在多模态浪潮加速的 2025 年,美团再次交出了一份令人惊艳的答卷。
继 LongCat-Flash-Chat 与 LongCat-Flash-Thinking 之后,LongCat 系列迎来了新成员------LongCat-Flash-Omni。

它不仅是美团 LongCat 团队在大语言模型之后的重要升级,更是开源社区首次实现**"全模态覆盖 + 端到端架构 + 大参数高效推理"于一体的模型 。
****Omni 不只是能"看图""听声""说话",它正在让 AI 真正具备**理解世界的多感官能力。
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:AIHub,欢迎关注收藏!
一、从 Flash 到 Omni
LongCat-Flash 系列一直以高效架构和极致响应速度闻名,Omni 则在此基础上,迈出了从单一输入到"全模态协同"的一步。
LongCat-Flash-Omni = 高效架构 + 多模态感知 + 实时语音交互
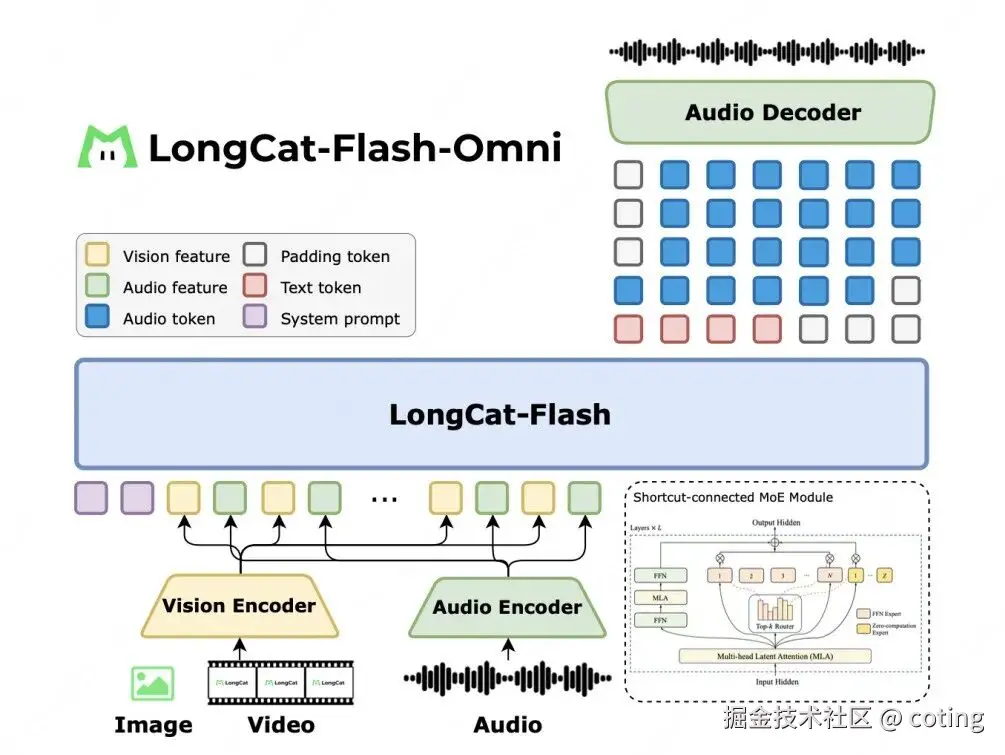
它集成了视觉、音频、文本和视频等多种输入形式,并通过创新的 Shortcut-Connected MoE(ScMoE)架构(含零计算专家),在保持超大参数规模(总参数 5600 亿,激活 270 亿)的同时,实现了毫秒级低延迟的流式交互体验。
这意味着,即使是面对长达数分钟的音视频输入,它依然能做到实时响应与自然交流。
二、端到端架构
不同于传统的多模态模型(往往由独立的感知器 + 文本模型拼接而成),LongCat-Flash-Omni 采用了完全端到端的一体化设计:
- 视觉编码器:轻量高效,参数量仅约 6 亿;
- 音频编解码器:支持语音感知与重建,直接生成自然语音;
- 核心 LLM:直接处理图像、文本、语音等多模态 token;
- 流式推理引擎:支持 128K tokens 上下文与 8 分钟音视频交互。
这种设计的关键在于:所有模态都在统一的 token 空间内协同处理,LLM 不再是"后端翻译机",而是成为多模态信息的中枢处理器。
因此,Omni 不仅能"理解视频讲的是什么",还能在对话中"听懂你的语气""看懂你的表情",实现真正的"听、看、说、想"一体化智能。
三、渐进式多模融合
全模态模型的最大难题是------不同模态的数据分布完全不同。Omni 的解决思路是 渐进式早期多模融合训练(Progressive Early Fusion)。
它把复杂的多模态学习过程分为六个阶段,从语言出发,逐步融入听觉与视觉能力:
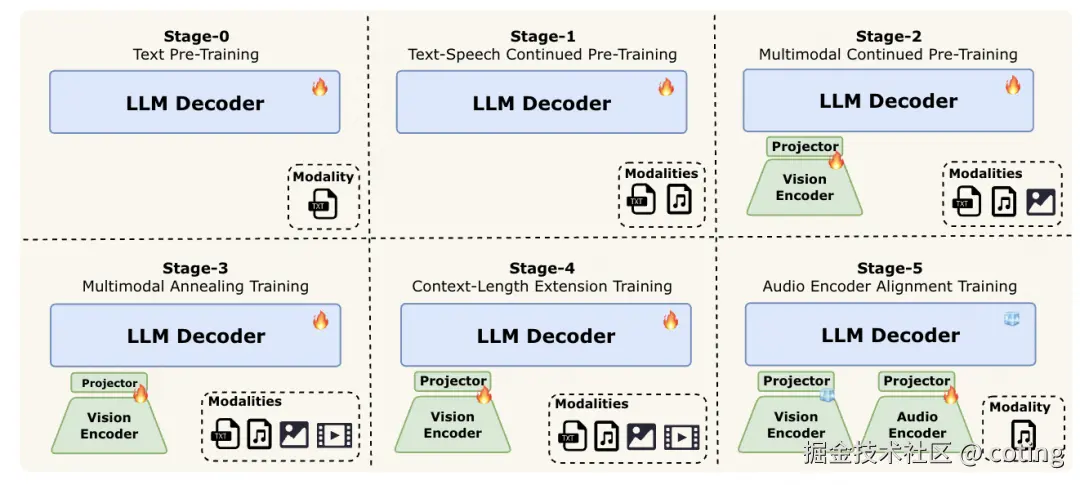
- 阶段 0:文本预训练 ------ 奠定语言理解基础;
- 阶段 1:语音引入 ------ 对齐声学表征与语言特征空间;
- 阶段 2:图文融合 ------ 加入大规模图像-文本对齐语料;
- 阶段 3:视频理解 ------ 引入动态视频数据,提升时空推理;
- 阶段 4:上下文扩展 ------ 上下文窗口拓展至 128K tokens;
- 阶段 5:语音对齐训练 ------ 缓解离散 token 信息丢失,提升语音保真度。
这种"逐层注入"策略让 Omni 在保持稳定文本能力的同时,实现了真正的全模态协同,各模态之间不再相互牵制,而是互相增强。
四、性能
在综合评估(Omni-Bench、WorldSense)中,LongCat-Flash-Omni 达到了开源最先进水平(SOTA)。
其单模态与跨模态表现同样亮眼:
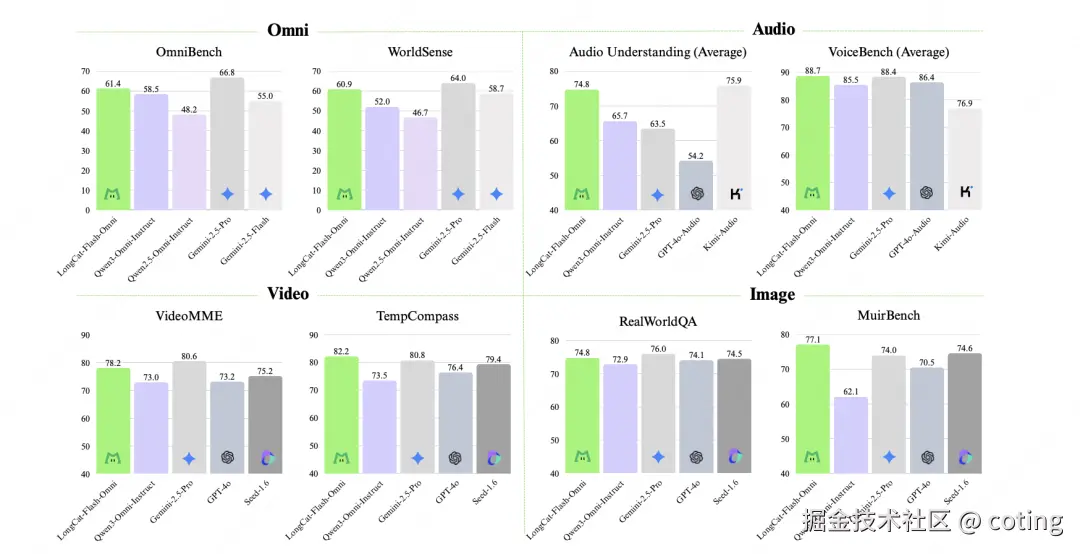
不仅如此,Omni 在端到端交互评分中也表现突出,在 250 名用户与 10 名专家评测中,其自然度与流畅度比当前最优开源模型 Qwen3-Omni 高出 0.56 分 ,接近闭源旗舰 Gemini-2.5-Pro 的实时交互体验。
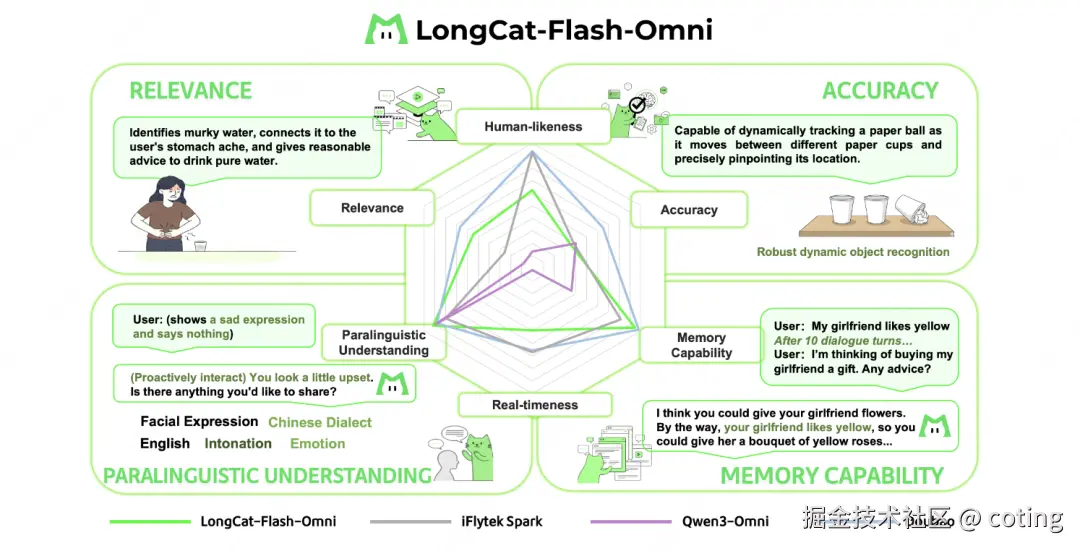
五、高效推理
Omni 的另一项核心突破,是在 5600 亿参数规模下依然保持毫秒级响应,秘诀在于 ScMoE(Shortcut-Connected Mixture of Experts)架构与"零计算专家"的组合。
- ScMoE 让模型只激活部分专家(约 270 亿参数),极大降低计算成本;
- "零计算专家"让路由层可以快速跳过冗余分支,实现流式处理;
- 结合"分块式音视频特征交织机制",保证音视频处理的连续性与低延迟。
最终,Omni 成为首个在开源范畴内实现**"大模型 + 实时交互"**的系统。
LongCat-Flash-Omni 的出现标志着一个转折点,AI 不再只是语言专家,而是一个能真正"感知世界"的多模态智能体,它能看图、能听声、能理解语气、能生成语音,并在同一框架下完成跨模态推理。
这不只是一次技术升级,更是世界模型方向的又一次重要跃迁:从理解文字 → 理解感官 → 理解世界。
当 AI 拥有了多模态感知能力,它也就拥有了通向具身智能的感知接口,多模态智能正在从功能叠加走向统一理解。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号coting!
📚 推荐阅读