文章首发于微信公众号《itThinking》, 原文链接:mp.weixin.qq.com/s/vLI9RCy4m...
在现代高并发、大规模分布式系统中,唯一标识符(ID)不仅是数据的"身份证",更是系统稳定性和可扩展性的基石。本文将深入探讨为什么需要分布式 ID、业务对 ID 的核心要求,并全面对比主流的分布式 ID 生成方案,包括其原理、优缺点、适用场景及性能表现。
1. 为什么需要分布式 ID?
单体系统 vs 分布式系统
在单体应用中,数据库主键常采用自增 ID(Auto Increment),简单高效。但在分布式架构下,尤其是进行分库分表后,这种方案会面临严重问题:多个数据库实例各自维护自增序列,导致ID 冲突;无法保证全局唯一性,破坏数据一致性;扩容困难,难以横向扩展。
📌 示例:订单表因数据量过大被拆分为 4 个库。若每个库独立自增,则可能出现多个"订单ID=1001"的记录,造成业务逻辑混乱。
2. 业务系统对分布式 ID 的核心要求
一个理想的分布式 ID 生成系统需满足以下关键特性:
| 要求 | 说明 |
|---|---|
| 全局唯一性 | 绝对不能重复,是 ID 的基本前提 |
| 趋势递增 | ID 整体递增(非严格连续),利于数据库索引性能(如 MySQL InnoDB 聚簇索引) |
| 单调递增(可选) | 某些场景(如事务版本号、消息序号)要求严格递增 |
| 信息安全 | ID 不应暴露业务信息(如订单量、用户增长),避免被竞对或爬虫推算 |
| 高性能 & 高可用 | 低延迟、高 QPS、99.999% 可用性(5个9) |
| 无中心依赖(理想) | 尽量减少对数据库、ZooKeeper 等外部组件的强依赖 |
⚠️ 注意:趋势递增 与 信息安全 往往互斥------前者希望有序,后者希望无序。需根据业务权衡。
3. 主流分布式 ID 生成方案对比
| 方案 | 原理 | 全局唯一 | 趋势递增 | 安全性 | 依赖 | QPS(单机) | 适用场景 |
|---|---|---|---|---|---|---|---|
| UUID | 本地生成 128 位随机/时间+MAC | ✅ | ❌ | 中(部分泄露 MAC) | 无 | >100万 | 日志、临时ID |
| 数据库自增(Flickr Ticket Server) | 多DB + 步长隔离 | ✅ | ✅(趋势) | 低(可推算) | MySQL | ~1万 | 小规模系统 |
| 号段模式(Segment) | 批量预取 ID 段到内存 | ✅ | ✅ | 低 | MySQL | 10万+ | 高并发写入 |
| Redis INCR | Redis 自增原子操作 | ✅ | ✅ | 低 | Redis | 10万+ | 已有 Redis 架构 |
| Snowflake | 时间戳 + 机器ID + 序列号 | ✅ | ✅ | 中 | 时钟 | 40万+ | 通用场景 |
| 百度 UidGenerator | Snowflake 改进 + RingBuffer | ✅ | ✅ | 中 | DB(分配 workerId) | 600万 | 超高并发 |
| 美团 Leaf(Segment) | 优化号段 + 双 buffer 预加载 | ✅ | ✅ | 低 | MySQL | 5万+ | 订单、支付等 |
| 美团 Leaf(Snowflake) | Snowflake + ZooKeeper 自动分配 workerId | ✅ | ✅ | 中 | ZK + 时钟 | 5万+ | 需防冲突的 Snowflake |
| 滴滴 TinyID | Leaf-segment 多 DB 扩展版 | ✅ | ✅ | 低 | MySQL(多源) | 10万+ | 多租户、多业务线 |
💡 注:QPS 数据基于典型配置(如 4C8G 机器),实际受网络、存储、GC 等影响。
3.1 UUID
UUID是一个128位的数字,其结构通常由五个部分组成,为了方便阅读,通常转换成32个十六进制数字的形式表示。格式:8-4-4-4-12,共 36 字符(如9acadbef-f92f-49fb-8907-1cd91a493982)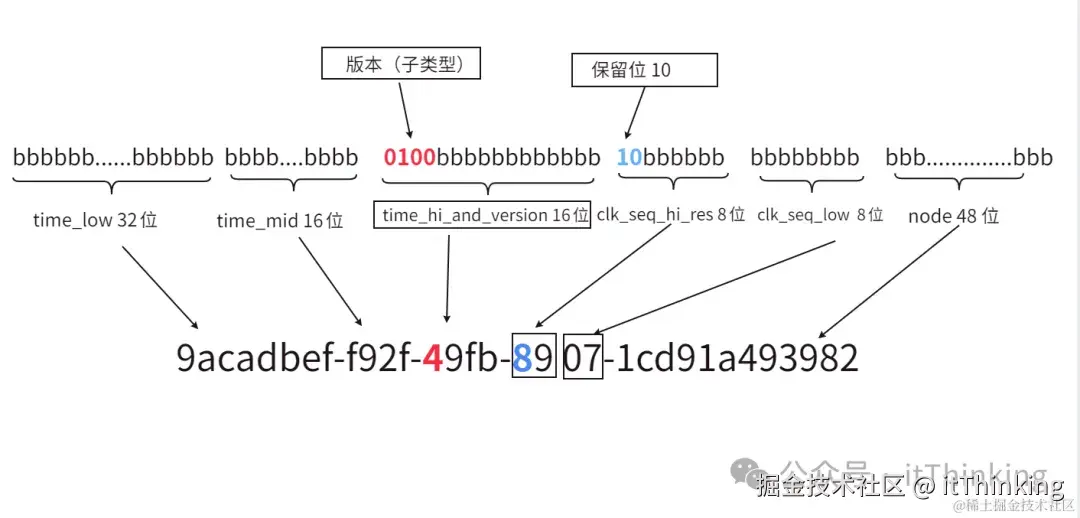
| 字段 | hexOctet(字节) | 位置 | 备注 |
|---|---|---|---|
| time_low | 4 | 0-3 | 时间戳 的低位部分 |
| time_mid | 2 | 4-5 | 时间戳的中间部分 |
| time_hi_and_version | 2 | 6-7 | 时间戳高位部分与 版本 字段,其中12位代表时间戳的高12位,4位则用来标识UUID的版本号 |
| clock_seq_hi_and_reserved | 1 | 8 | 时钟序列 高位与 保留位 |
| clock_seq_low | 1 | 9 | 时钟序列低位 |
| node | 6 | 10-15 | 节点标识符,提供空间唯一性,通常基于MAC地址或随机数生成,以确保全局范围内的唯一性 |
- 优点:本地生成、无网络开销、极高性能
- 缺点:
- 长度大(36字符),占用存储空间;
- 无序,导致 InnoDB 频繁页分裂,写性能下降;
- 部分版本(v1)含 MAC 地址,存在隐私泄露风险。
- 适用:非主键场景(如 traceId、sessionId)
3.2 数据库自增(Flickr Ticket Server)
原理:N 台 DB,步长 = N,offset = 0~N-1缺点:
- 扩容复杂(需重新分配 offset 和 step);
- 强依赖 DB,单点故障风险;
- ID 可预测,不安全。
性能:受限于单 DB 写入能力,通常 < 1万 QPS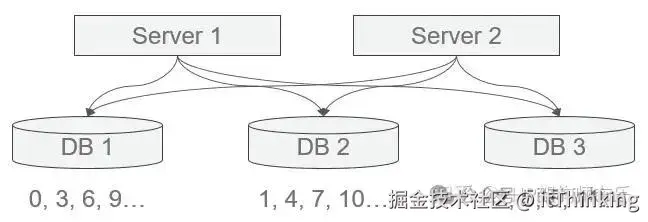
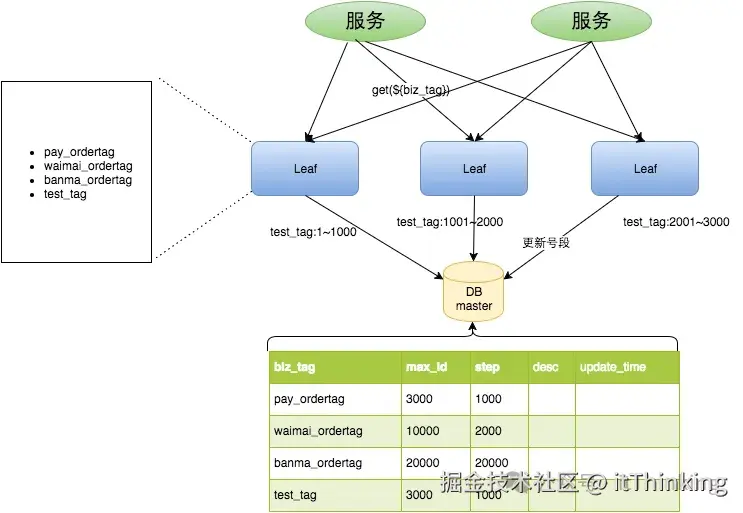
3.3 号段模式(Segment)
- 核心思想:一次从 DB 获取一段 ID(如 1~1000),用完再取
- 优化(Leaf-segment):
-
- 双 Buffer 预加载:当前号段用到 10% 时异步加载下一段,避免临界阻塞;
- biz_tag 隔离:不同业务使用不同 tag,互不影响;
-
- 高可用:主从 + Atlas 中间件自动切换。
- 性能:Leaf 实测 5万 QPS,TP999 < 1ms
- 缺点:
- 仍依赖 DB;
- ID 可推算
3.4 Redis 实现
- 命令:INCR key或 INCRBY key step
- 优点:原子性、高性能、简单
- 缺点:
-
- 引入 Redis 依赖;
- 集群模式下需类似 DB 的分段策略;
- 持久化可能丢失 ID(需 AOF + fsync)
- 性能:单 Redis 实例可达 10万+ QPS
3.5 雪花算法(Snowflake)
雪花算法(Snowflake)是由 Twitter 开源的分布式 ID 生成算法,以划分命名空间的方式将 64-bit 位分割成多个部分,每个部分代表不同的含义。在 Java 中 Long 类型是 64 位的,所以 Java 程序中一般使用 Long 类型存储。
- 64 位结构:
-
- 1 bit 符号位(固定 0)
- 41 bit 时间戳(毫秒,约 69 年)
- 10 bit 机器 ID(1024 节点)
- 12 bit 序列号(4096/毫秒)
- 优点:趋势递增、无 DB 依赖、高性能
- 致命缺陷:时钟回拨→ 可能重复 ID
- 性能:理论 409.6万 QPS,实测 40万+

3.6 百度 UidGenerator
- 改进点:
- 时间单位改为 秒(28 bit → 支持 8.7 年);
- workerId 扩展至 22 bit(支持 420 万机器);
- 使用 RingBuffer 缓存 ID,生产消费分离;
- 解决 CPU Cache 伪共享问题。
- 性能:单机 600万 QPS(官方数据)
- 依赖:启动时需 DB 分配 workerId(可复用)
3.7 美团 Leaf
3.7.1 Leaf-segment(号段模式增强版)
- 表结构:
sql
CREATE TABLE leaf_alloc ( biz_tag VARCHAR(128) NOT NULL, max_id BIGINT NOT NULL DEFAULT '1', step INT NOT NULL, description VARCHAR(256), update_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY(biz_tag));- 特性:双 buffer、biz_tag 隔离、DB 主从高可用
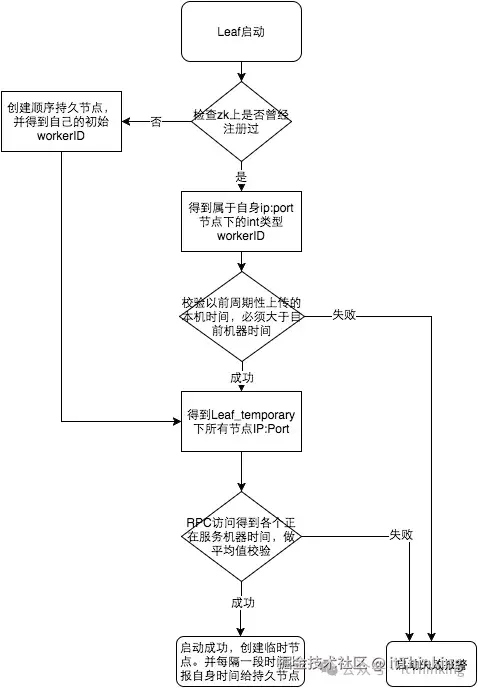
3.7.2 Leaf-snowflake(Snowflake + 自动注册)
- workerId 自动分配:通过 ZooKeeper 持久顺序节点生成
- 时钟回拨处理:
-
- 小回拨(<5ms):等待;
- 大回拨:报警并拒绝服务
- 弱依赖 ZK:本地缓存 workerId 文件,重启可用
3.8 滴滴 TinyID
- 定位:Leaf-segment 的多 DB 扩展版
-
特性:
-
- 支持多数据源(failover);
- 提供 HTTP API 和 Java Client;
- 支持多业务隔离(类似 biz_tag)
-
适用:已有 MySQL 集群、需多租户支持的场景
4. 总结与选型建议
| 场景 | 推荐方案 |
|---|---|
| 超高并发、无安全要求 | 百度 UidGenerator |
| 已有 MySQL、需简单集成 | 美团 Leaf-segment / 滴滴 TinyID |
| 无 DB 依赖、容忍时钟风险 | Snowflake / Leaf-snowflake |
| 临时 ID、非主键 | UUID |
| 已有 Redis 架构 | Redis INCR |
✅ 最佳实践:
- 核心业务(如订单)建议使用 Leaf-segment(可控、稳定);
- 日志追踪可使用 UUID;
- 若追求极致性能且能管控时钟,可选 UidGenerator。
参考资料
- 美团技术团队 - Leaf
- 百度 UidGenerator GitHub
- Twitter Snowflake (Archived)
- 滴滴 TinyID GitHub