4、表模型
https://doris.apache.org/zh-CN/docs/table-design/data-model/overview
在 Doris 中建表时需要指定表模型,以定义数据存储与管理方式。在 Doris 中提供了明细模型、聚合模型以及主键模型三种表模型,可以应对不同的应用场景需求。不同的表模型具有相应的数据去重、聚合及更新机制。选择合适的表模型有助于实现业务目标,同时保证数据处理的灵活性和高效性。
表模型分类
在 Doris 中支持三种表模型:
- 明细模型(Duplicate Key Model):允许指定的Key 列重复,Doirs 存储层保留所有写入的数据,适用于必须保留所有原始数据记录的情况;
- 主键模型(Unique Key Model):每一行的 Key 值唯一 ,可确保给定的 Key 列不会存在重复行,Doris 存储层对每个 key 只保留最新写入的数据,适用于数据更新的情况;
- 聚合模型(Aggregate Key Model):可根据 Key 列聚合数据,Doris 存储层保留聚合后的数据,从而可以减少存储空间和提升查询性能;通常用于需要汇总或聚合信息(如总数或平均值)的情况。
在建表后,表模型的属性已经确认,无法修改。针对业务选择合适的模型至关重要:
- Duplicate Key:适合任意维度的 Ad-hoc 查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)。
- Unique Key:针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用 ROLLUP 等预聚合带来的查询优势。
- Aggregate Key :可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对
count(*)查询很不友好。同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
排序键
在 Doris 中,数据以列的形式存储,一张表可以分为 key 列与 value 列。其中,key 列用于分组与排序,value 列用于参与聚合。Key 列可以是一个或多个字段,在建表时,按照各种表模型中,Aggregate Key、Unique Key 和 Duplicate Key 的列进行数据排序存储。
不同的表模型都需要在建表时指定 Key 列,分别有不同的意义:对于 Duplicate Key 模型,Key 列表示排序,没有唯一键的约束。在 Aggregate Key 与 Unique Key 模型中,会基于 Key 列进行聚合,Key 列既有排序的能力,又有唯一键的约束。
选择排序键时,可以遵循以下建议:
- Key 列必须在所有 Value 列之前。
- 尽量选择整型类型。因为整型类型的计算和查找效率远高于字符串。
- 对于不同长度的整型类型的选择原则,遵循够用即可。
- 对于
VARCHAR和STRING类型的长度,遵循够用即可原则
明细模型
明细模型是 Doris 中的默认建表模型 ,用于保存每条原始数据记录。在建表时,通过 DUPLICATE KEY 指定数据存储的排序列,以优化常用查询。一般建议选择三列或更少的列作为排序键,具体选择方式参考排序键。
使用场景
一般明细模型中的数据只进行追加,旧数据不会更新。明细模型适用于需要存储全量原始数据的场景:
- 日志存储
- 用户行为数据
- 交易数据
建表说明
在建表时,可以通过 DUPLICATE KEY 关键字指定明细模型。明细表必须指定数据的 Key 列 ,用于在存储时对数据进行排序。下例的明细表中存储了日志信息,并针对于 log_time、log_type 及 error_code 三列进行了排序:
CREATE TABLE IF NOT EXISTS example_tbl_duplicate
(
log_time DATETIME NOT NULL,
log_type INT NOT NULL,
error_code INT,
error_msg VARCHAR(1024),
op_id BIGINT,
op_time DATETIME
)
DUPLICATE KEY(log_time, log_type, error_code)
DISTRIBUTED BY HASH(log_type) BUCKETS 10;数据插入与存储
在明细表中,数据不进行去重与聚合,插入数据即存储数据。明细模型中Key 列只作为排序。
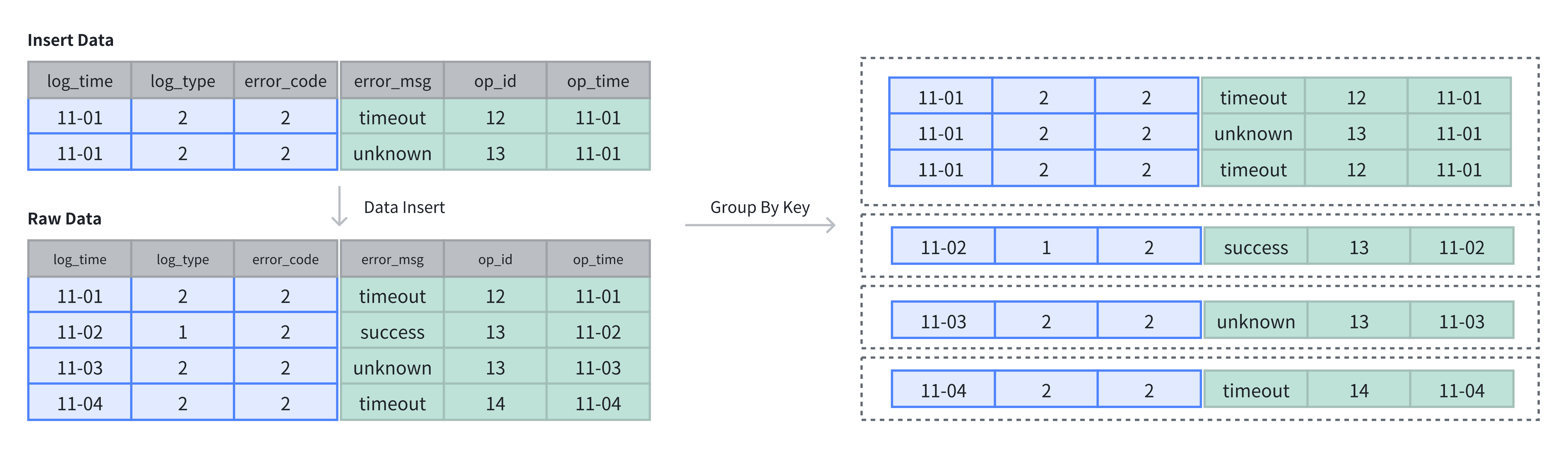
在上例中,表中原有 4 行数据,插入 2 行数据后,采用追加(APPEND)方式存储,共计 6 行数据:
-- 4 rows raw data
INSERT INTO example_tbl_duplicate VALUES
('2024-11-01 00:00:00', 2, 2, 'timeout', 12, '2024-11-01 01:00:00'),
('2024-11-02 00:00:00', 1, 2, 'success', 13, '2024-11-02 01:00:00'),
('2024-11-03 00:00:00', 2, 2, 'unknown', 13, '2024-11-03 01:00:00'),
('2024-11-04 00:00:00', 2, 2, 'unknown', 12, '2024-11-04 01:00:00');
-- insert into 2 rows
INSERT INTO example_tbl_duplicate VALUES
('2024-11-01 00:00:00', 2, 2, 'timeout', 12, '2024-11-01 01:00:00'),
('2024-11-01 00:00:00', 2, 2, 'unknown', 13, '2024-11-01 01:00:00');
-- check the rows of table
SELECT * FROM example_tbl_duplicate;
+---------------------+----------+------------+-----------+-------+---------------------+
| log_time | log_type | error_code | error_msg | op_id | op_time |
+---------------------+----------+------------+-----------+-------+---------------------+
| 2024-11-02 00:00:00 | 1 | 2 | success | 13 | 2024-11-02 01:00:00 |
| 2024-11-01 00:00:00 | 2 | 2 | timeout | 12 | 2024-11-01 01:00:00 |
| 2024-11-03 00:00:00 | 2 | 2 | unknown | 13 | 2024-11-03 01:00:00 |
| 2024-11-04 00:00:00 | 2 | 2 | unknown | 12 | 2024-11-04 01:00:00 |
| 2024-11-01 00:00:00 | 2 | 2 | unknown | 13 | 2024-11-01 01:00:00 |
| 2024-11-01 00:00:00 | 2 | 2 | timeout | 12 | 2024-11-01 01:00:00 |
+---------------------+----------+------------+-----------+-------+----------------------主键模型
当需要更新数据时,可以选择主键模型(Unique Key Model)。该模型保证 Key 列的唯一性,插入或更新数据时,新数据会覆盖具有相同 Key 的旧数据,确保数据记录为最新。与其他数据模型相比,主键模型适用于数据的更新场景,在插入过程中进行主键级别的更新覆盖。
主键模型有以下特点:
- 基于主键进行 UPSERT(update insert):在插入数据时,主键重复的数据会更新,主键不存在的记录会插入;
- 基于主键进行去重:主键模型中的 Key 列具有唯一性,会对根据主键列对数据进行去重操作;
- 高频数据更新:支持高频数据更新场景,同时平衡数据更新性能与查询性能。
实现方式
在 Doris 中主键模型有两种实现方式:
- 写时合并(merge-on-write):自 1.2 版本起,Doris 默认使用写时合并模式,数据在写入时立即合并相同 Key 的记录,确保存储的始终是最新数据。写时合并兼顾查询和写入性能,避免多个版本的数据合并,大多数场景推荐使用此模式;
- 读时合并(merge-on-read):在 1.2 版本前,Doris 中的主键模型默认使用读时合并模式,数据在写入时并不进行合并,以增量的方式被追加存储,在 Doris 内保留多个版本。查询 时,会对数据进行相同 Key 的版本合并。读时合并适合写多读少的场景,在查询是需要进行多个版本合并。
在 Doris 中基于主键模型更新有两种语义:
- 整行更新 :Unique Key 模型默认的更新语义为整行
UPSERT,即 UPDATE OR INSERT,该行数据的 Key 如果存在,则进行更新,如果不存在,则进行新数据插入。 - 部分列更新:如果用户希望更新部分字段,需要使用写时合并实现,并通过特定的参数来开启部分列更新的支持。
写时合并
在建表时,使用 UNIQUE KEY 关键字可以指定主键表。通过显示开启 enable_unique_key_merge_on_write 属性可以指定写时合并模式。自 Doris 2.1 版本以后,默认开启写时合并:
CREATE TABLE IF NOT EXISTS example_tbl_unique
(
user_id LARGEINT NOT NULL,
user_name VARCHAR(50) NOT NULL,
city VARCHAR(20),
age SMALLINT,
sex TINYINT
)
UNIQUE KEY(user_id, user_name)
DISTRIBUTED BY HASH(user_id) BUCKETS 10
PROPERTIES (
"enable_unique_key_merge_on_write" = "true"
);读时合并
在建表时,使用 UNIQUE KEY 关键字可以指定主键表。通过显示关闭 enable_unique_key_merge_on_write 属性可以指定读时合并模式。在 Doris 2.1 版本之前,默认开启读时合并:
CREATE TABLE IF NOT EXISTS example_tbl_unique
(
user_id LARGEINT NOT NULL,
username VARCHAR(50) NOT NULL,
city VARCHAR(20),
age SMALLINT,
sex TINYINT
)
UNIQUE KEY(user_id, username)
DISTRIBUTED BY HASH(user_id) BUCKETS 10
PROPERTIES (
"enable_unique_key_merge_on_write" = "false"
);数据插入与存储
在主键表中,Key 列不仅用于排序,还用于去重,插入数据时,相同 Key 的记录会被覆盖。
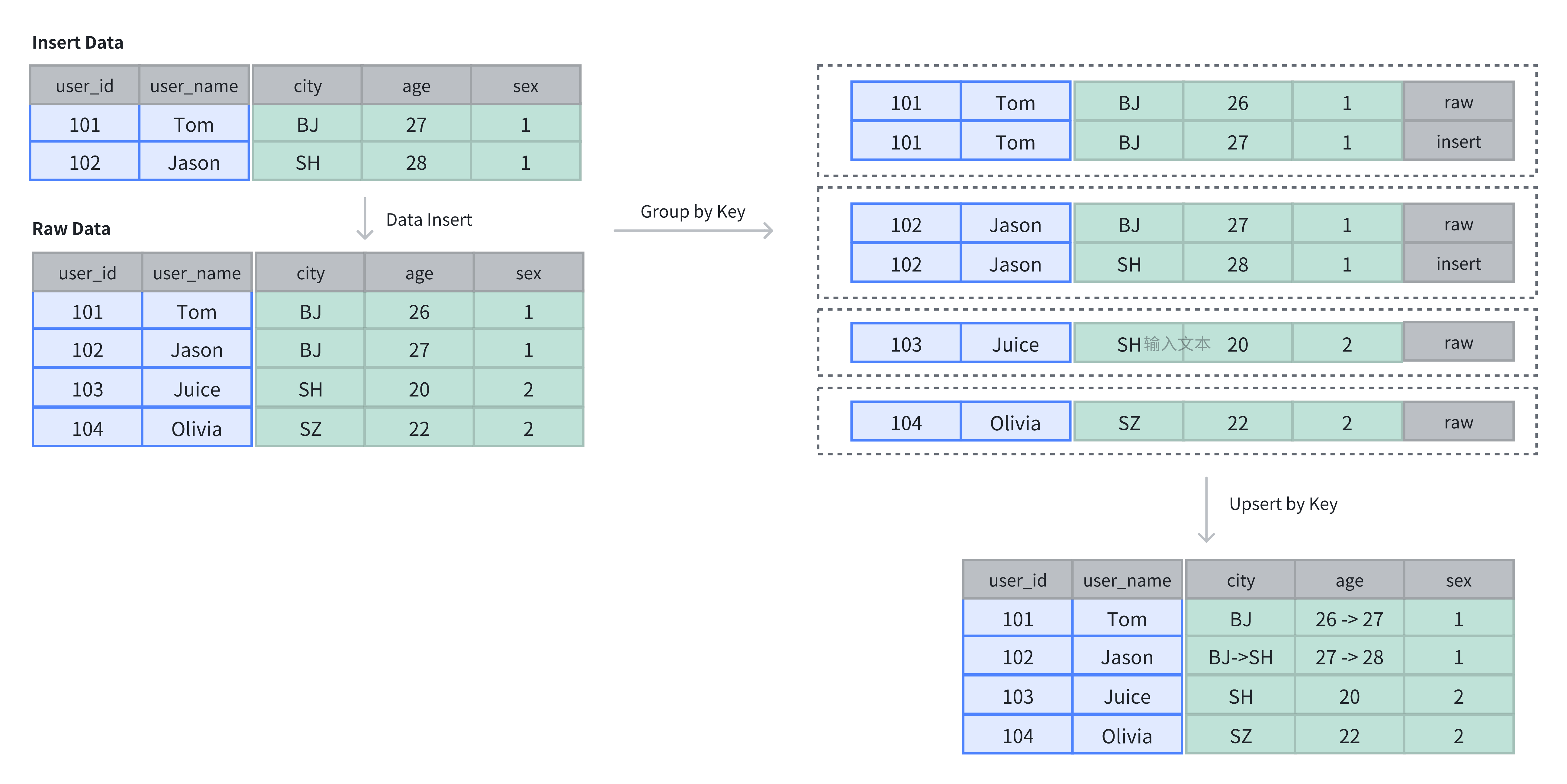
如上例所示,原表中有 4 行数据,插入 2 行后,新插入的数据基于主键进行了更新:
-- insert into raw data
INSERT INTO example_tbl_unique VALUES
(101, 'Tom', 'BJ', 26, 1),
(102, 'Jason', 'BJ', 27, 1),
(103, 'Juice', 'SH', 20, 2),
(104, 'Olivia', 'SZ', 22, 2);
-- insert into data to update by key
INSERT INTO example_tbl_unique VALUES
(101, 'Tom', 'BJ', 27, 1),
(102, 'Jason', 'SH', 28, 1);
-- check updated data
SELECT * FROM example_tbl_unique;
+---------+----------+------+------+------+
| user_id | username | city | age | sex |
+---------+----------+------+------+------+
| 101 | Tom | BJ | 27 | 1 |
| 102 | Jason | SH | 28 | 1 |
| 104 | Olivia | SZ | 22 | 2 |
| 103 | Juice | SH | 20 | 2 |
+---------+----------+------+------+------+注意事项
- Unique 表的实现方式只能在建表时确定,无法通过 schema change 进行修改;
- 在整行
UPSERT语义下,即使用户使用 insert into 指定部分列进行写入,Doris 也会在 Planner 中将未提供的列使用 NULL 值或者默认值进行填充; - 部分列更新。如果用户希望更新部分字段,需要使用写时合并实现,并通过特定的参数来开启部分列更新的支持。请查阅文档部分列更新获取相关使用建议;
- 使用 Unique 表时,为了保证数据的唯一性,分区键必须包含在 Key 列内。
聚合模型
Doris 的聚合模型专为高效处理大规模数据查询中的聚合操作设计。它通过预聚合数据,减少重复计算,提升查询性能。聚合模型只存储聚合后的数据,节省存储空间并加速查询。
使用场景
- 明细数据进行汇总:用于电商平台的月销售业绩、金融风控的客户交易总额、广告投放的点击量等业务场景中,进行多维度汇总;
- 不需要查询原始明细数据:如驾驶舱报表、用户交易行为分析等,原始数据存储在数据湖中,仅需存储汇总后的数据。
原理
每一次数据导入会在聚合模型内形成一个版本,在 Compaction 阶段进行版本合并,在查询时会按照主键进行数据聚合:
- 数据导入阶段:数据按批次导入,每批次生成一个版本,并对相同聚合键的数据进行初步聚合(如求和、计数);
- 后台文件合并阶段(Compaction):多个版本文件会定期合并,减少冗余并优化存储;
- 查询阶段:查询时,系统会聚合同一聚合键的数据,确保查询结果准确。
建表说明
使用 AGGREGATE KEY 关键字在建表时指定聚合模型,并指定 Key 列用于聚合 Value 列。
CREATE TABLE IF NOT EXISTS example_tbl_agg
(
user_id LARGEINT NOT NULL,
load_dt DATE NOT NULL,
city VARCHAR(20),
last_visit_dt DATETIME REPLACE DEFAULT "1970-01-01 00:00:00",
cost BIGINT SUM DEFAULT "0",
max_dwell INT MAX DEFAULT "0",
)
AGGREGATE KEY(user_id, load_dt, city)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;上例中定义了用户信息和访问行为表,将 user_id、load_date、city 及 age 作为 Key 列进行聚合。数据导入时,Key 列会聚合成一行,Value 列会按照指定的聚合类型进行维度聚合。
在聚合表中支持以下类型的维度聚合:
|---------------------|---------------------------------------|
| 聚合方式 | 描述 |
| SUM | 求和,多行的 Value 进行累加。 |
| REPLACE | 替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。 |
| MAX | 保留最大值。 |
| MIN | 保留最小值。 |
| REPLACE_IF_NOT_NULL | 非空值替换。与 REPLACE 的区别在于对 null 值,不做替换。 |
| HLL_UNION | HLL 类型的列的聚合方式,通过 HyperLogLog 算法聚合。 |
| BITMAP_UNION | BITMAP 类型的列的聚合方式,进行位图的并集聚合。 |
提示:
如果以上的聚合方式无法满足业务需求,可以选择使用 agg_state 类型。
数据插入与存储
在聚合表中,数据基于主键进行聚合操作。数据插入后及完成聚合操作。
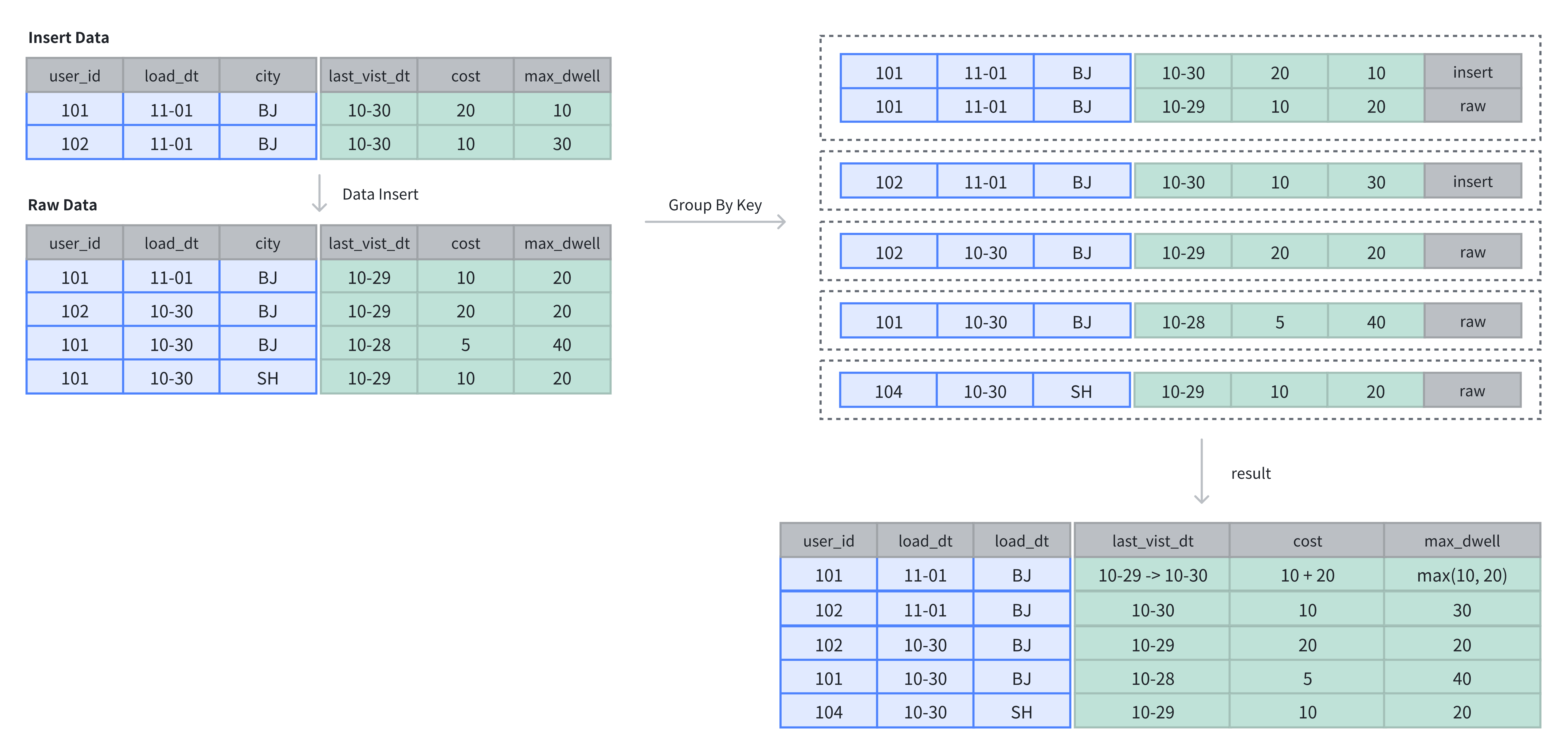
在上例中,表中原有 4 行数据,在插入 2 行数据后,基于 Key 列进行维度列的聚合操作:
-- 4 rows raw data
INSERT INTO example_tbl_agg VALUES
(101, '2024-11-01', 'BJ', '2024-10-29', 10, 20),
(102, '2024-10-30', 'BJ', '2024-10-29', 20, 20),
(101, '2024-10-30', 'BJ', '2024-10-28', 5, 40),
(101, '2024-10-30', 'SH', '2024-10-29', 10, 20);
-- insert into 2 rows
INSERT INTO example_tbl_agg VALUES
(101, '2024-11-01', 'BJ', '2024-10-30', 20, 10),
(102, '2024-11-01', 'BJ', '2024-10-30', 10, 30);
-- check the rows of table
SELECT * FROM example_tbl_agg;
+---------+------------+------+---------------------+------+----------------+
| user_id | load_date | city | last_visit_date | cost | max_dwell_time |
+---------+------------+------+---------------------+------+----------------+
| 102 | 2024-10-30 | BJ | 2024-10-29 00:00:00 | 20 | 20 |
| 102 | 2024-11-01 | BJ | 2024-10-30 00:00:00 | 10 | 30 |
| 101 | 2024-10-30 | BJ | 2024-10-28 00:00:00 | 5 | 40 |
| 101 | 2024-10-30 | SH | 2024-10-29 00:00:00 | 10 | 20 |
| 101 | 2024-11-01 | BJ | 2024-10-30 00:00:00 | 30 | 20 |
+---------+------------+------+---------------------+------+----------------+案例实操
Bitmap(位图)是一种使用位数组(bit array)来表示一组整数(通常是用户 ID、商品 ID 等离散值)是否存在的数据结构。
例如,如果我们要记录哪些用户访问了网站,可以用一个 Bitmap,其中:
- 每一个 bit 代表一个用户 ID(通常是经过编码后的整数,如 0, 1, 2, ...)
- 如果某位是 1,表示该用户存在(访问过/购买过等)
- 如果是 0,则表示不存在
假如我有一个位数组 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
user_id=1001 TO_BITMAP(1001) --> 下标 10 --> 0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0
user_id=1001 TO_BITMAP(1001) --> 下标 10 -->0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0
user_id=1002 TO_BITMAP(1002) --> 下标 11 -->0,0,0,0,0,0,0,0,0,0,1,1,0,0,0,0,0,0
将来根据bitmap_count 统计有多少个 1 就表示有几个用户。
-- 统计每天每个页面的pv和uv
-- pv: 一个页面的总访问次数就是pv
-- uv: 一个页面去重之后的访问用户数
CREATE TABLE `pv_bitmap` (
`dt` varchar(10) NULL COMMENT "",
`page` varchar(10) NULL COMMENT "",
`pv` BIGINT SUM DEFAULT "0",
`user_id` bitmap BITMAP_UNION NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`dt`, `page`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`dt`) BUCKETS 2
properties('replication_num' = '1');
bitmap可以理解为一维数组,里面要么是1,要么是0 [0,0,0,0,0,0,0,0,0....]
跟布隆过滤器有一定的关系。
INSERT INTO pv_bitmap VALUES
('2025-07-04','a.html',1,TO_BITMAP(101)),
('2025-07-04','a.html',1,TO_BITMAP(101)),
('2025-07-04','a.html',1,TO_BITMAP(102))
;
select * from pv_bitmap;
-- bitmap_count 统计bitmap中1的个数
select dt,page,pv,bitmap_count(user_id) from pv_bitmap;
4.数据的导入
Apache Doris 提供的数据导入方式可以分为四类:
- 实时写入:应用程序通过 HTTP 或者 JDBC 实时写入数据到 Doris 表中,适用于需要实时分析和查询的场景。
-
- 极少量数据(5 分钟一次)时可以使用 JDBC INSERT 写入数据。
- 吞吐较高时推荐使用 Stream Load 通过 HTTP 写入数据。
-
流式同步 :通过实时数据流(如 Flink、Kafka、事务数据库)将数据实时导入到 Doris 表中,适用于需要实时分析和查询的场景。
-
批量导入:将数据从外部存储系统(如对象存储、HDFS、本地文件、NAS)批量加载到 Doris 表中,适用于非实时数据导入的需求。
-
- 可以使用 Broker Load 将对象存储和 HDFS 中的文件写入到 Doris 中。
- 可以使用 INSERT INTO SELECT 将对象存储、HDFS 和 NAS 中的文件同步写入到 Doris 中,配合 JOB 可以异步写入。
- 可以使用 Stream Load 或者 Doris Streamloader 将本地文件写入 Doris 中。
- 外部数据源集成:通过与外部数据源(如 Hive、JDBC、Iceberg 等)的集成,实现对外部数据的查询和部分数据导入到 Doris 表中。
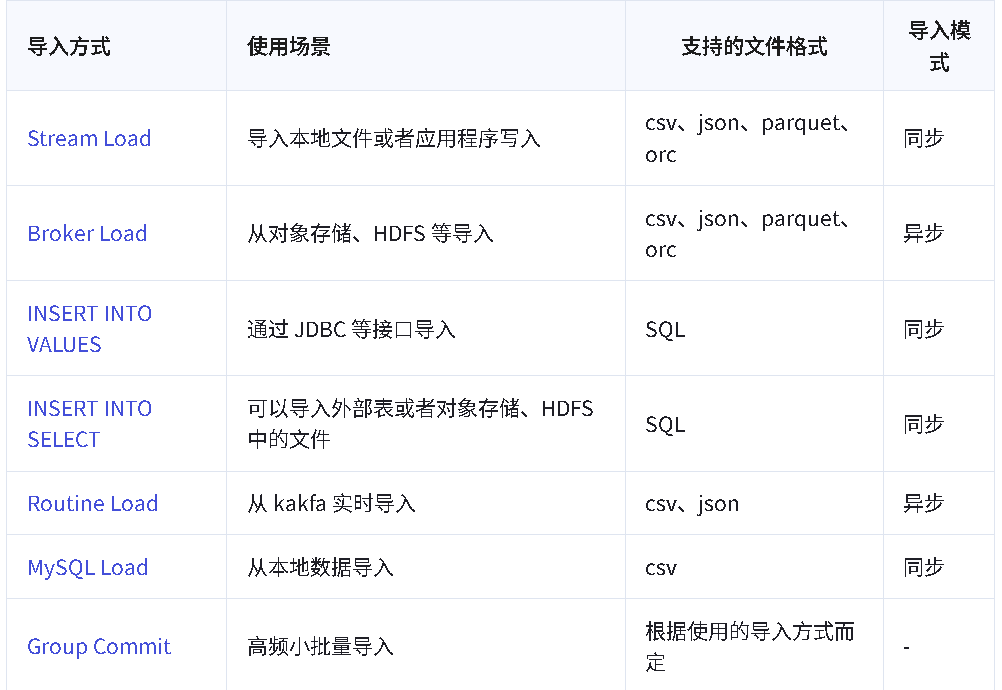
4.1 本地文件
Doris 提供多种方式从本地数据导入:
- Stream Load
Stream Load 是通过 HTTP 协议将本地文件或数据流导入到 Doris 中。Stream Load 是一个同步导入方式,执行导入后返回导入结果,可以通过请求的返回判断导入是否成功。支持导入 CSV、JSON、Parquet 与 ORC 格式的数据。更多文档参考stream load。
- streamloader
Streamloader 工具是一款用于将数据导入 Doris 数据库的专用客户端工具,底层基于 Stream Load 实现,可以提供多文件,多并发导入的功能,降低大数据量导入的耗时。更多文档参考Streamloader。
- MySQL Load
Doris 兼容 MySQL 协议,可以使用 MySQL 标准的 LOAD DATA 语法导入本地文件。MySQL Load 是一种同步导入方式,执行导入后即返回导入结果,主要适用于导入客户端本地 CSV 文件。更多文档参考MySQL Load。
使用 Stream Load 导入
第 1 步:准备数据
创建 CSV 文件 streamload_example.csv,内容如下:
cd /home
mkdir doris_data
1,Emily,25
2,Benjamin,35
3,Olivia,28
4,Alexander,60
5,Ava,17
6,William,69
7,Sophia,32
8,James,64
9,Emma,37
10,Liam,64第 2 步:在库中创建表
在 Doris 中创建表,语法如下:
CREATE TABLE testdb.test_streamload(
user_id BIGINT NOT NULL COMMENT "用户 ID",
name VARCHAR(20) COMMENT "用户姓名",
age INT COMMENT "用户年龄"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;第 3 步:使用 Stream Load 导入数据
使用 curl 提交 Stream Load 导入作业:
curl --location-trusted -u root:123456 \
-H "column_separator:," \
-H "columns:user_id,name,age" \
-T /home/doris_data/streamload_example.csv \
-XPUT http://bigdata01:8030/api/testdb/test_streamload/_stream_loadStream Load 是一种同步导入方式,导入结果会直接返回给用户。
{
"TxnId": 3,
"Label": "123",
"Comment": "",
"TwoPhaseCommit": "false",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 10,
"NumberLoadedRows": 10,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 118,
"LoadTimeMs": 173,
"BeginTxnTimeMs": 1,
"StreamLoadPutTimeMs": 70,
"ReadDataTimeMs": 2,
"WriteDataTimeMs": 48,
"CommitAndPublishTimeMs": 52
}第 4 步:检查导入数据
select count(*) from testdb.test_streamload;
+----------+
| count(*) |
+----------+
| 10 |
+----------+该方式中涉及 HOST:PORT 都是对应的HTTP 协议端口。
- BE 的 HTTP 协议端口,默认为 8040。
- FE 的 HTTP 协议端口,默认为 8030。
但须保证客户端所在机器网络能够联通FE, BE 所在机器。
curl的一些可配置的参数:
- label: 导入任务的标签,相同标签的数据无法多次导入。(标签默认保留30分钟)
- column_separator:用于指定导入文件中的列分隔符,默认为\t。
- line_delimiter:用于指定导入文件中的换行符,默认为\n。
- columns:用于指定文件中的列和table中列的对应关系,默认一一对应
例1: 表中有3个列"c1, c2, c3",源文件中的三个列一次对应的是"c3,c2,c1"; 那么需要指定-H "columns: c3, c2, c1"
例2: 表中有3个列"c1, c2, c3", 源文件中前三列依次对应,但是有多余1列;那么需要指定-H "columns: c1, c2, c3, xxx";最后一个列随意指定个名称占位即可
例3: 表中有3个列"year, month, day"三个列,源文件中只有一个时间列,为"2018-06-01 01:02:03"格式;那么可以指定
-H "columns: col, year = year(col), month=month(col), day=day(col)"完成导入
- where: 用来过滤导入文件中的数据
例1: 只导入大于k1列等于20180601的数据,那么可以在导入时候指定-H "where: k1 = 20180601"
- max_filter_ratio:最大容忍可过滤(数据不规范等原因)的数据比例。默认零容忍。数据不规范不包括通过 where 条件过滤掉的行。
- partitions: 用于指定这次导入所 涉及 的partition。如果用户能够确定数据对应的partition,推荐指定该项。不满足这些分区的数据将被过滤掉。
比如指定导入到p1, p2分区,
-H "partitions: p1, p2"
- timeout: 指定导入的超时时间。单位秒。默认是 600 秒。可设置范围为 1 秒 ~ 259200 秒。
- timezone: 指定本次导入所使用的时区。默认为东八区。该参数会影响所有导入涉及的和时区有关的函数结果
- exec_mem_limit: 导入内存限制。默认为 2GB。单位为字节。
- format: 指定导入数据格式,默认是csv,支持json格式。
- read_json_by_line: 布尔类型,为true表示支持每行读取一个json对象,默认值为false。
- merge_type: 数据的合并类型,一共支持三种类型APPEND、DELETE、MERGE 其中,APPEND是默认值,表示这批数据全部需要追加到现有数据中,DELETE 表示删除与这批数据key相同的所有行,MERGE 语义 需要与delete 条件联合使用,表示满足delete 条件的数据按照DELETE 语义处理其余的按照APPEND 语义处理, 示例:-H "merge_type: MERGE" -H "delete: flag=1"
- delete: 仅在 MERGE下有意义, 表示数据的删除条件 function_column.sequence_col: 只适用于UNIQUE_KEYS,相同key列下,保证value列按照source_sequence列进行REPLACE, source_sequence可以是数据源中的列,也可以是表结构中的一列。
导入建议
- Stream Load 只能导入本地文件。
- 建议一个导入请求的数据量控制在 1 - 2 GB 以内。如果有大量本地文件,可以分批并发提交。
使用 Streamloader 工具导入(略)
该工具不是 doris 自带的,需要现在源码,并编译,才能使用,源码地址:
https://github.com/apache/doris-streamloader
使用 stream loader 工具导入数据
doris-streamloader --source_file="/root/doris_data/streamloader_example.csv" --url="http://node01:8330" --header="column_separator:," --db="testdb" --table="test_streamloader"使用 MySQL Load 从本地数据导入
第 1 步:准备数据
创建名为 client_local.csv 的文件,样例数据如下:
1,10
2,20
3,30
4,40
5,50
6,60第 2 步:在库中创建表
在执行 LOAD DATA 命令前,需要先链接 mysql 客户端。记得使用命令的方式,datagrip 不行。
mysql --local-infile -h bigdata01 -P 9030 -u root -D testdb -p123456执行 MySQL Load,在连接时需要使用指定参数选项:
- 在链接 mysql 客户端时,必须使用
--local-infile选项,否则可能会报错。 - 通过 JDBC 链接,需要在 URL 中指定配置
allowLoadLocalInfile=true
在 Doris 中创建以下表:
CREATE TABLE testdb.t1 (
pk INT,
v1 INT SUM
) AGGREGATE KEY (pk)
DISTRIBUTED BY hash (pk);第 3 步:使用 Mysql Load 导入数据
链接 MySQL Client 后,创建导入作业,命令如下:
LOAD DATA LOCAL
INFILE '/home/doris_data/client_local.csv'
INTO TABLE testdb.t1
COLUMNS TERMINATED BY ','
LINES TERMINATED BY '\n';第 4 步:检查导入数据
MySQL Load 是一种同步的导入方式,导入后结果会在命令行中返回给用户。如果导入执行失败,会展示具体的报错信息。
如下是导入成功的结果显示,会返回导入的行数:
Query OK, 6 row affected (0.17 sec)
Records: 6 Deleted: 0 Skipped: 0 Warnings: 0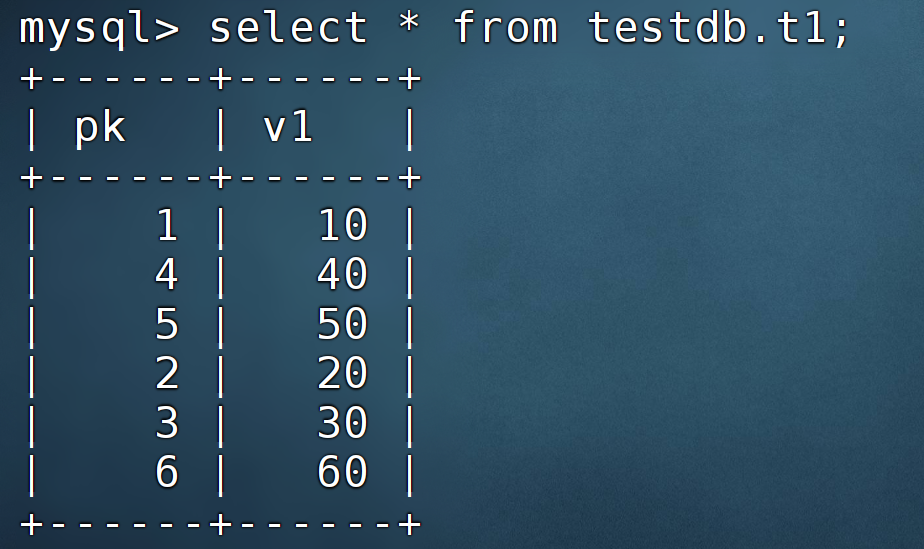
4.2 HDFS
Doris 提供两种方式从 HDFS 导入文件:
- 使用 HDFS Load 将 HDFS 文件导入到 Doris 中,这是一个异步的导入方式。
- 使用 TVF 将 HDFS 文件导入到 Doris 中,这是一个同步的导入方式。
使用 HDFS Load 导入
使用 HDFS Load 导入 HDFS 上的文件,详细步骤可以参考 Broker Load 手册
第 1 步:准备数据

hdfs dfs -put streamload_example.csv /home第 2 步:在 Doris 中创建表
CREATE TABLE test_hdfsload(
user_id BIGINT NOT NULL COMMENT "user id",
name VARCHAR(20) COMMENT "name",
age INT COMMENT "age"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;第 3 步:使用 HDFS Load 导入数据
LOAD LABEL hdfs_load_2025_12_19
(
DATA INFILE("hdfs://bigdata01:9820/home/streamload_example.csv")
INTO TABLE test_hdfsload
COLUMNS TERMINATED BY ","
FORMAT AS "CSV"
(user_id, name, age)
)
with HDFS
(
"fs.defaultFS" = "hdfs://bigdata01:9820",
"hadoop.username" = "root"
)
PROPERTIES
(
"timeout" = "3600"
);第 4 步:检查导入数据
SELECT * FROM test_hdfsload;结果:
mysql> select * from test_hdfsload;
+---------+-----------+------+
| user_id | name | age |
+---------+-----------+------+
| 5 | Ava | 17 |
| 10 | Liam | 64 |
| 7 | Sophia | 32 |
| 9 | Emma | 37 |
| 1 | Emily | 25 |
| 4 | Alexander | 60 |
| 2 | Benjamin | 35 |
| 3 | Olivia | 28 |
| 6 | William | 69 |
| 8 | James | 64 |
+---------+-----------+------+
10 rows in set (0.04 sec)Stream Load 用于将本地文件导入到doris中。Stream Load 是通过 HTTP 协议与 Doris 进行连接交互的。
语法 导入格式:
语法示例:
LOAD LABEL test.label_202204(
[MERGE|APPEND|DELETE] -- 不写就是append
DATA INFILE
(
"file_path1"[, file_path2, ...] -- 描述数据的路径 这边可以写多个 ,以逗号分割
)
[NEGATIVE] -- 负增长
INTO TABLE `table_name` -- 导入的表名字
[PARTITION (p1, p2, ...)] -- 导入到哪些分区,不符合这些分区的就会被过滤掉
[COLUMNS TERMINATED BY "column_separator"] -- 指定分隔符
[FORMAT AS "file_type"] -- 指定存储的文件类型
[(column_list)] -- 指定导入哪些列
[COLUMNS FROM PATH AS (c1, c2, ...)] -- 从路劲中抽取的部分列
[SET (column_mapping)] -- 对于列可以做一些映射,写一些函数
-- 这个参数要写在要写在set的后面
[PRECEDING FILTER predicate] -- 在mapping前做过滤做一些过滤
[WHERE predicate] -- 在mapping后做一些过滤 比如id>10
[DELETE ON expr] --根据字段去做一些抵消消除的策略 需要配合MERGE
[ORDER BY source_sequence] -- 导入数据的时候保证数据顺序
[PROPERTIES ("key1"="value1", ...)] -- 一些配置参数这是一个异步 的 操作,所以需要去查看下执行的状态.
show load order by createtime desc limit 1\G;
参数的说明
- load_label:导入任务的唯一 Label
- MERGE\|APPEND\|DELETE:数据合并类型。默认为 APPEND,表示本次导入是普通的追加写操作。MERGE 和 DELETE 类型仅适用于 Unique Key 模型表。其中 MERGE 类型需要配合 DELETE ON 语句使用,以标注 Delete Flag 列。而 DELETE 类型则表示本次导入的所有数据皆为删除数据
- DATA INFILE:被导入文件的路径,可以为多个。
- NEGTIVE:该关键词用于表示本次导入为一批"负"导入。这种方式仅针对具有整型 SUM 聚合类型的聚合数据表。该方式会将导入数据中,SUM 聚合列对应的整型数值取反。主要用于冲抵之前导入错误的数据。
- PARTITION(p1, p2, ...):可以指定仅导入表的某些分区。不再分区范围内的数据将被忽略。
- COLUMNS TERMINATED BY:指定列分隔符
- FORMAT AS:指定要导入文件的类型,支持 CSV、PARQUET 和 ORC 格式。默认为 CSV。
- Column list:用于指定原始文件中的列顺序。
- COLUMNS FROM PATH AS:指定从导入文件路径中抽取的列。
- PRECEDING FILTER:前置过滤条件。数据首先根据 column list 和 COLUMNS FROM PATH AS 按顺序拼接成原始数据行。然后按照前置过滤条件进行过滤。
- SET (column_mapping):指定列的转换函数。
- WHERE predicate:根据条件对导入的数据进行过滤。
- DELETE ON expr:需配合 MEREGE 导入模式一起使用,仅针对 Unique Key 模型的表。用于指定导入数据中表示 Delete Flag 的列和计算关系。
- load_properties:指定导入的相关参数。目前支持以下参数:
-
- timeout:导入超时时间。默认为 4 小时。单位秒。
- max_filter_ratio:最大容忍可过滤(数据不规范等原因)的数据比例。默认零容忍。取值范围为0到1。
- exec_mem_limit:导入内存限制。默认为 2GB。单位为字节。
- strict_mode:是否对数据进行严格限制。默认为 false。
- timezone:指定某些受时区影响的函数的时区,如 strftime/alignment_timestamp/from_unixtime 等等,具体请查阅 时区 文档。如果不指定,则使用 "Asia/Shanghai" 时区
记录一个问题:
type:LOAD_RUN_FAIL; msg:errCode = 2, detailMessage = (bigdata02)[MEM_ALLOC_FAILED]Create Expr failed because [E11] Allocator sys memory check failed: Cannot alloc:64, consuming tracker:<Load#Id=6f5cbea1a558446a-af9cdbd2b4d0d386>, peak used 4096, current used 4096, exec node:<>, process memory used 682.63 MB exceed limit 1.60 GB or sys available memory 41.84 MB less than low water mark 91.08 MB.
0# doris::Exception::Exception(int, std::basic_string_view<char, std::char_traits<char> > const&) at /var/local/ldb-toolchain/bin/../lib/gcc/x86_64-linux-gnu/11/../../../../include/c++/11/bits/unique_ptr.h:173
1# Allocator<false, false, false, DefaultMemoryAllocator>::sys_memory_check(unsigned long) const at /home/zcp/repo_center/doris_release/doris/be/src/vec/common/allocator.cpp:129
2# Allocator<false, false, false, DefaultMemoryAllocator>::alloc_impl(unsigned long, unsigned long) at /home/zcp/repo_center/doris_release/doris/be/src/vec/common/allocator.cpp:187
3# doris::vectorized::ColumnStr<unsigned int>::reserve(unsigned long) at /home/zcp/repo_center/doris_release/doris/be/src/vec/common/pod_array.h:143
4# doris::vectorized::ColumnNullable::reserve(unsigned long) at /home/zcp/repo_center/doris_release/doris/be/src/vec/common/cow.h:198
5# doris::vectorized::IDataType::create_column_const(unsigned long, doris::vectorized::Field const&) const at /home/zcp/repo_center/doris_release/doris/be/src/vec/common/cow.h:198
6# doris::vectorized::VLiteral::init(doris::TExprNode const&) at /home/zcp/repo_center/doris_release/doris/be/src/vec/common/cow.h:143
7# std::_Sp_counted_ptr_inplace<doris::vectorized::VLiteral, std::allocator<doris::vectorized::VLiteral>, (__gnu_cxx::_Lock_policy)2>::_Sp_counted_ptr_inplace<doris::TExprNode const&>(std::allocator<doris::vectorized::VLiteral>, doris::TExprNode const&) at /var/local/ldb-toolchain/bin/../lib/gcc/x86_64-linux-gnu/11/../../../../include/c++/11/bits/shared_ptr_base.h:521
8# doris::vectorized::VExpr::create_expr(doris::TExprNode const&, std::shared_ptr<doris::vectorized::VExpr>&) at /var/local/ldb-toolchain/bin/../lib/gcc/x86_64-linux-gnu/11/../../../../include/c++/11/bits/shared_ptr_base.h:565以上错误原因是 bigdata02 和 03 的内存已经所剩不多了,调大即可。
进阶参数示例
从 HDFS 导入数据,使用通配符匹配两批文件。分别导入到两个表中
LOAD LABEL example_db.label2
(
DATA INFILE("hdfs://hdfs_host:hdfs_port/input/file-10*")
INTO TABLE `my_table1`
PARTITION (p1)
COLUMNS TERMINATED BY ","
FORMAT AS "parquet"
(id, tmp_salary, tmp_score)
SET (
salary= tmp_salary + 1000,
score = tmp_score + 10
),
DATA INFILE("hdfs://hdfs_host:hdfs_port/input/file-20*")
INTO TABLE `my_table2`
COLUMNS TERMINATED BY ","
(k1, k2, k3)
)
with HDFS (
"fs.defaultFS"="hdfs://hadoop11:8020",
"hadoop.username"="root"
)导入数据,并提取文件路径中的分区字段
LOAD LABEL example_db.label10
(
DATA INFILE("hdfs://hdfs_host:hdfs_port/user/hive/warehouse/table_name/dt=20221125/*")
INTO TABLE `my_table`
FORMAT AS "csv"
(k1, k2, k3)
COLUMNS FROM PATH AS (dt)
)
WITH BROKER hdfs
(
"username"="hdfs_user",
"password"="hdfs_password"
);对导入数据进行过滤。
LOAD LABEL example_db.label6
(
DATA INFILE("hdfs://host:port/input/file")
INTO TABLE `my_table`
(k1, k2, k3)
SET (
k2 = k2 + 1
)
PRECEDING FILTER k1 = 1
WHERE k1 > k2
)
WITH BROKER hdfs
(
"username"="user",
"password"="pass"
);
只有原始数据中,k1 = 1,并且转换后,k1 > k2 的行才会被导入。取消导入任务
当 Broker load 作业状态不为 CANCELLED 或 FINISHED 时,可以被用户手动取消。
取消时需要指定待取消导入任务的 Label 。取消导入命令语法可执行 HELP CANCEL LOAD 查看。
CANCEL LOAD [FROM db_name] WHERE LABEL="load_label";4.3 使用 Insert 方式同步数据
用户可以通过 MySQL 协议,使用 INSERT 语句进行数据导入。
INSERT 语句的使用方式和 MySQL 等数据库中 INSERT 语句的使用方式类似。 INSERT 语句支持以下两种语法:
* INSERT INTO table SELECT ...
* INSERT INTO table VALUES(...)对于 Doris 来说,一个 INSERT 命令就是一个完整的导入事务。
因此不论是导入一条数据,还是多条数据,我们都不建议在生产环境使用这种方式进行数据导入。高频次的 INSERT 操作会导致在存储层产生大量的小文件,会严重影响系统性能。
该方式仅用于线下简单测试或低频少量的操作。
或者可以使用以下方式进行批量的插入操作:
INSERT INTO example_tbl VALUES
(1000, "baidu1", 3.25)
(2000, "baidu2", 4.25)
(3000, "baidu3", 5.25);5 导出数据
Apache Doris 提供以下三种不同的数据导出方式:
- SELECT INTO OUTFILE:支持任意 SQL 结果集的导出。
- EXPORT:支持表级别的部分或全部数据导出。
- MySQL DUMP:兼容 MySQL Dump 指令的数据导出。
5.1 Export
本文档将介绍如何使用EXPORT命令导出 Doris 中存储的数据。
Export 是 Doris 提供的一种将数据异步导出的功能。该功能可以将用户指定的表或分区的数据,以指定的文件格式,导出到目标存储系统中,包括对象存储、HDFS 或本地文件系统。
Export 是一个异步执行的命令,命令执行成功后,立即返回结果,用户可以通过Show Export 命令查看该 Export 任务的详细信息。
快速上手
建表与导入数据
CREATE TABLE IF NOT EXISTS tbl (
`c1` int(11) NULL,
`c2` string NULL,
`c3` bigint NULL
)
DISTRIBUTED BY HASH(c1) BUCKETS 20
PROPERTIES("replication_num" = "1");
insert into tbl values
(1, 'doris', 18),
(2, 'nereids', 20),
(3, 'pipelibe', 99999),
(4, 'Apache', 122123455),
(5, null, null);创建导出作业
导出到 HDFS
将 tbl 表的所有数据导出到 HDFS 上,设置导出作业的文件格式为 csv(默认格式),并设置列分割符为 ,。
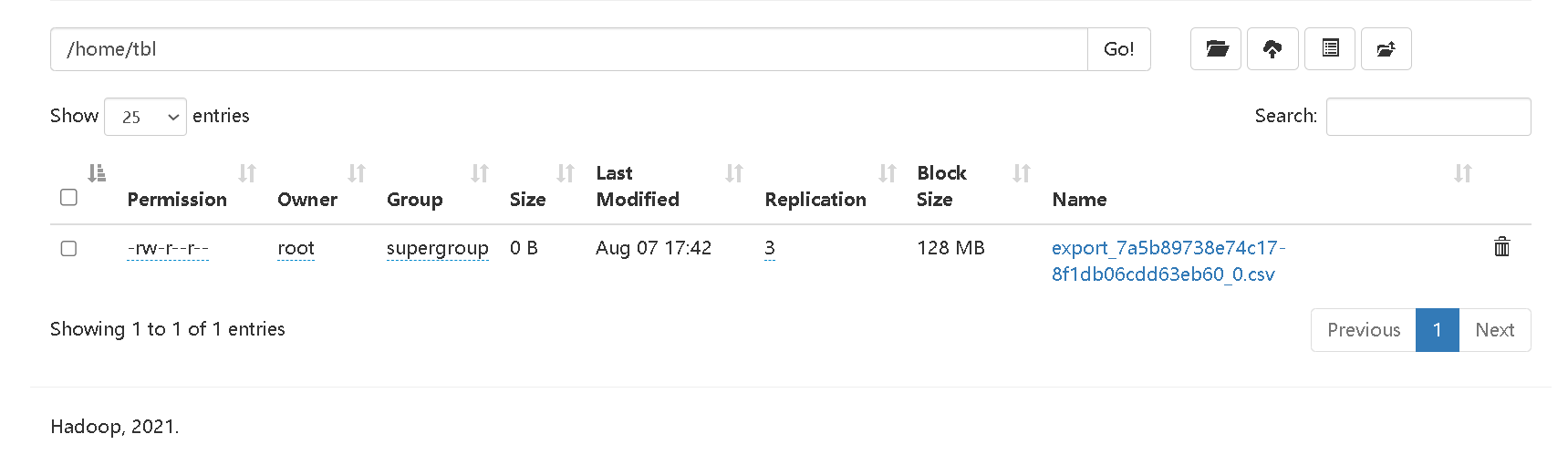
EXPORT TABLE tbl
TO "hdfs://bigdata01:9820/home/tbl/export_"
PROPERTIES
(
"line_delimiter" = ","
)
with HDFS (
"fs.defaultFS"="hdfs://bigdata01:9820",
"hadoop.username" = "root"
);
查看导出作业
提交作业后,可以通过 SHOW EXPORT 命令查询导出作业状态,结果举例如下:
mysql> show export\G
*************************** 1. row ***************************
JobId: 143265
Label: export_0aa6c944-5a09-4d0b-80e1-cb09ea223f65
State: FINISHED
Progress: 100%
TaskInfo: {"partitions":[],"parallelism":5,"data_consistency":"partition","format":"csv","broker":"S3","column_separator":"\t","line_delimiter":"\n","max_file_size":"2048MB","delete_existing_files":"","with_bom":"false","db":"tpch1","tbl":"lineitem"}
Path: s3://bucket/export/export_
CreateTime: 2024-06-11 18:01:18
StartTime: 2024-06-11 18:01:18
FinishTime: 2024-06-11 18:01:31
Timeout: 7200
ErrorMsg: NULL
OutfileInfo: [
[
{
"fileNumber": "1",
"totalRows": "6001215",
"fileSize": "747503989",
"url": "s3://bucket/export/export_6555cd33e7447c1-baa9568b5c4eb0ac_*"
}
]
]
1 row in set (0.00 sec)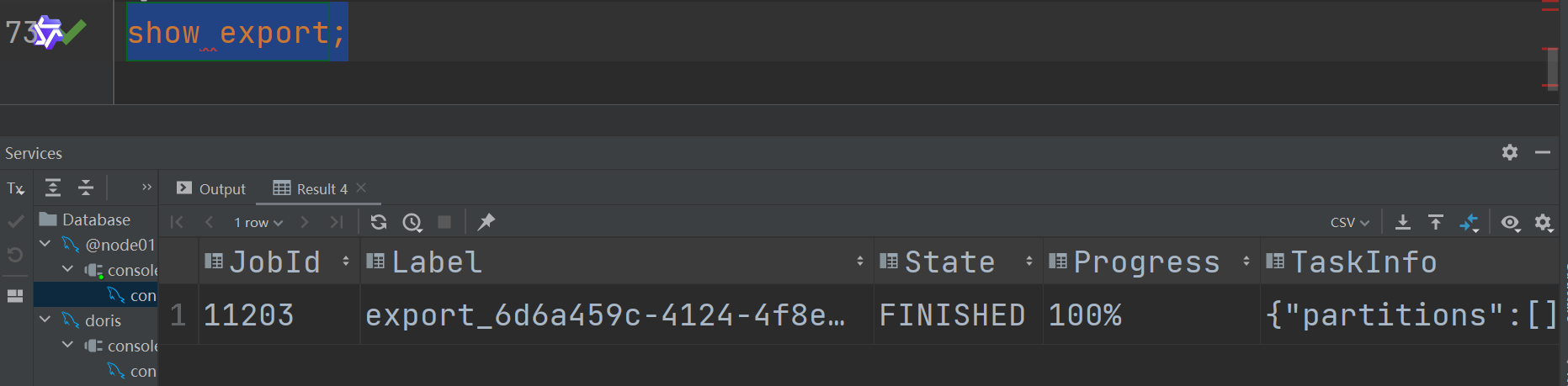
5.2 SELECT INTO OUTFILE
本文档将介绍如何使用 SELECT INTO OUTFILE 命令进行查询结果的导出操作。
SELECT INTO OUTFILE 命令将 SELECT 部分的结果数据,以指定的文件格式导出到目标存储系统中,包括对象存储或 HDFS。
SELECT INTO OUTFILE 是一个同步命令,命令返回即表示导出结束。若导出成功,会返回导出的文件数量、大小、路径等信息。若导出失败,会返回错误信息
导出到 HDFS
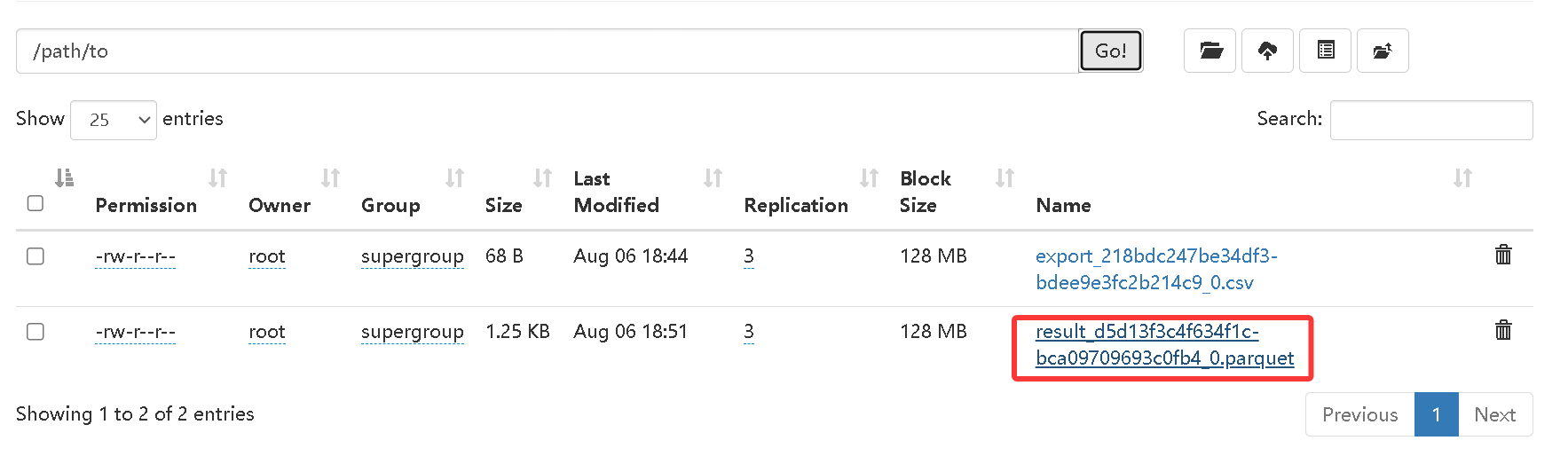
将查询结果导出到文件 hdfs://path/to/ 目录下,指定导出格式为 Parquet:
SELECT c1, c2, c3 FROM tbl
INTO OUTFILE "hdfs://bigdata01:9820/home/tbl/result_"
FORMAT AS PARQUET
PROPERTIES
(
"fs.defaultFS" = "hdfs://bigdata01:9820",
"hadoop.username" = "root"
);

导出到本地文件系统
导出到本地文件系统功能默认是关闭的。这个功能仅用于本地调试和开发,请勿用于生产环境。
如要开启这个功能请在 fe.conf 中添加 enable_outfile_to_local=true 并且重启 FE
5.3 MySQL Dump
Doris 在 0.15 之后的版本已经支持通过 mysqldump 工具导出数据或者表结构
使用示例
导出
- 导出 test 数据库中的 table1 表:
mysqldump -h127.0.0.1 -P9030 -uroot --no-tablespaces --databases test --tables table1 - 导出 test 数据库中的 table1 表结构:
mysqldump -h127.0.0.1 -P9030 -uroot --no-tablespaces --databases test --tables table1 --no-data - 导出 test1, test2 数据库中所有表:
mysqldump -h127.0.0.1 -P9030 -uroot --no-tablespaces --databases test1 test2 - 导出所有数据库和表
mysqldump -h127.0.0.1 -P9030 -uroot --no-tablespaces --all-databases
更多的使用参数可以参考mysqldump 的使用手册
导入
mysqldump导出的结果可以重定向到文件中,之后可以通过 source 命令导入到 Doris 中 source filenamme.sql
注意
- 由于 Doris 中没有 MySQL 里的 tablespace 概念,因此在使用 MySQL Dump 时要加上
--no-tablespaces参数 - 使用 MySQL Dump 导出数据和表结构仅用于开发测试或者数据量很小的情况,请勿用于大数据量的生产环境