ControlNet 插件
ControlNet 概述
ControlNet(控制网)是由 lllyasviel 团队于 2023 年提出的神经网络架构,核心是为了解决在 Stable Diffusion 中如何让图像生成变得更加可控的问题,是 Stable Diffusion 迈向工业化的非常重要的一步。
ControlNet 通过预处理器提取参考图中的姿态、深度、边缘等结构信息,再由 ControlNet 模型转换为检查点模型能够理解的生成条件,让生成图像精准遵循参考图的布局与结构,彻底解决生图结构失控的痛点,是 Stable Diffusion 中实现精准控图的核心插件。
ControlNet 插件的应用场景:
- 插画创作:基于线稿生成高精度彩色插画,保留线条构图。
- 角色设计:基于姿势参考图生成指定动作的角色形象,如游戏角色战斗姿势等。
- 建筑可视化:根据图纸生成写实风格的建筑效果图。
- 3D 模型辅助生成:根据深度图、法线图控制生成图像的空间立体感,辅助 3D 建模纹理绘制。
- 摄影修图:基于照片生成二次元风格图像,保留人物构图。
图生图与 ControlNet 插件的区别:
- 图生图是基于已有图像,通过调整参数、添加提示词等让模型生成新图像,对原图依赖度高,主要是在原图基础上修改或拓展。
- ControlNet 是 Stable Diffusion 插件,虽本质也是图生图,但可借助多种控制类型(如边缘线稿、姿态、深度等)和预处理器,在遵循原构图下更灵活、精确地控制图像生成,对原图破坏小,自由度与可控性更高。
ControlNet 插件的发展史:
- V1.0(2023-03):初代发布,仅 8 支持种基础预处理器(Canny、HED、Midas Depth、OpenPose 等),实现边缘、姿态、深度等核心控制。
- V1.1(2023-11):扩展至 14 种,新增 Lineart、Shuffle、Reference 等预处理器,优化训练数据与稳定性,适配更多场景。
- SDXL 适配(2023-2024):插件更新支持 SDXL,推出适配大模型的专用预处理器(如 SDXL - ControlNet Tile、Depth 等),强化细节控制,同步兼容 SD1.5 生态。
- 多模态与精细化(2024-2025):新增 InstructP2P、Reference 、PuLID、DWPose 等预处理器,引入 ONNX 加速、AIO 集成预处理,提升效率与兼容性,覆盖文控、脸部优化、风格迁移等多元需求。
- 社区与生态拓展:第三方衍生预处理器(如针对 FLUX 的适配版)涌现,预处理器与模型解耦更灵活,支持多预处理器叠加,兼顾显存优化与控制精度平衡。
ControlNet 安装
ControlNet 插件的安装与使用:https://github.com/lllyasviel/ControlNet
LiblibAI 已内置 ControlNet 插件,在本地部署的 Stable Diffusion 中使用 ControlNet,需要确保 ControlNet 插件已经安装到 WebUI 中。
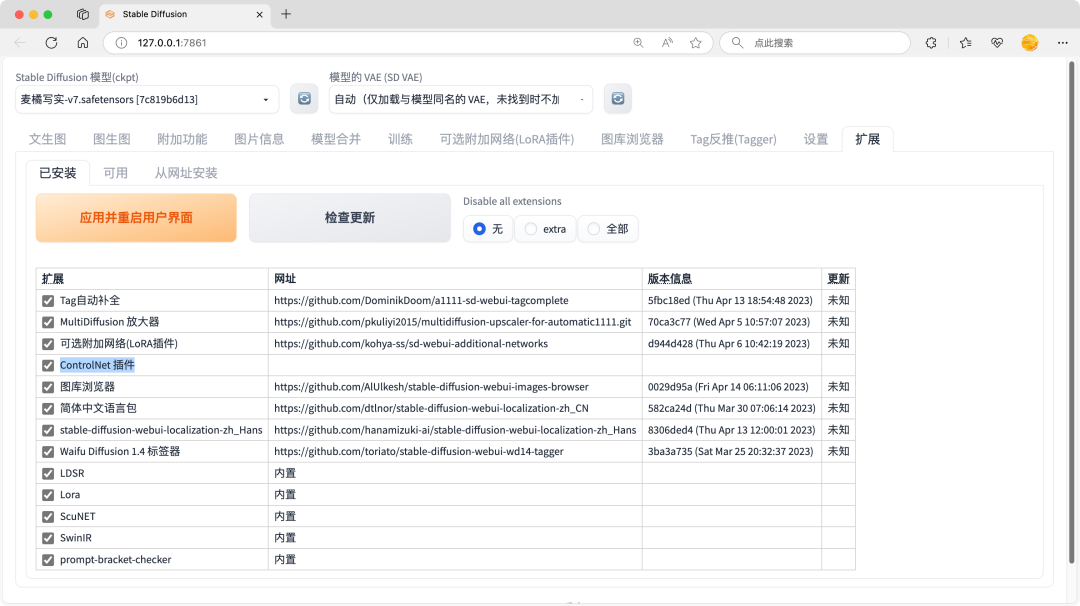
ControlNet 仅凭插件本体是无法正常运行的,必须结合特定的 ControlNet 预处理器、模型,以实现不同的功能效果。
ControlNet 基本参数
ControlNet 面板主要分为图像上传板块、控制类型板块、控制参数板块。
在图像上传板块可以上传参考图,通过输入参考图像来引导 AI 生成在细节、风格、结构等方面更符合创作者期望的图像,实现对图像生成过程的精细控制。
在控制类型(Control Type)板块中,可以选择控制的模式,每一种模式对应不同的预处理器,也对应不同的 ControlNet 模型,在选择时,检查点模型、控制模式、预处理器、ControlNet 模型四者一一对应。
ControlNet 可使用的预处理器非常多,允许创作者通过引入额外的控制信号来引导图像生成的过程,从而生成更精确、更丰富的效果,预处理器就像是给 AI 翻译图像语言的工具。
- 画轮廓:用边缘检测预处理器,把照片里的物体轮廓线条提取出来(像自动生成线稿),告诉 AI 按这个形状来画。
- 看深度:用深度检测预处理器,分析照片里物体的远近关系(比如谁在前、谁在后),让 AI 生成的新图有类似的空间感。
- 学姿势:用姿态检测预处理器,识别照片里人物的动作(比如抬手、走路),让 AI 生成的人物摆出一样的姿势。
在控制参数板块中,可以调整相关参数:
- 完美像素:自动让参考图的分辨率、比例和最终生成图保持一致,避免因尺寸不匹配导致的结构变形。
- 允许预览:在生成最终图像前,先预览预处理器输出的控制图,能提前确认结构是否符合预期,避免生成后才发现控制图有问题。
- 控制权重(Control Weight):取值范围为 0~2,表示 ControlNet 对生成图像的控制程度,数值越大,参考图的引导作用越强,生成图像越贴近参考图的特征。
- 上传蒙版:用于指定参考图里需要修改的白色区域和保留不动的黑色区域,实现精准局部重绘。
- 起始步数(Starting Control Step):取值范围为 0~1,表示 ControlNet 在图像生成过程中,从哪个阶段开始发挥作用。0 表示从生成过程一开始就起作用,数值越接近 1,ControlNet 介入越晚,前期主要由基础模型按常规方式生成。
- 完结步数(Ending Control Step):取值范围为 0~1,表示 ControlNet 在图像生成过程中作用结束的阶段。1 表示一直作用到生成结束,数值越接近 0,ControlNet 提前结束控制,后期主要由基础模型自由生成。
- 预处理器分辨率(Preprocessor Resolution):在使用预处理器对图像进行处理时,图像所被设定的分辨率大小,其决定了预处理器处理图像的精细程度,数值越高,处理后的图像细节越丰富,但计算量也会增大,处理耗时增加。
- 控制模式(Control Mode):用于调节在图像生成中提示词和 ControlNet 上传图像对最终生成结果的影响侧重,可选均衡、更注重提示词、更倾向于让 ControlNet 自由发挥。
- 图片缩放模式(Resize Model):决定参考图适配生成需求的方式,可选拉伸、裁剪、填充。
ControlNet 支持同时使用多个预处理器(即叠加多个 ControlNet 控制单元),只需在界面中开启多个 ControlNet 选项卡,分别选择不同预处理器、上传对应控制图即可。
ControlNet 基本用法
以生成一张人物写实图为例,参考生成参数如下。
- ckpt 检查点模型:麦橘超然 majicFlus
- 正向提示词(中文):一个女孩,在海边,穿着白色长裙,长袖,戴着太阳帽,面带微笑
- 正向提示词(英文):A girl,over the sea,white long dress,long sleeves,sun hat,smile
- 负向提示词:ng_deepnegative_v1_75t,(badhandv4:1.2),EasyNegative,(worst quality:2)
- 采样方法:Euler a
- 迭代步数:30
- 图片尺寸:768x1024
- 提示词引导系数:3.5
生成效果:

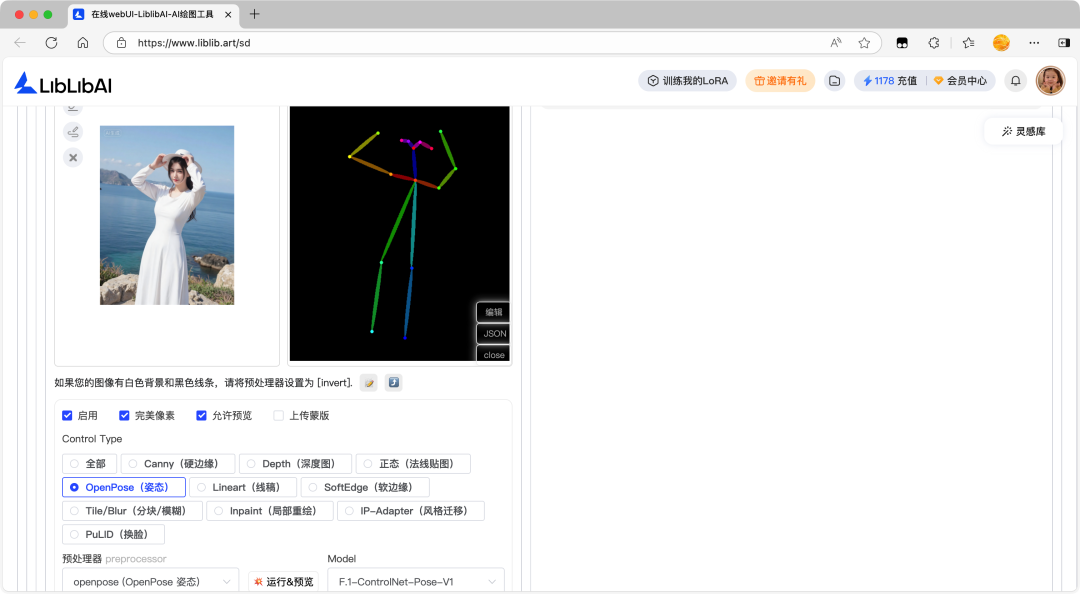
以上图为例,使用 ControlNet 控制人物姿态,参考插件参数如下。
- 完美像素:启用
- 控制类型:OpenPose 姿态
- 预处理器:openpose(OpenPose 姿态)
- ControlNet 模型:F.1-ControlNet-Pose-V1
- 控制权重:1.5
- 起始步数:0
- 完结步数:0.7
- 控制模式:均衡
- 图片缩放模式:填充
爆炸运行 & 预览效果:
调整生成参数如下。
- 正向提示词(中文):一个男孩,在海边,穿着白色裤子,长袖,戴着太阳帽,面带微笑
- 正向提示词(英文):A boy,by the sea,wearing white pants,long sleeves,wearing a sun hat,with a smile on his face
- 图片数量:4
生成效果:




ControlNet 预处理器
OpenPose 姿态
OpenPose 是一种基于计算机视觉的人体姿态估计算法,通过检测人体关键点(如关节、面部特征点)并连接成骨骼结构,精确捕捉人物的动作和姿态。
OpenPose 算法通常检测以下关键点:
- 身体:18 个关键点(头部、颈部、肩膀、肘部、手腕、髋部、膝盖、脚踝等)。
- 手部:每只手 21 个关键点(手指关节和手掌)。
- 面部:70 个关键点(眼睛、眉毛、鼻子、嘴巴等)。
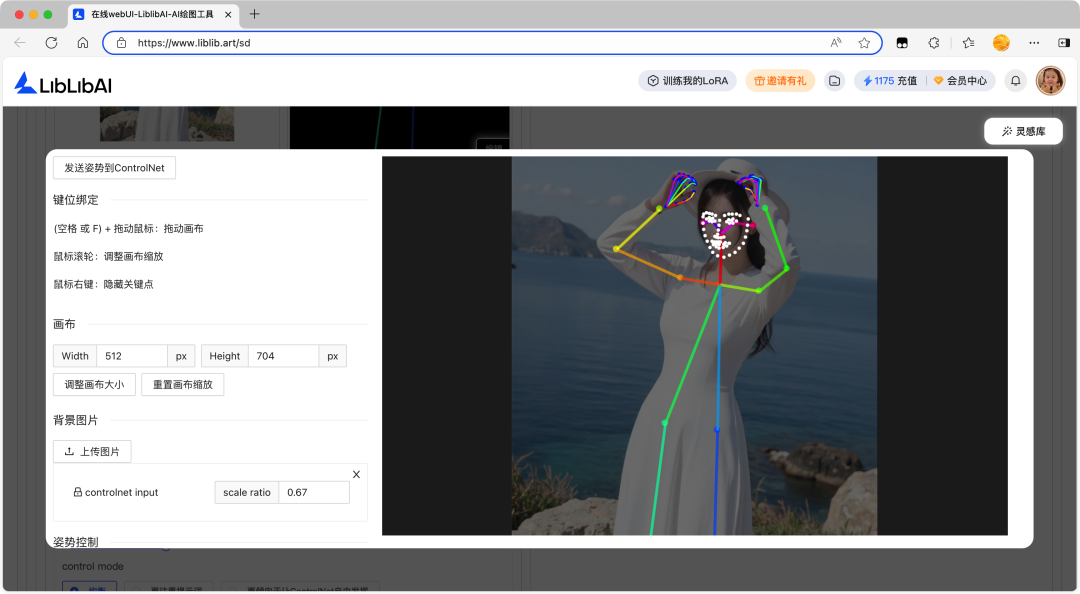
OpenPose 姿态预处理器允许创作者通过上传姿态参考图或直接绘制骨架来控制生成图像中的人物姿势。
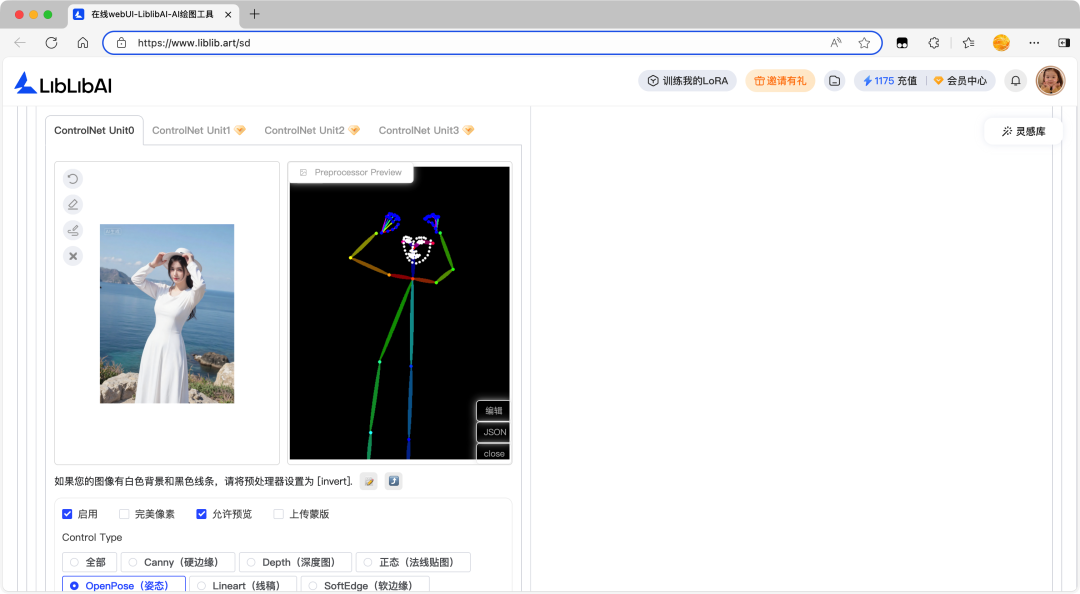
OpenPose 姿态预处理器的应用场景:
- 人物动作控制:让模型生成的人物摆出指定姿势如跳舞、运动,比如输入瑜伽动作姿势图,模型就能画出对应姿势的插画。
- 多人物场景协调:控制画面中多个人物的互动姿势,避免人物动作僵硬或冲突。
- 动画/游戏角色设计:快速生成角色的关键帧动作,减少手绘工作量,后续可导入 3D 软件细化。
OpenPose 姿态预处理器的关键参数:
- 通过调整不同的预处理器,可以单独对姿态、手部等组合进行识别,也可以使用精度更高的预处理器得到更准确的姿势。
- 如:openpose full 高精度检测全身姿态、openpose hand 检测姿态及手部、openpose faceonly 仅检测脸部等。
在 OpenPose 姿态预处理器中,可以打开姿态编辑器调整姿态以重塑动作。
Canny 硬边缘
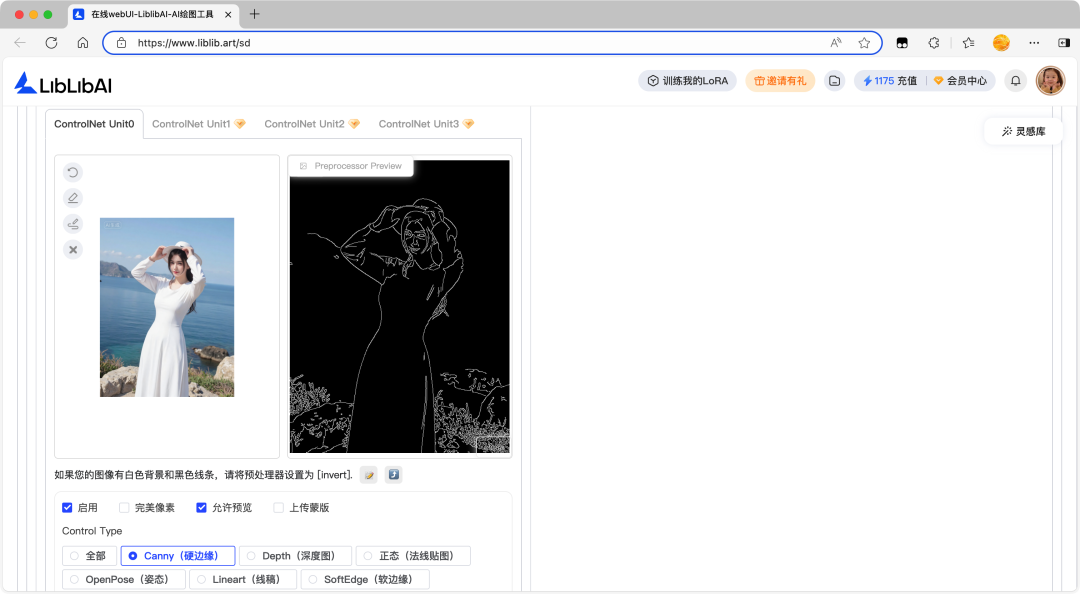
Canny 硬边缘预处理器用于提取图像的边缘轮廓,生成清晰的线条引导,且线条只有黑白两色,便于模型理解和遵循。
Canny 硬边缘预处理器的应用场景:
- 漫画插画风格生成:用清晰线条勾勒人物轮廓,搭配提示词生成日系动漫效果,低阈值保留发丝细节,高阈值强化主体轮廓。
- 照片转线条画:将写实照片转为线条引导的艺术图,通过调整阈值控制线条疏密,适合制作极简风格海报或创意头像。
- 建筑或机械设计可视化:突出硬边缘结构,帮助模型理解几何形状,生成工业设计草图或建筑外观渲染图。
- 线稿上色:导入手绘线稿图,提取清晰轮廓,搭配风格提示词让 AI 精准填充色彩,既保留线稿的结构感,又能快速生成多样配色的插画。
Canny 硬边缘预处理器的关键参数:
- 高低阈值(High/Low Threshold):阈值越高,识别出来的线条越少。
- 如果上传的参考图是白色背景和黑色线条的图,预处理器直接设置为 invert 反转。
SoftEdge 软边缘
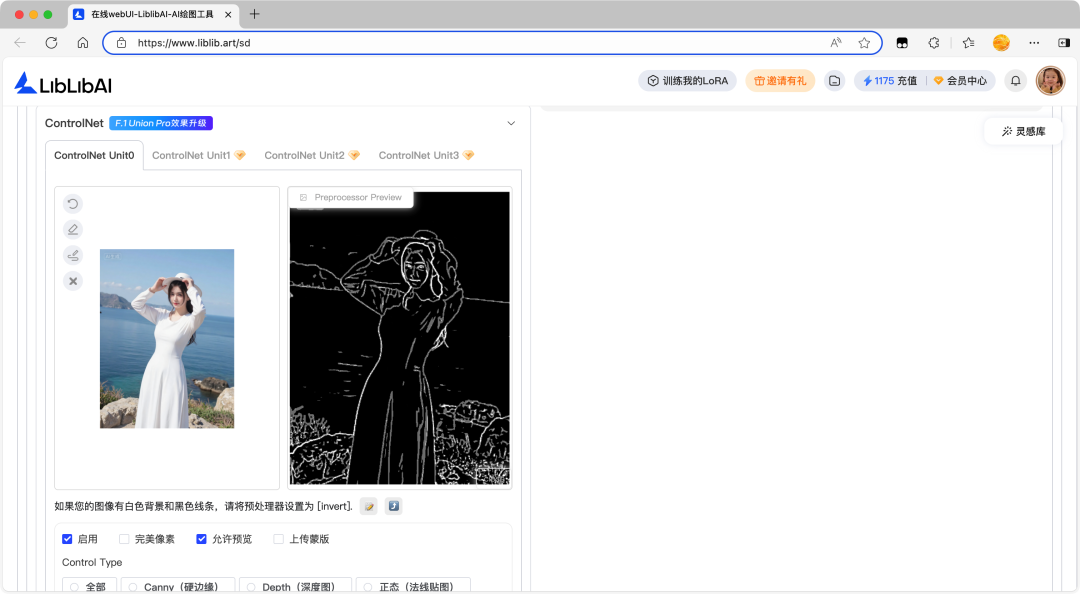
SoftEdge 软边缘预处理器用于处理图像边缘轮廓信息,目标是识别并区分图像中各种形状(如直线、圆弧等)的边缘。
SoftEdge 软边缘预处理器的应用场景:
- 艺术插画创作:绘制梦幻、柔和风格插画时,让元素边缘自然融合过渡,比如画一朵朦胧的花朵、缥缈的云朵,营造诗意氛围。
- 产品渲染图:处理产品渲染图中产品与背景的衔接,让产品边缘不生硬,比如电子产品融入场景时,使产品与周围环境过渡自然,增强真实感。
- 人像摄影后期:修饰人像照片,柔化人物发丝、皮肤边缘,弱化瑕疵,呈现更自然柔和的肤质与轮廓,提升人像美感。
- 立体艺术字:生成带有柔和渐变边缘的艺术字效果,让字体轮廓不生硬,与背景的光影、色彩自然衔接。
SoftEdge 软边缘预处理器的关键参数:
- 通过调整不同的预处理器变体,可适配不同精度与安全需求。
- 如:hed 边缘柔和度高,pidinet 边缘更精准,teed 偏细腻线条,anyline 兼容多种线稿类型。
- 带有 safe 的预处理器在生成过程中加入了安全机制,可有效避免生成包含不良或敏感内容的边缘信息,适用于儿童绘本绘制、正规出版物配图制作等对内容安全性要求较高的场景。
Lineart 线稿
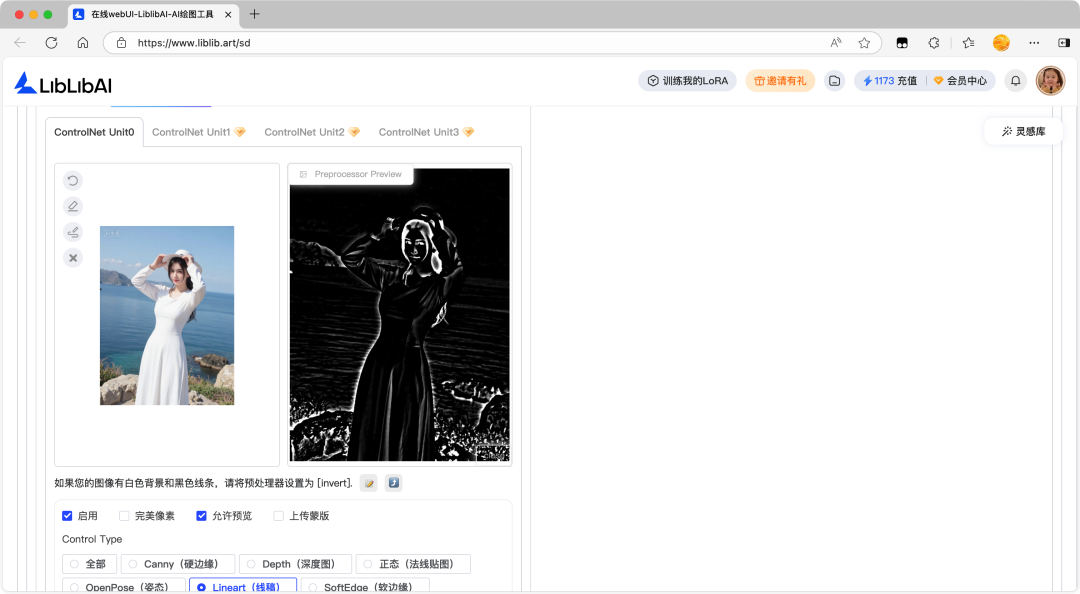
Lineart 线稿预处理器是一种用于控制图像生成过程中线稿风格的约束方式,允许创作者输入简单线条或线稿(通常只包含黑白线条,没有色彩和阴影),生成符合轮廓的完整图像。
Lineart 线稿预处理器的应用场景:
- 插画漫画创作:把照片转成干净的线稿,直接用于上色或让模型生成日系、欧美漫画等风格。
- 服装设计草图:快速生成服装轮廓线稿(如裙子褶皱、领口形状等),模型可以基于线稿填充不同材质或花纹(如蕾丝、皮革等)。
- UI 图标设计:制作简洁的界面元素或图标,线条粗细均匀,模型能保持设计风格统一。
Lineart 线稿预处理器的关键参数:
- 通过调整不同的预处理器,可以适配不同的风格类型。
- 如:anime 动漫线稿提取、realistic 写实线稿提取、standard 标准线稿提取等。
MLSD 直线
MLSD 是一种基于深度学习的直线检测算法,能够识别图像中的直线段而非简单的边缘,并将其转化为清晰的矢量线条。
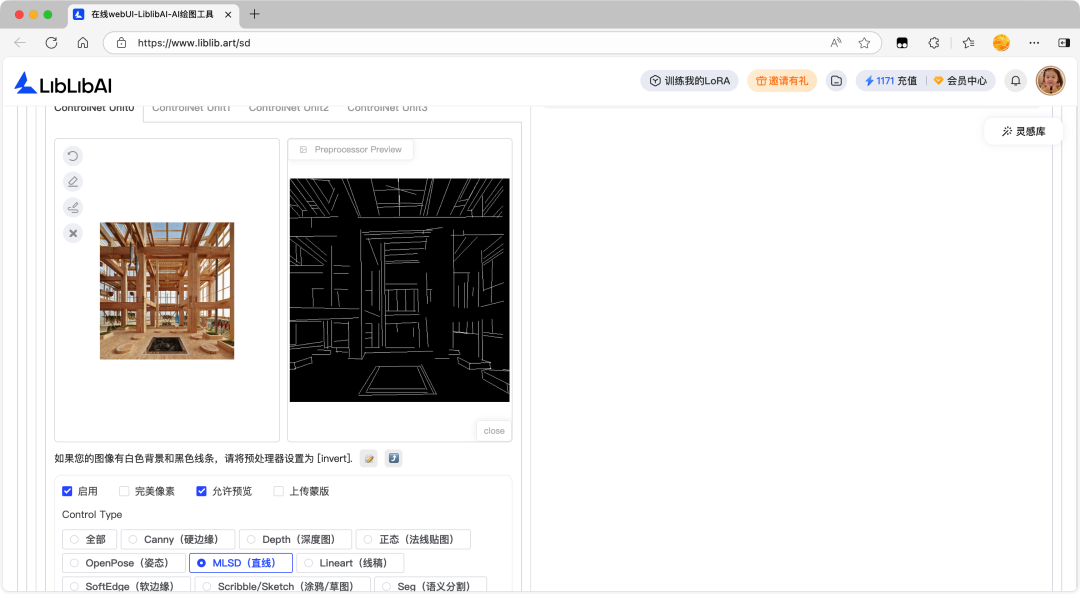
Lineart 线稿、Canny 硬边缘、SoftEdge 软边缘、MLSD 直线的异同:
- Lineart 线稿是专门提取干净的绘画线稿,适配不同风格的线条感,提供更加细致的线条识别和控制。
- Canny 硬边缘是提取黑白硬轮廓边缘,侧重物体形状边界。
- SoftEdge 软边缘是提取柔和语义边缘,边缘过渡自然不生硬。
- MLSD 直线是精准提取图像中的直线与几何轮廓,过滤曲线、纹理等干扰信息,仅聚焦规则几何线条的约束。
- 四者核心差异是线条的提取范围、风格属性和硬朗程度,前三者覆盖全类型边缘 / 线条,MLSD 仅针对直线类几何结构。
MLSD 直线检测预处理器的应用场景:
- 建筑设计效果图生成:根据建筑草图生成精准比例的别墅、写字楼效果图,保证墙体、门窗、梁柱的直线笔直。
- 室内空间布局设计:锁定房间的墙面、地板、天花板的直线结构,生成不同风格的家装效果,避免空间比例失衡。
- 工业产品设计:生成电子产品、家具、工具等带规则几何结构的产品图,保证产品的线条规整、造型精准。
- 线稿优化与风格化:将粗糙的建筑线稿转化为写实或插画风格的成品图,保留原始线稿的几何结构。
- 几何风格艺术创作:生成极简主义、构成主义风格的艺术作品,强化画面的直线分割与几何美感。
MLSD 直线检测预处理器的关键参数:
- MLSD Value Threshold(MLSD 值阈值)用于筛选直线检测结果,其值越高对直线像素值要求越严,检测出的直线越少。
- MLSD Distance Threshold(MLSD 距离阈值)用于判断两条线段能否合并为一条的依据,其值越大允许线段间距离越大,直线检测结果更简洁。
Depth 深度图
Depth 即深度,源于三维概念,描述物体间远近关系,图像只有黑白两色,白色表示距离镜头近,黑色表示距离镜头远,深度图能将图像采集器到场景各点的距离作为像素值,体现画面物体三维深度关系。
Depth 深度图预处理器通过传递图片空间信息,指导 AI 图像生成,辅助指定构图、姿势和 3D 结构等,在保持原始构图时生成新颖图像,比如创建有空间感的多层次场景,让 AI 理解动作层次和空间信息。
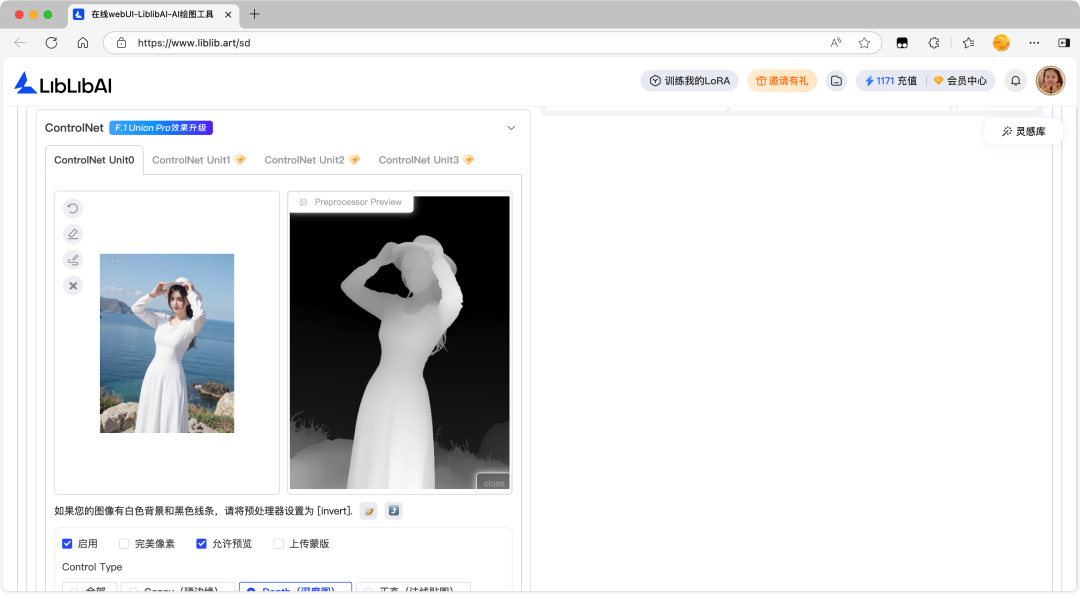
Depth 深度图预处理器的应用场景:
- 3D 场景生成与立体效果:给模型输入带深度信息的图(近实远虚),生成有纵深感的场景,比如模拟森林深处、走廊尽头的空间层次。
- 物体遮挡关系控制:让模型知道谁在前、谁在后,比如画人物拿杯子时,用深度图确保手在杯子前面,避免元素错位。
- 景深特效模拟:通过调整深度范围,让模型生成类似相机大光圈效果,比如拍人像时虚化背景突出主体,或拍微距时虚化前景聚焦昆虫。
Depth 深度图预处理器的关键参数:
- 通过调整不同的预处理器,可以灵活匹配不同场景的空间精度需求,快速获取从大场景纵深到精细局部层次的深度控制图。
- 如:Midas 速度快适配大场景,Zoe 全局均衡通用性强,Leres/Leres++ 细节拉满适合精细构图,DepthAnything 泛化性佳适配任意风格。
Tile/Blur 分块/模糊
Tile/Blur 分块/模糊预处理器是 ControlNet 里负责高清修复与大图生成的预处理器,核心作用是拆分图像为多个小块并保留局部细节特征,避免大尺寸生图时出现模糊、重复纹理或细节丢失的问题,同时柔化块与块之间的拼接痕迹,让画面更自然连贯。
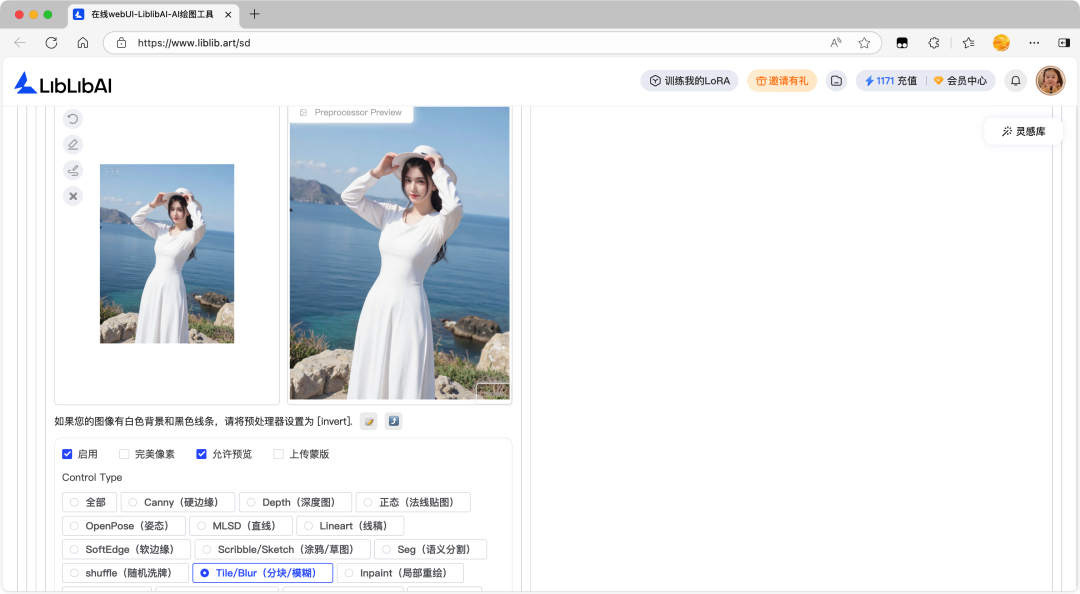
Tile/Blur 分块/模糊预处理器与 Tiled Diffusion 插件的异同:
- 相同:都可以用于放大场景的分块处理。
- 原理不同:Tile/Blur 分块/模糊预处理器先提取原图分块特征作控制图,通过 ControlNet 模型约束生成,而 Tiled Diffusion 插件在潜空间分块,通过算法逐块生成并拼接。
- 显存控制不同:Tile/Blur 分块/模糊预处理器显存占用低,依赖 ControlNet 轻量处理,而 Tiled Diffusion 可通过分块大小、重叠区域灵活控制,小分块更省显存。
- 细节可控性不同:Tile/Blur 分块/模糊预处理器处理的细节贴合原图,创意空间受控制权重影响,而 Tiled Diffusion 插件可调分块、重叠、采样步数,还支持区域提示,自由度更高。
- Tile/Blur 分块/模糊预处理器与 Tiled Diffusion 插件经常结合使用,尤其在大图生成、低显存设备高清放大、复杂细节修复等场景,二者互补,前者控结构与细节,后者控显存与拼接,协同解决大尺寸生图爆显存、细节丢失、拼接断层三大痛点。
Tile/Blur 分块/模糊预处理器的应用场景:
- 中小尺寸图像高清放大,保留边缘与纹理细节,避免放大后模糊。
- 重复纹理(如布料、墙面、瓷砖)的拼接痕迹修复,让纹理过渡自然。
- 风格转绘时锁定原图色彩与结构(如真人漫改、插画转写实),减少风格偏移。
- 老照片、监控截图、压缩图等低质图像的细节修复,去除噪点与划痕。
- 设计稿、文献扫描件的高清化处理,适配打印与数字出版的精度要求。
Tile/Blur 分块/模糊预处理器的关键参数:
- 通过调整不同的预处理器,可以适配不同的细节与色彩需求,实现布局锁定、色彩固定或锐化增强等效果。
- 如:resample 侧重保留布局与细节、colorfix 在保留布局的同时固定色彩、colorfix+sharp 在固定色彩基础上增加锐化、blur_gaussian 通过高斯模糊调整画面景深与融合度。
Inpaint 局部重绘
Inpaint 局部重绘预处理器用于通过蒙版精准锁定需要修改的区域,对图像的局部区域进行重绘或修复。
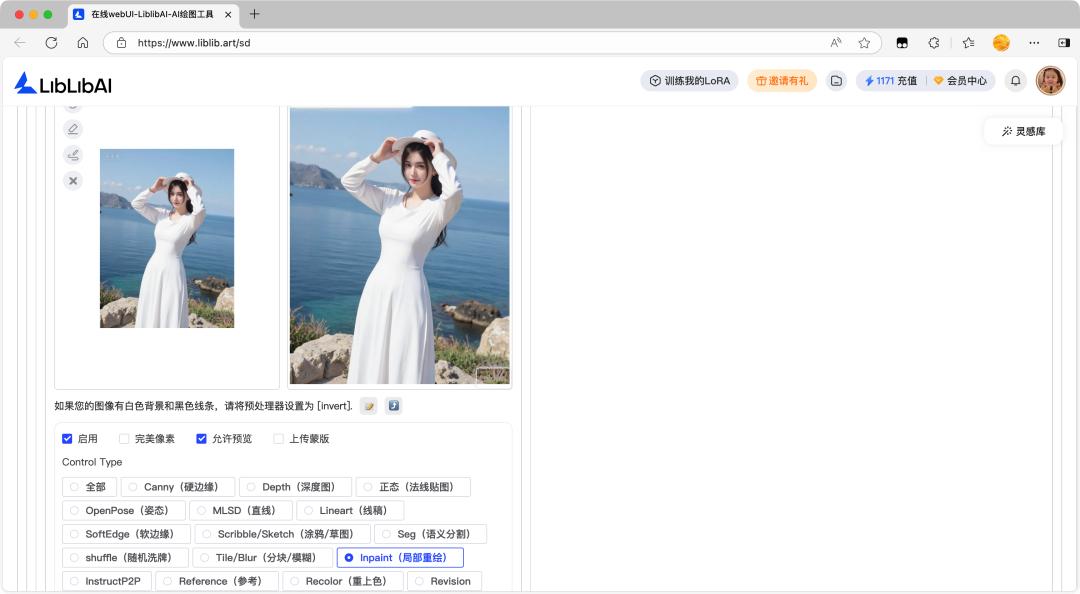
Inpaint 局部重绘预处理器与图生图局部重绘的异同:
- 相同:都能对图像局部区域进行修改,通过蒙版框选目标区域,实现精准的局部重绘需求。
- 原理不同:Inpaint 局部重绘预处理器先提取原图非蒙版区域的结构特征作为控制图,约束生成过程中全局结构不偏移,而图生图局部重绘仅依赖蒙版限定重绘范围,无额外结构约束,生成结果易受提示词影响出现整体比例失衡。
- 结构稳定性不同:Inpaint 局部重绘预处理器通过 ControlNet 模型锁定非蒙版区域的轮廓、透视、比例,即使蒙版区域较大,也能保证主体与背景的衔接自然,而图生图局部重绘在大区域修改时,易出现主体变形、背景错位等问题。
- 操作灵活度不同:Inpaint 局部重绘预处理器需在 ControlNet 面板与图生图面板配合设置,参数调节维度更多(如控制权重、引导时机),而图生图局部重绘操作更简洁,仅需在图生图面板设置蒙版与重绘幅度,适合快速简单的局部修改。
- 适配场景不同:Inpaint 局部重绘预处理器适合复杂场景的局部重绘(如人物换衣、场景替换等),而图生图局部重绘适合简单的局部修复(如去杂物、小范围补全)。
- Inpaint 局部重绘预处理器通常与多类工具(如图生图局部重绘、OpenPose 姿态预处理器等)配合实现精准且协调的图像局部优化。
Inpaint 局部重绘预处理器的应用场景:
- 人物局部修改:更换衣服款式/颜色、调整发型、修改妆容,保留人物肢体姿态与背景不变。
- 场景局部替换:将室内背景改为户外风景、把普通街道替换为赛博朋克风格街道,保证主体与新背景透视匹配。
- 图像杂物去除:删除照片中的路人、水印、电线等干扰元素,让画面更简洁,同时还原背景细节。
- 局部细节精修:优化产品图的瑕疵、增强插画的局部纹理、修复老照片的局部破损。
- 创意局部改造:给普通物体添加特效(给杯子加蒸汽、给人物加翅膀)、将平面元素改为立体效果,兼顾创意与画面协调性。
Inpaint 局部重绘预处理器的关键参数:
- 通过调整不同的预处理器,可以适配不同的局部重绘需求,实现结构精准锁定或细节保留优先的效果。
- 如:global_harmonious 兼顾蒙版区域与全局画面的色彩,光影协调,避免出现局部与背景割裂的问题、only_mask 仅聚焦蒙版区域修改,对非蒙版区域无额外约束,适合简单的局部补全、sketch 可结合草图控制蒙版区域的结构,适合需要精准控制局部形态的场景。
Segmentation 语义分割
Segmentation 语义分割预处理器可以将图像按语义类别(如人物、天空、建筑、植物、衣物等)进行像素级分割,生成带类别标签的控制图,通过精准锁定特定类别区域实现针对性生成或修改,确保不同语义区域的边界清晰、内容匹配,避免区域混淆或内容错位。
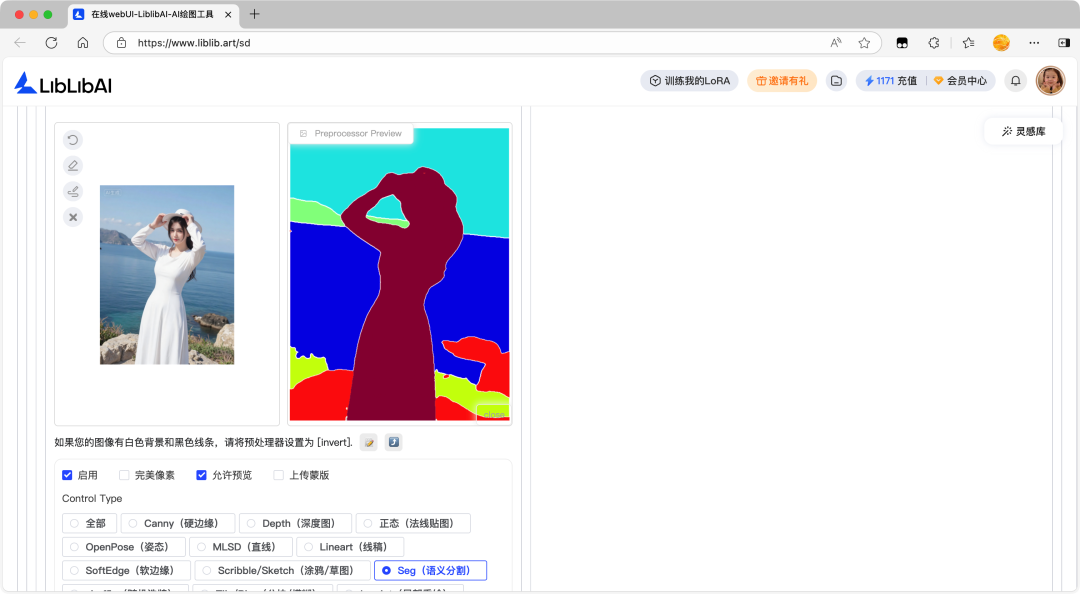
Segmentation 语义分割预处理器的应用场景:
- 场景元素批量替换:将全图的天空替换为晚霞/星空、把所有植物替换为秋季植被,保持其他区域结构不变。
- 全局风格统一调整:仅让人物区域保持写实风格,将背景建筑区域转为动漫风格,实现多风格融合。
- 多区域精准控色:统一调整全图衣物的颜色、优化所有建筑的光影色调,确保同类别区域风格协调。
- 复杂场景分层创作:先分割出人物、背景、道具等区域,分别对各区域进行细节强化,再整合生成高质量图像。
- 图像内容规整优化:修正场景中语义错位的元素(如将误判为植物的道具修正为金属材质)、统一调整同类别元素的比例与位置。
Segmentation 语义分割预处理器的关键参数:
- 通过调整不同的预处理器变体,可适配不同场景的语义分割需求。
- 如:ade20k 擅长室内外场景精细分割、coco 聚焦常见物体的粗粒度分割,能识别 80 + 类高频物体。
Recolor 重上色
Recolor 重上色预处理器是 ControlNet 中专注于图像色彩重塑的预处理器,核心作用是在严格保留原图构图、轮廓与细节结构的基础上,对图像进行重新上色或色彩优化,无需改动画面主体形态即可实现黑白转彩色、风格调色等效果,同时尽量贴合提示词定义的色彩逻辑,让色彩过渡自然且与内容匹配。
Recolor 重上色预处理器与图生图局部重绘的异同:
- 相同:都能对图像进行色彩调整,实现特定区域或整体的颜色改变。
- 原理不同:Recolor 重上色预处理器先提取原图的亮度或强度特征作为控制图,通过 ControlNet 模型约束色彩生成,确保结构不偏移,而图生图局部重绘依赖蒙版框选目标区域,通过重绘幅度控制色彩覆盖范围。
- 操作复杂度不同:Recolor 重上色预处理器无需手动框选,仅需设置参数和提示词即可实现全图或全局色彩重塑,操作更简洁,而图生图局部重绘需精准绘制蒙版,对细节操作要求更高。
- 色彩可控性不同:Recolor 重上色预处理器的色彩效果受提示词描述精度影响较大,易出现颜色串色,而图生图局部重绘通过蒙版精准锁定区域,配合提示词可实现点对点的精准色彩替换,可控性更强。
- 适用效率不同:Recolor 重上色预处理器适合全图色彩风格统一调整(如黑白照片整体上色),效率更高,而图生图局部重绘适合多区域差异化色彩修改(如同时修改衣服、头发、背景颜色),灵活性更强。
Recolor 重上色预处理器的应用场景:
- 黑白老照片、老影像的色彩还原,唤醒复古影像的岁月细节。
- 线稿/草图快速上色,保留线条结构的同时生成多样色彩方案。
- 现有图像的风格调色,如将冷色调转为暖色调、实现赛博朋克/莫兰迪等色彩风格迁移。
- 产品设计多色方案预览,在固定产品形态下快速切换不同配色。
- 低饱和/褪色图像的色彩增强,还原画面原本的色彩层次。
Recolor 重上色预处理器的关键参数:
- 通过调整不同的预处理器,可以适配不同的色彩重塑需求,实现亮度优先或饱和度优先的上色效果。
- 如:luminance 细节清晰,色彩过渡自然、intensity 色彩饱和、视觉冲击强。
IP-Adapter 风格迁移
IP-Adapter(Image Prompt Adapter)风格迁移预处理器通过参考图提取人物形象特征或画面风格特征,无需复杂提示词即可将参考特征融入生成过程,实现一键迁移 IP 形象、统一风格,同时保留模型原生的创意生成能力,兼顾精准度与灵活性。
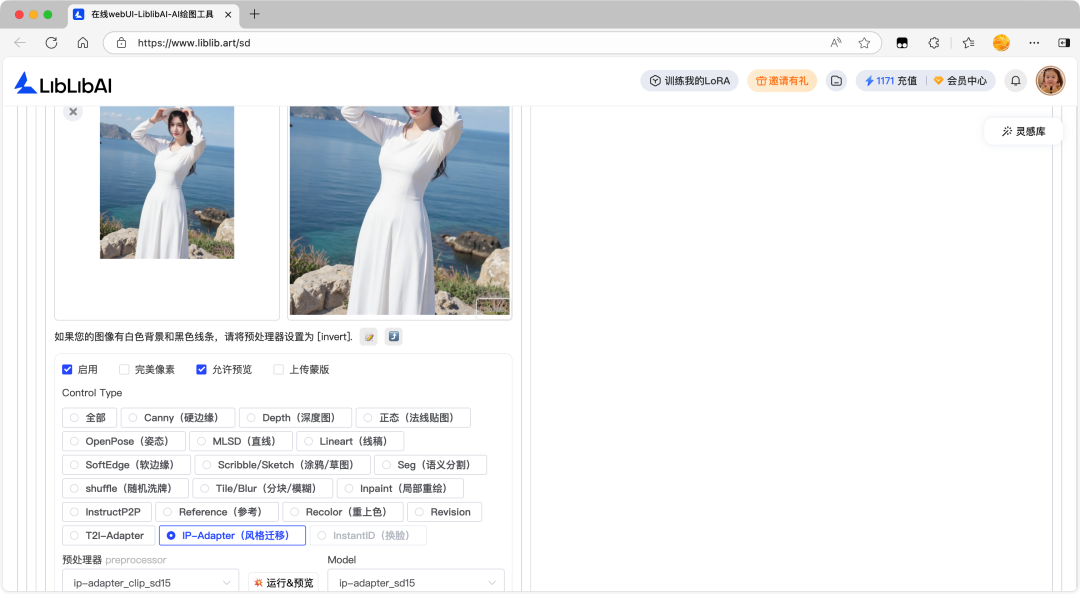
IP-Adapter 风格迁移预处理器的应用场景:
- IP 形象精准复刻:将原创角色、动漫 IP 的五官、造型迁移到不同场景,如把卡通 IP 形象融入古风场景、科幻场景。
- 多图风格统一:批量迁移参考图的艺术风格,让生成的系列图保持一致风格。
- 真人形象二次元化:基于真人照片迁移五官特征,生成同形象的动漫/插画风格作品。
- 细节化风格迁移:仅迁移参考图的局部特征(如参考图的光影色调、服饰纹理),保留主体创意生成。
IP-Adapter 风格迁移预处理器的关键参数:
- 通过选择不同的特征提取模式,适配形象 / 风格迁移需求。
- 如:clip_sd15 是 SD 1.5 中适配任意图像的基础特征复用、face_id 专注真人脸 ID 迁移,实现五官复刻、face_id_plus 额外保留面部细节与神态,精度更高。
其他预处理器
部分 ControlNet 预处理器虽使用频率略低,但能解决特定场景的控图需求,可根据创作目标灵活选用。
- NormalMap 正态法线贴图预处理器用于提取图像的法线方向信息生成贴图,强化物体的光影立体感与材质质感,适配 3D 渲染、游戏模型等场景。
- Scribble/Sketch 涂鸦/草图预处理器用于将任意手绘涂鸦、简易线稿转化为结构控制图,基于粗糙线条生成对应风格的完整图像,降低创作门槛。
- Shuffle 随机洗牌预处理器用于打乱原图的内容元素,保留风格,生成与原图风格一致但内容不同的新图像,适合快速拓展同风格素材。
- InstructP2P 指导生图预处理器用于通过文字指令精准控制图像局部修改,实现文字驱动的定向生图,无需手动蒙版。
- Reference 参考预处理器用于提取参考图的风格、内容特征,让生成图与参考图保持风格或元素一致性,兼顾创意与参考特征的复用。
- Revision 预处理器用于基于原图与文字指令,对图像进行局部或全局的优化修订,实现精准的图像迭代优化。
- T2I-Adapter 预处理器用于将文字描述转化为多维度控制信号,辅助 Stable Diffusion 生成更贴合文字指令的图像,强化文生图的精准度。