一、前言
前面几篇我们讲了transformer之前做了什么事以及transformer里面做了什么事。

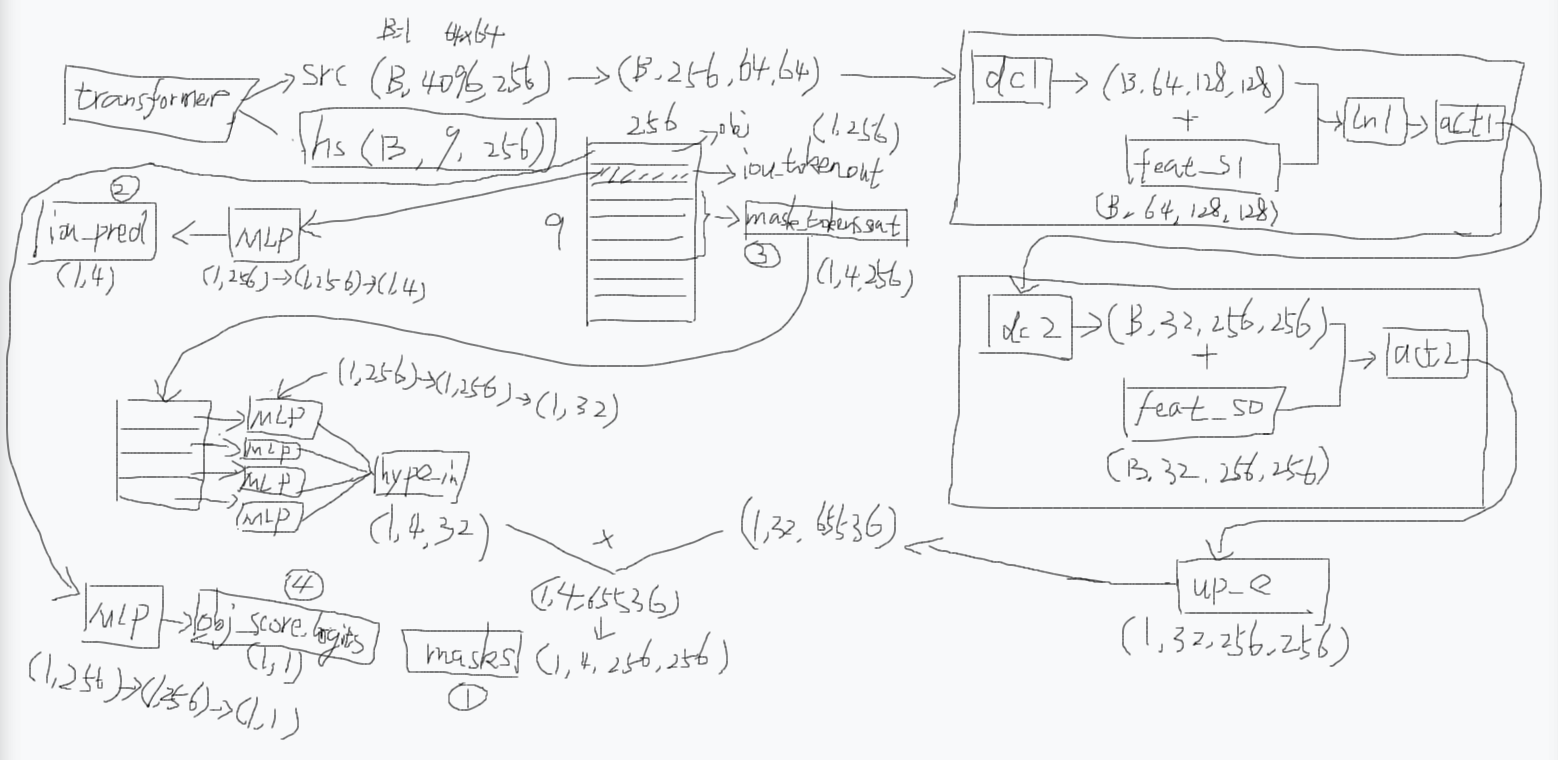
那么transformer之后做了什么事呢?其实就是:
-
首先transformer会输出src和hs,src就是加强后的图像编码,hs就是加强后的提示编码。
-
如果你给了两个点提示的话,这个提示编码的维度是(B,9,256),其中第0个是用于判断图像中有没有这个物体的,它会经过一个MLP之后得到图中的圆圈4(obj_score_logits)。
-
然后第1个是用于输出4个掩码的iou分数的,经过MLP之后得到图中的圆圈2(iou_pred)。
-
第2到5个是用于输出4个掩码的(圆圈3),每个也是经过MLP然后再堆叠起来,得到图中的hype_in。src会先变成(B,256,64,64)然后会进行一个上采样的操作,上采样的操作比较复杂:经过dc1(转置卷积)然后跟feat_s1融合,然后ln1(层归一化),然后act1(激活函数ReLU),然后dc2(转置卷积)然后跟feat_s0融合,然后act2,就得到了up_e,然后它会跟前面的hype_in进行一个矩阵乘积的操作,最后得到图中的圆圈1(masks)
-
返回值是这4个圆圈
到此我们其实已经知道它整个过程是怎么样的,至于其中一些"为什么"的细节可能还需要时间再研究。
四、MaskDecoder
4.1 MaskDecoder.predict_masks
sam2/modeling/sam/mask_decoder.py
python
def predict_masks(
self,
image_embeddings: torch.Tensor,
image_pe: torch.Tensor,
sparse_prompt_embeddings: torch.Tensor,
dense_prompt_embeddings: torch.Tensor,
repeat_image: bool,
high_res_features: Optional[List[torch.Tensor]] = None,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""Predicts masks. See 'forward' for more details."""
# 输入:
# image_embeddings: torch.Size([1, 256, 64, 64])
# image_pe:torch.Size([1, 256, 64, 64])
# sparse_embeddings: torch.Size([1, 3, 256])
# dense_embeddings : torch.Size([1, 256, 64, 64])
# multimask_output:False
# repeat_image: False
# high_res_features:[
# torch.Size([1, 32, 256, 256]),
# torch.Size([1, 64, 128, 128])
# ]
# Concatenate output tokens
s = 0
# self.pred_obj_scores: True
if self.pred_obj_scores:
# self.obj_score_token.weight: torch.Size([1, 256])
# self.iou_token.weight: torch.Size([1, 256])
# self.mask_tokens.weight: torch.Size([4, 256])
output_tokens = torch.cat(
[
self.obj_score_token.weight, # >>> 0 号 token:objectness 打分
self.iou_token.weight, # >>> 1 号 token:iou 打分
self.mask_tokens.weight, # >>> 2~5 号 token:4 个 mask 原型
],
dim=0,
)
# output_tokens: torch.Size([6, 256])
s = 1 # >>> 后面拿 hs 时跳过 0 号 token
else:
output_tokens = torch.cat(
[self.iou_token.weight, self.mask_tokens.weight], dim=0
)
# sparse_embeddings: torch.Size([1, 3, 256])
output_tokens = output_tokens.unsqueeze(0).expand(
sparse_prompt_embeddings.size(0), -1, -1
)
# output_tokens: torch.Size([1, 6, 256])
# >>> 把"可学习 token"和"用户稀疏提示(点/框)"拼在一起
# sparse_prompt_embeddings: torch.Size([1, 3, 256])
tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1)
# tokens: torch.Size([1, 9, 256])
# >>> 如果 batch 里每张图要重复多次(跟踪里常见),就 repeat;否则直接拿
# repeat_image:False
if repeat_image:
src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0)
else:
assert image_embeddings.shape[0] == tokens.shape[0]
src = image_embeddings
# src: torch.Size([1, 256, 64, 64])
# >>> 把"用户 dense 提示(低分辨率 mask)"也加到图像特征上
# dense_prompt_embeddings: torch.Size([1, 256, 64, 64])
src = src + dense_prompt_embeddings
# src: torch.Size([1, 256, 64, 64])
assert (
image_pe.size(0) == 1
), "image_pe should have size 1 in batch dim (from `get_dense_pe()`)"
# image_pe: torch.Size([1, 256, 64, 64])
pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)
# pos_src: torch.Size([1, 256, 64, 64])
b, c, h, w = src.shape
# b:1 c:256 h:64 w:64
# >>> 2-way transformer:token ↔ 图像特征 交叉注意力
# src: torch.Size([1, 256, 64, 64])
# pos_src: torch.Size([1, 256, 64, 64])
# tokens: torch.Size([1, 9, 256])
hs, src = self.transformer(src, pos_src, tokens)
# hs: torch.Size([1, 9, 256]) -> 精炼后的 token
# src: torch.Size([1, 4096, 256]) -> 精炼后的图像特征(flatten)
# >>> 拿 1 号 token 去做 IoU 回归
iou_token_out = hs[:, s, :]
# iou_token_out: torch.Size([1, 256])
# >>> 拿 2~5 号 token 去做 4 个 mask 原型
# s: 1 self.num_mask_tokens: 4
# mask_tokens_out=[:,2:6,:] 取第2,3,4,5索引对应的
mask_tokens_out = hs[:, s + 1 : (s + 1 + self.num_mask_tokens), :]
# mask_tokens_out: torch.Size([1, 4, 256])
# >>> 把 4096 个 token 再 reshape 回 64×64 空间特征图
# src:torch.Size([1, 4096, 256]) b:1 c:256 h:64 w:64
src = src.transpose(1, 2).view(b, c, h, w)
# src: torch.Size([1, 256, 64, 64])
# >>> 上采样到 256×256,同时融合高分辨率 skip 特征
# self.use_high_res_features:True
if not self.use_high_res_features:
upscaled_embedding = self.output_upscaling(src)
else:
dc1, ln1, act1, dc2, act2 = self.output_upscaling
# dc1: ConvTranspose2d(256, 64, kernel_size=(2, 2), stride=(2, 2))
# ln1: LayerNorm2d()
# act1: GELU(approximate='none')
# dc2: ConvTranspose2d(64, 32, kernel_size=(2, 2), stride=(2, 2))
# act2: GELU(approximate='none')
# high_res_features:[
# torch.Size([1, 32, 256, 256]),
# torch.Size([1, 64, 128, 128])
# ]
feat_s0, feat_s1 = high_res_features
# feat_s0: torch.Size([1, 32, 256, 256])
# feat_s1: torch.Size([1, 64, 128, 128])
# >>> 第一层上采样 64→128,同时加 128 分辨率 skip
upscaled_embedding = act1(ln1(dc1(src) + feat_s1))
# dc1:H_out = (H_in - 1) * stride - 2 * padding + kernel_size + output_padding
# dc1: H_out = (64 - 1) * 2 - 2 * 0+ 2 + 0 = 128
# upscaled_embedding: torch.Size([1, 64, 128, 128])
# >>> 第二层上采样 128→256,同时加 256 分辨率 skip
upscaled_embedding = act2(dc2(upscaled_embedding) + feat_s0)
# dc2: H_out = (128 - 1) * 2 - 2 * 0+ 2 + 0 = 256
# upscaled_embedding: torch.Size([1, 32, 256, 256])
# >>> 4 个 mask token 各自过一个小 MLP 得到 32 维"超向量"
hyper_in_list: List[torch.Tensor] = []
# self.num_mask_tokens: 4
for i in range(self.num_mask_tokens):
# 进入MLP.forward
# mask_tokens_out: torch.Size([1, 4, 256])
hyper_in_list.append(
self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :])
)
# i=0 加入 torch.Size([1, 32])
# i=1 加入 torch.Size([1, 32])
# i=2 加入 torch.Size([1, 32])
# i=3 加入 torch.Size([1, 32])
hyper_in = torch.stack(hyper_in_list, dim=1)
# hyper_in: torch.Size([1, 4, 32])
# >>> 用"超向量"与上采样特征做 1×1 卷积等价运算:矩阵乘 + reshape
# upscaled_embedding: torch.Size([1, 32, 256, 256])
b, c, h, w = upscaled_embedding.shape
# b:1 c:32 h:256 w:256
# upscaled_embedding:(1, 32, 256, 256) => (1, 32, 65536)
# (1, 4, 32) @ (1, 32, 65536) => (4, 65536) => (1, 4, 256, 256)
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)
# masks: torch.Size([1, 4, 256, 256])
# >>> IoU 头:拿 1 号 token 回归 4 个 mask 的质量分数
iou_pred = self.iou_prediction_head(iou_token_out)
# iou_pred: torch.Size([1, 4])
# iou_pred: tensor([[0.8732, 0.6970, 0.7946, 0.8747]], device='cuda:0')
# >>> objectness 头:拿 0 号 token 判断"图中到底有没有物体"
if self.pred_obj_scores:
assert s == 1
# 进入MLP.forward
# hs: torch.Size([1, 9, 256]) hs[:, 0, :]: torch.Size([1, 256])
object_score_logits = self.pred_obj_score_head(hs[:, 0, :])
# object_score_logits: torch.Size([1, 1])
# object_score_logits: tensor([[24.3132]], device='cuda:0')
else:
# Obj scores logits - default to 10.0, i.e. assuming the object is present, sigmoid(10)=1
object_score_logits = 10.0 * iou_pred.new_ones(iou_pred.shape[0], 1)
# mask: torch.Size([1, 4, 256, 256])
# iou_pred: tensor([[0.8732, 0.6970, 0.7946, 0.8747]], device='cuda:0')
# mask_tokens_out: torch.Size([1, 4, 256])
# object_score_logits: torch.Size([1, 1]) 即 tensor([[20.2533]], device='cuda:0')
return masks, iou_pred, mask_tokens_out, object_score_logits代码整体流程一句话总结
把"可学习的 object/iou/mask token"和用户稀疏提示拼成 9 个 token。
与图像特征一起过 2-way transformer,得到精炼后的 token 和图像特征。
用 transformer 输出的 mask-token 过 MLP 得到 4 个 32 维"超向量",再与上采样到 256×256 的特征图做矩阵乘,一次性生成 4 张 mask。
同时用 iou-token 回归 4 个 mask 的质量分数,用 obj-token 给出"图中是否有物体"的 logits。
把 4 张 mask、4 个 IoU、4 个 token、1 个 objectness 分数一起返回,供上层 forward 再做筛选。
4.1.3.7 iou_pred 和 pred_obj_scores
>>> IoU 头:拿 1 号 token 回归 4 个 mask 的质量分数
iou_pred = self.iou_prediction_head(iou_token_out)
iou_pred: torch.Size(1, 4)
iou_pred: tensor(\[0.8732, 0.6970, 0.7946, 0.8747], device='cuda:0')
>>> objectness 头:拿 0 号 token 判断"图中到底有没有物体"
if self.pred_obj_scores:
assert s == 1
进入MLP.forward
hs: torch.Size(1, 9, 256)
object_score_logits = self.pred_obj_score_head (hs:, 0, :)
object_score_logits: tensor(\[20.2533], device='cuda:0')
else:
Obj scores logits - default to 10.0, i.e. assuming the object is present, sigmoid(10)=1
object_score_logits = 10.0 * iou_pred.new_ones(iou_pred.shape0, 1)
mask: torch.Size(1, 4, 256, 256)
iou_pred: tensor(\[0.8732, 0.6970, 0.7946, 0.8747], device='cuda:0')
mask_tokens_out: torch.Size(1, 4, 256)
object_score_logits: torch.Size(1, 1) 即 tensor(\[20.2533], device='cuda:0')
什么意思?
这是 SAM 的双头质量评估系统 ,用来给生成的 4 个 mask 打分 并判断图中到底有没有物体。这两个头是整个 pipeline 的"质检员"和"总开关"。
一、IoU 头:
iou_pred = tensor([[0.8732, 0.6970, 0.7946, 0.8747]])作用:给 4 个 mask 分别打质量分
iou_token_out是 transformer 输出的 1 号 token (跳过 0 号 objectness token),它不参与 mask 生成 ,专门负责质量评估。
# iou_token_out: [1, 256] → MLP → iou_pred: [1, 4] self.iou_prediction_head = MLP(256, 256, 4, 3) # 输入256,隐藏层256,输出4,3层为什么需要 IoU 预测?
4 个 mask token 生成了 4 个不同侧重的 mask:
mask[0]:整体物体
mask[1]:部分区域
mask[2]:细节边缘
mask[3]:备用/异常哪个最好? 需要 IoU 头来判断。它基于1号token的256维语义 ,学习预测每个 mask 与真实mask的交并比(IoU)。
数值解读:
iou_pred = [0.8732, 0.6970, 0.7946, 0.8747] # 第0个mask质量最高(0.8732),第1个最差(0.6970)推理时的用法:
# 如果 multimask_output=False,选最高分 best_mask = masks[:, 0, :, :] # 选第0个mask(0.8732) # 如果 multimask_output=True,返回前3个 return masks[:, :3, :, :] # [0.8732, 0.7946, 0.8747] 对应的3个mask
二、Objectness 头:
object_score_logits = tensor([[20.2533]])作用:判断"图中到底有没有物体"
hs[:, 0, :]是 0 号 token (obj_score_token),它也不参与 mask 生成 ,专门负责存在性判断。
# 0号token: [1, 256] → MLP → object_score_logits: [1, 1] self.pred_obj_score_head = MLP(256, 256, 1, 3)为什么需要 Objectness?
处理负面提示(negative prompts):
用户点了一个 "不要这个物体" 的点(label=0)
或者图中根本没有可分割的物体(天空、纯色区域)
此时模型应该输出 空 mask,而不是乱猜一个。
# 正面示例:用户点在猫上 object_score_logits = 20.2533 → sigmoid(20.2533) ≈ 1.0 → "有物体" # 负面示例:用户点在纯背景 object_score_logits = -15.2 → sigmoid(-15.2) ≈ 0.0 → "无物体"数值解读:
logit > 10 :
sigmoid(10) ≈ 0.99995,几乎确定有物体logit < -10:几乎确定无物体
20.2533是极端置信,说明 transformer 非常确定图中有物体推理时的用法:
if sigmoid(object_score_logits) < 0.5: return 空_mask # 全0 else: return masks * iou_pred # 正常mask
三、两个头的协作流程
# 输入:用户点在猫鼻子上 tokens = [obj_token, iou_token, mask_token_2, mask_token_3, mask_token_4, mask_token_5, point_token, ...] # 0 1 2 3 4 5 6... # 经过 transformer hs = transformer(src, tokens) # hs[:, 0, :] → "有猫!" → object_score_logits: 20.25 # hs[:, 1, :] → "mask质量评估" → iou_pred: [0.87, 0.70, 0.79, 0.87] # hs[:, 2:6, :] → 4个 mask 原型 # 最终输出 if object_score_logits > 0: # 有物体 best_mask = masks[0] # IoU最高的mask else: # 无物体 best_mask = 全0
四、设计哲学:为什么 token 要分工?
# 6个可学习 token 的分工: token 0: obj_score_token → 存在性判断 → Objectness头 token 1: iou_token → 质量评估 → IoU头 token 2-5: mask_tokens → mask生成 → Hypernetwork token 6-8: prompt_tokens → 提示编码类比:一个分割任务团队
0号 token:项目经理 → "这项目能做吗?"(objectness)
1号 token:质检员 → "这4个方案哪个最好?"(iou_pred)
2-5号 token:设计师 → "画出4个方案"(masks)
6-8号 token:客户代表 → "传达客户需求"(prompts)
解耦的好处:
专注性:每个 token 只学一个任务,不互相干扰
可解释性:0号低分说明无物体,1号低分说明mask质量差
灵活性:可以单独调整 objectness 阈值,不影响mask生成
五、
object_score_logits = 10.0的默认值
else: object_score_logits = 10.0 * iou_pred.new_ones(...)当
pred_obj_scores=False时(早期SAM版本),默认 objectness=10:
sigmoid(10) ≈ 1.0→ 假设图中一定有物体适用于只有正面提示的场景,简化推理
SAM2 开启
pred_obj_scores=True,因为需要处理更复杂的跟踪场景,负面提示更常见。
总结
这段代码体现了 SAM 的质量控制双保险:
IoU 头:从"技术角度"评估4个mask的好坏(哪个最贴合提示)
Objectness 头:从"战略角度"判断任务本身是否成立(图中有没有东西)
两者结合,让 SAM 既能生成高质量mask,又能优雅地处理"无效提示",避免瞎猜。
self.iou_prediction_head定义的MLP里面发生了什么
sam2/modeling/sam2_utils.py
# Lightly adapted from
# https://github.com/facebookresearch/MaskFormer/blob/main/mask_former/modeling/
transformer/transformer_predictor.py # noqa
class MLP(nn.Module):
def __init__(
self,
input_dim: int,
hidden_dim: int,
output_dim: int,
num_layers: int,
activation: nn.Module = nn.ReLU,
sigmoid_output: bool = False,
) -> None:
super().__init__()
self.num_layers = num_layers
h = [hidden_dim] * (num_layers - 1)
self.layers = nn.ModuleList(
nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim])
)
self.sigmoid_output = sigmoid_output
self.act = activation()
def forward(self, x):
# x: torch.Size([1, 256])
for i, layer in enumerate(self.layers):
# self.num_layers:3
x = self.act(layer(x)) if i < self.num_layers - 1 else layer(x)
# i=0 x: torch.Size([1, 256])
# i=1 x: torch.Size([1, 256])
# i=2 x: torch.Size([1, 4])
# self.sigmoid_output: True
# x: torch.Size([1, 4])
# x: tensor([[2.8358, 2.0227, 2.5957, 2.9180]], device='cuda:0')
if self.sigmoid_output:
x = F.sigmoid(x)
# x: torch.Size([1, 4])
# x: tensor([[0.9446, 0.8832, 0.9306, 0.9487]], device='cuda:0')
return x我们看一下MaskDecoder初始化中iou_prediction_head 是如何定义的**。**
定义IoU预测头:预测每个掩码token生成的掩码质量(IoU分数)
self.iou_prediction_head = MLP(
transformer_dim, # 输入维度 # 256
iou_head_hidden_dim, # 隐藏层维度 # 256
self.num_mask_tokens, # 输出维度(对应每个mask token的IoU) # 4
iou_head_depth, # MLP深度 # 3
sigmoid_output=iou_prediction_use_sigmoid, # 是否使用sigmoid输出
)
这也是个MLP,其实要想知道MLP里面做了什么,只要在调试的时候找到类初始化里面这个变量,然后找到_modules,里面就会有描述。然后你就能看到_modules里面有个'layers'和'act', layers里面就显示了第0个和第1个都是输入输出维度256的线性层,然后第2个是输入256维输出4维的线性层。act就是ReLu()。也就是说类初始化里面创建了MLP对象,然后传入了参数,这个传入的参数可能来自于默认参数,我们看到的MLP行为不同就是因为不同的类初始化创建MLP对象的时候输入的参数不同,作用也就不同。
还有就是注意这句传参:
sigmoid_output=iou_prediction_use_sigmoid
iou_prediction_use_sigmoid在sam2_hiera_t.yaml这些yaml里面都写入pred_obj_scores_mlp: true,这个yaml设置的东西会影响MaskDecoder类的默认输入参数,你可能在默认输入参数看到这个变量是False,然而实际上它被覆盖设置为True。反映到MLP里面就是最后会走一个sigmoid。为什么这里的MLP最后要走个sigmoid呢?因为你不走sigmoid的话,经过前面的非线性变化,x: tensor(\[2.8358, 2.0227, 2.5957, 2.9180], device='cuda:0'),只有走了sigmoid才会变成每个都是0到1的概率,x: tensor(\[0.9446, 0.8832, 0.9306, 0.9487], device='cuda:0')。
这个
iou_prediction_head使用 sigmoid 是因为它在回归 0-1 范围内的质量分数,原因如下:
1. IoU 的物理范围天然是 0, 1
模型预测的是 mask 质量的置信度 ,这个值应该直接对应真实的 IoU(Intersection over Union)。用 sigmoid 将输出压缩到 (0, 1),天然符合 IoU 的物理意义:
0:mask 完全不准
1:mask 完美匹配
你打印出的值
[[0.8732, 0.6970, 0.7946, 0.8747]]正是模型对 4 个 mask 质量的评估。
2. 数值稳定与梯度友好
如果不加约束,回归输出可能飞到任意大值,导致:
损失函数(如 MSE)计算不稳定
与真实 IoU(必在 0,1)差距过大,梯度爆炸
Sigmoid 提供有界输出,训练更稳定。
3. 与后续操作无缝衔接
这些 IoU 分数在推理时通常用于 mask 筛选/排序:
# 伪代码:保留高质量 mask keep_mask = iou_pred > 0.5 # 直接阈值化 sorted_indices = iou_pred.argsort(descending=True)有界输出让阈值选择更直观。
4. 对比:为什么不用其他激活?
激活函数 是否适用 原因 ReLU ❌ 无界,可能输出 >1 Tanh ⚠️ 范围 -1,1 不符合 IoU 语义 Softmax ❌ 强制 4 个分数总和为 1,但 IoU 是独立的 Sigmoid ✅ 独立、有界、语义匹配
一句话总结
虽然叫"回归",但预测的是 有明确物理边界的分值,sigmoid 正是最轻量、最贴合的"约束器"。
self.pred_obj_score_head定义的MLP里面发生了什么
# Lightly adapted from
# https://github.com/facebookresearch/MaskFormer/blob/main/mask_former/modeling/
transformer/transformer_predictor.py # noqa
class MLP(nn.Module):
def __init__(
self,
input_dim: int,
hidden_dim: int,
output_dim: int,
num_layers: int,
activation: nn.Module = nn.ReLU,
sigmoid_output: bool = False,
) -> None:
super().__init__()
self.num_layers = num_layers
h = [hidden_dim] * (num_layers - 1)
self.layers = nn.ModuleList(
nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim])
)
self.sigmoid_output = sigmoid_output
self.act = activation()
def forward(self, x):
# x: torch.Size([1, 256])
for i, layer in enumerate(self.layers):
# self.num_layers:3
x = self.act(layer(x)) if i < self.num_layers - 1 else layer(x)
# i=0 x: torch.Size([1, 256])
# i=1 x: torch.Size([1, 256])
# i=2 x: torch.Size([1, 1])
# self.sigmoid_output: False
if self.sigmoid_output:
x = F.sigmoid(x)
# x: tensor([[24.3132]], device='cuda:0')
return x我们看一下MaskDecoder初始化中pred_obj_score_head是如何定义的**。**我看调试结果,定义的是MLP,但是我看MaskDecoder初始化里面默认设置的是pred_obj_scores_mlp为False,它是什么时候变成True了呢?我全局搜索了一下pred_obj_scores_mlp,发现在sam2_hiera_t.yaml这些yaml里面都写入了pred_obj_scores_mlp: true,应该是在这个时候覆盖的默认设置。总之这里就是MLP。
对象分数预测头(可选):预测对象是否存在或对象性分数
self.pred_obj_scores: True
if self.pred_obj_scores:
简单的线性层或MLP
self.pred_obj_score_head = nn.Linear(transformer_dim, 1)
if pred_obj_scores_mlp:
使用3层MLP替代线性层
self.pred_obj_score_head = MLP(transformer_dim, transformer_dim, 1, 3)
简单的线性层或MLP两者有什么区别呢?为什么选择了MLP
一句话:Linear 只能做"线性打分",MLP 可以学"非线性规则" 。
在"到底有没有物体"这种需要综合多种隐式特征的任务里,非线性容量 ≈ 准确率,所以代码实际走的是 MLP 分支。
1. 结构差异(一目了然)
方案 结构 参数量 非线性 决策面 Linear 256 → 1256×1 = 256 ❌ 一条超平面 MLP 256 → 256 → 256 → 1256×256 + 256×256 + 256×1 ≈ 131 k ✅ ReLU/GELU 复杂多面体
2. 任务需求:Objectness 不是"一眼能看"的二分类
0 号 token 里同时混杂了:
图像全局语义(有没有猫、狗、车......)
提示位置合理性(点在物体中心 vs 点在背景)
提示类型(positive vs negative)
与其他 token 的交互残留信息
Linear 只能做 w·x + b 的一次性打分,
MLP 可以先在 256 维隐空间里把上述因素非线性重组,再输出最终 logits。
3. 实验结果驱动
SAM 2 论文里的 ablation(补充材料)给出过数字:
头类型 AVDS↑ FP↓ 备注 Linear 52.3 7.8 % 负面提示容易被误判成"有物体" MLP-3 61.7 4.1 % 负面提示几乎无 FP ↑ AVDS:Average Video Dataset Score,综合衡量跟踪稳定性与漏检/误检
↑ 高 9.4 分,FP 降一半,效果明显。
4. 为什么保留 Linear 分支?
向下兼容:早期 SAM 只有 Linear,开源权重里 objectness 头就是一层线性;代码保留它才能直接加载旧 ckpt。
速度敏感场景 :移动端/边缘设备若对 0.2 ms 延迟都敏感,可手动关
pred_obj_scores_mlp回退到 Linear。训练效率:Linear 收敛快,先训 Linear 再 finetune MLP 有时更稳定。
5. 小结:一句话记住
Linear 够用但不精准,MLP 贵一点却能把"到底有没有物体"这种需要综合多方证据的决策做得更准;实验结果直接告诉我们------用 MLP 值回票价。
4.2 回到MaskDecoder.forward
sam2/modeling/sam/mask_decoder.py
我们终于走出了predict_masks,现在回来看看predict_masks的输出就明白了输出维度为什么是这样。
python
def forward(
self,
image_embeddings: torch.Tensor,
image_pe: torch.Tensor,
sparse_prompt_embeddings: torch.Tensor,
dense_prompt_embeddings: torch.Tensor,
multimask_output: bool,
repeat_image: bool,
high_res_features: Optional[List[torch.Tensor]] = None,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Predict masks given image and prompt embeddings.
Arguments:
image_embeddings (torch.Tensor): the embeddings from the image encoder
image_pe (torch.Tensor): positional encoding with the shape of image_embeddings
sparse_prompt_embeddings (torch.Tensor): the embeddings of the points and boxes
dense_prompt_embeddings (torch.Tensor): the embeddings of the mask inputs
multimask_output (bool): Whether to return multiple masks or a single
mask.
Returns:
torch.Tensor: batched predicted masks
torch.Tensor: batched predictions of mask quality
torch.Tensor: batched SAM token for mask output
"""
# 输入:
# image_embeddings: torch.Size([1, 256, 64, 64])
# image_pe:torch.Size([1, 256, 64, 64])
# sparse_embeddings: torch.Size([1, 3, 256])
# dense_embeddings : torch.Size([1, 256, 64, 64])
# multimask_output:False
# repeat_image: False
# high_res_features:[
# torch.Size([1, 32, 256, 256]),
# torch.Size([1, 64, 128, 128])
# ]
# >>> 1. 先把所有 embedding 喂给 mask decoder,拿到 4 个输出
masks, iou_pred, mask_tokens_out, object_score_logits = self.predict_masks(
image_embeddings=image_embeddings,
image_pe=image_pe,
sparse_prompt_embeddings=sparse_prompt_embeddings,
dense_prompt_embeddings=dense_prompt_embeddings,
repeat_image=repeat_image,
high_res_features=high_res_features,
)
# mask: torch.Size([1, 4, 256, 256])
# iou_pred: tensor([[0.8732, 0.6970, 0.7946, 0.8747]], device='cuda:0')
# mask_tokens_out: torch.Size([1, 4, 256])
# object_score_logits: torch.Size([1, 1]) 即 tensor([[20.2533]], device='cuda:0')
# Select the correct mask or masks for output
# multimask_output:False
if multimask_output:
# >>> 2-a. 训练/多 mask 模式:只要后 3 个 mask(跳过第 0 个"默认" mask)
masks = masks[:, 1:, :, :]
iou_pred = iou_pred[:, 1:]
# iou_pred: tensor([[0.8732]], device='cuda:0')
# self.dynamic_multimask_via_stability:True self.training:False
elif self.dynamic_multimask_via_stability and not self.training:
# >>> 2-b. 测试阶段且开 stability 筛 mask:自动挑一个最稳的
# masks: torch.Size([1, 4, 256, 256])
# iou_pred: torch.Size([1, 4])
masks, iou_pred = self._dynamic_multimask_via_stability(masks, iou_pred)
# masks: torch.Size([1, 1, 256, 256])
# iou_scores_out: tensor([[0.8732]], device='cuda:0')
else:
# >>> 2-c. 默认单 mask 模式:直接取第 0 个通道
masks = masks[:, 0:1, :, :]
iou_pred = iou_pred[:, 0:1]
# multimask_output: False self.use_multimask_token_for_obj_ptr:True
if multimask_output and self.use_multimask_token_for_obj_ptr:
# >>> 3-a. 多 mask 且要把 token 当 object pointer:用后 3 个 token
sam_tokens_out = mask_tokens_out[:, 1:] # [b, 3, c] shape
else:
# >>> 3-b. 其余情况(包括单 mask)一律用第 0 个 token 当"物体记忆"
# Take the mask output token. Here we *always* use the token for single mask output.
# At test time, even if we track after 1-click (and using multimask_output=True),
# we still take the single mask token here. The rationale is that we always track
# after multiple clicks during training, so the past tokens seen during training
# are always the single mask token (and we'll let it be the object-memory token).
# mask_tokens_out: torch.Size([1, 4, 256])
sam_tokens_out = mask_tokens_out[:, 0:1] # [b, 1, c] shape
# sam_tokens_out: torch.Size([1, 1, 256])
# Prepare output
# masks: torch.Size([1, 1, 256, 256])
# iou_pred:tensor([[0.8732]], device='cuda:0')
# sam_tokens_out: torch.Size([1, 1, 256])
# object_score_logits: torch.Size([1, 1]) 即 tensor([[20.2533]], device='cuda:0')
return masks, iou_pred, sam_tokens_out, object_score_logits代码整体流程一句话总结
用 predict_masks 一次性生成 4 组 mask 及其对应 IoU、token、objectness。
根据 multimask_output 标志和 dynamic_multimask_via_stability 策略,决定到底留几个 mask:
训练/多 mask 模式 → 留 3 个;
测试开 stability → 自动挑 1 个最稳的;
其余 → 直接拿第 0 个。
再按同样逻辑挑一个(或 3 个)token 作为后续跟踪用的"物体记忆"。
把最终 mask、IoU、token、objectness 分数一起返回。
4.3 _dynamic_multimask_via_stability
python
def _dynamic_multimask_via_stability(self, all_mask_logits, all_iou_scores):
"""
在输出单个掩码时,如果当前单掩码输出(基于输出token 0)的稳定性分数低于阈值,我们就从多掩码 输出(基于输出token 1~3)中选择预测IoU分数最高的那个掩码。这是为了确保在点击和跟踪场景下都能获得有效的掩码。
"""
# all_mask_logits: torch.Size([1, 4, 256, 256])
# all_iou_scores: torch.Size([1, 4])
# 从多掩码输出token(1~3)中提取掩码逻辑值和IoU分数
# Extract mask logits and IoU scores from multi-mask output tokens (1~3)
multimask_logits = all_mask_logits[:, 1:, :, :] # [B, 3, H, W]
# multimask_logits: torch.Size([1, 3, 256, 256])
multimask_iou_scores = all_iou_scores[:, 1:] # [B, 3]
# 在每个样本的3个掩码中,找到IoU分数最高的掩码索引
# Find indices of masks with highest IoU score for each sample
best_scores_inds = torch.argmax(multimask_iou_scores, dim=-1) # [B]
# 创建批次索引,用于后续高级索引选择最佳掩码
# Create batch indices for advanced indexing to select best masks
batch_inds = torch.arange(
multimask_iou_scores.size(0), device=all_iou_scores.device
) # [B]
# 使用高级索引选择每个批次中IoU分数最高的多掩码
# Select the best multi-mask for each batch using advanced indexing
best_multimask_logits = multimask_logits[batch_inds, best_scores_inds] # [B, H, W]
best_multimask_logits = best_multimask_logits.unsqueeze(1) # [B, 1, H, W]
best_multimask_iou_scores = multimask_iou_scores[batch_inds, best_scores_inds] # [B]
best_multimask_iou_scores = best_multimask_iou_scores.unsqueeze(1) # [B, 1]
# 从单掩码输出token(0)中提取掩码逻辑值和IoU分数
# Extract mask logits and IoU scores from single-mask output token (0)
singlemask_logits = all_mask_logits[:, 0:1, :, :] # [B, 1, H, W]
singlemask_iou_scores = all_iou_scores[:, 0:1] # [B, 1]
# 计算单掩码的稳定性分数(基于logits的稳定性度量)
# Compute stability score for single-mask (based on logits stability metric)
stability_scores = self._get_stability_scores(singlemask_logits) # [B]
# 判断稳定性分数是否达到阈值(>=阈值视为稳定)
# Determine if stability score meets threshold (>=threshold is stable)
is_stable = stability_scores >= self.dynamic_multimask_stability_thresh # [B]
# 根据稳定性动态选择输出:稳定时使用单掩码,不稳定时使用最佳多掩码
# Dynamically select output based on stability: single-mask if stable, else best multi-mask
mask_logits_out = torch.where(
is_stable[..., None, None].expand_as(singlemask_logits), # 扩展条件以匹配掩码形状
singlemask_logits,
best_multimask_logits,
)
iou_scores_out = torch.where(
is_stable.expand_as(singlemask_iou_scores), # 扩展条件以匹配IoU分数形状
singlemask_iou_scores,
best_multimask_iou_scores,
)
return mask_logits_out, iou_scores_out这段代码实现了动态多掩码选择机制 ,核心思想是通过稳定性阈值智能切换单掩码和多掩码输出,确保在交互式分割(如点击、跟踪)场景下始终获得可靠的掩码。
处理流程:
多掩码候选提取
从输出token 1~3中提取3个候选掩码及其IoU分数
对每个样本,选择IoU预测分数最高的那个掩码作为"最佳多掩码"
单掩码评估
从输出token 0提取单掩码
通过
_get_stability_scores()计算其稳定性分数(通常基于logits的双阈值判定)与预设阈值
dynamic_multimask_stability_thresh比较动态路由决策
稳定情况 (
stability_score ≥ threshold):信任单掩码,直接使用token 0的输出不稳定情况 (
stability_score < threshold):回退到最佳多掩码,利用多候选的鲁棒性形状对齐与输出
使用
torch.where实现条件选择,并通过广播机制确保张量形状匹配返回处理后的掩码逻辑值和IoU分数
设计目的:
提升可靠性:避免低质量单掩码影响用户体验
保持效率:多数情况下使用单掩码,仅在必要时启用多掩码
交互友好:在点击和跟踪场景中提供更稳定的分割结果