大家好,我是 Qoder 团队的夏振华,主要负责 Qoder Agent 相关工作。今天我将从技术角度解释 Qoder 中 Credits 的消耗机制,并分享节省 Credits 的最佳实践。
一、主流 AI 模型的定价策略
首先,很多用户对海外模型的定价体系不太了解,所以对 Credits 的消耗"没概念"------比如一个任务为什么会消耗这么多 Credits?
这里以某厂商的两个模型系列为例:
- O 系列(模型最新):输入 5/MTok,输出25/MTok,缓存读取价格 $0.50/MTok。
- S 系列(模型次新):输入 3/MTok,输出15/MTok,缓存读取价格 $0.30/MTok。

两个系列的整体定价策略基本类似,但最关键的一点:如果能命中缓存,成本只要 1/10!

所以,Qoder 做了很多技术策略去优化缓存命中率。而大家在使用时,如果也能用一些能命中缓存的方式,也会非常节省成本。
二、Qoder Agent 的交互成本构成
接下来,让我们来看下 Coding Agent 的交互流程与 Token 消耗的情况:

- System+Tools
如果做过 Agent 的开发的同学可能会了解到,我们会给模型一个身份:"你是一个编程专家,擅长 XXX,遇到 XXX 情况要用 XXX 工具"。还会给模型很多工具,例如代码读取、代码编辑、终端执行、Web 检索......如果用了 MCP,也会加进去。
这部分一般是可以命中缓存的,在前面的模型下约 $0.3/MTok。
-
User
你其实在提问的时候,经常会类似我这里写到的一些用法,比如:"帮我生成一个 to-do APP。"
你还可能引入文件、图片(比如设计稿截图)、Agents.md、Rules、目录等辅助让 Agent 的生成的更好。这部分是输入,一般会命中到前面讲的那个模型的成本里面的 catch。
-
Action
然后模型会输出一个一个的 Action,相当于让模型帮我去构建一个 to do APP,那么这个模型可能会说:"我要读 一个文件" 、"我要编辑 一个文件"或 "我要创建一个新文件"。这个其实就是模型的输出,模型的输出是比较贵的,约 $15/MTok。
-
Observation
最后 Qoder 的 Agent 就会通过工具会调用的方式去拿到这个 Action 对应的一个 Observation 的结果。这个结果通过 Catch Write 的方式去请求模型,成本约 $3.75/MTok。
重点来了:你问一个问题,Agent 不是一次就完事的!它会循环调用模型:Action → Observation → Action → Observation......直到任务完成或需要你确认。
所以,一次用户请求 = N 次模型调用 = N 次收费!

三、Qoder 真实场景成本测算
一次对话的成本计算公式:总成本 = 模型调用次数 × (缓存部分 + 普通输入 + 输出部分)。
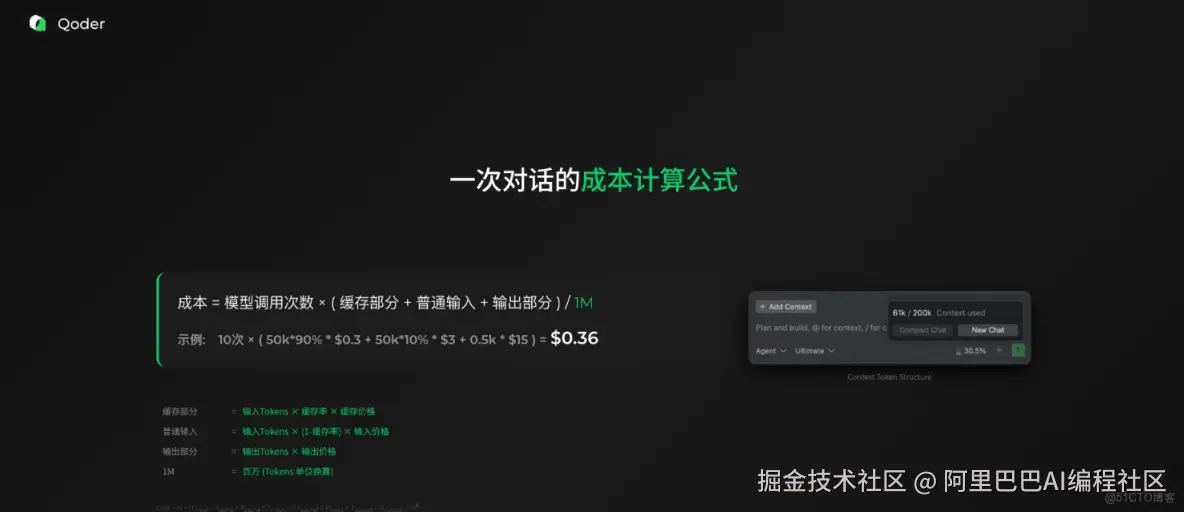
一次对话的成本,其实它是由那个模型调用的次数作为这个基数的,就是你调十次那就收十次的钱。如果你问一个你好,Qoder 回一个你好,那可能就只收一次的钱。每一次的话,其实有它的缓存部分,也有没有命中缓存的部分,再加上模型的输出部分,最后加在一起的总成本。
场景 1:上下文长度对成本的影响
- 从 100K 上下文开始对话,假设一次任务调用 10 次模型,90%缓存命中率:
- O 系列模型:≈ $1.00/次对话
- S 系列模型:≈ $0.59/次对话

- 同样的任务,从20K上下文开始对话:
- O 系列模型:≈ $0.22/次对话
- S 系列模型:≈ $0.13/次对话

可以看出,从20K上下文开始对话与从100K上下文开始对话相比,可以节省约 78%成本。所以,如果你的新任务和历史对话无关,请务必新开一个窗口!
目前Qoder 支持查看用户的Credits 消耗账单,在真实场景下,我们的单次对话调用大约 0.1 1,这是正常的 Credits 消耗范围。

场景 2:上下文压缩对成本的影响
当上下文快达到模型上限(比如 200K)时,必须做压缩。Claude Code 上下文在 160~180K 时的一次压缩成本大约 $0.48。Qoder 做了深度优化,通过智能缓存命中,一次压缩成本节省 84%!

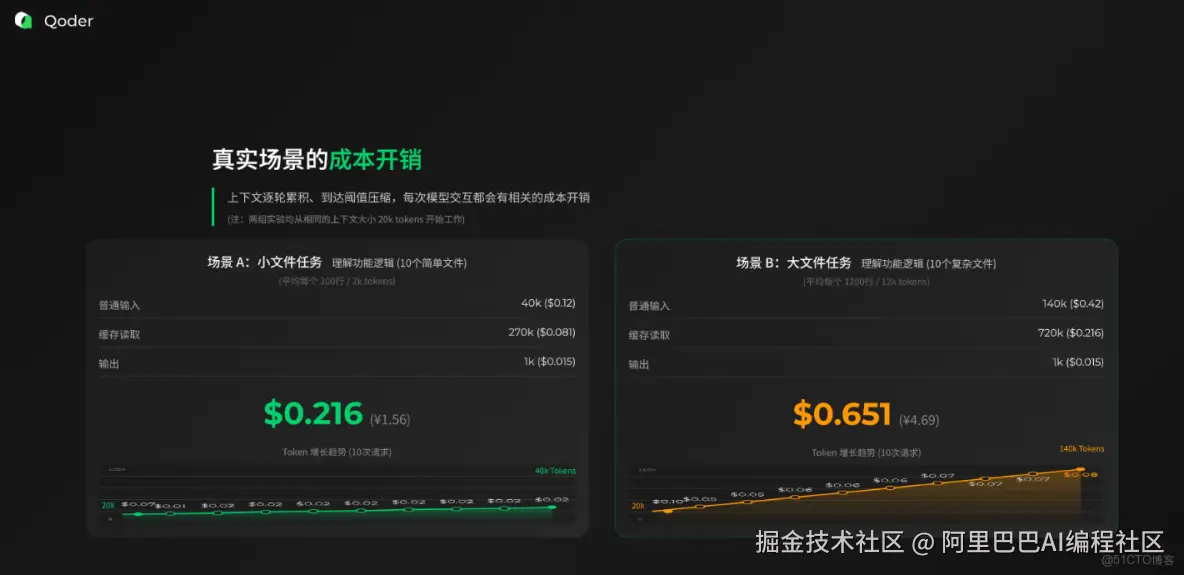
上下文逐论累积,到达阈值压缩,每次模型交互都会有相关的压缩成本。以文件大小影响压缩成本为例:
- 小文件任务:成本 ≈ $0.20,结束时上下文 ≈ 40K
- 大文件任务:成本 ≈ $0.65,结束时上下文 ≈ 140K
结束时上下文大小也会直接影响后续追问成本。
四、节省 Credits 的最佳实践
1. 无关话题,新开窗口
避免上下文积累,保持会话简洁,减少 Token 消耗。

2. 明确告知期望行为
告诉 AI:特定项目不要写测试、不要运行、不要写过程说明和解释文档。

3. 发现跑偏,立即终止
发现 Agent 偏离目标时,立即停止,避免无谓 Token 消耗。

4. 慎用对话式回滚
如果某一次的对话产生了一些代码变更,不是我预期内的,建议使用 Qoder 的 Revert 功能或 Reject 变更,不推荐通过聊天让 AI 回滚代码。

5. 按需选择模型等级
Qoder提供多级模型选择,您可根据任务复杂度和具体场景需求灵活选择适合的模型:
- Lite:适合简单任务,例如:简单问答、语法检查。
- Efficient:经济高效,适合日常编码、小功能开发。
- Auto、Performance:适合复杂功能、全栈开发。
- Ultimate:使用海外最好、最顶尖的模型,适合企业级项目、高精度任务成本最高。

6. 优化代码仓库结构
尽量让我们的代码仓库的结构和 AI 更友好:
- 控制仓库代码文件的长度,避免过长的代码文件。建议单文件不超过200行,避免2000+行的巨无霸文件,以提升代码可维护性和AI处理效率。
- 使用强类型语言,减少 AI 幻觉
- 写代码时添加函数注释,提升 AI 检索精度
- 配置
.qoderignore,排除无需分析的目录(如node_modules、构建产物、隐私文件),减少无效 Token。

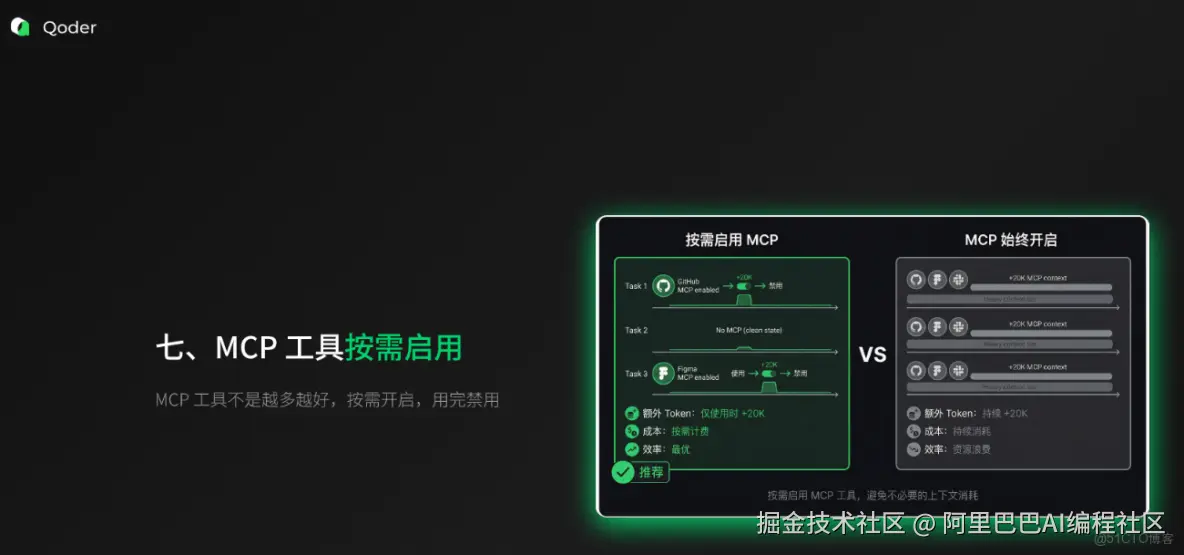
7. 按需启用 MCP 工具
MCP 的工具你可以按需启用,别因为某个 MCP 工具"挺火"就一直开着,它会一直占着你的上下文成本!不用的 MCP,赶紧禁用。避免加载"工具数量庞大"的低效 MCP。
8. 连续对话利用缓存
模型缓存有效期基本上在 5~10 分钟,如果你提完问题,半小时后再追问,就无法命中缓存,成本就会更高。
妙招:用 Qoder 的消息队列!任务还在跑时,直接在输入框里写下一条指令,回车。它会自动排队,无缝衔接,大幅度命中缓存,降低 Credits!

总结
节省Credits的本质,是提升人机协作的效率,绝非一味地减少使用,而是通过清晰的指令 、对上下文的主动管理 和恰到好处的人机分工,来极致提升人机协作的效率。掌握这些技巧,您将能最大化Credits的价值,让Qoder真正成为提升您开发效率和创造力的强大助力!