结果。
这是一个基础的多层感知机(Multi-Layer Perceptron),是最基础的前馈神经网络。
看似能实现了从(N, 3)到(N, 10)的分类结果,其实是在对每个点进行分类。它不考虑点云的整体结构。因此它有局限性,无法利用点云的全局信息(比如椅子的整体形状)。
因此,它基本就是教学使用,让我们了解神经网络的基本原理。
神经网络其实就是流水线步骤,就好比原料经过几步加工成产品。

比如生产包子,输入是面粉、馅料,输出是包子。那么,用手可以,用机器也可以。用机器的话,一次包一个可以,卷成肉条再批量切割也可以。因此,它不是唯一的,有各种方式方法。
我们看看其他的神经网络,比如PointNet。
白银:PointNet系列
如果你想优先保证成功并理解3D深度学习核心思想,PointNet(一种经典结构)是一个不错的选择。
下面的例子,不是PointNet的完整实现,只是一个比MLP进步一些,同时又接近PointNet的模型。
python
import torch.nn as nn
class PointClassifier(nn.Module):
def __init__(self):
super().__init__()
self.point_mlp = nn.Sequential(
nn.Linear(3, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
)
self.classifier = nn.Sequential(
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 10)
)
def forward(self, x):
# x: (B, N, 3)
x = self.point_mlp(x) # (B, N, 128)
x = x.max(dim=1)[0] # (B, 128) 池化
x = self.classifier(x) # (B, 10)
return x我们看看主要区别是什么?
输入变化了一些:上一个是(N, 3),现在是(B, N, 3)。B是batch size,N是点的数量,多了一个批次的概念,也就是处理一批点云。
传统MLP里,结构是一串全连接层构成的序列。看这个,它先通过MLP提取点的特征(point_mlp部分),然后用最大池化来聚合多个点的特征(x.max部分),最终用分类器进行分类(classifier部分)。
这套网络,采用了PointNet的中心思想,更适合处理点云数据的分类任务。
分类时,结构基本还是"评委打分"那一套。
less
self.classifier = nn.Sequential(
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 10)
)我们看到评委是128个,后来减少到64个,最后由10名终极Boss做最终分类。
但是前面这128个评委面对的不再是原始数据,而是经过MLP提取的特征。到他们这里,点云数据已经被"浓缩"成了128维的特征向量,而这些向量包含了点云的全局信息。
我们的PointClassifier已经接近PointNet的结构了。到PointNet++,又有新增的增强。
PointNet主要关注全局信息,可能忽视点云数据的局部结构(例如,椅子背和椅子腿存在角度)。因此,PointNet++通过引入类似于卷积神经网络(CNN)的感受野来捕捉局部特征。
反正是越加越复杂,越加越强大。然而,强大不是无限的,仍然有一定的局限性。
比如面对旋转和缩放,PointNet++虽然具有一定的鲁棒性(抗干扰+稳定性),但不是天然具备不变性。它的一些优化,只是让它不敏感,而非完全忽略。可能还需要靠数据增强来实现。
数据增强就是对原始数据进行一些变换,比如旋转、缩放、平移等,从而生成新的样本。也就是"拔一根毫毛变出猴万个"。
那么,后面还可以升级。但是升级不能在PointNet基础上进行了,得另起炉灶。
黄金:等变图神经网络EGNN
预测一个乱七八糟的椅子的点云数据。如果说之前的策略都是"嗯......你歪了,我来摆正你。哦,我知道啦,你是椅子!"。那么EGNN就是"只要相对关系没变,我还能认出来"。
EGNN,E(n)-Equivariant Graph Neural Network:图神经网络中对"边"进行条件化处理。它的设计适合于各种需要处理边关系的任务,尤其在点云、化学分子结构等领域表现突出。
而且,它也可能适用于社交网络分析。因为社交网络中的节点代表用户,边代表用户之间的关系,边的权重(如交互频率)可能对用户行为预测有用。
看下面的代码。
python
import torch
import torch.nn as nn
class EdgeMLP(nn.Module):
def __init__(self, node_dim, hidden_dim):
super().__init__()
self.mlp = nn.Sequential(
nn.Linear(2 * node_dim + 1, hidden_dim),
nn.SiLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.SiLU()
)
def forward(self, h_i, h_j, dist2):
# h_i, h_j: [E, node_dim]
# dist2: [E, 1]
return self.mlp(torch.cat([h_i, h_j, dist2], dim=-1))就像两个人在打电话:h_i:
- 第一个人的特征(比如:我是椅子腿)。
h_j:第二个人的特征(比如:我是椅子背)。dist2:我们之间的距离(比如:1.5)。
这里只用到距离,不用方向!
ini
# 计算两个节点之间的距离平方
dist2 = ((x_i - x_j) ** 2).sum(dim=-1, keepdim=True)旋转时,会产生各式各样的数据,x₁−x₂、y₁−y₂都会变。不管怎么旋转、平移,只要两点之间的相对距离不变,这个数就不变。之前咱们老说,谁谁本身不天然具备旋转不变。但是,当边特征只依赖于距离这样的不变量时,模型在这一信息通路上具备了天然的旋转、平移不变性。
EGNN 不是"我天生就不变",而是"我允许你很自然地把不变性放进来" 。
在EGNN之后,人们进一步发展出了等变性的SE(3)-EGNN。所谓等变性,就是随着椅子的数据变换,预测值也随着物理规律而变换。
比如,如果椅子整体旋转x度,模型也跟着输出"受力方向和大小随之旋转x度" 。
那位朋友说,嗐,你这个不就是基础的回归问题吗?输入x改变,输出y根据某个函数f计算也改变:y = f(x)。
朋友,还真不一样。
传统回归需要大量数据训练,比如预测受力情况,你得先把各个角度的输入以及输出交给模型学习。
但是等变性模型却是这样:f(g·x)=g·f(x)。模型结构本身就只允许满足这个公式的函数存在。
再通俗一点,传统回归说:我猜......这个输入对应这个输出。
它的潜台词是:靠运气、需要大数据、换一个场景就失效。
等变回归的潜台词:力是一个向量,它就应该跟着几何一起转。
等变网络不是教孩子"看很多椅子,记住它们的反应",而是"椅子旋转了,本质没变,力也该一起转"。
它不是预测,是"模型天然符合物理"。因为物理世界满足对称性、守恒律、坐标无关性。等变回归通过将物理或几何规律引入,实现了预测一致性(每次都一样)、泛化能力(哪里都适用)。
当然,它也不是万能的,也有适用场景:
- 数据稀缺:训练数据成本高(安全生产),样本量有限(自然灾害)。
- 分布外泛化:组合方式太多,测试时都很难遇到一些场景。
- 高维几何:复杂多变的空间结构,几何变量描述。
总结
好了,我的这套研究就结束了。这才到了黄金,后面还有铂金、钻石啥的,我相信他们会出现的。
我们看到,技术的发展超乎我们的想象,很少是"增量升级",多是颠覆性的"另起炉灶" 。而解决问题的方法也并非唯一,他们成本不同,适用场景不同,效果也不同。
我是TF男孩:专业实用化,永远不做大。