前言
Redis (REmote DIctionary Server) 作为当今最流行的内存数据库,已经成为互联网架构中不可或缺的基础组件。从简单的缓存加速到复杂的分布式系统,Redis凭借其卓越的性能和丰富的数据结构,在各种场景中发挥着关键作用。
本文将深入剖析Redis的核心技术,从底层数据结构到高可用架构,从理论原理到生产实践,帮助读者建立对Redis的系统性认知。无论你是初学者还是有经验的开发者,都能从中获得新的启发。
第一章:Redis核心原理与架构
1.1 Redis为什么这么快?
Redis以其极致的性能闻名,在单机环境下可以轻松达到10万+QPS的吞吐量。这种惊人的性能背后,是多个设计决策的协同作用。
1.1.1 内存存储:接近硬件极限的速度
Redis将数据主要存储在内存中,这是其高性能的基石。相比传统关系型数据库需要频繁进行磁盘I/O,内存的访问速度要快3-4个数量级:
性能对比:
内存访问: ~100纳秒
SSD随机读: ~100微秒 (慢1000倍)
机械硬盘随机读: ~10毫秒 (慢10万倍)这种性能差异意味着,在内存中完成的操作几乎可以忽略延迟,这是Redis能够支撑高并发场景的根本原因。
1.1.2 单线程模型:简单即美
Redis的核心设计采用单线程模型处理所有客户端请求。这个看似"反直觉"的设计,实际上带来了巨大的优势:
避免线程上下文切换
- 多线程程序需要频繁进行线程切换,每次切换都需要保存/恢复寄存器、刷新TLB等,开销可达微秒级
- 单线程模型完全避免了这种开销,CPU可以持续执行命令处理逻辑
消除锁竞争
- 多线程访问共享数据需要加锁保护,锁的获取和释放本身就有性能开销
- 更严重的是,锁竞争会导致线程阻塞,降低并发度
- 单线程天然避免了竞态条件,不需要任何锁机制
简化代码逻辑
- 无需考虑线程安全问题,代码逻辑更清晰
- 调试和问题排查更容易
注意: 从Redis 6.0开始,引入了多线程I/O模型来处理网络数据的读写,但命令执行仍然是单线程。这种设计既保留了单线程的优势,又提升了网络I/O的处理能力。
Redis 6.0+ 架构 Main Thread
(命令解析、执行、响应构建) I/O Thread 1
(网络读写) I/O Thread 2
(网络读写)
1.1.3 I/O多路复用:一个线程管理万千连接
既然是单线程,Redis如何同时处理成千上万个客户端连接呢?答案是I/O多路复用技术。
传统阻塞I/O的问题
在传统的阻塞I/O模型中,每个连接需要一个线程处理:
Thread 1 Socket 1
(阻塞等待数据) Thread 2 Socket 2
(阻塞等待数据) Thread 3 Socket 3
(阻塞等待数据) ... ...
这种模式在高并发场景下会产生大量线程,造成:
- 内存消耗大(每个线程需要1MB左右的栈空间)
- 线程切换开销高
- 系统负载重
I/O多路复用的解决方案
I/O多路复用允许单个线程监听多个socket,只有当某个socket有数据到达时才进行处理:
Event Loop (单线程) epoll_wait() 返回就绪的socket列表 处理 Socket A (读取命令) 处理 Socket B (写入响应) 处理 Socket C (读取命令)
Redis根据不同操作系统选择最优的I/O多路复用实现:
- Linux: epoll (支持O(1)复杂度的事件通知)
- macOS/BSD: kqueue
- 其他: select/poll (性能较差,仅作后备方案)
epoll的优势:
- 支持的并发连接数没有上限(select限制1024)
- 采用回调机制,时间复杂度O(1)(select/poll是O(n))
- 只返回活跃的连接,避免了无效遍历
1.1.4 高效的数据结构
Redis针对不同场景精心设计了多种数据结构,每种结构都经过高度优化:
| 数据类型 | 底层实现 | 时间复杂度 |
|---|---|---|
| String | SDS / int / embstr / raw | O(1) |
| Hash | listpack / hashtable | O(1) |
| List | quicklist | O(1) 头尾, O(N) 中间 |
| Set | intset / hashtable | O(1) |
| Sorted Set | listpack / skiplist | O(log N) |
这些数据结构不仅操作效率高,还会根据数据规模自动选择最优的编码方式,兼顾性能和内存占用。
性能对比示例:
假设100万次操作:
Redis (内存+优化结构): ~0.1秒
MySQL (磁盘+B+树): ~10秒
差距: 100倍小结
Redis的高性能是内存存储、单线程模型、I/O多路复用、高效数据结构多方面协同的结果。这些设计选择相互配合,构成了Redis性能的四大支柱:
Redis高性能架构体系 内存存储
(基础) 单线程
(避免竞争) I/O多路复用
(扩展) 高效数据结构
(优化)
1.2 全局哈希表原理
Redis的所有键值对都存储在一个全局的哈希表中,理解这个核心数据结构对于掌握Redis的工作原理至关重要。
1.2.1 哈希表的基本结构
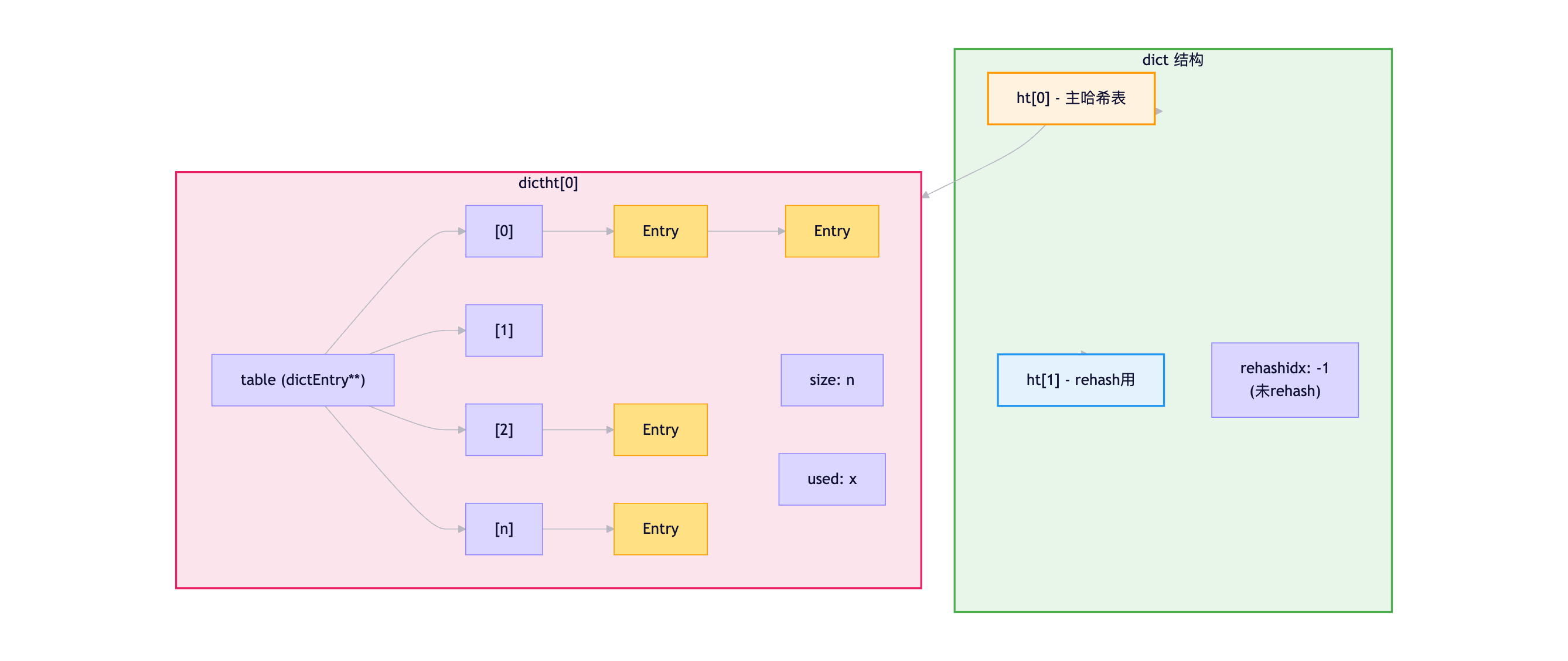
Redis使用的哈希表(dict)结构如下:
dict {
dictType *type; // 类型特定函数
void *privdata; // 私有数据
dictht ht[2]; // 两个哈希表(用于rehash)
long rehashidx; // rehash进度(-1表示未进行)
int iterators; // 当前运行的迭代器数量
}
dictht {
dictEntry **table; // 哈希表数组
unsigned long size; // 哈希表大小(总是2的幂)
unsigned long sizemask; // 大小掩码(size-1)
unsigned long used; // 已有节点数量
}
dictEntry {
void *key; // 键
union {
void *val; // 值
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; // 指向下一个节点(链地址法)
}可视化结构 :
1.2.2 哈希函数与寻址
当执行SET key value时,Redis的操作流程:
步骤1: 计算哈希值
c
hash = dictHashKey(dict, key);
// 使用MurmurHash或SipHash算法,产生均匀分布的哈希值步骤2: 计算索引位置
c
index = hash & dict->ht[0].sizemask;
// 等同于 hash % size,但位运算更快
// 前提是size必须是2的幂步骤3: 存储键值对
- 在tableindex位置创建新的dictEntry
- 如果该位置已有entry,则插入到链表头部(O(1)操作)
查找过程 (GET key):
c
1. 计算key的哈希值: hash = dictHashKey(dict, key)
2. 计算索引: index = hash & sizemask
3. 在table[index]的链表中遍历,比较key
4. 找到则返回value,未找到返回NULL时间复杂度分析:
- 最好情况: O(1) - 没有哈希冲突
- 平均情况: O(1) - 哈希函数分布均匀,链表长度短
- 最坏情况: O(n) - 所有key都冲突到同一个位置(实际几乎不可能)
1.2.3 链地址法解决哈希冲突
当多个key计算出相同的索引时,就发生了哈希冲突。Redis采用链地址法(Separate Chaining)解决:
哈希表 table5 Entry
(key1) table5 Entry
(key2) Entry
(key3) NULL hash(key1) % size = 5 hash(key2) % size = 5 hash(key3) % size = 5
插入策略:
- 新节点总是插入到链表头部(头插法)
- 优点: O(1)插入时间
- 缺点: 可能导致链表越来越长,降低查询性能
负载因子:
load_factor = used / size
例如:
used = 1000 (已存储1000个key)
size = 1024 (哈希表大小)
load_factor = 1000/1024 ≈ 0.98当负载因子过高时,链表会变长,需要扩容(rehash)。
1.2.4 渐进式Rehash:巧妙的动态扩容
为什么需要rehash?
随着数据增加,负载因子升高,查询性能下降。此时需要扩容:
- 扩容: 当
used >= size时触发(负载因子≥1) - 缩容: 当
used < size/10时触发(负载因子<0.1)
传统rehash的问题:
如果哈希表有100万个key,一次性rehash需要:
- 分配新的哈希表(2倍大小)
- 遍历所有旧entry
- 重新计算哈希值并插入新表
- 释放旧表
这个过程可能耗时数百毫秒,导致Redis阻塞,无法处理请求!
渐进式Rehash的解决方案:
Redis采用分而治之的策略,将rehash工作分散到多次操作中:
初始状态:
dict {
ht[0]: 有数据
ht[1]: 空
rehashidx: -1
}
触发rehash:
1. 为ht[1]分配空间(size = ht[0].used * 2)
2. 设置rehashidx = 0
渐进式迁移:
每次执行添加、删除、查找、更新操作时:
1. 顺带将ht[0].table[rehashidx]的所有entry迁移到ht[1]
2. rehashidx++
3. 当ht[0]全部迁移完成,释放ht[0],ht[1]变为ht[0],rehashidx=-1
额外的定时任务:
每100ms执行1ms的批量迁移,避免长时间不操作导致rehash无法完成渐进式rehash期间的操作:
查找操作:
- 先在ht[0]查找
- 未找到再在ht[1]查找
插入操作:
- 一律插入ht[1](保证ht[0]的数据只减不增)
删除操作:
- 在ht[0]和ht[1]都尝试删除可视化流程:

性能优势:
传统一次性rehash:
阻塞时间: 100ms (100万key)
影响: 所有请求等待,客户端超时渐进式rehash:
每次操作额外开销: ~1微秒 (迁移一个桶)
总阻塞时间: 0
影响: 几乎无感知1.2.5 实战示例:观察rehash过程
我们可以通过INFO stats命令观察rehash状态:
bash
redis-cli INFO stats | grep -E "used_memory|keys|expires"输出示例:
# Stats
total_commands_processed:1000000
used_memory:10485760
used_memory_human:10.00M
keys=500000
expires=100000模拟大量写入触发rehash:
bash
# 写入100万个key
redis-cli --eval bulk_insert.lua
# 观察内存变化
redis-cli INFO memory | grep used_memory_rss小结
Redis全局哈希表的设计体现了工程上的精妙权衡:
- 哈希表: 提供O(1)的平均查找性能
- 链地址法: 简单有效地解决冲突
- 渐进式rehash: 保证扩容过程不阻塞服务
- 双哈希表: 支持渐进式rehash的巧妙设计
这种设计让Redis能够在保持高性能的同时,优雅地处理数据规模的动态变化。
第二章:数据结构与底层实现
Redis不仅提供了丰富的数据类型供应用层使用,更在底层实现了多种高效的数据结构。理解这种"上层类型"与"底层编码"的映射关系,是掌握Redis性能优化的关键。
2.1 数据类型与底层编码的映射关系
Redis遵循"内存优化优先"的原则,会根据数据的特征自动选择最优的底层编码:
应用层数据类型 → 底层编码方式 → 转换条件
String
├── int (整数值,能用long表示)
├── embstr (字符串,≤44字节)
└── raw (字符串,>44字节)
Hash
├── listpack (元素<512 && 所有key/value<64字节)
└── hashtable (元素≥512 || 任一key/value≥64字节)
List
└── quicklist (统一使用,内部是ziplist双向链表)
Set
├── intset (全是整数 && 元素<512)
└── hashtable (非整数 || 元素≥512)
Sorted Set
├── listpack (元素<128 && 所有member<64字节)
└── skiplist+dict (元素≥128 || 任一member≥64字节)编码转换示例:
bash
# String类型的编码变化
127.0.0.1:6379> SET num 100
OK
127.0.0.1:6379> OBJECT ENCODING num
"int"
127.0.0.1:6379> SET short "hello"
OK
127.0.0.1:6379> OBJECT ENCODING short
"embstr"
127.0.0.1:6379> SET long "this is a very long string that exceeds 44 bytes limit..."
OK
127.0.0.1:6379> OBJECT ENCODING long
"raw"
# Hash类型的编码变化
127.0.0.1:6379> HSET user name "Alice"
(integer) 1
127.0.0.1:6379> OBJECT ENCODING user
"listpack"
# 插入512个字段后
127.0.0.1:6379> HSET user field512 "value"
(integer) 1
127.0.0.1:6379> OBJECT ENCODING user
"hashtable"为什么要有多种编码?
- 内存优化: 小数据量时用紧凑的编码(如listpack),节省内存
- 性能优化: 大数据量时用高效的编码(如hashtable、skiplist),保证性能
- 自动转换: 开发者无需关心,Redis自动选择最优编码
2.2 五大基础数据类型详解
2.2.1 String:最简单也最复杂
应用场景:
- 缓存:用户信息、配置数据、HTML片段
- 计数器:网站访问量、点赞数、库存数
- 分布式锁:基于SETNX实现
- 限流:基于INCR+EXPIRE实现
底层实现:
String类型看似简单,实际上有三种编码方式:
1. int编码
当value可以用long类型(8字节)表示时,直接存储整数值:
c
typedef struct redisObject {
unsigned type:4; // 类型:OBJ_STRING
unsigned encoding:4; // 编码:OBJ_ENCODING_INT
void *ptr; // 直接存储整数值
} robj;优势:
- 节省内存(不需要额外的字符串结构)
- 支持INCR/DECR等原子操作
示例:
bash
127.0.0.1:6379> SET counter 100
OK
127.0.0.1:6379> INCR counter
(integer) 101
127.0.0.1:6379> OBJECT ENCODING counter
"int"2. embstr编码(embedded string)
当字符串长度≤44字节时,使用embstr编码:
一次内存分配 embstr编码 (连续内存) SDS Header + buf
(最多44字节字符串) redisObject
(16 bytes)
优势:
- 只需一次内存分配(raw需要两次)
- 内存连续,缓存友好
- 释放内存只需一次free
为什么是44字节?
Redis对象内存分配单元: 64字节
redisObject: 16字节
SDS header: 3字节(len, alloc, flags)
SDS 空字符结尾: 1字节
可用空间: 64 - 16 - 3 - 1 = 44字节3. raw编码
当字符串长度>44字节时,使用raw编码:
两次内存分配 ptr指针 redisObject SDS Header
len, alloc, flags
buf (大字符串)
缺点:
- 两次内存分配
- 两次内存释放
但对于大字符串,这种分离的设计更灵活(可以独立扩容SDS而不影响redisObject)。
SDS (Simple Dynamic String)
Redis自己实现的字符串结构,相比C字符串有巨大优势:
c
struct sdshdr {
uint32_t len; // 当前字符串长度
uint32_t alloc; // 已分配容量(不包含header和'\0')
unsigned char flags; // 类型标志
char buf[]; // 字节数组
};SDS vs C字符串:
| 特性 | C字符串 | SDS |
|---|---|---|
| 获取长度 | O(n)遍历 | O(1)读取len字段 |
| 二进制安全 | 否(遇到'\0'截断) | 是(通过len判断) |
| 缓冲区溢出 | 容易(strcat不检查) | 自动扩容,安全 |
| 内存重分配 | 每次修改都重分配 | 空间预分配+惰性释放 |
空间预分配策略:
c
// 字符串增长时
if (newlen < 1MB) {
alloc = newlen * 2; // 翻倍分配
} else {
alloc = newlen + 1MB; // 额外分配1MB
}示例:
原字符串: len=10, alloc=10, buf="hello redis"
追加 " world": len=16
实际分配: alloc=32 (预分配了16字节空闲空间)
下次追加: 如果<16字节,无需重新分配内存惰性空间释放:
原字符串: len=100, alloc=100
截断到10字节: len=10, alloc=100 (保留90字节备用)
好处: 下次增长时可能直接使用,避免重分配实战案例:计数器场景
java
// 商品库存扣减
@Service
public class StockService {
@Autowired
private StringRedisTemplate redisTemplate;
public boolean decrStock(Long productId) {
String key = "stock:" + productId;
Long stock = redisTemplate.opsForValue().decrement(key);
return stock != null && stock >= 0;
}
}Redis内部执行:
- 读取key对应的value(int编码,直接获取整数)
- 减1
- 存回(仍是int编码)
- 全过程O(1),无锁,原子性
2.2.2 Hash:对象存储的最佳选择
应用场景:
- 存储对象:用户信息、商品详情、订单数据
- 购物车:field=商品ID, value=数量
- Session共享:分布式系统的会话存储
为什么用Hash而不是String?
方案对比:
方案1: String存JSON
SET user:1001 '{"name":"Alice","age":25,"email":"alice@example.com"}'
缺点:
- 修改单个字段需要全量读取+反序列化+修改+序列化+全量写入
- 内存占用高(JSON格式本身有冗余)
方案2: String存多个key
SET user:1001:name "Alice"
SET user:1001:age 25
SET user:1001:email "alice@example.com"
缺点:
- key数量多,占用内存(每个key都有redisObject开销)
- 无法原子性操作多个字段
方案3: Hash ✅
HSET user:1001 name "Alice" age 25 email "alice@example.com"
优点:
- 支持单字段操作(HGET/HSET/HINCRBY)
- 内存占用少(小hash使用listpack紧凑编码)
- 可以原子性操作多个字段(HMSET)底层实现:
1. listpack编码(紧凑列表)
条件:
- 字段数量 < 512 (hash-max-listpack-entries)
- 所有key和value长度 < 64字节 (hash-max-listpack-value)
结构:
存储方式 entry结构 listpack结构 value1 key1 key2 value2 key3 value3 encoding data len total_bytes | num_elements entry1 entry2 ...
优势:
- 内存连续,缓存友好
- 无指针开销(数组访问)
- 内存占用极小
缺点:
- 查找O(n)(需要遍历)
- 插入/删除需要移动数据
2. hashtable编码
当超过阈值时,转换为hashtable(dict结构,见1.2节):
dict结构 (Hash类型) ht0 dictEntry
key: name
value: Alice dictEntry
key: age
value: 25 dictEntry
key: email
value: ...
优势:
- 查找/插入/删除 O(1)
- 支持大数据量
内存对比:
100个字段的对象:
listpack: ~5KB
hashtable: ~15KB (包含指针、dictEntry等开销)实战案例:用户信息缓存
java
@Service
public class UserCacheService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// 缓存用户信息
public void cacheUser(User user) {
String key = "user:" + user.getId();
Map<String, Object> userMap = new HashMap<>();
userMap.put("name", user.getName());
userMap.put("age", user.getAge());
userMap.put("email", user.getEmail());
userMap.put("vip", user.isVip());
redisTemplate.opsForHash().putAll(key, userMap);
redisTemplate.expire(key, 30, TimeUnit.MINUTES);
}
// 更新单个字段
public void updateUserAge(Long userId, int age) {
String key = "user:" + userId;
redisTemplate.opsForHash().put(key, "age", age);
}
// 增加积分
public Long incrPoints(Long userId, long delta) {
String key = "user:" + userId;
return redisTemplate.opsForHash().increment(key, "points", delta);
}
}内存优化技巧:
如果有大量小对象,可以使用Hash分段存储:
优化方案 不优化方案 users:1 → Hash
(id 1-100) field '1001' → JSON field '1002' → JSON ... users:2 → Hash
(id 101-200) ... user:1001 → Hash user:1002 → Hash ... user:9999 → Hash 每个Hash都有
redisObject开销 优势:
- redisObject数量减少100倍
- 每个Hash可用listpack编码
- 内存节省50%+
注意: 这种优化需要权衡查询复杂度和内存节省。
2.2.3 List:双端队列的完美实现
应用场景:
- 消息队列:异步任务处理(LPUSH + BRPOP)
- 时间线:微博/朋友圈动态(LPUSH + LRANGE)
- 最新列表:最新评论、最新订单
- 栈/队列:LPUSH+LPOP(栈)、LPUSH+RPOP(队列)
底层实现:quicklist
Redis 3.2之后,List统一使用quicklist 编码,它是双向链表 和ziplist的混合体:
quicklist结构 Node1 head Node2 Node3 tail ziplist
e1,e2 ziplist
e3,e4 ziplist
e5,e6
为什么不用单一数据结构?
纯双向链表:
优点: 插入删除O(1)
缺点: 每个节点都有prev/next指针,内存开销大
内存不连续,缓存不友好
纯ziplist:
优点: 内存连续,紧凑
缺点: 插入删除需要移动数据,大列表性能差
可能触发连锁更新(cascade update)
quicklist (最优):
每个节点是一个ziplist,兼顾两者优势
- 节点间用链表连接,插入删除快
- 节点内用ziplist,内存紧凑quicklist配置参数:
conf
# 每个ziplist的最大大小
list-max-ziplist-size -2
# -5: 64KB
# -4: 32KB
# -3: 16KB
# -2: 8KB (默认)
# -1: 4KB
# 正数: 表示元素个数
# 压缩深度(两端不压缩的节点数)
list-compress-depth 0
# 0: 不压缩(默认)
# 1: 首尾各1个节点不压缩,中间压缩
# 2: 首尾各2个节点不压缩,中间压缩quicklist的优化策略:
场景1: 访问头尾频繁(消息队列)
list-compress-depth 1
效果: 保持头尾快速访问,中间节点LZF压缩节省内存
场景2: 随机访问(时间线翻页)
list-compress-depth 0
效果: 不压缩,牺牲内存换取访问速度实战案例:异步任务队列
生产者:
java
@Service
public class TaskProducer {
@Autowired
private StringRedisTemplate redisTemplate;
public void pushTask(Task task) {
String taskJson = JSON.toJSONString(task);
redisTemplate.opsForList().leftPush("task:queue", taskJson);
}
}消费者:
java
@Service
public class TaskConsumer {
@Autowired
private StringRedisTemplate redisTemplate;
@Scheduled(fixedDelay = 100)
public void consumeTask() {
// 阻塞式弹出,超时时间5秒
String taskJson = redisTemplate.opsForList()
.rightPop("task:queue", 5, TimeUnit.SECONDS);
if (taskJson != null) {
Task task = JSON.parseObject(taskJson, Task.class);
processTask(task);
}
}
}为什么用BRPOP而不是RPOP循环?
方案1: 轮询 (不推荐)
while (true) {
String task = RPOP("task:queue");
if (task == null) {
sleep(100ms); // 空转,浪费CPU
}
}
方案2: 阻塞弹出 (推荐)
while (true) {
String task = BRPOP("task:queue", 5);
// 无任务时阻塞等待,不占CPU
}2.2.4 Set:高效去重的利器
应用场景:
- 去重集合:点赞用户、投票用户、标签集合
- 共同好友:SINTER计算交集
- 推荐系统:SDIFF计算差集(你可能认识的人)
- 抽奖系统:SRANDMEMBER随机抽取
底层实现:
1. intset编码
条件:
- 所有元素都是整数
- 元素个数 < 512 (set-max-intset-entries)
结构:
c
typedef struct intset {
uint32_t encoding; // 编码方式:int16/int32/int64
uint32_t length; // 元素个数
int8_t contents[]; // 有序数组
} intset;特点:
- 内存紧凑(无指针开销)
- 有序数组,支持二分查找O(logN)
- 自动升级编码(int16→int32→int64)
编码升级示例:
初始状态 (int16编码):
intset {
encoding = INT16
length = 3
contents = [1, 10, 100] (每个元素2字节)
}
插入65535 (超过int16范围):
intset {
encoding = INT32 (升级!)
length = 4
contents = [1, 10, 100, 65535] (每个元素4字节)
}
注意: 只升级,不降级(删除大数也不会降级编码)2. hashtable编码
当条件不满足时,转为hashtable:
dict结构 (Set类型) ht0 dictEntry
key: user:1001
value: NULL dictEntry
key: user:1002
value: NULL dictEntry
key: user:1003
value: NULL 注意: Set只用key
value都是NULL
实战案例:点赞功能
java
@Service
public class LikeService {
@Autowired
private StringRedisTemplate redisTemplate;
// 点赞
public boolean like(Long articleId, Long userId) {
String key = "article:like:" + articleId;
Long result = redisTemplate.opsForSet().add(key, userId.toString());
return result != null && result > 0;
}
// 取消点赞
public boolean unlike(Long articleId, Long userId) {
String key = "article:like:" + articleId;
Long result = redisTemplate.opsForSet().remove(key, userId.toString());
return result != null && result > 0;
}
// 判断是否点赞
public boolean hasLiked(Long articleId, Long userId) {
String key = "article:like:" + articleId;
return redisTemplate.opsForSet().isMember(key, userId.toString());
}
// 获取点赞数
public long getLikeCount(Long articleId) {
String key = "article:like:" + articleId;
Long size = redisTemplate.opsForSet().size(key);
return size != null ? size : 0;
}
// 共同点赞(两篇文章都点赞的用户)
public Set<String> getCommonLikers(Long articleId1, Long articleId2) {
String key1 = "article:like:" + articleId1;
String key2 = "article:like:" + articleId2;
return redisTemplate.opsForSet().intersect(key1, key2);
}
}集合运算示例:
bash
# 创建三个用户的好友集合
SADD user:1001:friends "2001" "2002" "2003" "2004"
SADD user:1002:friends "2003" "2004" "2005" "2006"
SADD user:1003:friends "2001" "2005" "2007"
# 共同好友(交集)
SINTER user:1001:friends user:1002:friends
# 输出: "2003" "2004"
# 可能认识的人(1001的好友的好友,但不是1001的好友)
SDIFF user:1002:friends user:1001:friends
# 输出: "2005" "2006"
# 所有涉及的人(并集)
SUNION user:1001:friends user:1002:friends user:1003:friends
# 输出: "2001" "2002" "2003" "2004" "2005" "2006" "2007"2.2.5 Sorted Set:排行榜的终极方案
应用场景:
- 排行榜:游戏积分、文章热度、商品销量
- 延迟队列:score=时间戳,按时间顺序处理
- 带权重任务:score=优先级
- 范围查询:价格区间、时间区间
底层实现:
1. listpack编码
条件:
- 元素个数 < 128 (zset-max-listpack-entries)
- 所有member长度 < 64字节 (zset-max-listpack-value)
结构:
listpack存储:
[member1, score1, member2, score2, member3, score3, ...]
按score有序排列2. skiplist + hashtable 编码
当超过阈值时,使用双结构:
Sorted Set 双结构 skiplist
(跳表)
按score排序 dict
(哈希表)
member→score 范围查询
O(logN + M) 查询分数
O(1)
为什么需要两个结构?
只用skiplist:
- 范围查询: O(logN + M) ✅
- 查询分数: O(logN) ❌
只用hashtable:
- 查询分数: O(1) ✅
- 范围查询: O(N) ❌ (需要全表扫描+排序)
skiplist + dict:
- 范围查询: O(logN + M) ✅ (用skiplist)
- 查询分数: O(1) ✅ (用dict)
- 代价: 额外的内存(存两份member)跳表(Skiplist)原理:
跳表是一种随机化的多层链表,提供O(logN)的查找性能:
Level 0 (最底层) Level 1 Level 2 Level 3 NULL 80 70 60 50 40 30 20 10 1 NULL 80 70 60 50 40 30 20 10 1 NULL 80 50 20 1 NULL 50 1
查找过程 (查找score=50):
1. 从最高层开始: L3[1] → L3[50] (找到!)
2. 时间复杂度: O(logN)
对比:
有序数组二分查找: O(logN) 查找,但插入O(N)
跳表: O(logN) 查找,O(logN) 插入跳表节点结构:
c
typedef struct zskiplistNode {
sds ele; // member
double score; // 分数
struct zskiplistNode *backward; // 后退指针(用于ZREVRANGE)
struct zskiplistLevel {
struct zskiplistNode *forward; // 前进指针
unsigned long span; // 跨度(用于计算rank)
} level[]; // 层数组
} zskiplistNode;实战案例:游戏排行榜
java
@Service
public class LeaderboardService {
@Autowired
private StringRedisTemplate redisTemplate;
// 更新玩家分数
public void updateScore(Long userId, double score) {
String key = "game:leaderboard";
redisTemplate.opsForZSet().add(key, userId.toString(), score);
}
// 增加分数(杀怪、完成任务等)
public Double incrScore(Long userId, double delta) {
String key = "game:leaderboard";
return redisTemplate.opsForZSet().incrementScore(key, userId.toString(), delta);
}
// 获取TOP100
public Set<ZSetOperations.TypedTuple<String>> getTop100() {
String key = "game:leaderboard";
// 按score降序,取前100
return redisTemplate.opsForZSet()
.reverseRangeWithScores(key, 0, 99);
}
// 获取玩家排名(从1开始)
public Long getRank(Long userId) {
String key = "game:leaderboard";
// reverseRank返回降序排名(0开始)
Long rank = redisTemplate.opsForZSet()
.reverseRank(key, userId.toString());
return rank != null ? rank + 1 : null;
}
// 获取玩家分数
public Double getScore(Long userId) {
String key = "game:leaderboard";
return redisTemplate.opsForZSet().score(key, userId.toString());
}
// 获取分数在[min, max]区间的玩家
public Set<String> getPlayersByScoreRange(double min, double max) {
String key = "game:leaderboard";
return redisTemplate.opsForZSet().rangeByScore(key, min, max);
}
}延迟队列实现:
java
@Service
public class DelayQueue {
@Autowired
private StringRedisTemplate redisTemplate;
// 添加延迟任务(score=执行时间戳)
public void addTask(String taskId, long executeTime) {
String key = "delay:queue";
redisTemplate.opsForZSet().add(key, taskId, executeTime);
}
// 消费到期任务
@Scheduled(fixedDelay = 1000)
public void consumeTasks() {
String key = "delay:queue";
long now = System.currentTimeMillis();
// 获取到期任务(score <= now)
Set<String> tasks = redisTemplate.opsForZSet()
.rangeByScore(key, 0, now);
if (tasks != null && !tasks.isEmpty()) {
for (String taskId : tasks) {
// 处理任务
processTask(taskId);
// 删除已处理任务
redisTemplate.opsForZSet().remove(key, taskId);
}
}
}
}2.3 高级数据类型
2.3.1 HyperLogLog:大数据量的基数统计
应用场景:
- UV统计:网站独立访客数
- 去重计数:搜索词去重、在线用户数
- 允许误差的大数据量统计
原理:
HyperLogLog是一种概率算法,用极小的内存(12KB)估算大数据集的基数(去重后的数量):
传统方案:
Set存储所有元素 → 统计size
问题: 1亿个用户ID,需要~1GB内存
HyperLogLog方案:
固定12KB内存,估算1亿个元素
误差率: ~0.81%基本命令:
bash
# 添加元素
PFADD uv:20250122 "user:1001" "user:1002" "user:1003"
(integer) 1
# 获取基数估算值
PFCOUNT uv:20250122
(integer) 3
# 合并多个HyperLogLog
PFADD uv:20250122 "user:1001" "user:1002"
PFADD uv:20250123 "user:1002" "user:1003"
PFMERGE uv:week uv:20250122 uv:20250123
PFCOUNT uv:week
(integer) 3 # 去重后的总数实战案例:UV统计
java
@Service
public class UVStatService {
@Autowired
private StringRedisTemplate redisTemplate;
// 记录访问
public void recordVisit(String userId, LocalDate date) {
String key = "uv:" + date.toString();
redisTemplate.opsForHyperLogLog().add(key, userId);
// 设置过期时间(保留30天)
redisTemplate.expire(key, 30, TimeUnit.DAYS);
}
// 获取某天UV
public long getDailyUV(LocalDate date) {
String key = "uv:" + date.toString();
Long count = redisTemplate.opsForHyperLogLog().size(key);
return count != null ? count : 0;
}
// 获取周UV(合并7天数据)
public long getWeeklyUV(LocalDate endDate) {
String targetKey = "uv:week:" + endDate.toString();
String[] sourceKeys = new String[7];
for (int i = 0; i < 7; i++) {
sourceKeys[i] = "uv:" + endDate.minusDays(i).toString();
}
redisTemplate.opsForHyperLogLog().union(targetKey, sourceKeys);
Long count = redisTemplate.opsForHyperLogLog().size(targetKey);
redisTemplate.delete(targetKey); // 清理临时key
return count != null ? count : 0;
}
}何时用HyperLogLog?
使用条件:
✅ 数据量大(百万级以上)
✅ 只需要基数统计,不需要具体元素
✅ 可以容忍0.81%的误差
不适用场景:
❌ 需要精确计数
❌ 需要获取具体元素
❌ 数据量小(直接用Set更合适)2.3.2 Bitmaps:极致的空间效率
应用场景:
- 签到打卡:每天1位,1年只需46字节
- 用户行为标记:是否活跃、是否付费等布尔状态
- 在线状态:1=在线,0=离线
- DAU/WAU/MAU统计
原理:
Bitmap本质是String类型,通过位操作实现:
String "hello" 的二进制表示:
h e l l o
01101000 01100101 01101100 01101100 01101111
↑ bit0 ↑ bit39基本命令:
bash
# 设置位
SETBIT user:1001:signin:202501 0 1 # 1月1日签到
SETBIT user:1001:signin:202501 1 1 # 1月2日签到
SETBIT user:1001:signin:202501 2 0 # 1月3日未签到
# 获取位
GETBIT user:1001:signin:202501 0
(integer) 1
# 统计1的个数
BITCOUNT user:1001:signin:202501
(integer) 2 # 签到2天
# 位运算
BITOP AND result key1 key2 # 交集
BITOP OR result key1 key2 # 并集
BITOP XOR result key1 key2 # 异或实战案例:签到系统
java
@Service
public class SignInService {
@Autowired
private StringRedisTemplate redisTemplate;
// 签到
public boolean signIn(Long userId, LocalDate date) {
String key = buildKey(userId, date);
int dayOfMonth = date.getDayOfMonth();
// offset从0开始,第1天对应offset=0
return redisTemplate.opsForValue()
.setBit(key, dayOfMonth - 1, true);
}
// 检查是否签到
public boolean hasSignedIn(Long userId, LocalDate date) {
String key = buildKey(userId, date);
int dayOfMonth = date.getDayOfMonth();
Boolean bit = redisTemplate.opsForValue()
.getBit(key, dayOfMonth - 1);
return bit != null && bit;
}
// 获取本月签到天数
public long getMonthlySignInCount(Long userId, LocalDate date) {
String key = buildKey(userId, date);
// 使用Lua脚本执行BITCOUNT
Long count = redisTemplate.execute(
(RedisCallback<Long>) con -> con.bitCount(key.getBytes())
);
return count != null ? count : 0;
}
// 获取连续签到天数
public int getContinuousSignInDays(Long userId) {
LocalDate today = LocalDate.now();
int continuous = 0;
for (int i = 0; i < 365; i++) {
LocalDate date = today.minusDays(i);
if (hasSignedIn(userId, date)) {
continuous++;
} else {
break;
}
}
return continuous;
}
private String buildKey(Long userId, LocalDate date) {
return String.format("user:%d:signin:%d%02d",
userId, date.getYear(), date.getMonthValue());
}
}DAU统计:
java
@Service
public class DAUStatService {
@Autowired
private StringRedisTemplate redisTemplate;
// 记录用户活跃
public void recordActive(Long userId, LocalDate date) {
String key = "dau:" + date.toString();
redisTemplate.opsForValue().setBit(key, userId, true);
}
// 获取DAU
public long getDAU(LocalDate date) {
String key = "dau:" + date.toString();
return redisTemplate.execute(
(RedisCallback<Long>) con -> con.bitCount(key.getBytes())
);
}
// 获取连续7天都活跃的用户数(留存)
public long get7DayRetention(LocalDate endDate) {
String[] keys = new String[7];
for (int i = 0; i < 7; i++) {
keys[i] = "dau:" + endDate.minusDays(i).toString();
}
String resultKey = "retention:7day:" + endDate.toString();
// AND运算:所有天都为1的位才为1
redisTemplate.execute((RedisCallback<Void>) con -> {
con.bitOp(RedisStringCommands.BitOperation.AND,
resultKey.getBytes(),
Arrays.stream(keys).map(String::getBytes).toArray(byte[][]::new));
return null;
});
long count = redisTemplate.execute(
(RedisCallback<Long>) con -> con.bitCount(resultKey.getBytes())
);
redisTemplate.delete(resultKey);
return count;
}
}内存效率对比:
场景: 1亿用户的签到数据(一个月)
方案1: Set存储
SET user:signin:20250122 → {1001, 1002, 1003, ...}
内存: ~1.6GB (每个ID按16字节计算)
方案2: Bitmap
SETBIT user:signin:20250122 1001 1
SETBIT user:signin:20250122 1002 1
内存: ~12MB (1亿位 = 12.5MB)
节省: 99%以上!2.3.3 GEO:地理位置神器
应用场景:
- 附近的人/店铺/车辆
- 外卖配送范围判断
- 地理围栏(Geofencing)
- 共享单车查找
原理:
GEO基于Sorted Set 实现,使用GeoHash算法将二维坐标编码为一维整数作为score:
经纬度坐标
(116.397128, 39.916527) GeoHash编码算法 52位整数
4069885552316445 存入Sorted Set
ZADD locations 4069885552316445 'place:1'
基本命令:
bash
# 添加地理位置
GEOADD locations 116.397128 39.916527 "Tiananmen"
GEOADD locations 116.403414 39.924091 "Beijing Railway Station"
# 获取坐标
GEOPOS locations "Tiananmen"
1) 1) "116.39712899923324585"
2) "39.9165270024036098"
# 计算距离
GEODIST locations "Tiananmen" "Beijing Railway Station" km
"1.2345"
# 查找半径范围内的位置
GEORADIUS locations 116.397128 39.916527 5 km WITHDIST WITHCOORD
1) 1) "Tiananmen"
2) "0.0000"
3) 1) "116.39712899923324585"
2) "39.9165270024036098"
2) 1) "Beijing Railway Station"
2) "1.2345"
3) 1) "116.40341401100158691"
2) "39.92409008156928252"
# 以某个成员为中心查找
GEORADIUSBYMEMBER locations "Tiananmen" 5 km实战案例:附近的充电桩
java
@Service
public class ChargingStationService {
@Autowired
private StringRedisTemplate redisTemplate;
// 添加充电桩位置
public void addStation(Long stationId, double longitude, double latitude) {
String key = "geo:charging:stations";
redisTemplate.opsForGeo().add(key,
new Point(longitude, latitude),
"station:" + stationId);
}
// 查找附近的充电桩
public List<StationDTO> findNearbyStations(
double longitude, double latitude, double radiusKm) {
String key = "geo:charging:stations";
// 搜索参数
Circle circle = new Circle(
new Point(longitude, latitude),
new Distance(radiusKm, Metrics.KILOMETERS)
);
RedisGeoCommands.GeoRadiusCommandArgs args =
RedisGeoCommands.GeoRadiusCommandArgs.newGeoRadiusArgs()
.includeDistance() // 包含距离
.includeCoordinates() // 包含坐标
.sortAscending() // 按距离升序
.limit(20); // 最多返回20个
GeoResults<RedisGeoCommands.GeoLocation<String>> results =
redisTemplate.opsForGeo().radius(key, circle, args);
if (results == null) {
return Collections.emptyList();
}
return results.getContent().stream()
.map(result -> {
String member = result.getContent().getName();
Long stationId = Long.parseLong(member.replace("station:", ""));
Point point = result.getContent().getPoint();
Distance distance = result.getDistance();
return new StationDTO(
stationId,
point.getX(),
point.getY(),
distance.getValue()
);
})
.collect(Collectors.toList());
}
// 判断是否在配送范围内
public boolean isInDeliveryRange(
Long stationId, double userLng, double userLat, double maxDistanceKm) {
String key = "geo:charging:stations";
String member = "station:" + stationId;
// 获取充电桩坐标
List<Point> points = redisTemplate.opsForGeo().position(key, member);
if (points == null || points.isEmpty() || points.get(0) == null) {
return false;
}
Point stationPoint = points.get(0);
// 计算距离
Distance distance = redisTemplate.opsForGeo().distance(
key,
member,
new Point(userLng, userLat),
Metrics.KILOMETERS
);
return distance != null && distance.getValue() <= maxDistanceKm;
}
}GeoHash的优势:
1. 降维:
二维坐标 → 一维整数
可以利用Sorted Set的范围查询
2. 前缀匹配:
GeoHash前缀相同 = 地理位置接近
wx4g0ec → 精度约19米
wx4g0 → 精度约610米
wx4g → 精度约19公里
3. 性能:
附近查询: O(logN + M)
M = 返回结果数量注意事项:
GeoHash的局限:
1. 边界问题:
两个点虽然很近,但可能GeoHash前缀不同
(处在GeoHash网格的边界)
解决: Redis会搜索周边多个网格
2. 极地问题:
在南北极附近,经度变化大但实际距离很近
解决: GeoHash使用Haversine公式计算实际距离
3. 精度限制:
Redis GEO使用52位整数,精度约0.6米第三章:持久化机制深度解析
Redis作为内存数据库,数据存储在内存中,一旦进程退出或服务器宕机,数据就会丢失。为了解决这个问题,Redis提供了持久化机制,将内存中的数据保存到磁盘,实现数据的持久化存储。
3.1 RDB:快照持久化
RDB(Redis Database)是Redis的默认持久化方式,它通过创建数据快照来保存某个时间点的完整数据集。
3.1.1 RDB的工作原理
触发方式:
-
手动触发:
SAVE: 阻塞主进程,直到RDB文件创建完成(生产环境禁用)BGSAVE: fork子进程,后台异步创建RDB文件(推荐)
-
自动触发:
conf# redis.conf配置 save 900 1 # 900秒内至少1个key被修改 save 300 10 # 300秒内至少10个key被修改 save 60 10000 # 60秒内至少10000个key被修改
BGSAVE流程:
1. Redis主进程fork()一个子进程
├─ 主进程:继续处理客户端请求
└─ 子进程:将数据写入临时RDB文件
2. COW (Copy-On-Write)机制:
├─ fork后,子进程获得内存数据的副本(页表复制,数据共享)
└─ 主进程修改数据时,才复制物理内存页(写时复制)
3. 子进程完成RDB写入:
├─ 原子性重命名:temp.rdb → dump.rdb
└─ 通知主进程,子进程退出流程图:
主进程 子进程 1. fork() 创建子进程 COW机制: 页表复制,数据共享 2. 继续处理客户端请求 2. 遍历内存数据 写操作触发COW (复制修改的内存页) 3. 写入temp.rdb 4. rename temp.rdb → dump.rdb 5. 信号通知完成 6. 退出 继续运行 主进程 子进程
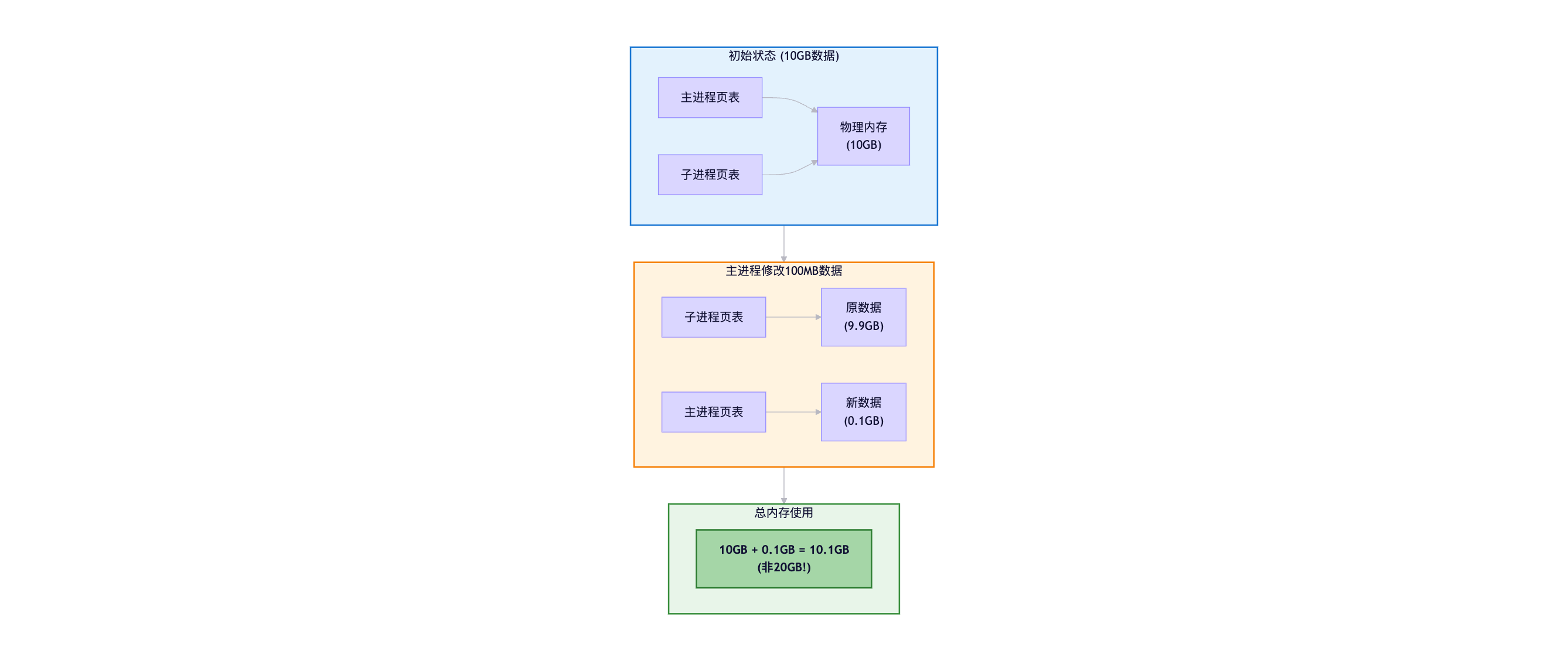
3.1.2 COW (Copy-On-Write)机制详解
COW是RDB高效的关键:
传统复制方式 (假设数据10GB):
1. fork子进程
2. 复制10GB内存数据 → 子进程独立内存
3. 子进程写RDB (数据已是旧版本)
问题:
- 复制10GB耗时长(阻塞)
- 内存占用翻倍(10GB → 20GB)COW机制:
1. fork子进程
2. 复制页表指针,数据共享 (瞬间完成)
3. 主进程修改数据时:
├─ 复制被修改的内存页
└─ 修改副本,原页面保留给子进程
内存增长 = 期间修改的数据量 (通常<10%)示例 :
3.1.3 RDB文件格式
RDB文件采用二进制格式,高度压缩:
RDB文件结构 REDIS - 魔数(5字节) 0009 - RDB版本号 FA - 辅助字段开始 元数据
(redis版本,创建时间等) FE 00 - 数据库编号(0号库) FB - rehash表大小信息 键值对数据 FF - EOF标记 CRC64 - 校验和(8字节)
压缩机制:
整数压缩:
100 → 1字节 (小整数)
100000 → 4字节 (int32)
字符串压缩:
"hello" → LZF压缩 (相似字符串压缩率高)
列表压缩:
连续整数 → 整数集合编码
短字符串 → ziplist编码3.1.4 RDB的优缺点
优点:
- 紧凑的单文件: 便于备份、传输、灾难恢复
- 恢复速度快: 直接加载二进制数据,比AOF重放命令快得多
- 性能影响小: fork+COW机制,主进程几乎无阻塞
- 适合冷备: 可设置定时任务,保存不同时间点的快照
缺点:
-
数据丢失风险: 两次快照之间的数据可能丢失
例如: save 300 10 (5分钟触发一次) 如果在第4分钟宕机,4分钟的数据全部丢失 -
fork开销: 数据量大时,fork会阻塞主进程(通常几百毫秒)
10GB数据 → fork耗时约200-500ms 期间无法处理请求 -
COW内存压力: 写密集场景,内存占用可能激增
10GB数据,短时间内修改50% → 额外需要5GB内存 可能触发OOM
3.2 AOF:追加日志持久化
AOF(Append Only File)通过记录每一个写命令来持久化数据,类似MySQL的binlog。
3.2.1 AOF的工作原理
记录方式:
客户端执行命令:
SET user:1001 "Alice"
HSET product:2001 name "iPhone" price 999
AOF日志记录 (RESP协议):
*3
$3
SET
$9
user:1001
$5
Alice
*4
$4
HSET
$12
product:2001
$4
name
$6
iPhone写入流程:
1. 命令传播:
客户端命令 → Redis执行 → 写入AOF缓冲区
2. 文件同步 (根据appendfsync配置):
AOF缓冲区 → 操作系统缓冲区 → fsync()到磁盘
3. 三种同步策略:
always: 每个命令都fsync (最安全,最慢)
everysec: 每秒fsync一次 (默认,平衡)
no: 由OS决定 (最快,最不安全)同步策略对比:
| 策略 | 性能 | 数据安全性 | 数据丢失风险 |
|---|---|---|---|
| always | 差 (~几百QPS) | 最高 | 0 (实时同步) |
| everysec | 中 (~万级QPS) | 高 | 最多1秒数据 |
| no | 好 (~十万级QPS) | 低 | 可能丢失OS缓冲区的数据(几秒到几十秒) |
推荐配置:
conf
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec # 平衡性能和安全性
no-appendfsync-on-rewrite no # rewrite期间不fsync,避免阻塞3.2.2 AOF重写机制
问题: AOF文件会无限增长,因为每个写命令都会被记录,即使是对同一个key的多次修改。
重写原理:
原AOF文件 (100条命令):
SET counter 1
INCR counter
INCR counter
...
INCR counter
DEL user:old
SET user:1001 "Alice"
SET user:1001 "Bob" # 覆盖前一条
SET user:1001 "Charlie" # 最终值
重写后 (合并为当前状态):
SET counter 100
SET user:1001 "Charlie"
效果: 100条 → 2条,文件大小减少95%重写流程 (BGREWRITEAOF):
1. fork子进程:
├─ 子进程:根据内存数据生成新AOF
└─ 主进程:继续处理请求,新命令写入:
├→ 旧AOF文件
└→ AOF重写缓冲区 (内存)
2. 子进程完成新AOF:
├─ 通知主进程
└─ 主进程将重写缓冲区追加到新AOF (阻塞)
3. 原子性替换:
rename new.aof → appendonly.aof流程图:
主进程 子进程 fork() 创建子进程 继续处理请求 写入旧AOF 写入重写缓冲区 遍历内存 生成新AOF temp-rewrite.aof par 并行执行 信号通知完成 (阻塞) 追加重写缓冲区到新AOF rename → appendonly.aof 继续使用新AOF 主进程 子进程
自动触发重写:
conf
auto-aof-rewrite-percentage 100 # AOF文件大小比上次重写后增长100%
auto-aof-rewrite-min-size 64mb # 且AOF文件至少64MB
示例:
上次重写后: 100MB
触发条件: 当前AOF >= 200MB3.2.3 AOF数据恢复
Redis启动时自动加载AOF文件:
1. 读取AOF文件
2. 逐行解析命令
3. 在内存中重新执行每条命令
4. 恢复到宕机前的状态恢复速度对比:
10GB数据:
RDB恢复: ~30秒 (直接加载)
AOF恢复: ~5分钟 (重放命令)
结论: RDB >> AOF (恢复速度)AOF文件损坏修复:
bash
# 检查AOF文件
redis-check-aof appendonly.aof
# 修复AOF文件(删除损坏部分)
redis-check-aof --fix appendonly.aof3.2.4 AOF的优缺点
优点:
-
数据安全性高:
- everysec模式最多丢失1秒数据
- always模式几乎不丢数据
-
可读性好: 文本格式,可以手动编辑
bashcat appendonly.aof *3 $3 SET $3 key $5 value -
支持误操作恢复:
bash# 误执行FLUSHALL # 编辑AOF,删除最后的FLUSHALL命令 # 重启Redis,数据恢复
缺点:
-
文件体积大: 比RDB大得多
10GB数据: RDB文件: ~8GB (压缩后) AOF文件: ~20GB (命令文本) -
恢复速度慢: 需要重放所有命令
-
性能开销: fsync操作影响性能
always模式: QPS可能下降90%
3.3 混合持久化:最佳实践
Redis 4.0引入了混合持久化,结合RDB和AOF的优点。
3.3.1 混合持久化原理
配置:
conf
aof-use-rdb-preamble yes # 开启混合持久化(默认yes)文件结构:
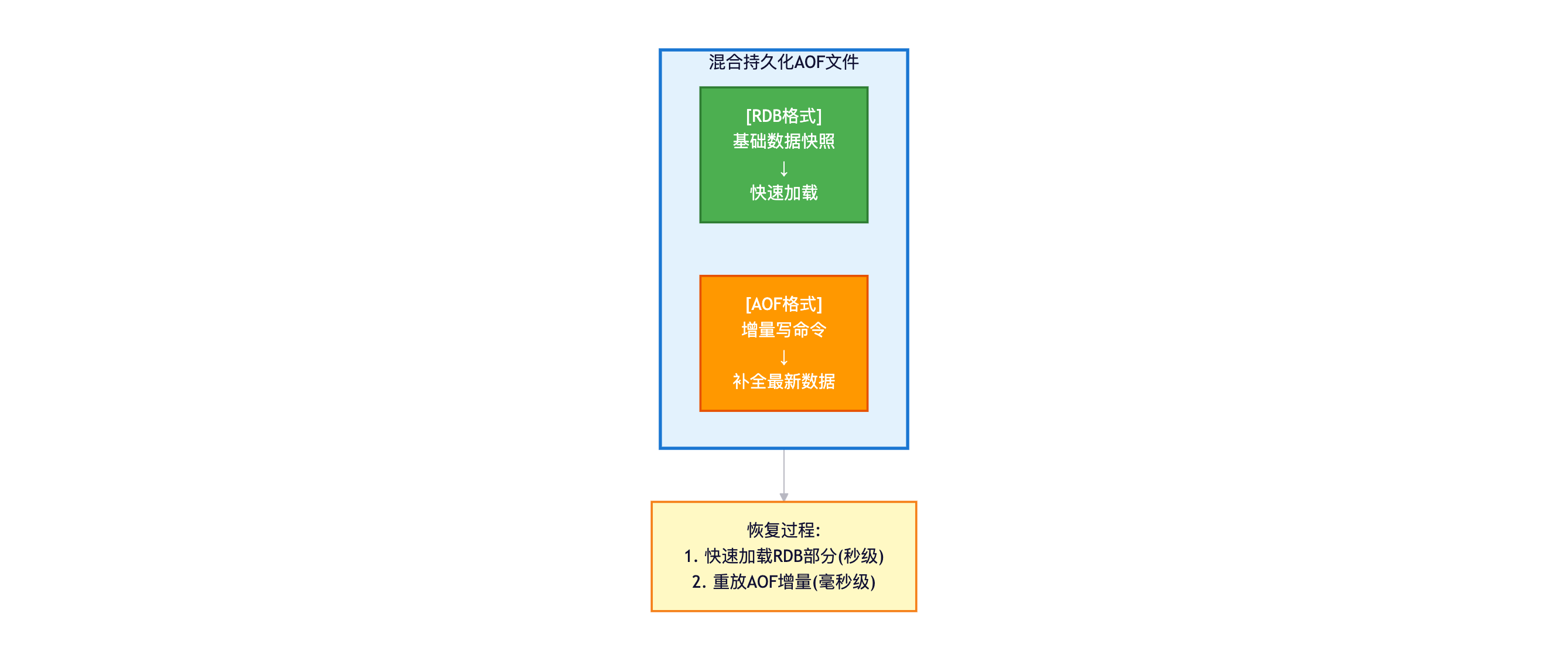
重写过程:
BGREWRITEAOF触发时:
1. 子进程用RDB格式写入内存快照 (前半部分)
2. 主进程的增量命令用AOF格式追加 (后半部分)
结果: appendonly.aof = RDB数据 + AOF增量恢复过程:
1. 读取AOF文件头部,识别为RDB格式
2. 快速加载RDB部分 (秒级)
3. 重放AOF部分的增量命令 (很少,毫秒级)
恢复时间: RDB速度 + 少量AOF开销3.3.2 持久化方案选择
场景对比:
| 场景 | 推荐方案 | 配置 |
|---|---|---|
| 缓存 (可丢失) | 仅RDB | save 900 1 |
| 数据重要 | 混合持久化 | aof-use-rdb-preamble yes + appendfsync everysec |
| 极致性能 | 关闭持久化 | save "" + appendonly no |
| 极致安全 | AOF always | appendfsync always (牺牲性能) |
| 大数据集 | RDB + 定期备份 | fork开销小,恢复快 |
生产环境配置模板:
conf
# 混合持久化(推荐)
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
aof-use-rdb-preamble yes
# AOF重写优化
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
no-appendfsync-on-rewrite no
# RDB备份(双保险)
save 900 1
save 300 10
save 60 10000
dbfilename dump.rdb
# 性能优化
rdb-save-incremental-fsync yes # RDB增量fsync,避免阻塞监控指标:
bash
# 查看持久化状态
redis-cli INFO persistence
# 关键指标:
aof_enabled:1
aof_current_size:1234567
aof_base_size:1000000
aof_pending_rewrite:0
rdb_last_save_time:1674123456
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:2第四章:高可用架构设计
单机Redis的问题:
- 单点故障: 宕机导致服务不可用
- 容量瓶颈: 单机内存有限
- 性能瓶颈: 单机QPS有上限
Redis提供三种高可用方案:主从复制、Sentinel哨兵、Cluster集群。
4.1 主从复制
主从复制实现数据的多副本存储,支持读写分离和容灾备份。
4.1.1 主从架构
复制流 复制流 复制流 Master
(读写) Slave1
(只读) Slave2
(只读) Slave3
(只读)
配置方式:
bash
# 从节点配置
replicaof 192.168.1.100 6379 # 指定主节点
masterauth <password> # 主节点密码
# 或运行时动态配置
redis-cli> REPLICAOF 192.168.1.100 6379特点:
- 主节点:处理写请求,同步数据到从节点
- 从节点:处理读请求,实时复制主节点数据
- 异步复制:主节点不等待从节点确认,性能高但可能有延迟
4.1.2 全量复制流程
触发条件:
- 从节点首次连接主节点
- 从节点长时间断线重连(复制积压缓冲区数据已丢失)
完整流程:
从节点 主节点 1. 发送PSYNC ? -1 2. 判断为全量复制 生成runid和offset 3. +FULLRESYNC runid offset 4. BGSAVE生成RDB (fork子进程) 5. 新命令写入: 复制缓冲区 复制积压缓冲区 6. 发送RDB文件 7. 清空本地数据 加载RDB 8. 发送缓冲区命令 9. 执行缓冲区命令 10. 进入增量复制阶段 从节点 主节点
关键概念:
runid (运行ID):
- 每个Redis实例的唯一标识(40位随机字符串)
- 重启后改变
- 用于判断是否为同一主节点
offset (复制偏移量):
- 主从都维护一个偏移量
- 主节点:已发送的字节数
- 从节点:已接收的字节数
- 偏移量一致 = 数据同步
复制积压缓冲区:
- 主节点的环形缓冲区(默认1MB)
- 保存最近的复制命令
- 用于部分复制4.1.3 增量复制(部分复制)
触发条件:
- 从节点短暂断线重连
- 复制积压缓冲区仍保留缺失的数据
流程:

复制积压缓冲区优化:
conf
# 计算合理大小
repl-backlog-size = 写速率(字节/秒) × 断线时长(秒) × 2
示例:
写速率: 10MB/s
允许断线: 60秒
repl-backlog-size = 10MB * 60 * 2 = 1200MB
配置:
repl-backlog-size 1200mb
repl-backlog-ttl 3600 # 1小时内无从节点,释放缓冲区4.1.4 心跳与命令传播
正常运行阶段:
主节点 → 从节点:
- 每秒发送: PING (心跳)
- 实时发送: 写命令 (命令传播)
从节点 → 主节点:
- 每秒发送: REPLCONF ACK <offset> (汇报偏移量)
作用:
- 检测网络状态
- 检测从节点是否存活
- 辅助实现min-slaves配置min-slaves机制:
conf
min-replicas-to-write 1 # 至少1个从节点在线
min-replicas-max-lag 10 # 延迟不超过10秒
效果:
如果从节点少于1个,或延迟>10秒
→ 主节点拒绝写请求 (保证数据不丢失)4.1.5 主从架构的优缺点
优点:
- 读写分离:主写从读,提升并发能力
- 数据备份:多副本存储,防止数据丢失
- 快速恢复:从节点可以快速提升为主节点
缺点:
- 无自动故障转移:主节点宕机需人工介入
- 复制延迟:异步复制可能导致主从不一致
- 全量复制开销:大数据集下,RDB生成和传输耗时长
应用场景:
适合:
- 读多写少的场景(读写分离)
- 数据备份和灾难恢复
- 主节点故障率低的场景
不适合:
- 需要自动故障转移
- 写密集型场景(主节点压力大)4.2 Sentinel哨兵模式
Sentinel解决了主从复制的核心痛点:自动故障转移。
4.2.1 Sentinel架构
Redis主从 Sentinel集群(3节点) 监控 监控 监控 监控 监控 监控 复制 复制 Master
(读写) Slave1
(只读) Slave2
(只读) Sentinel1 Sentinel2 Sentinel3
Sentinel的三大职责:
-
监控(Monitoring):
- 检查主从节点是否正常工作
- 通过PING命令,每秒检测一次
-
通知(Notification):
- 当被监控的节点出现问题,通过API通知管理员或其他程序
-
自动故障转移(Automatic Failover):
- 主节点故障时,自动选举新主节点
- 其他从节点改为复制新主节点
- 通知客户端新的主节点地址
4.2.2 故障检测机制
主观下线(Subjectively Down, SDOWN):
单个Sentinel判断:
1. 向主节点发送PING
2. 超时未响应(down-after-milliseconds)
3. 标记为主观下线
配置:
sentinel monitor mymaster 192.168.1.100 6379 2
sentinel down-after-milliseconds mymaster 30000 # 30秒超时客观下线(Objectively Down, ODOWN):
多数Sentinel确认:
1. Sentinel1检测到主观下线
2. 询问其他Sentinel:"你们认为主节点下线了吗?"
3. 如果quorum个Sentinel都认为下线
4. 标记为客观下线
quorum配置:
sentinel monitor mymaster 192.168.1.100 6379 2
↑
quorum=2流程图:
多数Sentinel确认 Sentinel1检测流程 Yes No Yes No 询问其他Sentinel quorum个Sentinel
都认为下线? 标记为客观下线ODOWN 超时未响应? 向主节点发送PING 标记为主观下线SDOWN 触发故障转移
4.2.3 选举Leader Sentinel
客观下线后,需要选举一个Leader Sentinel来执行故障转移:
Raft算法简化版:
1. 每个Sentinel向其他Sentinel发送:
"我要成为Leader,请投票给我"
2. 投票规则:
- 先到先得:第一个请求投票的获得选票
- 每个Sentinel在一轮选举中只能投一票
3. 获得多数票(>N/2)的Sentinel成为Leader
示例 (3个Sentinel):
Sentinel1: 得票2 (自己+Sentinel2) → 成为Leader
Sentinel2: 得票1 (自己)
Sentinel3: 得票0
Sentinel1执行故障转移4.2.4 故障转移流程
完整流程:
1. 选择新主节点 (从所有从节点中选择):
优先级判断:
├─ replica-priority最小的从节点 (0排除)
├─ 复制偏移量最大的 (数据最新)
└─ runid最小的 (字典序)
2. 提升新主节点:
Leader Sentinel向选中的从节点发送:
SLAVEOF NO ONE
3. 更新其他从节点:
向其他从节点发送:
SLAVEOF <新主节点IP> <新主节点端口>
4. 更新旧主节点配置:
当旧主节点恢复时,配置为从节点
5. 通知客户端:
发布订阅机制通知新的主节点地址流程图:
客观下线检测 选举Leader Sentinel 选择新主节点
(根据优先级) SLAVEOF NO ONE
Slave1提升为Master SLAVEOF 新Master
Slave2, Slave3切换复制 更新配置文件 故障转移完成
4.2.5 Sentinel配置示例
sentinel.conf:
conf
# 监控主节点
sentinel monitor mymaster 192.168.1.100 6379 2
# 名称 IP 端口 quorum
# 密码
sentinel auth-pass mymaster <password>
# 超时时间
sentinel down-after-milliseconds mymaster 30000
# 故障转移超时
sentinel failover-timeout mymaster 180000
# 并行同步从节点数量
sentinel parallel-syncs mymaster 1
# 1表示一次只同步1个从节点,避免全量复制压垮主节点
# 通知脚本
sentinel notification-script mymaster /var/redis/notify.sh
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh启动Sentinel:
bash
# 启动Sentinel (至少3个节点,保证高可用)
redis-sentinel /etc/redis/sentinel-26379.conf
redis-sentinel /etc/redis/sentinel-26380.conf
redis-sentinel /etc/redis/sentinel-26381.conf
# 查看Sentinel状态
redis-cli -p 26379
sentinel master mymaster
sentinel slaves mymaster
sentinel sentinels mymaster4.2.6 客户端连接Sentinel
Jedis示例:
java
// Sentinel地址列表
Set<String> sentinels = new HashSet<>();
sentinels.add("192.168.1.201:26379");
sentinels.add("192.168.1.202:26379");
sentinels.add("192.168.1.203:26379");
// 创建Sentinel连接池
JedisSentinelPool pool = new JedisSentinelPool(
"mymaster", // 主节点名称
sentinels, // Sentinel地址
poolConfig,
"password"
);
// 获取连接(自动连接当前主节点)
try (Jedis jedis = pool.getResource()) {
jedis.set("key", "value");
}
// 故障转移后,自动连接新主节点,无需修改代码Spring Boot配置:
yaml
spring:
redis:
sentinel:
master: mymaster
nodes:
- 192.168.1.201:26379
- 192.168.1.202:26379
- 192.168.1.203:26379
password: yourpassword4.3 Cluster集群模式
Redis Cluster是Redis官方的分布式解决方案,实现了数据分片和高可用。
4.3.1 Cluster架构
Redis Cluster (6节点) 复制 复制 复制 Master1
槽 0-5460 Master2
槽 5461-10922 Master3
槽 10923-16383 Slave1 Slave2 Slave3 核心特性 数据分片
(16384个槽) 无中心化
(Gossip协议) 自动故障转移 水平扩展
核心特性:
- 数据分片: 16384个哈希槽,分配给多个主节点
- 无中心化: 节点间通过Gossip协议通信,无需Proxy
- 自动故障转移: 主节点宕机,自动提升从节点
- 水平扩展: 可动态增减节点
4.3.2 哈希槽分片机制
哈希槽计算:
key → CRC16(key) % 16384 = slot
示例:
key = "user:1001"
CRC16("user:1001") = 31234
slot = 31234 % 16384 = 14850
→ 该key存储在负责14850槽的节点上槽位分配:
16384个槽平均分配给N个主节点:
3节点集群:
Master1: 0-5460 (5461个槽)
Master2: 5461-10922 (5462个槽)
Master3: 10923-16383 (5461个槽)
6节点集群:
Master1: 0-2730
Master2: 2731-5461
Master3: 5462-8192
Master4: 8193-10923
Master5: 10924-13653
Master6: 13654-16383为什么是16384个槽?
1. 心跳包大小:
槽位信息用bitmap传输
16384 / 8 = 2KB (可接受)
65536 / 8 = 8KB (太大)
2. 集群规模:
官方推荐最多1000个节点
16384个槽足够分配
3. 迁移效率:
槽位越少,迁移速度越快4.3.3 请求路由:MOVED重定向
客户端如何找到key所在的节点?
方案1: 客户端直接计算(推荐)
java
// Smart Client (Jedis/Lettuce)
1. 客户端缓存槽位映射表:
槽0-5460 → 192.168.1.101:6379
槽5461-10922 → 192.168.1.102:6379
槽10923-16383 → 192.168.1.103:6379
2. 计算key的槽位:
slot = CRC16("user:1001") % 16384 = 14850
3. 查表,直接请求负责该槽的节点:
192.168.1.103:6379
4. 执行命令方案2: MOVED重定向
客户端请求错误节点时:
Client → Node1: GET user:1001
↓
Node1发现槽14850不归自己管理
↓
Node1 → Client: -MOVED 14850 192.168.1.103:6379
↓
Client更新槽位映射表
↓
Client → Node3: GET user:1001
↓
Node3 → Client: "Alice"MOVED重定向示例:
bash
# 直连Node1
redis-cli -c -h 192.168.1.101 -p 6379
127.0.0.1:6379> GET user:1001
-> Redirected to slot [14850] located at 192.168.1.103:6379
"Alice"
# -c参数启用自动重定向4.3.4 ASK重定向:槽迁移场景
当槽位正在迁移时,会出现ASK重定向:
迁移流程:
场景: 将槽14850从Node1迁移到Node2
1. 开始迁移:
Node2> CLUSTER SETSLOT 14850 IMPORTING Node1
Node1> CLUSTER SETSLOT 14850 MIGRATING Node2
2. 迁移数据:
Node1> CLUSTER GETKEYSINSLOT 14850 100
→ ["user:1001", "user:1002", ...]
Node1> MIGRATE 192.168.1.102 6379 user:1001 0 5000
(将user:1001迁移到Node2)
3. 请求路由:
- 如果key已迁移 → Node1返回ASK重定向
- 如果key未迁移 → Node1直接处理
4. 完成迁移:
CLUSTER SETSLOT 14850 NODE <Node2 ID>ASK vs MOVED:
| 特性 | MOVED | ASK |
|---|---|---|
| 含义 | 槽位已永久迁移 | 槽位正在迁移 |
| 客户端缓存 | 更新槽位映射 | 不更新(临时) |
| 命令前缀 | 无 | 需要发送ASKING命令 |
ASK重定向示例:
Client Node1 Node2 GET user:1001 user:1001已迁移到Node2 -ASK 14850 192.168.1.102:6379 ASKING GET user:1001 "Alice" ASK是临时重定向,不更新缓存 Client Node1 Node2
4.3.5 Gossip协议:去中心化通信
Cluster节点间通过Gossip协议交换信息:
Gossip消息类型:
-
PING: 心跳消息
- 每秒随机选择5个节点发送PING
- 携带自己的状态和部分其他节点状态
-
PONG: PING的响应
- 返回自己的状态信息
-
MEET: 加入集群
- 新节点通过MEET消息加入集群
x
- 新节点通过MEET消息加入集群
-
FAIL: 节点下线
- 超过半数节点认为某节点下线,广播FAIL消息
Gossip通信流程:
每秒执行:
1. 随机选择5个节点
2. 选择最久未通信的节点
3. 向这些节点发送PING消息
PING消息内容:
- 发送者信息(ID, IP, 端口, 槽位)
- 随机选择2-3个节点的状态信息
- 自己已知的集群状态
收到PING后:
1. 更新发送者信息
2. 更新其他节点信息
3. 返回PONG消息最终一致性:
信息传播时间:
- 单跳: 1秒 (PING周期)
- 全网收敛: O(logN) 秒
示例 (100节点):
- 理论收敛时间: ~7秒
- 实际收敛时间: ~10秒 (网络延迟)4.3.6 故障检测与转移
PFAIL (疑似下线):
节点A检测到节点B超时:
1. 标记节点B为PFAIL
2. 在PING消息中携带这个信息
3. 其他节点收到后,更新自己对节点B的认知FAIL (确认下线):
当超过半数主节点认为节点B PFAIL:
1. 节点A将节点B标记为FAIL
2. 广播FAIL消息给所有节点
3. 所有节点立即标记节点B为FAIL
公式: FAIL节点数 > 主节点总数 / 2自动故障转移:
Master1宕机后:
1. Slave1检测到Master1下线
2. 发起选举:
- 向其他主节点请求投票
- 投票规则: 先到先得,每个主节点只投一票
3. Slave1获得多数票:
- 提升为Master
- 接管Master1的槽位
4. 广播PONG消息:
- 通知所有节点新的拓扑结构
5. 客户端感知:
- 收到MOVED重定向
- 更新槽位映射表流程图:
Master1宕机 Slave1检测到(超时) 标记PFAIL 收集其他节点反馈 标记FAIL 发起选举 请求投票 Master2投票给Slave1
Master3投票给Slave1 Slave1获得2票
(>3主节点/2) 提升为新Master1 广播拓扑更新 客户端收到MOVED重定向
4.3.7 Cluster搭建实战
环境准备 (3主3从):
bash
# 创建6个节点目录
mkdir -p /redis/cluster/{7001,7002,7003,7004,7005,7006}
# 配置文件模板 redis-7001.conf
port 7001
cluster-enabled yes
cluster-config-file nodes-7001.conf
cluster-node-timeout 5000
appendonly yes
dir /redis/cluster/7001启动节点:
bash
# 启动6个节点
redis-server /redis/cluster/7001/redis-7001.conf
redis-server /redis/cluster/7002/redis-7002.conf
redis-server /redis/cluster/7003/redis-7003.conf
redis-server /redis/cluster/7004/redis-7004.conf
redis-server /redis/cluster/7005/redis-7005.conf
redis-server /redis/cluster/7006/redis-7006.conf创建集群:
bash
# Redis 5.0+
redis-cli --cluster create \
192.168.1.100:7001 \
192.168.1.100:7002 \
192.168.1.100:7003 \
192.168.1.100:7004 \
192.168.1.100:7005 \
192.168.1.100:7006 \
--cluster-replicas 1
# --cluster-replicas 1: 每个主节点1个从节点
# 输出:
# Master[0] -> Slots 0-5460
# Master[1] -> Slots 5461-10922
# Master[2] -> Slots 10923-16383
# Replica[0] -> Master[0]
# Replica[1] -> Master[1]
# Replica[2] -> Master[2]验证集群:
bash
redis-cli -c -p 7001
127.0.0.1:7001> CLUSTER INFO
cluster_state:ok
cluster_slots_assigned:16384
cluster_known_nodes:6
cluster_size:3
127.0.0.1:7001> CLUSTER NODES
# 显示所有节点和槽位分配动态扩容:
bash
# 添加新主节点
redis-cli --cluster add-node 192.168.1.100:7007 192.168.1.100:7001
# 分配槽位
redis-cli --cluster reshard 192.168.1.100:7001
# 交互式输入:
# - 迁移多少槽位? 4096
# - 接收节点ID? <7007的节点ID>
# - 源节点? all (从所有节点平均分配)
# 添加从节点
redis-cli --cluster add-node 192.168.1.100:7008 192.168.1.100:7001 \
--cluster-slave \
--cluster-master-id <7007的节点ID>4.3.8 Cluster使用注意事项
多key操作限制:
bash
# ❌ 错误:key可能在不同节点
MGET user:1001 user:1002 user:1003
(error) CROSSSLOT Keys in request don't hash to the same slot
# ✅ 正确:使用Hash Tag
# {user}部分参与哈希计算,确保在同一槽位
MGET {user}:1001 {user}:1002 {user}:1003
# Hash Tag原理:
CRC16("{user}:1001") = CRC16("user")
CRC16("{user}:1002") = CRC16("user")
→ 同一槽位事务限制:
bash
# ❌ 不支持跨节点事务
MULTI
SET user:1001 "Alice" # 槽14850 → Node1
SET product:2001 "iPhone" # 槽9374 → Node2
EXEC
(error) CROSSSLOT
# ✅ 使用Hash Tag
MULTI
SET {order:123}:user "Alice"
SET {order:123}:product "iPhone"
EXEC
OK最佳实践:
1. 业务设计:
- 相关数据使用相同Hash Tag
- 避免大key (超过100MB)
2. 节点数量:
- 建议3-10个主节点
- 节点过多,Gossip开销大
3. 从节点配置:
- 每个主节点至少1个从节点
- 读写分离需手动配置readonly
4. 监控:
- 槽位分布是否均衡
- 节点内存使用率
- 故障转移次数第五章:生产实战与最佳实践
5.1 缓存常见问题
5.1.1 缓存雪崩
问题描述:
大量缓存在同一时间过期,导致大量请求直接打到数据库,造成数据库压力激增甚至宕机。
场景示例:
凌晨0点,运营活动结束:
- 10万个商品缓存同时过期 (TTL=24小时)
- 早上8点用户涌入
- 所有请求查数据库
- 数据库CPU 100%, 响应超时解决方案:
1. 过期时间加随机值
java
// ❌ 错误:固定TTL
redisTemplate.opsForValue().set(key, value, 24, TimeUnit.HOURS);
// ✅ 正确:TTL + 随机偏移
int baseTime = 24 * 60 * 60; // 24小时
int randomTime = new Random().nextInt(300); // 0-5分钟随机
redisTemplate.opsForValue().set(key, value, baseTime + randomTime, TimeUnit.SECONDS);2. 多级缓存
java
@Service
public class ProductService {
// L1: 本地缓存(Caffeine)
private LoadingCache<Long, Product> localCache = Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.build(this::loadFromRedis);
// L2: Redis缓存
@Autowired
private StringRedisTemplate redisTemplate;
public Product getProduct(Long id) {
// 先查本地缓存
Product product = localCache.get(id);
if (product != null) {
return product;
}
// 再查Redis
String json = redisTemplate.opsForValue().get("product:" + id);
if (json != null) {
return JSON.parseObject(json, Product.class);
}
// 最后查数据库
product = productMapper.selectById(id);
if (product != null) {
// 回写Redis (TTL随机)
int ttl = 86400 + new Random().nextInt(7200);
redisTemplate.opsForValue().set("product:" + id,
JSON.toJSONString(product), ttl, TimeUnit.SECONDS);
}
return product;
}
}3. 热点数据永不过期
java
// 后台定时任务,主动刷新热点数据
@Scheduled(cron = "0 */10 * * * ?") // 每10分钟
public void refreshHotData() {
List<Long> hotProductIds = getHotProductIds(); // 获取热门商品
for (Long id : hotProductIds) {
Product product = productMapper.selectById(id);
redisTemplate.opsForValue().set("product:" + id,
JSON.toJSONString(product), 0, TimeUnit.SECONDS); // 永不过期
}
}5.1.2 缓存击穿
问题描述:
某个热点key失效的瞬间,大量并发请求击穿缓存,直接查数据库。
场景示例:
爆款商品缓存过期:
- 瞬间10000个请求
- 缓存MISS
- 10000个数据库查询同时执行
- 数据库连接池耗尽解决方案:
1. 互斥锁(SETNX)
java
public Product getProductWithMutex(Long id) {
String key = "product:" + id;
String lockKey = "lock:product:" + id;
// 1. 查缓存
String json = redisTemplate.opsForValue().get(key);
if (json != null) {
return JSON.parseObject(json, Product.class);
}
// 2. 尝试获取锁
Boolean lock = redisTemplate.opsForValue().setIfAbsent(lockKey, "1", 10, TimeUnit.SECONDS);
if (Boolean.TRUE.equals(lock)) {
try {
// 3. 查数据库
Product product = productMapper.selectById(id);
if (product != null) {
// 4. 回写缓存
redisTemplate.opsForValue().set(key, JSON.toJSONString(product),
3600, TimeUnit.SECONDS);
}
return product;
} finally {
// 5. 释放锁
redisTemplate.delete(lockKey);
}
} else {
// 6. 未获取锁,等待后重试
try {
Thread.sleep(50);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
return getProductWithMutex(id); // 递归重试
}
}2. 逻辑过期(推荐)
java
@Data
public class CacheData {
private Object data; // 实际数据
private Long expireTime; // 逻辑过期时间
}
public Product getProductWithLogicalExpire(Long id) {
String key = "product:" + id;
// 1. 查缓存
String json = redisTemplate.opsForValue().get(key);
if (json == null) {
return null; // 缓存未命中
}
CacheData cacheData = JSON.parseObject(json, CacheData.class);
Product product = JSON.parseObject((String) cacheData.getData(), Product.class);
// 2. 判断逻辑过期
if (cacheData.getExpireTime() > System.currentTimeMillis()) {
return product; // 未过期,直接返回
}
// 3. 已过期,尝试获取锁
String lockKey = "lock:product:" + id;
Boolean lock = redisTemplate.opsForValue().setIfAbsent(lockKey, "1", 10, TimeUnit.SECONDS);
if (Boolean.TRUE.equals(lock)) {
// 4. 异步更新缓存
CompletableFuture.runAsync(() -> {
try {
Product newProduct = productMapper.selectById(id);
CacheData newCacheData = new CacheData();
newCacheData.setData(JSON.toJSONString(newProduct));
newCacheData.setExpireTime(System.currentTimeMillis() + 3600000); // 1小时后
redisTemplate.opsForValue().set(key, JSON.toJSONString(newCacheData));
} finally {
redisTemplate.delete(lockKey);
}
});
}
// 5. 返回旧数据(不阻塞)
return product;
}5.1.3 缓存穿透
问题描述:
查询一个不存在的数据,缓存和数据库都没有,导致每次请求都打到数据库。
场景示例:
恶意攻击:
- 请求不存在的商品ID: -1, -2, -3, ...
- Redis查不到
- 数据库查不到
- 大量无效查询,数据库压力大解决方案:
1. 空值缓存
java
public Product getProduct(Long id) {
String key = "product:" + id;
// 1. 查缓存
String json = redisTemplate.opsForValue().get(key);
if (json != null) {
if ("null".equals(json)) {
return null; // 缓存的空值
}
return JSON.parseObject(json, Product.class);
}
// 2. 查数据库
Product product = productMapper.selectById(id);
if (product != null) {
// 3. 缓存正常数据
redisTemplate.opsForValue().set(key, JSON.toJSONString(product),
3600, TimeUnit.SECONDS);
} else {
// 4. 缓存空值(短TTL)
redisTemplate.opsForValue().set(key, "null",
60, TimeUnit.SECONDS); // 1分钟
}
return product;
}2. 布隆过滤器(推荐)
java
@Configuration
public class BloomFilterConfig {
@Bean
public BloomFilter<Long> productBloomFilter() {
// 预估100万个商品,误判率0.01%
BloomFilter<Long> filter = BloomFilter.create(
Funnels.longFunnel(),
1000000,
0.0001
);
// 初始化:加载所有商品ID
List<Long> productIds = productMapper.selectAllIds();
productIds.forEach(filter::put);
return filter;
}
}
@Service
public class ProductService {
@Autowired
private BloomFilter<Long> productBloomFilter;
public Product getProduct(Long id) {
// 1. 布隆过滤器判断
if (!productBloomFilter.mightContain(id)) {
return null; // 一定不存在,直接返回
}
// 2. 可能存在,查缓存
String key = "product:" + id;
String json = redisTemplate.opsForValue().get(key);
if (json != null) {
return JSON.parseObject(json, Product.class);
}
// 3. 查数据库
Product product = productMapper.selectById(id);
if (product != null) {
redisTemplate.opsForValue().set(key, JSON.toJSONString(product),
3600, TimeUnit.SECONDS);
}
return product;
}
// 新增商品时,同步到布隆过滤器
public void addProduct(Product product) {
productMapper.insert(product);
productBloomFilter.put(product.getId());
}
}Redis布隆过滤器 (RedisBloom模块):
bash
# 安装RedisBloom模块
docker run -p 6379:6379 --name redis-bloom \
redis/redis-stack-server:latest
# 创建布隆过滤器
BF.RESERVE product:bloom 0.0001 1000000
# 添加元素
BF.ADD product:bloom 1001
# 检查存在性
BF.EXISTS product:bloom 1001
(integer) 1 # 可能存在
BF.EXISTS product:bloom 9999
(integer) 0 # 一定不存在5.1.4 热点Key
问题描述:
某个key被极高并发访问,超过单个Redis节点的处理能力。
场景示例:
大促活动:
- 抢购页面QPS: 100万/秒
- 热点商品key: product:9999
- 单节点极限: ~10万QPS
- 瓶颈: 网络带宽、CPU解决方案:
1. 本地缓存 + 失效通知
java
@Service
public class HotKeyService {
// 本地缓存(应用内存)
private LoadingCache<String, String> localCache = Caffeine.newBuilder()
.maximumSize(10000)
.expireAfterWrite(10, TimeUnit.SECONDS) // 短TTL
.build(key -> redisTemplate.opsForValue().get(key));
@Autowired
private StringRedisTemplate redisTemplate;
public String get(String key) {
// 先查本地缓存
return localCache.get(key);
}
// 更新数据时,通过Redis Pub/Sub通知所有节点失效
public void update(String key, String value) {
redisTemplate.opsForValue().set(key, value);
// 发布失效通知
redisTemplate.convertAndSend("cache:invalidate", key);
}
// 订阅失效通知
@RedisListener(topics = "cache:invalidate")
public void onCacheInvalidate(String key) {
localCache.invalidate(key);
}
}2. Key拆分
java
// 将热点key拆分为N个子key
public String getHotKey(String key) {
int replica = new Random().nextInt(10); // 10个副本
String subKey = key + ":replica:" + replica;
String value = redisTemplate.opsForValue().get(subKey);
if (value == null) {
// 查数据库
value = loadFromDB(key);
// 同时写入10个副本
for (int i = 0; i < 10; i++) {
redisTemplate.opsForValue().set(key + ":replica:" + i, value,
3600, TimeUnit.SECONDS);
}
}
return value;
}3. Redis Cluster读写分离
java
// 热点key路由到从节点
@Configuration
public class RedisClusterConfig {
@Bean
public LettuceClientConfigurationBuilder clientConfig() {
return LettuceClientConfiguration.builder()
.readFrom(ReadFrom.REPLICA_PREFERRED); // 优先从节点读
}
}
// 写主节点,读从节点
redisTemplate.opsForValue().set(key, value); // → 主节点
redisTemplate.opsForValue().get(key); // → 从节点 (3个从节点分担读压力)5.1.5 缓存一致性
问题描述:
缓存和数据库数据不一致。
常见方案对比:
| 方案 | 流程 | 一致性 | 并发问题 |
|---|---|---|---|
| 先更新DB,再删缓存 | UPDATE DB → DEL Cache | 最终一致 | 低概率不一致 |
| 先删缓存,再更新DB | DEL Cache → UPDATE DB | 最终一致 | 高概率不一致 |
| 先更新DB,再更新缓存 | UPDATE DB → SET Cache | 最终一致 | 浪费(可能未读取) |
推荐方案:先更新DB,再删缓存 + 延迟双删
java
public void updateProduct(Product product) {
String key = "product:" + product.getId();
// 1. 第一次删除缓存
redisTemplate.delete(key);
// 2. 更新数据库
productMapper.updateById(product);
// 3. 延迟删除缓存(200ms后)
CompletableFuture.runAsync(() -> {
try {
Thread.sleep(200); // 等待其他事务提交
redisTemplate.delete(key);
} catch (InterruptedException e) {
Thread.currentThread.interrupt();
}
});
}终极方案:监听数据库变更(Canal)
java
// 使用Canal监听MySQL binlog
@Component
public class CanalCacheSync implements EntryHandler<Product> {
@Autowired
private StringRedisTemplate redisTemplate;
@Override
@InsertListenPoint
public void onEvent(Product product) {
String key = "product:" + product.getId();
redisTemplate.opsForValue().set(key, JSON.toJSONString(product),
3600, TimeUnit.SECONDS);
}
@Override
@UpdateListenPoint
public void onEvent(Product before, Product after) {
String key = "product:" + after.getId();
redisTemplate.delete(key); // 删除缓存,下次查询时重新加载
}
@Override
@DeleteListenPoint
public void onEvent(Product product) {
String key = "product:" + product.getId();
redisTemplate.delete(key);
}
}5.2 分布式锁
5.2.1 基本实现
正确的加锁方式:
java
public boolean tryLock(String lockKey, String requestId, int expireTime) {
// SET key value NX EX expire
// NX: 不存在才设置
// EX: 过期时间(秒)
Boolean result = redisTemplate.opsForValue()
.setIfAbsent(lockKey, requestId, expireTime, TimeUnit.SECONDS);
return Boolean.TRUE.equals(result);
}正确的解锁方式(Lua脚本保证原子性):
java
public boolean unlock(String lockKey, String requestId) {
String script =
"if redis.call('get', KEYS[1]) == ARGV[1] then " +
" return redis.call('del', KEYS[1]) " +
"else " +
" return 0 " +
"end";
Long result = redisTemplate.execute(
new DefaultRedisScript<>(script, Long.class),
Collections.singletonList(lockKey),
requestId
);
return Long.valueOf(1L).equals(result);
}完整示例:
java
public void processOrder(Long orderId) {
String lockKey = "lock:order:" + orderId;
String requestId = UUID.randomUUID().toString();
try {
// 1. 尝试获取锁(10秒过期)
if (tryLock(lockKey, requestId, 10)) {
try {
// 2. 执行业务逻辑
Order order = orderMapper.selectById(orderId);
order.setStatus(OrderStatus.PROCESSING);
orderMapper.updateById(order);
// ...
} finally {
// 3. 释放锁
unlock(lockKey, requestId);
}
} else {
throw new BusinessException("系统繁忙,请稍后重试");
}
} catch (Exception e) {
log.error("处理订单失败", e);
throw e;
}
}5.2.2 Redisson:生产级分布式锁
引入依赖:
xml
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.24.3</version>
</dependency>配置:
yaml
spring:
redis:
host: 192.168.1.100
port: 6379
password: yourpassword使用示例:
java
@Service
public class OrderService {
@Autowired
private RedissonClient redissonClient;
public void processOrder(Long orderId) {
RLock lock = redissonClient.getLock("lock:order:" + orderId);
try {
// 尝试获取锁:
// - 等待时间: 10秒
// - 锁自动释放时间: 30秒
// - 时间单位: 秒
boolean locked = lock.tryLock(10, 30, TimeUnit.SECONDS);
if (locked) {
try {
// 执行业务逻辑
// ...
} finally {
lock.unlock();
}
} else {
throw new BusinessException("获取锁超时");
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new BusinessException("获取锁被中断");
}
}
}Redisson的优势:
-
看门狗自动续期:
默认锁过期时间: 30秒 看门狗检查周期: 10秒 如果业务未完成,自动续期: T=0s: 获取锁,过期时间30s T=10s: 看门狗检查,续期到40s T=20s: 看门狗检查,续期到50s T=25s: 业务完成,释放锁 -
可重入锁:
javaRLock lock = redissonClient.getLock("myLock"); lock.lock(); try { methodA(); // methodA内部也获取myLock,不会死锁 } finally { lock.unlock(); } -
RedLock (多实例):
javaRLock lock1 = redisson1.getLock("lock"); RLock lock2 = redisson2.getLock("lock"); RLock lock3 = redisson3.getLock("lock"); RedissonRedLock redLock = new RedissonRedLock(lock1, lock2, lock3); try { redLock.lock(); // 业务逻辑 } finally { redLock.unlock(); }
5.3 过期策略与内存淘汰
5.3.1 过期删除策略
Redis采用惰性删除 + 定期删除组合:
惰性删除:
客户端查询key时:
1. 检查key是否过期
2. 如果过期:
- 删除key
- 返回nil
3. 如果未过期:
- 返回value定期删除:
Redis每100ms执行一次(serverCron):
1. 随机抽取20个设置了过期时间的key
2. 删除其中已过期的key
3. 如果过期key比例>25%,重复步骤1
单次执行时间限制: 25ms
目的: 避免阻塞主线程5.3.2 内存淘汰策略
当内存达到maxmemory限制时,触发淘汰:
8种淘汰策略:
| 策略 | 说明 |
|---|---|
| noeviction | 不淘汰,写操作返回错误(默认) |
| allkeys-lru | 所有key中淘汰最少使用的 |
| allkeys-lfu | 所有key中淘汰访问频率最低的 |
| allkeys-random | 所有key中随机淘汰 |
| volatile-lru | 有过期时间的key中淘汰最少使用的 |
| volatile-lfu | 有过期时间的key中淘汰访问频率最低的 |
| volatile-random | 有过期时间的key中随机淘汰 |
| volatile-ttl | 有过期时间的key中淘汰TTL最小的 |
配置:
conf
maxmemory 10gb
maxmemory-policy allkeys-lru # 推荐场景选择:
缓存场景 (所有数据都可淘汰):
→ allkeys-lru / allkeys-lfu
混合场景 (部分数据不能淘汰):
→ volatile-lru / volatile-ttl
→ 永久数据不设过期时间
极致性能 (牺牲准确性):
→ allkeys-random (无需LRU算法计算)总结
本文从Redis核心原理、数据结构、持久化、高可用、生产实战五个维度,深入剖析了Redis的技术体系:
核心原理篇:
- 内存存储、单线程、I/O多路复用、高效数据结构是Redis高性能的四大支柱
- 全局哈希表的渐进式rehash机制,优雅地解决了动态扩容问题
数据结构篇:
- 五大基础类型(String/Hash/List/Set/ZSet)底层编码的自动转换,兼顾性能和内存
- 三大高级类型(HyperLogLog/Bitmap/GEO)解决特定场景的极致优化
持久化篇:
- RDB快照的COW机制,保证高性能
- AOF日志的可靠性,保证数据安全
- 混合持久化结合两者优势,是生产环境的最佳选择
高可用篇:
- 主从复制实现数据备份和读写分离
- Sentinel提供自动故障转移
- Cluster实现数据分片和水平扩展
生产实战篇:
- 缓存雪崩/击穿/穿透/热点key的解决方案
- 分布式锁的正确实现和Redisson实践
- 过期策略和内存淘汰的原理
Redis作为现代架构的核心组件,深入理解其底层原理和最佳实践,是每个后端工程师的必修课。希望本文能帮助你建立Redis的系统性认知,在实际项目中游刃有余地运用Redis技术。
参考资料:
- 《Redis设计与实现》- 黄健宏
- 《Redis开发与运维》- 付磊 张益军
- Redis官方文档: https://redis.io/docs/
- Redis源码: https://github.com/redis/redis