目录
[第二阶段:深度学习时代 - Two-Stage检测器](#第二阶段:深度学习时代 - Two-Stage检测器)
[Fast R-CNN (2015)](#Fast R-CNN (2015))
[Faster R-CNN (2015)](#Faster R-CNN (2015))
[三、Two-Stage 方法的固有优缺点](#三、Two-Stage 方法的固有优缺点)
目标检测的核心评价指标
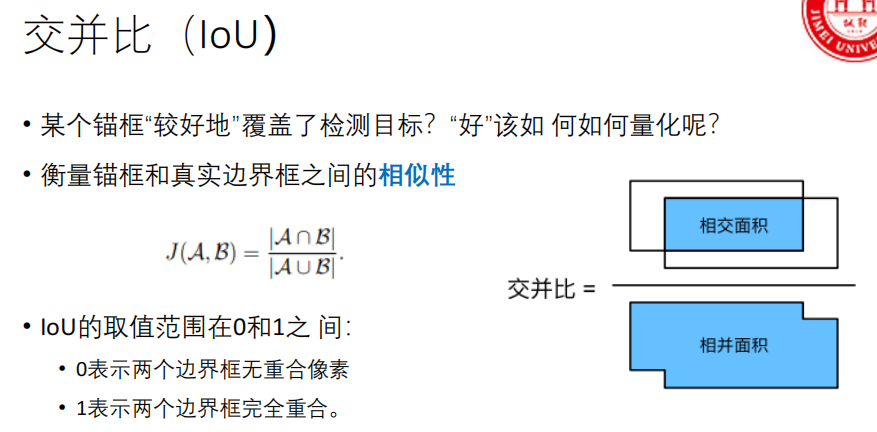
1、交并比(IoU)
衡量预测框(Prediction Box) 和真实框(Ground Truth Box) 的重合程度。
- 意义 :IoU 越接近1,说明预测框定位越准。通常用**阈值(如0.5)**来判断一个预测框是否正确匹配了一个真实目标(True Positive)。
2. 平均精度均值(mAP )
衡量模型在所有类别 上的综合检测精度,是最核心的指标。
- 查准率(Precision) :
预测对的目标数 / 所有预测出的目标数。- 查全率(Recall) :
预测对的目标数 / 图中所有真实目标数。
3. 速度指标:FPS模型每秒能处理多少张图片。

目标检测算法发展史
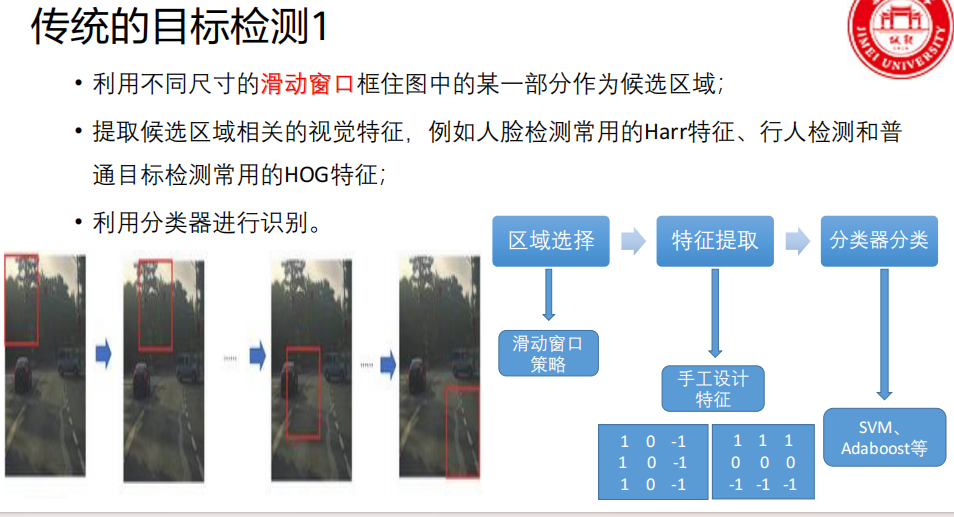
第一阶段:传统目标检测
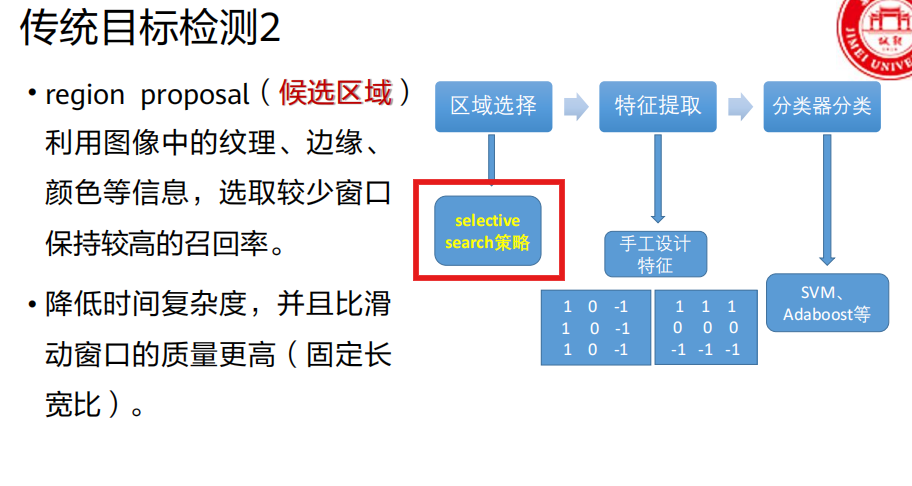
第二阶段:深度学习时代 - Two-Stage检测器
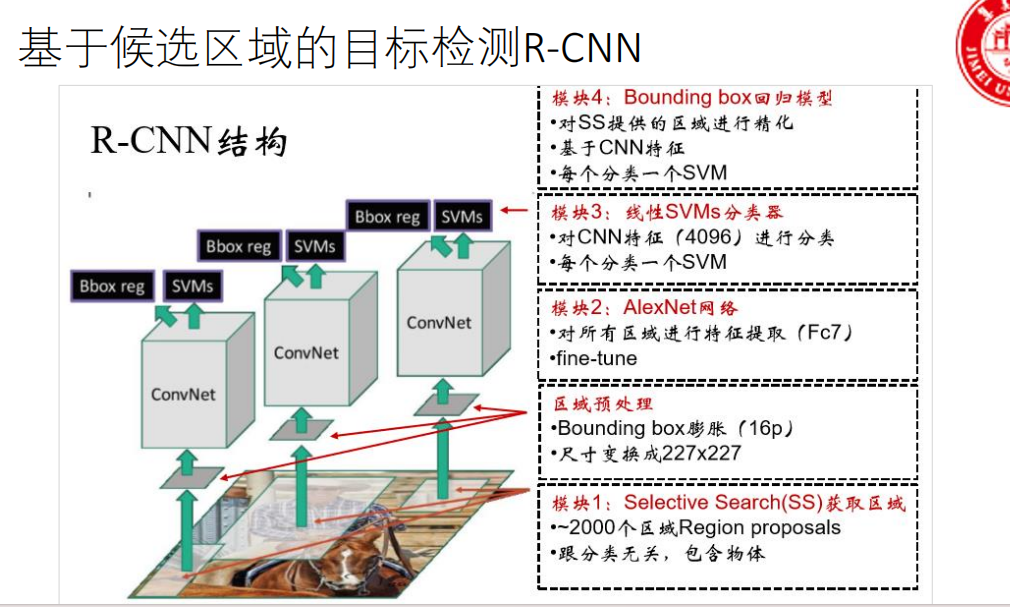
R-CNN (2013)
步骤一:区域提名(找出"可能"有东西的地方)
操作 :使用一种叫做 "选择性搜索(Selective Search)" 的传统图像算法,在输入图片上生成大约 2000个 候选区域(Region Proposals)。
理解:这些区域是算法"猜"的物体可能位置,跟物体具体是什么类别无关。目的是把需要仔细检测的范围,从整张图缩小到这几千个框里。
步骤二:区域归一化(把不同大小的框变成一样大)
操作 :将上一步得到的2000个形状、大小各异的候选框,全部暴力缩放(Warp) 到固定尺寸(例如 227像素 x 227像素)。
图片被拉伸/压缩,可能会导致变形
原因:后面用来提特征的CNN网络(如AlexNet)要求输入图片尺寸固定。
步骤三:特征提取(用CNN抽取"高级"特征)
操作 :将每一个缩放后的227x227区域,单独输入一个预先在大型图像分类数据集(如ImageNet)上训练好的CNN网络。
输出 :取CNN网络的某一层(通常是最后一个全连接层)的输出,得到一个固定长度的特征向量(4096个数字)。这个向量就是这个区域的"深度特征描述"。
关键问题(也是主要缺点) :一张图片的2000个 候选区域,每个都要独立地、完整地 通过一次CNN进行前向传播,存在海量的重复计算。
结果:2000 , 4096
步骤四:分类(判断框里是什么)
操作 :不是用CNN直接分类。而是为每一个待检测的物体类别 (比如要检测20类物体,就训练20个),单独训练一个二分类的支持向量机(SVM)。
过程:用步骤三得到的4096维特征向量,输入这20个SVM分类器。
结果:得到每个区域对于各个类别的得分。 2000,20
步骤五:边框回归(把框调得更准)
操作 :同样为每个类别训练一个线性回归模型。
过程 :对于被分类为某个类别(比如"猫")的区域,用对应的回归模型,根据它的4096维特征,预测一个位置和尺寸的微调量(Δx, Δy, Δw, Δh),对候选框进行精细调整,让它更贴合真实的猫。
步骤六:后处理(去除重复的框)
操作 :经过以上步骤,同一只猫可能被好几个重叠的、得分不同的框检测到。这时使用 非极大值抑制(NMS)。
规则 :只保留得分最高 的那个框,然后剔除掉所有和这个框重叠面积很大(IoU超过某个阈值,如0.3)的其他框。最终得到简洁的检测结果。
【RNN总结】
使用卷积神经网络(CNN)来提取图像特征,代替传统手工特征,以此提升检测精度。具体做法是先用"选择性搜索"算法在图上找约2000个可能包含物体的候选框,然后把每个框缩放成固定大小,分别送进CNN网络提取出一个固定长度的特征向量,最后用多个SVM分类器判断框内物体类别,并用回归器微调框的位置。
R-CNN 主要缺点:
速度极慢:一张图的2000个候选框,每个都要独立过一遍CNN,计算大量重复。
训练复杂:需要分多个阶段训练(CNN微调、SVM训练、回归器训练),过程繁琐且不能联合优化。
变形失真:候选框被强制缩放到统一尺寸,会造成图像拉伸或压缩,影响特征质量。


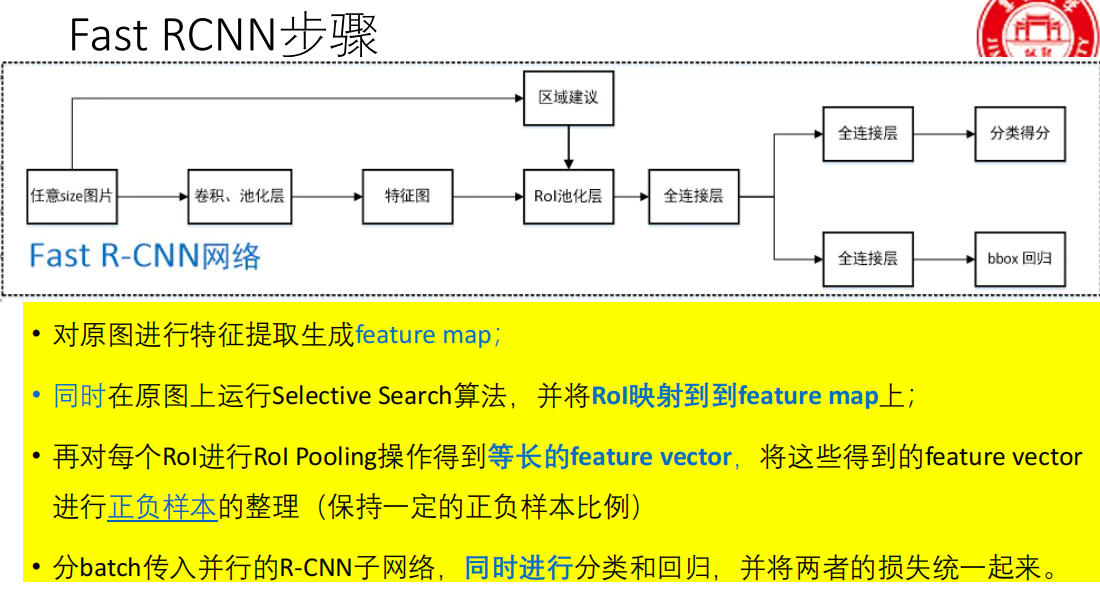
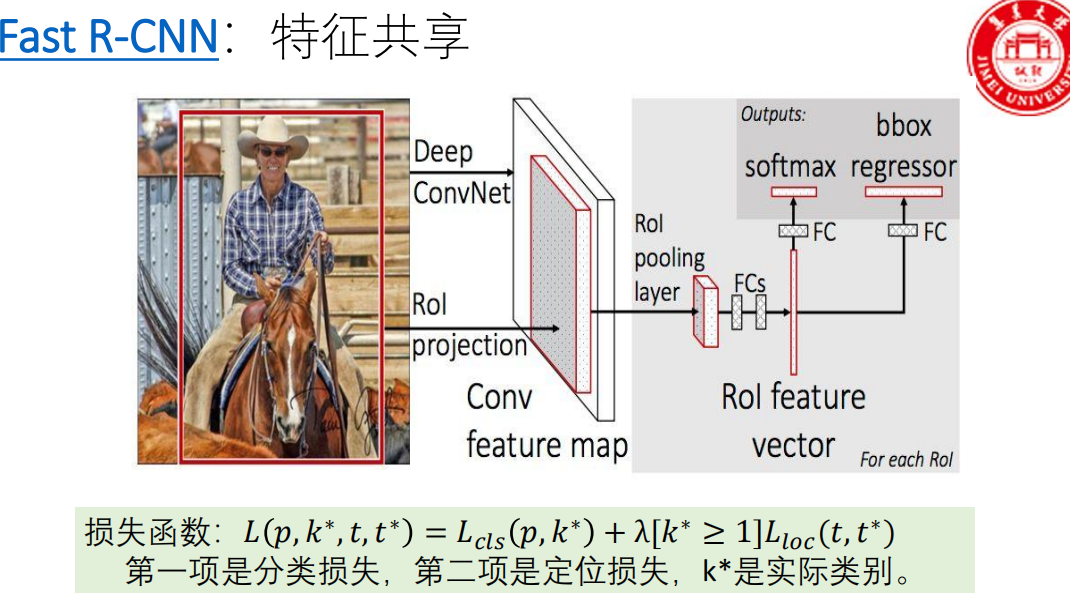
Fast R-CNN (2015)
Fast R-CNN的核心思想是:整张图片只通过CNN一次,得到一张共享的特征图(Feature Map),然后用一种叫做RoI Pooling的技术,从这个共享特征图上为每个候选区域提取出固定大小的特征,最后用一个多任务损失函数实现端到端训练。
- 关键词:特征共享、RoI Pooling、多任务损失、(训练过程)端到端。
步骤一:特征提取(一次搞定)
操作 :将整张输入图片送入一个CNN(如VGG16)。
输出 :得到整张图片对应的共享特征图(Feature Map)。
关键改进 :这是质的飞跃! 不再像R-CNN那样对2000个区域分别计算CNN,而是只算一次。特征图上的每个点都对应原图一个区域的特征。
步骤二:区域提名(仍是Selective Search)
操作 :和R-CNN一样,在原始输入图片上运行Selective Search算法,生成约2000个候选区域(RoI, Region of Interest)。
注意:此时还没有用到特征图。
步骤三:RoI投影与池化
这是Fast R-CNN最核心的创新点,解决了候选框大小不一 和特征图共享之间的矛盾。
投影 :将步骤二在原图 上得到的每个RoI的坐标,根据CNN下采样的比例(步幅,stride),精确映射到步骤一得到的共享特征图上。这样,每个RoI在特征图上就对应一小块区域。
RoI Pooling(区域兴趣池化):
输入 :特征图上的一块任意大小的矩形区域(即一个RoI)。
操作 :将这个区域均匀划分 成一个固定大小的网格(例如 7x7 的格子)。然后,在每个小格子内进行最大池化(Max Pooling)。
输出 :一个 固定大小(7x7) 的特征图。
目的 :无论原始的RoI多大、多小,经过RoI Pooling后,都变成同样尺寸的特征,从而可以被后续的全连接层处理。这比R-CNN的暴力缩放(Warp)更合理,保留了空间结构信息。
步骤四:分类与回归(一个网络,两个输出头)
操作:将RoI Pooling输出的固定大小(如7x7)的特征,展平后送入几个全连接层。
两个并行输出层:
分类层(Softmax) :输出该RoI属于 (N+1)个类别 的概率分布(N个目标类 + 1个背景类)。这里用Softmax取代了R-CNN中大量的SVM分类器,结构大大简化。
回归层(Bounding-box Regressor) :输出一个 4维向量
(tx, ty, tw, th),代表对该RoI位置和尺寸的精修偏移量。每个类别都有自己独立的4个回归参数。步骤五:后处理(NMS)
- 同R-CNN,使用非极大值抑制去除重复框。
训练方式:多任务损失函数
- 计算一个RoI样本的总损失
分类损失
p:网络softmax头输出的**(N+1)维概率向量**。
k*:这个RoI的真实类别标签 。k* = 0代表背景,k* ≥ 1代表具体的目标类别(如1=猫,2=狗)。计算方式 :这就是标准的多类交叉熵损失 。它衡量预测概率分布
p与真实类别k*(一个one-hot向量)之间的差距。作用:让网络学会正确分类。
定位损失
λ:一个超参数,用于平衡分类损失和定位损失的权重。通常设置为1。
[k* ≥ 1]:这是一个指示函数(Iverson bracket) ,它是整个设计的关键。
当
k* ≥ 1(即该RoI是前景目标 )时,[k* ≥ 1] = 1,需要计算定位损失。当
k* = 0(即该RoI是背景 )时,[k* ≥ 1] = 0,定位损失项为0,不参与计算。
t:网络bbox回归头输出的4维预测偏移量(tₓ, tᵧ, t_w, t_h)。
t*:这个RoI对应的真实目标偏移量。它是根据RoI与它匹配的真实框(ground-truth box)计算出来的,表示"如何将当前RoI调整到与真实框完美重合"所需的偏移量。
L_loc(t, t*)的计算 :通常使用 Smooth L1 损失。
对于每个坐标分量(如
tₓ和t*ₓ),SmoothL1(x) = { 0.5x² if |x| < 1; |x| - 0.5 otherwise }。它对离群值(预测误差过大)比L2损失更鲁棒,有助于稳定训练。
作用 :只针对前景目标,让网络学会预测出准确的框位置偏移量。
公式本质与优点:
这个公式将分类任务 和定位任务 的损失加权求和 ,形成一个统一的多任务损失函数。
端到端训练 :在每次反向传播时,网络根据这个总损失
L来同时更新特征提取网络(ConvNet)、分类头和回归头的所有参数。训练简化 :无需再像R-CNN那样分阶段训练CNN、SVM和回归器。一次前向-反向传播,完成所有优化。
【总结】
为了解决R-CNN的速度和训练繁琐问题,核心思路是整张图片只通过卷积网络一次,生成共享的特征图 。对于外部算法(如Selective Search)生成的每个候选区域(RoI),通过一种叫 RoI Pooling 的操作,从共享特征图上提取出固定大小的特征向量。然后,用一个全连接网络同时完成分类(Softmax)和边框回归(BBox Regressor) ,并通过一个多任务损失函数实现端到端的联合训练。
Fast R-CNN 主要缺点:
区域提名瓶颈 :候选区域的生成仍然依赖外部算法(如Selective Search),该步骤在CPU上运行,速度慢,且无法与GPU上的深度学习网络联合优化,成为整个系统新的速度瓶颈。
RoI Pooling的量化误差 :RoI Pooling中对坐标进行两次量化取整(将候选区域映射到特征图网格时一次,划分网格池化时又一次),会引入误差,影响小目标或边界框的定位精度。
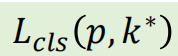
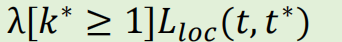
Faster R-CNN (2015)
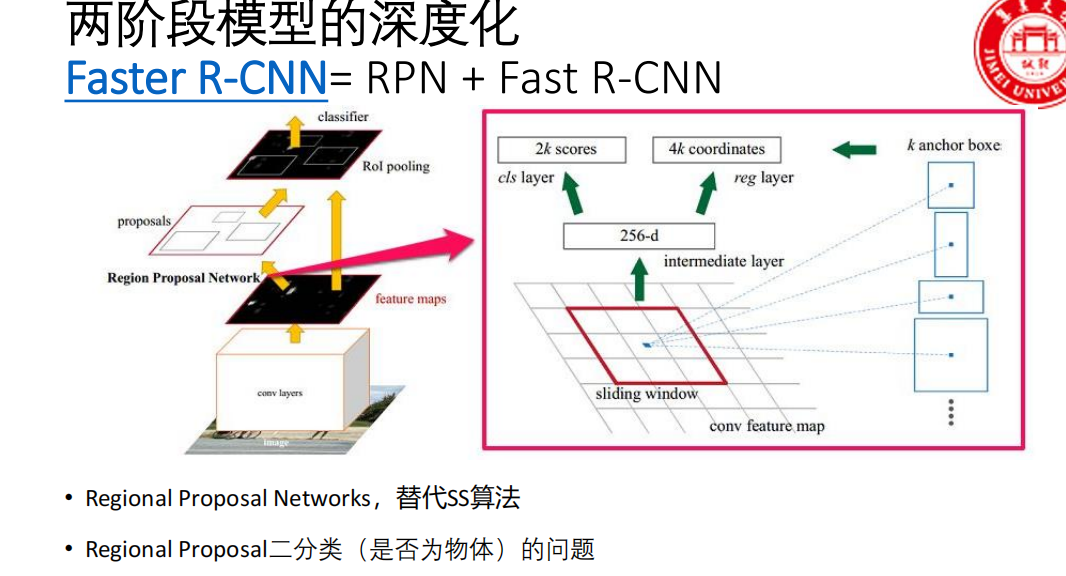
Faster R-CNN的核心思想是:用一个神经网络(称为RPN,Region Proposal Network)来替代Selective Search算法,让候选区域的生成也变成神经网络的一部分,从而实现从输入图像到检测结果的完全端到端学习。
- 关键词:RPN(区域提议网络)、Anchor(锚框)、完全端到端。
Faster R-CNN可以看作 RPN + Fast R-CNN 的集成。
共享Backbone:输入图像 -> CNN(如ResNet) -> 共享特征图。
RPN :共享特征图 -> RPN -> 输出 约300个高质量候选区域(Proposals)。
RoI Pooling :将RPN生成的Proposals坐标映射到同一个共享特征图上,进行RoI Pooling(与Fast R-CNN完全相同)。
Fast R-CNN头部 :对池化后的特征进行分类(是什么物体)和边框回归(二次精修)。注意:这里进行的是更精细的第二次分类和回归。
关键点 :RPN和Fast R-CNN头部共享同一个特征图,计算效率极高。
核心组件:RPN(区域提议网络)
- RPN是一个全卷积网络 ,输入是共享特征图,输出是一系列高质量的候选区域 及其是前景/背景的得分。
RPN的工作原理
输入 :Backbone网络(如VGG/ResNet)提取的共享特征图。
滑动窗口:在特征图上用一个小的滑动窗口(如3x3卷积)遍历每个位置。
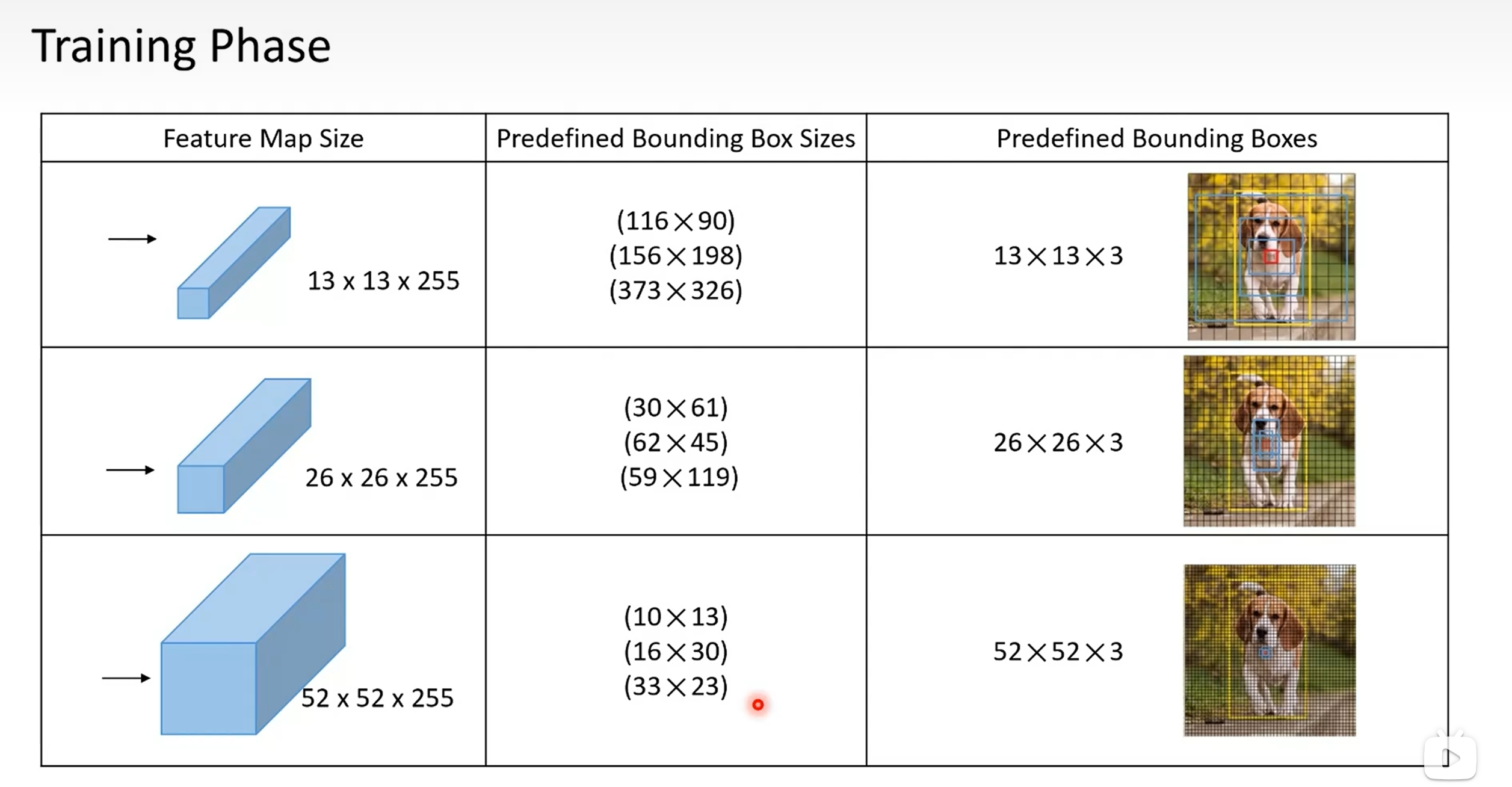
锚框(Anchor)机制 - 关键创新:
在特征图的每一个像素点(即每个滑动窗口中心) ,预先定义 k个(默认k=9) 不同尺寸和长宽比的基准框 ,这些框就是 Anchor。
9个Anchor通常由3种面积(
128², 256², 512²)和3种长宽比(1:1, 1:2, 2:1)组合而成。作用:Anchor覆盖了图像上各种可能的位置、大小和形状,为后续的预测提供了"参考点"或"先验框"。
RPN的两个任务:
分类任务 :对于每个Anchor,预测它是 "前景"(包含物体) 还是 "背景" 。输出
2k个分数(每个Anchor对应2个分数:前景分、背景分)。回归任务 :对于每个Anchor,预测一个 4维的偏移量
(tₓ, tᵧ, t_w, t_h),这个偏移量表示如何将这个Anchor调整得更接近真实物体框 。输出4k个坐标值。k 是在特征图每个滑动窗口位置(即每个像素点)上预先设定的 Anchor 的数量。
Anchor标签分配
正样本:1. 与某个真实框IoU最高的Anchor; 2. 与任意真实框IoU > 0.7的Anchor。
负样本:与所有真实框IoU < 0.3的Anchor。
忽略样本:IoU在0.3, 0.7之间的Anchor,不参与训练。
生成候选区域(Proposal):
用预测的前景分数对所有Anchor排序。
应用预测的偏移量对Anchor进行调整,得到初步的候选框。
使用NMS(非极大值抑制)合并重叠的候选框。
选取Top-N 得分最高的候选框,输出给后面的Fast R-CNN模块。这些框的质量远高于Selective Search生成的框。
工作流程
【总结】
为解决Fast R-CNN依赖外部候选区域生成器(如Selective Search)的瓶颈,其核心思路是引入一个称为RPN(区域提议网络)的神经网络来替代外部算法 。RPN在共享特征图的每个位置上预设多个不同尺度和长宽比的锚框(Anchor),并直接预测这些Anchor是前景/背景的分数以及相对于真实框的偏移量,从而生成高质量的候选区域。最终网络结构由 RPN(负责生成候选框) 和 Fast R-CNN头部(负责对候选框进行分类和精修) 串联组成,两者共享同一个骨干网络提取的特征图。
Faster R-CNN 主要缺点:
两阶段固有延迟:"先提名(RPN),再检测(Fast R-CNN头)"的串行流程,使其推理速度无法达到最极致的实时性。
计算冗余:Fast R-CNN头部需要对每个候选区域进行独立计算,当候选区域较多或存在重叠时,存在重复计算。
Anchor依赖与超参数敏感:检测性能依赖于预设的Anchor尺度、长宽比等超参数,需要对数据集进行一定先验分析或调优。



Two-Stage 目标检测算法
一、核心思想与统一流程
所有Two-Stage方法都遵循 "先粗选,再细判" 的哲学。它将检测任务解耦为两个串行的子任务:
第一阶段(Region Proposal) :从整张图像中找出有限数量 (几百到几千个)可能包含物体的候选区域。目标是高召回率(宁可错找,不可遗漏)。
第二阶段(Classification & Regression) :对每个候选区域进行精细处理,包括:
分类:判断它属于哪个具体类别(或背景)。
回归:对候选框的位置和大小进行微调,使其更贴合目标。
二、算法进化史与关键改进
1. R-CNN(起点)
贡献 :开创性地将CNN深度特征引入目标检测,取代手工特征。
核心流程 :SS找框 -> 各自缩放 -> 各自CNN提特征 -> SVM分类 -> 回归器精修。
核心缺陷:
速度极慢 :每个候选区域独立通过CNN,重复计算严重。
训练繁琐 :CNN微调、SVM训练、回归器训练多阶段分离,非端到端。
2. Fast R-CNN(解决"慢"与"繁琐")
贡献 :引入特征共享 与RoI Pooling,实现端到端训练。
核心流程 :整图CNN -> 共享特征图 -> SS找框 -> RoI Pooling (从共享图提取固定特征) -> 统一网络(Softmax分类+回归)。
核心改进:
速度提升:整图只过一次CNN,消除重复计算。
训练简化 :通过多任务损失函数
实现分类与回归的端到端联合训练。
遗留问题 :Region Proposal 仍依赖外部算法(Selective Search),是该阶段速度瓶颈。
3. Faster R-CNN(解决"最后瓶颈")
贡献 :用神经网络(RPN )替代外部算法,实现完全端到端。
核心流程 :整图CNN -> 共享特征图 -> RPN生成候选框 -> RoI Pooling -> Fast R-CNN头部分类与回归。
核心创新:
RPN(区域提议网络) :一个轻量级全卷积网络,在特征图上通过锚框(Anchor) 机制,直接预测候选框及前景背景分数。
Anchor机制:在特征图每个位置预设多个尺度和长宽比的参考框,为RPN提供学习起点。
最终形态 :成为Two-Stage方法的标杆,精度高,但速度受限于两阶段串行架构。
三、Two-Stage 方法的固有优缺点
优点:
精度高:两阶段设计让网络有机会对候选区域进行"二次细判",RPN提供的候选框质量高,减少了后续判别的干扰。
结构清晰:"提名-验证"的流程符合直觉,易于理解和改进。
缺点(固有缺陷):
速度瓶颈 :两阶段必须串行执行,无法像单阶段方法那样完全并行。R-CNN头部的计算无法在候选框间共享。
计算冗余 :在
RoI Pooling及之后的全连接计算中,对空间重叠的候选区域存在重复计算。内存占用大:需要保存中间的大量候选区域特征,训练时显存消耗较高。
流程复杂:模型设计、训练调参相对复杂。
四、核心组件与概念回顾
Selective Search (SS):传统区域提名算法,被RPN取代。
RoI Pooling:将不同大小的候选区域映射到固定大小特征的关键操作。(Fast R-CNN引入)
多任务损失函数 :
L = L_cls(分类) + λ L_loc(回归),实现端到端训练的基础。(Fast R-CNN引入)RPN:区域提议网络,用Anchor和卷积实现高效候选框生成。(Faster R-CNN引入)
Anchor:预设的参考框,是RPN预测的基准。(Faster R-CNN引入)
NMS(非极大值抑制):后处理步骤,用于消除重复检测框。(所有方法共用)
YOLO系列
yolov1(了解)
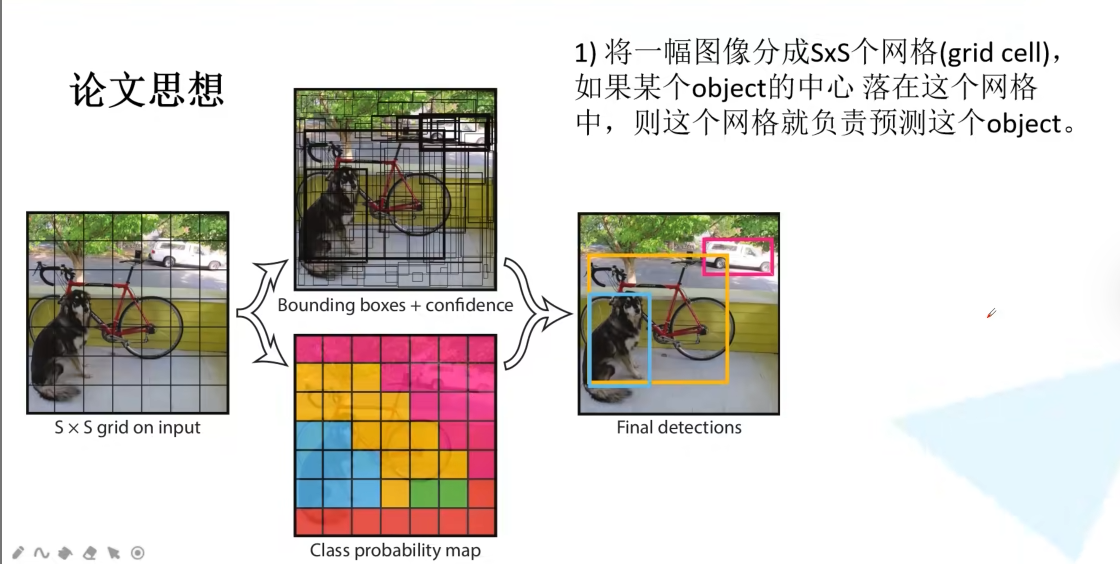
核心思想:将目标检测重新定义为一个单一的、端到端的回归问题,直接从图像像素映射到边界框坐标和类别概率。
与传统/Two-Stage方法的根本区别:
传统方法:
图像 -> 找可能区域 -> 对区域分类。("看两眼")YOLO v1 :
图像 -> 直接预测框和类。("看一眼",即You Only Look Once)如何实现"看一眼"?:
划分网格 :将输入图像均匀分割成
S x S个网格(例如7 x 7)。责任分配 :每个网格单元负责预测那些"中心点"落在自己区域内的物体。
并行预测:每个网格单元都独立地、同时地预测若干个边界框以及所有类别的概率。
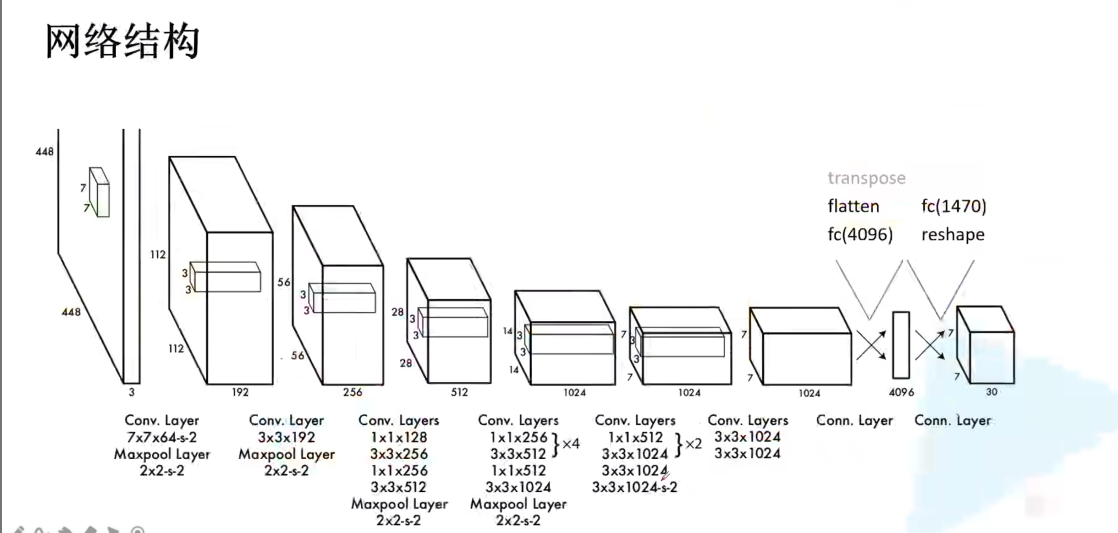
网络结构(一个单纯的卷积网络)
YOLO v1的骨干网络是一个自定义的、借鉴GoogLeNet的卷积神经网络,由24个卷积层和2个全连接层组成。
前端(卷积层):疯狂下采样,提取丰富的图像特征。
末端(全连接层) :将卷积特征"压平",并最终输出那个
7x7x30的预测张量。关键点 :这是一个纯粹的回归网络,输入是图片,输出是张量,没有RPN,没有RoI Pooling,结构异常清晰。
网络输出张量详解
网络最后的输出是一个固定大小的三维张量。
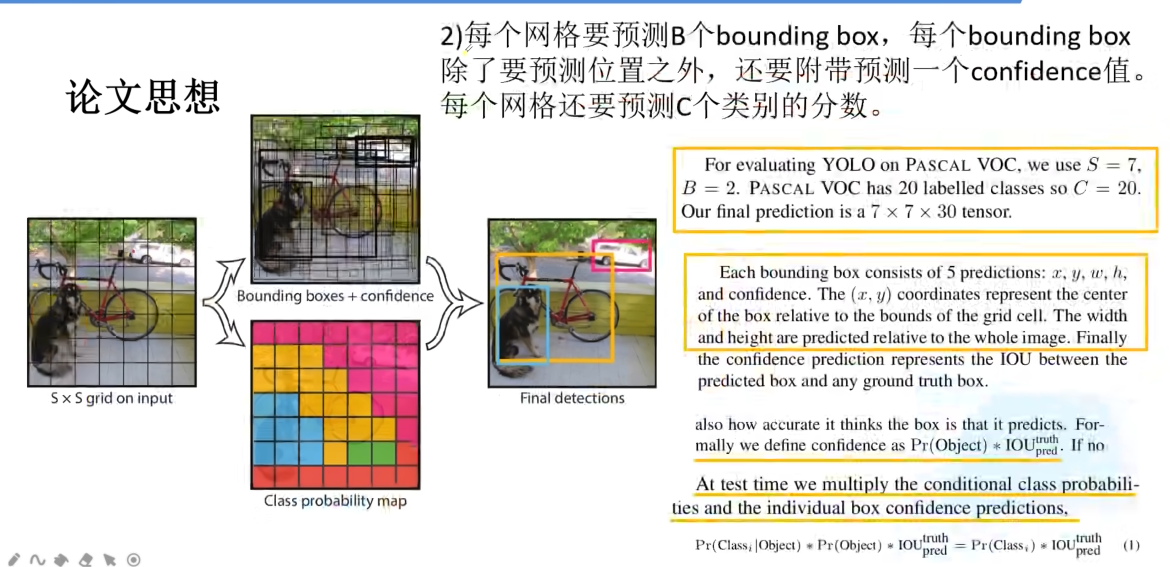
对于PASCAL VOC数据集(20类),YOLO v1的典型配置是:
S = 7:将图像分成7x7=49个网格。
B = 2:每个网格预测2个边界框(Bounding Box)。
C = 20:需要检测的物体类别数为20。那么,每个网格需要预测多少个数?我们来算一下:
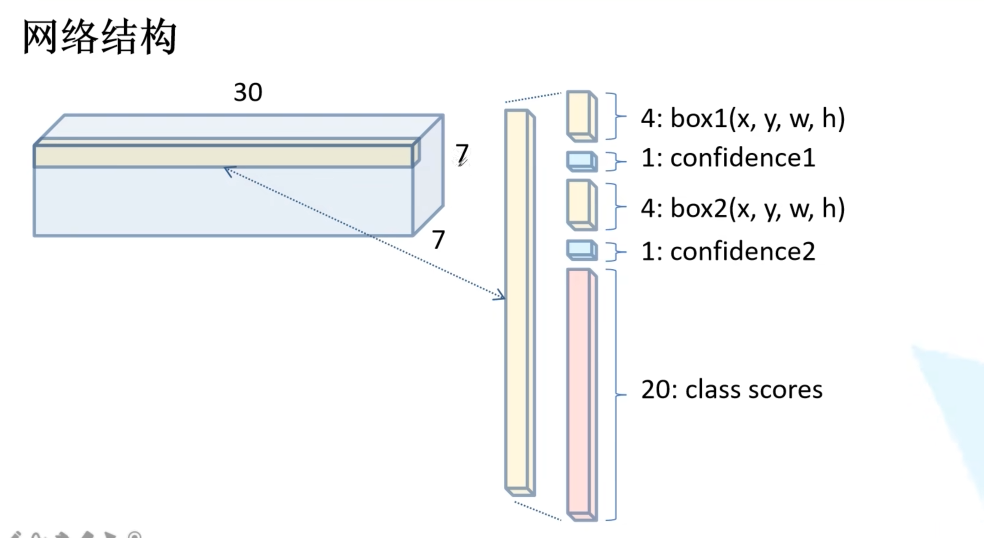
每个边界框预测 5个值 :
(x, y, w, h, confidence)。
(x, y):边界框中心相对于该网格左上角的偏移量 ,范围在[0, 1]。这使得中心点被约束在本网格内。
(w, h):边界框的宽和高相对于整张图片的宽和高的比例 ,范围在[0, 1]。
confidence(置信度):这个框包含一个物体的把握有多大,以及它预测得准不准 。公式上定义为:Pr(Object) * IOU(pred, truth)。
Pr(Object):框内有物体的概率(0或1)。
IOU(pred, truth):预测框与真实框的交并比。所以,如果一个框内没物体,它的置信度应为0;如果有物体,置信度就等于预测框与真实框的IoU。
每个网格预测 C个类条件概率 :
Pr(Class_i | Object),即在假设网格内有物体 的前提下,这个物体属于第i类的概率。注意:一个网格只预测一组类别概率,与其预测的B个框共享。因此,一个网格需要输出的总数值为:
B * 5 + C = 2*5 + 20 = 30。最终,整个网络的输出张量形状为:
[S, S, B*5+C] = [7, 7, 30]。
- 这个
7 x 7 x 30的张量,就是YOLO v1对整张图片的唯一一次 、完整 的预测结果。它包含了7x7=49个网格的预测信息,每个网格信息是一个30维的向量。预测与推理
在预测时,我们需要从
7x7x30的张量中解读出最终的检测结果。
计算每个边界框的"类别特异性置信度分数":
公式:
Score = Pr(Class_i | Object) * Confidence解释 :
Pr(Class_i | Object)来自网格预测的类别概率;Confidence来自边界框自身的置信度(包含了"是否有物体"和"框准不准"的信息)。物理意义 :这个分数综合反映了 "这个框里有一个物体,这个物体是第i类,而且这个框画得很准" 的整体把握。
计算后,我们得到
S x S x B x C个分数(7x7x2x20=1960个)。阈值过滤:设定一个阈值,滤除分数低的预测。
非极大值抑制(NMS):对每个类别独立进行NMS,得到最终检测框。
补充:NMS说明
假设我们完成了预测,计算出了所有框的"类别特异性置信度分数",现在要对 "狗" 这个类别进行NMS。我们得到了10个被模型认为是"狗"的预测框,每个框有它的坐标
(x1, y1, x2, y2)和对应的分数score。步骤如下:
准备列表 :将这10个预测框放入一个集合
D中。最终要保留的框放入集合R(初始为空)。选出分数最高的框:
从集合
D中找出分数最高 的那个框M(它就是当前我们认为最可靠的"狗"框)。将
M从D中移除,并加入到最终结果集合R中。计算IoU并抑制:
遍历集合
D中剩下的每一个框b_i。计算框
b_i与刚选出的"最佳框"M的 IoU。如果
IoU(b_i, M) > 阈值 Nt(例如,设定Nt = 0.5),则认为b_i和M预测的是同一个物体 。由于M的分数更高,我们更相信M,因此将b_i从集合D中删除(抑制)。如果
IoU(b_i, M) <= Nt,则认为b_i和M预测的是不同的物体 (或者同一个物体的不同部分),保留b_i在集合D中。循环 :重复步骤2和步骤3,直到集合
D为空。输出 :此时集合
R中保存的,就是经过NMS后,对于"狗"这个类别所有不重叠的最终预测框。【yolov1总结】
- YOLO v1的核心思想是将目标检测彻底重构为单次回归问题。它将输入图像划分为S×S的网格,每个网格负责预测中心点落在其内的物体。每个网格输出B个边界框(每个框含中心坐标、宽高和置信度)和一组所有类别的条件概率。最终,网络直接输出一个固定大小的张量(如7×7×30),其中包含所有预测信息。通过"网格责任划分"和"端到端回归",YOLO v1实现了仅需一次前向传播即可完成检测,其根本局限在于每个网格预测能力有限,导致定位精度不高、小目标和密集目标检测效果差。
yolov2(了解)
核心Pipeline:
- 输入图像 -> Darknet-19 提取特征 -> Passthrough Layer 融合高低层特征 -> 在融合后的特征图每个网格位置,为5个聚类先验锚框预测偏移量、置信度和类别概率 -> 使用 Sigmoid 约束公式将偏移量解码为最终框坐标 -> 计算最终得分并执行 NMS -> 输出检测框。
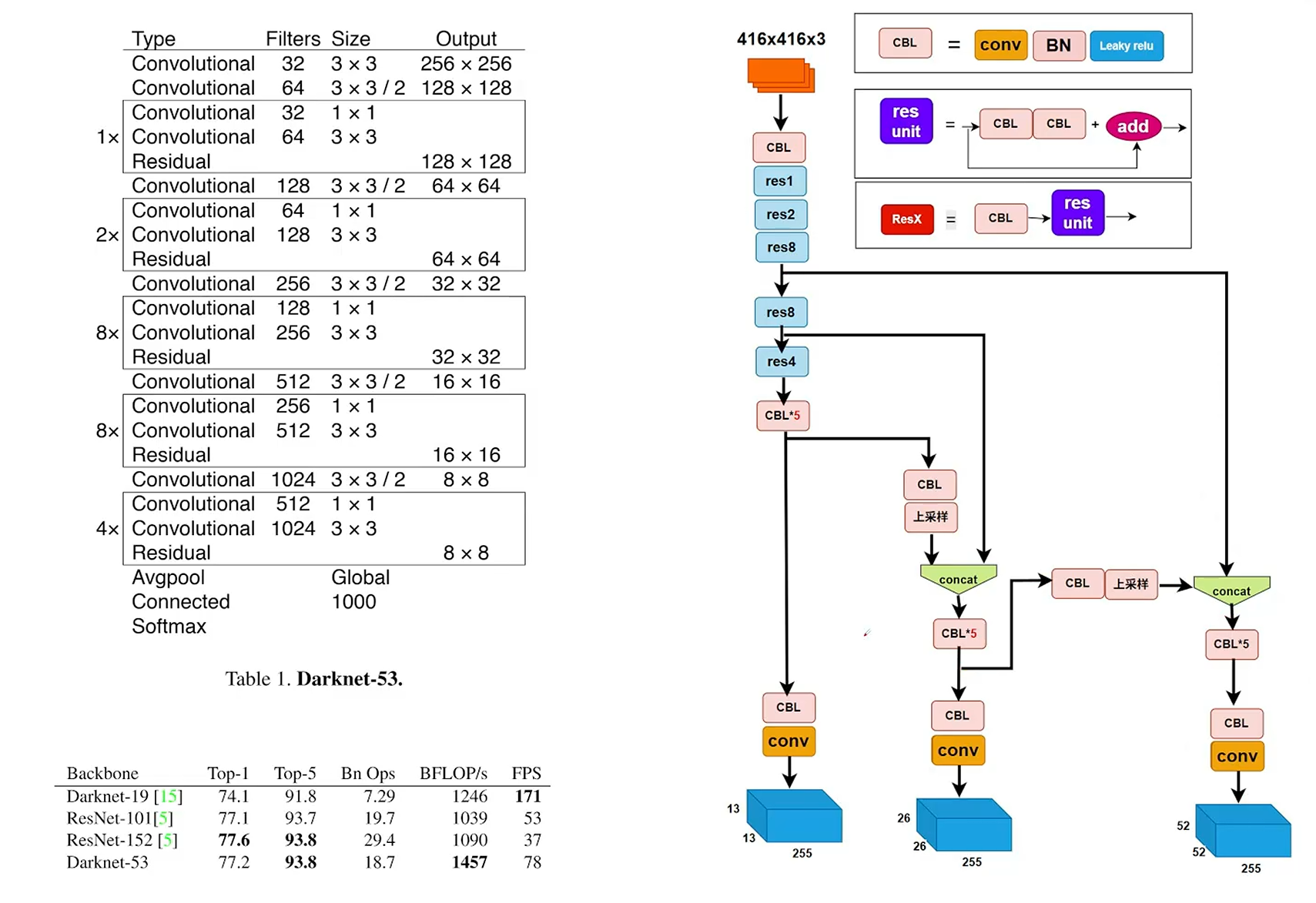
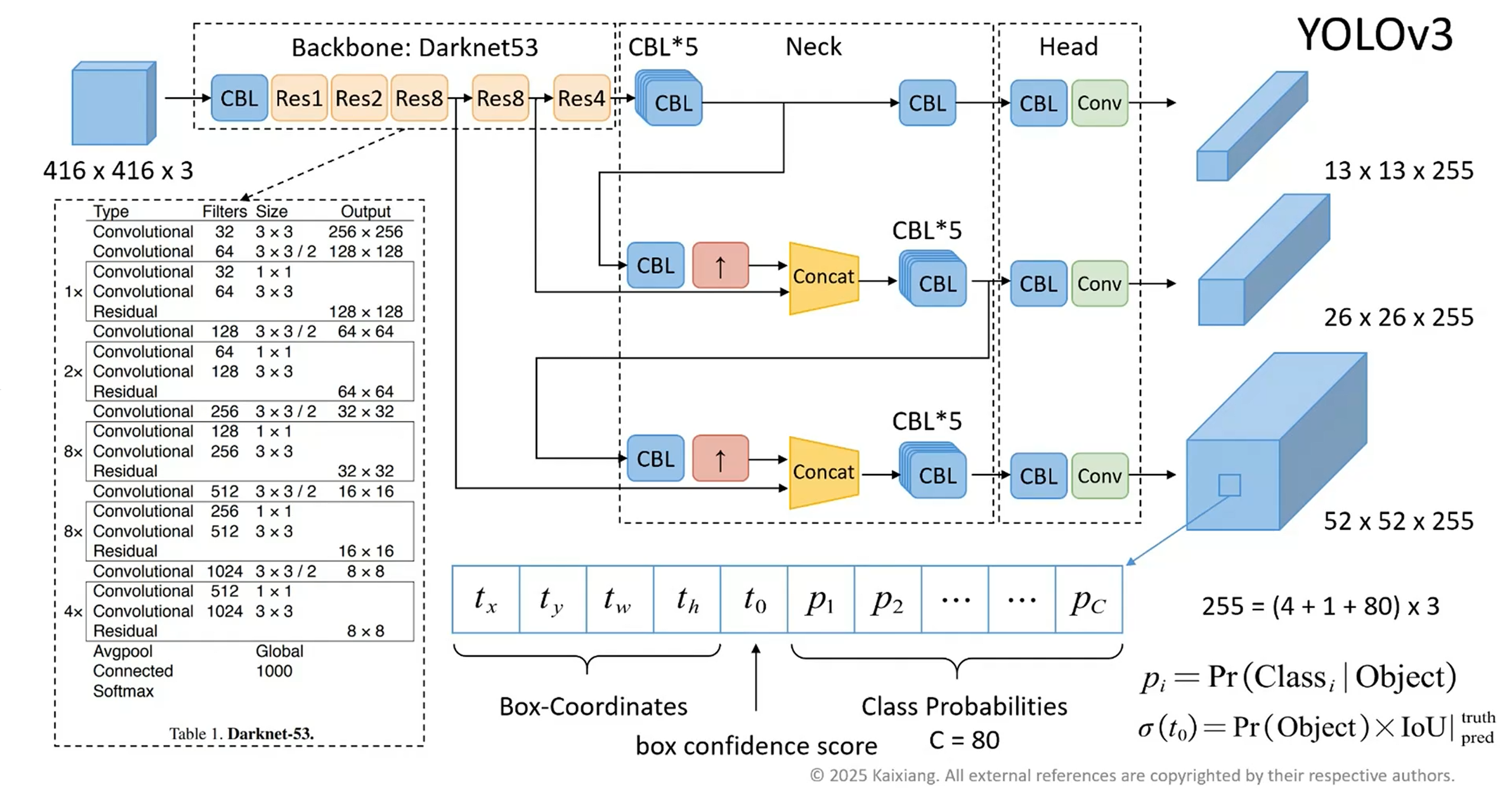
yolov3(重点)
pipeline
- YOLOv3采用了一种单阶段、端到端的检测框架。其核心流程为:输入图像首先通过一个称为 Darknet-53 的深度卷积神经网络(CNN)进行特征提取,生成多尺度的特征图。随后,这些特征图通过一个 特征金字塔网络(FPN) 结构进行融合与增强,最终在三个不同尺度的输出层上进行预测。每个预测层负责对应尺度的目标,并通过预定义的 锚框(Anchor Boxes) 来回归边界框的位置、置信度及类别概率。网络的输出经过后处理步骤,主要是 非极大值抑制(NMS),以消除冗余检测框,得到最终的检测结果。