Patroni + HAProxy + Keepalived + watchdog + ETCD 各组件原理
前言
上篇文章中介绍了如何使用 Patroni + HAProxy + Keepalived + watchdog + ETCD 搭建高可用的 PostgreSQL 集群,本文主要解析下每个组件的原理及维护。所有组件的流程架构图如下:
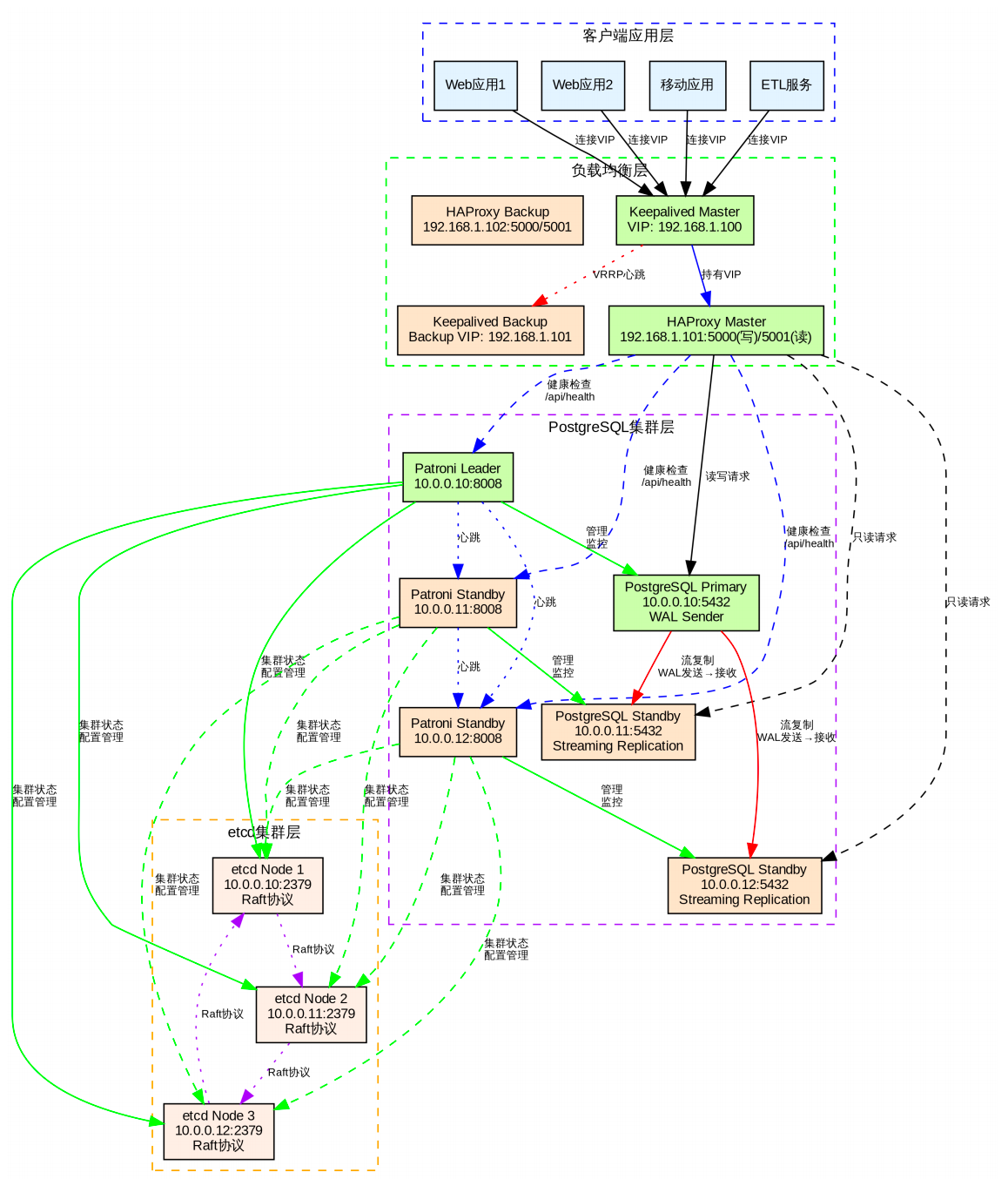
在以上的图中主要有一些的功能:
客户端应用层 :业务系统通过统一 VIP 访问。
负载均衡层 :HAProxy + Keepalived 实现智能路由,智能读写路由优化性能。
数据库集群层 :PostgreSQL + Patroni 实现数据高可用,实现毫秒级切换,使业务无感知。
分布式一致性:ETCD 集群提供一致性保障,防止集群出现脑裂的现象。
HAProxy 组件
HAProxy(High Availability Proxy)是一款开源高性能代理软件,核心定位是"高可用"与"负载均衡",同时支持 TCP和 HTTP/HTTPS协议的应用代理。在 PostgreSQL 高可用架构中,HAProxy 扮演着关键角色,是实现数据库集群负载均衡和高可用性的核心组件。

sql
在 /etc/haproxy/haproxy.cfg 配置文件中有以下的一段配置,其中含义如下:
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
inter 2s # 健康检查间隔
fall 3 # 失败阈值(3次失败标记为down)
rise 2 # 恢复阈值(2次成功标记为up)
option pgsql-check # PostgreSQL专用健康检查
timeout connect 5s # 连接超时
timeout server 30s # 服务器响应超时HAProxy 具有六大核心组件分别是:
Frontend - 前端请求处理和路由
Backend - 后端服务器管理和负载均衡
Load Balancer - 负载均衡算法执行
Health Checker - 服务器健康状态检查
Connection Manager - 连接管理和优化
Statistics Engine - 性能统计和监控
HAProxy 请求处理流程是:
Accept Connection - 接受客户端连接
Parse Request - 解析请求内容
Route Request - 路由到合适的后端
Select Server - 选择后端服务器
Connect to Server - 连接到后端服务器
Proxy Traffic - 代理请求和响应
Process Response - 处理服务器响应
Close Connection - 关闭连接并清理
HAProxy 负载均衡算法包含以下内容,默认的是Round Robin
Round Robin - 轮询算法
Least Connections - 最少连接算法
Source IP Hashing - 源 IP 哈希算法
URI Hashing - URI 哈希算法
URL Parameter - URL 参数算法
HAProxy 健康检查类型包含以下的方式,默认的HTTP方式:
TCP Check - TCP 端口连通性检查
HTTP Check - HTTP 请求和响应检查
SSL Check - SSL 证书和连接检查
SMTP Check - SMTP 服务检查
PostgreSQL Check - PostgreSQL 数据库检查
Keepalived 组件
Keepalived 核心作用是通过 VRRP 协议实现虚拟 IP 高可用,为主备 HAProxy 节点提供心跳检测与故障切换,确保负载均衡层的业务接入稳定,避免单点故障导致服务中断的重要组件。
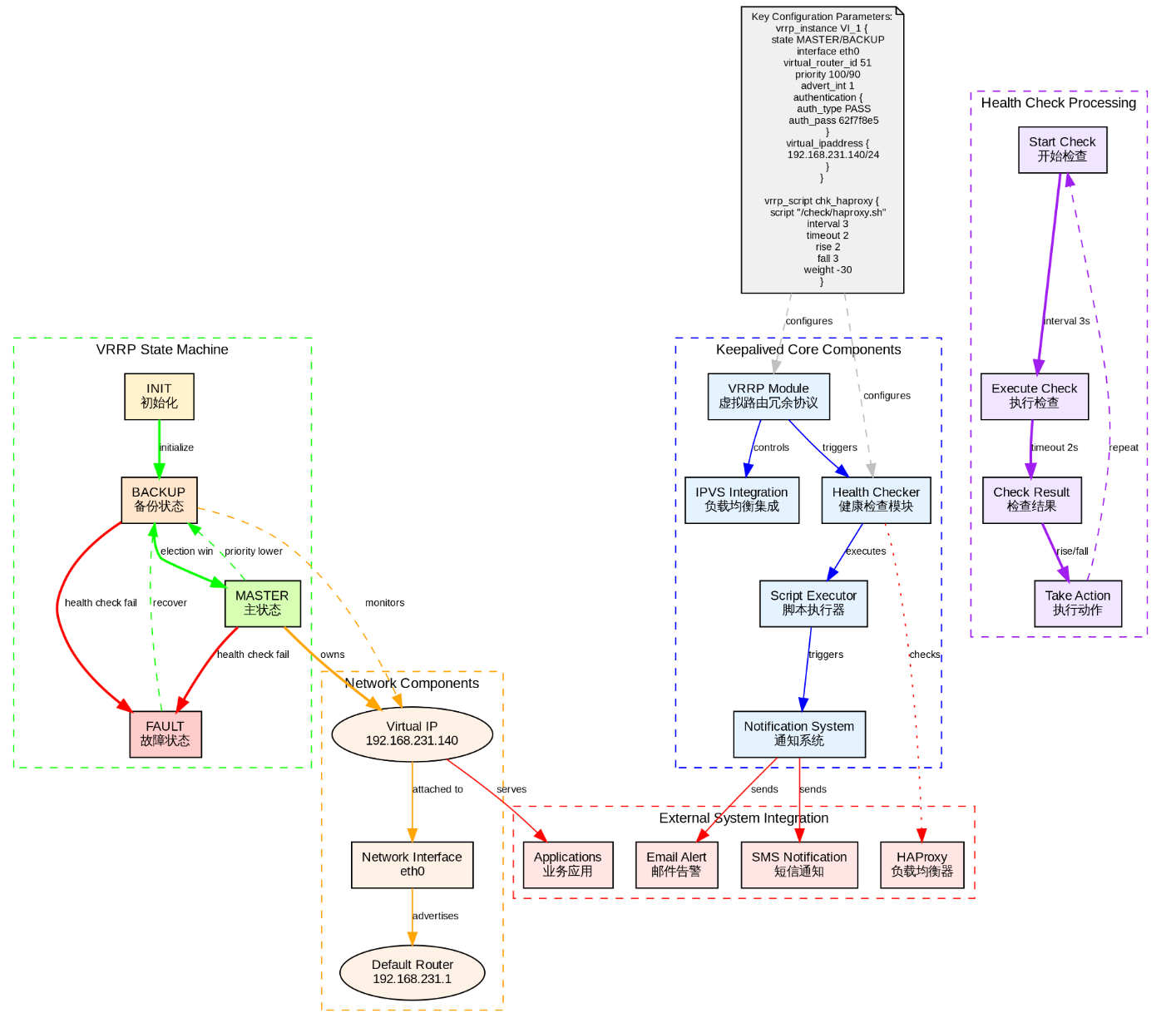
sql
vrrp_instance VI_1 {
state MASTER/BACKUP
interface eth0
virtual_router_id 51
priority 100/90 # 主/备节点优先级
advert_int 1 # VRRP心跳广播间隔
authentication {
auth_type PASS
auth_pass 62f7f8e5
}
virtual_ipaddress {
192.168.231.140/24
}
}
vrrp_script chk_haproxy {
script "/check/haproxy.sh"
interval 3
timeout 2
rise 2
fall 3
weight -30
}Keepalived 的五大核心组件如下:
VRRP 模块 - 实现虚拟路由冗余协议
健康检查模块 - 监控后端服务状态
IPVS 集成 - 负载均衡功能
脚本执行器 - 执行自定义检查脚本
通知系统 - 状态变化告警
Keepalived 的 VRRP 状态如下:
INIT → BACKUP → MASTER → FAULT
Keepalived 的健康检查流程如下:
开始检查 - 按时间间隔启动
执行检查 - 运行检查脚本或命令
检查结果 - 分析返回状态
执行动作 - 根据结果调整 VRRP 状态
Keepalived 故障处理机制如下:
主节点故障 :自动选举新主节点,VIP 无缝转移
健康检查失败 :优先级调整,自动切换状态
服务恢复:自动回到正常状态
ETCD 组件
etcd 是基于 Raft 协议的分布式键值存储,为 Patroni 集群提供强一致性的状态存储与共识服务,记录数据库节点角色、选举信息和配置数据,保障 Leader 选举的唯一性,防止脑裂,是实现 PostgreSQL 高可用自动故障转移的核心组件。
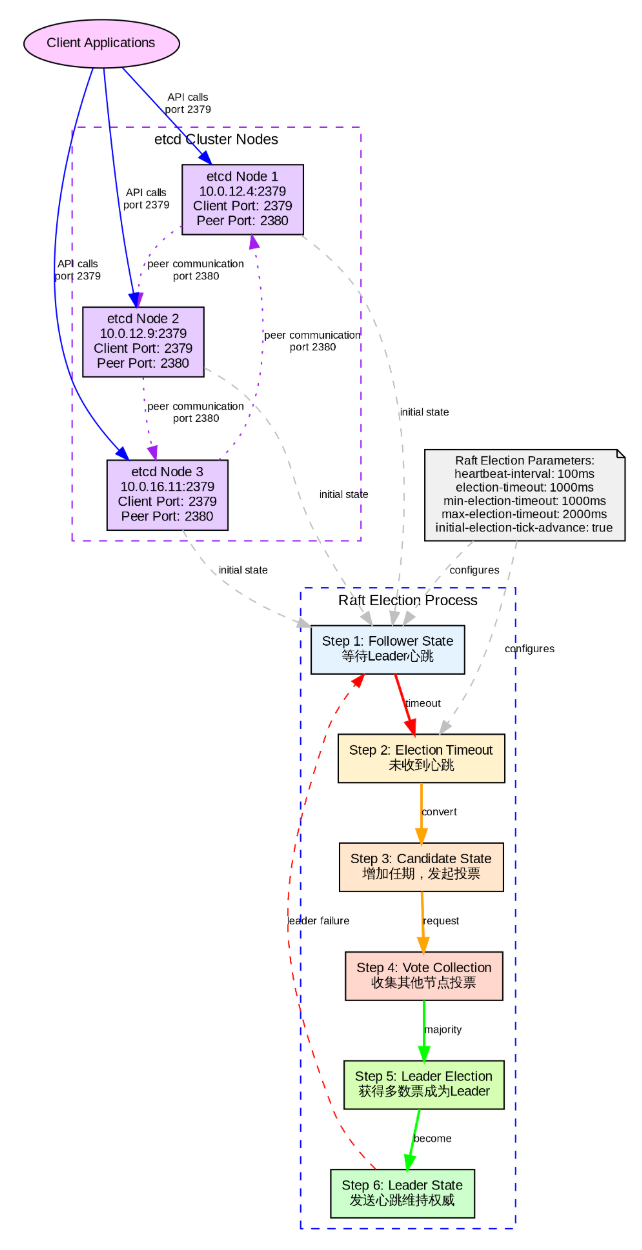
etcd 在选举时主要通过以下参数控制
sql
--heartbeat-interval=100ms # Leader心跳间隔
--election-timeout=1000ms # 选举超时时间
--min-election-timeout=1000ms # 最小选举超时
--max-election-timeout=2000ms # 最大选举超时
--initial-election-tick-advance=true # 初始选举优化Raft 选举流程如下:
Step 1 : Follower State-等待 Leader 心跳
Step 2 : Election Timeout-未收到心跳触发选举
Step 3 : Candidate State-增加任期,发起投票
Step 4 : Vote Collection-收集其他节点投票
Step 5 : Leader Election-获得多数票成为 Leader
Step 6: Leader State-发送心跳维持权威
watchdog 组件
Watchdog 是通过接收 Patroni 的定时心跳来监控其运行状态,一旦检测到进程假死、无响应或心跳超时,会立即触发服务甚至服务重启,强制终止异常节点的不确定状态,有效防止脑裂问题,保障数据库集群的一致性和可用性。
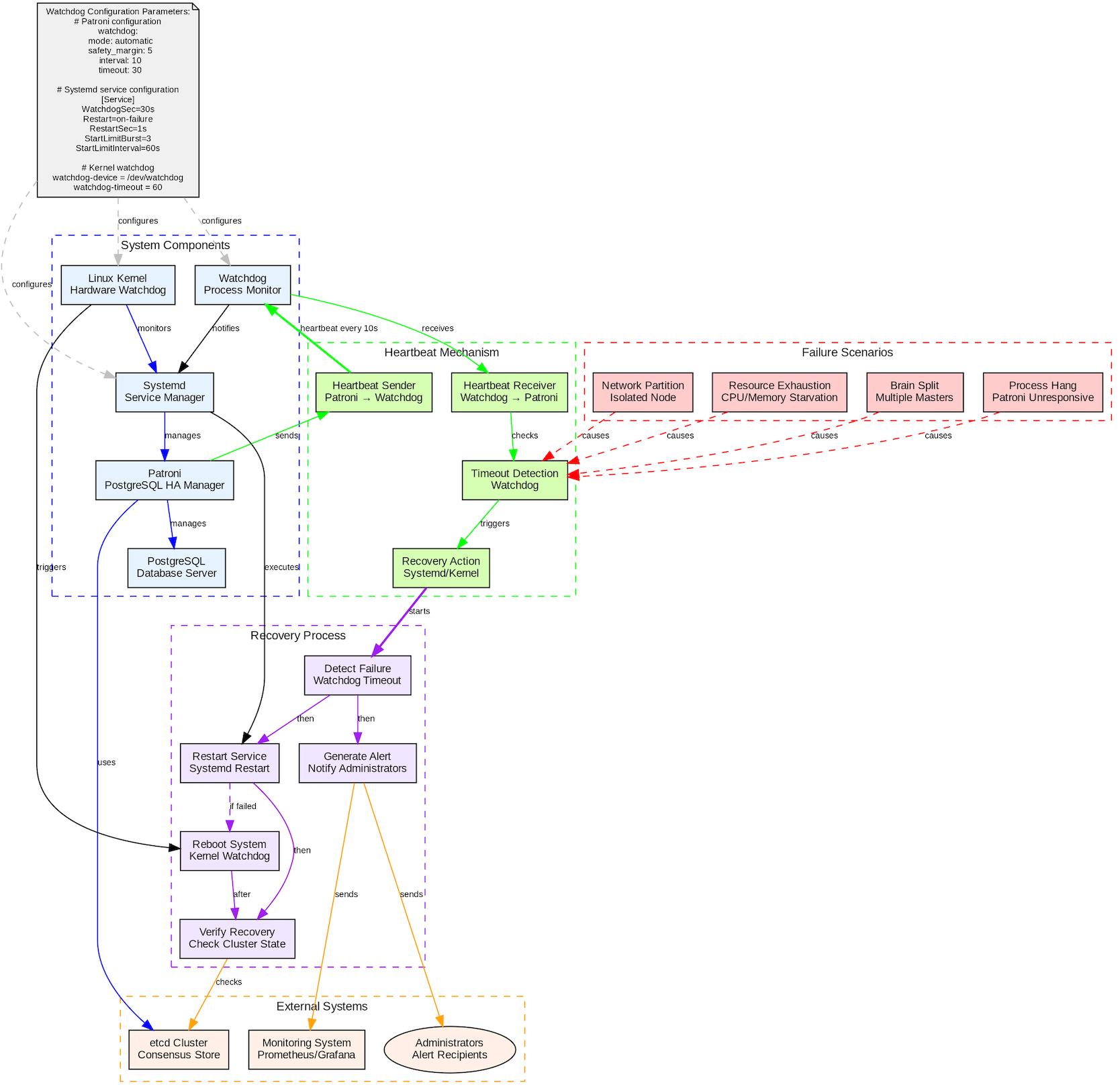
sql
# Watchdog配置
watchdog:
mode: automatic
safety_margin: 5
interval: 10
timeout: 30
# Systemd服务配置
[Service]
WatchdogSec=30s
Restart=on-failure
RestartSec=1s
StartLimitBurst=3
StartLimitInterval=60sWatchdog 四大核心组件如下:
Watchdog - 进程监控器,接收 Patroni 心跳
Patroni - PostgreSQL 高可用管理器,发送心跳
Systemd - 服务管理器,处理服务重启
Linux Kernel - 内核 Watchdog,提供硬件级保障
Watchdog 的心跳检测机制如下:
心跳发送 : Patroni 每 10 秒发送一次心跳
心跳接收 : Watchdog 监控心跳状态
超时检测 : 30 秒超时触发恢复动作
安全裕度: 5 秒缓冲时间
Watchdog 处理的故障场景包含:
脑裂问题 - 多个主节点同时存在
进程假死 - Patroni 进程存在但无响应
网络分区 - 节点与 etcd 集群隔离
资源耗尽 - CPU / 内存 / 磁盘资源不足
Watchdog 恢复处理流程如下:
故障检测 - Watchdog 检测到心跳超时
告警通知 - 通知管理员和监控系统
服务重启 - Systemd 重启 Patroni 服务
系统重启 - 内核 Watchdog 触发系统重启(最后手段)
恢复验证 - 检查集群状态和数据一致性
Watchdog 防止脑裂的工作原理如下:
心跳超时检测 : 30 秒内未收到心跳
自动重启机制 : 防止故障节点继续写入
集群状态验证 : 与 etcd 集群状态对比
数据一致性检查: 验证 WAL 日志位置
Patroni 组件
Patroni 是 PostgreSQL 高可用架构的核心管家,基于 etcd 共识机制实现自动化的主备选举、故障检测与故障转移,实时监控数据库状态并维护集群配置一致性,协调主备节点的流复制同步,防止脑裂问题,无缝对接 HAProxy 实现流量智能路由,让 PostgreSQL 集群的高可用运维彻底告别手动操作。

sql
dcs:
ttl: 30 # Leader租约超时时间
loop_wait: 10 # 心跳发送间隔
retry_timeout: 10 # 重试超时时间
maximum_lag_on_failover: 1048576 # 最大复制延迟
election:
retry_timeout: 10 # 选举重试超时
maximum_retry_timeout: 30 # 最大选举重试超时
retry_interval: 2 # 选举重试间隔
priority: 100 # 节点优先级Patroni 的五大核心组件有以下的部分:
Election Manager - 选举管理器,处理状态转换和投票
Health Monitor - 健康监控器,检测节点和服务状态
etcd Client - etcd 客户端,实现分布式共识
PostgreSQL - 数据库服务,根据角色处理读写请求
REST API - 提供状态查询和手动干预接口
Patroni 的选举状态流程如下:
INIT → FOLLOWER → CANDIDATE → LEADER LEADER → DEMOTED → FOLLOWER
故障检测 - 检测 Leader 心跳超时或服务故障
触发选举 - 节点转换为 CANDIDATE 状态
竞选投票 - 向其他节点请求投票
收集选票 - 统计投票结果
选举领导者 - 获得多数票的节点成为 Leader
提升 Postgres - 将 PostgreSQL 提升为主节点
通知集群 - 更新 etcd 状态并通知其他组件
Patroni防止脑裂机制有以下方式:
etcd 共识保障 - 使用分布式锁和租约机制
多数票原则 - 必须获得集群多数节点的支持
自动降级机制 - 故障节点自动降级避免数据不一致