DQN及其变体DDQN对比学习记录
分别给出代码
python
# 定义简单神经网络
class Net(nn.Module):
def __init__(self, input_dim, output_dim):
super(Net, self).__init__()
self.input_dim = input_dim # 网络的输入维度
self.output_dim = output_dim # 网络的输出维度
# 定义一个仅包含全连接层的网络,激活函数使用ReLU函数
self.fc = nn.Sequential(
nn.Linear(self.input_dim, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, self.output_dim)
)
# 定义前向传播,输出动作Q值
def forward(self, state):
action = self.fc(s
python
# 经验回放缓冲区
class ReplayBuffer:
# 构造函数,max_size是缓冲区的最大容量
def __init__(self, max_size):
self.max_size = max_size
self.buffer = collections.deque(maxlen = self.max_size) # 用collections的队列存储,先进先出
# 添加experience(五元组)到缓冲区
def add(self, state, action, reward, next_state, done):
experience = (state, action, reward, next_state, done)
self.buffer.append(experience)
# 从buffer中随机采样,数量为batch_size
def sample(self, batch_size):
batch = random.sample(self.buffer, batch_size)
state, action, reward, next_state, done = zip(*batch)
return state, action, reward, next_state, done
# 返回缓冲区数据数量
def __len__(self):
return len(self.buffer)DQN
python
# 定义DQN类
class DQN:
# 构造函数,参数包含环境,学习率,折扣因子,经验回放缓冲区大小,目标网络更新频率
def __init__(self, env, learning_rate=0.001, gamma=0.99, buffer_size=10000, T=10):
self.env = env
self.learning_rate = learning_rate
self.gamma = gamma
self.replay_buffer = ReplayBuffer(max_size=buffer_size)
self.T = T
# 判断可用的设备是 CPU 还是 GPU
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义Q网络和目标网络,模型结构是一样的
self.model = Net(env.observation_space.shape[0], env.action_space.n).to(self.device)
self.target_model = Net(env.observation_space.shape[0], env.action_space.n).to(self.device)
# 初始化时,令目标网络的参数就等于Q网络的参数
for param, target_param in zip(self.model.parameters(), self.target_model.parameters()):
target_param.data.copy_(param)
# 定义Adam优化器
self.optimizer = torch.optim.Adam(self.model.parameters(), lr=learning_rate)
# 记录模型更新的次数,用于决定何时更新目标模型
self.update_count = 0
# 根据epsilon-greedy策略选择动作
def choose_action(self, state, epsilon=0.1):
if np.random.rand() < epsilon: # 以epsilon的概率随机选择一个动作
return np.random.randint(self.env.action_space.n)
else: # 否则选择模型认为最优的动作
state = torch.FloatTensor(np.array([state])).to(self.device)
action = self.model(state).argmax().item()
return action
# 计算损失函数,参数batch为随机采样的一批数据
def compute_loss(self, batch):
# 取出数据,并将其转换为numpy数组
# 然后进一步转换为tensor,并将数据转移到指定计算资源设备上
states, actions, rewards, next_states, dones = batch
states = torch.FloatTensor(np.array(states)).to(self.device)
actions = torch.tensor(np.array(actions)).view(-1, 1).to(self.device)
rewards = torch.FloatTensor(np.array(rewards)).view(-1, 1).to(self.device)
next_states = torch.FloatTensor(np.array(next_states)).to(self.device)
dones = torch.FloatTensor(np.array(dones)).view(-1, 1).to(self.device)
# 计算当前Q值,即Q网络对当前状态动作样本对的Q值估计
curr_Q = self.model(states).gather(1, actions)
# 计算目标网络对下一状态的Q值估计
next_Q = self.target_model(next_states)
# 选择下一状态中最大的Q值
max_next_Q = torch.max(next_Q, 1)[0].view(-1, 1)
# 计算期望的Q值,若达到终止状态则直接是reward
expected_Q = rewards + (1 - dones) * self.gamma * max_next_Q
# 计算当前Q值和期望Q值之间的均方误差,返回结果
loss = torch.mean(F.mse_loss(curr_Q, expected_Q))
return loss
# 模型更新,参数为批次大小
def update(self, batch_size):
# 从经验回放缓冲区中随机采样
batch = self.replay_buffer.sample(batch_size)
# 计算这部分数据的损失
loss = self.compute_loss(batch)
# 梯度清零、反向传播、更新参数
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 每隔一段时间,更新目标网络的参数
if self.update_count % self.T == 0:
for param, target_param in zip(self.model.parameters(), self.target_model.parameters()):
target_param.data.copy_(param)
# 记录模型更新的次数
self.update_count += 1DDQN
python
# 定义DDQN代理类
class Agent:
# 构造函数,参数包含环境,学习率,折扣因子,经验回放缓冲区大小,目标网络更新频率
def __init__(self, env, learning_rate=0.001, gamma=0.99, buffer_size=10000, T=10):
self.env = env
self.learning_rate = learning_rate
self.gamma = gamma
self.replay_buffer = ReplayBuffer(max_size=buffer_size)
self.T = T
# 判断可用的设备是 CPU 还是 GPU
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义Q网络和目标网络,模型结构是一样的
self.model = Net(env.observation_space.shape[0], env.action_space.n).to(self.device)
self.target_model = Net(env.observation_space.shape[0], env.action_space.n).to(self.device)
# 初始化时,令目标网络的参数就等于Q网络的参数
for param, target_param in zip(self.model.parameters(), self.target_model.parameters()):
target_param.data.copy_(param)
# 定义Adam优化器
self.optimizer = torch.optim.Adam(self.model.parameters())
# 记录模型更新的次数,用于决定何时更新目标模型
self.update_count = 0
# 根据epsilon-greedy策略选择动作
def choose_action(self, state, epsilon=0.1):
if np.random.rand() < epsilon: # 以epsilon的概率随机选择一个动作
return np.random.randint(self.env.action_space.n)
else: # 否则选择模型认为最优的动作
state = torch.FloatTensor(np.array([state])).to(self.device)
action = self.model(state).argmax().item()
return action
# 计算损失函数,参数batch为随机采样的一批数据
def compute_loss(self, batch):
# 取出数据,并将其转换为numpy数组
# 然后进一步转换为tensor,并将数据转移到指定计算资源设备上
states, actions, rewards, next_states, dones = batch
states = torch.FloatTensor(np.array(states)).to(self.device)
actions = torch.tensor(np.array(actions)).view(-1, 1).to(self.device)
rewards = torch.FloatTensor(np.array(rewards)).view(-1, 1).to(self.device)
next_states = torch.FloatTensor(np.array(next_states)).to(self.device)
dones = torch.FloatTensor(np.array(dones)).view(-1, 1).to(self.device)
# 计算当前Q值,即Q网络对当前状态动作样本对的Q值估计
curr_Q = self.model(states).gather(1, actions)
# 计算目标网络对下一状态的Q值估计,DDQN区别于DQN的点
next_model_Q = self.model(next_states)
next_target_Q = self.target_model(next_states)
# 选择下一状态中最大的Q值
max_next_Q = next_target_Q.gather(1, torch.max(next_model_Q, 1)[1].unsqueeze(1))
# 计算期望的Q值,若达到终止状态则直接是reward
expected_Q = rewards + (1 - dones) * self.gamma * max_next_Q
# 计算当前Q值和期望Q值之间的均方误差,返回结果
loss = torch.mean(F.mse_loss(curr_Q, expected_Q))
return loss
# 模型更新,参数为批次大小
def update(self, batch_size):
# 从经验回放缓冲区中随机采样
batch = self.replay_buffer.sample(batch_size)
# 计算这部分数据的损失
loss = self.compute_loss(batch)
# 梯度清零、反向传播、更新参数
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 每隔一段时间,更新目标网络的参数
if self.update_count % self.T == 0:
for param, target_param in zip(self.model.parameters(), self.target_model.parameters()):
target_param.data.copy_(param)
# 记录模型更新的次数
self.update_count += 1对比区别
对于DQN及其变体,具体的区别在于更新方式。DDQN的状态转移图如下,利用Q网络接收S_(t+1),得到最大值的动作at再传递给target_Q网络。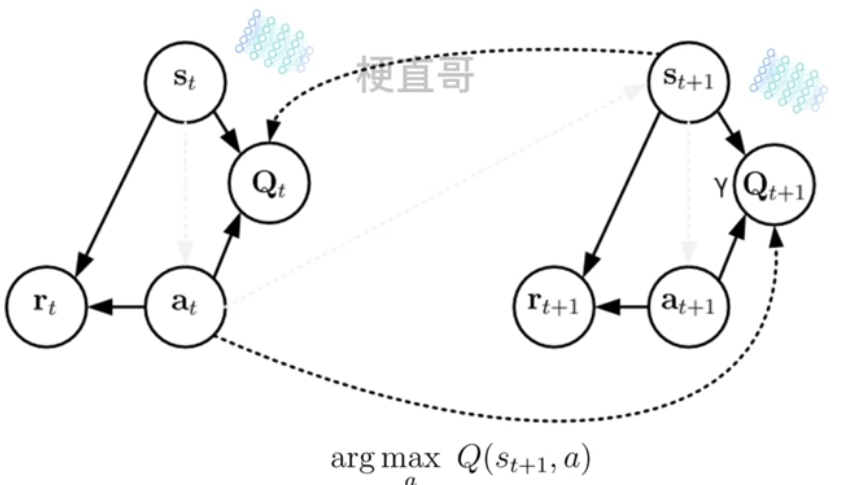
在强化学习中,Double DQN (DDQN) 和 DQN 都是基于 Q-learning 的深度强化学习算法。它们的目标是通过神经网络近似 Q 函数,进而学习最优策略。两者的主要区别在于 计算目标 Q 值 的方法上。我们来详细分析你提供的 DQN 和 DDQN 的代码,并说明它们的区别。
1. DQN 代码解读
DQN 的代码:
python
# 计算当前Q值,即Q网络对当前状态动作样本对的Q值估计
curr_Q = self.model(states).gather(1, actions)
# 计算目标网络对下一状态的Q值估计
next_Q = self.target_model(next_states)
# 选择下一状态中最大的Q值
max_next_Q = torch.max(next_Q, 1)[0].view(-1, 1)
# 计算期望的Q值,若达到终止状态则直接是reward
expected_Q = rewards + (1 - dones) * self.gamma * max_next_Q1.1 curr_Q = self.model(states).gather(1, actions)
self.model(states):使用当前的 Q 网络(self.model)计算每个状态下所有动作的 Q 值。gather(1, actions):gather操作从模型输出的 Q 值中 按actions的索引 提取出对应状态下实际执行动作的 Q 值。actions是从经验回放中采样得到的实际动作。
1.2 next_Q = self.target_model(next_states)
self.target_model(next_states):使用目标网络(self.target_model)计算下一状态的所有动作的 Q 值。- 目标网络的作用是稳定训练过程,因此它是固定一段时间更新的。
1.3 max_next_Q = torch.max(next_Q, 1)[0].view(-1, 1)
torch.max(next_Q, 1):从目标网络的输出next_Q中选出每个状态下的最大 Q 值。1代表在 动作维度 上求最大值。返回值包括最大值和对应的索引。[0]提取出最大 Q 值。.view(-1, 1):将max_next_Q转换为形状(batch_size, 1),确保后续计算可以顺利进行。
1.4 expected_Q = rewards + (1 - dones) * self.gamma * max_next_Q
- 计算期望的 Q 值。
rewards是即时奖励,max_next_Q是下一状态中最大的 Q 值。self.gamma是折扣因子。 (1 - dones):如果done为True(终止状态),则期望 Q 值为reward;否则,期望 Q 值包含下一个状态的最大 Q 值。
2. DDQN 代码解读
现在我们来看 DDQN 的代码:
python
# 计算当前Q值,即Q网络对当前状态动作样本对的Q值估计
curr_Q = self.model(states).gather(1, actions)
# 计算目标网络对下一状态的Q值估计,DDQN区别于DQN的点
next_model_Q = self.model(next_states)
next_target_Q = self.target_model(next_states)
# 选择下一状态中最大的Q值
max_next_Q = next_target_Q.gather(1, torch.max(next_model_Q, 1)[1].unsqueeze(1))
# 计算期望的Q值,若达到终止状态则直接是reward
expected_Q = rewards + (1 - dones) * self.gamma * max_next_Q2.1 curr_Q = self.model(states).gather(1, actions)
- 这部分与 DQN 中的相同,计算当前 Q 值。
2.2 next_model_Q = self.model(next_states)
- 在 DDQN 中,
next_model_Q是通过 当前的 Q 网络 来计算下一状态下所有动作的 Q 值。 - 这与 DQN 的
next_Q = self.target_model(next_states)不同,DQN 直接使用目标网络来计算下一状态的 Q 值,而 DDQN 在计算最大 Q 值时,使用了 当前 Q 网络 (即self.model)来选择下一状态下的最大动作 Q 值。
2.3 next_target_Q = self.target_model(next_states)
- 这部分与 DQN 相同,计算目标网络对下一状态的 Q 值估计。
2.4 max_next_Q = next_target_Q.gather(1, torch.max(next_model_Q, 1)[1].unsqueeze(1))
-
区别 :在 DDQN 中,选择最大 Q 值的过程分为两步:
- 首先 ,使用当前的 Q 网络(
next_model_Q)来选择下一状态下的最优动作,得到该动作的索引(torch.max(next_model_Q, 1)[1])。 - 然后 ,使用目标网络(
next_target_Q)来计算该最优动作对应的 Q 值。通过gather(1, ...)操作,选择目标网络中对应最优动作的 Q 值。
这一点是 DDQN 与 DQN 的最大区别 :DQN 直接使用目标网络来计算最大 Q 值 ,而 DDQN 通过当前网络选择最优动作,目标网络计算该动作的 Q 值 。这种做法减少了 过度估计 的问题,使得 DQN 更加稳定。
- 首先 ,使用当前的 Q 网络(
2.5 expected_Q = rewards + (1 - dones) * self.gamma * max_next_Q
- 这部分与 DQN 相同,计算期望的 Q 值。
3. DQN 与 DDQN 的主要区别
-
DQN :在计算目标 Q 值时,直接使用 目标网络 (
target_model)来计算下一状态的最大 Q 值。pythonmax_next_Q = torch.max(next_Q, 1)[0].view(-1, 1) -
DDQN :将 选择最优动作 和 估计最优动作的 Q 值 分开:
- 使用 当前 Q 网络 (
model)来选择下一状态下的最优动作。 - 使用 目标网络 (
target_model)来计算选择的最优动作的 Q 值。
pythonmax_next_Q = next_target_Q.gather(1, torch.max(next_model_Q, 1)[1].unsqueeze(1)) - 使用 当前 Q 网络 (
4. 为什么 DDQN 更好?
DQN 存在 过度估计 Q 值 的问题。当目标网络直接选择最大 Q 值时,可能导致目标 Q 值被高估,因为目标网络本身是通过最大 Q 值计算的。如果当前 Q 网络选择了一个错误的动作,可能会导致更新不准确。而 DDQN 通过分离动作选择和 Q 值估计,减小了这种过度估计的影响。
总结
- DQN 使用目标网络来选择下一状态下的最大 Q 值,这可能导致 过度估计 问题。
- DDQN 通过 当前 Q 网络 选择最优动作,使用 目标网络 来计算该最优动作的 Q 值,从而减小了 过度估计 的问题,使得训练更加稳定。
通过这种方式,DDQN 解决了 DQN 中的估计偏差问题,提高了 Q 值的准确性和训练的稳定性。