DM0 是一个流匹配系列改进的 VLA 架构,适用于真实的物理机器人中
兼顾模型的通用多模态能力和具身动作控制能力,形成 VLM骨干 + 流匹配 动作专家 的端到端架构
- 核心是提出具身空间推理增强 ,通过四层分层的辅助 预测目标 构建空间思维链(CoT),为模型提供结构化的监督信号,引导模型从
高层语义推理逐步过渡到空间落地和低层动作执行:-
子任务预测:将复杂的整体任务,分解为一系列可解释、可执行的细粒度子任务步骤,核心是"高层任务的逻辑分解";
-
目标边界框预测:在视觉观测中,精准定位目标物体或与任务相关的区域,核心是"抽象语义到视觉空间";
-
端执行器轨迹预测:在机器人主相机视角下,预测末端执行器的未来运动轨迹,核心是"视觉空间到机器人运动空间的转化";
-
离散动作预测:预测机器人的离散控制指令令牌,核心是"机器人运动空间到具体动作指令的转换,同时给后续的连续动作生成提供指导"。
-
上面的四种高层具身推理信息,可以理解为"在给最终输出的连续动作序列,进行辅助指导;就像辅助训练的思路,共享VLM层"
-
论文地址:https://dexmal.com/DM0_Tech_Report.pdf
开源地址:https://github.com/Dexmal/dexbotic
DM0 处理不仅能完成VLA相关的具身操作任务,还能进行VLN相关的具身导航任务~
1、模型框架
DM0的模型架构,如下图所示,展示了从多模态输入到机器人连续动作输出的完整推理流程:
核心是通过具身空间推理增强,形成空间思维链推理,实现从高层语义推理到低层物理控制的渐进式指导

把整个思路流程拆解为以下5个关键阶段:
1. 输入预处理与多模态融合
- 图像输入 :左侧的多视图桌面场景图像,先经过 感知编码器(PE,400M参数) 处理,生成结构化的
Visual Token(视觉特征嵌入)。 - 状态与指令输入 :同时获取机器人的
Robot State(本体感受状态,如关节角度、位置)和人类语言Instruction(如"Pick the second flower from the left")。 - 输入整合 :将
Visual Token、Robot State、Instruction三者拼接,作为 大语言模型(LLM,1.7B参数) 的统一输入。
2. LLM驱动的空间思维链推理(分层预测)
LLM作为核心推理引擎,通过四层递进的辅助预测目标,构建从抽象语义到具象空间的"空间思维链",逐步约束动作解空间:
-
子任务分解(Subtask)
- 输出:将复杂指令拆解为可执行的细粒度子任务文本(如"Pick the second flower from the left")。
- 作用:完成高层语义理解与任务逻辑分解,为后续空间定位提供语义指导。
-
目标边界框预测(Target BBox)
- 输出:在视觉图像中定位目标物体的空间坐标(图中红框标注的花朵)。
- 作用:将抽象语义目标落地到视觉空间,明确动作的空间目标位置。
-
末端执行器轨迹预测(EEF Trajectory)
- 输出:预测机器人末端执行器(End-Effector)的未来运动路径。
- 作用:将视觉空间目标转化为机器人运动空间的轨迹,建立空间位置与运动的关联。
-
离散动作预测(Discrete Action)
- 输出:离散化的动作令牌序列(如
207, 15, 153, 75, 198, 122, 4),对应具体的控制指令。 - 作用:将运动轨迹转化为可被模型理解的离散动作表示,为连续动作生成提供语义约束。
- 输出:离散化的动作令牌序列(如
这四层预测的输出会作为上下文反馈给LLM(图中浅橙色方块箭头),形成迭代式的结构化推理,逐步缩小动作假设空间。
3. 连续动作生成(ActionExpert)
- 特征复用 :LLM的键值缓存(KV Cache)作为 动作专家(ActionExpert,300M参数) 的输入,高效复用多模态推理特征。
- 流匹配生成 :ActionExpert基于流匹配(Flow Matching)算法,结合高斯噪声
ε ~ N(0, I),输出连续动作序列[a_t, a_{t+1}, ..., a_{t+H}]。 - 作用:将离散动作约束转化为机器人可直接执行的连续控制信号,实现从语义推理到物理动作的最终落地。
4. 动作输出与机器人执行
- 最终输出的连续动作序列
[a_t, ..., a_{t+H}]直接作为机器人的控制指令,驱动末端执行器完成目标操作(如抓取指定花朵)。
5. 模型框架总结
整个流程的本质是 "语义→空间→运动→控制" 的渐进式转化:
- 从抽象语言指令出发,通过LLM的分层推理,逐步将语义目标锚定到视觉空间、运动空间,再转化为离散动作约束;
- 最后由ActionExpert基于流匹配生成连续动作,实现从"理解任务"到"执行动作"的端到端闭环。
这种设计既保证了推理的可解释性(空间思维链),又提升了动作生成的精准性(约束解空间),是DM0在具身操纵任务中取得优异性能的关键技术路径。
2、模型架构设计细节
DM0 核心设计目标是构建能支撑多源异构数据联合训练、实现"语义推理-连续动作"端到端生成的VLA架构,
同时兼顾模型的通用多模态能力和具身动作控制能力,最终落地为"视觉-语言模型(VLM)骨干 + 流匹配(Flow Matching)动作专家"的双核心组件端到端架构。
核心设计细节
- 双组件分工与实现
- VLM骨干 :以Qwen3-1.7B大语言模型(LLM)为基础,新增 感知编码器(PE)实现多模态感知能力,核心负责多模态输入处理、语义理解、具身推理,并为动作专家提供富含语义和物理先验的特征表征;其中多视图视觉输入会先resize至728×728,再通过2个3×3卷积层(步幅2)完成4倍下采样,生成适配LLM的图像嵌入特征。
- 流匹配动作专家 :基于流匹配(Lipman et al., 2022)算法构建,核心负责连续动作生成 ,其输入并非VLM的最终输出,而是从VLM骨干中提取的键值(KV)缓存,既实现了特征复用,又提升了训练和推理的效率,最终输出机器人的连续控制动作序列。
- 双推理模式
模型推理时支持两种灵活模式,兼顾动作生成效率 和推理可解释性 ,是端到端架构的重要设计亮点:直接预测模式:从多模态观测和语言指令中,直接预测连续动作序列,适用于对推理效率要求高的场景;推理先行模式:先生成文本化的具身推理结果( l ^ \hat{l} l^),再基于该推理结果为动作专家提供约束,进而生成连续动作,适用于复杂长视野任务,让模型的动作生成有明确的语义逻辑支撑。
- 数学形式化表达
DM0 将联合模型的分布进行因式分解,清晰界定了双组件的协作关系:(这里的公式,会详细讲解)
π θ ( l ^ , a t : t + H ∣ o t , l ) = π θ ( l ^ ∣ o t , l ) ⋅ π θ ( a t : t + H ∣ o t , l , l ^ ) \pi_{\theta}\left(\hat{l}, a_{t: t+H} | o_{t}, l\right)=\pi_{\theta}\left(\hat{l} | o_{t}, l\right) \cdot \pi_{\theta}\left(a_{t: t+H} | o_{t}, l, \hat{l}\right) πθ(l^,at:t+H∣ot,l)=πθ(l^∣ot,l)⋅πθ(at:t+H∣ot,l,l^)
其中 o t = I t , s t o_t=I_t,s_t ot=It,st为t时刻的多模态观测(视觉输入 I t I_t It+机器人本体感受状态 s t s_t st), l l l为人类语言指令, l ^ \hat{l} l^为VLM预测的具身推理文本, a t : t + H a_{t:t+H} at:t+H为H时间步的连续动作序列。该公式直观体现了动作生成依赖于VLM的推理结果,实现了推理与控制的语义耦合。
2.1、模型框架的公式表示
模型架构 的核心公式是:
π θ ( l ^ , a t : t + H ∣ o t , l ) = π θ ( l ^ ∣ o t , l ) ⋅ π θ ( a t : t + H ∣ o t , l , l ^ ) \pi_{\theta}\left(\hat{l}, a_{t: t+H} \mid o_{t}, l\right)=\pi_{\theta}\left(\hat{l} \mid o_{t}, l\right) \cdot \pi_{\theta}\left(a_{t: t+H} \mid o_{t}, l, \hat{l}\right) πθ(l^,at:t+H∣ot,l)=πθ(l^∣ot,l)⋅πθ(at:t+H∣ot,l,l^)
逐个解释每个符号的物理意义:
| 符号 | 含义 |
|---|---|
| o t = I t , s t o_t = I_t, s_t ot=It,st | 智能体在时刻 t t t 的多模态观测 : • I t I_t It:多视图视觉图像输入(如桌面场景图) • s t s_t st:机器人本体感受状态(如关节角度、末端执行器位置) |
| l l l | 人类语言指令(如"Pick the second flower from the left") |
| l ^ \hat{l} l^ | VLM 骨干生成的具身推理文本(子任务分解、空间定位等的文本化推理结果) |
| a t : t + H a_{t:t+H} at:t+H | 从 t t t 到 t + H t+H t+H 时间步的连续动作序列(机器人可直接执行的控制指令) |
| π θ \pi_{\theta} πθ | 整个模型的参数化策略( θ \theta θ 为模型可学习参数) |
2.2、公式的核心意义:推理-动作的耦合逻辑
这个公式是对模型联合分布的因式分解,直观展示了 DM0 从"理解指令"到"生成动作"的两步式工作流:
-
第一步:推理生成( π θ ( l ^ ∣ o t , l ) \pi_{\theta}\left(\hat{l} \mid o_{t}, l\right) πθ(l^∣ot,l))
- 由 VLM 骨干(Qwen3-1.7B + 感知编码器 PE)执行。
- 输入:多模态观测 o t o_t ot + 语言指令 l l l。
- 输出:具身推理文本 l ^ \hat{l} l^(如子任务分解、目标边界框描述、末端执行器轨迹规划等)。
- 作用:将抽象的语言指令转化为结构化的空间推理结果,为后续动作生成提供明确的语义和空间约束。
-
第二步:动作生成( π θ ( a t : t + H ∣ o t , l , l ^ ) \pi_{\theta}\left(a_{t: t+H} \mid o_{t}, l, \hat{l}\right) πθ(at:t+H∣ot,l,l^))
- 由 流匹配动作专家(ActionExpert)执行。
- 输入:多模态观测 o t o_t ot + 语言指令 l l l + 推理结果 l ^ \hat{l} l^。
- 输出:连续动作序列 a t : t + H a_{t:t+H} at:t+H。
- 作用:在推理结果的约束下,生成精准的物理控制动作,实现从"理解任务"到"执行动作"的落地。
2.3、公式与模型架构的对应关系
这个公式是对图中流程的数学抽象,我们可以把它和模型架构的双组件设计一一对应:
-
VLM 骨干 :对应公式中的 π θ ( l ^ ∣ o t , l ) \pi_{\theta}\left(\hat{l} \mid o_{t}, l\right) πθ(l^∣ot,l),负责多模态感知和具身推理。
- 输入:视觉 Token(由 PE 处理图像生成)、机器人状态 s t s_t st、语言指令 l l l。
- 输出:推理文本 l ^ \hat{l} l^(子任务、目标 BBox、EEF 轨迹、离散动作等)。
-
流匹配动作专家 :对应公式中的 π θ ( a t : t + H ∣ o t , l , l ^ ) \pi_{\theta}\left(a_{t: t+H} \mid o_{t}, l, \hat{l}\right) πθ(at:t+H∣ot,l,l^),负责连续动作生成。
- 输入:从 VLM 提取的 KV 缓存(高效复用推理特征)+ 高斯噪声 ε ∼ N ( 0 , I ) \varepsilon \sim \mathcal{N}(0, I) ε∼N(0,I)。
- 输出:连续动作序列 a t : t + H a_{t:t+H} at:t+H,直接驱动机器人执行。
2.4、设计价值
- 端到端架构摒弃了传统VLA模型的模块化拆分设计,减少了模块间的信息损耗,让语义推理与动作控制的特征能深度融合;
- 双组件的明确分工,让VLM专注于其擅长的语义理解和推理,动作专家专注于连续控制,充分发挥各自的技术优势;
- KV缓存的复用机制和双推理模式,兼顾了模型的训练/推理效率与复杂任务的可解释性,适配不同的具身应用场景;
- 基于Qwen3-1.7B的轻量级设计(整体仅2B参数),让DM0在保证性能的同时,具备更好的工程部署性,区别于其他大参数量的VLA模型。
3、多源混合训练:梯度解耦的混合训练策略,解决"学动作丢语义"的核心痛点
传统VLA模型的关键训练难题:若直接对VLM和动作专家进行联合端到端训练,同时优化语言理解和连续动作控制目标,会严重侵蚀VLM预训练的语义表征,导致模型的通用多模态能力退化,出现"学了动作,丢了推理"的灾难性遗忘。
针对这一问题,DM0 提出基于知识绝缘(KI)思想的混合梯度策略 ,并配套设计了双损失加权的总训练目标,实现了VLM通用语义能力的保留 与动作专家连续控制能力的习得 的双向平衡,是DM0能兼顾"通用理解"和"具身动作"的训练保障。
3.1、核心设计细节
-
核心梯度解耦策略
借鉴知识绝缘思想,对具身数据和非具身数据采用差异化的梯度传递规则:
- 训练具身数据 时,动作专家的梯度不回传至VLM骨干,从根本上避免了连续动作的优化目标对VLM语义表征的侵蚀,保证其预训练的通用推理能力不退化;
- 训练非具身数据 时,VLM仍保持可训练状态,可持续从网络文本、图文配对等数据中优化语义理解和多模态推理能力,实现通用能力的持续迭代。
同时,为了让VLM的推理结果能更好地指导动作专家的生成,论文让VLM额外学习离散动作令牌的预测,引导VLM编码与动作相关的语义信息,实现VLM与动作专家的语义对齐。
-
双损失函数设计
针对VLM和动作专家的不同任务目标,设计了专属的损失函数,再通过加权融合形成总训练目标,让模型同时优化推理和控制能力:
- VLM的自回归交叉熵损失( L A R \mathcal{L}_{AR} LAR) :用于优化VLM对具身推理文本 和离散动作令牌 的自回归预测能力,公式为:
L A R ( θ ) = − E D l o g π θ ( l \^ ∣ o t , l ) \mathcal{L}{AR}(\theta)=-\mathbb{E}{\mathcal{D}}\leftlog \\pi_{\\theta}\\left(\\hat{l} \| o_{t}, l\\right)\\right LAR(θ)=−EDlogπθ(l\^∣ot,l)
核心让VLM学会从多模态观测和语言指令中,生成符合逻辑的具身推理结果和动作相关令牌。 - 动作专家的流匹配损失( L F M \mathcal{L}_{FM} LFM) :基于流匹配算法设计,用于优化动作专家对连续动作序列 的生成能力,公式为:
L F M ( θ ) = E D , ε , τ ∥ π θ ( a ~ t : t + H , o t , l , τ ) − ( A t : t + H − ε ) ∥ 2 \mathcal{L}{FM}(\theta)=\mathbb{E}{\mathcal{D}, \varepsilon, \tau}\left\| \pi_{\theta}\left(\tilde{a}{t: t+H}, o{t}, l, \tau\right)-\left(A_{t: t+H}-\varepsilon\right)\right\| ^{2} LFM(θ)=ED,ε,τ∥πθ(a~t:t+H,ot,l,τ)−(At:t+H−ε)∥2
其中 A t : t + H A_{t:t+H} At:t+H为真实连续动作序列, ε ∼ N ( 0 , I ) \varepsilon \sim N(0,I) ε∼N(0,I)为高斯噪声, τ ∈ 0 , 1 \tau \in 0,1 τ∈0,1为流时间步, a ~ t : t + H = τ A t : t + H + ( 1 − τ ) ε \tilde{a}{t:t+H}=\tau A{t:t+H}+(1-\tau)\varepsilon a~t:t+H=τAt:t+H+(1−τ)ε为加噪后的动作序列。流匹配损失的设计,让动作专家能更好地学习连续动作的分布特征,提升连续控制的精准性。
- VLM的自回归交叉熵损失( L A R \mathcal{L}_{AR} LAR) :用于优化VLM对具身推理文本 和离散动作令牌 的自回归预测能力,公式为:
-
总训练目标
将双损失进行加权融合,形成模型的总训练目标:
L t o t a l ( θ ) = λ L A R ( θ ) + L F M ( θ ) \mathcal {L}{total}(\theta )=\lambda \mathcal {L}{AR}(\theta )+\mathcal {L}_{FM}(\theta ) Ltotal(θ)=λLAR(θ)+LFM(θ)其中 λ \lambda λ为加权系数,论文在联合训练中设置 λ = 1 \lambda=1 λ=1,让语义推理和连续控制的优化目标处于同等重要的地位。
3.2、梯度解耦策略(知识绝缘思想)
- 梯度传递规则
- 训练具身数据 (机器人操纵/导航轨迹)时:动作专家的梯度不回传至VLM骨干,从根本上避免连续动作的优化目标对VLM语义表征的侵蚀。
- 训练非具身数据(网络文本、图文配对等)时:VLM保持可训练状态,持续从通用数据中优化语义理解和多模态推理能力。
- 语义对齐机制
为了让VLM的推理结果能有效指导动作专家,论文让VLM额外学习离散动作令牌的预测任务,引导VLM编码与动作相关的语义信息,实现VLM与动作专家的语义对齐。
3.3、损失函数1:自回归交叉熵损失( L A R \mathcal{L}_{AR} LAR)
这个损失函数专门用于优化VLM骨干的具身推理能力,让模型能从多模态观测和语言指令中,生成符合逻辑的具身推理文本和离散动作令牌。
公式表达
L A R ( θ ) = − E D log π θ ( l \^ ∣ o t , l ) \mathcal{L}{AR}(\theta) = -\mathbb{E}{\mathcal{D}} \left \\log \\pi_{\\theta}\\left(\\hat{l} \\mid o_{t}, l\\right) \\right LAR(θ)=−EDlogπθ(l\^∣ot,l)
符号拆解
| 符号 | 物理意义 |
|---|---|
| θ \theta θ | 模型的可学习参数 |
| D \mathcal{D} D | 训练数据集(包含具身和非具身数据) |
| π θ \pi_{\theta} πθ | 模型的参数化分布 |
| o t = I t , s t o_t = I_t, s_t ot=It,st | t时刻的多模态观测(视觉输入 I t I_t It + 机器人本体感受状态 s t s_t st) |
| l l l | 人类语言指令(如"Pick the second flower from the left") |
| l ^ \hat{l} l^ | VLM预测的具身推理文本(子任务分解、目标边界框描述、离散动作令牌等) |
设计逻辑
- 这是一个典型的自回归语言建模损失,通过最小化负对数似然,让VLM学会在给定观测和指令的条件下,生成最合理的推理结果。
- 离散动作令牌的预测任务,让VLM的输出不仅包含语义推理,还包含与动作直接相关的信息,为后续动作专家的生成提供语义约束。
3.4、损失函数2:流匹配损失( L F M \mathcal{L}_{FM} LFM)
这个损失函数专门用于优化流匹配动作专家的连续动作生成能力,让模型能精准预测机器人的连续控制动作序列。
公式表达
L F M ( θ ) = E D , ε , τ ∥ π θ ( a ~ t : t + H , o t , l , τ ) − ( A t : t + H − ε ) ∥ 2 \mathcal{L}{FM}(\theta) = \mathbb{E}{\mathcal{D}, \varepsilon, \tau} \left\| \pi_{\theta}\left(\tilde{a}{t:t+H}, o{t}, l, \tau\right) - \left(A_{t:t+H} - \varepsilon\right) \right\|^{2} LFM(θ)=ED,ε,τ∥πθ(a~t:t+H,ot,l,τ)−(At:t+H−ε)∥2
符号拆解
| 符号 | 物理意义 |
|---|---|
| A t : t + H A_{t:t+H} At:t+H | 从 t t t到 t + H t+H t+H时间步的真实连续动作序列(机器人的实际控制指令) |
| ε ∼ N ( 0 , I ) \varepsilon \sim \mathcal{N}(0, I) ε∼N(0,I) | 从标准高斯分布中采样的噪声向量 |
| τ ∈ 0 , 1 \tau \in 0, 1 τ∈0,1 | 流时间步(用于控制噪声强度, τ = 0 \tau=0 τ=0时全是噪声, τ = 1 \tau=1 τ=1时全是真实动作) |
| a ~ t : t + H = τ A t : t + H + ( 1 − τ ) ε \tilde{a}{t:t+H} = \tau A{t:t+H} + (1-\tau)\varepsilon a~t:t+H=τAt:t+H+(1−τ)ε | 加噪后的动作序列(流匹配的核心中间变量) |
| π θ ( a ~ t : t + H , o t , l , τ ) \pi_{\theta}\left(\tilde{a}{t:t+H}, o{t}, l, \tau\right) πθ(a~t:t+H,ot,l,τ) | 动作专家在给定加噪动作、观测、指令和时间步 τ \tau τ时,预测的"去噪方向"(即从噪声到真实动作的流向量) |
设计逻辑
- 流匹配(Flow Matching)的核心思想是:通过学习从噪声到真实动作的"流"(即连续变换),来建模动作的分布。
- 损失函数的目标是让动作专家预测的去噪方向,尽可能接近真实的"噪声到动作"的变换向量( A t : t + H − ε A_{t:t+H} - \varepsilon At:t+H−ε)。
- 这种设计相比传统的扩散模型,训练更稳定,生成的连续动作更平滑、精准,非常适合机器人控制场景。
3.5、总训练目标:双损失加权融合
为了让模型同时优化"语义推理"和"连续控制"两个目标,论文将两个损失函数进行加权融合,形成总训练目标:
L t o t a l ( θ ) = λ L A R ( θ ) + L F M ( θ ) \mathcal{L}{total}(\theta) = \lambda \mathcal{L}{AR}(\theta) + \mathcal{L}_{FM}(\theta) Ltotal(θ)=λLAR(θ)+LFM(θ)
其中, λ \lambda λ 是加权系数,论文在联合训练中设置 λ = 1 \lambda = 1 λ=1,让语义推理和连续控制的优化目标处于同等重要的地位。
3.6、设计价值
- 梯度解耦策略是对传统VLA联合训练模式的根本性革新,从训练机制上解决了"语义表征侵蚀"和"灾难性遗忘"问题,让模型能同时保有通用多模态能力和具身动作能力;
- 离散动作令牌的预测任务,实现了VLM与动作专家的语义对齐,让VLM的推理结果能有效指导动作专家的连续动作生成,避免了"推理与动作脱节";
4、具身空间推理增强------------辅助指导
传统端到端VLA模型的痛点在于:
- 抽象落地难:人类指令(如"Pick the second flower")是抽象语义,而机器人动作是具体的空间坐标变换,二者之间缺乏明确的桥梁。
- 解空间过大:面对复杂长视野任务,机器人可能的动作组合无穷大,若无约束,模型极易生成无效动作(如乱挥手臂或碰撞物体)。
- 黑箱不可解释:模型直接输出动作,无法得知其"为什么要这么做",导致调试困难、鲁棒性差。
核心解决方案是:构建"空间思维链(Spatial Chain of Thought)",通过分层递进的结构化监督,引导模型从抽象语义逐步落地到具象空间动作。
核心机制:四层分层预测(The Four-Layer Hierarchical Prediction)
如图所示,模型并非一步到位直接输出连续动作,而是按照**"子任务 → 目标框 → 末端轨迹 → 离散动作"**的四层顺序,依次完成推理落地。这四步构成了DM0的"空间支架"。
第一层:子任务预测(Subtask Prediction)
- 输入 :语言指令
l+ 多模态观测o_t。 - 输出 :抽象的具身推理文本 l ^ s u b \hat{l}_{sub} l^sub(例如:"First, locate the second flower from the left, then grasp it.")。
- 技术作用 :
- 逻辑分解:将复杂的整体任务拆解为细粒度、可执行的子步骤。
- 语义锚定:为后续的空间定位提供高层语义指南,确保机器人理解任务的整体逻辑。
第二层:目标边界框预测(Target BBox Prediction)
- 输入 :视觉观测
I_t+ 第一层子任务推理。 - 输出 :目标物体的像素坐标框 ( x 1 , y 1 , x 2 , y 2 x_1, y_1, x_2, y_2 x1,y1,x2,y2,如图中红框标注的花朵)。
- 技术作用 :
- 视觉落地:将抽象的语言目标("second flower")转化为图像中的具体空间位置。
- 注意力聚焦:引导模型的视觉注意力集中在目标区域,抑制背景干扰,为后续动作提供精准的空间靶点。
第三层:末端执行器轨迹预测(EEF Trajectory Prediction)
- 输入 :目标BBox + 机器人状态
s_t。 - 输出 :机器人末端执行器(End-Effector)在相机坐标系下的运动路径。
- 技术作用 :
- 模态转化:建立了"图像像素空间"与"机器人运动空间"之间的映射。
- 路径预演:预测出从当前位置到目标位置的最优路径,预判是否会发生碰撞,为最终动作提供运动学层面的约束。
第四层:离散动作预测(Discrete Action Prediction)
- 输入:EEF轨迹 + 任务指令。
- 输出 :离散的动作令牌序列 (如
[207, 15, 153, ...])。 - 技术作用 :
- 动作编码:将连续的轨迹规划转化为机器人控制器可以理解的离散指令令牌。
- 解空间收缩:这是一个关键的"瓶颈"步骤,通过离散化的动作令牌,极大地缩小了后续连续动作专家的搜索空间。
5、模型训练方案
DM0采用三阶段训练方式,三阶段训练的核心逻辑是 "先打基础,再融能力,后做优化"
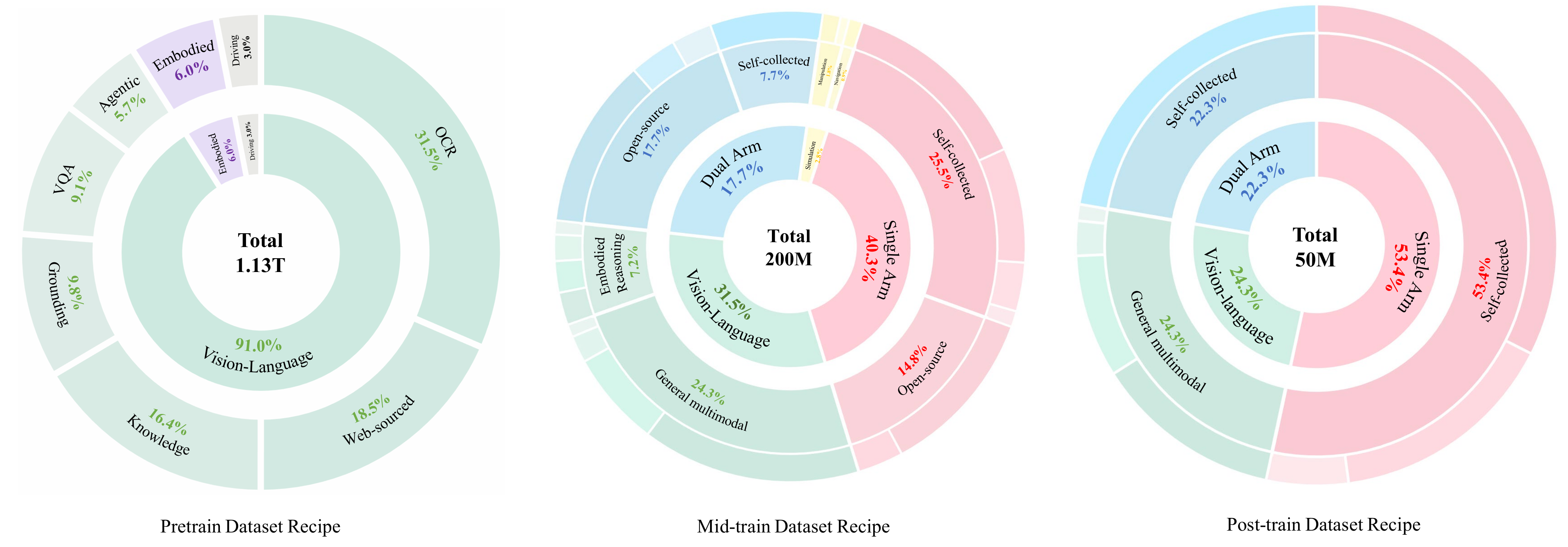
各阶段目标、数据、设置差异显著,核心数字与配置如下表:
| 训练阶段 | 核心目标 | 核心数据规模 | 关键训练设置 |
|---|---|---|---|
| 预训练 | 构建强多模态基础,联合学习语义知识与物理先验 | 8大领域数据,1.2T tokens,370K步骤 | AdamW优化器,全局批次8192,学习率从 5 × 10 − 5 5×10^{-5} 5×10−5衰减至 6 × 10 − 6 6×10^{-6} 6×10−6 |
| 中训练 | 引入动作预测,实现语言推理与物理动作耦合,保留通用多模态能力 | 5类混合数据,200M样本 | 64×H20 GPU,1轮训练,学习率从 2.5 × 10 − 5 2.5×10^{-5} 2.5×10−5衰减至 1 × 10 − 5 1×10^{-5} 1×10−5,AMP开启 |
| 后训练 | 针对目标机器人专属优化,稳定视动对齐 | 重采样数据+目标机器人具身数据,50M样本 | 复用中训练的优化配置与损失函数,仅调整数据采样和目标机器人范围 |
如下图所示,展示了 DM0 三阶段训练中,数据集配方的递进式变化,直观体现了 "从通用到专属、从基础到应用" 的训练逻辑:
- 预训练:以通用数据为主,少量物理数据打底 → 构建 "语义 + 物理" 的基础表征。
- 中训练:动作数据与通用数据并重 → 实现 "推理 + 动作" 的能力耦合。
- 后训练:聚焦自采专属数据 → 完成 "目标机器人" 的落地适配。
5.1、阶段1:预训练(Pretraining)------ 构建多模态基础的"地基工程"
核心目标
让模型从大规模异构数据中联合学习语义知识与物理先验,为后续动作学习奠定坚实的多模态基础,避免传统VLA模型"先学语义,再补物理"的范式缺陷。
数据设计
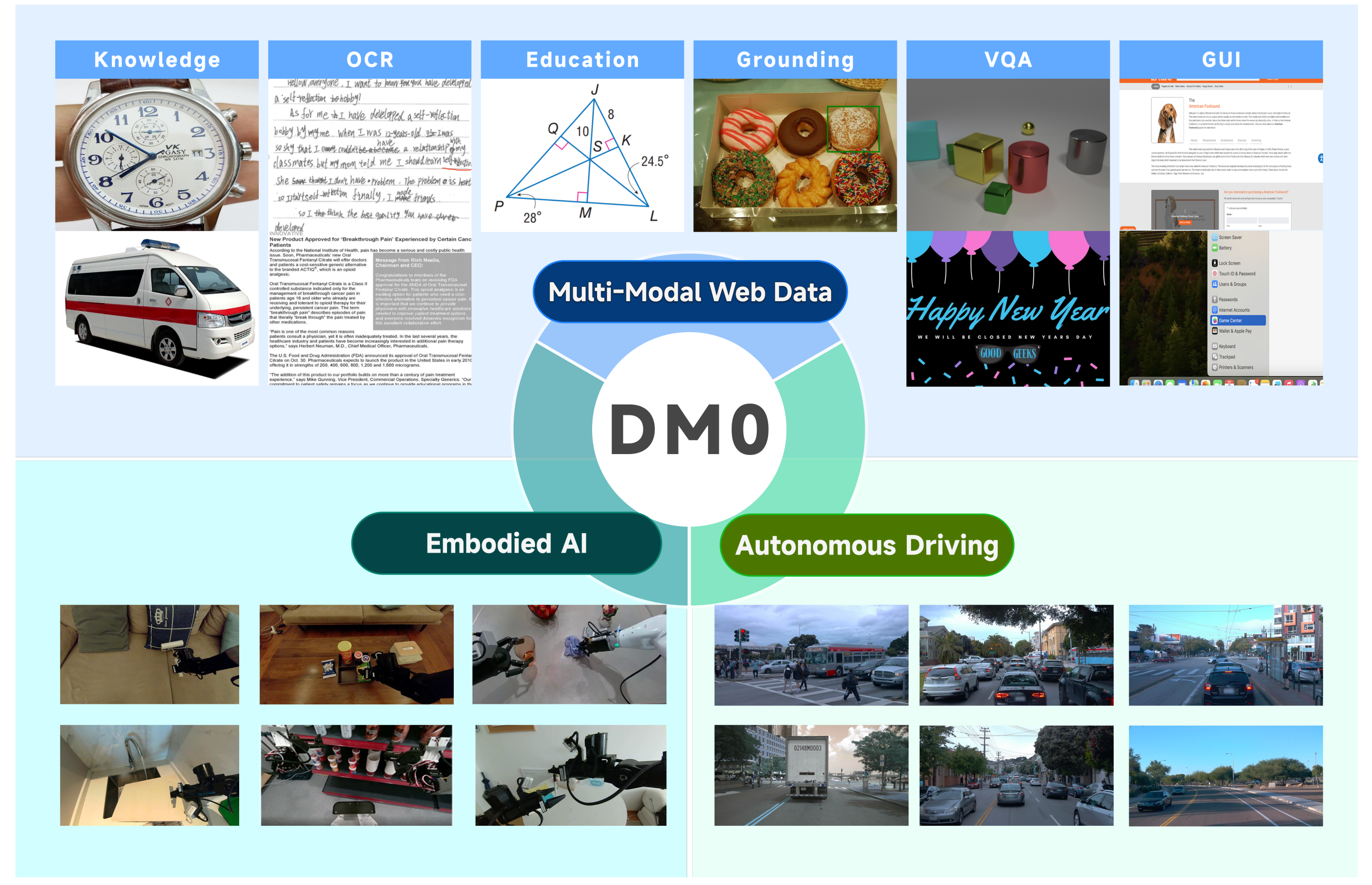
- 覆盖领域:8大核心领域,包括知识、教育、OCR、定位计数、VQA、GUI、自动驾驶、具身交互。
- 数据规模:1.2T tokens,370K训练步骤,是模型学习通用知识和物理规则的核心来源。
- 设计逻辑 :
- 自动驾驶和具身交互数据的引入,让模型从训练初始阶段就接触物理世界的动态性、连续性和空间特性,构建内在物理基础。
- 知识、教育、VQA等数据的融合,让模型同时保有强大的语义理解和推理能力,为后续具身推理提供支撑。

如上图所示,是 DM0 模型多源异构训练数据体系与核心能力覆盖范围的展示。
训练设置
- 优化器:AdamW,权重衰减0.01,β1=0.9,β2=0.999。
- 全局批次:8192,保证训练的稳定性和数据多样性。
- 学习率:从5×10⁻⁵线性衰减至6×10⁻⁶,避免训练后期模型震荡。
- 其他:开启混合精度训练(FP16),提升训练效率。
关键价值
预训练阶段是DM0区别于传统VLA模型的核心起点:它从一开始就将物理数据与语义数据同等对待,让模型的表征天然具备"语义丰富性+物理可执行性",为后续动作学习打下了坚实基础。
5.2、阶段2:中训练(Mid-Training)------ 实现推理与动作耦合的"融合工程"
核心目标
在预训练的基础上,引入动作预测任务,实现语言推理与物理动作的深度耦合,同时通过混合梯度策略防止通用多模态能力退化,让模型既能"理解任务",又能"生成动作"。
数据设计
- 数据类型:5类混合数据,包括视觉语言通用数据、具身推理数据、仿真数据、单臂机器人数据、双臂机器人数据。
- 数据规模:200M样本,是预训练数据的补充和聚焦,重点强化具身场景下的推理与动作能力。
- 增强策略 :
- 设计500种对话模板,让模型在不同指令风格下学习,提升泛化性。
- 对机器人轨迹采用关键帧采样,去除冗余数据,提升训练效率。
- 设计逻辑 :
- 混合通用数据和具身数据,让模型在学习动作的同时,持续优化通用多模态能力。
- 仿真数据的引入,让模型能低成本地学习大量物理交互场景,为真实机器人数据的学习做预热。
训练设置
- 硬件配置:64×H20 GPU,1轮训练,保证大规模数据的高效处理。
- 学习率:从2.5×10⁻⁵线性衰减至1×10⁻⁵,适配动作学习的精细调整需求。
- 损失函数 :同时优化自回归交叉熵损失( L A R \mathcal{L}{AR} LAR)和流匹配损失( L F M \mathcal{L}{FM} LFM),总损失为 L t o t a l = λ L A R + L F M \mathcal{L}{total} = \lambda \mathcal{L}{AR} + \mathcal{L}_{FM} Ltotal=λLAR+LFM( λ = 1 \lambda=1 λ=1)。
- 梯度策略:采用混合梯度策略,训练具身数据时,动作专家的梯度不回传至VLM骨干,防止语义表征侵蚀。
关键价值
中训练阶段是DM0实现"具身原生"的核心环节:它通过混合梯度策略解决了传统VLA模型的"灾难性遗忘"问题,让模型能同时保有通用多模态能力和具身动作能力,为后续实验中Specialist和Generalist配置的性能表现提供了核心支撑。
5.3、阶段3:后训练(Post-Training)------ 适配目标机器人的"落地工程"
核心目标
针对目标机器人平台(如UR5、Franka、ARX5、ALOHA)做专属优化,缩小具身多样性以降低分布方差,稳定视动对齐,让模型能在实际部署场景中稳定执行任务。
数据设计
- 数据类型:重采样的预训练/中训练高质量数据 + 目标机器人专属具身数据。
- 数据规模:50M样本,聚焦目标机器人的动力学和传感器特性,避免无关数据的干扰。
- 设计逻辑 :
- 仅保留目标机器人的单/双臂具身数据,缩小具身多样性,降低分布方差,让模型更精准地适配目标设备。
- 重采样高质量通用数据,保证模型在适配机器人的同时,不丢失通用推理能力。
训练设置
- 优化配置:完全复用中训练的优化器、学习率和损失函数设置,保证训练的一致性和稳定性。
- 调整重点:仅调整数据采样策略和目标机器人范围,聚焦专属优化,避免过度训练导致的过拟合。
关键价值
后训练阶段是DM0从"实验室模型"到"实际部署"的关键桥梁:它让模型能针对不同机器人平台做精细化适配,稳定视动对齐,解决了传统VLA模型"在仿真中表现好,在真实机器人上表现差"的落地难题。
6、模型效果
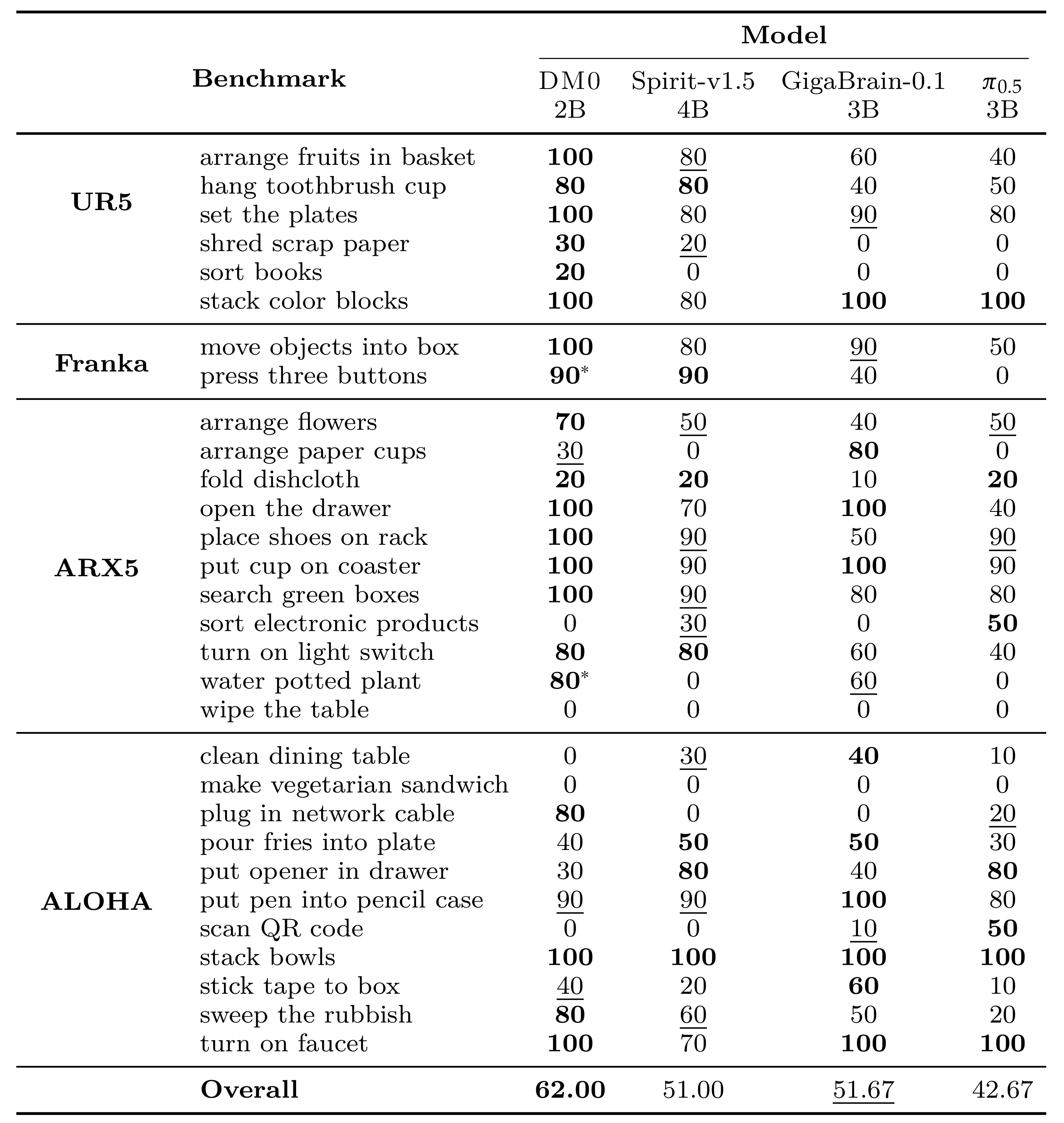
在机器人挑战赛(RoboChallenge)中,Table30 基准测试下主流开源 VLA 模型性能对比:
- 指标为任务成功率;
- 100 代表最高,90 代表第二高。
- 带 * 标记的任务采用进度监督训练;
- 2026 年 2 月 10 日(
目前在RoboChallenge是SOTA)
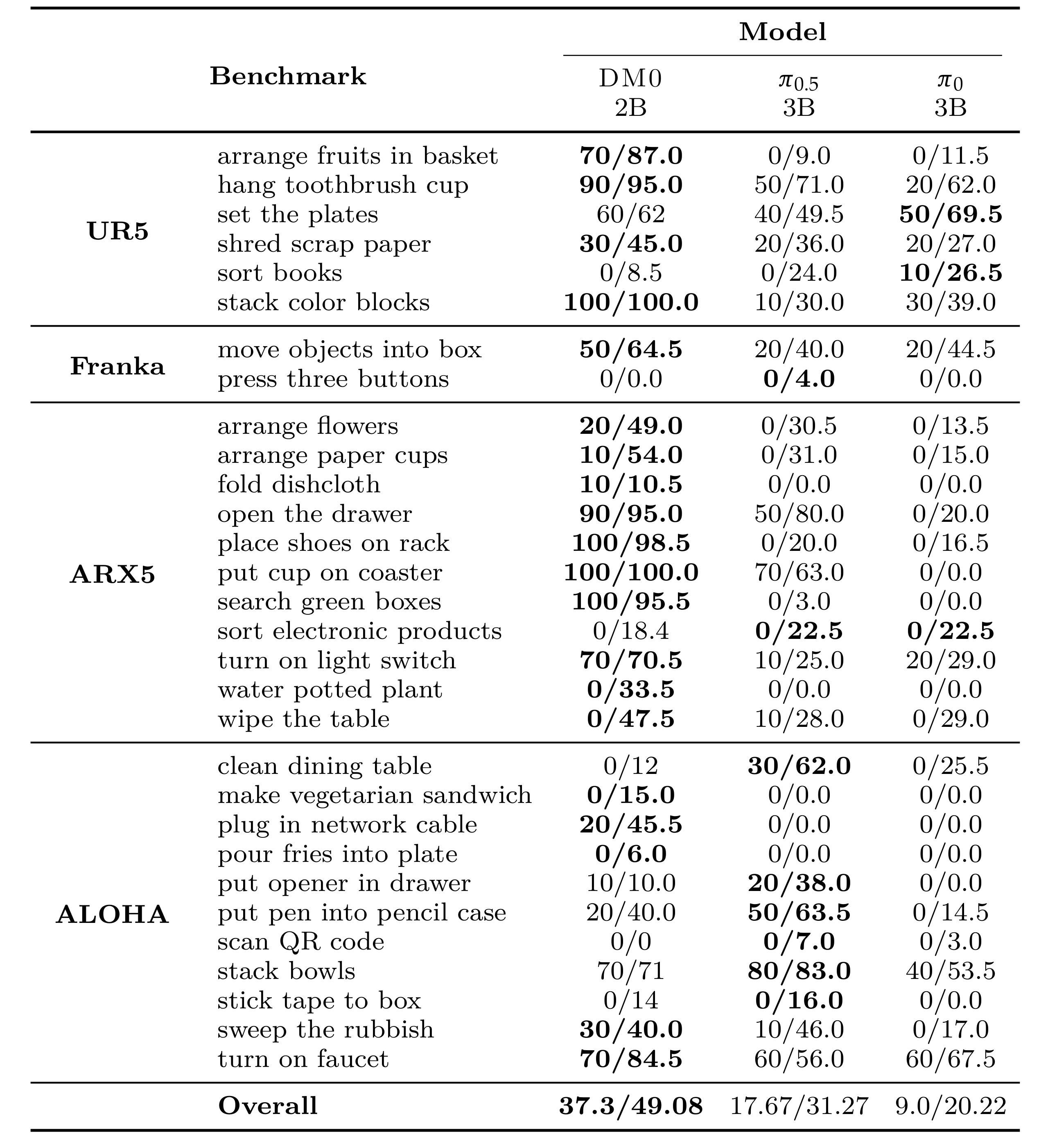
在 RoboChallenge 的 Table30 基准任务中,与当前主流开源通用 VLA 模型(π0 与 π0.5)的对比结果。
- 按成功率 / 得分进行排序。
- 得分项中,100/100 表示最高分。
模型效果:

看了一下开源代码,DM0 处理不仅能完成VLA相关的具身操作任务,还能进行VLN相关的具身导航任务:
参考链接:https://github.com/dexmal/dexbotic/blob/main/docs/DM0.md
下面是目标导航(ObjectNav)的官方复现效果:
- SR成功率挺高的
- SPL比较低,可能生成太多无效动作了
| Method | HM3D SR ↑ | HM3D SPL ↑ | MP3D SR ↑ | MP3D SPL ↑ |
|---|---|---|---|---|
| VLFM | 52.5 | 30.4 | 36.4 | 17.5 |
| L3MVN | 54.2 | 25.5 | - | - |
| UniGoal | 54.5 | 25.1 | 41.0 | 16.4 |
| OVRL | 62.0 | 26.8 | 28.6 | 7.4 |
| PirlNav | 70.4 | 34.1 | - | - |
| Uni-NaVid | 73.7 | 37.1 | - | - |
| DM0 | 73.5 | 25.7 | 45.3 | 12.9 |
分享完成~