这段代码是一个 HarmonyOS NEXT平台下基于 @kit.CoreSpeechKit 实现的文本转语音(TTS)封装类 ,整体结构清晰、注释详细,符合官方 API 使用规范。
TextToSpeech.ets文件如下:
typescript
//文本转语音
import { textToSpeech } from '@kit.CoreSpeechKit';
// 一 、创建语音播报对象()
//二 、 设置语音合成播报回调() speak()、stop()、isBusy()需要设置回调
//三 、 合成并播报文本、停止合成或停止播报、判断当前是否处于合成或播报中、
//四 、 释放对象
class TextToSpeech {
//实例对象
ttsEngine: textToSpeech.TextToSpeechEngine | null = null
//功能应用
//查询支持的音色信息
async GetVoicesList() {
//获取引擎对象
await this.Creat()
//实例对象
const ttsEngine = this.ttsEngine
//查询音色
/* * 配置信息:
* requestId : 必填 请求ID,全局不允许重复。。
* online ; 必填 模式。0为在线,目前不支持;1为离线,当前仅支持离线模式。
* extraParams ;可选 附加参数。
* <'person', number> 查询的音色。。 可选,非空时则language必填,当前仅支持0小艺女声音色。
* <'language', string> 查询的语种。可选,当前仅支持"zh-CN"中文。
* */
let voicesQuery: textToSpeech.VoiceQuery = {
requestId: Date.now().toString(), // requestId在同一实例内仅能用一次,请勿重复设置 ----可自行按照唯一性规则生成
online: 1
}
/*
* language 支持的语种信息。
* person 支持的音色信息。
* style 风格。interaction-broadcast:普通话播报。
* status 目前的使用状态。 GA:可使用状态 EOM:废弃状态
* gender 性别 male:男性 female:女性
* description 语音的描述,角色属性、支持的情感等说明
* */
const resList = await ttsEngine?.listVoices(voicesQuery)
// 输出音色列表
return resList
}
//功能应用
//合成并播放文本
async speak(text: string,) {
//1、获取引擎对象
await this.Creat()
//实例对象
const ttsEngine = this.ttsEngine
//2、设置回调 注册监听
await this.setListener()
// 设置合成参数:speakParams
/*
* requestId 必填 合成播报ID,全局不允许重复。
* extraParams 可选 合成参数。用于配置语速、音量、音调、合成类型等
* <'speed', number> 语速 可选,支持范围[0.5-2],不传参时默认为1
* <'volume', number> 音量 可选,支持范围[0-2],不传参时默认为1。
* <'languageContext', string> 语境,播放阿拉伯数字用的语种。可选,当前仅支持"zh-CN"中文,不传参时默认"zh-CN"
* <'audioType', string> 音频类型 可选,当前仅支持"pcm",不传参时默认为"pcm"(PCM 即脉冲编码调制 (Pulse Code Modulation))
* <'playType', number> 合成类型。可选,不传参时默认为1。 0:仅合成不播报,返回音频流。 1:合成与播报不返回音频流。
* <'soundChannel', number> 通道。可选,参数范围0-16,整数类型,可参考音频流使用类型介绍来选择适合自己的音频场景。不传参时默认为3,语音助手通道。
* <'queueMode', number> 播报模式。可选,不传参时默认为0。0:排队模式播报。1:抢占模式播报。
*
* */
let extraParam: Record<string, Object> = {
"speed": 1,
"volume": 2,
"pitch": 1,
"languageContext": 'zh-CN',
"audioType": "pcm"
}
let speakParams: textToSpeech.SpeakParams = {
requestId: Date.now().toString(), // requestId在同一实例内仅能用一次,请勿重复设置 ----可自行按照唯一性规则生成
// extraParams: extraParam
}
// 传入文本originalText,调用speak接口
ttsEngine?.speak(text, speakParams);
}
//功能应用
//停止播报
async stop() {
//1、获取引擎对象
await this.Creat()
//实例对象
const ttsEngine = this.ttsEngine
//2、设置回调 注册监听
await this.setListener()
//停止播放
ttsEngine?.stop();
}
//功能应用
//判断当前是否处于合成或播报中
async isBusy() {
//1、获取引擎对象
await this.Creat()
//实例对象
const ttsEngine = this.ttsEngine
//2、设置回调 注册监听
await this.setListener()
//true:引擎正处于合成或播报状态。
// false:引擎没有处于合成或播报状态。
return ttsEngine?.isBusy();
}
//功能应用
//关闭引擎,释放引擎资源。
async shutdown() {
//1、获取引擎对象
await this.Creat()
//实例对象
const ttsEngine = this.ttsEngine
// 调用shutdown接口
ttsEngine?.shutdown();
}
//设置语音合成播报回调
private async setListener() {
//获取引擎对象
await this.Creat()
//实例对象
const ttsEngine = this.ttsEngine
// 设置speak的回调信息
let speakListener: textToSpeech.SpeakListener = {
// 开始合成或播报的回调--返回请求ID、播报相关参数,例如通道数、采样率、采样位数信息
onStart(requestId: string, response: textToSpeech.StartResponse) {
console.info('开始合成: ' + 'requestId: ' + requestId);
console.info('开始合成: ' + 'response: ' + JSON.stringify(response));
},
// 合成完成或播报完成回调--返回请求ID,完成合成或播报相关信息。
onComplete(requestId: string, response: textToSpeech.CompleteResponse) {
console.info('合成完成: ' + 'requestId: ' + requestId);
console.info('合成完成: ' + 'response: ' + JSON.stringify(response));
},
// 停止合成或播报回调--表示stop已完成。
onStop(requestId: string, response: textToSpeech.StopResponse) {
console.info('停止合成: ' + 'requestId: ' + requestId);
console.info('停止合成: ' + 'response: ' + JSON.stringify(response));
},
// 返回音频流---返回请求ID,音频流信息,音频附加信息如格式、时长等。若需要返回音频流信息
onData(requestId: string, audio: ArrayBuffer, response: textToSpeech.SynthesisResponse) {
console.log('返回音频流: ' + ' requestId: ' + requestId + ' audio: ' + audio);
console.log('返回音频流: ' + ' requestId: ' + requestId + ' audio: ' + audio);
console.log('返回音频流: ' + ' response: ' + JSON.stringify(response));
},
// 错误回调---返回请求ID、错误码及错误描述。
onError(requestId: string, errorCode: number, errorMessage: string) {
console.error('错误回调: ' + 'requestId: ' + requestId + ' errorCode: ' + errorCode + 'errorMessage: ' + errorMessage);
}
};
// 设置回调
ttsEngine?.setListener(speakListener);
}
//创建对象
private async Creat() {
//判断是否支持文本播报
if (!canIUse('SystemCapability.AI.TextToSpeech')) {
AlertDialog.show({ message: '当前设备不支持文本播报' })
return Promise.reject('当前设备不支持文本播报')
} else {
//判断是否存在引擎
if (this.ttsEngine) {
return this.ttsEngine
}
try {
//1、创建语音播报对象的设置信息
/*
* 配置信息:
* language : 必填 语种, 当前仅支持"zh-CN"中文。
* online ; 必填 模式。0为在线,目前不支持;1为离线,当前仅支持离线模式。
* person ; 必填 音色。0为小艺女生音色,当前仅支持小艺女生音色。
* extraParams ;可选 附加参数。
* <'style', string> 风格。 可选,不设置时默认为"interaction-broadcast",当前仅支持"interaction-broadcast" 普通话播报。
* <'locate', string> 区域信息。可选,不设置时默认为"CN",当前仅支持"CN"。CN:中国。
* <'name', string> 引擎名称。可选,引擎名称,不设置是默认为空。
* */
let initParamsInfo: textToSpeech.CreateEngineParams = {
language: 'zh-CN',
person: 0,
online: 1,
// extraParams: { "style": 'interaction-broadcast', "locate": 'CN', "name": 'EngineName' } //name:引擎名称,可自定义
}
//1、创建语音播报对象的设置信息
const ttsEngine = await textToSpeech.createEngine(initParamsInfo)
this.ttsEngine = ttsEngine
return ttsEngine
} catch (err) {
return Promise.reject(err)
}
}
}
}
export const textTospeech = new TextToSpeech();下面的代码放在index.ets中
typescript
import { textTospeech } from './TextToSpeech'
@Entry
@Component
struct Index {
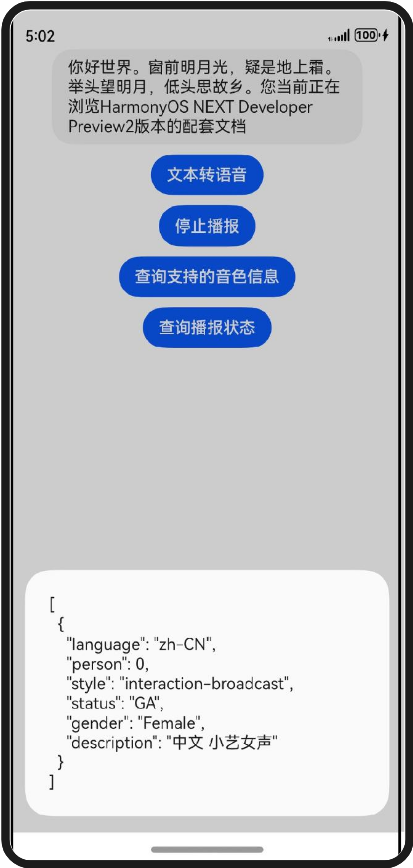
@State text:string = '你好世界。窗前明月光,疑是地上霜。举头望明月,低头思故乡。您当前正在浏览HarmonyOS NEXT Developer Preview2版本的配套文档'
build() {
Column({space:10}){
TextArea({text:$$this.text})
.width('80%')
Button('文本转语音')
.onClick(()=>{
try {
textTospeech.speak(this.text)
} catch (err) {
AlertDialog.show({ message: JSON.stringify( err,null,2)})
}
})
Button('停止播报')
.onClick(()=>{
textTospeech.stop()
})
Button('查询支持的音色信息')
.onClick(async ()=>{
const list = await textTospeech.GetVoicesList()
AlertDialog.show({ message: JSON.stringify( list,null,2)})
})
Button('查询播报状态')
.onClick(async ()=>{
// 查询播报状态
let isBusy = await textTospeech.isBusy();
AlertDialog.show({ message: JSON.stringify( isBusy,null,2)})
})
}
.width('100%')
.height('100%')
}
}
下面我将从 原理、流程、关键点、注意事项 四个维度为你做系统性解释:
一、整体目标
实现一个 可复用的 TTS 工具类 TextToSpeech,支持以下功能:
- 创建 TTS 引擎
- 播报文本(合成 + 播放)
- 停止播报
- 查询是否正在播报(
isBusy) - 获取支持的音色列表(
listVoices) - 释放资源(
shutdown)
并通过单例 textTospeech 在页面中调用。
二、核心流程解析(四步走)
第一步:创建引擎(Creat() 方法)
ts
const ttsEngine = await textToSpeech.createEngine(initParamsInfo)关键参数说明:
| 参数 | 值 | 说明 |
|---|---|---|
language |
'zh-CN' |
必填,当前仅支持中文 |
person |
0 |
必填,0 = 小艺女声(唯一可用音色) |
online |
1 |
必填 ,1 = 离线模式(在线模式目前不支持) |
extraParams.style |
'interaction-broadcast' |
普通话播报风格(默认值) |
注意:HarmonyOS NEXT 当前 仅支持离线 TTS ,且 只有小艺女声音色。
安全检查:
ts
if (!canIUse('SystemCapability.AI.TextToSpeech')) {
// 模拟器或旧设备会走到这里
}这是 必须的前置判断,避免在不支持设备上调用崩溃。
第二步:设置回调(setListener())
通过 setListener() 注册 SpeakListener,监听 TTS 全生命周期事件:
| 回调方法 | 触发时机 | 用途 |
|---|---|---|
onStart |
开始合成/播报 | 日志、UI 反馈(如"正在朗读...") |
onComplete |
合成+播报完成 | 自动执行下一步(如关闭动画) |
onStop |
调用 stop() 后完成 |
清理状态 |
onData |
返回音频流(仅当 playType: 0) |
用于录音、保存音频等 |
onError |
出错(如资源缺失、ID重复) | 错误提示、重试 |
💡 你的代码中每次调用
speak/stop/isBusy都重新注册监听器,虽无错,但冗余 。建议在Creat()成功后只注册一次。
第三步:执行操作(speak, stop, isBusy)
1. speak(text)
- 生成唯一
requestId(你用了Date.now().toString(),可行但不严格唯一) - 设置
extraParams控制语速、音量等 - 调用
ttsEngine.speak(text, params)
🔔 注意:
requestId在同一引擎实例中不能重复!否则会报错。生产环境建议用 UUID。
2. stop()
- 调用
ttsEngine.stop()→ 触发onStop回调 - 不会销毁引擎,只是中断当前播报
3. isBusy()
- 返回
boolean:true表示正在合成或播放 - 可用于禁用"再次播报"按钮,防止冲突
第四步:释放资源(shutdown())
ts
ttsEngine?.shutdown();- 释放底层 TTS 引擎占用的内存和系统资源
- 应用退出或长时间不用时应调用
- 调用后
ttsEngine应置为null,下次使用需重新Creat()
❗ 你的代码中
shutdown()没有将this.ttsEngine = null,会导致后续误用已释放对象。建议补充:
ts
async shutdown() {
if (this.ttsEngine) {
await this.ttsEngine.shutdown();
this.ttsEngine = null; // 👈 关键!
}
}三、重要注意事项(避坑指南)
1. 只能在真机运行
- 模拟器
canIUse(...)永远返回false - 必须使用 HarmonyOS NEXT 真机(如 Mate 60/Pura 70)
2. 必须配置 module.json5 依赖
json
{
"dependencies": [
{ "name": "CoreSpeechKit", "type": "kit" }
]
}3. 首次使用需下载离线语音包
- 首次调用 TTS 时,系统会弹窗提示"下载小艺语音包"
- 若未下载,
createEngine可能失败(错误码常见1003400005)
4. requestId 必须全局唯一(至少在当前引擎内)
-
你用
Date.now()在快速连续点击时可能重复 -
推荐改用:
tsrequestId: Math.random().toString(36).substring(2, 10)
5. 不要频繁创建/销毁引擎
createEngine是重量级操作- 建议 单例 + 复用(你已做到),避免内存抖动
四、优化建议
1. 改进 requestId 生成
ts
private generateRequestId(): string {
return Date.now() + '_' + Math.floor(Math.random() * 10000);
}2. 监听器只注册一次
ts
private async Creat() {
if (this.ttsEngine) return this.ttsEngine;
// ...创建引擎...
this.ttsEngine = ttsEngine;
this.setListener(); // 👈 只在这里注册一次
return ttsEngine;
}3. 补充 shutdown 后置空
ts
async shutdown() {
if (this.ttsEngine) {
await this.ttsEngine.shutdown();
this.ttsEngine = null;
}
}4. 增加重试或降级逻辑(模拟器友好)
ts
// 在页面中
Button('文本转语音').onClick(() => {
if (!canIUse('SystemCapability.AI.TextToSpeech')) {
promptAction.showToast({ message: '请在真机上体验语音功能' });
return;
}
textTospeech.speak(this.text);
})唯一限制是:必须在 HarmonyOS NEXT 真机上运行 。
只要满足这个条件,你的 TTS 功能就能正常工作!
如果你在真机上仍遇到问题,请检查:
- 是否已下载"小艺语音离线包"?
module.json5是否包含CoreSpeechKit?- 是否开启了"文字转语音"权限?(【设置】→【辅助功能】→【文字转语音】)