
Diffusion Large Language Model (DLLM)是大模型圈近期最火的topic之一,对于VLA来说,我们的motivation是充分利用dllm在生成理解一体化方面天然的优势,将未来帧生成和动作预测统一在一个框架内。
对于生成理解一体化的Unified VLA模型,我们关注的核心问题是如何实现图像生成和动作预测的相互裨益,针对这个问题我们提出了联合离散去噪过程Joint Discrete Denoising Diffusion Process (JD3P),即我们将不同模态的去噪过程统一在同一个去噪轨迹中,通过hybrid attention让动作在去噪过程内持续受益于图像的去噪过程。为了在推理阶段充分发挥dllm的优势,我们设计了前缀KV Cache和基于置信度的decoding机制,在提升推理速度的同时保证动作质量。最后,作为第一个全面开源的Diffusion VLA在达到SOTA-level性能的同时相比自回归模型实现了四倍的加速,我们在主流benchmark (CALVIN, LIBERO, SIMPLER) 上进行了全面的评测提供了完整的训练、测试代码以及模型权重。
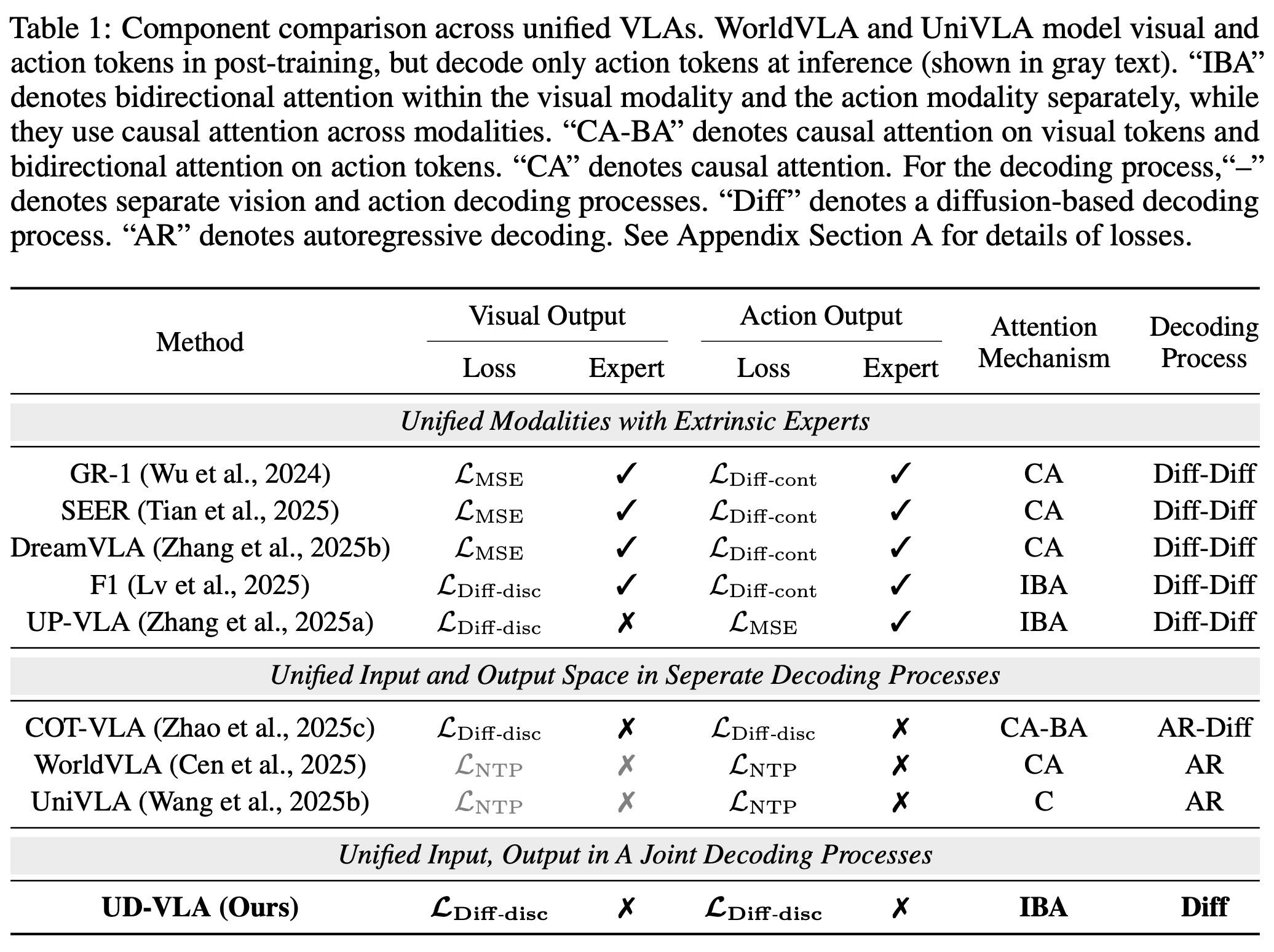
UD-VLA架构
1) Unified Tokenization
我们把 text / image / action 用emu3 tokenzier/VQ tokenizer/FAST tokenizer离散化为 tokens,并拼成一条单一多模态序列。并用特殊token/``and``/标记不同模态
序列结构:
text tokens ; current image tokens ; future image tokens ; action tokens
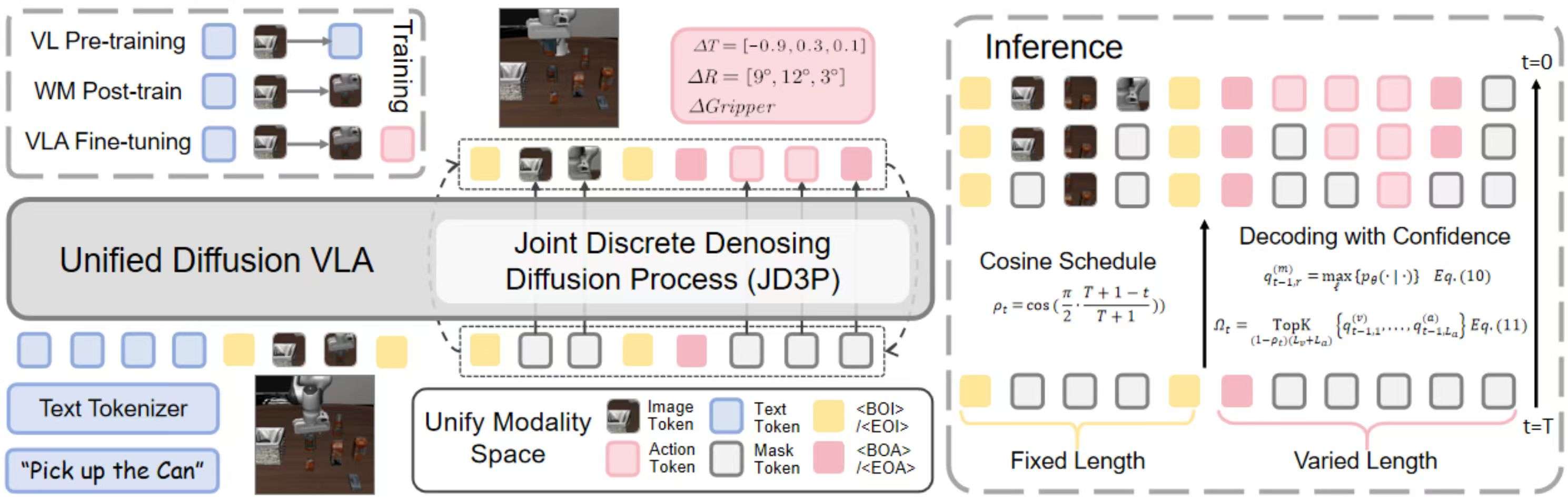
2) Hybrid Attention Mechanism
我们保持不同模态之间和文本模态内因果,视觉模态以及动作模态内保持双向。这样做的目的是让动作在去噪过程内持续受益于图像的去噪过程
3)Joint Discrete Denoising Diffusion Process (JD3P)
动作与图像在同一个去噪步骤中并行生成 。设未来图像 token 为 v 0 \mathbf{v}_0 v0,动作 token 为 a 0 \mathbf{a}_0 a0,其联合序列为:
$$
\mathbf{v}_0,\ \mathbf{a}_0
\bigl(v_{0,1},\dots,v_{0,L_v},\ a_{0,1},\dots,a_{0,L_a}\bigr).
我们加入一个掩码 token M \\mathrm{M} M。在步骤 t t t 的加噪转移为: ##
\mathbf{Q}t,\mathbf{e}{t,r}
(1-\beta_t),\mathbf{e}{t,r}
+
\beta_t,\mathbf{e} {\mathrm{M}}.
$$
去噪过程可分解为:
p θ ( v t − 1 , a t − 1 ∣ v t , a t , c ) = p θ ( v t − 1 ∣ v t , c ) p θ ( a t − 1 ∣ v t , a t , c ) . p_\theta(\mathbf{v}{t-1},\mathbf{a}{t-1}\mid \mathbf{v}t,\mathbf{a}t,\mathbf{c}) \;=\; p\theta(\mathbf{v}{t-1}\mid \mathbf{v}t,\mathbf{c})\; p\theta(\mathbf{a}_{t-1}\mid \mathbf{v}_t,\mathbf{a}_t,\mathbf{c}). pθ(vt−1,at−1∣vt,at,c)=pθ(vt−1∣vt,c)pθ(at−1∣vt,at,c).
我们采用 单步掩码预测 目标,仅对 被掩码的位置 计算交叉熵:
L CE ( θ ) = − β ∑ j L v log p θ ( v ) ( v 0 , j ∣ v t , c ) 1 { v t , j = M } − ∑ i L a log p θ ( a ) ( a 0 , i ∣ v t , a t , c ) 1 { a t , i = M } . \mathcal{L}{\text{CE}}(\theta) = - \beta \sum{j}^{L_v} \log p_\theta^{(v)}\!\big(v_{0,j}\mid \mathbf{v}t,\mathbf{c}\big)\, \mathbf{1}\{v{t,j}=\mathrm{M}\} \;-\; \sum_{i}^{L_a} \log p_\theta^{(a)}\!\big(a_{0,i}\mid \mathbf{v}_t,\mathbf{a}t,\mathbf{c}\big)\, \mathbf{1}\{a{t,i}=\mathrm{M}\}. LCE(θ)=−βj∑Lvlogpθ(v)(v0,j∣vt,c)1{vt,j=M}−i∑Lalogpθ(a)(a0,i∣vt,at,c)1{at,i=M}.
4) 训练 (Training)
-
阶段 (i). 在大规模视频数据集上进行后训练,注入未来图像生成能力。
text tokens ; current image tokens ; future image tokens . \\;\\text{text tokens}\\;;\\;\\text{current image tokens}\\;;\\;\\text{future image tokens}\\;. text tokens;current image tokens;future image tokens. -
阶段 (ii). 共同优化图像和动作生成;将自回归解码重构为扩散过程(JD3P),通过移位操作预测下一个 token。
text tokens ; current tokens ; future image tokens action tokens . \\;\\text{text tokens}\\;;\\;\\text{current tokens}\\;;\\;\\text{future image tokens}\\;\\text{action tokens}. text tokens;current tokens;future image tokensaction tokens.
推理 (Inference)
并行解码与自适应掩码
初始化 v T \mathbf{v}_T vT 和 a T \mathbf{a}_T aT 的所有位置为 <MASK>,并进行少量迭代。
前缀 KV 缓存与预填充
复用前缀token的kv缓存和预填充 <BOI>、<EOI>、<BOA> 以引导去噪。
基于置信度的解码
使用通过置信度对掩码位置进行排序:
q t − 1 , r = max ℓ { p θ ( ℓ ∣ v t , u ) , r ∈ { 1 , ... , L v } , p θ ( ℓ ∣ v t , a t , u ) , r ∈ { L v + 1 , ... , L v + L a } . q_{t-1,r}=\max_{\ell}\begin{cases} p_\theta(\ell \mid \mathbf v_t,\mathbf u), & r\in\{1,\ldots,L_v\},\\6pt p_\theta(\ell \mid \mathbf v_t,\mathbf a_t,\mathbf u), & r\in\{L_v+1,\ldots,L_v+L_a\}. \end{cases} qt−1,r=ℓmax⎩ ⎨ ⎧pθ(ℓ∣vt,u),pθ(ℓ∣vt,at,u),r∈{1,...,Lv},r∈{Lv+1,...,Lv+La}.
通过温度化的 Gumbel 采样更新前 ( 1 − ρ t ) ∣ M t ∣ (1-\rho_t)|M_t| (1−ρt)∣Mt∣ 个条目:
v t − 1 , j , a t − 1 , i = arg max y 1 κ t log p θ ( y ∣ v t , a t , u ) + η c , η c ∼ G u m b e l ( 0 , 1 ) . v_{t-1,j},a_{t-1,i}=\arg\max_{y}\Big\\tfrac{1}{\\kappa_t}\\log p_\\theta(y \\mid \\mathbf v_t,\\mathbf a_t,\\mathbf u)+\\eta_c\\Big,\; \eta_c\sim \mathrm{Gumbel}(0,1). vt−1,j,at−1,i=argymaxκt1logpθ(y∣vt,at,u)+ηc,ηc∼Gumbel(0,1).
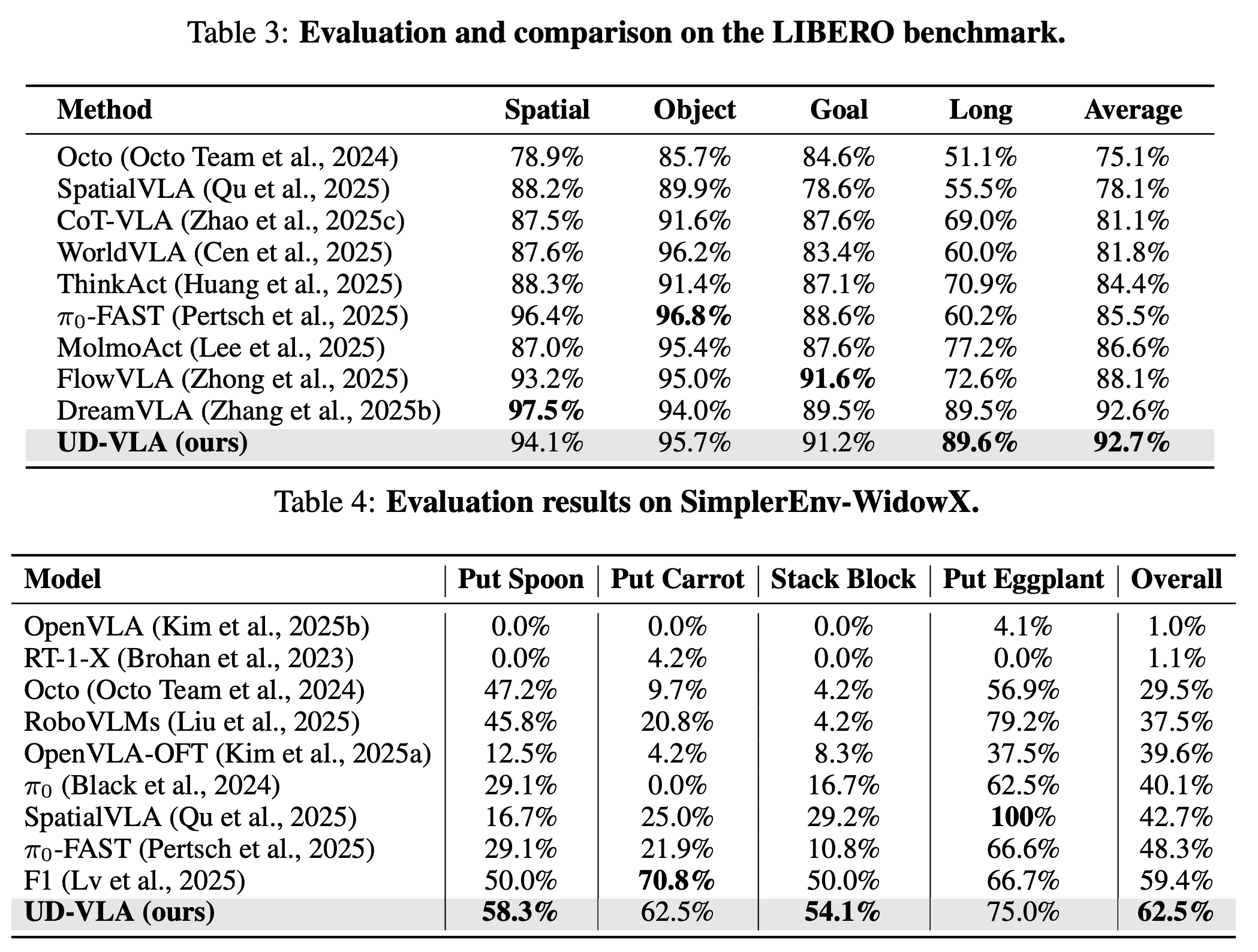
实验
仿真实验
视觉cot生成
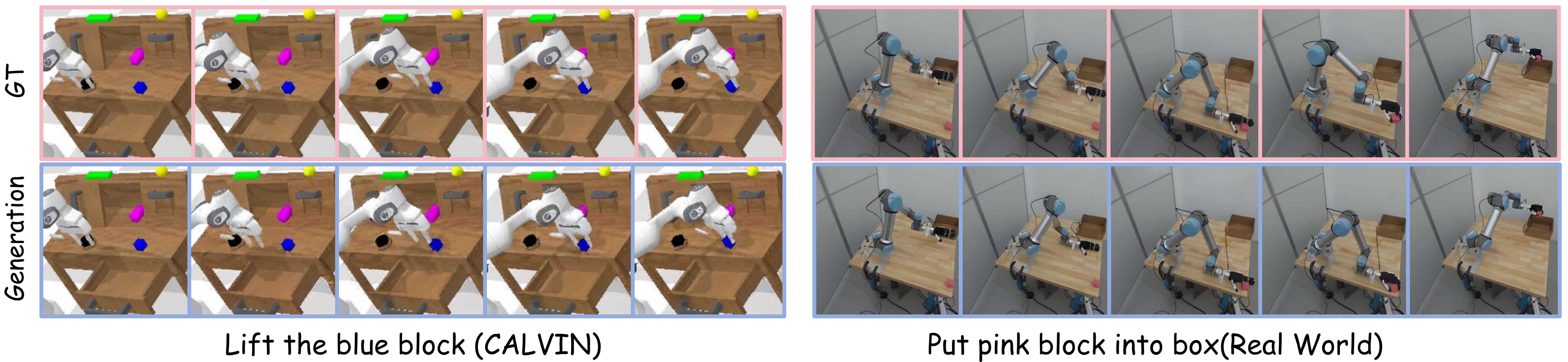

真机实验
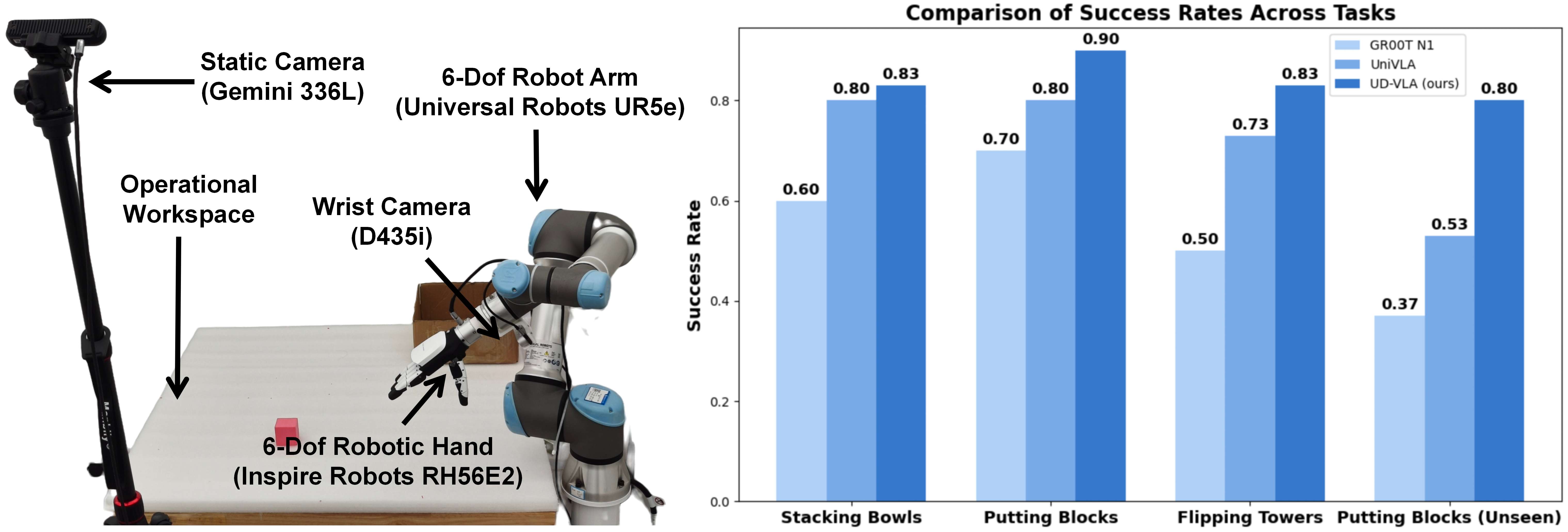
最后
我们在Diffusion VLA方向上长期的尝试,在今年三月就探索了Parallel VLA的一种形式PD-VLA(uniform的迭代形式),它通过并行且多次迭代输出action,可以视作diffusion VLA的最早期探索,基于PD-VLA,我们进一步探索了Diffusion VLA的推理加速,通过一致性蒸馏的方式将基于OpenVLA的模型速度提升了四倍。得益于dllm的发展,Unified Diffusion VLA探索了多模态的生成理解统一的关键问题,我们希望他不仅可以作为好的开源VLA基座,也可以作为团队在diffusion VLA一系列研究上的最新结果提供给大家真正的insights。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?