前言
在推动AI落地业务的过程中,我们常面临一个两难选择:通用大模型存在"感知瓶颈",难以深入业务细节;而为其专门微调则性价比过低。为破解此局,我们提出了 "大模型泛化理解,小模型垂直执行" 的混合架构。该架构的核心在于发挥各自优势,既保障了对复杂场景的适应能力,又实现了垂直场景下的降本增效,为AI的规模化落地提供了可靠路径。
本节将用一个具体的目标检测小模型,详解其定义以及训练与应用的关键步骤。
一、关于目标检测的定义
目标检测就是让计算机在图片或视频中,不仅能找到 所有我们感兴趣的物体在哪里,还能识别出它们各是什么。
我们可以把它拆解成两个核心任务:
-
定位 :回答"在哪里?"
- 找到图像中所有目标物体的位置,通常用一个矩形框 把它们框出来。
-
分类 :回答"是什么?"
- 识别出框出来的每一个物体具体属于什么类别。
目标检测的最终输出是一系列带标签的框:

为了更好地理解,我们可以把它和相关的技术做个对比:
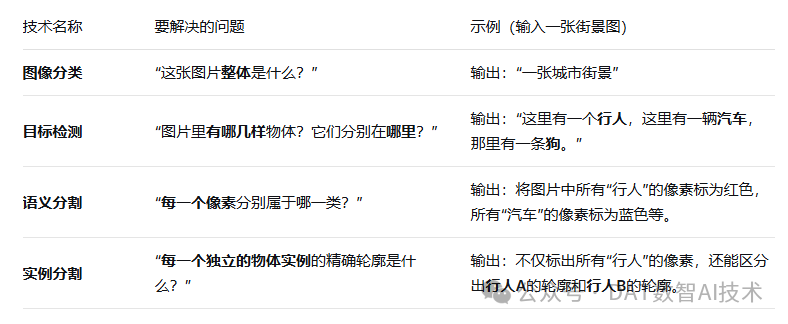
目标检测在理解图像细节** 方面,比简单的图像分类前进了一大步,但又不像分割那样追求极致的像素级精度。它在精度 和计算效率之间取得了很好的平衡,非常适合需要实时感知物体位置和类别的应用。**
目标检测技术发展迅猛,主要可以分为:
-
两阶段检测器:
-
思路:先产生一系列可能包含物体的"候选区域",再对每个候选区域进行分类和微调。
-
代表 :R-CNN系列(Fast R-CNN, Faster R-CNN)。
-
特点:通常精度高,但速度相对慢。
-
-
单阶段检测器:
-
思路:将图像直接输入一个网络,一次性输出所有边界框和类别。
-
代表 :YOLO 、SSD。
-
特点:速度非常快,能满足实时检测需求,精度也在不断逼近两阶段模型。
-
-
基于Transformer的检测器:
-
思路:利用Transformer架构将目标检测视为一个"集合预测"问题。
-
代表 :DETR。
-
特点:简化了检测流程,取得了非常出色的性能。
-
二、如何快速训练一个目标检测模型
训练一个目标检测模型的第一步是:数据的准备;需要拍摄或搜集至少100-200张包含你目标物体的图片。如果没有怎么办?可以P图,或者抠图。
下面我将以训练一个盒子识别的模型为例进行拆解分析:
①我想训练一个识别烟盒子是"万宝路"还是"黄鹤楼"的模型,但是我现在只有两个烟盒子的图片:

②所以, 我需要随便找一个背景图片bk.png用来作为容器承载目标盒子:
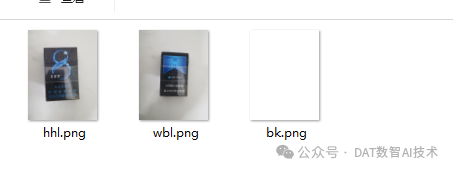
③接着,我将从hhl.png或者wbl.png中抓取到目标盒子,然后往背景图bk.png中进行随机填充,填充后的图片中有8个随机的盒子:

为了确保训练数据充足,我将生成100张随机填充的图片:

④数据准备好了后,下一步就可以开始进行训练了,这里我选择的是快速训练YOLO的模型架构,由于数据量比较少,因此对环境要求不高,这里我选择用自己的window机器CPU进行训练,10分钟后完成训练,并得到一个模型文件:
|-----------------------------------------------------------------|
| 快速训练一个目标检测模型的流程可以归纳为: 准备数据(Roboflow) → 选择模型(YOLOv8) → 训练 → 评估使用 |
⑤模型训练完成后,就可以开始目标检测了:
检测方案1:P一张只有一个目标的图片,验证模型识别的准确性
检测文件为:test1.png
|---------------------------------------------------------------------------------|
|  |
|
检测结果为:

检测输出的带框标注图片为:test1_result.png
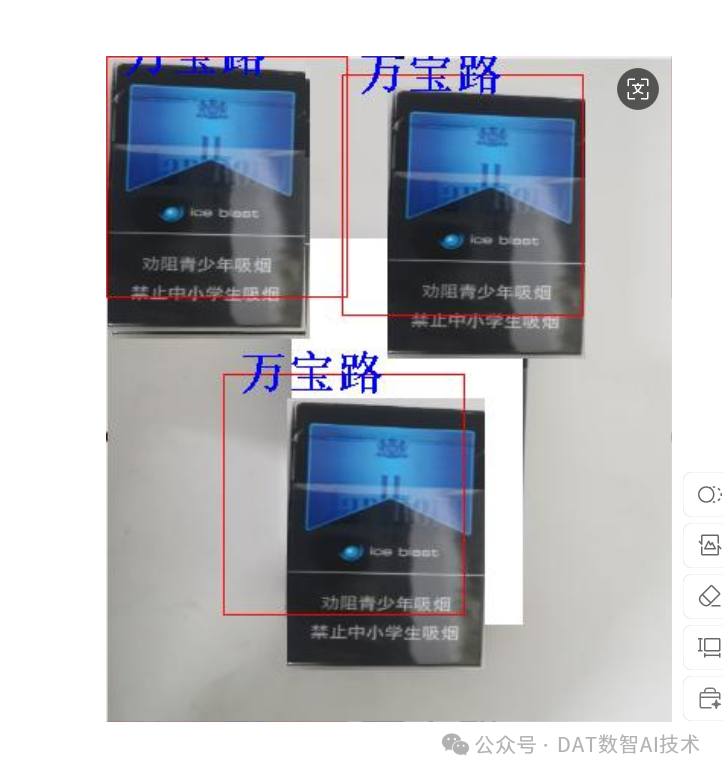
检测结果正确
检测方案2:P一张有2个目标的图片,验证模型识别的准确性
检测文件为:test2.png

检测输出的带框标注图片为:test1_result.png
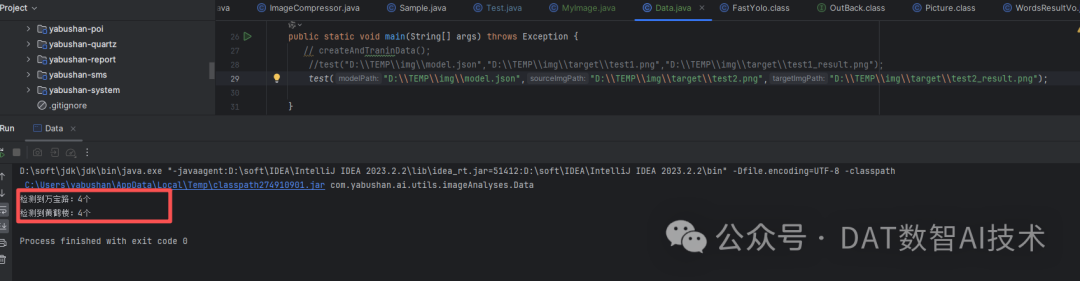
检测输出的带框标注图片为:test1_result.png

检测结果正确
三、目标检测技术的业务场景
目标检测就是让计算机在图片或视频中找到并识别出特定物体 的技术。与仅能识别图像中"有什么"的图像分类不同,目标检测需要同时回答"在哪里 "和"是什么"两个问题。它能够在复杂环境中定位多个物体,并用边界框标出它们的位置和类别。
这项技术从早期的传统机器学习方法,发展到如今基于深度学习的模型,如YOLO、SSD和Faster R-CNN等,准确度和速度都有了惊人提升。而真正让人兴奋的,是这些技术正悄然渗透到我们生活的各个角落,解决着许多传统手段难以应对的挑战。
相关业务场景有如下:
1、防灾减灾:24小时不眠的"守护者"
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 山区公路边坡滑坡是威胁行车安全的重大隐患。传统的人工巡检不仅效率低下,而且无法实现全天候监测。某山区公路管理局引入了基于目标检测的智能监测系统后,情况发生了根本改变。 通过分析沿线摄像头拍摄的实时视频,自动识别边坡上的危险岩石,并监测其位移变化。当系统检测到有石块处于危险位置时,会在毫秒级内发出警报,提醒管理人员及时处理。 |
2、零售行业:24小时自动售货
|-------------------------------------------------------------|
| 传统模式:顾客需要精准地按下代表商品的按钮或输入代码。 目标检测赋能后的模式 :"即拿即走"。 |
工作原理:
-
顾客打开货柜门。
-
内部的摄像头通过实时目标检测 ,识别出顾客拿取的商品品类和数量(例如,一罐可乐、一包薯片)。
-
顾客关门后,系统自动结算,从关联的支付账户中扣款。
总结
目标检测作为计算机视觉的基石技术,其应用几乎遍布所有需要"看得懂"场景的行业,是实现自动化和智能化的关键一环。