周志华《机器学习---西瓜书》八
八、集成学习
以下是按顺序整理的内容:
1. 集成学习
- 定义:使用多个学习器协同解决问题的方法("多个模型融合")。
- 实践表现:近十年KDDCup、Kaggle等竞赛的获胜方案几乎都用到了集成技术,是实战中提升模型性能的关键方法之一。

2.好而不同
如何得到好的集成
-
核心原则:令个体学习器 "好而不同" 。
- "好":个体学习器的性能不能太差(如准确率高于随机猜测);
- "不同":个体学习器之间要有差异性(预测结果不完全一致)。
-
示例验证:
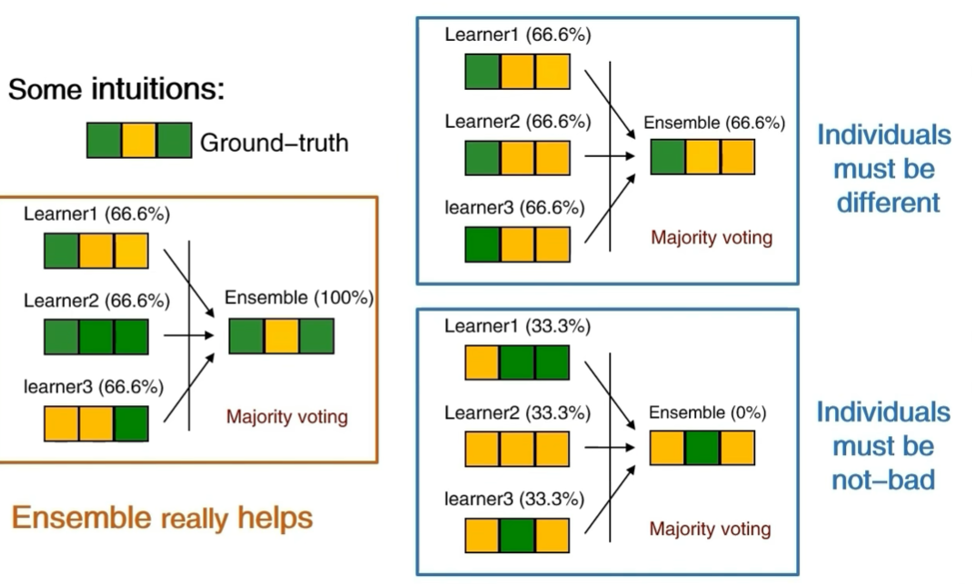
- 当个体学习器"好且不同"时,集成性能会远高于单个学习器;
- 若个体学习器"差"或"无差异",集成性能会很差甚至失效。
多样性是关键(误差-分歧分解)
-
理论分解:集成误差 E=Eˉ−AˉE = \bar{E} - \bar{A}E=Eˉ−Aˉ,其中:
- Eˉ\bar{E}Eˉ:个体学习器的平均误差;
- Aˉ\bar{A}Aˉ:个体学习器的平均"分歧"(即多样性)。
-
结论:个体学习器越准确、多样性越高,集成性能越好。
-
局限:"分歧"缺乏可操作的定义,且该分解仅适用于回归任务的平方损失场景。
3. 成功的集成学习方法分类
- 序列化方法 (个体学习器按顺序训练,后一个学习器依赖前一个):
代表:AdaBoost、GradientBoost、LPBoost等。 - 并行化方法 (个体学习器独立训练):
代表:Bagging、Random Forest、Random Subspace等。
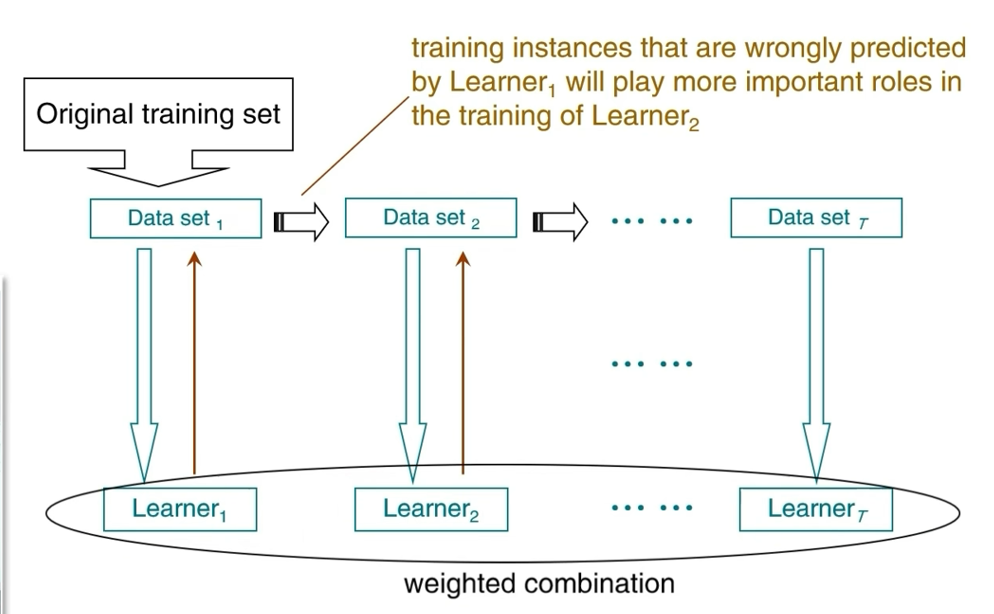
4. Boosting流程
-
核心思路:逐步调整数据集权重,让前一个学习器预测错误的样本在后续训练中获得更高权重,最终通过"加权组合"整合所有学习器。
-
流程:
- 从原始数据集生成初始子数据集,训练第一个学习器;
- 根据第一个学习器的预测结果,增加错误样本的权重,生成新的子数据集,训练第二个学习器;
- 重复上述步骤,得到多个学习器;
- 对所有学习器的输出进行加权组合,得到最终结果。
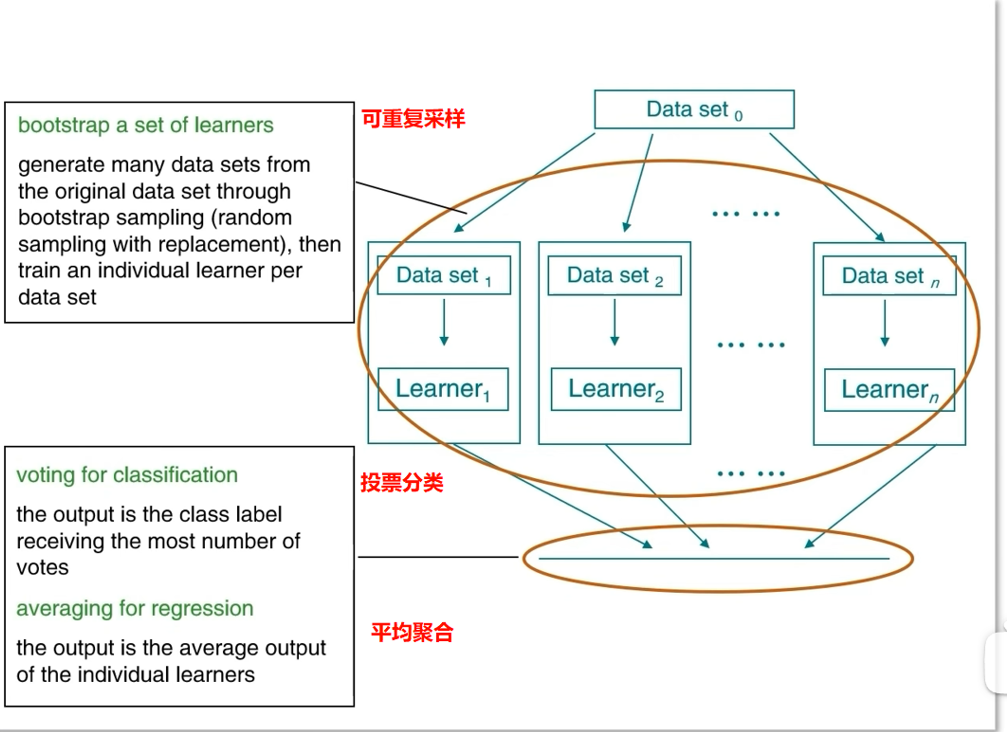
5. Bagging
-
核心思路:通过可重复采样(Bootstrap) 生成多个数据集,每个数据集训练一个个体学习器,最终通过"投票(分类)"或"平均(回归)"聚合结果。
-
流程:
- 从原始数据集通过Bootstrap采样(有放回随机采样)生成多个子数据集;
- 每个子数据集训练一个个体学习器;
- 分类任务:选择得票最多的类别;回归任务:取个体学习器的输出平均值。