- 从质量视角可此问题,翻译后就成为面向风险的设计,使系统具备控制风险的能力,提供更高的可用性能力;为什么要高可用,对于一个公司而言,可以完整理解为『公司为什么要做{系统的高可用}』,以公司为对象,从内看包括:人,软件,硬件,从外看包括:客户,股东,社会,从自身看包括:公司;
- 高可用(HA)架构的核心目标是 "最小化故障影响、最大化系统可用性",其落地执行需摆脱 "纯技术堆砌",构建 "设计→治理→防范→落地保障" 的保障体系 ------ 既要通过架构设计从源头降低故障概率,也要通过治理机制持续优化,更要通过风险防范兜底故障损失,最终确保方案 "可执行、可落地、可验证"。
1 高可用框架模型
高可用设计的质量保障,其可执行落地的保障策略,可以从 "架构层、治理层、风险层、落地层" 等一系列的系统工程,对其进行实施,核心框架如下:

可量化的核心指标(量化的可用性指标):
- 系统可用率:核心业务≥99.99%(年度故障时长≤52.56 分钟),非核心业务≥99.9%(年度故障时长≤8.76 小时);
- 故障恢复指标:RTO(恢复时间)≤30 分钟,RPO(数据丢失量)≤5 分钟;
- 变更安全指标:变更故障率≤0.1%,回滚成功率≥99.9%。
2 架构设计
架构设计的核心是 "冗余、隔离、降级、自愈",避免单点故障,从源头降低故障发生概率和影响范围。
2.1 核心设计原则
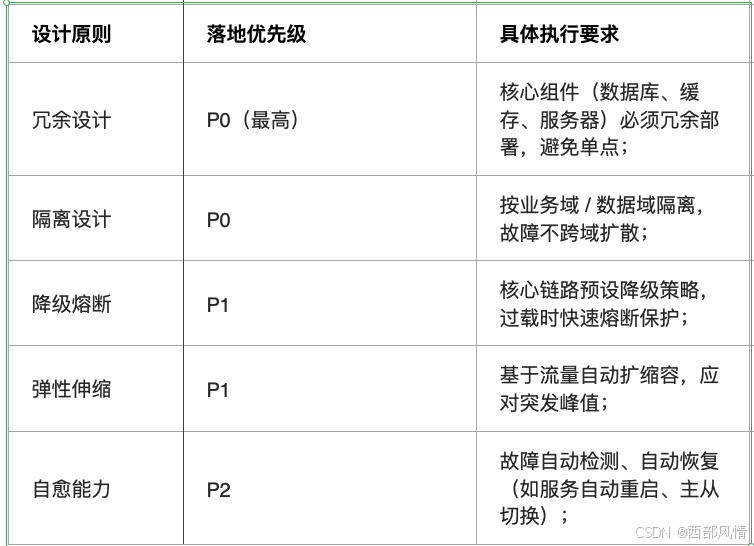
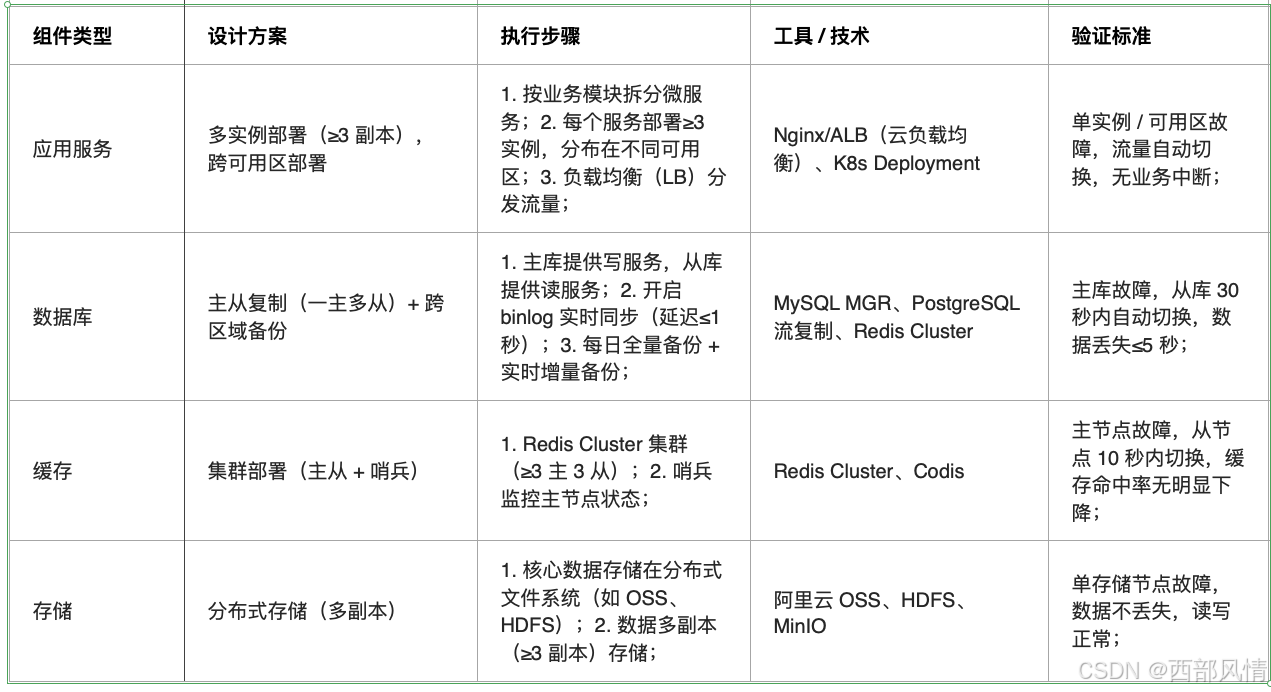
2.1.1 冗余设计
避免单点故障
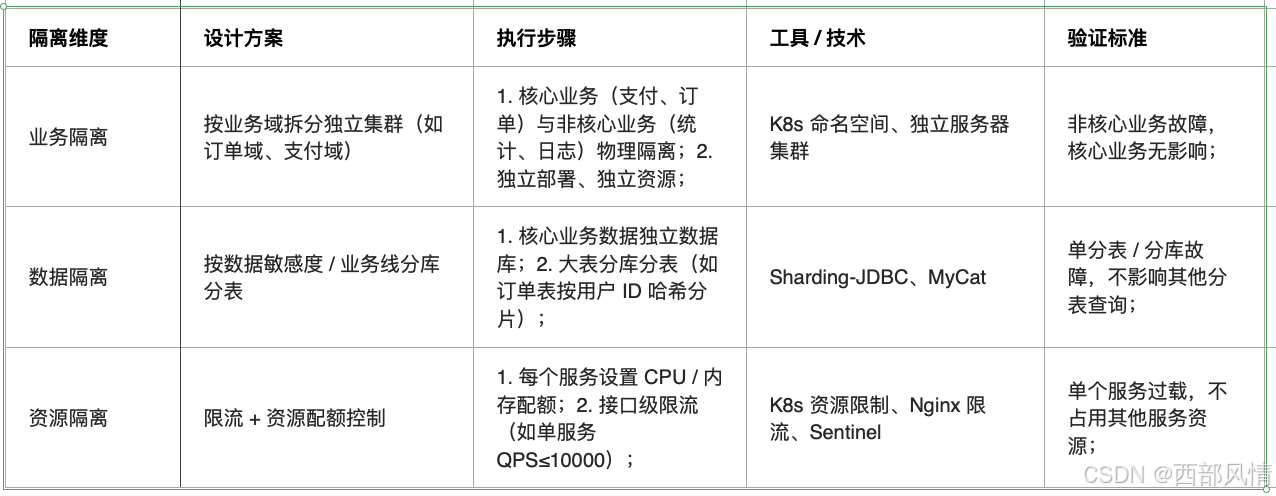
2.1.2 隔离设计
故障不扩散
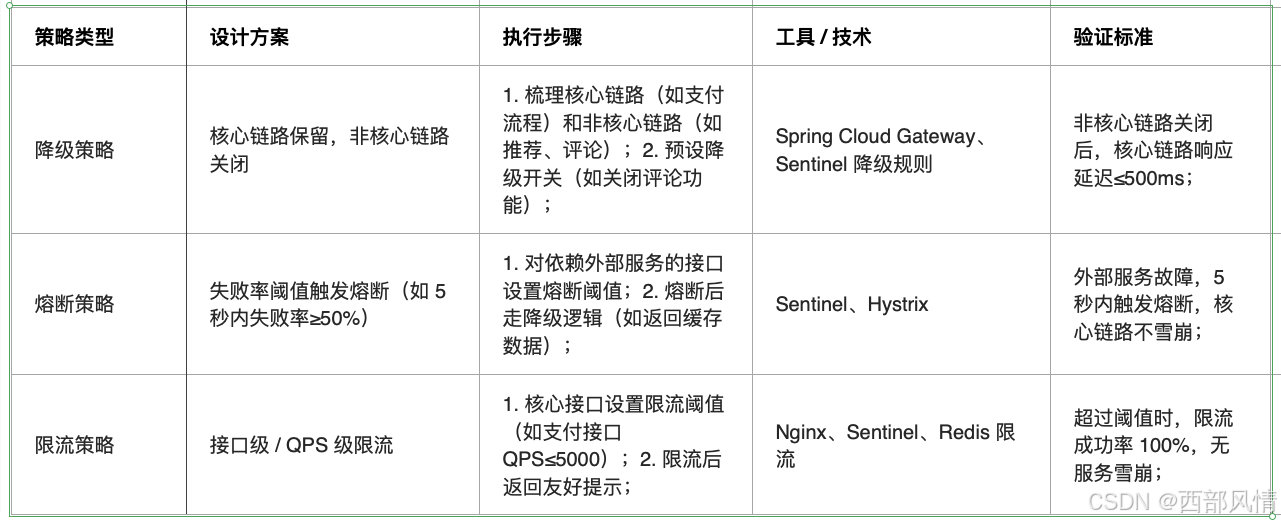
2.1.3 降级熔断
过载时,保护核心链路
2.1.4 设计输出物
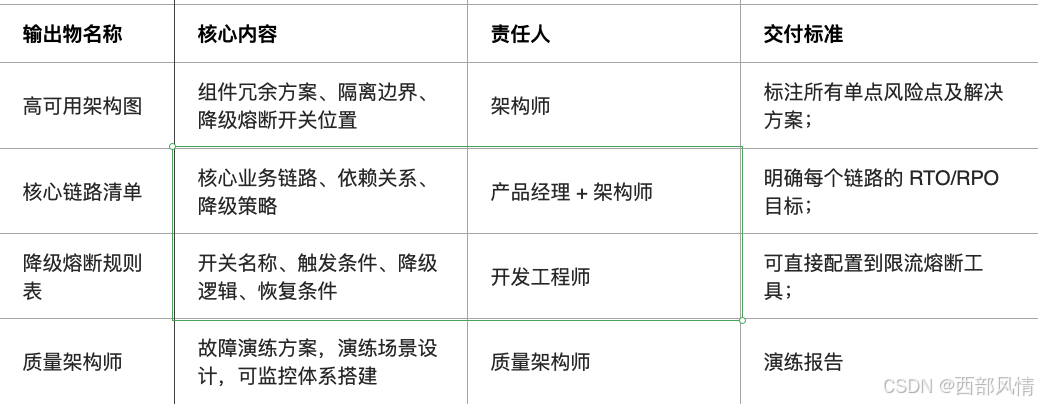
3 治理机制
架构设计后,需通过治理机制确保高可用状态持续维持,避免 "设计归设计,执行归执行"状态。
3.1 核心治理机制
快速优先落地,见成效的机制
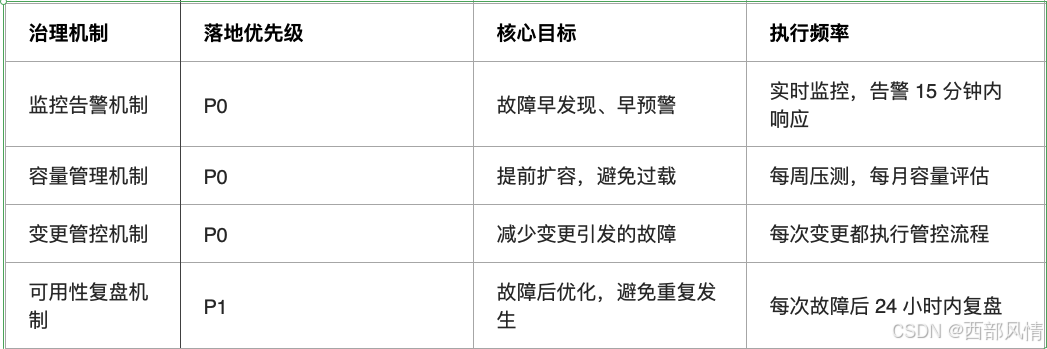
3.1.1 监控告警机制
故障早发现
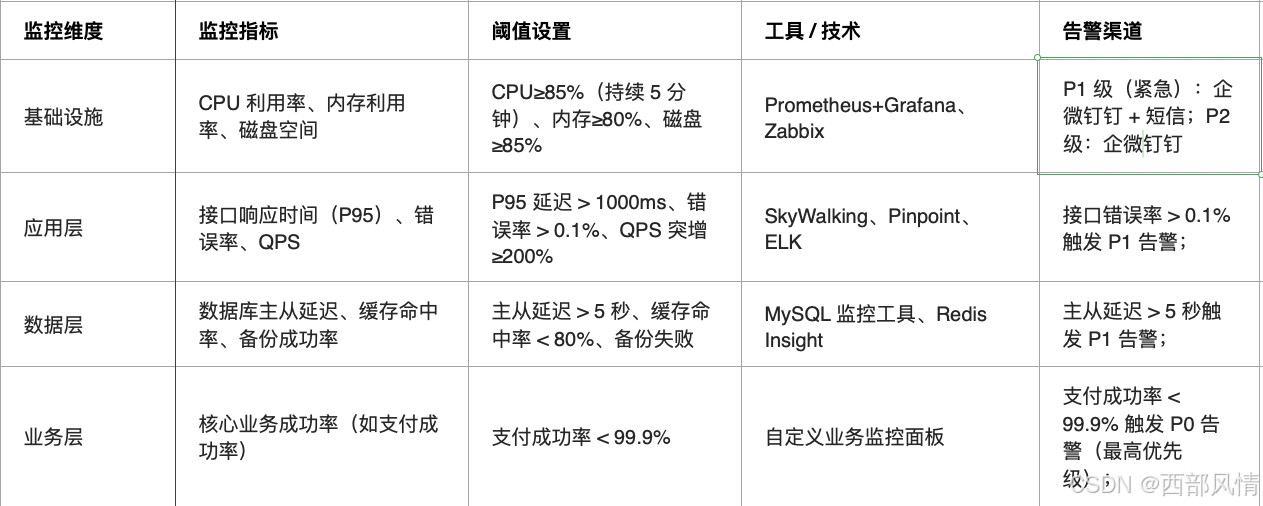
搭建步骤
- 梳理 "基础设施→应用→数据→业务" 四级监控指标(参考上表);
- 搭建可视化监控大盘(Grafana/SkyWalking),核心指标实时展示;
- 配置告警规则(避免误报:同一指标连续 3 次触发才告警);
- 建立告警响应流程(15 分钟内响应,30 分钟内初步定位根因)。
3.1.2 容量管理机制
避免过载故障
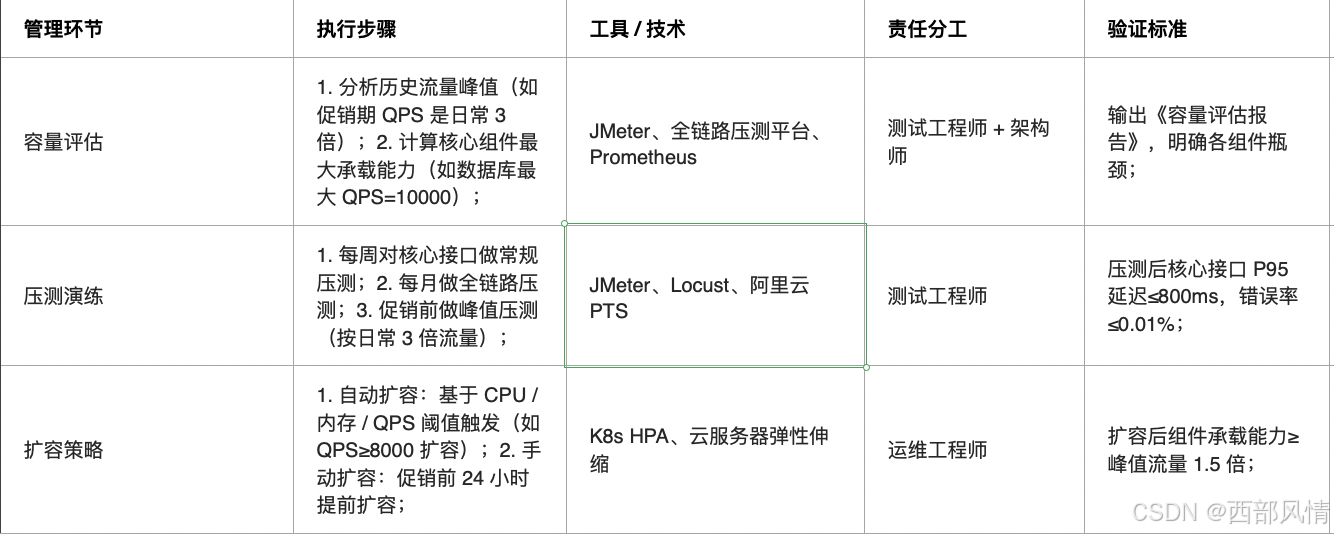
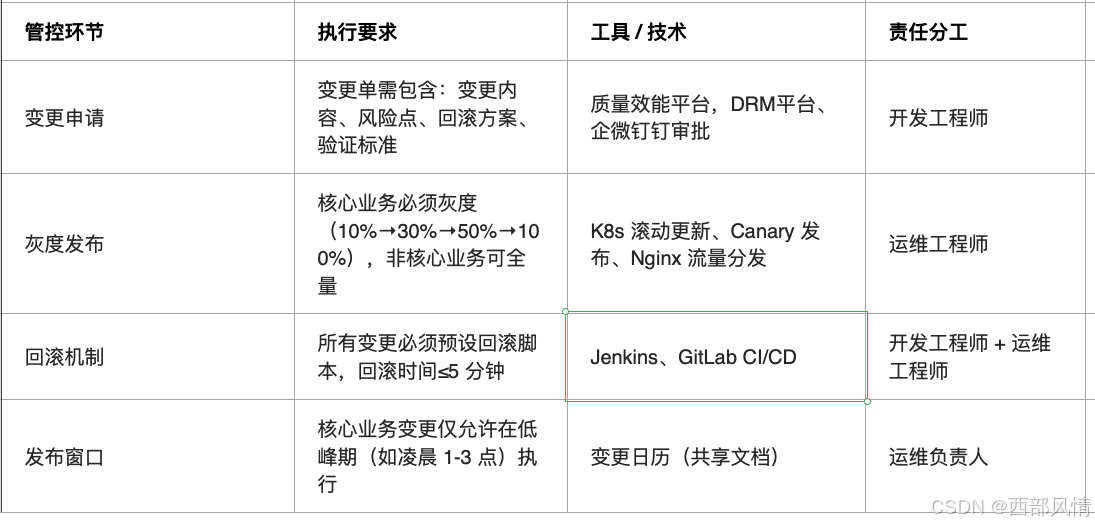
3.1.3 变更管控机制
减少人为『故障』
变更(代码发布、配置修改、版本升级)是故障的主要诱因(占比≥70%),需通过 "灰度、审批、回滚" 三重保障:

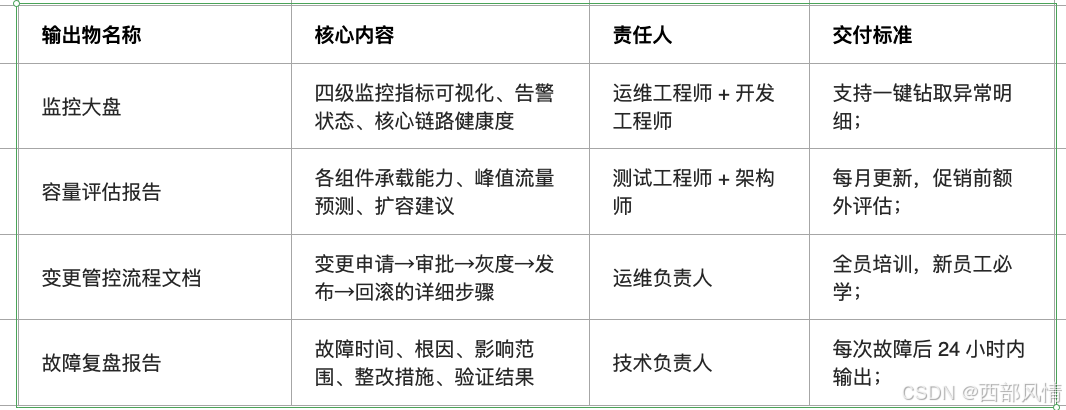
3.1.4 治理落地输出物
4 风险防范
将故障降到最小损失,即使架构设计和治理到位,故障仍可能发生,需通过 "故障演练、灾备建设、应急响应" 三大手段,兜底故障损失,确保快速恢复。
4.1 故障演练
提前显露风险(混沌工程)
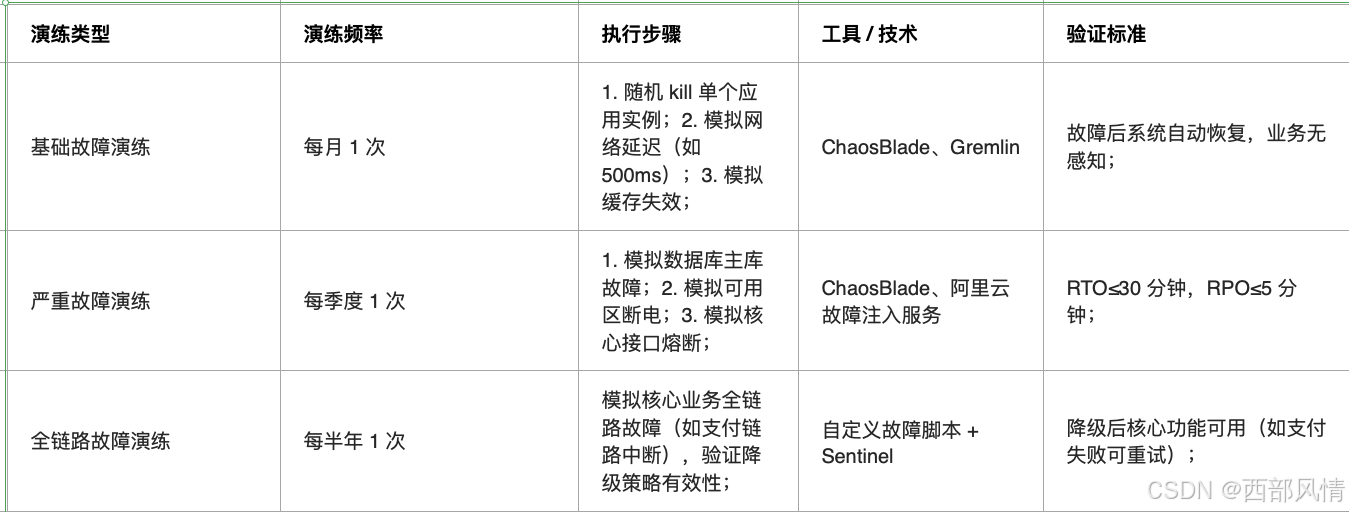
执行注意事项:
- 无监控,不演练,无应急,不演练;
- 演练前必须通知业务团队,选择低峰期执行;
- 演练前备份数据,准备回滚方案;
- 演练后输出《故障演练报告》,整改暴露的问题。
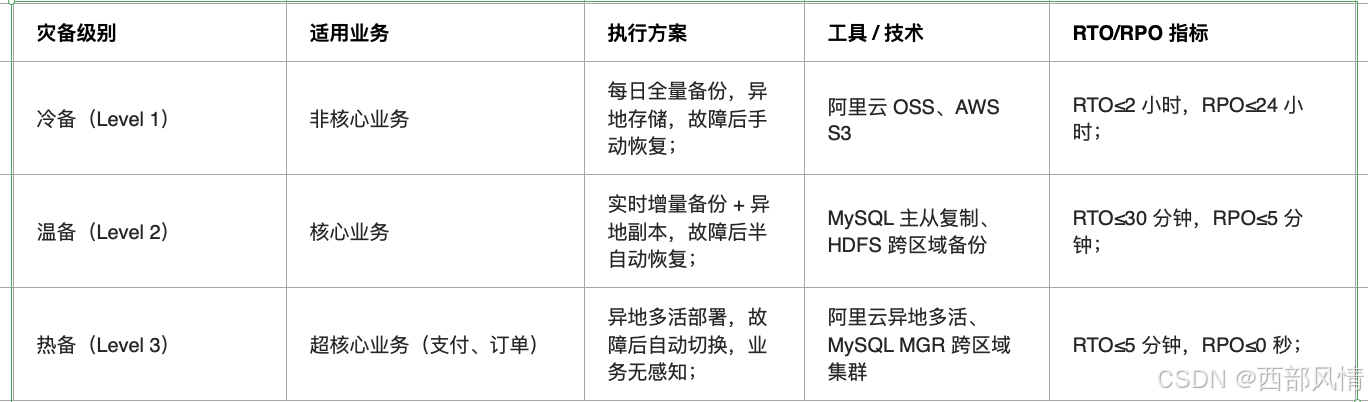
4.2 灾备建设
数据不丢失,业务可恢复
4.3 应急响应
故障发生后,快速止血
4.3.1 应急响应流程:

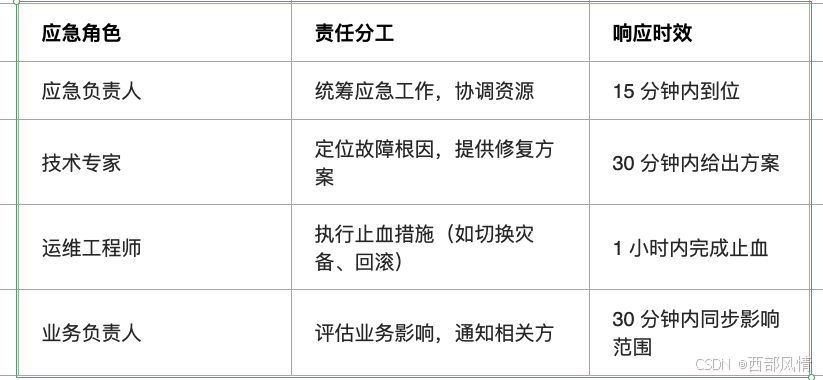
4.3.2 应急响应输出成果
- 《应急响应报告》:记录故障处理全流程、根因、整改措施;
- 《业务恢复验证报告》:验证核心功能是否恢复正常;
5 落地保障
确保方案执行到位,高可用落地的最大障碍是 "执行不力",需通过 "组织保障、工具支撑、考核机制" 确保方案落地。
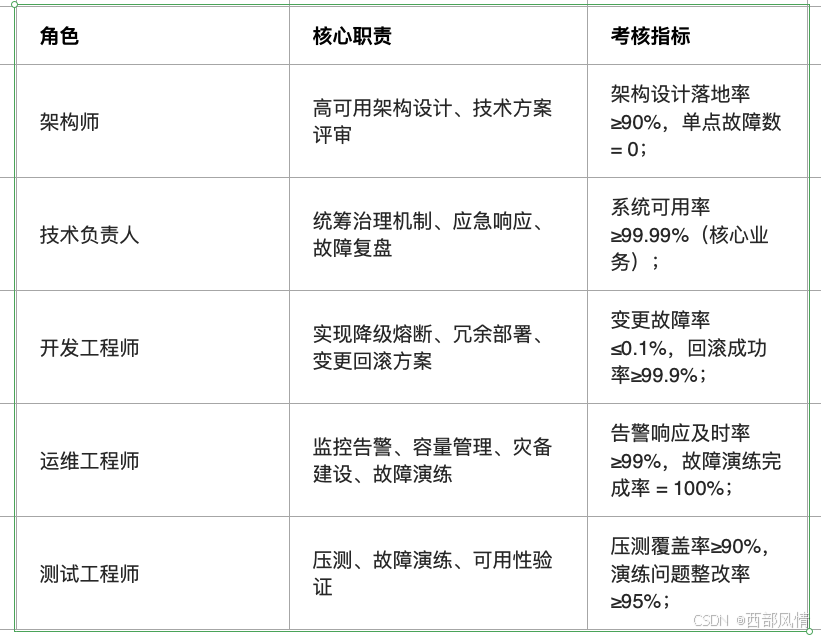
5.1 组织保障:明确责任分工
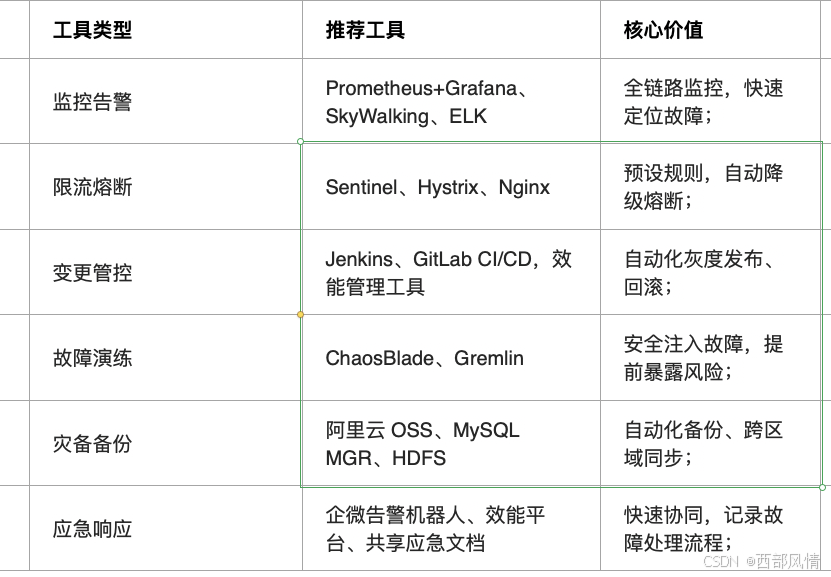
5.2 工具支撑:降低落地成本
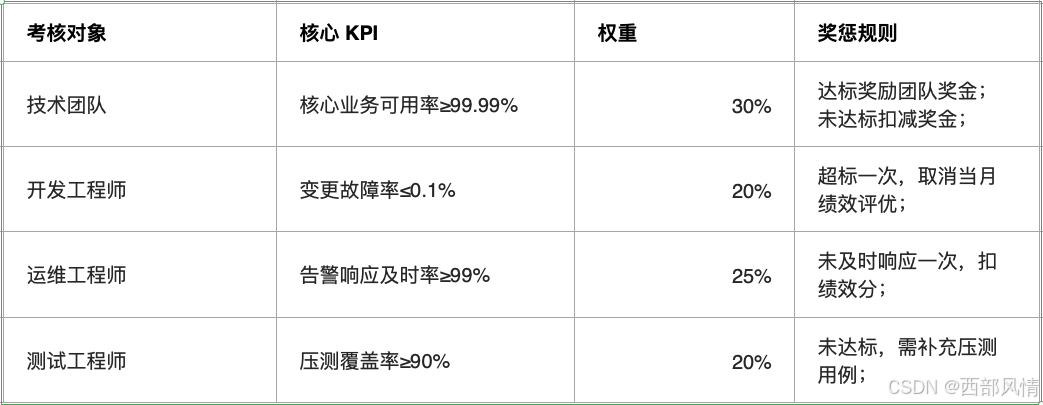
5.3 考核机制:绑定高可用目标
6 分阶段落地计划
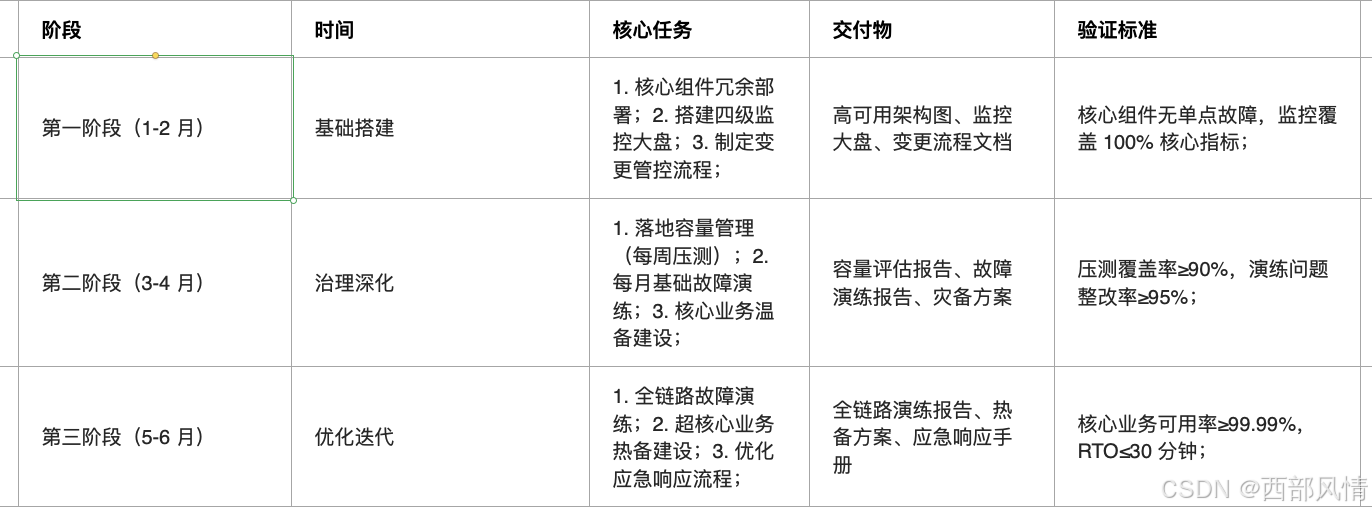
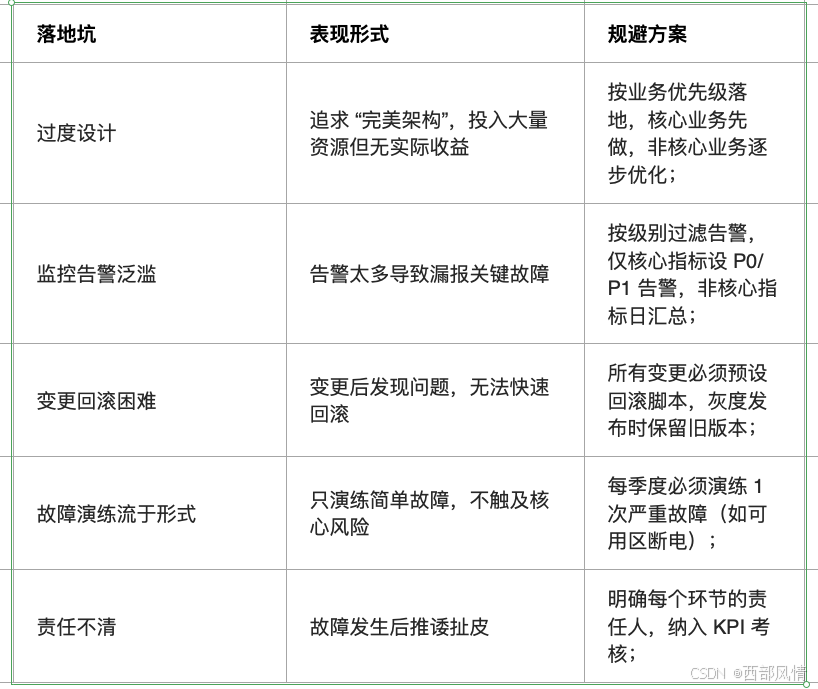
7 常见落地坑与规避方案
8 总结
高可用架构设计治理及风险防范的落地核心是 "先基础后高级、先核心后非核心、先预防后兜底":
- 设计阶段:用冗余、隔离、降级筑牢技术基石,避免单点故障;
- 治理阶段:用监控、容量、变更管控持续保障,避免可用性滑坡;
- 防范阶段:用故障演练、灾备、应急响应兜底损失,确保快速恢复;
- 落地阶段:用组织、工具、考核确保执行到位,形成闭环迭代。
- 关键是 "量化目标、明确责任、工具支撑、持续验证",避免纯理论堆砌,让高可用方案真正 "可落地、可执行、可验证"。