本节目录
代理是什么
在计算机网络和系统架构中,代理是指一个中间人,它代替客户端或者服务器去执行某些操作,通常用于转发请求、增强安全性、提升性能或实现访问控制。而根据角色的不同,代理可分为多种类型,最常见的是正向代理和反向代理:
正向代理:
正向代理就是中间人代表客户端去向服务器发起请求,服务器看到的也是代理的 ip,不知道真实客户端是谁。这种方式一般用于突破网络限制、匿名浏览、公司内网统一出口等情况。
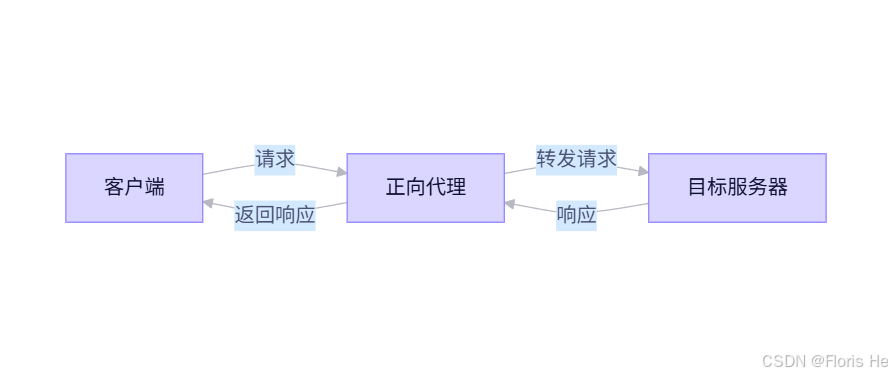
正向代理示意图
反向代理:
反向代理刚好相反,它是中间人代表服务器接收客户端请求,并将请求转发给内部的真实服务器。客户端看到的是代理的地址,以为这就是访问的目标服务,从而可以隐藏真实服务器。这种方式一般用于负载均衡、HTTPS 解密、Web 防火墙、微服务网关等场景。
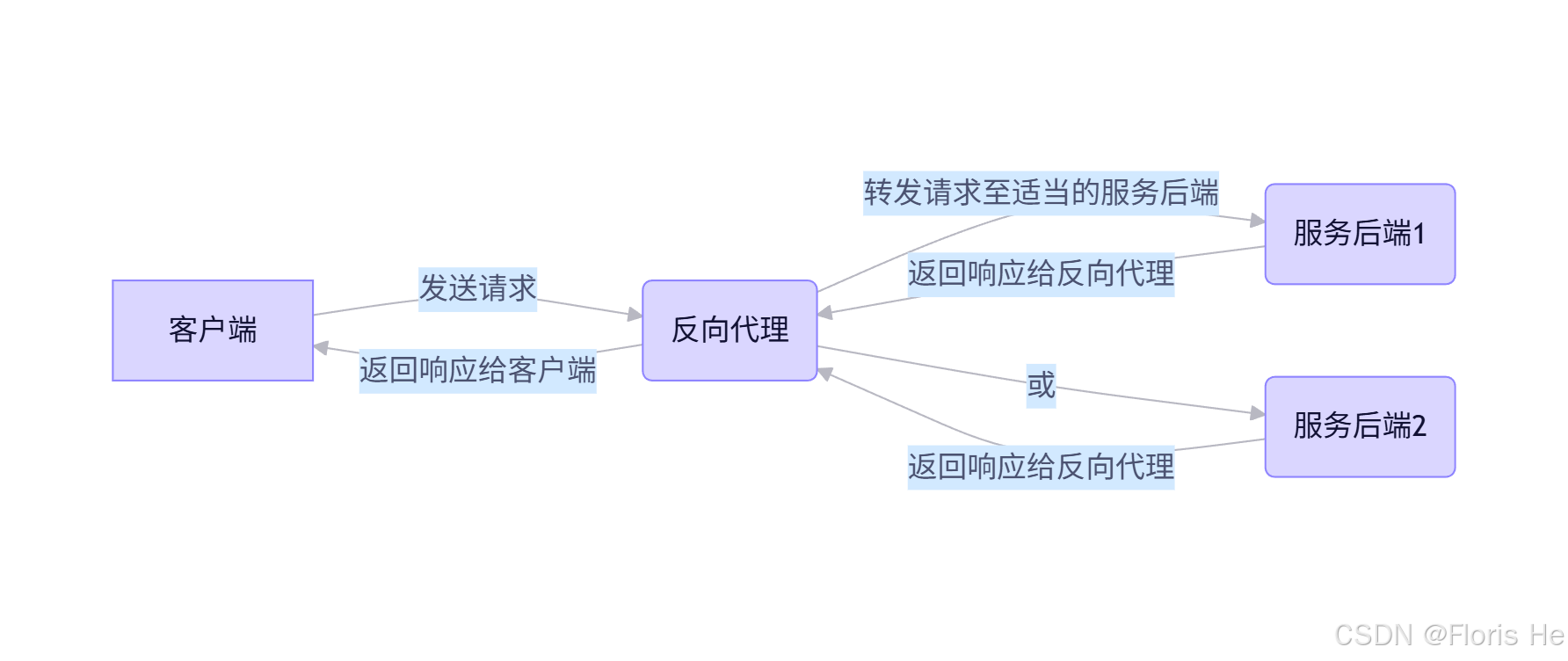
反向代理示意图
HTTP 反向代理流程
下面以 nginx 为例,当客户端请求到达前置 nginx 服务器时,流程如下图所示:

在上述流程中,nginx 需要使用 ngx_http_proxy_module、ngx_http_headers_module、ngx_http_upstream_module、ngx_http_proxy_cache_module 等模块。下面是反向代理各个阶段可以配置的项目:
-
proxy_pass指令设置后端服务器地址:nginxlocation /v1 { proxy_pass http://backend; proxy_pass http://192.168.1.10:8080; } # 针对商业版 nginx 的主动健康检查,开源版 nginx 忽略即可 match server_ok { status 200; # 设置期望状态码 header Content-Type = application/json; # (可选) 检查响应头 body ~ "status ok"; # (可选) 使用正则检查响应体是否包含特定字符 } # 定义负载均衡组 upstream backendName { server node1:8080 weight=5; # server 指定后端对象,weight 指定权重,数字越大越容易被选择 server node2:8080 max_fails=3 fail_timeout=15s; # 被动健康检查,在 15s 时间窗口内,连续失败达到3次,会被标记为不可用 server node3:8080 down; # 标记此服务器停用 server node4:8080 max_conns=2000 # 限制分配给该服务器的最大活跃连接数,防止后端被冲了(nginx-1.11.5之前为商业版功能,现已开源) server 192.168.1.12 backup; # 备用机,当所有非 backup 都挂了,就连接这台 keepalive 32; # 保持 32 个长连接,降低 nginx 连接后端服务器的开销 ip_hash; # 使用符合场景的负载分配算法 # 以下功能适用于商业版(nginx plus) server node5:8080 slow_start=15s # 设置服务器为慢启动,防止才恢复的服务因过载又被标记为不可用 zone backend_mem 64k; # 存储所有的 worker 健康状态,适用此方式进行健康检查,就无需 max_fails 等指令了 } location /api { proxy_pass http://backendName; # 使用上面定义的名称 health_check interval=5s fails=3 passes=2 uri=/ishealth match=server_ok; # 启用主动健康检查(商业版功能) } location /aaa { # url 末尾 / 的坑,假如请求访问 http://abc.com/aaa/bbb proxy_pass http://backend; # 不带 /,则后端收到的请求是完整的 uri,既 /aaa/bbb # proxy_pass http://backend/; # 带 /,则后端收到的请求是完整的 uri,既 /bbb(/aaa 在 location 上出现,被截断) }注意:
- 路径开头必须写上
http://、https://; - 同一个 location 只能存在一条
proxy_pass指令,存在多条的话最有最后一条生效; - 若 url 末尾带
/,则会删除 location 上匹配的路径部分(路径重写行为不同);(见上述示例) - 如果 location 使用了正则表达式匹配,则此指令中 url 不能包含任何 uri 部分(既只能是
http://node:8080这种形式,不能是http://node:8080/api这种形式); - 如果 upstream 块中只有一台服务器,那么
max_fails、fail_timeout、slow_start参数都无效,因为只有一台后端将永远无法视为不可用; - 负载均衡组中的 keepalive 只会影响 nginx 到后端服务器,与客户端连接是否具备 keep-alive 无关。
知识连接:开源版 nginx 存在被动检查的局限性(使用max_fails指令,用户必须请求失败一次,nginx 才知道后端挂了)。而在商业版(nginx plus)或 tengine(阿里巴巴基于开源 nginx 深度定制和优化后开发的)上就支持主动健康检查,即 nginx 主动定期发请求探测后端。
- 路径开头必须写上
-
proxy_set_header设置转发给后端的请求头,默认情况下后端服务器看到的请求头信息是代理服务器的,而非真实用户的,为了让后端获取用户真实信息,必须手动设置 header;nginxproxy_set_header Host $host; # 保留原始 Host proxy_set_header X-Real-IP $remote_addr; # 传递真实客户端 ip proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; # 追加代理链 proxy_set_header X-Forwarded-Proto $scheme; # 传递原始协议注意:
- nginx 的配置继承逻辑是覆盖式的,如果在 location 块中定义了任何一个
proxy_set_header,那么 http 或 server 块中定义的所有proxy_set_header都会在该 location 中失效,必须全部重写。
- nginx 的配置继承逻辑是覆盖式的,如果在 location 块中定义了任何一个
-
proxy_redirect修改后端返回的 location 或 refresh 头中的地址,后端返回的一般都是私有地址,使用此指令的任务就是把这些内部地址翻译成客户端可以访问的外部公网地址;nginxproxy_redirect default; # 自动模式,nginx 默认开启,绝大多数情况下够用了 proxy_redirect http://backend/ https://abc.com/; # 手动模式,将内部地址替换为 https://abc.com/使用建议:
- 仅当后端服务器返回 301 或 302 状态码,且包含 Location 响应头时才使用的到此指令;
- 如果你确定不需要 nginx 动你的 header(如你正在做一个透明代理),就可以显式关闭
proxy_redirect off;
-
proxy_connect_timeout & proxy_send_timeout & proxy_read_timeout控制与后端连接的超时时间;nginxproxy_connect_timeout 5s; # 连接后端服务器超时,超时错误码 502 或 504,默认都是 60s proxy_send_timeout 10s; # 向后端发送请求超时,超时错误码 408 或重置连接 proxy_read_timeout 30s; # 后端返回响应超时,超时错误码 504注意:此处的 send 和 read 设置的是两次网络操作之间的时间间隔,如果后端一直在断断续续的发送或接受数据,那么两个断续之间的时间只要不超过设置时间,连接就会一直存在。
使用建议:- connect 建议无脑设置,如果后端服务器宕机或网络不可达,nginx 可以马上做出调整;
- 如果存在超大文件上传,建议将 send 值调大,否则超时 nginx 会主动断开连接;
- 如果后端服务器是执行的超耗时处理,建议将 read 值调大,否则超时 nginx 会主动断开连接。
-
proxy_buffering决定了 nginx 在接收后端服务器的响应时,是先存起来之后再统一发给用户,还是边收边发;nginxproxy_buffering on # 先收完后端响应后,再统一发给客户端(默认值) proxy_buffering off # 流式转发(尽量流式,受客户端、后端等影响) proxy_buffer_size 4k; # 设置存储 hander 头的缓冲区大小 proxy_buffers 16 4k; # 设置 body 内容的缓冲区大小 proxy_busy_buffers_size 8k; # 控制在响应还没完全读完时,允许向客户端发送多少数据 proxy_max_temp_file_size 0; # 当内存缓冲区占满后,nginx 允许将多大的响应写入磁盘临时文件 proxy_temp_path /data/nginx_temp; # 如果设置了可以写入磁盘文件,则需设定具体路径使用建议:
- 对于通用 web 应用来说,可以不用管它,它默认是开启的,可以显著减轻后端服务器的压力;(适合 90% 的网站)
- 如果是做实时监控画面或者像 AI 逐字输出那样的流式响应,那就建议关闭。(适合实时通信的网站)
-proxy_buffer_size一般 4~8k 足够,但如果使用了大量 cookie 或自定义 hander,则需要调大到 16~32k左右;(根据实际情况调整) proxy_buffers这个值不能太小,要保证 页面数量 X 大小 能够覆盖 80% 以上的 body 内容;proxy_busy_buffers_size一般建议设置为单个页面大小的两倍,如果proxy_buffers 8 8k是这设置的,则此项就可以设为 16k;- 如果你不希望大文件下载占满了磁盘,那么建议设置
proxy_max_temp_file_size 0,如果你是视频等流媒体服务,可以缓存大文件,那么proxy_max_temp_file_size可以设为具体值,如proxy_max_temp_file_size 2G。
-
proxy_cache使用反向代理缓存,当下一个用户请求相同的内容时,nginx 直接读取本地缓存,就不再请求后端服务器;nginx# 定义缓存位置为 /var/cache/nginx # 定义缓存目录层级为 1:2,防止同一个文件夹下文件太多 # 定义缓存名称和内存索引大小 # 定义缓存最大容量 # 定义超时时间,超时后无人访问将强制删除 proxy_cache_path /var/cache/nginx levels=1:2 keys_zone=myCache:10m max_size=1g inactive=60m use_temp_path=off; proxy_cache myCache; proxy_cache_valid 200 302 10m; # 对于成功的响应缓存 10 分钟 proxy_cache_purge myCache $host$1$is_args$args; # 提供一个手动或 api 触发缓存清理(开源版 nginx 需额外安装此模块,商业版无需)注意:
- 不要缓存动态数据,如果后端返回的响应头包含 Set-Cookie,nginx 通常不会缓存该请求,以防止消息发送混乱。
- nginx 默认使用 url 加上主机名作为缓存键。如果你的 url 里有不同的参数(?user_id=1 和 ?user_id=2),它们会被当做不同的缓存,这个无需担心;
- 当你的内容更新后,但 nginx 里的缓存还没过期,用户看到的依然是旧数据,这时需要手动清理(开源 nginx 需要安装插件(
ngx_cache_purge模块)、手动删除磁盘文件或后端直接使用新值(旧值等待过期即可))
-
proxy_next_upstream 容灾或重试,若当前后端服务器出现问题,nginx 会尝试请求转发给负载均衡组中的下一台服务器处理,避免了 nginx 失败一次就把错误返给客户端;
nginxproxy_next_upstream error timeout http_502 http_503 http_504; # tcp、connect、send、read 失败后,迅速更换后端服务器重试 proxy_next_upstream_tries 3; # 最多尝试三台不同的后端,设置为 1 时不重试 proxy_next_upstream_timeout 8s; # 所有重试总耗时不超过 8s建议:
- 这是生产级 nginx 中最重要的容灾指令(没有服务网格的环境下),强烈建议添加;
- 这个这里一般配合上文中的
max_fails使用,proxy_next_upstream负责快速止血,max_fails负责剔除问题后端; proxy_next_upstream不应该对业务上的错误进行重试,如 403 状态、500 状态等。proxy_next_upstream默认不会对 post、put、patch 操作重试,可以在proxy_next_upstream上添加non_idempotent指令打开(绝大多数情况不推荐);- 对于长连接和流失请求不适合重试,如 websocket、大文件上传、SSE 等;
- 如果使用此指令,尽量不要使用 ip_hash 算法,因为重试会导致会话丢失。
下面是一份生产级的 nginx 负载均衡反向代理的配置示例:
nginx
http {
...
# 定义负载均衡集群
upstream backend {
least_conn;
server 10.0.0.11:8080 weight=5 max_fails=3 fail_timeout=30s;
server 10.0.0.12:8080 weight=5 max_fails=3 fail_timeout=30s;
server 10.0.0.13:8080 backup;
keepalive 64;
}
# 定义缓存
proxy_cache_path /var/cache/nginx/api_cache levels=1:2 keys_zone=api_cache:50m max_size=5g inactive=60m use_temp_path=off;
server {
...
proxy_http_version 1.1; # 强制使用 http1.1 与后端通信,可以保持 keepalive 长连接
proxy_set_header Connection ""; # 清空客户端传来的此 hander,防止后端收到 "Connection: close" 时关闭连接
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# 超时控制(强烈建议)
proxy_connect_timeout 3s;
proxy_send_timeout 30s;
proxy_read_timeout 30s;
# 故障转移和重试策略
proxy_next_upstream error timeout http_502 http_503 http_504;
proxy_next_upstream_tries 3;
proxy_next_upstream_timeout 10s;
# 针对默认 api,不启用缓冲
location /api/ {
proxy_pass http://backend;
proxy_buffering off;
}
# 针对可缓冲的接口
location /public/ {
proxy_pass http://backend;
proxy_cache api_cache;
proxy_cache_valid 200 302 10m;
proxy_cache_valid 404 1m;
proxy_cache_use_stale error timeout http_502 http_503 http_504;
add_header X-Cache-Status $upstream_cache_status;
}
# 主动健康检查,仅允许 nginx 自己访问,防止后端服务假活
location = /health {
allow 127.0.0.1;
deny all;
proxy_pass http://backend;
access_log off;
}
}
}负载均衡算法
轮询算法:
此算法是默认策略,依次将请求分配给 upstream 列表中的服务器。它不需要额外配置,每个请求按时间顺序逐一分配。如果使用了 weight 指令,则表示加权轮询,权重高的服务器将会接收更多请求。
应用场景:通用场景。
最少连接数算法:
此算法会将新请求分配给当前活跃连接数最少的服务器,对于处理长连接、请求处理时间差异较大的场景(如视频流、大文件上传)会有奇效。
nginx
upstream backend {
least_conn; # 启用最少连接数算法
server 192.168.1.10;
server 192.168.1.11;
}应用场景:需要长连接的、处理时间不均匀的(后端 I/O 密集型计算)。(不适合后端是 CPU 密集型计算的)
IP HASH 算法:
此算法是根据客户端 ip 地址的哈希值决定将请求分配给哪台后端服务器,这种方式可以确保同一客户端始终访问同一台后端服务器,实现会话保持。
nginx
upstream backend {
ip_hash; # 启用 ip hash 算法
server 192.168.1.10;
server 192.168.1.11;
}注意:
此算法在老版本中不支持 ipv6(除非使用 hash $remote_addr + consistent),在新系统中除非需兼容老架构,否则不再推荐使用 ip_hash;
若某台服务器宕机,该 IP 的请求会被重新分配(会丢失会话)。
应用场景:需要会话保持的、需要支持老系统的。
通用 HASH 算法:
此算法可以基于用户自定义的 key(如 $request_uri、$cookie_jsessionid 等)进行哈希,进而实现更灵活的会话保持或缓存亲和性。
nginx
upstream backend {
hash $request_uri consistent; # 启用通用 hash 算法,consistent 表示使用一致性哈希
server 192.168.1.10;
server 192.168.1.11;
}注意:
- hash 算法不要为每个后端服务器设置权重 weight=xx,它是一种确定性的路由算法,写上权重也是无效的。(上面的老版 ip hash 也是一样的)
- 开源版 nginx 的通用 hash 算法本质上只是一种静态 hash,不支持商业版那样的一致性 hash(
consistent_hash),只适用于简单的会话保持,想要更流弊的功能(如分布式缓存)就上 nginx plus。
应用场景:需要更灵活的会话保持或缓存的。
随机算法:
顾名思义,此算法要么就是真随机选择一台后端,要么就是先选出所有连接最少或响应时间最少的后端组成一个列表,再从此列表中随机一个后端即可。
nginx
upstream backend {
random # 完全随机选择
random two [least_conn | least_time]; # 随机选两台,再按最少连接、最少响应时间选择最终服务器
server 192.168.1.10;
server 192.168.1.11;
server 192.168.1.12;
}应用场景:高并发的、性能分布均匀的。
最少时间算法:
此算法仅限于商业版(nginx plus),允许选择平均响应时间最短且活跃连接最少的服务器。
nginx
upstream backend {
least_time [header | last_byte]; # 基于从连接建立到收到响应头的时间、基于整个响应完成时间来选择服务器
server 192.168.1.10;
server 192.168.1.11;
}应用场景:对延迟很敏感的。
附加
下面是对开源版 nginx 负载均衡算法的一些自我理解,只考虑了算法的简单实现,仅供各位参考,别当真。
-
默认轮询算法:nginx 默认对负载均衡组中定义的后端服务器列表按照顺序依次分配请求,每处理一个新请求(同时改变当前服务器权重),其完成之后选择下一个服务器,循环往复。其实现基于
平滑加权轮询算法,避免连续多次选中高权重节点,使分配更均匀。算法核心逻辑:
- 每个节点维护一个原始权重值 weight 和当前动态权重值 currentWeight;
- 每次选择的时候都要用 currentWeight + weight 来组成新的 currentWeight;
- 查看这个新的 currentWeight 谁最大,选择最大的即可;
- 最后降低节点的 currentWeight = currentWeight - totalWeight 即可。
gopackage main import ( "fmt" "sync" ) // Server 表示一个后端服务器 type Server struct { Addr string Weight int } // 轮询器 type SmoothWeightedRoundRobin struct { servers []Server currentWeight []int // 当前动态权重 totalWeight int mu sync.Mutex } // 创建一个新的平滑加权轮询器 func NewSmoothWeightedRoundRobin(servers []Server) *SmoothWeightedRoundRobin { if len(servers) == 0 { panic("server list is empty") } total := 0 // 计算总体权重 for _, s := range servers { if s.Weight <= 0 { panic("weight must be positive") } total += s.Weight } current := make([]int, len(servers)) return &SmoothWeightedRoundRobin{ servers: servers, currentWeight: current, totalWeight: total, } } // 返回下一个选中的后端服务器地址 func (swrr *SmoothWeightedRoundRobin) Next() string { swrr.mu.Lock() defer swrr.mu.Unlock() // 所有 currentWeight += weight,计算最佳节点 bestIndex := 0 for i := 0; i < len(swrr.servers); i++ { swrr.currentWeight[i] += swrr.servers[i].Weight if swrr.currentWeight[i] > swrr.currentWeight[bestIndex] { bestIndex = i } } // 选中 bestIndex,减去 totalWeight swrr.currentWeight[bestIndex] -= swrr.totalWeight return swrr.servers[bestIndex].Addr } func main() { servers := []Server{ {Addr: "192.168.1.10", Weight: 3}, {Addr: "192.168.1.11", Weight: 1}, {Addr: "192.168.1.12", Weight: 2}, } lb := NewSmoothWeightedRoundRobin(servers) for i := 0; i < 12; i++ { fmt.Println(lb.Next()) } }
-
通用 hash 算法:基于请求特征做确定性映射的负载均衡策略,其默认使用的 MurmurHash2(早期为 CRC32 算法),以获得更好的 hash 分布和更低的碰撞概率,基于
hash(key) % N的确定性路由既不支持权重,也不具备一致性 hash 的平滑迁移能力。算法核心逻辑:
- 将到来的每一个请求的 key(uri、ip等)转换为字节序列;
- 使用上面提到的这个流弊算法计算出 key 的无符号 32 位 hash;
- 对这个 hash 执行取模运算得到一个首选的后端索引;
- 拿着这个索引去找对应后端即可。(如果这个后端不可用,就顺序向下找一个可用的就行)
gopackage main import ( "fmt" ) // Server 表示一个后端节点,用于判断节点是否可用,不参与 hash 计算 type Server struct { Addr string // 后端地址 Down bool // 是否不可用 } // 实现通用 hash 负载均衡,包含一个 hash 映射好了的 server 顺序数组 type HashLoadBalancer struct { servers []Server } // 计算 32 位 hash,data 是一个 hash 的字节序列,seed 种子通常是一个固定值(最核心的算法) // 这个算法函数是 AI 给我的,反正我写不出来了,这么流弊的东西我也是蒙的,脑子秀逗了都 func MurmurHash2(data []byte, seed uint32) uint32 { const m uint32 = 0x5bd1e995 const r uint32 = 24 length := uint32(len(data)) h := seed ^ length i := 0 for length >= 4 { // 将 4 个字节合成一个 uint32 k := uint32(data[i]) | uint32(data[i+1])<<8 | uint32(data[i+2])<<16 | uint32(data[i+3])<<24 // 混合 k *= m k ^= k >> r k *= m h *= m h ^= k i += 4 length -= 4 } // 处理剩余的 1~3 个字节 switch length { case 3: h ^= uint32(data[i+2]) << 16 fallthrough case 2: h ^= uint32(data[i+1]) << 8 fallthrough case 1: h ^= uint32(data[i]) h *= m } // 最终 avalanche h ^= h >> 13 h *= m h ^= h >> 15 return h } // 创建通用 hash 负载均衡器 func NewHashLoadBalancer(servers []Server) *HashLoadBalancer { if len(servers) == 0 { panic("server list is empty") } return &HashLoadBalancer{ servers: servers, } } // 根据给定的 key 选择一个后端节点(核心) func (lb *HashLoadBalancer) Next(key string) (Server, bool) { n := len(lb.servers) if n == 0 { return Server{}, false } // 使用流弊函数计算 hash 值 hash := MurmurHash2([]byte(key), 0) // 取模映射到后端数组索引 index := int(hash % uint32(n)) // 顺序向后查找可用节点 for i := 0; i < n; i++ { pos := (index + i) % n if !lb.servers[pos].Down { return lb.servers[pos], true } } return Server{}, false } func main() { servers := []Server{ {Addr: "10.0.0.1"}, {Addr: "10.0.0.2"}, {Addr: "10.0.0.3"}, } lb := NewHashLoadBalancer(servers) keys := []string{ "/index.html", "/api/user", "/api/order", "/index.html", "/index.html", "/api/user", "/api/user", } for _, key := range keys { srv, ok := lb.Next(key) if ok { fmt.Printf("key=%-15s -> %s\n", key, srv.Addr) } } } -
最少连接数:这个算法相对简单,总计就是每次请求选择当前活动连接数和权重最小的后端,请求开始时连接数 +1,请求结束时连接数 -1 就完了。
gopackage main import ( "fmt" "math" "sync" "time" ) // Server 表示一个后端服务器 type Server struct { Addr string // 后端地址 Weight int // 权重 Conns int // 当前活动连接数 } // 实现 least_conn 负载均衡 type LeastConnLB struct { servers []Server mu sync.Mutex } // 创建一个负载均衡组 func NewLeastConnLB(servers []Server) *LeastConnLB { if len(servers) == 0 { panic("server list is empty") } for i := range servers { if servers[i].Weight <= 0 { servers[i].Weight = 1 } } return &LeastConnLB{ servers: servers, } } // 选择一个最好的后端(综合 conns 和 weight 选出最好的节点) func (lb *LeastConnLB) Next() *Server { lb.mu.Lock() defer lb.mu.Unlock() var best *Server bestScore := math.MaxFloat64 for i := range lb.servers { s := &lb.servers[i] score := float64(s.Conns) / float64(s.Weight) if best == nil || score < bestScore { best = s bestScore = score } } // 分配连接 if best != nil { best.Conns++ } return best } // 请求处理完成,释放连接 func (lb *LeastConnLB) Done(s *Server) { lb.mu.Lock() defer lb.mu.Unlock() s.Conns-- } func handleRequest(lb *LeastConnLB, reqID int, processTime time.Duration, wg *sync.WaitGroup) { defer wg.Done() srv := lb.Next() if srv == nil { fmt.Printf("request %d: no backend available\n", reqID) return } // 模拟耗时请求的处理 fmt.Printf("request %d -> %s (conns=%d, weight=%d)\n", reqID, srv.Addr, srv.Conns, srv.Weight) time.Sleep(processTime) // 请求处理完成 lb.Done(srv) fmt.Printf("request %d done -> %s (conns=%d)\n", reqID, srv.Addr, srv.Conns) } func main() { servers := []Server{ {Addr: "10.0.0.1", Weight: 1}, {Addr: "10.0.0.2", Weight: 2}, {Addr: "10.0.0.3", Weight: 1}, } lb := NewLeastConnLB(servers) var wg sync.WaitGroup // 模拟 10 个并发请求 for i := 1; i <= 10; i++ { wg.Add(1) processTime := time.Duration(300+50*i) * time.Millisecond go handleRequest(lb, i, processTime, &wg) } wg.Wait() }