Part IV SQL Operators: Access Paths and Joins
A row source is a set of rows returned by a step in the execution plan. A SQL operator acts on a row source.
A unary operator acts on one input, as with access paths. A binary operator acts on two outputs, as with joins.
第四部分 SQL 操作符:访问路径与连接操作
行源 是执行计划中某个步骤返回的数据行集合。SQL 操作符作用于行源之上。
一元操作符处理单个输入,如访问路径操作;二元操作符处理两个输出,如连接操作。
9 Joins
Oracle Database provides several optimizations for joining row sets.
Oracle数据库为连接行集操作提供了多种优化技术。
9.1 About Joins
A join combines the output from exactly two row sources, such as tables or views, and returns one row source. The returned row source is the data set.
A join is characterized by multiple tables in the WHERE (non-ANSI) or FROM ... JOIN (ANSI) clause of a SQL statement. Whenever multiple tables exist in the FROM clause, Oracle Database performs a join.
A join condition compares two row sources using an expression. The join condition defines the relationship between the tables. If the statement does not specify a join condition, then the database performs a Cartesian join, matching every row in one table with every row in the other table.
9.1 关于连接操作
连接操作将两个行源(如表或视图)的输出组合成一个行源,该行源即构成最终的数据集。
当SQL语句的WHERE子句(非ANSI标准)或FROM ... JOIN子句(ANSI标准)中出现多表引用时,即构成连接操作。只要FROM子句中存在多个表,Oracle数据库就会执行连接。
连接条件通过表达式比较两个行源,用于定义表之间的关系。若语句未指定连接条件,数据库将执行笛卡尔连接,将一个表的每一行与另一个表的每一行进行
See Also:
• "Cartesian Joins"
• Oracle Database SQL Language Reference for a concise discussion of joins in Oracle SQL
另请参阅:
• 《笛卡尔连接》
• Oracle Database SQL Language Reference 获取Oracle SQL中连接操作的简明论述
9.1.1 Join Trees
Typically, a join tree is represented as an upside-down tree structure.
As shown in the following graphic, table1 is the left table, and table2 is the right table. The optimizer processes the join from left to right. For example, if this graphic depicted a nested loops join, then table1 is the outer loop, and table2 is the inner loop.
9.1.1 连接树
连接树通常表现为倒置的树形结构
如下图所示,table1为左表,table2为右表。优化器从左到右处理连接操作。例如,若此图表示嵌套循环连接,则table1为外循环,table2为内循环。

The input of a join can be the result set from a previous join. If the right child of every internal node of a join tree is a table, then the tree is a left deep join tree, as shown in the following example. Most join trees are left deep joins.
连接操作的输入可以是前次连接的结果集。若连接树中每个内部节点的右子节点均为基表,则该树称为左深连接树,如下图所示。大多数连接树都属于左深连接类型。
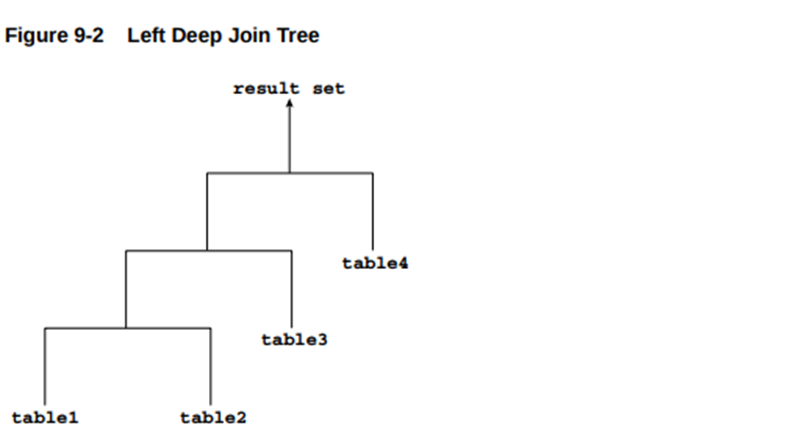
翻译说明:
1、内部节点(Internal node):树中既有父节点又有子节点的位置(如上图中的JOIN1、JOIN2、JOIN3)
2、右子节点(Right child):每个内部节点右侧直接连接的对象
3、基表(Table):原始数据表(非连接结果)
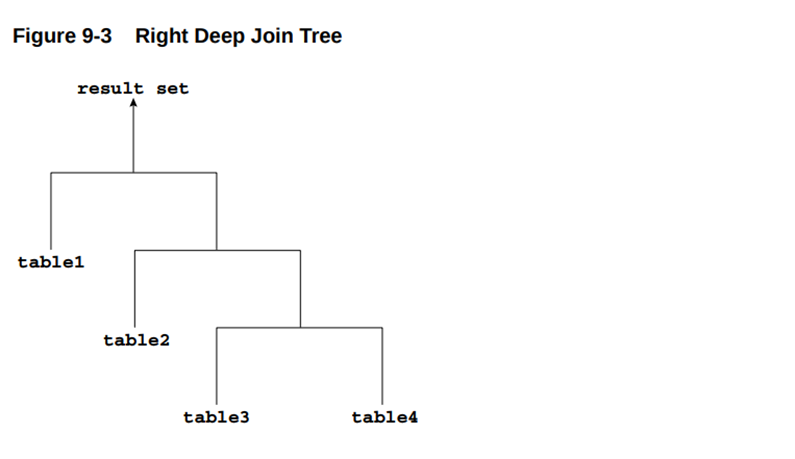
If the left child of every internal node of a join tree is a table, then the tree is called a right deep join tree, as shown in the following diagram.
如果连接树中每个内部节点的左子节点都是基表,则该树称为右深连接树,如下图所示。
If the left or the right child of an internal node of a join tree can be a join node, then the tree is called a bushy join tree. In the following example, table4 is a right child of a join node, table1 is the left child of a join node, and table2 is the left child of a join node.
如果连接树中某个内部节点的左子节点或右子节点可以是连接节点,则该树称为浓密连接树。在以下示例中,table4是连接节点的右子节点,table1是连接节点的左子节点,而table2也是连接节点的左子节点。
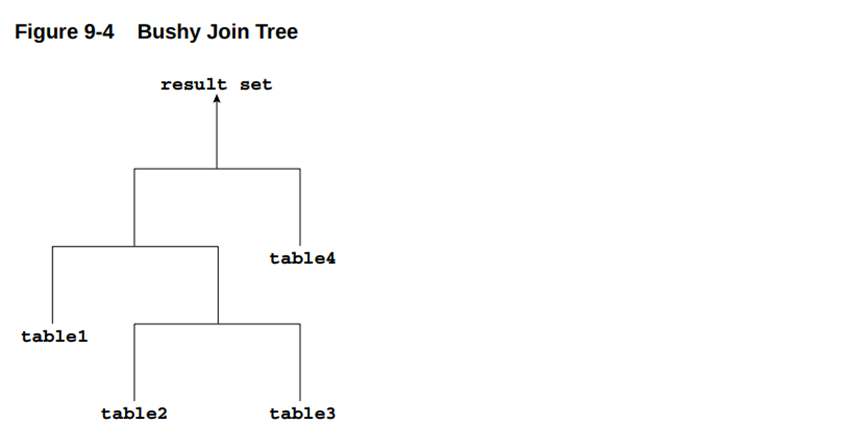
In yet another variation, both inputs of a join are the results of a previous join.
在另一种变体中,连接操作的左右两个输入均来自前序连接的结果集。
9.1.2 How the Optimizer Executes Join Statements
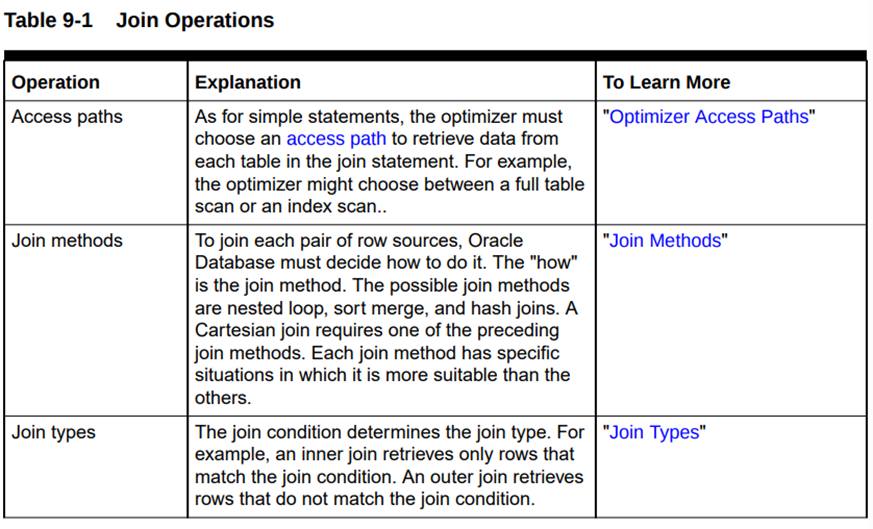
The database joins pairs of row sources. When multiple tables exist in the FROM clause, the optimizer must determine which join operation is most efficient for each pair.
The optimizer must make the interrelated decisions shown in the following table.
9.1.2 优化器如何执行连接语句
数据库对行源进行两两连接。当FROM子句中存在多个表时,优化器必须为每对表确定最高效的连接操作方式。
优化器需要做出下表中展示的相互关联的决策:



9.1.3 How the Optimizer Chooses Execution Plans for Joins
When determining the join order and method, the optimizer goal is to reduce the number of rows early so it performs less work throughout the execution of the SQL statement.
9.1.3 优化器如何选择连接执行计划
在确定连接顺序和方法时,优化器的核心目标是在执行早期尽可能减少数据行数量,从而降低整个SQL语句执行过程中的总体工作量。
The optimizer generates a set of execution plans, according to possible join orders, join methods, and available access paths. The optimizer then estimates the cost of each plan and chooses the one with the lowest cost. When choosing an execution plan, the optimizer considers the following factors:
优化器根据可能的连接顺序、连接方法以及可用访问路径生成一组候选执行计划。随后评估每个计划的成本,并选择成本最低的方案。在选择执行计划时,优化器会综合考虑以下因素:
• The optimizer first determines whether joining two or more tables results in a row source containing at most one row.
The optimizer recognizes such situations based on UNIQUE and PRIMARY KEY constraints on the tables. If such a situation exists, then the optimizer places these tables first in the join order. The optimizer then optimizes the join of the remaining set of tables.
优化器首先判断连接两个或多个表是否会产生最多包含单行数据的行源。
优化器基于表上的UNIQUE和PRIMARY KEY约束识别此类情况。若存在这种特殊连接关系,优化器会将这些表置于连接顺序的最前端,随后对剩余表集的连接进行优化。
• For join statements with outer join conditions, the table with the outer join operator typically comes after the other table in the condition in the join order.
In general, the optimizer does not consider join orders that violate this guideline, although the optimizer overrides this ordering condition in certain circumstances. Similarly, when a subquery has been converted into an antijoin or semijoin, the tables from the subquery must come after those tables in the outer query block to which they were connected or correlated. However, hash antijoins and semijoins are able to override this ordering condition in certain circumstances.
对于包含外连接条件的语句,带有外连接运算符的表通常应位于连接顺序中条件内另一表之后。
尽管优化器在特定情况下会突破此顺序约束,但通常不会考虑违反此准则的连接顺序。类似地,当子查询被转换为反连接或半连接时,子查询中的表必须位于外查询块中与之关联或相关的表之后。然而,哈希反连接和半连接在特定条件下也能够突破此顺序约束。
补充说明:
1、半连接 (Semijoin)
- 作用:检查主查询的行是否存在于子查询结果中
- 示例:
SELECT * FROM employees e
WHERE EXISTS (SELECT 1 FROM departments d
WHERE e.department_id = d.department_id)
2、反连接 (Antijoin)
- 作用:检查主查询的行是否不存在于子查询结果中
- 示例:
SELECT * FROM employees e
WHERE NOT EXISTS (SELECT 1 FROM departments d
WHERE e.department_id = d.department_id)
The optimizer estimates the cost of a query plan by computing the estimated I/Os and CPU. These I/Os have specific costs associated with them: one cost for a single block I/O, and another cost for multiblock I/Os. Also, different functions and expressions have CPU costs associated with them. The optimizer determines the total cost of a query plan using these metrics. These metrics may be influenced by many initialization parameter and session settings at compile time, such as the DB_FILE_MULTI_BLOCK_READ_COUNT setting, system statistics, and so on.
优化器通过计算预估的I/O和CPU资源消耗来评估查询计划的成本。这些I/O操作对应特定的代价系数:单块I/O具有一种成本权重,而多块I/O则对应另一种成本权重。此外,不同函数和表达式的执行也关联着相应的CPU开销。优化器基于这些度量指标确定查询计划的总体成本,这些指标在编译时可能受到多种初始化参数和会话设置的影响,例如DB_FILE_MULTI_BLOCK_READ_COUNT参数配置、系统统计信息等。
For example, the optimizer estimates costs in the following ways:
• The cost of a nested loops join depends on the cost of reading each selected row of the outer table and each of its matching rows of the inner table into memory. The optimizer estimates these costs using statistics in the data dictionary.
例如,优化器通过以下方式估算成本:
• 嵌套循环连接的成本取决于读取外层表每个选定行及其在内层表中所有匹配行到内存中的开销。优化器使用数据字典中的统计信息来估算这些成本。
• The cost of a sort merge join depends largely on the cost of reading all the sources into memory and sorting them.
• 排序合并连接的成本主要取决于将所有数据源读入内存并进行排序的成本。
• The cost of a hash join largely depends on the cost of building a hash table on one of the input sides to the join and using the rows from the other side of the join to probe it.
• 哈希连接的成本主要取决于在连接操作的一个输入端构建哈希表,并使用另一端的行数据探测该哈希表所产生的成本。
Example 9-1 Estimating Costs for Join Order and Method
Conceptually, the optimizer constructs a matrix of join orders and methods and the cost associated with each. For example, the optimizer must determine how best to join the date_dim and lineorder tables in a query. The following table shows the possible variations of methods and orders, and the cost for each. In this example, a nested loops join in the order date_dim, lineorder has the lowest cost.
示例9-1 连接顺序与方法的成本估算
从概念上讲,优化器会构建一个连接顺序与方法的矩阵,并计算每种组合的对应成本。例如,优化器必须确定查询中连接date_dim和lineorder表的最佳方式。下表展示了方法与顺序的可能组合及其各自成本。在本示例中,按date_dim、lineorder顺序的嵌套循环连接具有最低成本。
Table 9-2 Sample Costs for Join of date_dim and lineorder Tables
表9-2 date_dim 与lineorder 表连接成本示例

See Also:
• "Introduction to Optimizer Statistics"
• "Influencing the Optimizer " for more information about optimizer hints
• Oracle Database Reference to learn about DB_FILE_MULTIBLOCK_READ_COUNT
另请参阅:
• 《优化器统计信息简介》
• 《影响优化器》获取关于优化器提示符的更多信息
• Oracle Database Reference 了解DB_FILE_MULTIBLOCK_READ_COUNT参数