大家好,我叫王世杰,目前负责 Qoder 记忆系统的开发。今天,我将为大家分享如何通过记忆能力显著提升 AI 编程效率。
在传统 AI 编码智能体的使用中,我们常遇到几个关键痛点:
- 缺乏个性化:无法记住开发者的编码规范、沟通风格或技术偏好
- 重复犯错:同样的问题可能多次发生,拖慢任务进度
- 经验无法沉淀:每次对话都像"初次见面",历史成果无法复用
- 代码库零认知:每次都要重新分析整个工程,反复获取已知的上下文信息
为解决这些问题,Qoder 引入了长期记忆机制。随着你与 Qoder 的持续互动,它会逐步构建一套动态演进的记忆库------涵盖你的个人习惯、项目上下文、踩过的坑以及成功的解决方案。这些记忆会自动整理、更新,并在后续任务中智能调用。
借助这一能力,Qoder 不再只是一个工具,而是一位越用越懂你的开发伙伴。它能在长期协作中深度理解你的需求、风格与工程语境,真正实现高效、个性化的 AI 编程体验。
一、什么是记忆
首先,我想简单地和大家探讨一下,在智能体中,我们说的记忆是什么?
在 AI 编码场景中,我们面对大量上下文与知识。那么,哪些属于记忆?
我认为记忆与知识没有本质区别,关键在于主体不同、个性化程度不同、变化速率不同。
我们可以将知识分层理解为不同层级的记忆:
- 人类共通记忆:互联网知识、大模型训练数据
- 企业记忆:公司知识库、产品文档
- 项目记忆:代码、Repo Wiki、Agents 配置
- 用户记忆:个人编码规范、团队规则
- 智能体记忆:智能体在任务执行中自主总结的经验
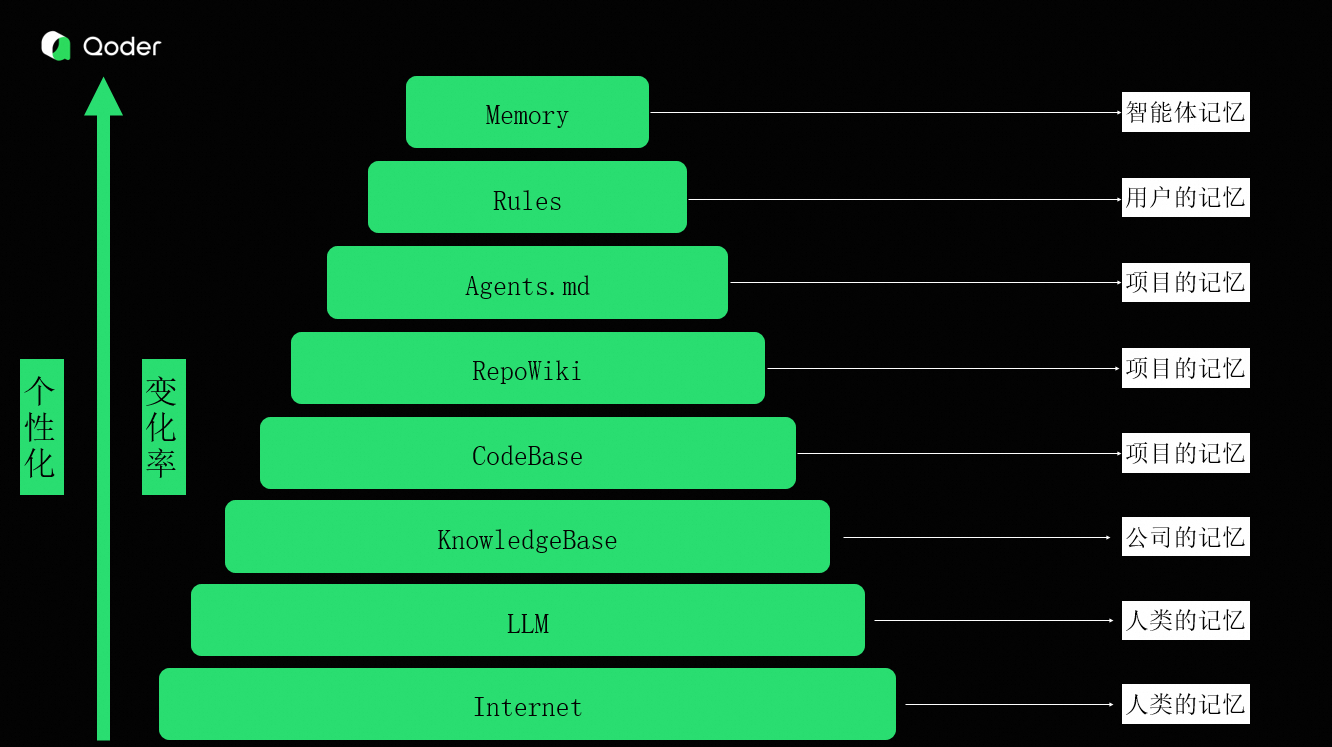
那么智能体的记忆,就是智能体在跟用户和外界的交互中,总结和存储的个性化的信息,是智能体对外部世界的理解。
二、Qoder 如何组织上下文记忆?
接下来,我们一起看下 Qoder是如何组织这些信息的。
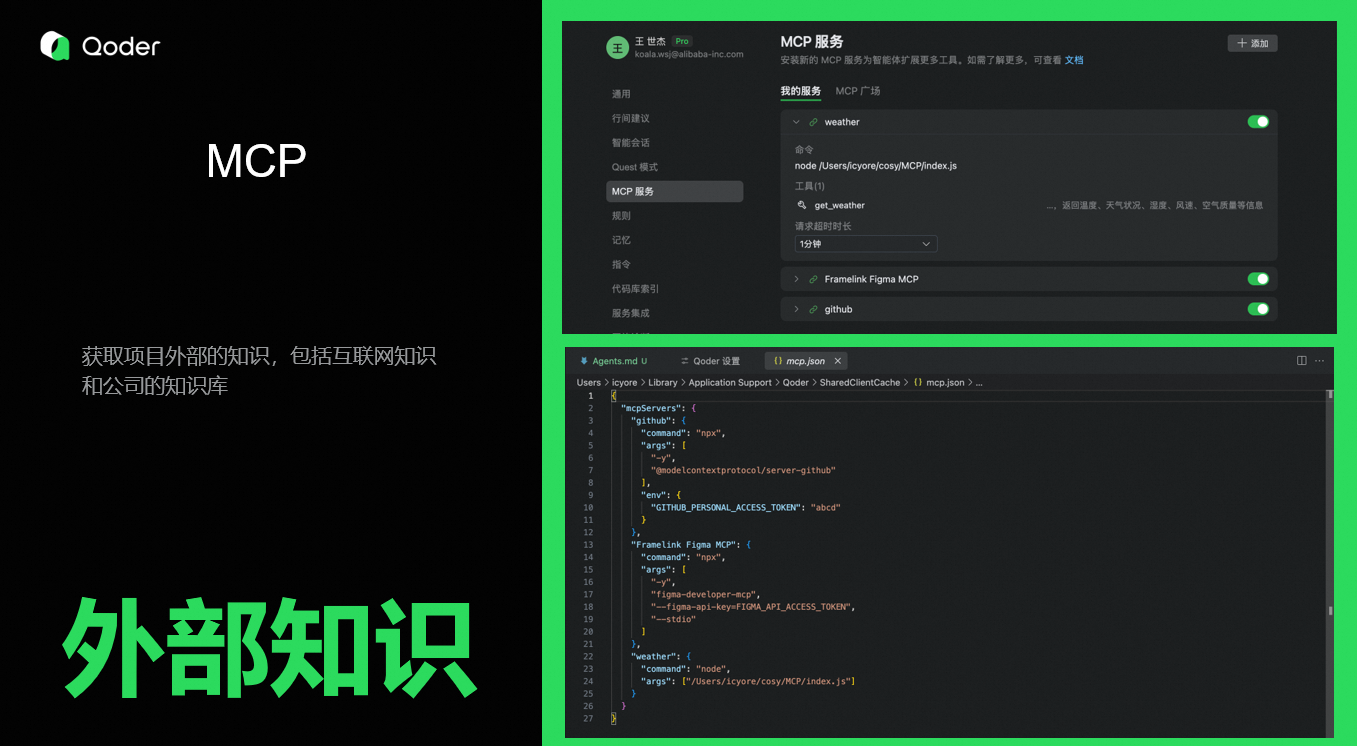
MCP
智能体背后的大模型已经学习了大部分公开的知识和源码,让AI Coding变成了可能。但训练一次周期比较长,而且不包含私有数据,如果我们要获取实时的互联网数据,或者公司私有数据,那我们可以通过MCP,对接外部信息源。
2. Repo Wiki
Wiki 是根据配置、文档、代码,自动生成项目说明书。每个分支都可以根据语言类型生成多个版本的Wiki,首次会进行全量生成,后续修改,支持增量更新。
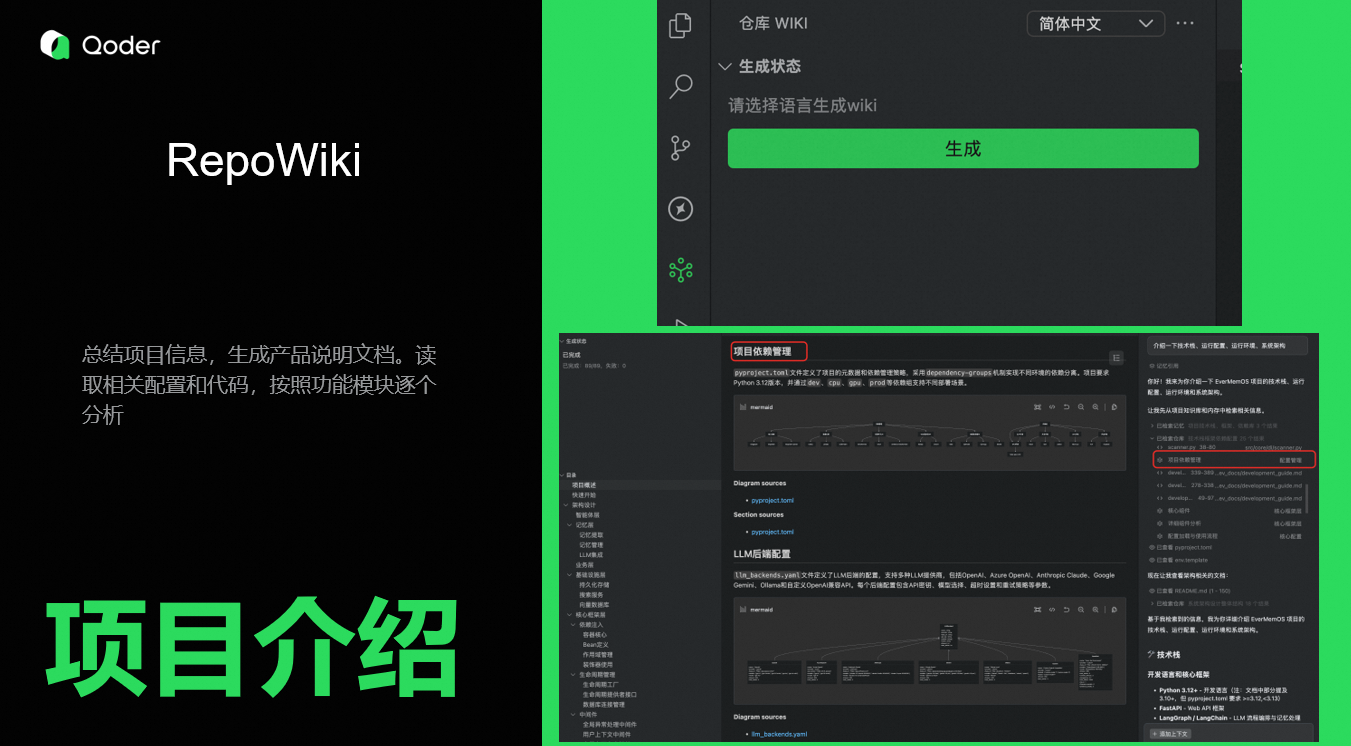
Wiki可以帮助梳理历史项目逻辑,尤其对项目新人更加友好,可以快速了解项目。可以直接看文档,也可以直接对智能体提问更通用的问题。然后在编码过程作为补充信息提供给智能体,支持智能体完成任务。
Wiki作为团队知识共享工具,支持git共享,一个人生成,全团队共用,其他人获取最新代码后,点击"**同步"**即可,避免 Credits浪费,还能节省时间。如果发现有问题的文档,还支持手动修改,从而实现团队经验共享。
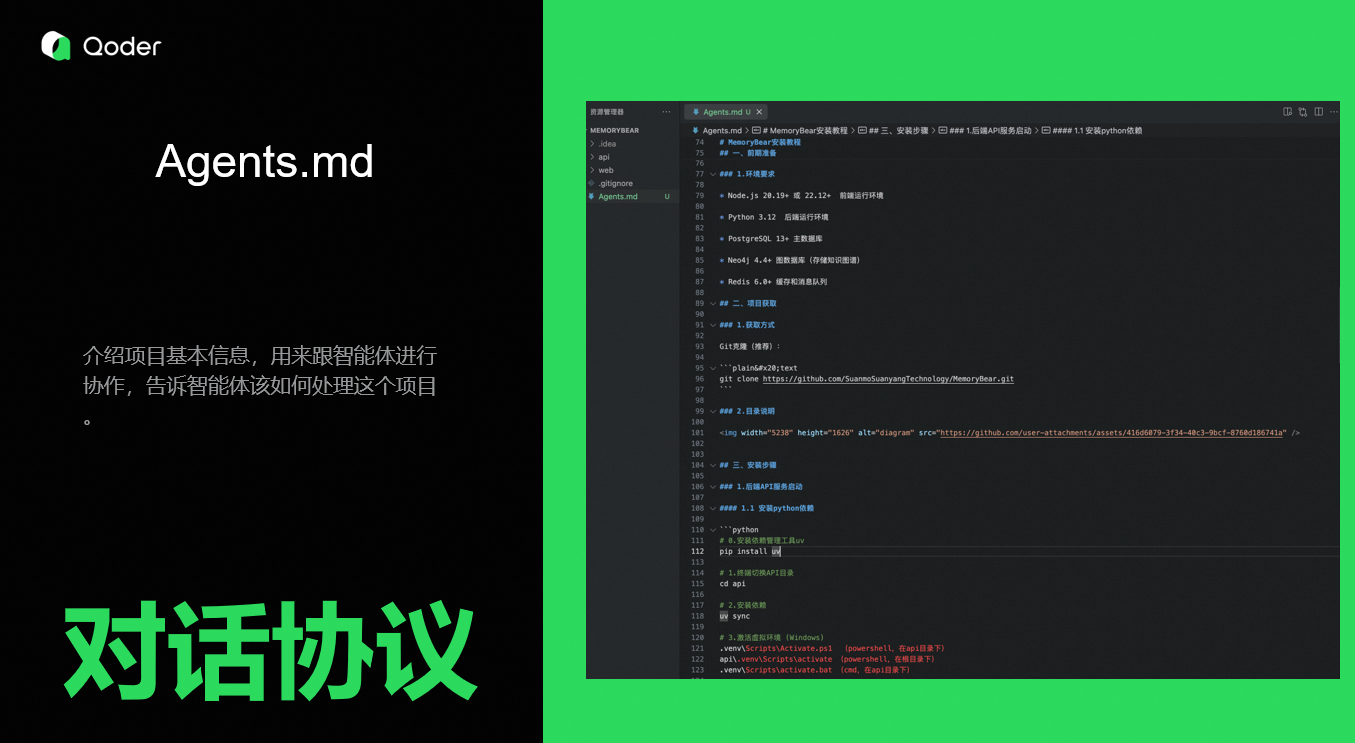
3. Agents.md
Agents是我们最近提供的能力,只要在在项目根目录创建Agents.md文件,智能体会自动读取。通过它可以介绍项目基本信息,用来跟智能体进行协作,告诉智能体该如何处理这个项目。
当前限制:最多一次读取500行或者30000字节左右,每次会话加载一次,后面对话不会重复加载,节省 Token。
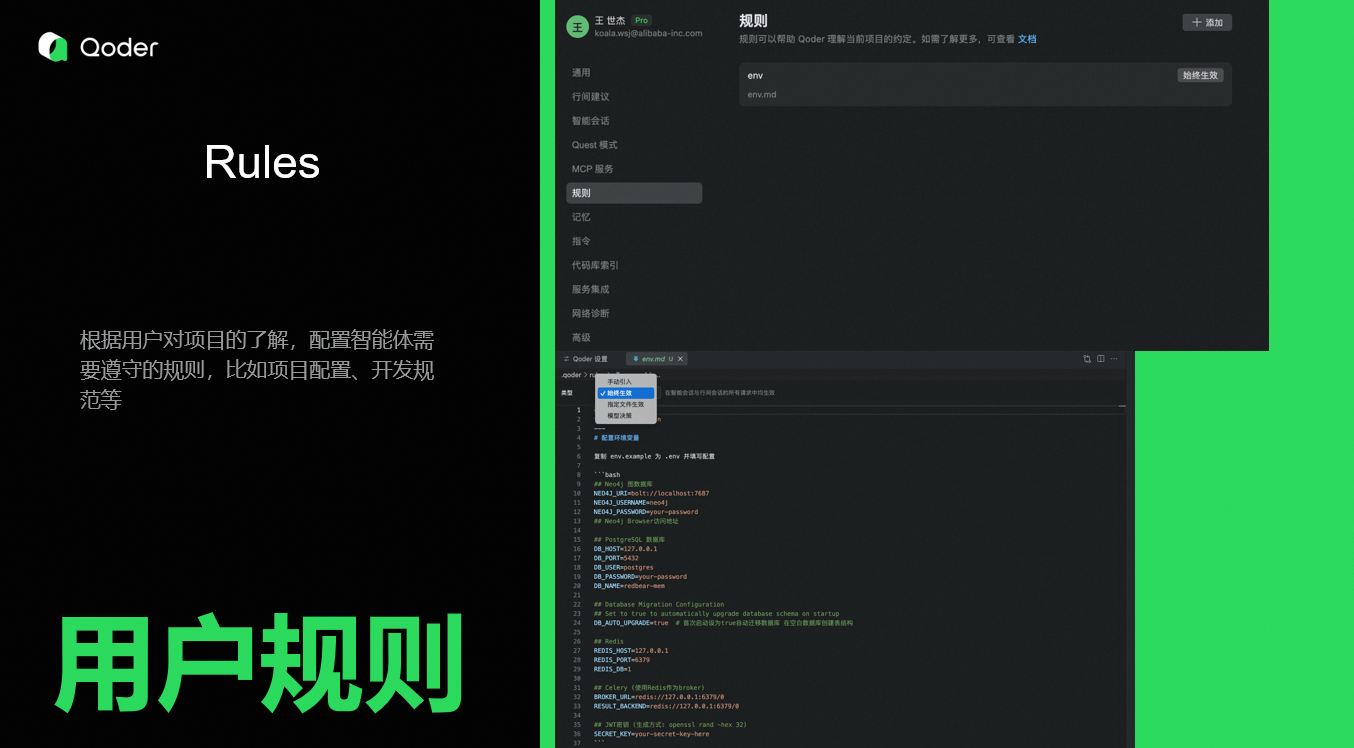
4. Rules
如果用户有自己的开发约束,可以将自己的开发规范或者环境信息,添加到规则,智能体按照规则完成任务。规则有四种生效模式:
- 始终生效:适用于所有智能会话和行间会话请求,如编码规范。
- 手动引入 :按需启用,通过智能会话面板或行间会话使用
@rule手动应用。 - 指定文件生效:仅对特定文件生效,如前端规则。
- 模型决策:模型在智能体模式下评估规则描述并决定何时应用。
5. Memory
智能体在对话中自动提取并整理:
- 用户偏好(沟通风格、个人信息)
- 项目信息(技术栈、环境配置)
- 开发规范(注释语言、测试要求)
- 历史经验(踩过的坑、成功方案)
当遇到相似任务时,智能体会主动"回忆"并复用这些记忆。

三、为什么需要记忆
1. 用户偏好
智能体可以记住用户的基本信息、爱好和沟通风格。
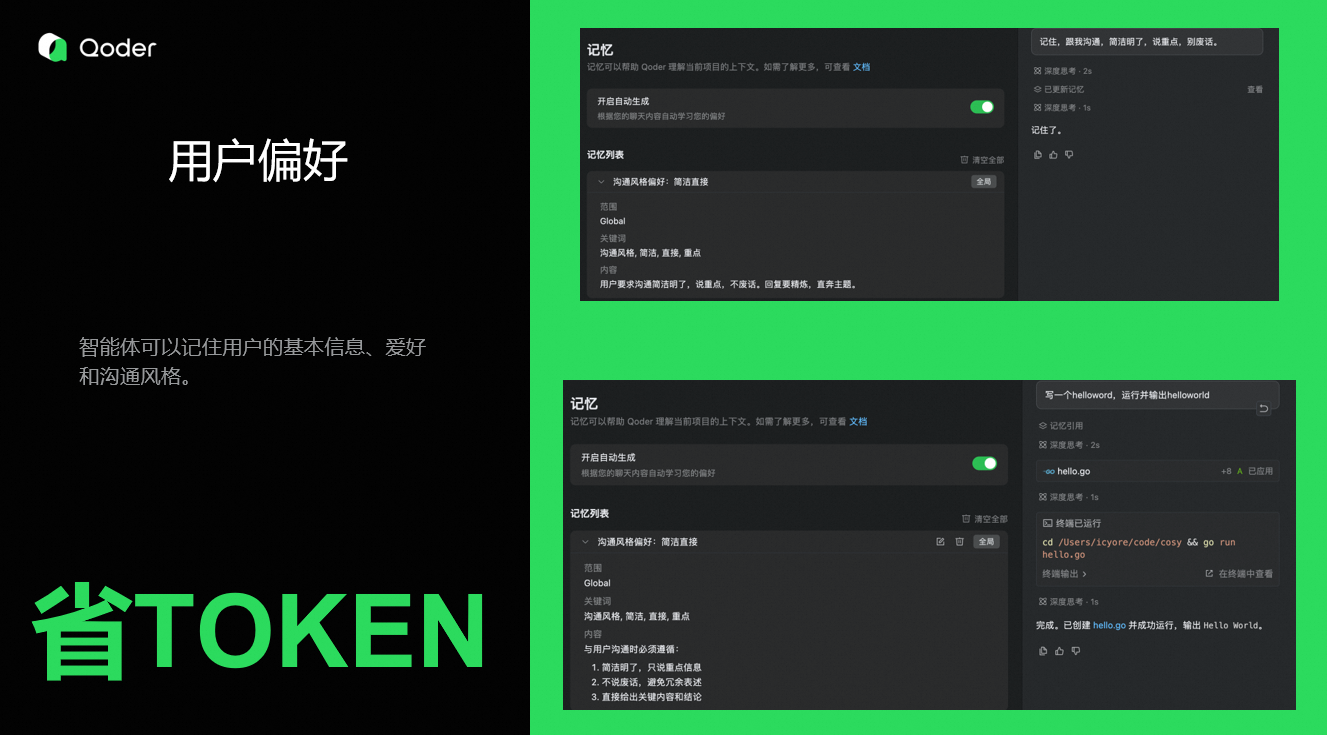
让智能体按照自己喜欢的风格进行沟通,如果不想看智能体执行细节,让他精简回答,在提速的同时降低Token的使用量,也能有效降低多轮对话时模型注意力涣散的问题。
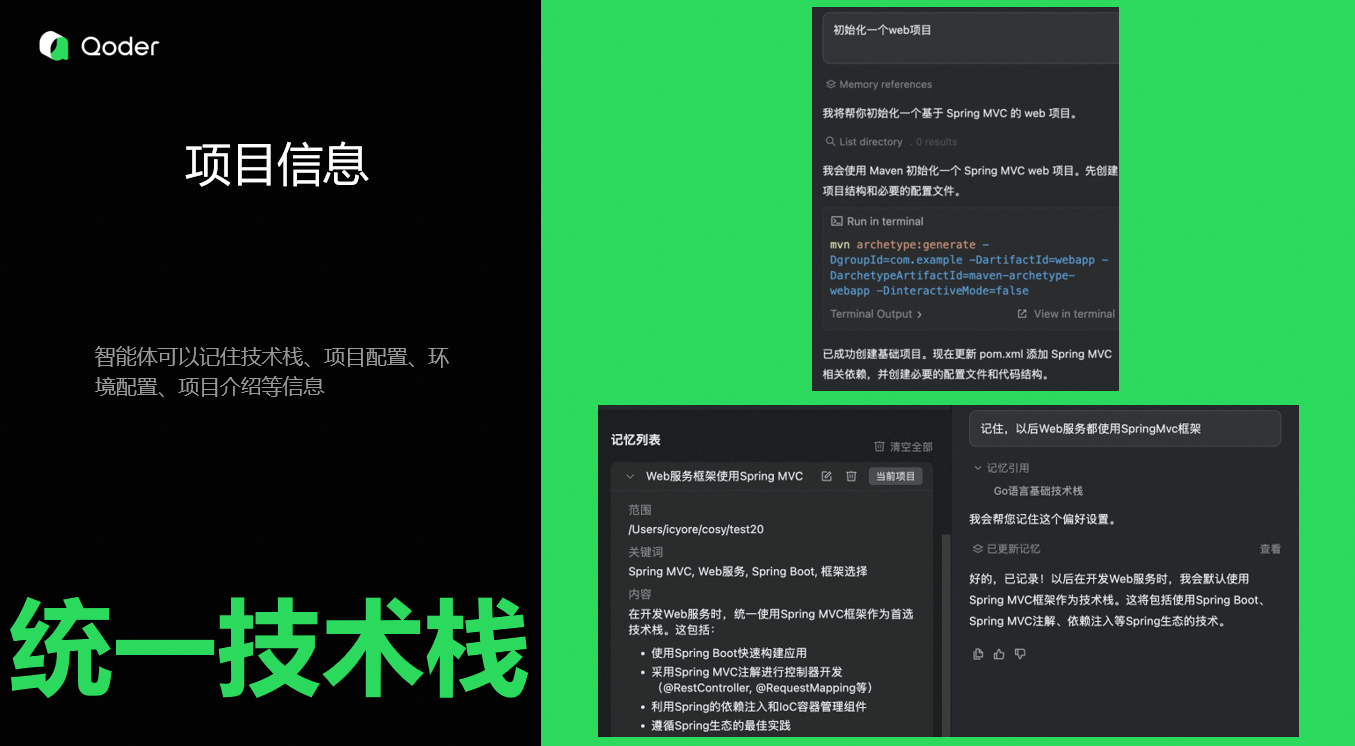
2. 项目信息
智能体可以记住项目信息,包括技术栈(如"前端 Vue3,后端 Spring Boot")、项目配置、环境配置、项目介绍等信息。比如我们经常创建新项目的话,就可以在第一次完整描述技术栈之后,让智能体记住,后续项目,直接一句话初始化项目。
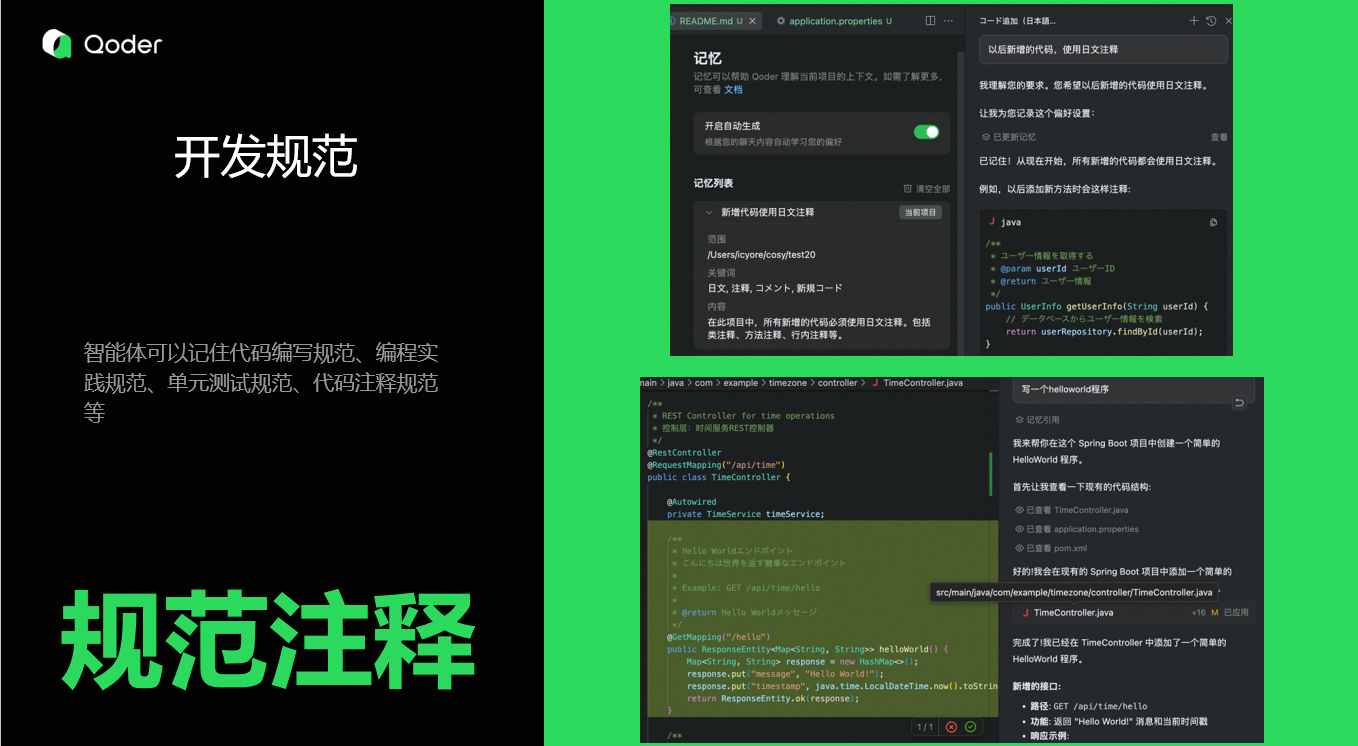
3. 开发规范
智能体可以记住开发规范,包括代码编写规范、编程实践规范、单元测试规范、代码注释规范等。约束智能体按照自己的要求完成任务。比如我们告诉他注释用日语,它即可以使用日语进行注释。
4. 历史经验复用
(1)避免踩坑
智能体能够记住之前犯过的错误,如果碰到相似的问题,就可以回忆之前记忆,避免犯相同的错误。

比如我的电脑上安装的是 Python 3,我让Qoder执行 Python程序,第一次Qoder优先尝试Python命令,发现未找到之后,尝试 python3 命令完成任务,那么第二次,再让 Qoder 去执行Python程序,那么Qoder就会直接使用 python3命令,降低工具调用次数与 Token消耗。
(2)重复经验
智能体能够记住任务处理方案,碰到相似问题,参考第一次的成功经验。

(3)相关文件预判
智能体还能记住任务相关文件, 相似的功能,往往聚集在相同的几个文件中,如果第一次修改功能,那么下次修改,如果是相似功能,智能体可以直接根据记忆,读取这相关文件进行修改,避免走弯路。

以上是我感觉比较常用的场景,长远来看,记忆可以做更多的事情。
我所理解的"氛围编程",并不是程序员简单地发出指令,智能体被动执行,而是在一个充满协作与理解的对话氛围中,程序自然地被构建出来。在这个过程中,智能体不再是代码的执行者,而是具备记忆能力的协作者------它能主动思考、提出问题,与程序员展开深入探讨,共同完成需求对齐和软件设计。
在现实中,越来越多的需求不再经过完整设计,就被直接交给智能体处理。需求的粒度越来越粗,甚至很多时候程序员自己都没有想清楚,就急于让智能体去实现。结果往往是前后逻辑冲突,因为智能体太听话了,认真来回修改,不仅浪费时间,也消耗宝贵的token资源。如果没有一个能够记住多个目标,并且具备反思能力的智能体,这类问题几乎是不可避免的。
在产品开发中,不应该把细节强加给人的大脑,而是让智能体来承担这部分记忆负担,从而释放程序员的思维。人脑并不擅长细节记忆,我经常写完代码,过两天自己都不认识了。而智能体可以做得更好,它能记住所有细节,让我们专注于更有创造性的工作。未来的编程,应该是程序员与智能体在更高维度进行高效协作的过程。程序员的角色将从"编码执行者"转变为"创意引导者"。

最后,讲一个智能体的附加价值,我觉得对我还挺有用的。作为一名程序员,我也深知这份工作的孤独。夜深人静时,面对沉默的电脑,常常感到疲惫与无助。
随着AICoding的发展,任务的颗粒度变得越来越粗,跟人协同编程的机会越来越少。市场上,一人公司比比皆是,个体开发者更容易陷入孤立无援的境地,有时候一个问题迟迟解决不了,真的很想骂人。
如果AI编程已成为不可逆的趋势,那我希望,我能与一个有温度的智能体一起工作。我希望我的工作过程是愉快的、舒适的。我希望它能理解我,在我崩溃时给予安慰;在我完成一项复杂任务时,给予肯定与鼓励,在我陷入思维陷阱时能够及时的提醒我。这条通往未来之路任重道远,但我们可以迈出第一步。
我在准备这个case的时候,虽然知道是我要求智能体如何回复我,但它真实的输出安慰的话,感觉心情舒畅很多。

当然,也有很多人不需要这样的安慰和鼓励,那就可以让智能体给你上点强度,可以直接粗暴一点,也会很有意思。比如碰到需求冲突的场景,它可以很幽默的指出来。

四、如何高效使用记忆
现在我们知道了什么是智能体记忆,也知道了它有什么样的价值,现在让我们把它用起来。
目前,系统已提供一个记忆管理页面,用户可以在其中查看当前的记忆列表,并对特定记忆进行修改或删除操作。然而,随着记忆数量的增加,手动维护这些记忆会变得既繁琐又低效。很多时候,用户也难以判断某条记忆是否有用。
所以我们不推荐用户积极主动去"管理"它。相反,我们希望用户在与智能体互动的过程中,能自然地感受到它的"成长"------越来越聪明、越来越懂你。这才是记忆存在的真正价值。

因此,我们选择将记忆的管理和优化交给智能体本身。它自己会进行记忆管理,用户无需时刻干预,就能享受更加智能的协作体验。
但用户的反馈依然非常重要,尽管智能体在努力"读懂"用户,但如果某些记忆引用确实误导了它,我们鼓励用户主动介入。例如:
-
删除不再相关的记忆;
-
手动修改记忆内容以提升准确性;
-
上报问题,帮助我们持续优化记忆系统。 这种在"出错时"的轻量级干预,是一种低成本而高效的纠错机制,能够显著提升后续交互的质量和效率。

相比在记忆管理界面操作记忆,我们推荐更自然的智能体教育,通过对话让它了解你,按照你的要求完成任务。你可以把智能体当作一个刚出生的小孩,持续去培养他,这样就能更加懂你,更加智能。
- 记住,XXX。
- 不要忘记XXX。
- 请确保XXX。
接下来,我跟大家分享下我是如何教育Qoder的。
记忆操作
首先是最简单的记忆增删改查,可以直接告诉智能体,想记住什么,想修改什么,想删除什么,想回忆什么。
-
先告诉 Qoder,你叫什么
-
问问他,是不是还记得你
-
改个名字,看看能不能记住
-
删掉不想要的记忆

这是最基础的增删改查操作,后面的技巧也是基于这四个基础操作。
用户偏好
可以把智能体当做一个小助手,让它记住你的偏好,尝试将一些常用的任务教给它,写代码的间隙,顺手帮你完成。
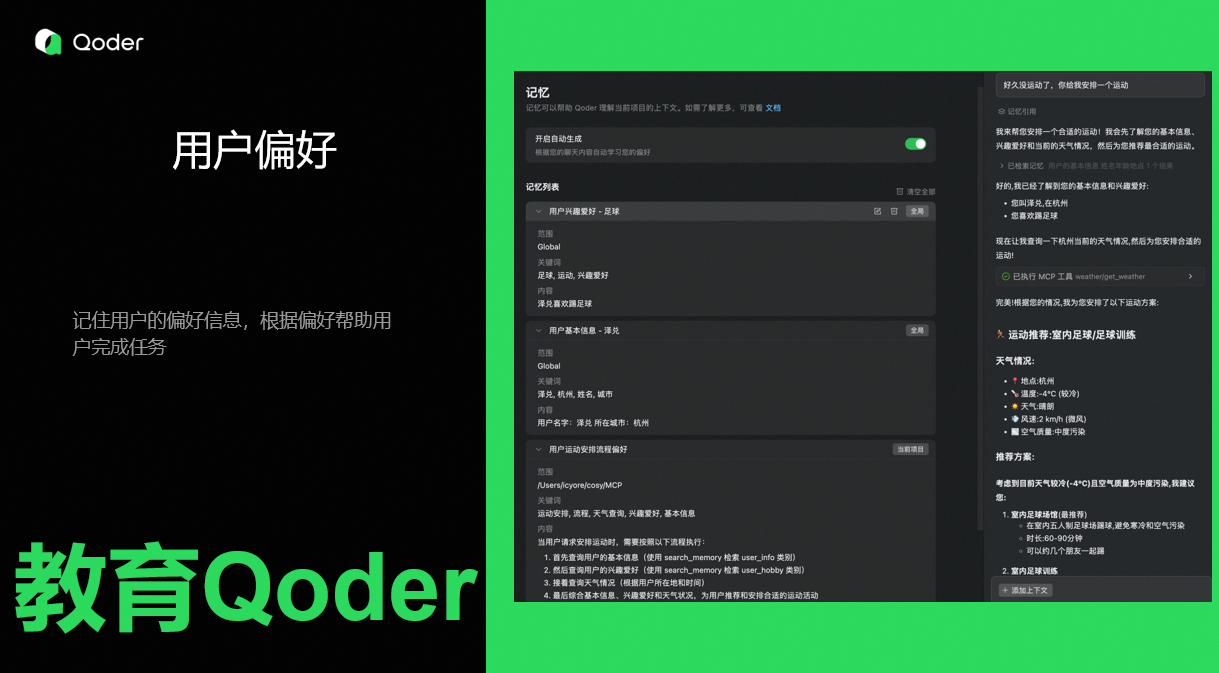
-
先介绍一下自己,让 Qoder 了解你。
-
教教 Qoder,让Qoder学会如何帮你安排运动。先查基本信息和爱好,然后查询天气情况,根据天气安排运动。
-
试试效果,看Qoder学会了没有。Qoder会回忆你的基本信息和爱好,然后根据天气给你安排一个运动。
大家可以尝试让Qoder帮一些小忙。
记忆冲突
随着使用时间的增长,智能体会记录越来越多的记忆,但有些记忆可能是陈旧的,不再适合最新的任务。所以,如果新需求跟历史记忆有冲突,用户需要及时介入,明确告诉智能体,以需求为准还是以记忆为准,如果是以需求为准,需要修改或者删除记忆,然后按照需求要求完成任务。

-
教教智能体,该如何处理冲突的记忆。
-
想不起来怎么办,沟通风格里提醒一下,碰到冲突应该怎么办。
-
试试记忆冲突,看看它的反应。它发现了冲突,还回忆起该如何解决冲突,现在需要用户决策。
-
用户选择了使用新的记忆,而且要求以后都用新的需求执行。智能体按照要求完成了任务,并且修改了记忆,这样下次就不会冲突了。
任务确认
修改代码是高危操作,可以让智能体先规划任务,详细描述要修改的内容,让用户判断无误后再执行,降低代码被改坏的风险。
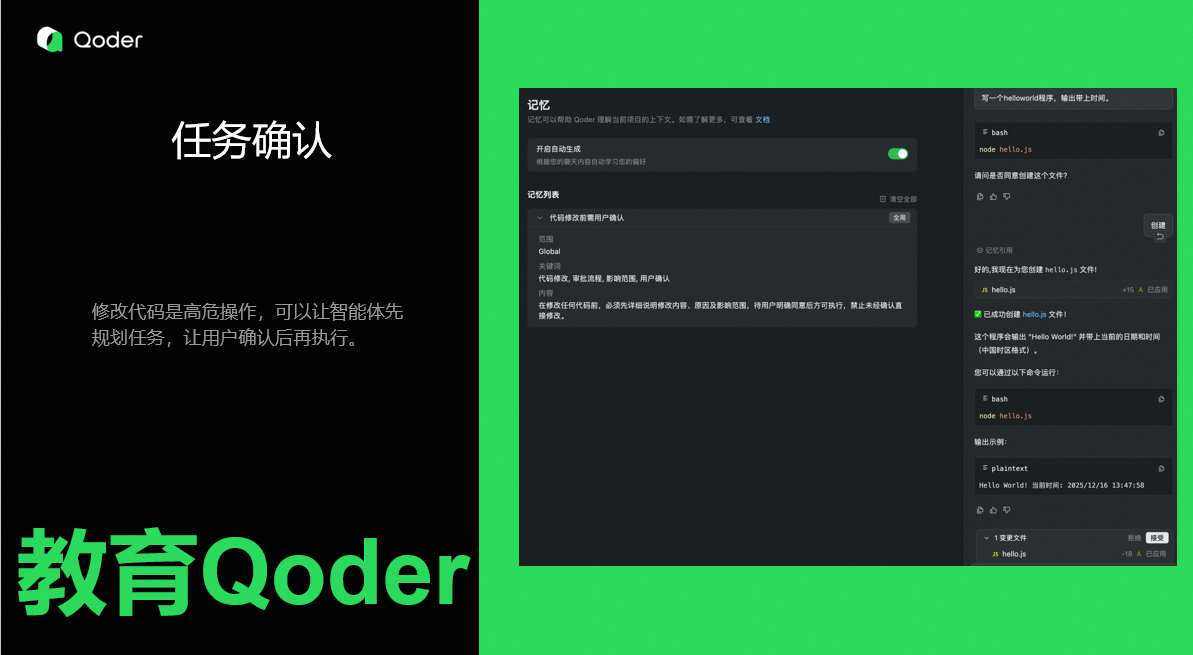
-
教育智能体,修改代码要先找用户确认。
-
修改代码,等待用户确认,用户同意后才会去修改代码。
五、如何打造记忆系统
接下来,我简单介绍一下如何打造一个记忆系统。
目前来看,未来记忆系统主要有三条演进路径:

-
生物启发-类脑
我们知道,人脑的能量利用率是很高的,生物启发方案的优点在于能耗低,未来能源成为瓶颈,可能是一个很好的替代方案。
-
参数精炼-大模型
大模型虽然推理速度快,泛化能力强,但是短板也很明显,效率低、准确性和稳定性差、成本高。
-
生态扩展-外挂记忆
外挂记忆技术成熟、落地迅速、 技术演进基础。通过外挂记忆,低成本收集和整理记忆,完成模型训练,让大模型记住。
未来记忆要走向融合,根据场景,进行不同深度的思考。模型记忆适合追求效率和泛化的场景,而外挂记忆则更适合需要高精度、可解释性和灵活控制的应用环境。
未来的记忆系统,要超越人脑,不仅要准确、稳定、高效、超大规模,还要能够迁移、共享、压缩与创新等,比如可迁移能力,我们以后可以在任何终端,无差别的跟同一个智能体对话。
共享能力,可以让团队协作变得更简单,任何智能体可以随时调用整个团队的经验来完成任务,对新人更加友好。当然,这可能也是一个新的商业模式,通过共享经验来盈利将变成可能,因为在未来,通用知识被大模型全部吃掉后,公司和个人,创造性的个性化问题解决方案,才有价值。
记忆生成
我们会在多个场景进行记忆提取,比如:对话结束、点采纳等。我们只提取重要的记忆内容,比如记忆是否是新的记忆、记忆是否有助于完成任务,将来是否可复用等。记忆提取后,会分类到不同的类型,避免记忆混淆在一起,增加维护成本,影响检索效果。

在提取的过程中,在模型提取后,我们会进行质量评估,只有达标的记忆才有价值被存储下来,避免记忆爆炸。新的记忆如果根历史记忆有冲突,需要及时进行冲突处理。
记忆检索
检索的核心流程是识别用户的意图,先召回一次非常相关的记忆和概览,然后智能体再根据任务的执行情况,通过记忆工具获取更多细节。
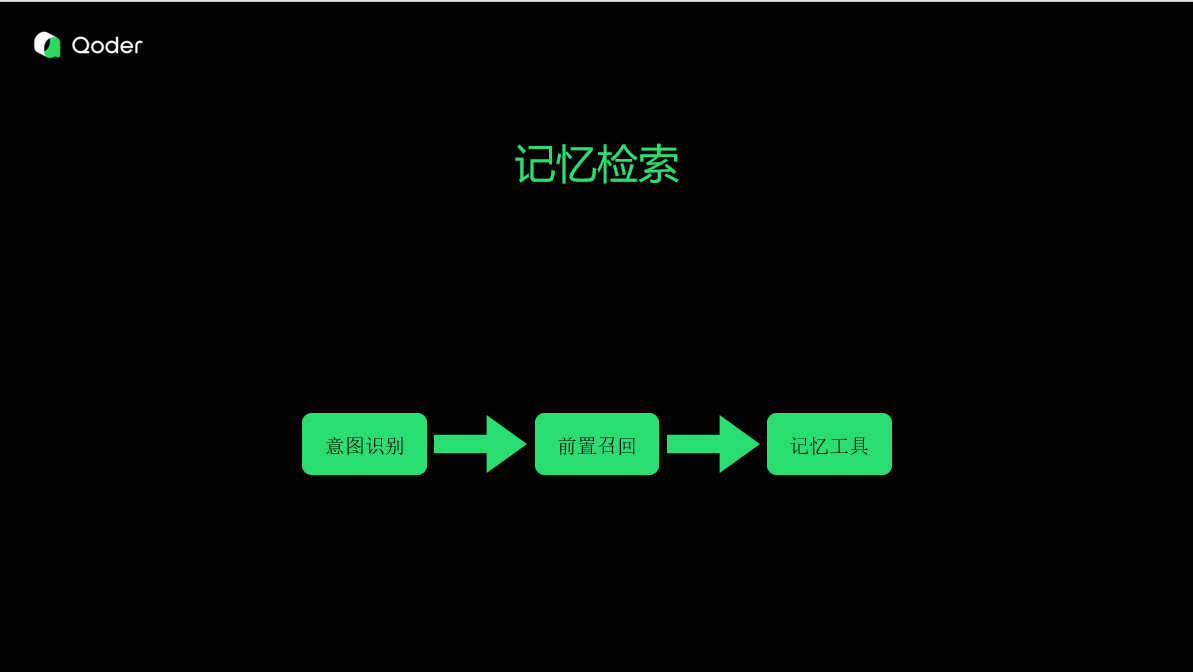
每次检索,我们会混合多种检索能力,比如语义、文本、图谱等,同时根据场景进行不同范围和深度的回忆。为智能体提供充足且准确的记忆内容,在帮助智能体完成任务的同时,一定程度上也会降低智能体的 Token消耗,因为复用经验降低了尝试成本。
记忆反思
我们建立了完整的记忆监控体系,从生产、检索、再到整理的全链路监控,每次对话后,我们会对记忆效果进行评估,判断记忆是有效、无效、还是有负面效果。

对于负面记忆,我们要通过监控体定位问题点,完成记忆的修复。
我们同时根据记忆的激活和评估结果,持续地维护工作记忆和训练记忆网络,让记忆变得越来越聪明。
记忆整理
最后是记忆整理。除了支持用户进行记忆管理和智能体教育外,我们更注重自动化整理------在记忆处于活跃状态时,系统会定时自动完成记忆的梳理与优化。

探测异常记忆,然后完成冲突处理、记忆融合。对于临时记录和长时间不用的记忆,也会进行遗忘和清理,保障只有有价值的记忆被存储下来。
写在最后
记忆系统仍在快速迭代中,欢迎大家积极体验、反馈问题,让我们一起打造"越来越懂你"的 Qoder!