前言
在之前的文章中我们使用 SpringBoot 配合 DeepSeek 构建了一个拥有聊天记忆的问答机器人,如果没有看过的可以翻下我之前的帖子。这次构建企业知识库将基于之前的内容来添砖加瓦。
构建知识库
在开始之前,我们需要了解 2 个概念:向量数据库 和检索增强生成(RAG)
- **向量数据库:**顾名思义,存储向量的数据库。什么是向量?可以简单理解为,文本、图片、视频等数据在空间中的坐标,语义相似的词在向量空间中距离更近,AI 根据距离来判断相似度。
- **检索增强生成(RAG):**当需要将用户查询发送到 AI 模型时,首先检索一组相似的文档。这些文档随后作为用户问题的上下文,与用户查询一起发送给 AI 模型。这种技术被称为检索增强生成(RAG)。
添加依赖
之前我们是直接使用的 DeepSeek 的依赖包,但是由于在硅基流动中没找到 DeepSeek 的嵌入模型,这里使用的千问的嵌入模型, Open AI 都能兼容。
xml
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-rag</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.1.2</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>配置嵌入模型
为什么要配置嵌入模型?
前面提到 AI 通过向量可以判断相似度,而嵌入模型就是用于生成向量。嵌入模型可以到硅基流动搜索 Embedding 关键字,这里就直接使用的千问模型。
yml
spring:
ai:
openai:
api-key: xxxx
base-url: https://api.siliconflow.cn
embedding:
options:
model: Qwen/Qwen3-Embedding-0.6B
chat:
options:
model: deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
temperature: 0.7聊天客户端配置
之前是直接在控制器中使用构造器的方式进行注入:
java
@RestController
@RequestMapping("/chat")
public class ChatBotController {
private final ChatClient chatClient;
public ChatBotController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
}现在我们直接抽取成配置。
java
@Configuration
public class ChatConfig {
@Bean
public ChatClient chatClient(ChatModel chatModel, EmbeddingModel embeddingModel, ChatMemory chatMemory) {
return ChatClient.builder(chatModel)
.defaultSystem("你是一个客服人员,针对用户的问题总是能以友好愉悦的方式去进行交流,希望带给客户很好的体验。")
.defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
.defaultAdvisors(VectorStoreChatMemoryAdvisor.builder(SimpleVectorStore.builder(embeddingModel).build()).build())
.build();
}
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();
}
}我们可以看到 ChatClient 的 bean 配置了 defaultSystem和 defaultAdvisors,defaultSystem用来生成默认的提示词,这里我给了个提示让它作为一名客服人员去回答问题。defaultAdvisors则是添加顾问,可以理解为一种拦截器,在请求 AI 前的一些操作,这里告诉 AI 使用内存作为记忆,并且使用内存作为向量数据库。
当然,实际企业不会直接使用内存作为记忆和向量数据库,我们可以直接基于自身的项目的架构选择合适的向量数据库和记忆会话历史。比如使用 mysql 存储会话历史,使用 redis-stack 做为向量数据库都是不错的选择。
到目前为止已经解决了之前思考问题:"我们怎么给 AI 预置一个角色?比如让它作为一个智能客服或者作为一个营养师。"
添加知识库
这里为了方便,直接使用了 PostConstruct模拟了知识库初始化,真实数据可以从数据库中获取,使用 CommandLineRunner接口加载数据。
java
@Autowired
private VectorStore vectorStore;
@PostConstruct
public void loadStore() {
List<Document> documents = List.of(
new Document("lanjii是开箱即用的 RBAC 权限管理系统。后端基于 Spring Boot3 构建, 集成了 JWT 认证、Spring Security 6、MyBatis-Plus\u200B 和 WebSocket\u200B 等核心技术。前端使用了 Vue3 +Vite + Element Plus + Pinia 构建。它是一个简洁、高效、无过多依赖的项目,支持按钮级别的权限控制,使用简单,开箱即用。")
);
vectorStore.add(documents);
}挂载知识库
在聊天客户端中直接添加 QuestionAnswerAdvisor就可以让我们在问 AI 时先从知识库中获取数据,然后经过 AI 整合后回答我们。
java
@RestController
@RequestMapping("/chat")
public class ChatBotController_demo {
@Autowired
private ChatClient chatClient;
@Autowired
private VectorStore vectorStore;
@PostConstruct
public void loadStore() {
List<Document> documents = List.of(
new Document("lanjii是开箱即用的 RBAC 权限管理系统。后端基于 Spring Boot3 构建, 集成了 JWT 认证、Spring Security 6、MyBatis-Plus\u200B 和 WebSocket\u200B 等核心技术。前端使用了 Vue3 +Vite + Element Plus + Pinia 构建。它是一个简洁、高效、无过多依赖的项目,支持按钮级别的权限控制,使用简单,开箱即用。")
);
vectorStore.add(documents);
}
@GetMapping(value = "/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> chatStream(String message, String conversationId) {
return chatClient.prompt()
.advisors(
a -> a.param(ChatMemory.CONVERSATION_ID, conversationId)
)
.advisors(QuestionAnswerAdvisor.builder(vectorStore).build())
.user(message)
.stream()
.content();
}
}不知大家有没有注意到这里使用到了 ChatMemory.CONVERSATION_ID,这是将聊天数据的上下文进行关联。上篇文章留下的思考中:如果用户 A 和用户 B 同时对 AI 进行对话,怎么让对话进行隔离?这里直接让不同的会话使用不同的 conversationId 即可。
至此,一个简单的知识库就构建好了,看下效果吧: 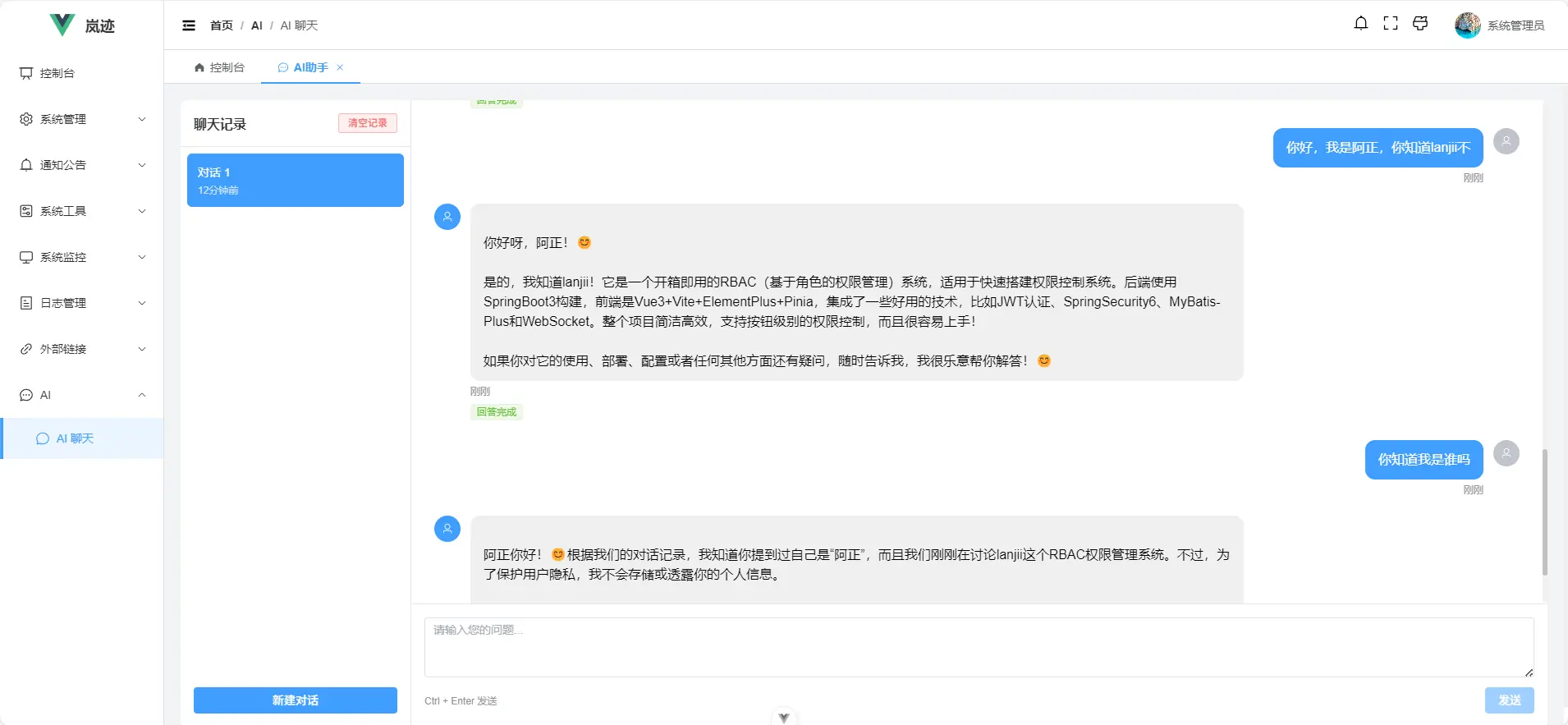
更可以达到这样的效果: 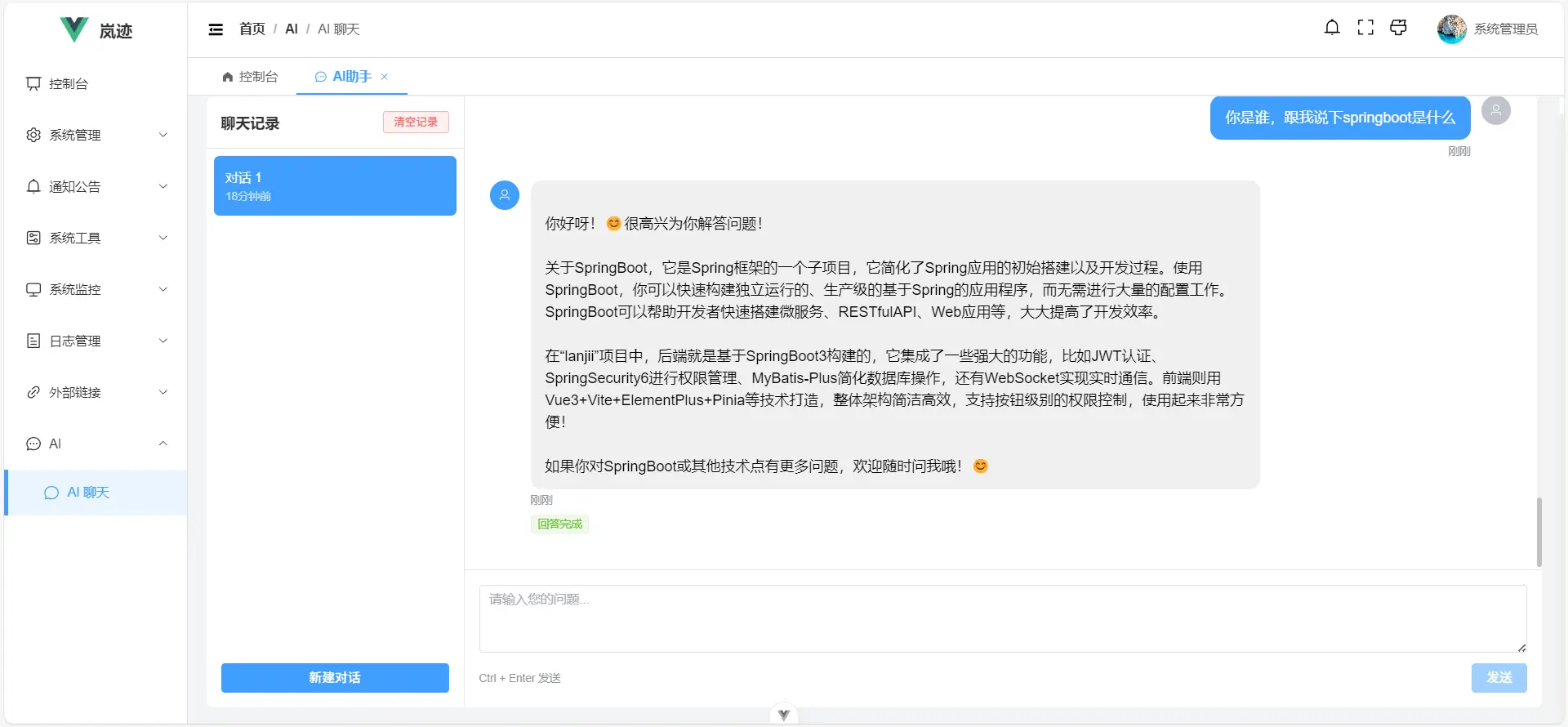
这样一个即有记忆功能,又能对话隔离,并且能直接关联知识库的问答系统就构建好了。
思考
又到了思考环节,按理说 AI 的场景运用到这里已经结束了,但是!!!
- 如果通过对话直接让 AI 跟我们完成业务操作,比如跟我下单,或者说取消机票?
完整代码
后续我会整理后将代码放在 Gitee:lanjii: 开箱即用的 RBAC 权限管理系统。后端基于 Spring Boot3 构建, 集成了 JWT 认证、Spring Security 6、MyBatis-Plus
这是一款 MIT 协议可商用的 SpringBoot 脚手架,拥有完整的权限控制和常用的基础功能。希望大家给个 Star,后面有新的功能和一些 BUG 的修复也会提交到 Gitee。 
小结
没得小结~~~