
为何诞生
开发这个工具的起因很简单,只是想给commit msg加上漂亮的emoji, 我找遍了社区所有的工具,没有一个能完美实现 DX懒人化 + 任意提交方式(不局限CLI) + 一致性 + 规范化 + 语义化版本控制 的完整闭环。
commitizen(cz), git-cz, cz-git, gitmoji 这类工具都无法做到完美,它要求开发者必须用其提供的CLI工具通过交互式命令行表单来选择emoji 输入提交信息来完成提交,但实际情况是并不能严格要求协作者只能用CLI工具提交,我们希望开发者无论是GUI CLI 还是 git commit -m 'xxx'都能自动加上emoji,甚至是github workflow中由工作流提交也能自动转换成符合规范的提交信息,这是最省心的且严谨的。
commitlint能很好的校验提交信息格式规范,但是它太严谨了,feat:foo 这一段提交就会报错,因为:后面少了空格,✨ feat: foo也会报错,因为它默认不支持emoji
所以基于以上两种搭配陷入困境:
- 要emoji就必须用交互式CLI表单的提交方式
- 要emoji就不能上commitlint
- 表单提交方式就无法兼顾CICD机器人提交规范化
因此诞生了committier, 可以让你任意提交,git hook会捕获你的提交信息,工具背后的解析器和规则集会自动读取monorepo中的变更,帮你转换成符合conventional commits规范的提交信息,既能附带emoji也能完美通过commitlint校验。
复杂性不会凭空消失,只会转移
这不是一个"又多一个"的那种工具,而是明确提交阶段的职责,将多个传统工具用这一个工具取代,并降低心智负担,less is more。将开发者(用户)在大型monorepo中规范化的复杂性转移到工具背后。
7加减2原则
开发者在每个阶段,工具本身不应该带来超过7+-2个需要记忆的知识,超过即是心智负担。
在传统的cz工具中,我们需要记忆提交只能用cli、源码改动了哪几个包填写哪些scope、类型有哪几种、这种类型对应了哪个emoji、输入格式要注意大小写等等,这明显负担太重了,简简单单一个提交为了迎合规范记那么多真的值得吗?
而committier能极大减少你需要额外学习和记忆的知识,90%情况下你只需要知道'feat', 'fix', 'chore'这三个关键词足矣。
git add ...2.git commit -m feat...3. 完事
committier 💗 commitlint

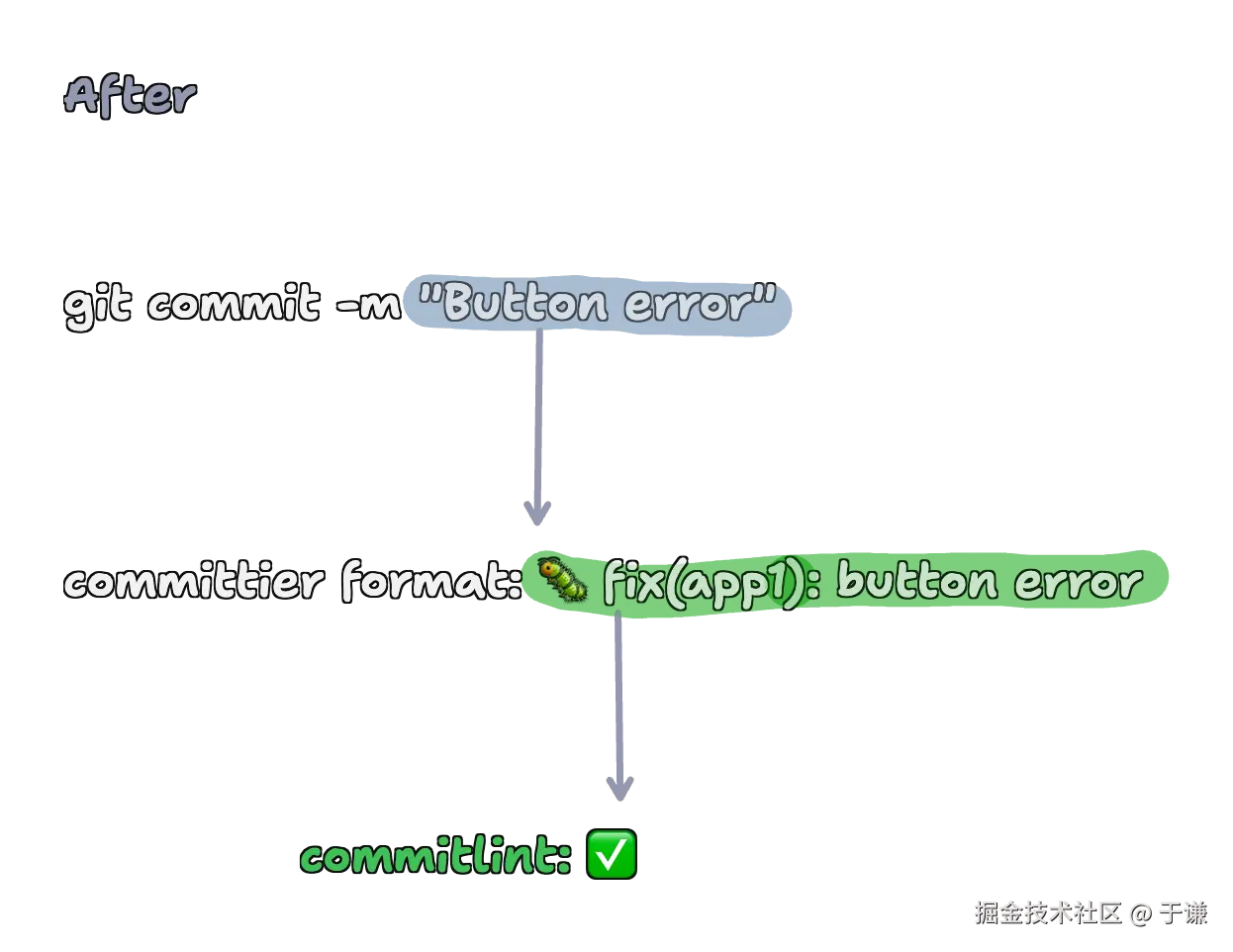
committier和commitlint的关系就像prettier和eslint。前者是约定大于配置的,无须任何配置即可按照默认推荐的风格完成自动转换和格式化,附加emoji, scope, 甚至自动生成description(如果你真的很懒),但它不会像lint那样强校验你的输入长度、特殊字符等等,因此这两个工具既可以完美配合,也可以任选其一单独使用,选择权在你。
语义化自动生成changelog
要实现自动生成,首先要确保commit msg是符合语义化(conventional commits)的
由于
- committier -> 始终将commit msg转化成符合语义化的格式
- commitlint -> 强校验commit msg确保只有符合语义化的格式
因此无论是组合或者任选其一,都能为后续生成changlog做准备。
这两个工具都没有内置changelog生成,因为日志属于版本控制的环节,不应该将日志提前到commit环节,所以将日志交给版本控制的专用工具。
版本控制主要分为两派工具
- 语义化:nx、lerna、semantic-release
- 文档: changesets
我推荐使用nx, 因为它能提取规范化的提交信息作为日志内容自动生成changelog, 免除开发者手写变更文档的麻烦,主打一个能偷懒则偷懒。
nx本身是一个很重的工具,有一定上手成本,但是我们不一定要用它的任务流、缓存等功能,如官方所说建议渐进式使用,只用它的nx release相关功能就可以了,我个人推荐在monorepo中的完美初始组合是:
pnpm workspace + husky + committier + commitlint + nx release
这些已经足够你构建项目、规范提交、版本控制、发布。
committier自动生成scope、description
默认是不会自动生成的,需要在配置文件中开启
committier.config.js
js
import { defineConfig } from "committier";
export default defineConfig({
autoScope: true,
defaultDescription: true
});假设现在提交两个文件分别在:
- apps/webapp/src/
app.tsx(包名为@mycomp/webapp) - packages/components/src/
button.tsx(包名为@mycomp/components)
添加到暂存区
sh
git add -A书写信息并提交,但这里我想偷懒,连信息都懒得写,我们只写一个feat表示这是一个特性变更
sh
git commit -m "feat"自动推断出变更的包名作为scope, 由于description没写,自动填充文件名作为信息
转换后, 提交成功成功✅
sh
✨ feat(webapp,components): app.tsx, button.tsx现在撤销commit, 重新来个不偷懒的书写例子, 但是我格式是很乱的,看看会不会被格式化
sh
git commit -m "feAT app,comp : Add button comp "转换后,提交成功✅
sh
✨ feat(webapp,components): add button compapp,comp是不合法的包名,因此被替换成正确的包名,description也从大小改为了小写,中间一堆空格也去掉了
以上使用场景很大程度上降低了monorepo跨包开发提交时手写scope的心智负担,因为往往我们很难记得住这次提交到底改动了哪些包,如果改动比较小,信息都可以不用写,允许开发者选择性偷懒,这对于非特性变更比较方便,例如
chore->chore(webapp): vite.config.tsdocs->docs: up README.md
committier后续规划
- 收集用户体验建议,按需增加规则集,例如自动转换issue链接,body转换markdown格式等等,任何idea都可以在评论区或者开发交流群里讨论、pr、协作都可以。
- rust重写,主要是为了分发纯二进制执行程序,让其他语言无需依赖node环境也能集成,另外还能提升解析性能 即使可以忽略不计。
- 插件化设计,源码比较整洁,架构已分层设计,随时可以插件化,但需要好好设计一下api
- 本地轻量模型,真正实现0手写自动生成,这个比较有难度,目前还没看到可行的解决方案,需要观摩、等待,大家有好的点子请一定告诉我🙏,要综合考虑模型大小 纯cpu速度 跨平台性。大模型可以不考虑,api接入普适性不强,主流ai IDE已经可以自动生成可以结合committier按需使用。
- Gitub workflow actions,提供一个流水线插件,方便其他语言集成,以及修复pr提交者越过本地校验而提交的不符合格式的信息。
- 文档补上简体中文