文件格式:
数据格式:
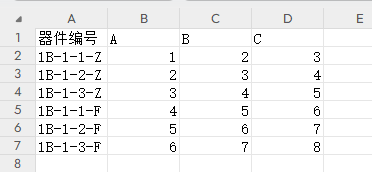
保存数据格式:
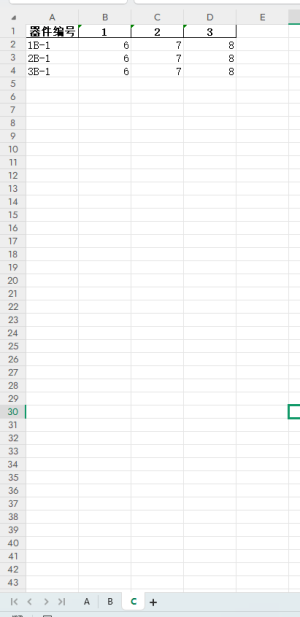
从上面可以看出,数据其实都一样,只是提取出来修改一下保存的方式,并且按照器件编号的顺序保存
提取器件编号要用到正则表达式:
- 原正则是
r'(2B-\d+-\d+)',只能匹配2B-数字-数字(如2B-3-5),无法匹配1B-1-1、34B-2-1。 - 新正则
r'(\d+B-\d+)':\d+:匹配 1 个或多个数字(如 1、2、34)。B:匹配字母 B(忽略大小写,因re.IGNORECASE)。-\d+:匹配短横线 + 数字(如 - 1、-3、-2)。- 最终可匹配
1B-1、2B-3、34B-2等格式。
- 若需要提取完整的三级编号 (如
1B-1-1、2B-3-5),可将正则改为r'(\d+B-\d+-\d+)'
代码:
python
import os
import re
import pandas as pd
'''
编写:hao
提取文件:-F&-Z合并后的结果,第一行为-Z
提取的行数取决于-Z(0,1,2)还是-F(3,4,5)
保存文件:器件编号+漏极电压(三列)+对应的参数
'''
# 定义目标文件夹路径
source_dir = r"D:\DATA_HAO\python\数据处理程序汇总-20251030\练习数据"
# 检查文件夹是否存在
if not os.path.exists(source_dir):
print(f"错误:文件夹 '{source_dir}' 不存在!")
exit(1)
# 定义筛选条件:文件名包含 "34B-" 且为 xlsx 文件
keyword = "2-"
xlsx_files = [
f for f in os.listdir(source_dir)
if f.endswith('.xlsx') and keyword in f
]
if not xlsx_files:
print(f"错误:文件夹 '{source_dir}' 中没有找到包含 '{keyword}' 的xlsx文件!")
print("提示:以下是该文件夹中的所有xlsx文件:")
for file in [f for f in os.listdir(source_dir) if f.endswith('.xlsx')]:
print(file)
exit(1)
# 创建结果保存目录
output_dir = os.path.join(source_dir, "result")
os.makedirs(output_dir, exist_ok=True)
# ===================== 核心配置(根据实际Excel调整,关键!)=====================
# 6个参数列名(作为Sheet名,对应Excel的列)
sheet_names = ['A', 'B', 'C']
# 3个漏极电压名(对应Excel的行,作为结果的列)
drain_voltages = ['1', '2', '3']
# 【关键1:列索引映射(参数列→Excel列索引)】
name_col_idx = 0 # A列:name列(索引0)
# 6个参数列对应的Excel列索引(一一对应sheet_names的顺序)
data_col_indices = [1, 2, 3] #
data_col_map = dict(zip(sheet_names, data_col_indices)) # 参数名→列索引
# 【关键2:行索引映射(漏极电压→Excel行索引)】
# 3个漏极电压对应的Excel行索引(一一对应drain_voltages的顺序,需根据实际调整!)
drain_row_indices = [3, 4, 5] #
drain_row_map = dict(zip(drain_voltages, drain_row_indices)) # 漏极电压→行索引
# 【关键3:要提取的目标行(name行,通常是固定行,如行0/行1,需根据实际调整)】
# 例如:name列的有效数据行是行3(Excel第4行),可改为列表如[3,4]提取多个name行
name_row_indices = [3] # 提取name列的行索引(需根据实际Excel调整)
# ================================================================================
# 初始化数据结构:{参数名: {器件编号: {漏极电压: 参数数值}}}
data_dict = {sheet: {} for sheet in sheet_names}
# 正则表达式:提取器件编号(如从"1B-1-1-Z"中提取"1B-1")
# 匹配规则:以34B开头,后面跟数字和短横线的部分
import re
# 正则表达式:提取器件编号(如从"1B-1-1-Z"中提取"1B-1",从"2B-3-5-F"中提取"2B-3")
# 匹配规则:
# 1. 匹配 数字+B 开头(如1B、2B、34B)
# 2. 后面跟 数字+短横线+数字(如-1-1),但只保留到第一个短横线后的数字(如1B-1、2B-3)
# 若需要提取完整的"1B-1-1",可将正则改为 r'(\d+B-\d+-\d+)'
device_id_pattern = re.compile(r'(\d+B-\d+)', re.IGNORECASE) # 匹配 数字B-数字(如1B-1、2B-3、34B-2)
def extract_device_id(name_str):
"""从name字符串中提取器件编号(如1B-1、2B-3)"""
# 先判断输入是否为有效字符串
if not isinstance(name_str, str) or name_str.strip() == "":
return "未知编号"
# 执行正则匹配
match = device_id_pattern.search(name_str)
if match:
return match.group(1) # 返回匹配到的器件编号
# 若未匹配到,返回原始字符串前10位(避免过长)或"未知编号"
return f"未知编号_{name_str.strip()[:10]}"
# 处理每个xlsx文件
for xlsx_file in xlsx_files:
file_path = os.path.join(source_dir, xlsx_file)
try:
# 读取Excel文件(保留所有列和行,方便调试)
df = pd.read_excel(file_path)
print(f"\n📄 文件 {xlsx_file}")
print(f"文件所有列名:{df.columns.tolist()}")
print(f"文件行列数:{df.shape}")
# 1. 过滤有效的name行(避免索引越界)
valid_name_rows = [row_idx for row_idx in name_row_indices if row_idx < df.shape[0]]
if not valid_name_rows:
print(f"⚠️ 文件 {xlsx_file} 无有效name行(索引:{name_row_indices}),跳过")
continue
# 2. 过滤有效的漏极电压行(避免索引越界)
valid_drain_rows = {drain: row_idx for drain, row_idx in drain_row_map.items() if row_idx < df.shape[0]}
if not valid_drain_rows:
print(f"⚠️ 文件 {xlsx_file} 无有效漏极电压行,跳过")
continue
print(f"📌 有效漏极电压行:{[(d, r + 1) for d, r in valid_drain_rows.items()]}(漏极电压→Excel行号)")
# 3. 遍历每个name行(提取原始name并解析器件编号)
for name_row_idx in valid_name_rows:
# 获取原始name内容(A列,name_col_idx)
original_name = str(df.iloc[name_row_idx, name_col_idx]).strip() if pd.notna(
df.iloc[name_row_idx, name_col_idx]) else f"未知_{name_row_idx}"
if not original_name:
print(f"⚠️ name行{name_row_idx + 1}:name为空,跳过")
continue
# 提取器件编号(核心:从name中解析34B-2-1这类编号)
device_id = extract_device_id(original_name)
print(f"📌 处理name行{name_row_idx + 1}:原始name={original_name} → 器件编号={device_id}")
# 4. 遍历每个参数列(Sheet名,如Ion(μA))
for sheet in sheet_names:
data_col_idx = data_col_map[sheet] # 参数对应的列索引
# 检查参数列索引是否有效
if data_col_idx >= df.shape[1]:
print(f"⚠️ 参数[{sheet}]列索引{data_col_idx}超出范围,跳过")
continue
# 初始化该器件编号的存储(若不存在)
if device_id not in data_dict[sheet]:
data_dict[sheet][device_id] = {d: None for d in drain_voltages}
# 5. 遍历每个漏极电压行(提取参数数值:参数列×漏极电压行)
for drain, drain_row_idx in valid_drain_rows.items():
# 提取数值:df.iloc[漏极电压行索引, 参数列索引]
value = df.iloc[drain_row_idx, data_col_idx] if pd.notna(
df.iloc[drain_row_idx, data_col_idx]) else None
# 赋值:器件编号 → 漏极电压 → 参数数值
data_dict[sheet][device_id][drain] = value
print(f"✓ 已处理文件:{xlsx_file}")
except Exception as e:
print(f"⚠️ 处理文件 '{xlsx_file}' 时出错:{str(e)}")
continue
# 整理数据并保存到Excel
output_file = os.path.join(output_dir, "combined_results.xlsx")
with pd.ExcelWriter(output_file, engine='openpyxl') as writer:
for sheet in sheet_names:
# 转换为DataFrame(列:器件编号 + 三个漏极电压)
rows = []
for device_id, drain_values in data_dict[sheet].items():
# 行内容:器件编号 + 每个漏极电压的数值(按drain_voltages顺序)
row = [device_id] + [drain_values[d] for d in drain_voltages]
rows.append(row)
# 处理空数据情况
if not rows:
df_result = pd.DataFrame(columns=['器件编号'] + drain_voltages)
else:
df_result = pd.DataFrame(rows, columns=['器件编号'] + drain_voltages)
# 处理Sheet名:过滤Excel非法字符(/:*?"<>|),限制长度
sheet_clean = sheet.replace('(', '_').replace(')', '').replace('/', '_').replace(' ', '_').replace('\\',
'_').replace(
'*', '_').replace('?', '_').replace('"', '_').replace('<', '_').replace('>', '_').replace('|', '_')[:31]
# 写入Excel
df_result.to_excel(writer, sheet_name=sheet_clean, index=False)
print(f"\n✓ 已保存Sheet: {sheet_clean}(共{len(rows)}行)")
print(f"\n✅ 处理完成!结果保存在:{output_file}")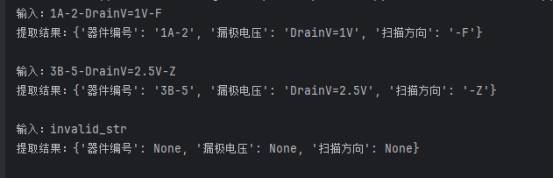
学习笔记:
re.compile 函数-编译正则表达式
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,可以给 match() 、 search() 以及 findall 等函数使用。
语法格式为:
re.compile(pattern, flags)
参数:
pattern : 一个字符串形式的正则表达式
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
re.I 忽略大小写
re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M 多行模式
re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
re.X 为了增加可读性,忽略空格和 # 后面的注释
# 编译正则表达式模式,使用分组捕获目标内容
# 正则表达式解析:
# ^:匹配字符串开头
# (.+?):非贪婪匹配,捕获分组1(器件编号,如1A-2)
# -DrainV=:匹配固定分隔符"-DrainV="
# ([\d\.]+V):捕获分组2(电压值,支持整数/小数+V,如1V、2.5V)
# -:匹配分隔符"-"
# ([A-Z]):捕获分组3(扫描方向的字符,如F、Z)
# $:匹配字符串结尾
pattern = re.compile(r'^(.+?)-DrainV=([\d\.]+V)-([A-Z])$')#编译正则表达式我们把正则表达式拆分成带编号的分组,看左括号的顺序:
正则表达式片段 左括号(的顺序 对应分组编号
匹配内容示例(输入:1A-2-DrainV=1V-F)
(.+?) 第 1 个左括号 group(1) 1A-2(器件编号)
(\\d\\.+V) 第 2 个左括号 group(2) 1V(电压值部分)
(A-Z) 第 3 个左括号 group(3) F(扫描方向字符