
从 Java 8 引入至今,Stream API 历经多次版本迭代,早已从基础的声明式集合处理,进化为支持并行计算、虚拟线程、有状态转换的强大工具链。
此前我曾撰写一文入门 Java Stream,文中介绍了 Java 流的基础概念,包括如何创建第一个 Java 流,以及如何通过过滤、映射和排序构建声明式流管道。我还演示了流、收集器与 Optional 的组合使用方式,并提供了基于 Java 流的函数式编程实例。若你刚接触 Java 流,建议先阅读该入门文章。
本文将超越基础范畴,深入探索 Java 流的高级应用技巧。你将系统了解 Java Stream API 中的短路操作、并行执行、虚拟线程及流汇聚器,掌握多 Java 流的合并方法,最后还会收获一份编写高效、可扩展流代码的最佳实践清单。
一、短路操作

流管道并非始终需要处理所有元素。在特定场景下,我们可借助"短路"(short-circuiting)技术,让操作一旦确定结果便立即终止流处理,从而节省时间与内存资源。
常见的短路操作如下:
findFirst():找到第一个匹配项后立即停止处理;findAny():返回任意一个匹配项(并行场景下效率更高);anyMatch()/allMatch()/noneMatch():结果一旦确定,立即终止流处理;limit(n):中间操作,仅处理前 n 个元素。
以下是 Java 流管道中短路操作的示例代码:
java
import java.util.List;
public class ShortCircuitDemo {
public static void main(String[] args) {
List<String> names = List.of("Duke", "Tux", "Juggy", "Moby", "Gordon");
boolean hasLongNames = names.stream()
.peek(System.out::println)
.anyMatch(n -> n.length() > 4);
}
}
该管道的输出结果为:
markdown
Duke
Tux
Juggy
处理到 Juggy 时,管道便停止了后续处理。这是因为此时已找到符合"长度大于 4"条件的元素,目标达成,无需再处理后续的 Moby 或 Gordon。短路机制的核心正是利用了流的"惰性"特性,实现任务的尽早完成。
二、并行:充分利用多核优势

默认情况下,流以顺序方式执行。当每个元素可独立处理,且任务属于 CPU 密集型时,切换为并行流能显著缩短处理时间。
底层实现上,Java 借助ForkJoinPool 将任务拆分至多个 CPU 核心并行执行,完成后再合并部分结果。示例代码如下:
java
import java.util.List;
public class ParallelDemo {
public static void main(String[] args) {
List<String> names = List.of("Duke", "Juggy", "Moby", "Tux", "Dash");
System.out.println("=== 顺序流 ===");
names.stream()
.peek(n -> System.out.println(Thread.currentThread().getName() + " -> " + n))
.filter(n -> n.length() > 4)
.count();
System.out.println("\n=== 并行流 ===");
names.parallelStream()
.peek(n -> System.out.println(Thread.currentThread().getName() + " -> " + n))
.filter(n -> n.length() > 4)
.count();
}
}
在典型多核运行环境中,顺序处理与并行处理的输出结果对比的示例如下:
rust
=== 顺序流 ===
main -> Duke
main -> Juggy
main -> Moby
main -> Tux
main -> Dash
=== 并行流 ===
ForkJoinPool.commonPool-worker-3 -> Moby
ForkJoinPool.commonPool-worker-1 -> Juggy
main -> Duke
ForkJoinPool.commonPool-worker-5 -> Dash
ForkJoinPool.commonPool-worker-7 -> Tux
顺序流在单个线程(通常是 main 线程)中运行,而并行流会将任务分配给多个 ForkJoinPool 工作线程,一般每个 CPU 核心对应一个工作线程。
通过以下代码可查看当前环境的可用 CPU 核心数量:
java
System.out.println(Runtime.getRuntime().availableProcessors());
需要注意的是,并行处理仅在处理大型数据集的 CPU 密集型、无状态计算时,才能真正发挥性能提升作用。对于轻量级任务或 I/O 密集型操作,线程管理的开销往往会超过其带来的性能增益。
2.1 顺序流与并行流处理对比
以下程序为每个元素模拟了 CPU 密集型任务,并分别测量顺序流与并行流的执行时间:
java
import java.util.*;
import java.util.stream.*;
import java.time.*;
public class ParallelThresholdDemo {
public static void main(String[] args) {
List<Integer> sizes = List.of(10_000, 100_000, 1_000_000, 10_000_000);
for (int size : sizes) {
List<Integer> data = IntStream.range(0, size).boxed().toList();
System.out.printf("%n数据量: %,d%n", size);
System.out.printf("顺序流: %d ms%n",
time(() -> data.stream()
.mapToLong(ParallelThresholdDemo::cpuWork)
.sum()));
System.out.printf("并行流: %d ms%n",
time(() -> data.parallelStream()
.mapToLong(ParallelThresholdDemo::cpuWork)
.sum()));
}
}
static long cpuWork(long n) {
long r = 0;
for (int i = 0; i < 200; i++) r += Math.sqrt(n + i);
return r;
}
static long time(Runnable task) {
Instant start = Instant.now();
task.run();
return Duration.between(start, Instant.now()).toMillis();
}
}
以下是在搭载 Intel Core i9(第 13 代)处理器、运行 Java 25 的设备上,顺序流与并行流的执行结果快照:
| 数据量 | 顺序流 | 并行流 |
|---|---|---|
| 10,000 | 8 ms | 11 ms |
| 100,000 | 78 ms | 41 ms |
| 1,000,000 | 770 ms | 140 ms |
| 10,000,000 | 7,950 ms | 910 ms |
从小数据量(10,000 个元素)的测试结果可见,并行版本反而略慢。这是因为线程的拆分、调度与合并本身存在固定开销。但随着每个元素计算量的增加,这种开销的占比逐渐降低,并行处理的优势便会显现出来。
不同处理器和架构的性能临界点存在差异:
- Intel Core i7/i9 或 AMD Ryzen 7/9:仅当处理数十万级数据或计算量较重的任务时,并行处理才能真正带来收益。这类平台的线程协调成本较高,因此小数据集采用顺序处理更高效。
- Apple Silicon(M1/M2/M3) :得益于统一内存架构和高效的线程调度,并行流通常在中等规模数据集上就能展现优势------一般在几百到几千个元素之后,性能便会超越顺序流,具体临界点取决于每个元素的计算复杂度。
可见,元素数量并非决定并行是否有效的核心因素,关键在于每个元素所承担的 CPU 计算量。若计算逻辑本身较轻量,顺序执行依然是更优选择。
2.2 并行流使用建议
若每个元素涉及大量数学运算、解析或压缩等操作,并行流的处理速度通常能达到顺序流的 5 至 9 倍。在决定是否使用并行流时,建议牢记以下几点:
- 当每个元素的处理成本较低时,需达到数万甚至更多元素规模,才能体现并行优势;
- 当每个元素的处理成本较高时,并行带来的性能提升会更早显现;
- 对于 I/O 操作或对顺序敏感的任务,优先采用顺序处理;
- 需结合硬件配置和任务负载特征判断------它们决定了并行处理何时能真正发挥作用。
并行流在元素独立、计算密集且数据量足够大(能让所有 CPU 核心保持忙碌)的场景下表现最佳。合理运用并行流,仅需少量代码改动,就能释放巨大的性能潜力。
2.3 并行流性能调优
并行流默认使用公共的 ForkJoinPool,它会自动创建足够数量的线程,以充分利用所有可用的 CPU 核心。多数情况下,默认配置即可满足需求,无需额外调整。但在基准测试或细粒度性能调优场景中,可将并行流运行在自定义的 ForkJoinPool 中,示例如下:
java
import java.util.concurrent.*;
import java.util.stream.IntStream;
public class ParallelTuningExample {
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool(8);
long result = pool.submit(() ->
IntStream.range(0, 1_000_000)
.parallel()
.sum()
).join();
}
}
使用专用的 ForkJoinPool,可在不影响应用其他部分的前提下,尝试不同的并行度级别,从而精准测量并行度对性能的影响。
避免修改全局设置:通过 System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "8") 修改全局配置,会改变整个 JVM 中公共线程池的行为,可能导致其他无关代码出现不可预测的性能问题。
核心要点:并行流仅在 CPU 密集型、无状态且元素可独立并行处理的场景下有优势。对于小数据集或 I/O 密集型任务,线程管理的开销通常会超过其收益,此时顺序流更高效、更简洁。
三、流与虚拟线程(Java 21+)

虚拟线程(Virtual Threads)是 Java 21 通过 Project Loom 引入的新特性,彻底重塑了 Java 的并发模型。需要注意的是,并行流专注于 CPU 密集型的并行计算,而虚拟线程则专为大规模 I/O 并发设计。
虚拟线程是轻量级的用户态线程,等待时不会阻塞底层的操作系统线程。这意味着我们可以高效运行成千上万------甚至数百万------个阻塞任务。示例代码如下:
java
import java.util.concurrent.*;
import java.util.stream.IntStream;
public class ThreadPerformanceComparison {
public static void main(String[] args) throws Exception {
int tasks = 1000;
run("平台线程(固定线程池)",
Executors.newFixedThreadPool(100), tasks);
run("虚拟线程(单任务单线程)",
Executors.newVirtualThreadPerTaskExecutor(), tasks);
}
static void run(String label, ExecutorService executor, int tasks) throws Exception {
long start = System.nanoTime();
var futures = IntStream.range(0, tasks)
.mapToObj(i -> executor.submit(() -> sleep(500)))
.toList();
// 等待所有任务完成
for (var future : futures) {
future.get();
}
System.out.printf("%s 完成耗时: %.3f s%n",
label, (System.nanoTime() - start) / 1_000_000_000.0);
executor.shutdown();
}
static void sleep(long millis) {
try {
Thread.sleep(millis);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
输出示例:平台线程 ≈ 5 s,虚拟线程 ≈ 0.6 s。
示例中使用了两种执行器,其工作原理差异如下:
newFixedThreadPool(100):创建由 100 个平台线程(即真实的操作系统线程)支持的执行器。最多同时运行 100 个任务,超出部分需排队等待空闲线程。每个平台线程在执行Thread.sleep()或 I/O 操作时会被完全阻塞,这意味着这 100 个线程在阻塞调用完成前无法处理其他任务。newVirtualThreadPerTaskExecutor():为每个任务创建一个虚拟线程。虚拟线程是轻量级的用户态线程,即便处于阻塞状态也不会占用操作系统线程。可类比为:少量货车(平台线程)负责运送数百万个包裹(虚拟线程),虽然同一时间仅有少数货车在行驶,但随着时间推移,成千上万次配送都能高效完成。
示例中,每个任务通过 Thread.sleep(500) 模拟阻塞 I/O 操作:
- 使用
newFixedThreadPool(100):仅能同时运行 100 个任务,1000 个任务需分 10 批次执行(1000 ÷ 100),每批次耗时 0.5 秒,总耗时约 5 秒。 - 使用
newVirtualThreadPerTaskExecutor():所有 1000 个任务可同时启动,并行休眠 500 毫秒,总耗时约 0.5--0.6 秒------仅为模拟延迟时间,无需等待队列。
虚拟线程通过在阻塞时释放底层操作系统线程,大幅降低了并发开销,从而以极低的资源成本实现海量 I/O 并发。并行流与虚拟线程均能提升性能,但核心在于场景匹配:
- 处理 CPU 密集型任务,且能从数据并行中受益时,使用并行流;
- 处理 I/O 密集型任务,尤其是大量操作需要等待外部资源时,使用虚拟线程。
四、流汇聚(Gatherers)
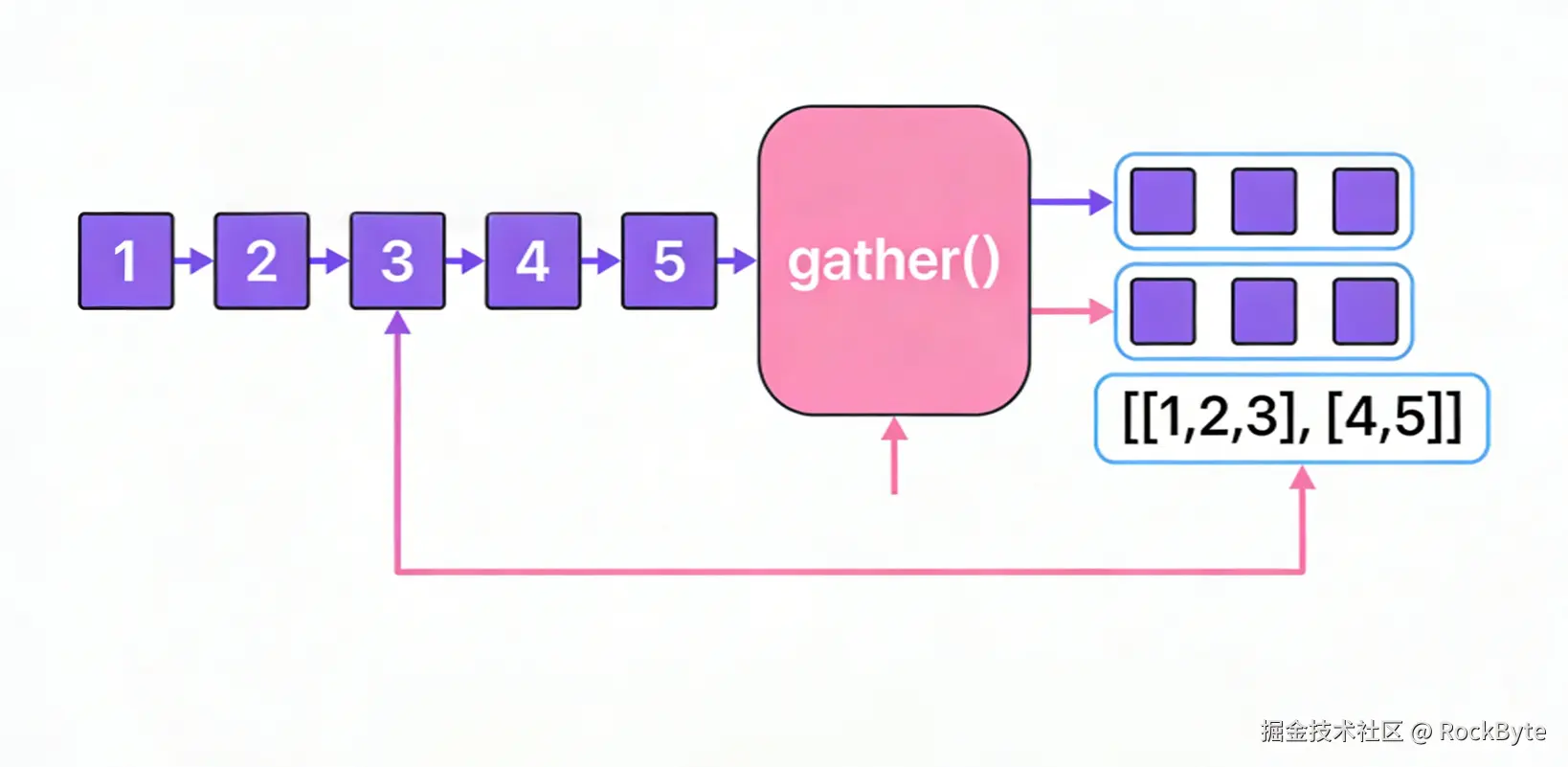
在 Java 22 之前,流非常适合处理 filter 或 map 这类无状态转换操作。但当需要依赖前面元素的逻辑(如滑动窗口、累计求和、条件分组等)时,就不得不放弃流,转而使用带可变状态的命令式循环。这一现状随着流汇聚器(Gatherers)的引入得以改变。
在流汇聚器出现前,若要计算包含三个元素的滑动窗口移动平均值,需编写如下代码:
java
List<Integer> data = List.of(1, 2, 3, 4, 5, 6);
List<Double> movingAverages = new ArrayList<>();
Deque<Integer> window = new ArrayDeque<>();
for (int value : data) {
window.add(value);
if (window.size() > 3) {
window.removeFirst();
}
if (window.size() == 3) { // 仅当窗口满时计算平均值
double avg = window.stream()
.mapToInt(Integer::intValue)
.average()
.orElse(0.0);
movingAverages.add(avg);
}
}
System.out.println(movingAverages);
// 输出:
// [2.0, 3.0, 4.0, 5.0]
这种方式虽能实现需求,但破坏了流原本的声明式、惰性特性。代码中需手动管理状态,混合了命令式与函数式风格,同时丧失了流的组合性。
如今,借助 Stream.gather() 及内置汇聚器,可重写上述示例。通过流汇聚器,能在保持惰性和可读性的前提下,直接在流管道中执行有状态操作:
java
List<Double> movingAverages = Stream.of(1, 2, 3, 4, 5, 6)
.gather(Gatherers.windowsSliding(3))
.map(window -> window.stream()
.mapToInt(Integer::intValue)
.average()
.orElse(0.0))
.toList();
System.out.println(movingAverages);
// 输出:
// [2.0, 3.0, 4.0, 5.0]
可以看到,windowsSliding(3) 会先汇聚 3 个元素,生成 [1,2,3],随后窗口向前滑动一位,依次生成 [2,3,4]、[3,4,5]、[4,5,6]。汇聚器会自动管理这些状态,因此我们能清晰表达复杂的数据流逻辑,无需手动实现缓冲或编写循环。
4.1 内置汇聚器
Stream Gatherers API 提供了以下内置汇聚器:
windowFixed(n):将数据划分为不重叠的批次,每批包含 n 个元素;windowsSliding(n):创建重叠窗口,适用于移动平均或趋势检测场景;scan(seed, acc):计算累计值或运行总和等累积指标;mapConcurrent(maxConcurrency, mapper):支持在可控并行度下进行并发映射。
4.2 收集器 vs 汇聚器(Collectors vs Gatherers)
在之前的入门文章中,我们已了解收集器(Collectors)。两者目标相近,但行为存在本质差异:收集器会在流处理结束时,将整个流聚合为单个结果(如列表、总和);而汇聚器在流处理过程中持续工作,保持元素间的上下文关联。
简单来说:收集器是一次性完成数据汇总,汇聚器则是在数据流动过程中持续重塑数据流。
以下通过流汇聚器计算累计总和的示例,进一步体现其优势:
java
Stream.of(2, 4, 6, 8)
.gather(Gatherers.scan(() -> 0, Integer::sum))
.forEach(System.out::println);
// 输出:
// 2, 6, 12, 20
每个输出值均包含截至当前元素的累计和,整个流依然保持惰性,且无副作用。
与所有技术一样,流汇聚器也有其适用场景。当满足以下条件时,可优先考虑使用流汇聚器:
- 应用涉及滑动窗口或累计分析;
- 需要生成依赖前序元素的指标或转换结果;
- 操作包含序列分析或模式识别;
- 代码需手动维护状态,但希望保持逻辑清晰的声明式风格。
汇聚器重塑了 Java 流在有状态操作上的完整表达能力,同时让流管道保持可读、高效,且对并行友好。
五、流的合并
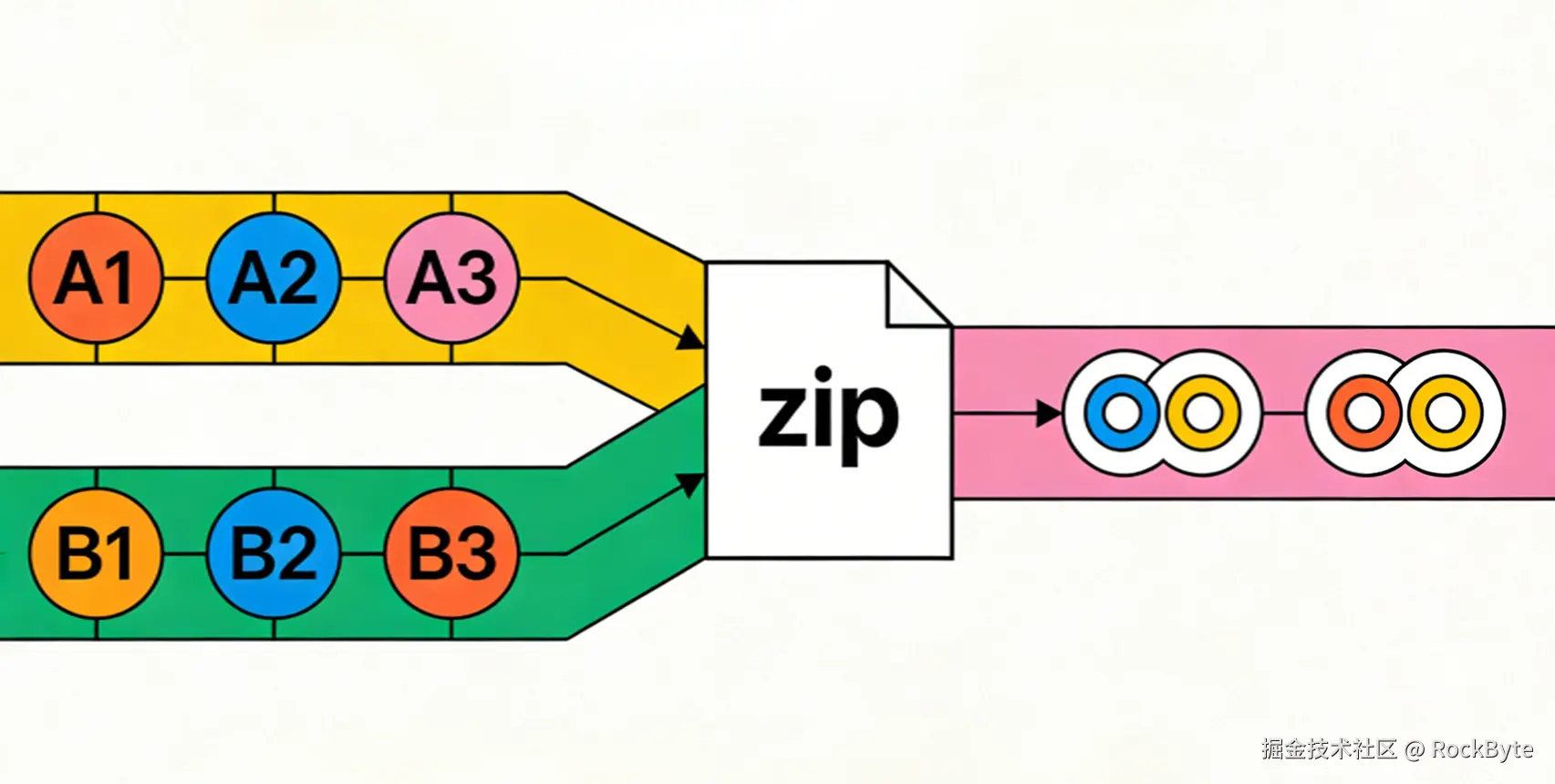
有时需要合并多个流的数据(如逐元素合并两个序列)。尽管 Stream API 目前未内置 zip() 方法,但我们可轻松自定义实现:
java
import java.util.*;
import java.util.function.BiFunction;
import java.util.stream.*;
public class StreamZipDemo {
public static <A, B, C> Stream<C> zip(
Stream<A> a, Stream<B> b, BiFunction<A, B, C> combiner) {
Iterator<A> itA = a.iterator();
Iterator<B> itB = b.iterator();
Iterable<C> iterable = () -> new Iterator<>() {
public boolean hasNext() {
return itA.hasNext() && itB.hasNext();
}
public C next() {
return combiner.apply(itA.next(), itB.next());
}
};
return StreamSupport.stream(iterable.spliterator(), false);
}
// 使用示例:
public static void main(String[] args) {
zip(Stream.of(1, 2, 3),
Stream.of("Duke", "Juggy", "Moby"),
(n, s) -> n + " → " + s)
.forEach(System.out::println);
}
}
输出结果如下:
markdown
1 → Duke
2 → Juggy
3 → Moby
拉链(zipping)操作会从两个流中逐对取出元素,直至其中一个流耗尽,非常适合合并具有关联关系的数据序列。
六、Java 流的陷阱与最佳实践
最后,我们总结 Java 流使用中的常见陷阱与优化建议,帮助你规避问题,提升代码的性能与效率。
6.1 应避免的陷阱
- 过度使用流:并非所有循环都适合用流实现,简单迭代有时更清晰、高效;
- 在 map/filter 中引入副作用:保持函数纯净性,避免修改外部状态;
- 忽略终端操作:牢记流的惰性特性,不执行终端操作就不会触发实际处理;
- 滥用并行流:并行流仅对 CPU 密集型任务有帮助,会拖慢 I/O 密集型任务;
- 重复使用已消费的流:流仅能遍历一次,一旦消费即不可复用;
- 误用汇聚器:避免共享可变状态,否则可能引发线程安全问题;
- 手动管理状态的" hack 方案" :优先使用
gatherers处理有状态逻辑,更简洁、安全。
6.2 最佳实践
为充分发挥 Java 流的优势,建议遵循以下最佳实践:
- 保持管道简洁可读:避免过长的链式调用,提升代码可维护性;
- 处理数字优先使用基本类型流 :如
IntStream、LongStream,减少装箱/拆箱开销; - 仅在调试时使用 peek() :该方法会破坏流的惰性,可能影响性能;
- 尽早过滤元素:在执行昂贵操作前,先通过过滤缩小数据集规模;
- 有状态逻辑优先使用内置汇聚器 :如
gatherers,更安全、高效; - 避免用并行流处理 I/O 操作:改用虚拟线程(virtual threads)实现高并发;
- 优化前先测量性能:使用 Java Microbenchmark Harness 或性能分析工具评估实际表现,再针对性调整。
七、结语
本文介绍的 Java Stream API 高级技术,将助力你在现代 Java 开发中实现高表达力、高性能的数据处理:短路操作节省计算资源,并行流充分利用多核优势,虚拟线程应对海量 I/O 并发,而汇聚器(Gatherers)则在不破坏声明式风格的前提下,完美支持有状态转换。
合理组合这些技术,你的流代码将始终保持简洁、可扩展的特性,如数据流般流畅高效!