Spring AI Alibaba 实战(五):RAG 三种架构
系列目标 :从零构建一个机票比价 Agent 本篇目标 :理解 RAG 本质 + 掌握 Two-Step / Agentic / Hybrid 三种 RAG 架构 + 构建 Document ETL 管道 + VectorStore 选型 前置知识:已完成第四篇,掌握 Memory 和 Checkpoint
理论篇
一、为什么需要 RAG------让 LLM 做"开卷考试"
1.1 RAG 解决什么问题
前几章我们的机票 Agent 已经能查询航班、对比价格、多轮对话了。但如果用户问:
arduino
"你们东方航空的退改签政策是什么?"
"经济舱允许携带多大的行李?"
"儿童票怎么购买?"LLM 要么编造答案 (幻觉),要么说"我不知道"------因为这些是航空公司的私有知识,不在 LLM 的训练数据中。
RAG(Retrieval-Augmented Generation,检索增强生成)解决的就是这个问题:让 LLM 在回答前先"翻参考资料"。
不用 RAG = 闭卷考试(凭记忆,可能答错) 用 RAG = 开卷考试(有参考资料,答案有据可查)
1.2 RAG vs 微调 vs Function Calling
| 方案 | 本质 | 适用场景 | 成本 |
|---|---|---|---|
| RAG(Vector) | 运行时检索外部知识 | 事实性问答、政策查询、文档问答 | 低(无需训练) |
| GraphRAG | 构建知识图谱 + 图遍历检索 | 多跳推理、实体关系问答(如"哪些航司允许免费改签且有会员计划") | 高(需 LLM 抽取实体关系) |
| 微调 | 把知识烧入模型参数 | 学习特定风格、行业术语 | 高(需要 GPU 训练) |
| Function Calling | 调用 API 获取实时数据 | 实时数据查询、执行操作 | 低 |
| 直接搜索(grep/BM25) | 关键词 / 正则精确匹配 | 代码搜索、结构化数据、精确查找 | 极低 |
- 用户问"退改签政策" → RAG(知识在文档中)
- 用户问"今天的航班价格" → Function Calling(需要实时数据)
- 用户要求"用东北话回答" → 微调(学习风格)
生产中常常组合使用:RAG 提供知识,Function Calling 提供能力,微调提升风格。我们的机票 Agent 就是 RAG + Function Calling 的组合。
1.3 三种 RAG 范式------VectorRAG vs GraphRAG vs PageIndex
"RAG"不止一种做法。根据数据结构和检索方式的不同,业界目前有三种主流范式:
| 维度 | VectorRAG | GraphRAG | PageIndex |
|---|---|---|---|
| 数据结构 | 文档 → 切片 → 向量 | 文档 → 实体 + 关系 → 知识图谱 | 文档 → 整页/整段保留原始结构 |
| 检索方式 | 语义相似度(ANN) | 图遍历 + 子图匹配 | 关键词(BM25)/ 全文索引 |
| 擅长 | 单跳事实问答:"退票政策是什么" | 多跳推理:"哪些航司允许免费改签且有会员积分" | 精确查找:"航班CA1234的行李额度" |
| 短板 | 多跳推理弱、否定语义混淆 | 构建成本极高(需 LLM 抽取实体关系)、更新慢 | 语义理解弱、同义词召回差 |
| 构建成本 | 低(Embedding + VectorStore) | 高(实体抽取 + 关系构建 + 图数据库) | 极低(Elasticsearch / 倒排索引) |
| 更新成本 | 中(重新切分 + 向量化) | 高(重新抽取实体关系) | 低(增量索引) |
| Spring AI 支持 | 原生支持 | 无原生支持,需自建 | 通过 Elasticsearch 间接支持 |
选型决策:
| 你的场景 | 推荐范式 | 理由 |
|---|---|---|
| 政策问答、文档查询、FAQ | VectorRAG | 最成熟、Spring AI 原生支持、开发成本低 |
| 需要跨文档多跳推理、实体关系分析 | GraphRAG | VectorRAG 天然做不到跨片段关联推理 |
| 精确查找、订单号/航班号检索 | PageIndex(BM25) | 关键词精确匹配比语义匹配更可靠 |
| 通用生产环境 | VectorRAG + BM25 混合检索 | 语义 + 精确互补,本章 3.4 节详解 |
工程判断 :大多数团队的第一选择应该是 VectorRAG + BM25 混合检索。GraphRAG 只在你的业务确实需要多跳推理时才值得投入------它的构建和维护成本是 VectorRAG 的 5-10 倍。不要因为技术新就上,先确认业务场景是否真的需要图遍历能力。
1.4 RAG 的真实边界------为什么 Claude 不依赖 RAG?
在 2024 年之前,RAG 几乎是"让 LLM 获取外部知识"的唯一答案。但随着模型上下文窗口的爆发式增长,这个假设正在被挑战。
一个值得思考的事实 :Claude(Anthropic)的上下文窗口是 200K token,Gemini 1.5 Pro 达到 1M token。以 Claude 为例,200K token ≈ 一本 300 页的书。如果你的知识库只有几十页文档,直接塞进上下文就行,为什么还要 RAG?
长上下文方案:用户提问 → 把整份文档塞入 System Prompt → LLM 直接在完整文档中找答案
RAG 方案:用户提问 → 向量化 → 检索 Top-K 片段 → 把片段塞入 Prompt → LLM 基于片段回答
两种方案的本质对比:
| 维度 | 长上下文直塞 | RAG 检索 |
|---|---|---|
| 信息完整性 | 100%(全文都在) | 部分(只有 Top-K 片段) |
| 实现复杂度 | 极低(零额外组件) | 高(向量库 + Embedding + 切分 + 检索) |
| 运维成本 | 零 | 高(向量库运维、文档更新、重索引) |
| Token 消耗 | 高(每次都送全文) | 低(只送检索到的片段) |
| 适用数据量 | < 200 页文档 | 任意规模 |
| 精确度 | 高(模型看到全部上下文) | 依赖检索质量 |
| 延迟 | 首 token 慢(长输入) | 首 token 快 |
所以 Claude 的策略是:
- 中小规模知识(< 200K token)→ 直接塞进上下文,不用 RAG
- 大规模知识库(> 200K token)→ 用 Tool Use(类似 Agentic RAG)按需检索
- 实时数据 → Tool Use 调用外部 API
这给了我们一个重要的工程判断:
不要因为"大家都在用 RAG"就无脑上 RAG。先算一笔账:你的知识库有多大?如果 < 100 页文档,长上下文可能比 RAG 更简单、更准确、更省运维。
何时该用 RAG,何时不该 : 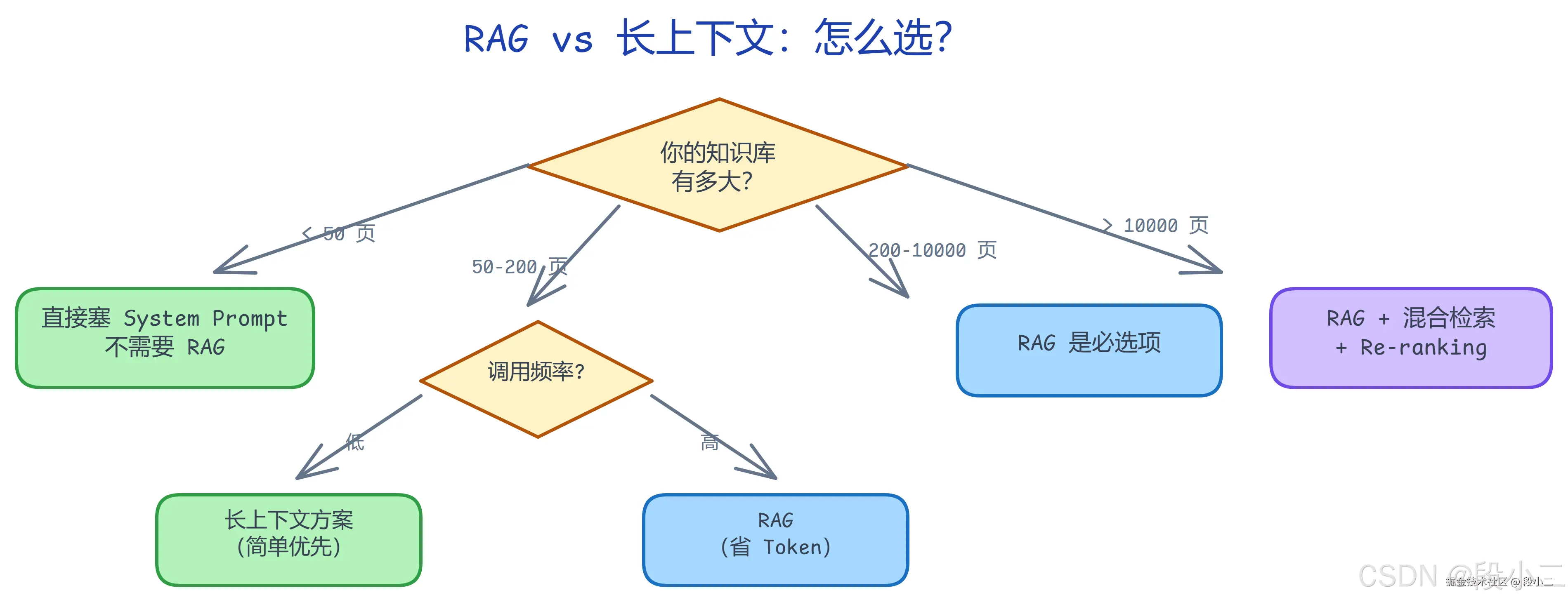
还有一类场景根本不需要 RAG------代码搜索。 Claude Code、Cursor、GitHub Code Search 都不用向量检索,而是用 ripgrep(关键词精确匹配)+ AST 语法树解析。原因很直接:代码是结构化 的,函数名、类名、变量名都是精确标识符,getUserById 和 deleteUserById 在向量空间里几乎一样,但语义完全不同。精确匹配在这里比语义匹配更可靠。
判断原则:数据是非结构化自然语言(政策、文档、FAQ)→ RAG;数据是结构化或有精确标识符(代码、日志、配置)→ 关键词搜索 / grep;需要实体间多跳推理(知识图谱类问题)→ 考虑 GraphRAG。
1.5 RAG 在真实业务中的六大痛点
教程里的 RAG Demo 总是很美好------切分、向量化、检索、回答,四步搞定。但到了真实业务中,RAG 的坑比想象中多得多。
痛点一:检索质量是 RAG 的天花板
RAG 的根本问题:LLM 只能基于检索到的内容回答。检索没命中 → LLM 必然答不对,无论模型多强。
真实数据:向量检索的 Top-5 命中率通常在 60%-80%,也就是说 20%-40% 的问题,正确答案根本没被检索到------这还是在"干净"文档上的表现。
痛点二:切分破坏信息完整性
这是 RAG 最被低估的问题。切分本质上是在"撕碎"原始文档。
📌 切分导致错误的典型场景:
一份退票政策文档包含"一、退票条件(经济舱/商务舱手续费规则)"和"二、特殊说明(3折以下不予退票)"。切分后这两部分被分到不同的 Chunk 中。
用户问:"我买的3折特价票能退吗?"
- 检索命中 Chunk 1(包含"退票"关键词)
- 但正确答案在 Chunk 2(特价票不予退票)
- LLM 基于 Chunk 1 回答"可以退,手续费5%"------错误!
真实业务中的切分问题还包括:表格被拆散 、代码块被截断 、上下文引用丢失 、多级标题嵌套导致语义断裂。
痛点三:Embedding 的语义鸿沟
向量检索依赖 Embedding 模型将文本转为语义向量。但 Embedding 模型有盲区:
| 盲区类型 | 示例 | 为什么搜不准 |
|---|---|---|
| 否定语义 | "不允许退票" vs "允许退票" | 向量距离很近(词几乎一样),但语义完全相反 |
| 专业术语 | "MCT(最短中转时间)" | Embedding 模型没见过这个缩写,检索效果极差 |
| 数值推理 | "超过20公斤的行李怎么收费?" | 向量检索不擅长数值比较 |
| 跨文档推理 | "A航空和B航空的退票政策区别?" | 需要同时检索两个文档并对比,单次检索做不到 |
痛点四:知识库的"冷启动"与持续维护
上线前 :文档格式不统一(PDF/Word/Excel/扫描件混杂),清洗数据的人工成本远超预期(通常占整个 RAG 项目 60% 的时间),切分策略需要反复调优,没有万能方案。
上线后:文档更新后需要重新切分、重新向量化、替换旧向量。如果换了 Embedding 模型,全量数据必须重新处理。知识库版本管理也是难题------旧政策和新政策共存,检索到旧的怎么办?而且没有自动化测试,你不知道这次更新有没有破坏已有的问答效果。
痛点五:多轮对话中的检索漂移
第1轮:用户问"经济舱退票政策" → 检索退票文档 ✅
第2轮:用户说"那商务舱呢?" → 检索什么?"那商务舱呢?"向量化后语义很弱,检索可能命中完全无关的"商务舱餐食"文档。正确做法:结合对话历史改写为"商务舱退票政策"。
痛点六:成本与延迟的隐性代价
| 环节 | 基础 RAG | Hybrid RAG |
|---|---|---|
| Embedding API(查询向量化) | ~0.001 元 | ~0.001 元 |
| 向量库查询 | ~5ms | ~5ms |
| 查询改写(LLM 调用) | --- | ~0.02 元 |
| 检索验证(LLM 调用) | --- | ~0.02 元 |
| 主回答(LLM 调用) | ~0.05 元 | ~0.05 元 |
| 回答验证(LLM 调用) | --- | ~0.02 元 |
| 合计 | ~0.051 元/次 | ~0.11 元/次 |
日均 10 万次调用 → 月成本 33 万元 (Hybrid)vs 15 万元 (基础 RAG),Hybrid 是基础 RAG 的 2 倍。
1.6 解决方案------从"能用"到"好用"
上面的六大痛点不是要劝退 RAG,而是说明:RAG 不是开箱即用的银弹,需要针对业务场景做工程化打磨。
| 痛点 | 解决方案 | 本章对应 |
|---|---|---|
| 检索不准 | 混合检索(向量 + BM25)+ Re-ranking | 3.4 节 |
| 切分破坏语义 | 语义感知切分 + overlap + 元数据标注 | 4.2 节 |
| Embedding 盲区 | 查询改写 + 多路检索 | 4.8 节 Hybrid RAG |
| 知识库维护 | 元数据版本管理 + 增量更新 + 自动化测试 | 4.6 节元数据过滤 |
| 多轮检索漂移 | 结合 Memory 上下文改写查询 | 4.8 节查询增强 |
| 成本与延迟 | 分级策略:简单问题直答,复杂问题才走 RAG | 4.7 节 Agentic RAG |
分级检索策略(推荐的生产方案):
arduino
用户提问
├── LLM 判断:需要检索吗?
│ ├── 不需要(闲聊/简单问题)→ 直接回答(省钱省时)
│ └── 需要 → Agentic RAG
│ ├── 第1次检索
│ │ ├── 结果充分 → 直接回答
│ │ └── 结果不足 → 改写查询,第2次检索
│ └── 最多重试 2 次(防止死循环)
│
│ 关键:让 LLM 当"检索调度器",而不是每次都机械检索工程判断 :在我们的机票 Agent 中,Agentic RAG 是最佳选择------LLM 自主决定何时查政策、何时查航班、何时直接回答。这比 Two-Step RAG 省 Token,比 Hybrid RAG 省成本,而且天然支持与 Function Calling 工具混合使用。
1.7 RAG 的完整流程
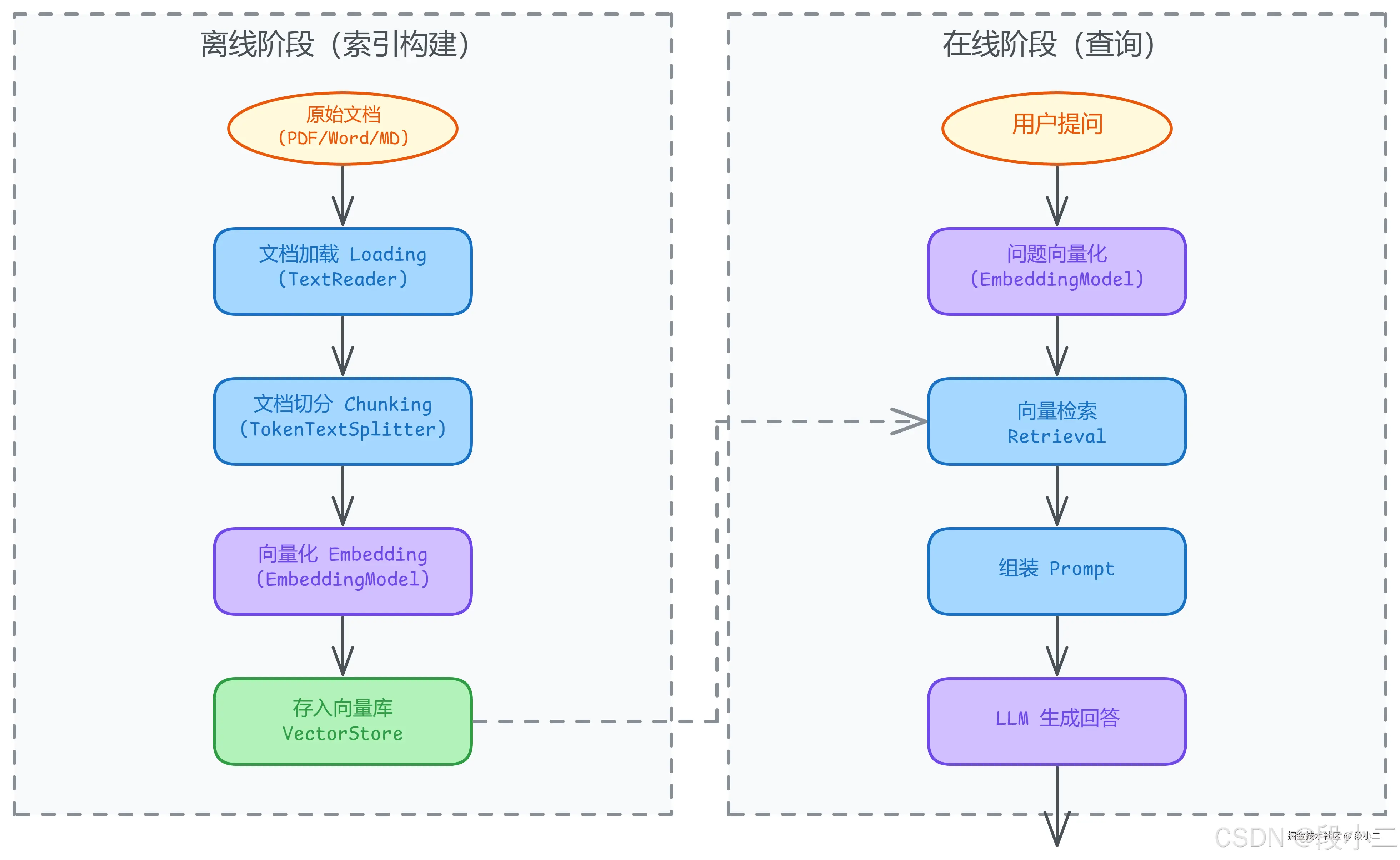
理解了 RAG 的定位和边界后,下一个问题是:具体怎么做? RAG 的离线和在线两个阶段各涉及哪些组件?Spring AI 提供了几种 RAG 实现模式?
二、核心概念------Document ETL 管道与三种 RAG 架构
2.1 Document ETL 四阶段
RAG 的离线阶段可以类比为传统 ETL(Extract-Transform-Load)管道:
| 阶段 | ETL 类比 | RAG 中的操作 | Spring AI 核心类 |
|---|---|---|---|
| 文档加载 | Extract | 读取 PDF/Word/MD 等格式 | TextReader, PagePdfDocumentReader, TikaDocumentReader |
| 文档切分 | Transform | 按语义切分为小片段 | TokenTextSplitter |
| 向量化 | Transform | 将文本转为向量表示 | EmbeddingModel |
| 存入向量库 | Load | 持久化到向量数据库 | VectorStore |
切分是 RAG 中最被低估的环节 。即使用了最好的模型和向量库,切分不好整个系统效果都会差。关键原则:不要切断语义完整的信息------表格不拆、列表不拆、段落尽量完整。
切分策略选型:
| 文档类型 | 建议 chunk_size | 切分策略 |
|---|---|---|
| FAQ / Q&A | 每条一片 | 按条目切分 |
| 技术文档 | 500-1000 字符 | 按标题/段落切分 |
| 法律合同 | 800-1500 字符 | 按条款切分 |
| 产品手册 | 300-800 字符 | 按段落递归切分 |
| 航空公司政策 | 500-800 字符 | 按政策条目切分 |
2.2 Embedding 模型选型
| 模型 | 维度 | 中文能力 | 推荐场景 |
|---|---|---|---|
| text-embedding-v3(DashScope) | 1024 | 最好 | 生产环境首选(中文) |
| bge-large-zh(BAAI) | 1024 | 优秀 | 开源自部署 |
| text-embedding-3-small(OpenAI) | 1536 | 好 | 通用场景 |
| all-MiniLM-L6-v2 | 384 | 差 | 仅英文 Demo |
关键原则 :文档和查询必须用同一个 Embedding 模型。换模型意味着所有文档必须重新向量化。
2.3 三种 RAG 架构概览
下图对比了三种架构的核心流程差异:
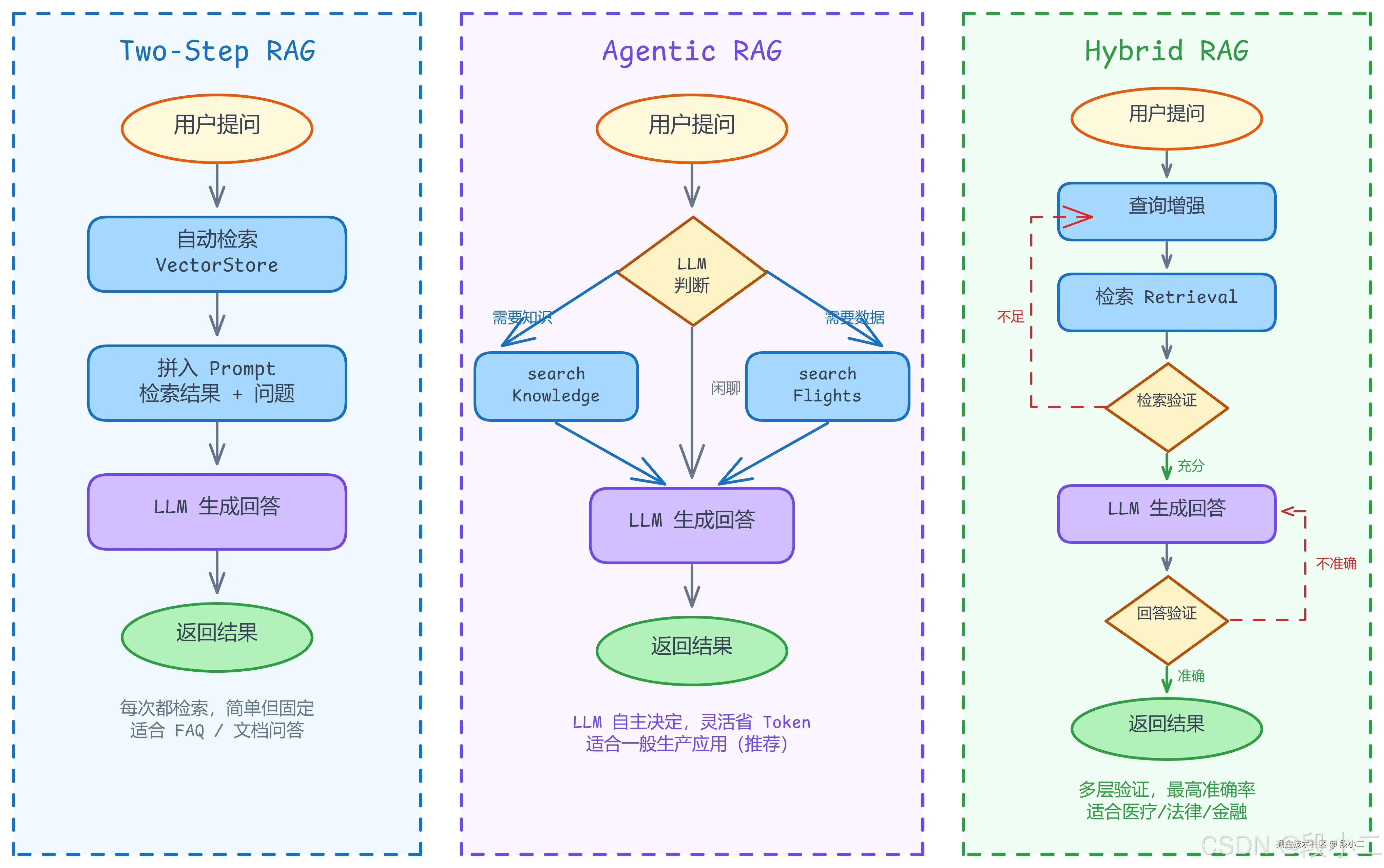
- Two-Step RAG :每次用户提问时,自动检索知识库,把结果拼到 Prompt 中。最基础的 RAG 模式。
- Agentic RAG:把检索能力当作一个 Tool 交给 LLM,让 LLM 自主决定是否需要检索、检索什么、检索几次。
- Hybrid RAG:在 Agentic RAG 基础上增加查询增强、检索验证、回答验证三层机制,大幅提升准确率。
2.4 三种 RAG 架构对比
| 维度 | Two-Step | Agentic | Hybrid |
|---|---|---|---|
| 复杂度 | 低 | 中 | 高 |
| 检索策略 | 固定检索 | LLM 自主检索 | 自主检索 + 多次重试 |
| 查询优化 | 无 | LLM 可改写 | 专门的查询增强 |
| 结果验证 | 无 | 无 | 检索验证 + 回答验证 |
| 准确率 | 基础 | 较高 | 最高 |
| Token 消耗 | 低 | 中 | 高(多次 LLM 调用) |
| 延迟 | 低 | 中 | 高 |
| 适用场景 | FAQ 问答 | 一般 Agent | 高准确率要求 |
选型建议 :Demo / 学习 / 简单 FAQ → Two-Step RAG | 一般生产应用 → Agentic RAG(推荐) | 医疗/法律/金融 → Hybrid RAG(准确率优先)
生产建议 :如果你的应用同时需要 RAG 和 Function Calling,优先选 Agentic RAG。它更灵活,且能与其他工具自然协同。
概念和架构都清楚了,接下来看 Spring AI 为这三种架构提供了哪些 API------搞清楚"用什么类、调什么方法",才能开始写代码。
三、API 与架构解析------Spring AI 的 RAG 接口设计
3.1 核心接口一览
Spring AI 围绕 RAG 提供了以下核心接口和类:
java
// 示意代码:Spring AI 的 DocumentReader 接口
public interface DocumentReader {
List<Document> read();
}
// 实现类:TextReader, PagePdfDocumentReader, TikaDocumentReader 等
java
// 示意代码:VectorStore 核心方法
public interface VectorStore {
void add(List<Document> documents);
List<Document> similaritySearch(SearchRequest request);
}
java
// 示意代码:Two-Step RAG 的核心 --- RetrievalAugmentationAdvisor
// 它作为 Advisor 拦截请求,自动完成检索并将结果拼入 Prompt
RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.topK(5)
.similarityThreshold(0.5)
.build())
.build();3.2 Two-Step RAG 的局限
| 局限 | 说明 |
|---|---|
| 只检索一次 | 检索结果不够好时,不会自动重试 |
| 查询不改写 | 用户的问题可能表述不清,直接检索效果差 |
| 无验证机制 | 不检查检索结果是否充分、回答是否忠实 |
| 固定策略 | 每次都检索,即使问题不需要检索(闲聊) |
Two-Step RAG 适合:FAQ 问答、文档查询等简单场景。复杂场景需要 Agentic RAG 或 Hybrid RAG。
3.3 Agentic RAG vs Two-Step RAG
| 维度 | Two-Step RAG | Agentic RAG |
|---|---|---|
| 检索时机 | 每次请求都检索 | LLM 自主判断是否需要 |
| 查询改写 | 不改写 | LLM 可以优化查询关键词 |
| 多次检索 | 只检索一次 | 信息不够时自动再检索 |
| Token 消耗 | 固定(每次都有检索结果) | 灵活(不需要时不检索,省 Token) |
| 与其他工具协同 | 独立 | 可与 Function Calling 工具混合使用 |
| 适用场景 | 简单文档问答 | 复杂 Agent(推荐) |
3.4 混合检索与重排序原理
单纯的向量检索有盲区------精确匹配差(订单号、专有名词)。混合检索结合向量和关键词的优势:
!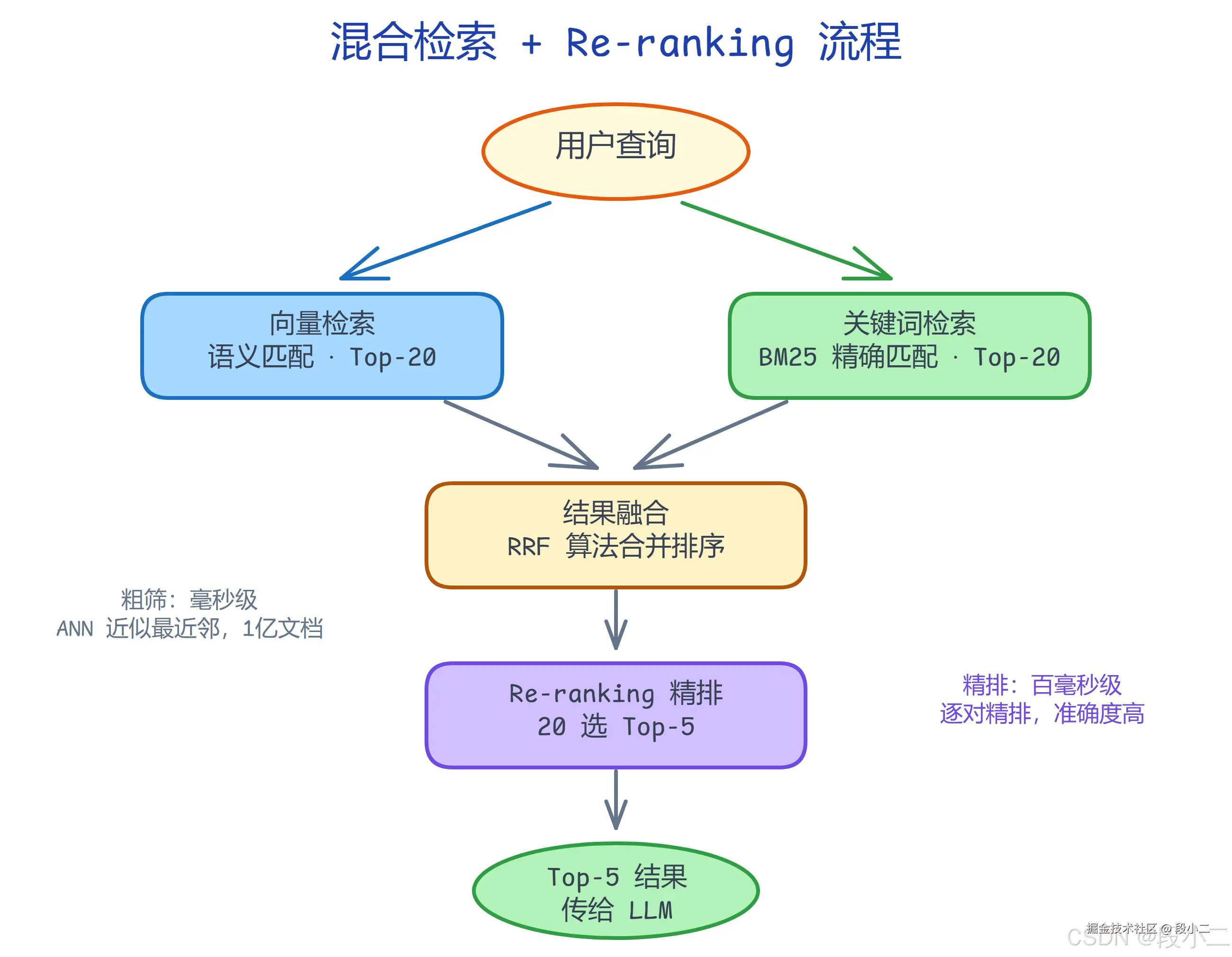
为什么分两步? 向量检索 1 亿文档 → 毫秒级(ANN 近似最近邻),得到 Top-20 粗筛结果;Re-ranker 对 20 个候选逐对精排 → 百毫秒级,选出 Top-5 传给 LLM。先粗后精 = 速度 + 精度兼得。
3.5 RAG 调优指南与评估
1.5 节分析了 RAG 在真实业务中的六大痛点,这里聚焦具体的调优手段和评估体系。
RAG 出错的五个环节(准确率乘法效应):
| 文档质量 | × 切分质量 | × 向量化质量 | × 检索质量 | × 生成质量 | = 最终准确率 |
|---|---|---|---|---|---|
| 0.95 | 0.90 | 0.85 | 0.90 | 0.90 | 0.59 |
即使每个环节 90%+,最终可能只有 60%!这就是准确率的乘法效应。
| 陷阱 | 现象 | 解决方案 |
|---|---|---|
| 文档过时 | 旧政策和新政策同时返回 | 元数据标记版本,检索时过滤 |
| 切分不当 | 表格被拆散、信息被截断 | 语义感知切分,保持结构完整 |
| 中英混用模型 | 中文文档用英文 Embedding | 使用中文优化模型(text-embedding-v3) |
| 检索不精确 | 语义相似但答案不匹配 | 混合检索 + Re-ranking |
| LLM 幻觉 | 编造文档中没有的内容 | System Prompt 强约束 + 回答验证 |
| Top-K 太小 | 关键信息没被检索到 | 增大 Top-K + 降低相似度阈值 |
| Top-K 太大 | 噪音太多干扰 LLM | 减小 Top-K + 加 Re-ranking |
RAG 评估指标:
核心评估维度:
| 维度 | 指标 | 含义 |
|---|---|---|
| 检索质量 | 命中率(Hit Rate) | Top-K 中是否包含正确答案 |
| MRR(Mean Reciprocal Rank) | 正确答案排第几 | |
| 回答质量 | 忠实度(Faithfulness) | 回答是否基于检索结果 |
| 相关性(Relevance) | 回答是否切中问题 | |
| 完整性(Completeness) | 回答是否遗漏关键信息 |
评估方法:人工评估(最准确但成本高)、LLM-as-Judge(用 GPT-4 / Claude 打分)、自动化测试集(准备 100 个 Q&A 对跑评估脚本)。
3.6 VectorStore 选型对比
| VectorStore | 性能 | 运维 | 适用场景 | 特色 |
|---|---|---|---|---|
| SimpleVectorStore | 低 | 无 | 开发/Demo | 零依赖,内存存储 |
| Redis | 高 | 中 | 通用生产环境 | 已有 Redis 基础设施时首选 |
| Elasticsearch | 高 | 中 | 已有 ES 集群 | 支持混合检索(向量+全文) |
| Milvus | 极高 | 高 | 大规模向量检索 | 专业向量库,亿级数据 |
| DashScope Cloud | 高 | 低 | 阿里云生态 | 全托管,无需运维 |
| PGVector | 中 | 低 | 已有 PostgreSQL | 在现有 PG 上加插件 |
快速选型:已有 Redis → RedisVectorStore | 已有 ES → ElasticsearchVectorStore | 用阿里云 → DashScope Cloud Store | 数据量 > 1000万 → Milvus | 刚起步/Demo → SimpleVectorStore
理论讲够了,下面进入实战。我们从最基础的"文档入库"开始,一步步构建出完整的 RAG 系统,最终集成到机票 Agent 中。
实战篇
四、动手编码------Document ETL 管道与 RAG 实现
4.1 文档加载(Loading)
Spring AI 支持多种文档格式:
java
// 纯文本
Resource textResource = new ClassPathResource("docs/airline-policy.txt");
TextReader textReader = new TextReader(textResource);
List<Document> docs = textReader.read();
// PDF
Resource pdfResource = new ClassPathResource("docs/baggage-rules.pdf");
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader(pdfResource);
List<Document> docs = pdfReader.read();
// Markdown(技术文档常用)
Resource mdResource = new ClassPathResource("docs/faq.md");
MarkdownDocumentReader mdReader = new MarkdownDocumentReader(mdResource);
List<Document> docs = mdReader.read();
// Tika(万能解析器:PDF/Word/HTML/Excel...)
Resource anyResource = new ClassPathResource("docs/handbook.docx");
TikaDocumentReader tikaReader = new TikaDocumentReader(anyResource);
List<Document> docs = tikaReader.read();添加元数据(后续可用于过滤检索):
java
List<Document> docs = textReader.read();
for (Document doc : docs) {
doc.getMetadata().put("source", "东方航空官网");
doc.getMetadata().put("category", "退改签政策");
doc.getMetadata().put("version", "2026-01");
doc.getMetadata().put("airline", "MU");
}4.2 文档切分(Chunking)
java
// 方式1:按 Token 数切分(推荐)
TokenTextSplitter splitter = new TokenTextSplitter(
800, // defaultChunkSize: 每片约 800 token
350, // minChunkSizeChars: 最小片段字符数
200, // minChunkLengthToEmbed: 低于此长度不向量化
100, // maxNumChunks: 单文档最大片段数
true // keepSeparator: 保留分隔符
);
List<Document> chunks = splitter.split(docs);
java
// 方式2:自定义切分(更灵活)
TextSplitter splitter = new TextSplitter() {
@Override
protected List<String> splitText(String text) {
// 按段落切分,保持语义完整
return Arrays.asList(text.split("\n\n"));
}
};4.3 向量化(Embedding)
java
// 使用 DashScope Embedding 模型(中文效果好)
@Bean
public EmbeddingModel embeddingModel() {
return DashScopeEmbeddingModel.builder()
.apiKey("your-api-key")
.modelName("text-embedding-v3") // 阿里云中文优化模型
.build();
}4.4 存入向量库(VectorStore)
java
// 开发环境:SimpleVectorStore(内存)
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();
}
// 入库
vectorStore.add(chunks); // chunks 是切分后的 Document 列表完整的 ETL 管道:
java
@Service
public class DocumentIngestionService {
private final VectorStore vectorStore;
public DocumentIngestionService(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
/**
* 一键入库:加载 → 切分 → 向量化 → 存储
*/
public void ingest(Resource resource, String category) {
// 1. 加载
TikaDocumentReader reader = new TikaDocumentReader(resource);
List<Document> docs = reader.read();
// 2. 添加元数据
docs.forEach(doc -> {
doc.getMetadata().put("category", category);
doc.getMetadata().put("ingested_at", LocalDateTime.now().toString());
});
// 3. 切分
TokenTextSplitter splitter = new TokenTextSplitter();
List<Document> chunks = splitter.split(docs);
// 4. 向量化 + 存储(VectorStore 内部自动调用 EmbeddingModel)
vectorStore.add(chunks);
log.info("入库完成: {} 个文档, {} 个片段", docs.size(), chunks.size());
}
}4.5 Two-Step RAG 实现:RetrievalAugmentationAdvisor
注意 :Spring AI 1.1.2 中
QuestionAnswerAdvisor已被RetrievalAugmentationAdvisor取代。如果你看到旧教程用的是QuestionAnswerAdvisor,请迁移到新 API。
java
@Configuration
public class RagConfig {
@Bean
public ChatClient ragChatClient(ChatClient.Builder builder,
VectorStore vectorStore) {
// Spring AI 1.1.2 使用 RetrievalAugmentationAdvisor
RetrievalAugmentationAdvisor ragAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.topK(5) // 检索 Top-5 片段
.similarityThreshold(0.5) // 相似度阈值
.build())
.build();
return builder
.defaultSystem("""
你是机票分析师「票小蜜」。
回答规则:
1. 严格基于提供的参考资料回答,不要编造
2. 如果参考资料中没有相关信息,请明确说"未找到相关信息"
3. 回答时引用信息来源
""")
.defaultAdvisors(ragAdvisor, new SimpleLoggerAdvisor())
.build();
}
}
java
@RestController
@RequestMapping("/api/v5/rag")
public class RagController {
private final ChatClient ragChatClient;
public RagController(ChatClient ragChatClient) {
this.ragChatClient = ragChatClient;
}
/**
* RAG 问答------自动检索知识库
*/
@GetMapping("/ask")
public String ask(@RequestParam String q) {
return ragChatClient.prompt(q)
.call()
.content();
}
}RetrievalAugmentationAdvisor 内部做了什么?
- 拦截用户请求
- 用用户问题在 VectorStore 中检索相关片段
- 把检索到的片段拼接到 Prompt 中(作为上下文)
- 转发给 LLM
- LLM 基于上下文回答
4.6 带元数据过滤的检索
java
// 只检索特定航空公司的政策
RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.topK(5)
.similarityThreshold(0.5)
.filterExpression("airline == 'MU'") // 只查东方航空
.build())
.build()
// 只检索最新版本
SearchRequest.builder()
.filterExpression("version == '2026-01'")
.build()
// 组合条件
SearchRequest.builder()
.filterExpression("airline == 'MU' AND category == '退改签'")
.build()4.7 Agentic RAG 实现:知识库检索作为 Tool
java
@Configuration
public class AgenticRagConfig {
/**
* 把知识库检索注册为一个 Tool
* LLM 自主决定何时调用
*/
@Bean
public FunctionCallback searchKnowledgeFunction(VectorStore vectorStore) {
return FunctionCallback.builder()
.function("searchKnowledge", (KnowledgeQuery query) -> {
// 执行向量检索
List<Document> results = vectorStore.similaritySearch(
SearchRequest.builder()
.query(query.question())
.topK(query.topK() != null ? query.topK() : 5)
.similarityThreshold(0.5)
.build()
);
if (results.isEmpty()) {
return "未在知识库中找到相关信息";
}
StringBuilder sb = new StringBuilder();
sb.append("检索到 ").append(results.size()).append(" 条相关信息:\n\n");
for (int i = 0; i < results.size(); i++) {
Document doc = results.get(i);
sb.append("【").append(i + 1).append("】");
sb.append(doc.getMetadata().getOrDefault("category", "")).append("\n");
sb.append(doc.getText()).append("\n\n");
}
return sb.toString();
})
.description("在航空公司知识库中搜索信息。" +
"用于查询退改签政策、行李规定、常旅客规则等航空公司政策问题。" +
"不适用于查询实时航班和价格(那个用 searchFlights 工具)。")
.inputType(KnowledgeQuery.class)
.build();
}
}
public record KnowledgeQuery(
@JsonProperty(required = true)
@JsonPropertyDescription("要搜索的问题,尽量用关键词表述")
String question,
@JsonPropertyDescription("返回结果数量,默认5,范围1-10")
Integer topK
) {}
java
@RestController
@RequestMapping("/api/v5/agent")
public class AgenticRagController {
private final ChatClient chatClient;
public AgenticRagController(ChatClient.Builder builder) {
this.chatClient = builder
.defaultSystem("""
你是机票分析师「票小蜜」。
你拥有以下能力:
1. searchFlights --- 查询实时航班和价格
2. compareFlights --- 对比航班
3. searchKnowledge --- 查询航空公司政策知识库
使用规则:
- 用户问航班价格/时间 → 用 searchFlights
- 用户问政策/规定/规则 → 用 searchKnowledge
- 闲聊/简单问题 → 直接回答,不调用工具
- 如果第一次检索信息不够,可以换个关键词再搜一次
- 严格基于检索结果回答政策类问题,不要编造
""")
.build();
}
@GetMapping("/chat")
public String chat(@RequestParam String q,
@RequestParam String sessionId) {
return chatClient.prompt(q)
.toolNames("searchFlights", "compareFlights", "searchKnowledge")
.advisors(advisor -> advisor
.param(ChatMemory.CONVERSATION_ID, sessionId))
.call()
.content();
}
}Agentic RAG 场景演示:
arduino
场景1:用户问政策
用户:"经济舱行李限额多少?"
LLM 判断:这是政策问题 → 调用 searchKnowledge("经济舱 行李 限额")
→ 基于检索结果准确回答
场景2:用户问航班
用户:"明天北京到上海的航班"
LLM 判断:这是实时数据 → 调用 searchFlights,不调用 searchKnowledge
→ 返回实时航班信息
场景3:闲聊
用户:"你好"
LLM 判断:闲聊 → 不调用任何工具
→ 直接回答"你好!我是票小蜜,有什么可以帮您?"
场景4:多轮检索
用户:"退改签政策和行李政策有什么关联?"
LLM 判断:需要两类信息
→ 第1次:searchKnowledge("退改签政策")
→ 第2次:searchKnowledge("行李政策")
→ 综合两次结果回答4.8 Hybrid RAG 实现
查询增强(Query Enhancement):
java
@Bean
public FunctionCallback searchKnowledgeEnhanced(VectorStore vectorStore,
ChatClient queryRewriter) {
return FunctionCallback.builder()
.function("searchKnowledge", (KnowledgeQuery query) -> {
// Step 1: 查询改写------用 LLM 优化查询
String rewrittenQuery = queryRewriter.prompt("""
请将以下用户问题改写为更适合知识库检索的形式。
要求:提取核心关键词,去掉口语化表述,补充隐含的上下文。
用户问题:%s
只输出改写后的查询,不要其他内容。
""".formatted(query.question()))
.call()
.content();
// Step 2: 用改写后的查询检索
List<Document> results = vectorStore.similaritySearch(
SearchRequest.builder()
.query(rewrittenQuery)
.topK(5)
.similarityThreshold(0.5)
.build()
);
return formatResults(results, rewrittenQuery);
})
.description("在知识库中搜索航空公司政策信息")
.inputType(KnowledgeQuery.class)
.build();
}查询改写示例:
arduino
用户原始问题:"我买的票能退吗"
改写后:"机票退票条件 退票政策 退票手续费"
用户原始问题:"带个大箱子上飞机行不行"
改写后:"随身行李 尺寸限制 登机箱 规定"
用户原始问题:"小孩怎么买票"
改写后:"儿童票 购买条件 年龄限制 票价折扣"检索验证(Retrieval Validation):
java
/**
* 检索结果充分性检查
*/
private boolean isRetrievalSufficient(String question, List<Document> results) {
if (results.isEmpty()) return false;
// 用 LLM 判断检索结果是否能回答问题
String verdict = validationClient.prompt("""
判断以下检索结果是否足以回答用户的问题。
用户问题:%s
检索结果:
%s
请只回答 YES 或 NO:
- YES: 检索结果中包含回答问题所需的关键信息
- NO: 检索结果不足以回答问题,需要更多信息
""".formatted(question, formatDocuments(results)))
.call()
.content()
.trim();
return verdict.equalsIgnoreCase("YES");
}回答验证(Answer Validation):
java
/**
* 回答忠实度检查(Faithfulness Check)
*/
private boolean isAnswerFaithful(String answer, List<Document> sources) {
String verdict = validationClient.prompt("""
检查以下回答是否忠实于给定的参考资料。
回答:
%s
参考资料:
%s
判断标准:
1. 回答中的每个事实性陈述是否都能在参考资料中找到依据
2. 回答是否添加了参考资料中没有的信息
3. 回答是否曲解了参考资料的含义
请只回答 FAITHFUL 或 UNFAITHFUL:
""".formatted(answer, formatDocuments(sources)))
.call()
.content()
.trim();
return verdict.equalsIgnoreCase("FAITHFUL");
}完整的 Hybrid RAG 流程:
java
@Service
public class HybridRagService {
private final VectorStore vectorStore;
private final ChatClient mainClient; // 主回答模型
private final ChatClient validationClient; // 验证模型(可以用更便宜的模型)
/**
* Hybrid RAG 完整流程
*/
public String answer(String question) {
// Step 1: 查询增强
String enhancedQuery = rewriteQuery(question);
// Step 2: 检索
List<Document> results = vectorStore.similaritySearch(
SearchRequest.builder()
.query(enhancedQuery)
.topK(5)
.similarityThreshold(0.5)
.build()
);
// Step 3: 检索验证------结果不够时换关键词重试
if (!isRetrievalSufficient(question, results)) {
String alternativeQuery = generateAlternativeQuery(question);
List<Document> moreResults = vectorStore.similaritySearch(
SearchRequest.builder()
.query(alternativeQuery)
.topK(5)
.build()
);
results.addAll(moreResults);
// 去重
results = deduplicateResults(results);
}
// Step 4: 生成回答
String answer = mainClient.prompt()
.system("""
严格基于以下参考资料回答问题。
如果资料中没有相关信息,请说"未找到相关信息"。
回答时标注信息来源。
参考资料:
%s
""".formatted(formatDocuments(results)))
.user(question)
.call()
.content();
// Step 5: 回答验证------不忠实时重新生成
if (!isAnswerFaithful(answer, results)) {
answer = mainClient.prompt()
.system("""
你之前的回答包含了参考资料中没有的信息。
请严格只使用以下资料重新回答,不要添加任何额外信息。
参考资料:
%s
""".formatted(formatDocuments(results)))
.user(question)
.call()
.content();
}
return answer;
}
}4.9 VectorStore 配置代码
java
// 1. SimpleVectorStore(内存,开发用)
@Bean
public VectorStore simpleVectorStore(EmbeddingModel model) {
return SimpleVectorStore.builder(model).build();
}
// 2. Redis(推荐生产环境)
@Bean
public VectorStore redisVectorStore(EmbeddingModel model) {
return RedisVectorStore.builder(jedisPooled, model)
.indexName("airline-knowledge")
.prefix("doc:")
.build();
}
// 3. Elasticsearch
@Bean
public VectorStore esVectorStore(EmbeddingModel model, RestClient restClient) {
return ElasticsearchVectorStore.builder(restClient, model)
.indexName("airline-knowledge")
.build();
}
// 4. Milvus(专业向量数据库)
@Bean
public VectorStore milvusVectorStore(EmbeddingModel model, MilvusServiceClient client) {
return MilvusVectorStore.builder(client, model)
.collectionName("airline_knowledge")
.build();
}
// 5. DashScope Cloud Store(阿里云托管)
@Bean
public VectorStore dashScopeStore(EmbeddingModel model) {
return DashScopeCloudStore.builder(model)
.pipelineId("your-pipeline-id")
.build();
}混合检索配置:
java
// Elasticsearch 天然支持混合检索
@Bean
public VectorStore hybridVectorStore(EmbeddingModel model, RestClient restClient) {
return ElasticsearchVectorStore.builder(restClient, model)
.indexName("airline-knowledge")
.similarityFunction(SimilarityFunction.COSINE)
.build();
// ES 同时支持向量检索和全文检索
}Re-ranking 精排:
java
// DashScope 提供了 Re-ranker 服务
// 在检索后、传给 LLM 前,对结果重排序
public List<Document> rerankResults(String query, List<Document> candidates) {
// 调用 DashScope Rerank API
RerankRequest request = RerankRequest.builder()
.model("gte-rerank")
.query(query)
.documents(candidates.stream().map(Document::getText).toList())
.topN(5)
.build();
RerankResponse response = dashScopeClient.rerank(request);
return response.getResults().stream()
.map(r -> candidates.get(r.getIndex()))
.toList();
}ETL 管道和三种 RAG 架构都实现完了。最后一步:把知识库检索能力接入我们的机票 Agent,让它既能查航班价格,又能回答政策问题。
五、与机票比价 Agent 的集成
5.1 准备知识库文档
java
// src/main/resources/docs/airline-policy.txt
text
# 东方航空国内航线客运政策
## 一、退票政策
### 1.1 经济舱退票
- 航班起飞前 7 天(含)以上:收取票价 5% 的退票手续费
- 航班起飞前 2-7 天:收取票价 15% 的退票手续费
- 航班起飞前 4 小时-2 天:收取票价 30% 的退票手续费
- 航班起飞前 4 小时以内及起飞后:收取票价 40% 的退票手续费
- 特价机票(3折以下)不予退票
### 1.2 商务舱退票
- 航班起飞前:收取票价 5% 的退票手续费
- 航班起飞后:收取票价 10% 的退票手续费
## 二、改签政策
### 2.1 免费改签条件
- 商务舱及以上舱位:不限次数免费改签
- 经济舱全价票:每张票可免费改签 1 次
### 2.2 收费改签
- 经济舱折扣票:改签需补齐票价差额
- 特价机票(3折以下):不予改签
## 三、行李政策
### 3.1 免费托运行李
- 经济舱:20公斤
- 商务舱:30公斤
- 头等舱:40公斤
- 婴儿旅客(无座位):10公斤
### 3.2 随身行李
- 每位旅客可携带一件随身行李
- 尺寸不超过 55cm × 40cm × 20cm
- 重量不超过 5 公斤
- 笔记本电脑可额外携带
### 3.3 超重行李收费
- 国内航线:超出部分按每公斤经济舱全价票价的 1.5% 收取
## 四、儿童票与婴儿票
### 4.1 儿童票(2-12岁)
- 票价为成人全价票的 50%
- 可免费托运行李与成人相同
- 需有成人陪同乘机
### 4.2 婴儿票(0-2岁)
- 票价为成人全价票的 10%
- 不占座位
- 每位成人最多携带 2 名婴儿
- 免费托运行李 10 公斤
## 五、常旅客计划
### 5.1 里程累积
- 经济舱:按实际飞行里程的 50%-100% 累积(视折扣而定)
- 商务舱:按实际飞行里程的 150% 累积
- 头等舱:按实际飞行里程的 200% 累积
### 5.2 会员等级
- 银卡:年飞行 4 万公里或 25 个航段
- 金卡:年飞行 8 万公里或 50 个航段
- 白金卡:年飞行 16 万公里或 90 个航段5.2 知识库入库
java
@Component
public class KnowledgeBaseInitializer implements CommandLineRunner {
private final VectorStore vectorStore;
public KnowledgeBaseInitializer(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
@Override
public void run(String... args) {
// 加载文档
Resource resource = new ClassPathResource("docs/airline-policy.txt");
TextReader reader = new TextReader(resource);
List<Document> docs = reader.read();
// 添加元数据
docs.forEach(doc -> {
doc.getMetadata().put("airline", "MU");
doc.getMetadata().put("source", "东方航空官网");
doc.getMetadata().put("version", "2026-01");
});
// 切分
TokenTextSplitter splitter = new TokenTextSplitter(
500, // chunkSize
200, // minChunkSizeChars
100, // minChunkLengthToEmbed
50, // maxNumChunks
true // keepSeparator
);
List<Document> chunks = splitter.split(docs);
// 存入向量库
vectorStore.add(chunks);
log.info("知识库初始化完成: {} 个片段已入库", chunks.size());
}
}5.3 完整的 Agentic RAG Agent
java
@Configuration
public class FlightKnowledgeAgentConfig {
@Bean
public ChatClient knowledgeAgent(ChatClient.Builder builder,
VectorStore vectorStore) {
// 注册知识库检索工具
FunctionCallback searchKnowledge = FunctionCallback.builder()
.function("searchKnowledge", (KnowledgeQuery query) -> {
List<Document> results = vectorStore.similaritySearch(
SearchRequest.builder()
.query(query.question())
.topK(5)
.similarityThreshold(0.5)
.build()
);
if (results.isEmpty()) return "知识库中未找到相关信息";
return results.stream()
.map(d -> d.getText())
.collect(Collectors.joining("\n---\n"));
})
.description("搜索航空公司政策知识库," +
"包括退改签、行李、儿童票、常旅客等政策信息")
.inputType(KnowledgeQuery.class)
.build();
return builder
.defaultSystem("""
你是东方航空的智能客服「票小蜜」。
能力:
1. searchFlights --- 查询实时航班价格
2. compareFlights --- 对比航班
3. searchKnowledge --- 查询航空公司政策
规则:
- 政策问题必须调用 searchKnowledge,严格基于结果回答
- 航班价格问题调用 searchFlights
- 不确定的信息说"建议您拨打客服热线 95530 确认"
- 回答要简洁、有条理
当前日期:%s
""".formatted(LocalDate.now()))
.defaultToolCallbacks(searchKnowledge)
.build();
}
}5.4 运行结果------测试对话
yaml
用户:经济舱能免费托运多少行李?
票小蜜:[调用 searchKnowledge("经济舱 免费托运行李")]
根据东方航空政策,经济舱旅客可免费托运 **20公斤** 行李。
此外,您还可以携带一件随身行李:
- 尺寸不超过 55cm × 40cm × 20cm
- 重量不超过 5 公斤
- 笔记本电脑可额外携带
如果行李超重,国内航线按每公斤经济舱全价票价的 1.5% 收取超重费。
---
用户:我买的特价票能退吗?
票小蜜:[调用 searchKnowledge("特价机票 退票")]
很遗憾,根据东方航空退票政策:
**3折以下的特价机票不予退票,也不予改签。**
如果您的票价在3折以上(含),则可以退票,但需要收取手续费:
- 起飞前7天以上:收取票价 5%
- 起飞前2-7天:收取票价 15%
- 起飞前4小时-2天:收取票价 30%
- 起飞前4小时内:收取票价 40%
建议您查看订单中的具体折扣信息,如有疑问请拨打客服热线 95530。
---
用户:查一下明天北京到上海的航班
票小蜜:[调用 searchFlights(from=北京, to=上海, date=2026-03-14)]
(注意:这次 LLM 判断需要实时数据,调用的是 searchFlights 而非 searchKnowledge)
为您查到 3 个航班:
| 航班号 | 航空公司 | 起飞→到达 | 价格 |
|--------|---------|----------|------|
| MU5678 | 东方航空 | 08:00→10:15 | ¥520 |
| HU7890 | 海南航空 | 17:00→19:20 | ¥550 |
| CA1234 | 中国国航 | 12:30→14:40 | ¥680 |六、FAQ 与踩坑记录
Q1:切分后的片段之间有语义断裂,检索结果答非所问怎么办?
现象:用户问"经济舱退票手续费",检索到的片段只包含"商务舱退票"的内容,因为"经济舱退票"信息被切分到另一个片段中。
解决方案:
- 使用带 overlap 的切分策略,让相邻片段有 10%-20% 的重叠内容
- 对结构化文档(如政策文档),按标题/章节切分而不是按固定字符数
- 在切分后人工抽查关键信息是否完整
Q2:Embedding 模型更换后,旧数据检索不到了
现象 :从 all-MiniLM-L6-v2 切换到 text-embedding-v3 后,原有向量库中的数据全部检索失效,相似度分数极低。
原因:不同 Embedding 模型产生的向量维度和空间分布不同,无法互相匹配。
解决方案:
- 更换模型后必须对所有文档重新向量化入库
- 建议在生产环境中将 Embedding 模型版本记录在元数据中,方便追溯
- 切换前先在测试环境验证新模型的检索效果
Q3:SimpleVectorStore 在应用重启后数据丢失
现象 :开发环境使用 SimpleVectorStore,每次重启 Spring Boot 应用后知识库数据全部丢失,需要重新入库。
解决方案:
- 开发环境可以在
CommandLineRunner中每次启动时自动入库(如本章示例) - 生产环境务必切换到持久化 VectorStore(Redis / ES / Milvus)
SimpleVectorStore支持save(File)和load(File)方法,可将数据序列化到本地文件作为临时方案
本章总结 & 下一章预告
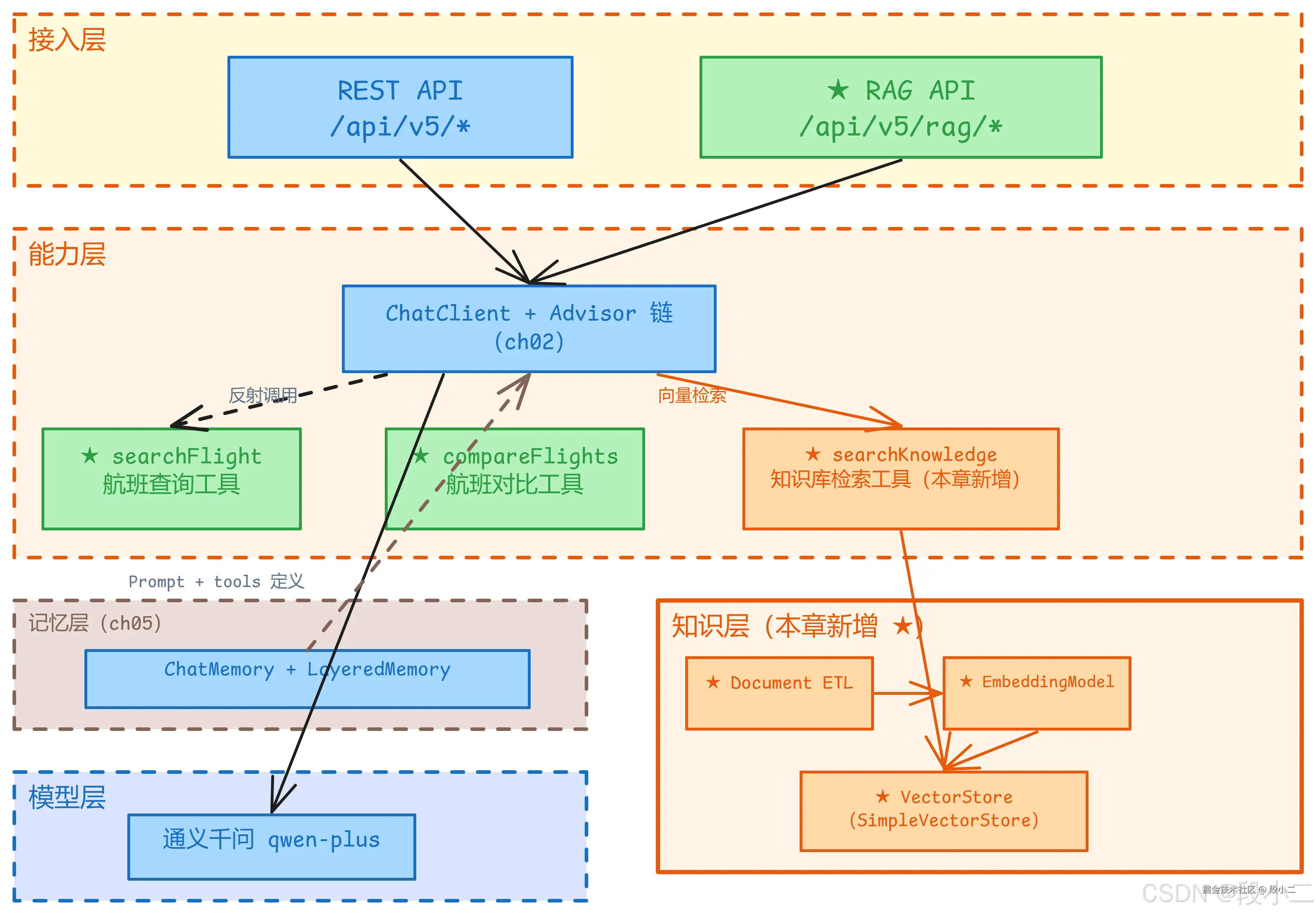
架构演进:本章新增的组件(★标记):
!
本章你学到了:
| 模块 | 核心知识点 |
|---|---|
| RAG 本质 | 开卷考试、vs 微调 vs Function Calling、离线索引 + 在线查询 |
| Document ETL | 文档加载(多格式)、文档切分(语义完整性)、Embedding 选型、VectorStore |
| Two-Step RAG | RetrievalAugmentationAdvisor、每次自动检索、简单但局限 |
| Agentic RAG | 检索作为 Tool、LLM 自主决定何时检索、可与其他工具协同 |
| Hybrid RAG | 查询增强(改写优化)、检索验证(充分性检查)、回答验证(忠实度检查) |
| 生产实践 | 混合检索(向量+关键词)、Re-ranking 精排、VectorStore 选型、RAG 评估体系 |
下一章预告:完整 Agent 集成实战
前6章的零件终于要组装了------下一篇我们将把 Function Calling + RAG + Memory + SafeGuard 焊成一个完整的"票小蜜"Agent:
- Advisor 链编排:SafeGuard → Memory → Logger 的正确顺序
- Tool 注册与激活 :
@Bean + @Description+.toolNames()按需激活 - Agentic RAG 集成:searchKnowledge 作为 Tool 与其他工具协同
- SafeGuardAdvisor:输入护栏的能力边界
- 7 个场景一个接口:航班查询、对比、政策问答、上下文推理、闲聊、护栏、断点恢复
本文代码仓库 :GitHub 链接(完成项目后补充) 系列目录 :Spring AI Alibaba Agent 实战系列 上一篇:(四)Memory 对话记忆与 Checkpoint
评论区聊聊
- 你的 RAG 用了哪种架构? Two-Step、Agentic 还是 Hybrid?实际检索准确率能到多少?遇到过哪些切分或检索的坑?
- 你的知识库有多大? 如果文档量不大(< 100 页),你会选择长上下文直塞还是 RAG?理由是什么?
- VectorStore 你选了什么? Redis、ES、Milvus 还是云托管?选型时最看重的因素是什么------性能、运维成本还是已有基础设施?
- RAG 上线后最头疼的维护问题是什么? 文档更新、Embedding 模型切换、检索漂移......你是怎么解决的?
如果这篇文章对你有帮助,欢迎点赞收藏。有问题欢迎评论区交流。