VibeVoice-Realtime 是一个轻量级实时 文本转语音模型,支持流式文本输入 和强大的长篇语音生成 。它可以用于构建实时TTS服务、叙述实时数据流,并让不同的大型语言模型从它们的第一个令牌开始说话(插入您首选的模型),远早于生成完整答案之前。它在大约300毫秒内产生初始可听语音(硬件依赖)。
github:https://github.com/microsoft/VibeVoice
gicode:https://gitcode.com/GitHub_Trending/vib/VibeVoice
魔搭模型下载:魔搭社区
省流总结:目前暂时不支持中文。可以cpu推理,但无法实时,生成的语音文件可以用。
安装VibeVoice
先下载源代码
git clone https://gitcode.com/GitHub_Trending/vib/VibeVoice安装python库
pip install -e .虚拟环境安装(可选)
如果为了不干扰其它程序,可以创建一个python虚拟环境,并在虚拟环境安装
python -m venv .venv
# windows下激活python环境
.venv\scripts\activate
pip install -e .安装完成
推理
启动模型推理web服务器
python demo/vibevoice_realtime_demo.py --model_path microsoft/VibeVoice-Realtime-0.5B启动服务会自动下载模型,下载速度还是挺快的
G:\github\VibeVoice\.venv\Lib\site-packages\huggingface_hub\file_download.py:798: UserWarning: Not enough free disk space to download the file. The expected file size is: 2035.33 MB. The target location C:\Users\Admin\.cache\huggingface\hub\models--microsoft--VibeVoice-Realtime-0.5B\blobs only has 1859.82 MB free disk space.
warnings.warn(
model.safetensors: 16%|█████████▍ | 325M/2.04G [00:57<04:17, 6.63MB/s]如果是cpu环境,要加上cpu参数,还可以修改侦听的端口数:
python demo/vibevoice_realtime_demo.py --model_path microsoft/VibeVoice-Realtime-0.5B --device cpu --port 4000然后用浏览器打开即可:
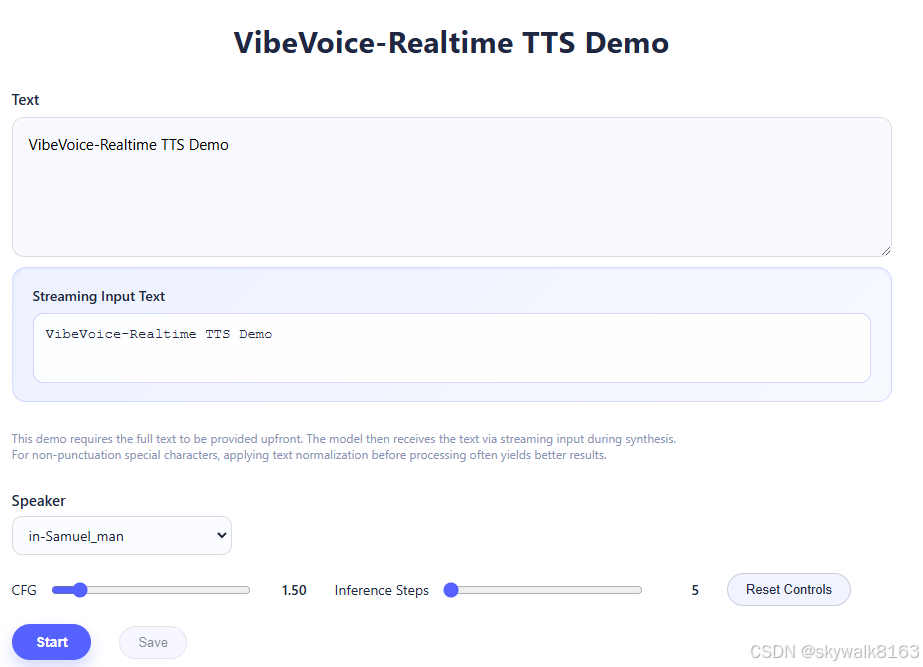
直接推理一个文本文件
# We provide some example scripts under demo/text_examples/ for demo
python demo/realtime_model_inference_from_file.py --model_path microsoft/VibeVoice-Realtime-0.5B --txt_path demo/text_examples/1p_vibevoice.txt --speaker_name Carter下载声音源
bash demo/download_experimental_voices.sh可惜这是linux下的sh文件,windows下无法用。
可惜没有中文语音源
总结
挺好的,它最大的特点,就是可以支持超长语音,比如VibeVoice-Realtime-0.5B可以实时生成,生成长度可以达到10分钟,VibeVoice-1.5B可以生成90分钟。
| 模型 | 上下文长度 | 生成长度 | 权重 |
|---|---|---|---|
| VibeVoice-Realtime-0.5B | 8k | ~10分钟 | 您在这里。 |
| VibeVoice-1.5B | 64K | ~90分钟 | HF链接 |
| VibeVoice-Large | 32K | ~45分钟 | HF链接 |
缺点就是截止到目前,还不支持中文,尽管它repo里面已经有了中文音频的视频展示。而且它那个展示里面的中文音频听着也比较生硬,能明显听出来是外国人说中文。
直接用cpu推理无法实时,有杂音,无法听清楚,但是生成的语音是可以使用的。
调试
启动后发现声音是异常的
原来默认用了德语发音器
但是改用了英文的,还是异常。原来是cpu推理的缘故。后来是下载到本地用播放器播放,声音正常。