系列概述
临近本科毕业,考虑到未来读研的方向以及自己的兴趣方向,我选择的课题大致为"基于VLA结构的指令驱动式机械臂仿真系统的实现"。
为什么说是VLA(Vision-Language-Action)"结构",因为就目前而言,我认为在目前剩下的几个月时间内从0实现一个正儿八经的VLA模型,所需要的时间、资金、模型资源的获取都是比较麻烦的。因此,我选择使用ROS2+LLM+视觉算法来实现一个"伪VLA"结构,就目前阶段(开题一个月)而言,我能给出的场景示意如下:
场景:指令输入"机械臂将蓝色方块夹起放到红色圆柱体上面",系统接收指令后,先通过视觉模块确定当前系统中各个物体的坐标,再通过开源大模型,结合已知坐标信息,通过预设的prompt生成动作序列,作为参数送入ROS2架构下的启动文件中,实现动作行为在gazebo下的仿真。
当前阶段我能给出粗糙的逻辑示意图如下:
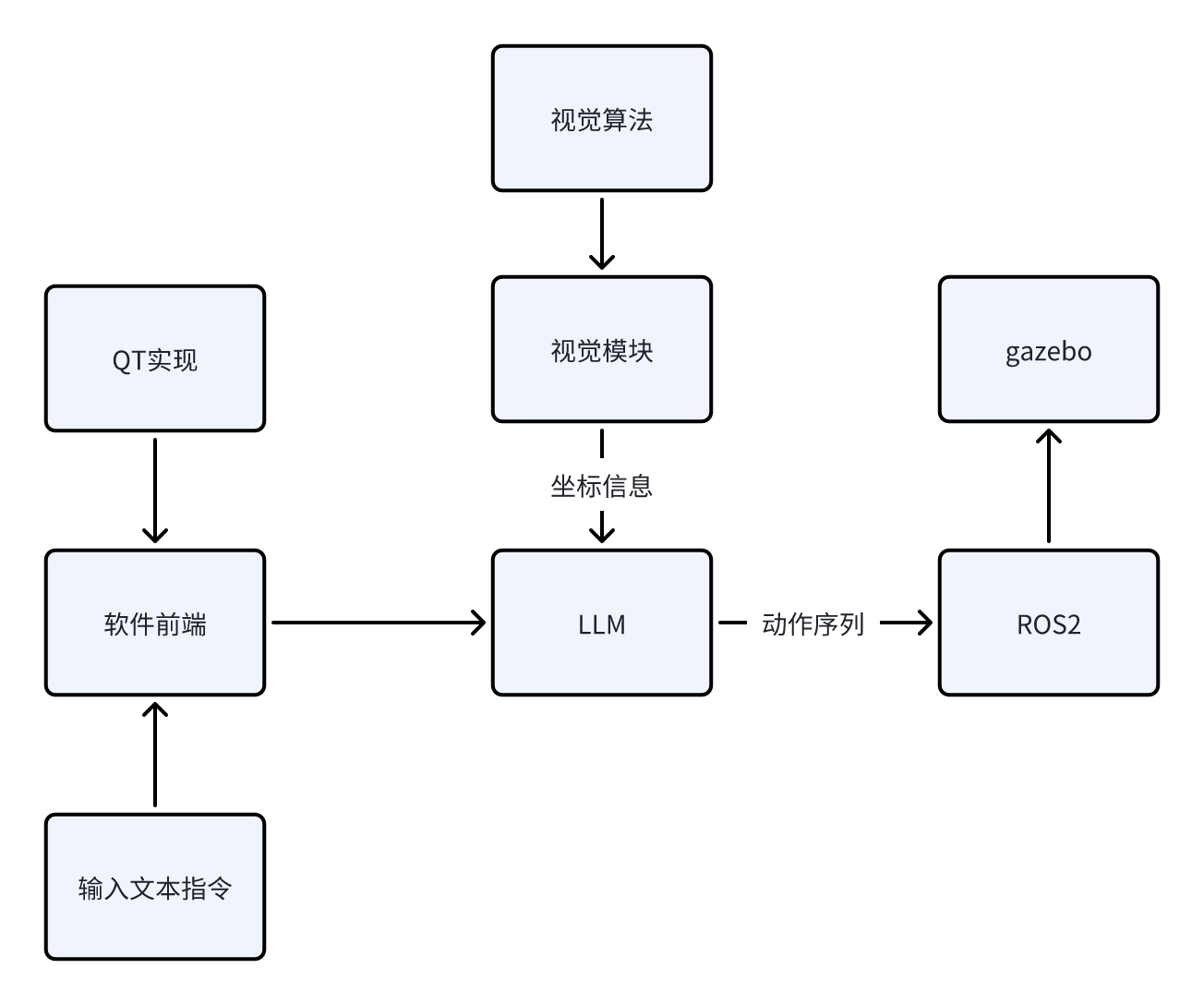
接下来,我将给出目前阶段我所计划的步骤实现,之后该系列的博客都会依照下面的框架进行更新。由于我也是初次入门ROS2以及深度学习相关的内容,所以本系列博客更多的充当学习笔记的作用,在书写过程中难免会出现错误以及天真的理论理解,还请各位指正。
我将该项目的实现分成下面几个步骤(每个步骤下的博客会一步一步地更新):
- 实现机械臂在ROS2+Gazebo环境下的控制、仿真。目标效果是给出任意坐标的方块,机械臂要能稳定的抓取,并放置到指定的坐标。
该步骤博客目录如下:
https://blog.csdn.net/m0_75114363/article/details/156164226?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_75114363/article/details/156166592?spm=1001.2014.3001.5502
-
加入视觉模块与算法。目标效果是在仿真环境下,对于随意放置的方块,视觉系统需要计算出其真实坐标给予机械臂控制模块,使得机械臂能够实现对其的抓取与放置。
-
加入视觉模块与算法。目标效果是在仿真环境下,对于随意放置的方块,视觉系统需要计算出其真实坐标给予机械臂控制模块,使得机械臂能够实现对其的抓取与放置。
该步骤博客目录如下:
- 加入LLM(本地部署或使用API)。目标效果是对于输入的任意文本指令,LLM能根据预设的prompt,结合视觉系统给予的信息,给予执行模块对应的动作序列,使得机械臂正确地实现输入的文本指令想达到的效果,实现V-L-A的完整交互。
该步骤博客目录如下:
- 实现整体系统的优化与完善,包括基于QT搭建软件前端、优化模型外观、加入更复杂的机械臂、实现更复杂的指令解析与运行。
该步骤博客目录如下:
我所使用的环境如下:
-
系统:Ubuntu22.04
-
ROS2: humble
项目地址:
https://github.com/Dukiyaaa/Cmd2Action
总结
本篇博客为该系列的总览,主要讲述了该项目的大致组成,后续我会持续更新系列内容,充当学习分享,如有谬误,欢迎指正。