我自己的原文哦~ https://blog.51cto.com/whaosoft143/14389407
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#Mio(Multimodal Interactive Omni-Avatar)
Mio框架横空出世:迈向真正具备交互、表达与进化能力的"交互式智能"数字人
- 论文标题:Towards Interactive Intelligence for Digital Humans
- 作者机构:盛大AI研究院东京;东京大学;东京科学大学;日本国立情报研究所
- 论文地址:https://arxiv.org/abs/2512.13674
- 项目主页: https://shandaai.github.io/project_mio_page/
,时长01:10
最近,数字人领域迎来了一项激动人心的进展。一篇名为Towards Interactive Intelligence for Digital Humans的论文,提出了一种全新的数字人范式------交互式智能(Interactive Intelligence) 。为了实现这一范式,研究者们推出了一个名为**Mio(Multimodal Interactive Omni-Avatar)**的端到端框架。这个框架的目标,是让数字人不再是只能模仿表面行为的"提线木偶",而是成为能够与用户无缝互动、拥有个性化表达、自适应反应甚至能自我进化的"智能体"。
Mio的出现,标志着数字人研究从追求"形似"的视觉真实感,迈向了探索"神似"的智能交互新阶段。
迈向"交互式智能":Mio框架的核心理念
传统的数字人,要么依赖于繁琐的手动CG制作流程,要么基于生成模型进行离线渲染。这些方法产生的角色,本质上是行为模式的"复读机",缺乏真正的交互逻辑和实时响应能力。
为了打破这一局限,Mio框架应运而生。它是一个统一的架构,巧妙地将认知推理与实时的多模态行为(面部、身体、语音)相结合,包含五个协同工作的专业模块:
- 思考者 (Thinker):作为数字人的"大脑",负责认知、推理和决策。
- 说话者 (Talker):作为"声带",将文本转化为富有情感和个性的语音。
- 面部动画师 (Face Animator):作为"表情肌",生成与语音和情绪同步的细腻面部动画,包括说话和聆听时的反应。
- 身体动画师 (Body Animator):作为"躯干",根据指令实时生成连贯、自然的身体动作。
- 渲染器 (Renderer):作为"皮肤",将所有参数化的动作信号,合成为高保真、多视角一致的视频画面。
接下来,我们将深入探索这个框架的每个模块,看看它们是如何协同工作,共同赋予Mio"交互式智能"的。
Thinker:数字人的"大脑"与"灵魂"
Thinker是Mio框架的指挥中心,其核心目标是让数字人拥有类似人类的思考和决策能力。为了实现这一点,它设计了两大核心机制:分层记忆系统 和离线自我进化。
分层记忆,告别"剧透"和"失忆"
为了让数字人在一个具有特定故事背景的环境中保持长期记忆和叙事连贯性,Thinker设计了一套分层记忆系统。
- 短期记忆:一个上下文缓冲区,用于处理眼前的对话。
- 长期记忆:一个"叙事知识图谱"(Diegetic Knowledge Graph)。这个图谱记录了故事世界中的所有知识、事件和人物关系,并且带有时间戳。
最关键的是,它采用了一种"故事时间感知"的检索增强生成(Story-Time-Aware RAG)技术。这意味着,当数字人需要从长期记忆中检索信息时,它只能访问"当前时间点"之前发生过的事,从而完美避免了"剧透"未来的尴尬,保证了叙事逻辑的严谨性。
无需标注的"自我进化"
如何让数字人的人设(Persona)越来越精准,而又无需昂贵的人工标注?Thinker采用了一种巧妙的"左右互搏"式自我训练循环。
- 一个**"场景生成策略"()** 会不断设计出刁钻的互动场景,专门用来挑战和探测当前数字人的"人设"弱点。
- 另一个**"互动扮演策略"()** 则扮演数字人本身,努力在这些场景中做出最符合人设的回应。
- 最后,一个**"多模态奖励模型"**会根据用户的全局满意度反馈(比如一个最终评分),智能地反推出每一次具体互动(比如某句话、某个表情)的"功劳"或"过错",并给予精细化的奖励或惩罚。
通过这个过程,数字人不断地在自我挑战中优化自己的行为,使其人格表现越来越稳定和真实。
Talker:Kodama,让声音富有表现力
Talker模块负责将Thinker生成的文本转化为生动的语音。研究者们为此开发了Kodama-Tokenizer 和Kodama-TTS。
核心思想在于将语音信号解耦为"语义"和"声学"两种信息。前者决定"说了什么",后者决定"听起来怎么样"。这种设计使得模型可以对不同信息进行针对性压缩和建模,最终以极低的比特率(1kbps)实现高质量的语音重建。
实验数据显示,Kodama-Tokenizer在语音重建任务中,多项客观指标(如STOI, PESQ)优于现有的XY-Tokenizer和XCodec2.0。
而在零样本TTS(Zero-shot TTS)任务中,Kodama-TTS在多个测试集上,无论是在自然度(DNSMOS)还是发音准确率(错误率)上,都展现出与SOTA模型(如Higgs)相当甚至更优的性能。
Face Animator:UniLS,会说还要会听
一个好的交谈者不仅要会说,更要会听。Face Animator模块通过提出的**UniLS (Unified Speak-Listen)**模型,解决了数字人在"聆听"时的"僵尸脸"问题。
UniLS的巧妙之处在于其两阶段训练策略:
- 第一阶段:无音频预训练。模型在海量的、无音频的视频数据上进行训练,学习各种内在的面部动态先验,如自然的眨眼、微表情和头部晃动。这相当于为模型注入了"无意识"下的自然行为模式。
- 第二阶段:音频驱动微调。在预训练好的模型基础上,引入对话双方的音频信号进行微调。通过交叉注意力机制,模型学会将内在的动态与外部的音频信号(自己说的和对方说的)结合起来,从而生成既包含说话时的口型同步,也包含聆听时的生动反应。
实验结果令人信服。无论是客观指标还是主观用户研究,UniLS都全面胜出。 在客观指标上(见下表),UniLS在说话(Speak)和聆听(Listen)两个场景下的各项误差和距离度量(如LVE, FDD, FID)都显著低于对比方法,尤其是聆听时的F-FID指标,从ARTalk*的10.779骤降至4.304,表明其生成的聆听动作分布更接近真实。
下面的定性对比图更直观地展示了UniLS的优势。在聆听时,对比方法(ARTalk*, DualTalk)的面部表情显得僵硬呆板,而UniLS生成的表情则生动自然。
在说话时,UniLS的面部表情和口型同步也更贴近真实情况。
在用户研究中,参与者在口型同步、表情自然度、聆听反应自然度等所有方面都更偏爱UniLS。尤其是在"聆听反应"上,超过**90%**的用户认为UniLS的表现远超竞品。
Body Animator:FloodDiffusion,让动作如行云流水
为了实现实时、可控、无限长的身体动作生成,Body Animator模块引入了FloodDiffusion,一种专为流式生成设计的扩散模型。
它解决了传统扩散模型无法用于实时应用的核心痛点,其关键设计包括:
- Causal VAE:首先使用一个因果VAE将高维的动作数据(263维)压缩到极低维的连续潜在空间(4维),大大降低了后续模型的计算负担。
- 下三角噪声调度(Lower-Triangular Noise Schedule):这是FloodDiffusion的核心创新。它不像标准扩散模型那样在每个时间步对整个序列施加同样水平的噪声,而是创造了一种"级联"式的去噪模式。在任何时刻,只有一小段"活动窗口"内的动作在被积极去噪,而之前的动作已经"尘埃落定",之后的动作则完全是噪声。
这种设计保证了模型在生成时,计算量是恒定的,延迟有严格的上界,从而实现了真正的流式输出。
- 时变文本条件(Time-Varying Text Conditioning):该模型可以随时接收来自Thinker的新指令(如从"走路"变为"挥手"),并丝滑地过渡到新动作,而不会产生停顿或突兀感。下图展示了模型如何根据指令输入时间的不同,生成完全不同的动作序列。
在HumanML3D和BABEL两个标准数据集上的评测显示,FloodDiffusion在多项动作质量和流畅度指标上,均达到了SOTA水平,尤其是在FID指标上,以0.057的成绩显著优于其他流式生成方法。
Renderer:AvatarDiT,打造照片级真实感
渲染器是Mio的"颜值担当",它负责将前面各个模块生成的参数化控制信号(FLAME面部参数、SMPL身体姿态、相机参数)转化为高保真、身份一致的视频。
研究者们提出了AvatarDiT ,一个基于视频扩散Transformer(Video Diffusion Transformer)的渲染框架。它同样采用了一个三阶段训练策略来解耦并学习身份、面部控制和多视角一致性这三大难题。
- 面部控制阶段:通过一个FLAME适配器,将参数化控制引入到预训练的视频生成模型中。
- 多视角控制阶段:利用多视角数据集进行训练,通过一个相机调制模块,强制模型学习到跨视角的几何一致性。
- 联合微调阶段:最后在同时拥有多视角和FLAME标注的数据上进行联合优化,弥合不同阶段之间的分布差异。
实验结果表明,AvatarDiT在多视角一致性和整体感知质量上均优于现有的SOTA方法。例如,在多视角一致性上,其CLIP相似度最高,LPIPS误差最低。
在整体感知质量上,其FID达到了68.72 ,FVD达到了176.70,均为所有对比方法中的最佳值。
主观评分中,AvatarDiT在所有维度(面部一致性、表情准确度、多视角一致性、综合质量)上都获得了最接近真实视频的评分。
一点思考
为了综合评估Mio的整体性能,研究者们还提出了一个全新的评估体系------交互式智能分数(Interactive Intelligence Score, IIS)。该分数将认知、声学、面部、身体和视觉五个维度的性能融合成一个0-100的综合分。
结果显示,Mio的总分达到了76.0 ,相比于之前各项SOTA模型的组合,实现了**+8.4**分的显著提升。
总而言之,Mio框架的提出,无疑为数字人领域的发展描绘了一幅激动人心的蓝图。它不再满足于创造一个外表逼真的"数字皮囊",而是致力于打造一个拥有内在逻辑、能够思考、表达并与世界真实互动的"数字生命"。从模仿到交互,Mio或许正是开启下一代数字人智能革命的关键钥匙。
....
#NEPA (Next-Embedding Predictive Autoregression)
告别像素重建!密歇根大学等提出NEPA:极简自回归预训练,无需Tokenizer,ImageNet Top-1达85.3%
你是否想过,为什么语言模型(LLM)可以通过简单的"预测下一个词"(Next-Token Prediction)变得如此强大,而视觉模型还在纠结于"重建像素"或者"对比学习"?GPT系列的成功告诉我们,生成式预测能够迫使模型理解数据的内在分布和语义逻辑。既然如此,视觉模型能否也通过预测"未来"来学习"现在",而不是费力地去重建每一个像素细节?
近日,来自密歇根大学、纽约大学、普林斯顿大学和弗吉尼亚大学的研究团队给出了肯定的答案。他们提出了一种名为 NEPA (Next-Embedding Predictive Autoregression) 的全新视觉预训练框架。NEPA 的核心思想极简而深刻:不在像素空间预测,也不引入离散的 Tokenizer,而是直接在连续的 Embedding 空间中预测下一个 Patch 的特征。
令人惊讶的是,仅仅凭借这一个简单的预测目标,无需任何解码器(Decoder)、无需对比学习(Contrastive Loss)、无需特定任务头,NEPA 就在 ImageNet-1K 上取得了 83.8% (ViT-B) 和 85.3% (ViT-L) 的 Top-1 准确率,甚至在语义分割任务上也表现出色。这或许标志着,视觉预训练终于找到了一条通向"原生生成式智能"的极简路径。

- 论文地址: https://arxiv.org/abs/2512.16922
- 项目主页: https://sihanxu.me/nepa
- 代码仓库(代码和模型已开源): https://github.com/SihanXu/NEPA
回归生成本质:为什么是"预测"而不是"重建"?
在过去的几年里,视觉自监督学习(SSL)主要被两大流派统治:一是对比学习 (如 MoCo, DINO),它通过拉近同一图像不同视图的特征来学习不变性;二是掩码图像建模(MIM,如 MAE, BEiT),它通过重建被遮挡的像素或 Token 来学习细节。
然而,这两种方法都有其"包袱"。对比学习往往依赖复杂的负样本对或动量编码器;MIM 虽然简单,但通常需要一个沉重的解码器来恢复像素,且主要关注底层细节而非高层语义。相比之下,LLM 的训练逻辑要直观得多:阅读上文,预测下文。这种自回归(Autoregressive) 的方式天然包含了因果推理和语境理解。
NEPA 正是将这种 GPT 式的哲学引入视觉领域的一次大胆尝试。作者认为,与其学习如何重建图像,不如学习如何"推演"图像。如果模型能够根据已有的视觉片段(Patches),准确预测出下一个片段的特征表示(Embedding),那么它一定已经理解了图像的语义结构和物体间的空间关系。
方法详解:极简的 NEPA 架构
NEPA 的美感在于其极致的简洁性。它不需要像素级的解码器(不像 MAE),也不需要离散的视觉词表(Visual Tokenizer,不像 BEiT 或 VQ-VAE),更不需要动量编码器(Unlike JEPA or MoCo)。
核心机制:Next-Embedding Prediction
NEPA 的工作流程可以概括为以下三步:
- 分块与编码:将输入图像 切分为 个非重叠的 Patch,并通过一个共享的编码器 映射为 Embedding 序列 。
- 自回归预测:使用一个标准的 Transformer 作为预测器 ,根据当前的上下文 预测下一个位置的 Embedding 。公式如下:
- 计算损失 :将预测出的 Embedding 与真实的 Embedding 进行对比。为了防止模型坍塌(即输出常数解),NEPA 引入了类似 SimSiam 的 Stop-Gradient 操作,即不对目标 Embedding 进行梯度回传。损失函数采用负余弦相似度:
这一设计与 Meta 提出的 JEPA (Joint-Embedding Predictive Architecture) 有异曲同工之妙,但 NEPA 更为激进和简化。如上图所示,JEPA 仍然保留了双塔结构(Context Encoder 和 Target Encoder),而 NEPA 则是单塔结构,完全在同一个序列中进行自回归预测,真正做到了"像语言模型一样训练"。
架构细节与训练稳定性
虽然框架简单,但要让自回归模型在连续空间中稳定训练并非易事。作者引入了一系列现代 Transformer 的设计组件来增强稳定性(如下图所示):
- RoPE (Rotary Position Embedding):旋转位置编码,增强了模型对相对位置的感知能力。
- LayerScale:通过可学习的层级缩放因子,稳定训练初期的优化过程。
- SwiGLU:替代传统的 GeLU 激活函数,与 LLaMA 等现代 LLM 保持一致。
- QK-Norm:对 Query 和 Key 进行归一化,防止注意力分数的梯度爆炸。
实验结果:简单却强大
那么,这种极简的策略效果如何呢?实验数据给出了有力的证明。
ImageNet 分类与扩展性
在标准的 ImageNet-1K 图像分类任务上,NEPA 展现了强大的性能。
- NEPA-B (ViT-Base) :仅需预训练,微调后达到了 83.8% 的 Top-1 准确率,这一成绩优于 MoCo v3 (83.2%) 和 BEiT (83.4%),与 MAE (83.6%) 和 DINO (83.6%) 持平或略优。
- NEPA-L (ViT-Large) :达到了 85.3% 的准确率,与 MAE-L (85.6%) 和 JEPA-L (85.2%) 处于同一梯队。
更重要的是,NEPA 表现出了良好的 Scaling Law(缩放定律)特性。随着训练 epoch 的增加,模型性能持续稳步提升,没有出现过拟合迹象。
语义分割:从全局到细节
除了分类任务,NEPA 在需要密集预测的语义分割任务上也表现出色。在 ADE20K 数据集上,NEPA-B 取得了 48.3 mIoU ,NEPA-L 更是达到了 54.0 mIoU ,NEPA-L优于 MAE (53.6 mIoU) 和 BEiT (53.3 mIoU)。
这一结果令人印象深刻,因为 NEPA 在预训练阶段从未接触过像素级的重建任务,也没有显式的解码器,却能学到如此精细的空间特征,证明了预测 Embedding 本身就足以捕捉图像的结构信息。
可视化分析:它真的"看懂"了吗?
为了探究 NEPA 到底学到了什么,作者可视化了模型的注意力图(Attention Map)和 Embedding 相似度图。
结果非常有趣:NEPA 展现出了显著的"以物体为中心"(Object-Centric)的特性。即使没有监督信号,当模型试图预测物体某一部分的 Embedding 时,它会自动关注该物体的其他部分以及相关的背景线索。例如,预测狗的头部特征时,模型会关注狗的身体;预测汽车的局部时,模型会关联整个车身。
这种长距离的语义关联能力,正是生成式预训练的魅力所在------为了准确预测"未知",模型必须深刻理解"已知"的全局语境。
局限与挑战
当然,NEPA 也并非完美。作者坦诚地展示了一些失败案例。实验表明在处理强反光表面、复杂阴影或重叠物体时,模型偶尔会感到困惑,将高光误认为物体特征,或将阴影误判为背景。
这暗示了目前的 ImageNet 数据集可能在物理场景的复杂性上还不足以让模型完全掌握光影规律,未来随着数据规模的扩大,这些问题有望得到缓解。
写在最后
NEPA 的出现,让我们看到了一种有意思的可能性:视觉和语言的预训练范式正在加速融合。这种简单的、自回归的、基于 Embedding 的预测任务,足以构建强大的视觉学习者。
仅凭在连续空间预测下一个Patch Embedding,即达成视觉预训练SOTA。
....
#VTP(Visual Tokenizer Pre-training)
VAE重建好意味着生成好?华科、MiniMax新解 VTP:用"语义理解"重塑视觉 Tokenizer 预训练
今天,我想跟大家聊一篇来自 MiniMax 和 华中科技大学的最新研究,论文标题是《Towards Scalable Pre-training of Visual Tokenizers for Generation》(中文可以理解为《面向生成任务的可扩展视觉Tokenizers预训练》)。这篇论文提出了一种名为 VTP 的统一视觉Tokenizer预训练框架,旨在解决当前生成模型中一个核心但常常被忽视的问题:视觉Tokenizers(比如大家熟悉的VAE)的预训练效率与生成质量之间的矛盾。
- 论文标题:Towards Scalable Pre-training of Visual Tokenizers for Generation
- 作者:Jingfeng Yao, Yuda Song, Yucong Zhou, Xinggang Wang
- 机构:华中科技大学,MiniMax
- 论文地址:https://arxiv.org/abs/2512.13687
- 代码仓库:https://github.com/MiniMax-AI/VTP
视觉Tokenizers的"成长烦恼":预训练缩放困境
在现代的扩散模型(如LDM)中,视觉Tokenizer扮演着至关重要的角色,它负责将高维的图像信息压缩到更紧凑的潜在空间,然后再由生成模型在此潜在空间中进行操作。传统的视觉Tokenizer预训练方法,通常以像素级别的重建(Reconstruction)为主要目标。然而,研究人员发现了一个颇为反直觉的现象:尽管重建精度越来越高,但生成模型的最终质量却往往没有同步提升,甚至可能出现负面影响。这就像我们专注于画面的每一个细节,却忽略了画面整体的意境和表达。
这种现象被论文作者称之为"预训练缩放问题"(pre-training scaling problem)。它意味着,即便我们投入大量的计算资源去优化视觉Tokenizer的重建能力,其对生成性能的提升却微乎其微。背后的原因在于,单纯的重建目标会让潜在空间偏向于捕捉低级(low-level)的像素信息,而对于生成模型至关重要的高级(high-level)语义信息,却缺乏有效的表达。这就像是模型只看到了"树木",却没能"看到森林"。
VTP框架:让Tokenizer"懂"得更多,生成得更好
为了解决这一痛点,VTP 框架应运而生。它提出一个核心观点:一个真正有效的潜在空间,必须能够简洁地表示高级语义。 VTP (Visual Tokenizer Pre-training)框架创新性地将图像-文本对比学习(image-text contrastive learning)、自监督学习(self-supervised learning)和传统的重建损失(reconstruction loss)结合起来,进行联合优化。
这个多任务学习方案使得模型在预训练阶段就能同时发展出高保真的重建能力、语义丰富的表示学习能力以及跨模态对齐能力。这就像是给Tokenizer开辟了多条"学习路径",让它不仅仅能"看清"像素,还能"理解"图像背后的含义,并将其与文本信息关联起来。
图:VTP框架概述。通过将表示学习(图像-文本对比和自监督学习)与视觉Transformer自动编码器中的重建相结合,VTP在生成性能上表现出良好的缩放特性。
从图中的框架概述我们可以看到,VTP 采用了一个Vision Transformer Auto-Encoder作为基础架构,并引入了三种损失进行联合优化。其中:
- 重建损失 :这是传统自动编码器的核心,确保Tokenizer能够忠实地还原输入图像的像素信息。
- 自监督学习损失 :这部分通过DINOv2等方法,帮助模型从大规模无标注数据中学习鲁棒的视觉表示,提升对视觉特征的理解能力。
- 图像-文本对比损失 :类似于CLIP,它让图像的潜在表示与对应的文本描述在潜在空间中对齐,从而赋予Tokenizer理解高级语义信息的能力。
通过将这三者以加权和的形式结合在一起:
其中 是平衡系数。这种设计确保了Tokenizer的潜在空间既能保留细节,又能捕捉高层语义,为下游的生成任务打下坚实基础。
实验:理解力是生成模型的关键驱动力
图:理解力是生成模型的关键驱动力。观察到视觉Tokenizer预训练期间,潜在空间的理解能力与生成能力之间存在显著的正相关。
实验结果明确指出,引入语义理解和感知任务能够显著增强模型的生成能力。论文观察到,潜在空间的语义质量与其生成性能之间存在强烈的正相关。这意味着,让Tokenizer更好地"理解"图像内容,比单纯提高像素重建精度更能有效提升生成质量。
- 卓越的缩放特性:计算、参数、数据同步提升
与传统的仅基于重建的Tokenizer不同,VTP 展示了卓越的缩放特性。这意味着,随着我们投入更多的计算资源(FLOPs )、增加模型参数量以及扩大数据集规模,VTP 的生成性能能够持续稳定地提升。而传统Tokenizer的性能,在达到一定规模后便会迅速停滞,无法从额外的资源投入中获益。
图:CLIP+AE和SSL+AE视觉Tokenizer预训练的可扩展性。VTP方法在计算量增加时,生成和理解能力同步增长,而基于VAE的Tokenizer性能则迅速饱和。
从图中的对比分析可以看出,当只进行重建训练时,虽然重建性能持续提升,但生成性能反而略有下降。这印证了单纯重建目标无法有效驱动生成能力扩展的观点。而 VTP 结合了对比学习和自监督学习后,生成和理解能力与计算投入呈现出强关联的同步增长。
更令人振奋的是,即使在不修改标准DiT训练配置的前提下,仅仅通过增加 VTP 预训练阶段的 FLOPs ,就能使下游生成任务的 FID指标提升65.8%!这与传统自动编码器在相同计算量下的停滞不前形成了鲜明对比。
图:数据和参数的可扩展性。DiT生成性能在固定训练FLOPs下,随着Tokenizer模型尺寸和训练数据的增加而提升。
这组图表进一步展示了 VTP 在数据和参数缩放上的优势。无论是扩大训练数据集规模,还是增加编码器和解码器的模型参数,VTP 的生成性能都表现出持续的进步,突破了传统方法性能增长的上限。
最终,经过大规模预训练的 VTP Tokenizer展现出极具竞争力的性能:在ImageNet上实现了 78.2%的零样本准确率 和 0.36的rFID ,并且在生成任务上的收敛速度比先进的蒸馏方法快4.1倍。
图:重建对比。VTP在色彩准确性和精细纹理的保留方面表现出卓越的重建性能。
图:生成对比。VTP在生成方面实现了更快的收敛,表明预训练范式具有更高的潜在上限。
这两张对比图直观地展示了 VTP 在重建细节(如色彩准确性和纹理保留)和生成收敛速度上的显著优势,进一步证实了其方法的有效性和潜力。
写在最后
VTP 框架的提出,为视觉Tokenizers的预训练带来了范式上的转变。它深刻地揭示了"理解"在"生成"任务中的核心地位,并提供了一个可扩展的解决方案,打破了传统方法在扩展性上的瓶颈。这意味着未来的生成模型,将能够拥有更强大、更富有语义的潜在空间,从而生成更高质量、更具创意的内容。
如果你对这个项目感兴趣,他们已经开源了预训练模型:
- 代码仓库 :
https://github.com/MiniMax-AI/VTP
....
#Styletailor
首个集成设计/推荐/试衣/打分的负反馈多智能体框架
最近,来自人工智能与数字经济广东省属实验室(深圳)、清华大学、新加坡国立大学、Bytedance Seed、、杭州电子科技大学和香港大学的研究者们联手,推出了一项名为 StyleTailor 的新工作,旨在通过分层负反馈机制,将个性化服装设计、购物推荐、虚拟试穿和系统评估整合到一个统一的多智能体框架中。这项研究已被人工智能顶级会议 AAAI 2026 接收,并且被选为Oral。
让我们一起来看看这篇工作的具体内容。
- 论文标题:StyleTailor : Towards Personalized Fashion Styling via Hierarchical Negative Feedback
- 作者团队:Hongbo Ma, Fei Shen, Hongbin Xu, Xiaoce Wang, Gang Xu, Jinkai Zheng, Liangqiong Qu, Ming Li
- 所属机构:人工智能与数字经济广东省属实验室(深圳),清华大学,新加坡国立大学,Bytedance Seed,杭州电子科技大学,香港大学
- 论文地址:https://arxiv.org/abs/2508.06555
- 项目主页:https://ma-hongbo.github.io/StyleTailor.github.io/
- 代码仓库:https://github.com/ma-hongbo/StyleTailor
智能设计的困境:盲目堆砌与流程割裂
不知道大家有没有发现,现在的智能体虽然在写代码、做图表甚至科研辅助上表现得"无所不能",但一旦涉及到与我们每个人生活息息相关的"个性化穿搭"时,就显得不那么"智能"。对于现有的智能体而言,仅给出意见或是仅提供一堆衣服图片都很容易,但提供从设计、选品、上身试穿到评估反馈这样真实流畅的一体化造型体验是很困难的。
这背后的一个关键痛点是:现有的多模态大模型在处理时尚这种需要极高精细度的任务时,推理能力和稳定性还远远不够。它们经常出现"幻觉",推荐出来的东西要么风格不搭,要么根本买不到。更糟糕的是,现有的框架缺乏有效的"纠错机制"。当模型生成的结果不满意时,它们往往只是简单粗暴地随机重试,而不是像真正的人类造型师那样,听取用户的"负面反馈"并进行针对性的调整。
这种缺乏迭代优化和用户对齐的能力,严重限制了智能时尚系统的实用性。为了打破这一僵局,研究团队提出了 StyleTailor,这是首个将个性化设计、购物推荐、虚拟试穿和系统评估无缝融合的多智能体协同框架。
方法概述
StyleTailor 的核心在于两部分协同工作的 AI 智能体------设计师 (Designer) 和 顾问 (Consultant)。它们共同打造了一套丝滑的个性化时尚造型工作流。"设计师"接受一张全身参考照()和自然语言描述的风格()为输入,并能够检索出一系列服装图片(),和它们的购买连接()。顾问接受选好的服装图片和原始照片为输入,利用图像编辑技术,直接生成一张虚拟试穿照。
设计师(Designer)的工作原理
解码过程
将用户的模糊需求视为一种待解码的抽象信号,利用视觉语言模型(VLM)将其转化为结构化的服装属性描述。这一过程不仅仅是简单的关键词提取,更是一个引入了"负面选择集"的迭代生成过程------即在生成新的设计方案时,会显式地参考并规避之前被拒绝的方案,确保每一轮的风格转译都比上一轮更精准、更符合用户意图。
选品过程
选品过程被看作是一个"搜索-校验-反思"的闭环系统。该过程不仅利用搜索引擎获取候选商品,更引入了基于 VQAScore 的单品级(Item-level)负反馈机制。
系统会计算检索图像与文本描述的视觉语义一致性,一旦得分低于阈值,VLM 会立即将视觉上的差异转化为负面提示词,指导搜索引擎进行下一轮更精确的检索,直到找到满意的单品。
专家序列
这个结构帮助设计从局部最优迈向全局一致。因为即便单件衣服都很完美,组合在一起也可能并不协调,所以系统引入了套装级(Outfit-level)负反馈机制,通过计算所有单品评分的几何平均值来评估整体搭配的协调性。如果整套方案未达标,系统将激活下一个"专家"接手,并将失败的搭配作为"反面教材"输入给新专家。
顾问(Consultant)的工作原理
渐进式生成视角
将复杂的全身试穿任务解构为一系列有序的图像编辑子过程。系统采用了一种基于空间物理属性的排序策略,按照服装覆盖面积从大到小的顺序逐层合成,有效降低了不同服饰间的视觉干扰,确保了最终生成的试穿图像在空间结构上的合理性。
视觉-语义闭环修正
将试穿生成视为一个由试穿级(Try-on-level)负反馈驱动的优化问题。这一过程引入了严格的质量检查机制,利用 CLIPScore 进行基于特征匹配的初筛,;若结果未达标,VLM 便将这些缺陷转化为明确的负面提示词。这迫使模型在迭代中不断"纠错",直至输出高保真、高真实感的试穿效果。
评价指标设计
- 风格一致性 (Style Consistency):系统先用 VLM 提取用户原图中的身体特征(不含衣物),将其与用户的风格偏好描述合并,再利用 VQAScore 计算生成图像与这一综合描述的语义对齐度。
- 视觉质量 (Visual Quality):系统采用 IQAScore 对生成图像的视觉保真度进行量化评估。
- 面部相似度 (Face Similarity):系统利用预训练的 InsightFace 模型,分别提取用户原图与试穿生成图的面部特征并计算余弦相似度,进而保证面部的相似度。
- VLM 艺术家 (VLM Artist):系统引入了一个基于 VLM 的评估智能体,模拟人类时尚专家的视角,从设计美学、版型合身度、搭配连贯性和整体氛围感四个维度,对生成结果进行 1-10 分的打分与专业点评。
实验结果分析
实验数据显示,StyleTailor 在所有关键指标上均大幅领先基线模型,展现了其对复杂穿搭指令的精准掌控。消融实验进一步证实了分层设计的必要性:单品与套装级的反馈奠定了风格基础,而试穿级的反馈则提高了生成的真实感与面部相似性,三者缺一不可。
评分直观地描绘了模型的优化过程,随着负反馈迭代的推进,无论是单品检索的精准度、套装搭配的协调性,还是最终试穿的还原度,各项指标均呈稳步上升态势。这有力证明了这套负反馈机制的有效性。
总结:迈向未来的智能时尚专家
StyleTailor 作为首个将时尚设计、购物推荐与虚拟试穿无缝融合的智能体框架,成功打破了多模态任务间的壁垒。
其核心在于引入了创新的多层负反馈机制,赋予了系统类似于人类的"反思"与迭代优化能力,显著增强了推理深度与生成质量。
配合为此量身定制的综合评估体系,StyleTailor 不仅在实验中确立了新的性能基准,更展现了在真实世界应用中的广阔潜力,有望引领未来以用户为中心的智能时尚系统迈向新的高度。
....
#基于傅里叶解耦的联合暗光增强和去模糊算法
本文介绍论文 Fourier-based Decoupling Network for Joint Low-Light Image Enhancement and Deblurring ,已被图像处理领域的国际顶级期刊 IEEE Transactions on Image Processing (TIP) 收录 。该研究由中山大学智能工程学院完成。论文第一作者为中山大学博士研究生涂陆炜,通讯作者为其导师金枝教授。
夜间手持拍摄的图像常常同时存在光照不足和运动模糊两种退化问题。先前的方法在空间域中独立处理这两种退化,但由于暗光和模糊在空间域中高度耦合,这些方法难以有效解耦并恢复出清晰的图像细节。
针对这一挑战,我们从频域的角度分析图像的退化表形式,并观察到一个关键现象:在傅里叶域中,暗光和模糊两种退化可以被独立地表示为图像的振幅 (amplitude) 和相位 (phase) 。基于此,我们深入分析了图像退化的物理过程,研究了暗光退化和模糊退化在振幅和相位上的表达形式,并提出了傅里叶解耦网络 (FDN),能够端到端实现联合暗光增强和去模糊,还可以实现用户自定义亮度恢复。大量实验证明,FDN在合成与真实世界数据集上均取得了当前最佳的性能,尤其在恢复图像边缘细节方面表现出良好的效果。
- 论文标题:Fourier-based Decoupling Network for Joint Low-Light Image Enhancement and Deblurring
- 论文作者:Luwei Tu1, Jiawei Wu1, Chenxi Wang1, Deyu Meng3,4, Zhi Jin1,2*
- 作者机构:中山大学1,广东省消防科学与智能应急技术实验室2,西安交通大学3,澳门科技大学4
- 论文链接:https://ieeexplore.ieee.org/document/11105001
- 项目主页:https://github.com/Jabruson/FDN-TIP2025
Abstract
本文提出了一种基于傅里叶域解耦的联合暗光增强和去模糊算法FDN。FDN从不同退化的物理过程出发,有效解耦并复原了暗光退化和模糊退化,能够恢复良好的图像边缘和细节。
本文的贡献与创新点如下:
- 基于低光和模糊在傅里叶域振幅和相位上的不同物理特性来设计网络 。我们深入探究了相位相关性与模糊信息、振幅调制与暗光退化信息之间的关系,为联合图像复原任务提供了高效的解耦方法。
- 我们设计了一种自注意力机制来提取不同类型的退化表征,并设计了一个高效的前馈网络 (FFN) 来自适应地学习幅度和相位的频率特征。此外,我们还引入了一种基于傅里叶变换的交叉注意力机制,为频率学习提供关键的先验知识。
- 实验结果表明,与当前的 SOTA 方法相比,我们的方法仅用 16.7% 的参数就达到了 SOTA 性能。尤其是在边缘恢复方面,我们的复原结果表现出了良好的性能。
Method
Motivation
我们的核心观察是,图像的结构信息(如边缘)主要由相位决定,而亮度、对比度等统计信息则主要由振幅决定。如图1所示,我们将一张正常光照的清晰图像(a)与一张暗光模糊图像(h)的相位进行交换,可以分别得到一张正常光照的模糊图像(d)和一张暗光的清晰图像(k)。这直观地证明了在傅里叶域中对暗光(振幅分量)和模糊(相位分量)进行解耦的可行性。我们还展示了仅包含相位分量的结果(f)和(m)以及仅包含振幅分量的结果(g)和(h),进一步说明相位分量能够充分表征图像结构信息这一点。
我们进一步从物理过程对这种解耦特性进行了理论推导:
- 振幅中的亮度信息:对于一幅灰度图像对于一副灰度图像,其傅里叶振幅的直流分量等于图像所有像素的总和,因此该直流分量可以被视为图像的全局亮度。然而,如果仅仅通过增加该直流分量来提升亮度会由于平等地增加每一个像素点而导致颜色失真。但如果我们同时缩放整个振幅分量而不是仅仅改变直流分量,我们就可以在保持相位分量的同时调整全局亮度并保持色彩的保真度。
- 相位中的模糊信息:由于图像结构信息主要由傅里叶相位表示,因此模糊退化主要表现为傅里叶相位分量的失真。从图像模糊的物理过程来看,图像模糊可以建模为一系列连续帧的平均:
结合傅里叶移位定理,我们可以推导出两个模糊程度不同,但是初始状态相同的图像之间的相位相关性:
该公式从数学上描述了两个模糊程度不同的图像之间的相位相关与模糊程度呈正比关系。这一理论指导我们设计了基于相位相关的注意力机制来专门提取和处理模糊信息。
Network Architecture
基于上述理论分析,我们设计了FDN,如图2所示,其整体架构由两个核心模块构成:多尺度振幅恢复模块 (MAR) 和 傅里叶解耦变换器 (FDformer) 。
MAR负责粗略的振幅恢复 。MAR生成的粗略振幅作为亮度先验,使FDformer能够专注于精细细节的恢复 。此外,MAR允许通过缩放因子来实现用户自定义的亮度恢复 。
FDformer是网络的核心,采用非对称的编码器-解码器架构,包含三个关键组件(如图3):傅里叶解耦自注意力 (FDSA), 傅里叶解耦前馈网络 (FDFFN), 和 傅里叶交叉注意力前馈网络 (FCAFFN)。
傅里叶解耦自注意力(FDSA) 。结合上述对不同退化信息在相位以及振幅上的表征分析,我们设计了FDSA以提取混合退化情景中的不同退化信息,FDSA旨在从相位中提取模糊特征,从振幅中提取暗光特征 。我们引入了三种注意力机制:
分别用于捕捉模糊退化信息、暗光退化信息以及混合退化信息。
傅里叶解耦前馈网络 (FDFFN) 。FDFFN包含并行的频率分支和空间分支 。频率分支利用可学习的滤波器,分别对特征的振幅和相位进行自适应的频域选择与调整 。空间分支用于学习局部信息以补充频域信息的表达。
**傅里叶交叉注意力前馈网络 (FCAFFN)。**FCAFFN负责将MAR提供的粗恢复振幅先验,以及输入图像的多尺度相位特征有效地融入到FDformer中 ,以此指导FDformer的亮度恢复以及结构信息恢复。FCAFFN同时包含了傅里叶交叉注意力机制以分别融合振幅和相位信息以及空间调制机制以辅助信息融合。
Experiments
Results on joint low-light image enhancement and deblurring
LOL-Blur数据集。 我们在公开的LOL-Blur 数据集上进行了广泛的定量评估,这是一个专用于联合暗光增强和去模糊的数据集 。如表1所示,我们不仅比较了专门由于联合暗光增强和去模糊的方法,我们还对比了专门用于暗光增强、去模糊以及通用的图像复原方法。FDN在关键指标(PSNR, SSIM, LPIPS, FID)上均超越了现有的各类方法 。值得注意的是,相较于SOTA方法VQCNIR,我们的FDN在性能更优的同时,参数量减少了83.3% 。
为了更全面的展示我们的方法的性能,我们进行了定性的评估。如图4的视觉对比所示,大多数方法在处理严重模糊的区域时效果不佳,或产生伪影。相比之下,我们的方法能够显著地恢复出更清晰的边缘和更精细的纹理细节(例如图中公交车的车牌和车身细节),证明了傅里叶解耦策略的优越性 。
Real-LOL-Blur数据集。为了验证模型在真实世界场景中的泛化能力,我们将在LOL-Blur上训练的模型在没有真实标签的Real-LOL-Blur数据集上进行了测试, 如表2所示。
此外,为了证明FDN的优越性,我们还将FDN与"先增强后去模糊"或"先去模糊后增强"的简单级联策略进行了比较 ,如表3所示。
在多个常用的无参考图像质量评价指标(NIQE, BRISQUE, PI)上,FDN的表现全面优于其他所有方法 。视觉对比也显示(图5和图6),在真实的夜景照片中,FDN能够恢复出最清晰的边缘和最自然的颜色,而其他方法往往难以处理严重的模糊或引入伪影。
Results of luminance control strategy
FDN还提供了一个自定义输出亮度的功能 。通过调整输入参数 (期望亮度与原始亮度的比值),用户可以轻松控制生成图像的明暗程度,以满足个性化的视觉偏好 。如图7所示,不同的自定义值会改变振幅,从而调整亮度,但相位基本保持稳定,保证了图像结构不被破坏 。图(b)的散点图进一步验证了我们亮度调节策略的精确性和可靠性 。
Ablation studies
为了验证我们所提出各个模块的有效性,我们进行了详细的消融研究(如表4)。实验结果表明,对于FDSAA,与空间域注意力(MDTA)或其他频域注意力(FSAS)相比,我们提出的FDSA由于能够解耦退化信息,性能提升显著 。而移除FDFFN中的振幅或相位滤波器或者替换FDFFN为其他常用的前馈网络均会导致性能明显下降,证明了对不同频率成分进行精细调整的必要性 。此外,实验结果表明,FCAFFN中的傅里叶交叉注意力机制以及空间调制策略都是同样必要的。
实验室介绍
中山大学智能工程学院的前沿视觉实验室
由学院金枝教授建设并维护,实验室目前聚焦在图像/视频质量增强、视频编解码、3D 重建和无接触人体生命体征监测等领域的研究。旨在优化从视频图像的采集、传输到增强以及服务后端应用的完整周期。
....
#SingRef6D
深度预测提升 14.41%!SingRef6D告诉你深度感知 LoFTR 有多强?
SingRef6D 仅用一张参考 RGB 图完成 6D 姿态估计:Token-Scaler 微调 DPAv2 使深度预测 δ₁.₀₅ 提升 14.4%,深度感知 LoFTR 匹配再把平均召回率拉高 6.1%,无需 CAD/多视图/NeRF,在 REAL275 等三数据集全面领先。
这篇文章提出了 SingRef6D,一种仅需单张 RGB 图像作为参考的单目新型物体 6D 姿态估计方法,解决了现有方法依赖深度传感器、多视图图像采集或训练视图合成模型和神经场等问题,能在资源受限场景下保持鲁棒性。该框架有两大关键创新:
一是在 Depth - Anything v2 基础上提出基于令牌缩放器的微调机制和新的优化损失,提升其在挑战性表面的深度预测能力,在 REAL275 深度预测上比 Depth - Anything v2(微调头部)提高了 14.41%(在 指标上);
二是引入深度感知匹配过程,将 RGB 和深度线索融合到统一的潜在空间,使系统能处理具有挑战性材料和光照条件下的匹配。
在 REAL275、ClearPose 和 Toyota - Light 数据集上的评估表明,该方法超过了现有技术,平均召回率提高了 6.1%。此外,文章还通过大量实验验证了方法在深度预测、姿态估计、跨域泛化等方面的有效性和优越性,以及在处理遮挡、反光物体和大视角变化等复杂场景时的鲁棒性。
下面一起来阅读一下这项工作~
论文信息
- 论文题目:SingRef6D: Monocular Novel Object Pose Estimation with a Single RGB Reference
- 作者:Jiahui Wang、Haiyue Zhu、Haoren Guo 等
- 作者机构:College of Design and Engineering, National University of Singapore;SIMTech, Agency for Science, Technology and Research (A*STAR)
- 论文链接 :https://arxiv.org/pdf/2509.21927
- 项目页面: https://plusgrey.github.io/singref6d/
摘要
近期的 6D 位姿估计方法表现出了显著的性能,但仍面临一些实际限制。例如,许多方法严重依赖传感器深度,在处理具有挑战性的表面条件(如透明或高反射材料)时可能会失效。同时,基于 RGB 的解决方案由于缺乏几何信息,在低光照和无纹理场景中的匹配性能不够稳健。
受这些问题的启发,我们提出了 SingRef6D,这是一个轻量级的流程,只需要一张 RGB 图像作为参考,无需昂贵的深度传感器、多视图图像采集,也无需训练视图合成模型和神经场。这使得 SingRef6D 即使在深度或密集模板不可用的资源受限环境中,也能保持稳健并具备良好的性能。
我们的框架包含两项关键创新。首先,我们在 Depth - Anything v2 的基础上,提出了一种基于令牌缩放器的微调机制,并采用了一种新颖的优化损失,以增强其即使在处理具有挑战性的表面时也能准确预测深度的能力。我们的结果显示,与 Depth - Anything v2(带微调头)相比,在 REAL275 深度预测上(在 指标下)有 14.41% 的提升。其次,得益于深度信息的可用性,我们引入了一种深度感知匹配过程,该过程能有效地将空间关系整合到 LoFTR 中,使我们的系统能够处理具有挑战性的材料和光照条件下的匹配问题。
在 REAL275、ClearPose 和 Toyota - Light 数据集上进行的位姿估计评估表明,我们的方法超越了现有最先进的方法,平均召回率提高了 6.1%。

01 效果展示
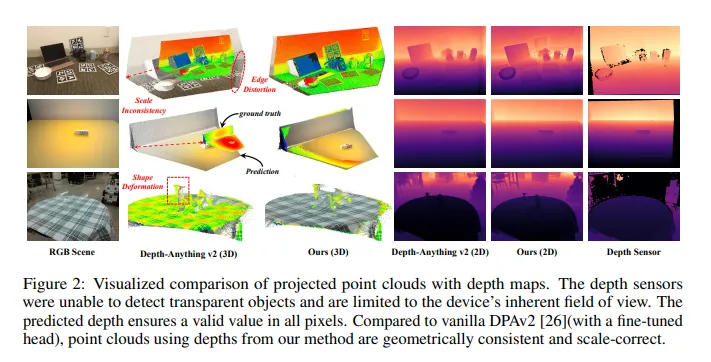
图4:本文方法与其他度量深度估计模型(SPID-peth、UniDepth、ScaleDepth、Metric3D)的深度预测可视化对比。我们的结果比其他基线更清晰,保留了全部有效像素,而真值反而缺失了关键数值。

图5:在三个数据集上6D姿态预测的可视化对比:红色点云及3D框为预测结果,绿色为真值。与基线方法相比,我们估计的姿态旋转误差更小、平移偏移更轻微。

02 主要贡献
文章的主要贡献总结如下:
- 提出了 SingRef6D,这是一种新颖的单目 6D 姿态估计流程,在严格的最小参考设置下,仅需单张参考 RGB 图像,无需依赖 CAD 模型、多视图采集或新视图合成。
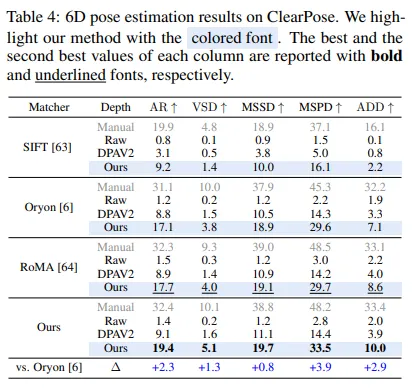
- 为 DPAv2 开发了一种基于令牌缩放器的微调方法,使度量深度估计能够处理具有挑战性的表面条件。在 ClearPose 数据集上,透明物体的精度从 31.23% 提高到了 54.30%。
- 在 LoFTR 的基础上提出了深度感知匹配方法,在三个姿态估计基准测试中,平均召回率提高了 6.1%。
03 基本原理是啥?
3.1 单参考 RGB 图像的 6D 姿态估计方法提出
受人类视觉系统启发,提出 SingRef6D,该方法仅需单张参考 RGB 图像,无需显式 3D 模型、精确深度传感或任何形式的新颖视图合成,就能进行 6D 姿态估计,且具有鲁棒性和通用性。
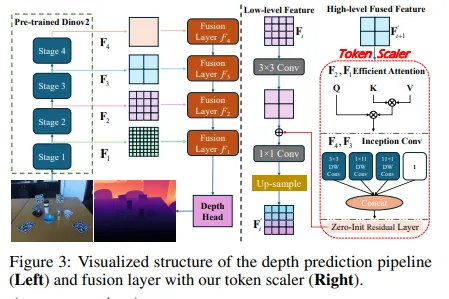
3.2 基于 Token - Scaler 的深度预测改进
- 针对 Depth-Anything v2(DPAv2),开发基于 Token-Scaler 的微调方法。引入新颖的 Token Scaler 自适应地对每个层级的特征进行重新加权,然后与上一层级的特征融合。数学上,对于特征提取的主干网络,设 表示第 阶段的特征( 分别对应低、中、高和全局级特征),通过 和 进行特征融合。
- 采用新的损失方案,包括全局损失和局部损失。全局损失 ,其中 为 Scale-Shift Invariant 损失, 为梯度匹配项,BerHu 损失用于更好地惩罚大残差;局部损失 。 为尺度对齐损失,量化物体内真实深度和预测深度的差异; 为边缘强调损失,约束深度图边缘的重建以减少3D失真; 为法向一致性损失,确保预测深度图中表面法向的方向一致性,维持表面连贯性以进行更准确的几何重建。
3.3 深度感知匹配与姿态求解
- 提出免微调的深度感知匹配模块,将度量深度与 RGB 输入有效结合以增强空间上下文理解。扩展 LoFTR,将相应的深度图作为额外输入,在潜空间中融合深度和 RGB 特征表示。具体而言,对于两张 RGB 图像 、 和对应的深度图 、 ,通过 提取特征,其中 enc(.)为预训练编码器,输入深度图进行归一化以保持一致尺度。
- 首先对粗特征通过 Transformer 解码器计算相似度再用双 softmax 得到匹配概率得到粗匹配对应关系 。然后基于粗匹配从细特征图中提取局部窗口,计算相关性得到细匹配 。
- 利用这些对应关系,通过确定性点云配准方法(如 PointDSC)或刚性变换求解算法,根据 计算查询对象的 6D 姿态。
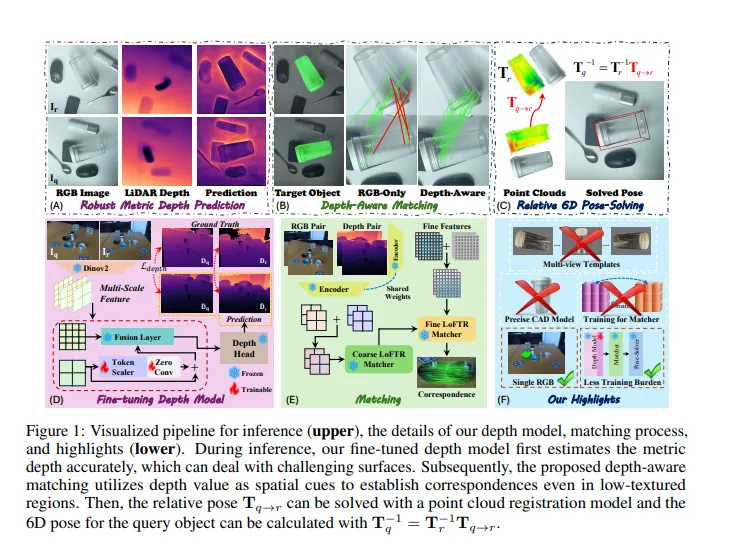
04 实验结果
文章通过多组实验验证了 SingRef6D 在 6D 位姿估计和深度预测方面的有效性和优越性,具体实验结果如下:
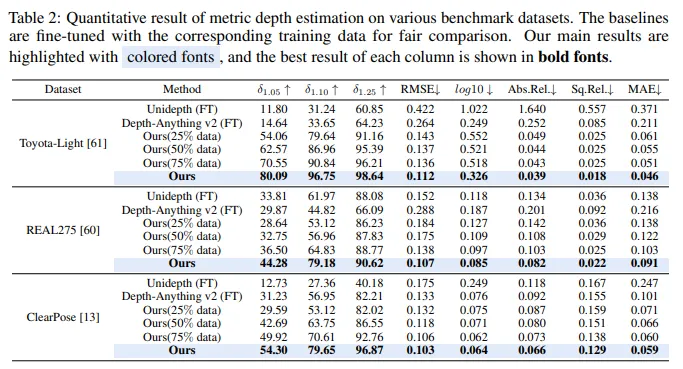
4.1 深度预测实验结果
- 多数据集表现:在 Toyota-Light、REAL275 和 ClearPose 数据集上,使用全部微调数据时,在 指标上分别比 DPAv2 提升 、 和 。更多训练数据可提升场景尺度理解,从而提高性能。
- 跨域深度微调:在跨域评估中,将深度估计模型在 REAL275 数据集上微调后,直接在 ClearPose 和 Toyota-Light 数据集上评估,虽性能有下降,但仍优于 DPA v2和 UniDepth 等微调基线。这得益于 token scaler 能自适应调节中间特征,以及损失函数对模型进行一致几何理解的正则化。
4.2 6D 位姿估计实验结果
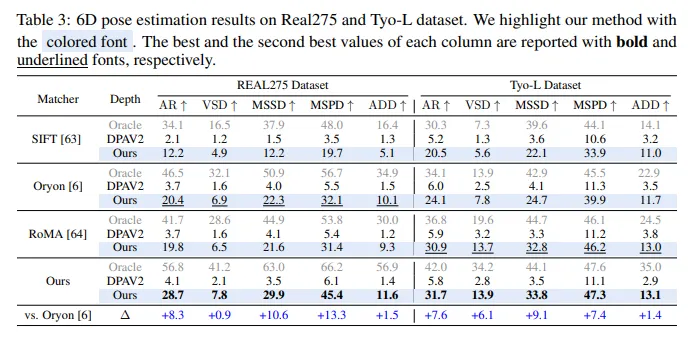
- 多基准测试表现:在 REAL275、Toyota - Light 和 ClearPose 三个基准测试中,与 SIFT 和 Oryon 相比,使用真实深度时平均 AR 分别提升 +15.3% 和 +6.5%,使用预测深度时分别提升 +12.6% 和 +6.1%。深度感知匹配能更好利用空间信息,相比 DPAv2(带微调头),与 Oryon 匹配时精度提升 +14.4%,与基于 LoFTR 的匹配方法匹配时提升 +20.3%。
- 额外位姿基准测试:在 LM - O 和 YCB - V 基准测试中,虽重度遮挡会使性能下降,但在单 RGB 参考设置下,仍显著优于基线。这得益于受人类视觉启发的机制,能在匹配策略中结合空间上下文,且在粗粒度和细粒度匹配阶段保持空间一致性。
- 与其他方法对比
- 与 FS6D 相比,在所选评估指标上表现更优;Any - 6D 使用标注深度时结果稍好,但依赖深度输入质量,使用 DPAv2 预测深度时性能大幅下降,而本文方法强调局部像素对齐,在 VSD 上召回率更高。
- 与 DVMNet 和 3DAHV 相比,虽角度误差略高,但在 AR 和 ADD 上表现更优,能进行更准确的平移估计,且适用于跨场景 6D 位姿估计,无需密集位姿标签。
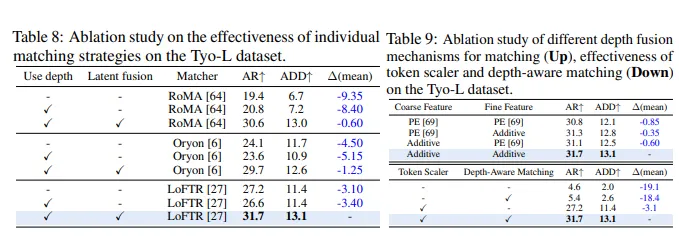
4.3 消融实验结果
- 损失函数有效性: 去除 、、 和 三个损失会导致 性能大幅下降 ,证明复合损失函数对准确几何估计的重要性。
- 微调范式效果: 仅微调 DPAv2 深度头效果不佳,将 token scaler 集成到 DPAv2中可显著提升性能,综合考虑训练负担和性能提升,选择冻结深度头。
- 匹配策略有效性: 深度感知匹配通过潜在融合使 AR 提升 ,简单加法融合在深度感知匹配中优于 PE 方法,且计算效率更高。无鲁棒深度预测会使投影 3D 点云效果不佳,导致性能下降。
4.4 其他实验结果
- 与注册方法对比:与 ICP、LePard 和 EYOC 等注册方法相比,本文方法在单 RGB 跨场景参考设置下表现更优。ICP 对初始化和噪声敏感,学习型注册方法因参考样本单一和点云不完整而性能不佳,而本文方法通过深度感知匹配建立初始对应关系,减少对重建点云完整性的依赖。
- 反光物体基准测试:在 HouseCat6D 基准测试中,针对反光物体,本文方法优于基线,能获得更高的深度质量。这是因为基线方法依赖 RGB 信息,而本文方法采用粗到细的匹配策略,能有效利用深度线索。
- 查询 - 参考视角差距影响:视角差异增大时,位姿估计性能下降,X 轴旋转影响更大,但本文方法在极端条件下性能下降较小(65%),而 Oryon 和 SIFT 等基线性能下降超 90%。这得益于模型能利用空间一致性,通过 token scaler 调整空间表示,以及损失函数的强几何约束。
05 总结 & 未来工作
5.1 总结
本文提出了一种名为 SingRef6D 的单目 6D 姿态估计方法,该方法仅需一张 RGB 参考图像,避免了对 CAD 模型、多视图图像采集或新颖视图合成的依赖。具体内容如下:
- 创新点
- 深度预测优化:提出基于令牌缩放器(token-scaler)的微调机制,结合新颖的优化损失,改进了 Depth-Anything v2,使其在预测具有挑战性表面(如透明、高反射材料)的准确深度方面表现出色。在 REAL275 数据集的深度预测上,与 Depth-Anything v2 相比,在 指标上有 的提升。
- 深度感知匹配:引入深度感知匹配过程,将深度信息与 RGB 信息有效融合到 LoFTR 的潜在空间中,增强了系统处理具有挑战性材料和光照条件下的匹配能力。在 REAL275、ClearPose 和 Toyota - Light 数据集上的姿态估计评估中,平均召回率提高了 6.1%。
- 方法优势
- 轻量级与高效性:无需昂贵的深度传感器、多视图图像采集或训练视图合成模型和神经场,在资源受限的环境中仍能保持鲁棒性和有效性。
- 泛化能力强:不依赖合成视图或神经场,在不同环境中具有显著的泛化能力。
- 局限性
- 该方法使用对象掩码来定位目标并约束对应匹配,因此其适用性仅限于有可用分割掩码的场景。
- 其泛化能力受限于 Depth - Anything v2 和预训练的匹配网络(如 LoFTR),在极暗条件下,RGB 相机捕捉到的有意义信息较少,可能会导致失败。
5.2 未来展望
- 模型微调拓展:令牌缩放器可用于微调其他基于 ViT 的模型。
- 应用增强:深度感知匹配有可能通过为多视图图像提供几何先验来增强场景重建等应用。
- 集成改进:集成视觉语言模型(VLMs)进行对象定位,可提高系统的可访问性和效率,为更广泛的用户提供更流畅的体验。
本文仅做学术分享,如有侵权,请联系删文。
....