文章目录
-
- [分析一个"慢查询"的 EXPLAIN 结果](#分析一个“慢查询”的 EXPLAIN 结果)
- [一、EXPLAIN 各列详解](#一、EXPLAIN 各列详解)
-
- id
- select_type
- table
- partitions
- [type ------ 决定性能好坏](#type —— 决定性能好坏)
- possible_keys
- key
- key_len
- ref
- rows
- filtered
- Extra
-
- [分析你的 `Extra`:](#分析你的
Extra:)
- [分析你的 `Extra`:](#分析你的
- 二、关键列:
- 三、索引分析
- 四、优化实战
- 优化前后对比
示例表结构:
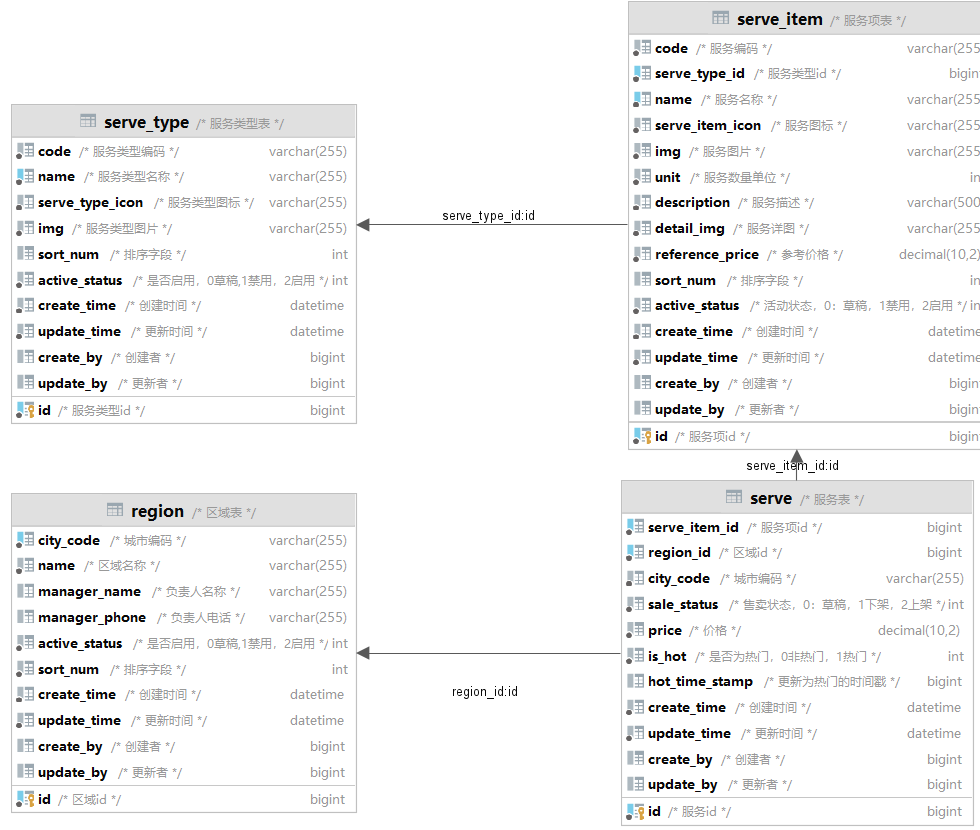
serve_type :服务类型表
serve_item : 服务项表,存储了本平台的家政服务项目
每个服务项都有一个服务类型,一个服务类型下有多个服务项,服务类型与服务项是一对多关系。
region :区域表,存储运营地区信息,一般情况区域表行政级别是市。
serve: 服务表,存储了各个区域运营的服务及相关信息。
一个区域下可以设置多个服务项,一个服务项可以被多个区域设置,region与serve_item是多对多关系。
分析一个"慢查询"的 EXPLAIN 结果
我们先写一个可能变慢的 SQL的执行计划:
获取北京市当前在售且服务项处于激活状态的服务信息
sql
EXPLAIN SELECT
r.name AS city_name,
st.name AS type_name,
si.name AS item_name,
s.price AS current_price
FROM serve s
JOIN region r ON s.region_id = r.id
JOIN serve_item si ON s.serve_item_id = si.id
JOIN serve_type st ON si.serve_type_id = st.id
WHERE
r.name = '北京市'
AND si.active_status = 2
AND s.sale_status = 1;得到如下结果:

一、EXPLAIN 各列详解
id
- 含义:查询中每个 SELECT 的唯一标识符。
- 解读 :
id=1是主查询(最外层)- 如果有子查询,会是
id=2、id=3等
- 本例中只有一个查询,所以全是
1
select_type
- 含义:查询类型。
- 常见值 :
SIMPLE:简单查询(无子查询、UNION)PRIMARY:主查询(外层查询)SUBQUERY:子查询DEPENDENT SUBQUERY:依赖外部查询的子查询
- 本例中都是
SIMPLE,说明是单条查询
table
- 含义:当前正在访问的表名。
- 按顺序是:
si→s→st→r
partitions
- 含义:如果表分区,显示使用的分区。
- 当前为
NULL,说明未使用分区表。
type ------ 决定性能好坏
| 值 | 含义 | 性能等级 |
|---|---|---|
ALL |
全表扫描 | ❌ 最差 |
index |
全索引扫描 | ⚠️ 差 |
range |
范围扫描(如 BETWEEN, IN) |
✅ 中等 |
ref |
使用非唯一索引查找(如 =) |
✅ 好 |
eq_ref |
使用唯一索引查找(如主键、唯一索引) | ✅ 很好 |
const |
常量查找(如主键等于某值) | ✅ 最好 |
分析我们的实际情况:
| 表 | type | 说明 |
|---|---|---|
si |
ALL |
❌ 全表扫描!这是性能瓶颈 |
s |
ref |
✅ 通过 serve_item_id 查找,用了索引 |
st |
eq_ref |
✅ 通过主键 serve_type_id 查找 |
r |
eq_ref |
✅ 通过主键 region_id 查找 |
possible_keys
- 含义:数据库认为可以用于该表的索引列表。
- 例如:
si的possible_keys是PRIMARY, serve_type_id
→ 说明数据库知道id和serve_type_id可以用来加速查询。
但注意:只是"可能"用,不保证真的用!
key
- 含义:实际使用的索引。
- 关键点:
key = NULL→ 没用任何索引(全表扫描)key = PRIMARY→ 用了主键索引key = serve_item_id→ 用了外键索引
分析:
| 表 | key | 是否有效 |
|---|---|---|
si |
NULL |
❌ 没用索引!导致全表扫描 |
s |
serve_item_id |
✅ 用了外键索引 |
st |
PRIMARY |
✅ 用了主键 |
r |
PRIMARY |
✅ 用了主键 |
key_len
- 含义:索引使用的字节数。
你可以通过它判断是否使用了完整的联合索引,通过长度判断使用了几个。
ref
- 含义:表示与索引比较的值或列。
- 例如:
jzo2o-foundations.si.id→ 用si.id去匹配s.serve_item_idjzo2o-foundations.si.serve_type_id→ 用si.serve_type_id去匹配st.id
它告诉你:"我用哪个字段去关联?"
rows
- 含义:MySQL 预估需要扫描的行数。
- 数字越小越好!
- 例如:
rows = 6→ 扫描 6 条记录rows = 100000→ 扫描 10万条 → 很慢!
这个数字是估算值,受统计信息影响。
filtered
- 含义:在使用索引后,还需要过滤多少百分比的数据。
- 范围:0~100
- 例如:
filtered = 16.67→ 索引找到的行中,只有 16.67% 符合条件
如果这个值很低(<10),说明索引没帮上忙,还是得大量过滤。
Extra
- 含义:额外信息.
- 常见值 :
Using where→ 查询中有 WHERE 条件,且不能完全由索引覆盖Using index→ 覆盖索引!只用索引就能返回结果,不用回表Using filesort→ 需要排序,可能很慢Using temporary→ 创建临时表,通常是因为 GROUP BY 或 DISTINCT
分析你的 Extra:
| 表 | Extra | 说明 |
|---|---|---|
si |
Using where |
在全表扫描后才过滤 active_status = 2 |
s |
Using where |
过滤 sale_status = 1 |
st |
NULL |
无需额外操作 |
r |
Using where |
过滤 name = '北京市' |
二、关键列:
要看一段SQL执行计划的关键字段:
1)type :扫描类型,也就是存储引擎是怎么到数据库里拿数据的。
如果出现:ALL全表扫描,index全索引扫描,需要优化。
2)key :实际使用的索引。
一般使用到了索引就没问题
3)rows : 预估扫描行数。
需要避免出现多表join时出现rows超过几千上万,就算用了索引也快不了
- extra : 额外开销。
避免出现额外的排序,如Using temporary,Using filesort等
三、索引分析
重新分析这个执行计划:

第一个表 si:全表扫描(ALL)
- 看到
type: ALL,说明 MySQL 是从头到尾把si表的所有数据都扫了一遍。 - 虽然它只查了 6 行,但"全表扫描"是个危险信号,尤其是当数据量变大时会很慢。
- 为什么? 因为虽然有
PRIMARY和类型id可能的索引,但最终没用上。
第二个表 s:用了索引(ref),但效率一般
type: ref是个好现象,说明用了索引查找。- 它用了
服务id和区域id的组合索引,这是对的。 - 但是
filtered: 10很低,意味着虽然找到了一些行,但大部分都被后续条件过滤掉了。
第三个表 st:很好,直接主键定位(eq_ref)
type: eq_ref,说明是通过主键精确匹配的,非常高效。- 只查了 1 行,也没问题。
- 结论: 这部分已经很完美了,不用改。
第四个表 r:也用了主键(eq_ref),但有点小问题
- 同样是
eq_ref,靠主键查的,看起来没问题。 - 但
filtered: 8.33很低,说明虽然查到了 1 行,但这个行还要被WHERE条件再筛一遍,可能很多不满足。
四、优化实战
1.创建缺失的索引
sql
-- 1. 加速按城市名查询
CREATE INDEX idx_region_name ON region(name);
-- 2. 加速服务项启用状态过滤
CREATE INDEX idx_serve_item_active ON serve_item(active_status);
-- 3. 加速"某区域已上架服务"的组合查询
CREATE INDEX idx_serve_region_sale ON serve(region_id, sale_status);重新执行sql:

可以看到现在的执行计划:
- 所有表都用了索引
- 没有全表扫描(
type=ALL) - 查询效率大幅提升
优化前后对比
| 项目 | 优化前 | 优化后 |
|---|---|---|
si 表 type |
ALL | eq_ref |
si 表 key |
NULL | PRIMARY |
r 表 key |
PRIMARY | idx_region_name |
s 表 key |
serve_item_id | idx_serve_region_sale |
rows 总量 |
~6×2×1×1 = 12 | ~1×2×1×1 = 2 |