在你开始写代码之前,请阅读xv6手册《book-riscv-rev1》的第2章、第4章的第4.3节和第4.4节以及相关源代码文件:
系统调用的用户空间代码在user/user.h和user/usys.pl中。
内核空间代码是kernel/syscall.h、kernel/syscall.c。
与进程相关的代码是kernel/proc.h和kernel/proc.c。
xv6手册《book-riscv-rev1》第二章
抽象系统资源
当谈及操作系统时,人们可能会问的第一个问题是为什么需要它?也就是说,我们可以将系统调用实现为一个库,应用程序可以与之链接。在此方案中,每个应用程序甚至可以根据自己的需求定制自己的库。应用程序可以直接与硬件资源交互 ,并以应用程序的最佳方式使用这些资源(例如,实现高性能或可预测的性能)。一些嵌入式设备或实时系统的操作系统就是这样组织的。
这种库函数方法的缺点是,如果有多个应用程序在运行,这些应用程序必须表现良好。例如,每个应用程序必须定期放弃中央处理器 ,以便其他应用程序能够运行。如果所有应用程序都相互信任并且没有错误,这种协同操作的分时方案可能是可以的。 然而更典型的情况是, 应用程序互不信任且存在bug,所以人们通常希望提供比合作方案更强的隔离。为了实现强隔离, 最好禁止应用程序直接访问敏感的硬件资源,而是将资源抽象为服务 。 例如,Unix应用程序只通过文件系统的open、read、write和close系统调用与存储交互,而不是直接读写磁盘。
同样,Unix在进程之间透明地切换硬件处理器,根据需要保存和恢复寄存器状态,这样应用程序就不必意识到分时共享的存在。这种透明性允许操作系统共享处理器,即使有些应用程序处于无限循环中。
用户态,核心态,以及系统调用
强隔离需要应用程序和操作系统之间的硬边界,如果应用程序出错,我们不希望操作系统失败或其他应用程序失败,相反,操作系统应该能够清理失败的应用程序,并继续运行其他应用程序,要实现强隔离,操作系统必须保证应用程序不能修改 (甚至读取)操作系统的数据结构和指令,以及应用程序不能访问其他进程的内存。
CPU为强隔离提供硬件支持。例如,RISC-V有三种CPU可以执行指令的模式:机器模式(Machine Mode)、用户模式(User Mode)和管理模式(Supervisor Mode)。在机器模式下执行的指令具有完全特权 ;CPU在机器模式下启动。机器模式主要用于配置计算机。Xv6在机器模式下执行很少的几行代码,然后更改为管理模式。
在管理模式下,CPU被允许执行特权指令:例如,启用和禁用中断、读取和写入保存页表地址的寄存器等。如果用户模式下的应用程序试图执行特权指令,那么CPU不会执行该指令,而是切换到管理模式,以便管理模式代码可以终止应用程序,因为它做了它不应该做的事情。
内核组织
一个关键的设计问题是操作系统的哪些部分应该以管理模式运行。一种可能是整个操作系统都驻留在内核中,这样所有系统调用的实现都以管理模式运行。这种组织被称为宏内核
在这种组织中,整个操作系统以完全的硬件特权运行。这个组织很方便,因为操作系统设计者不必考虑操作系统的哪一部分不需要完全的硬件特权。此外,操作系统的不同部分更容易合作。例如,一个操作系统可能有一个可以由文件系统和虚拟内存系统共享的数据缓存区。
宏组织的一个缺点是操作系统不同部分之间的接口通常很复杂,因此操作系统开发人员很容易犯错误。在宏内核中,一个错误就可能是致命的,因为管理模式中的错误经常会导致内核失败。如果内核失败,计算机停止工作,因此所有应用程序也会失败。计算机必须重启才能再次使用。
为了降低内核出错的风险,操作系统设计者可以最大限度地减少在管理模式下运行的操作系统代码量 ,并在用户模式下执行大部分操作系统 。这种内核组织被称为微内核 、
像大多数Unix操作系统一样,Xv6是作为一个宏内核实现的。因此,xv6内核接口对应于操作系统接口,内核实现了完整的操作系统。
进程
Xv6中的隔离单位是一个进程。进程抽象防止一个进程破坏或监视另一个进程的内存、CPU、文件描述符 等。它还防止一个进程破坏内核本身,这样一个进程就不能破坏内核的隔离机制。内核必须小心地实现进程抽象,因为一个有缺陷或恶意的应用程序可能会欺骗内核或硬件做坏事(例如,绕过隔离)。内核用来实现进程的机制包括用户/管理模式标志、地址空间和线程的时间切片。
为了帮助加强隔离,进程抽象给程序提供了一种错觉,即它有自己的专用机器 。进程为程序提供了一个看起来像是私有内存系统或地址空间的东西,其他进程不能读取或写入。进程还为程序提供了看起来像是自己的CPU来执行程序的指令。
Xv6使用页表(由硬件实现)为每个进程提供自己的地址空间。RISC-V页表将虚拟地址(RISC-V指令操纵的地址)转换(或"映射")为物理地址(CPU芯片发送到主存储器的地址)。
一个进程可以通过执行RISC-V的ecall指令进行系统调用,该指令提升硬件特权级别,并将程序计数器(PC)更改为内核定义的入口点,入口点的代码切换到内核栈,执行实现系统调用的内核指令,当系统调用完成时,内核切换回用户栈,并通过调用sret指令返回用户空间,该指令降低了硬件特权级别,并在系统调用指令刚结束时恢复执行用户指令。进程的线程可以在内核中"阻塞"等待I/O,并在I/O完成后恢复到中断的位置。
启动XV6和第一个进程
当RISC-V计算机上电时,它会初始化自己并运行一个存储在只读内存中的引导加载程序。引导加载程序将xv6内核加载到内存中。然后,在机器模式下,中央处理器从_entry (kernel/entry.S:6)开始运行xv6。Xv6启动时页式硬件(paging hardware)处于禁用模式:也就是说虚拟地址将直接映射到物理地址
system call tracing
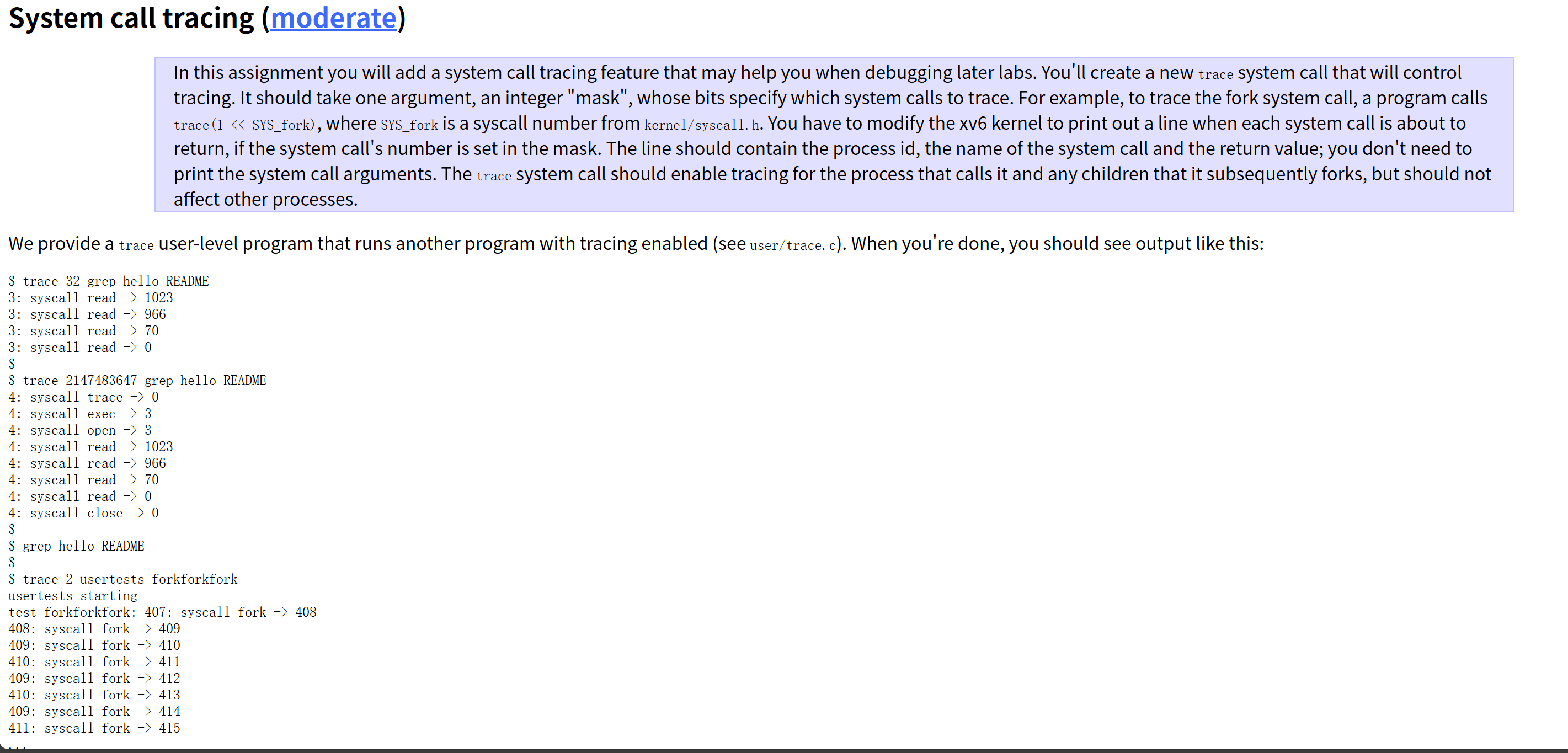
先看用户态user/trace.c的实现
c
int
main(int argc, char *argv[])
{
int i;
char *nargv[MAXARG];
if(argc < 3 || (argv[1][0] < '0' || argv[1][0] > '9')){
fprintf(2, "Usage: %s mask command\n", argv[0]);
exit(1);
}
if (trace(atoi(argv[1])) < 0) {
fprintf(2, "%s: trace failed\n", argv[0]);
exit(1);
}
for(i = 2; i < argc && i < MAXARG; i++){
nargv[i-2] = argv[i];
}
exec(nargv[0], nargv);
exit(0);
}其中trace(atoi(argv1),调用了系统调用,把参数掩码传入内核,之后通过 exec() 执行目标程序,让目标程序继承当前进程的跟踪掩码,从而实现对目标程序系统调用的跟踪。
而trace具体实现在usys.S中,
c
.global trace
trace:
li a7, SYS_trace
ecall
ret把系统调用编号SYS_trace放入a7寄存器中,通过ecall触发陷阱,调用内核。再把内核的返回值带回用户态;
内核状态下系统调用
uint64
sys_trace(void)
{
argint(0,&(myproc()->trace_mask));
return 0;
}
将传入的第0个参数赋值给myproc()->trace_mask)当前进程就记录了需要跟踪的掩码
注意我们需要修改fork函数 使得子进程也有这个掩码
c
np->trace_mask = p->trace_mask;
pid = np->pid;
// ...接下来我们需要考虑的是如何跟踪每个系统调用 打印出信息 自然想到在syscall中
c
void
syscall(void)
{
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
// Use num to lookup the system call function for num, call it,
// and store its return value in p->trapframe->a0
p->trapframe->a0 = syscalls[num]();
if((1<<num)&p->trace_mask)
printf("%d:syscall %s -> %d \n",p->pid,syscalls_name[num],p->trapframe->a0);
} else {
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}我们需要判断 系统调用号(存在a7里面)构建一个仅第num位是1 其余位是0的掩码 与p->tracemask同一个比特位同时为1时 条件成立,打印出进程ID,调用名称和返回结果。
然后下面是系统调用的核心映射表(部分)
c
static uint64 (*syscalls[])(void) = {
[SYS_fork] sys_fork,
[SYS_exit] sys_exit,
[SYS_wait] sys_wait,
[SYS_pipe] sys_pipe,前面的是宏定义 定义在 kernel/syscall.h,比如 #define SYS_fork 1, 每个系统调用都有一个整数编号
这是一个函数指针数组,核心作用是根据系统调用编号,找到内核中对应的实现函数。
c
static char *syscalls_name[] = {
[SYS_fork] "fork",
[SYS_exit] "exit",
[SYS_wait] "wait",
[SYS_pipe] "pipe",
[SYS_read] "read",这个是这是一个字符串指针数组 在打印系统调用名称时使用
sysinfo
 在这个作业中,您将添加一个系统调用sysinfo,它收集有关正在运行的系统的信息。系统调用采用一个参数:一个指向struct sysinfo的指针(参见kernel/sysinfo.h)。内核应该填写这个结构的字段:freemem字段应该设置为空闲内存的字节数,nproc字段应该设置为state字段不为UNUSED的进程数。我们提供了一个测试程序sysinfotest;如果输出"sysinfotest: OK"则通过。
在这个作业中,您将添加一个系统调用sysinfo,它收集有关正在运行的系统的信息。系统调用采用一个参数:一个指向struct sysinfo的指针(参见kernel/sysinfo.h)。内核应该填写这个结构的字段:freemem字段应该设置为空闲内存的字节数,nproc字段应该设置为state字段不为UNUSED的进程数。我们提供了一个测试程序sysinfotest;如果输出"sysinfotest: OK"则通过。
提示:
在Makefile的UPROGS中添加$U/_sysinfotest
当运行make qemu时,user/sysinfotest.c将会编译失败,遵循和上一个作业一样的步骤添加sysinfo系统调用。要在user/user.h中声明sysinfo()的原型,需要预先声明struct sysinfo的存在:
struct sysinfo;
int sysinfo(struct sysinfo *);
一旦修复了编译问题,就运行sysinfotest;但由于您还没有在内核中实现系统调用,执行将失败。
sysinfo需要将一个struct sysinfo复制回用户空间;请参阅sys_fstat()(kernel/sysfile.c)和filestat()(kernel/file.c)以获取如何使用copyout()执行此操作的示例。
要获取空闲内存量,请在kernel/kalloc.c中添加一个函数
要获取进程数,请在kernel/proc.c中添加一个函数
下面一步步实现
1.前两个提示很简单 直接加上
2.sysinfo需要将一个struct sysinfo复制回用户空间,参考sys_fstat()和filestat()如何使用copyout()
c
uint64
sys_fstat(void)
{
struct file *f;
uint64 st; // user pointer to struct stat
// 步骤1:读取用户态传入的第二个参数(&st)→ 存入变量 st
argaddr(1, &st);
// 步骤2:读取用户态传入的第一个参数(fd),找到对应的内核 file 结构体
// argfd(0, 0, &f):解析第0个参数(fd),验证权限,返回对应的 file 指针
if(argfd(0, 0, &f) < 0)
return -1;
return filestat(f, st);
}
int
filestat(struct file *f, uint64 addr)
{
struct proc *p = myproc();
struct stat st;
// 步骤1:仅处理 inode 文件(普通文件)或设备文件
if(f->type == FD_INODE || f->type == FD_DEVICE){
ilock(f->ip);
// 步骤3:从 inode 读取元信息,填充到内核态 st
stati(f->ip, &st);
// 步骤4:解锁 inode
iunlock(f->ip);
// 步骤5:把内核态 st 复制到用户态缓冲区(addr 是用户态地址)
if(copyout(p->pagetable, addr, (char *)&st, sizeof(st)) < 0)
return -1;
return 0;
}
return -1;
}用户态程序调用 fstat(fd, &st) 时:fd:文件描述符(标识已打开的文件);&st:用户态的 struct stat 缓冲区地址;
内核通过 sys_fstat 找到文件,读取元信息,再通过 filestat 把信息复制到用户态缓冲区
因此我们的复制这样写
c
if (copyout(myproc()->pagetable, dstaddr, (char *)&sinfo, sizeof sinfo) < 0)
return -1;3.在kernel/kalloc.c中添加一个函数用于获取空闲内存量
c
void get_free_memory(uint64 *dst)
{
*dst = 0;
struct run *p = kmem.freelist;
acquire(&kmem.lock);
while(p){
*dst +=PGSIZE;
p=p->next;
}
release(&kmem.lock);
}4.在kernel/proc.c中添加一个函数获取进程数
c
void
procnum(uint64 *dst)
{
*dst = 0;
struct proc *p;
for (p = proc; p < &proc[NPROC]; p++) {
if (p->state != UNUSED)
(*dst)++;
}
}5.下面实现sys_info
c
uint64
sys_sysinfo(void)
{
struct sysinfo sinfo;
get_free_memory(&sinfo.freemem);
procnum(&sinfo.nproc);
//uint64 dstaddr;:定义一个 64 位无符号整数变量,用于存储用户态地址(xv6 是 64 位系统,地址宽度为 64 位);
uint64 dstaddr;
//argaddr(0, &dstaddr);:调用 xv6 内核内置函数 argaddr,解析系统调用的第 0 个参数,将其值(用户态地址)写入 dstaddr
argaddr(0, &dstaddr);
if (copyout(myproc()->pagetable, dstaddr, (char *)&sinfo, sizeof sinfo) < 0)
return -1;
return 0;
}运行会报错
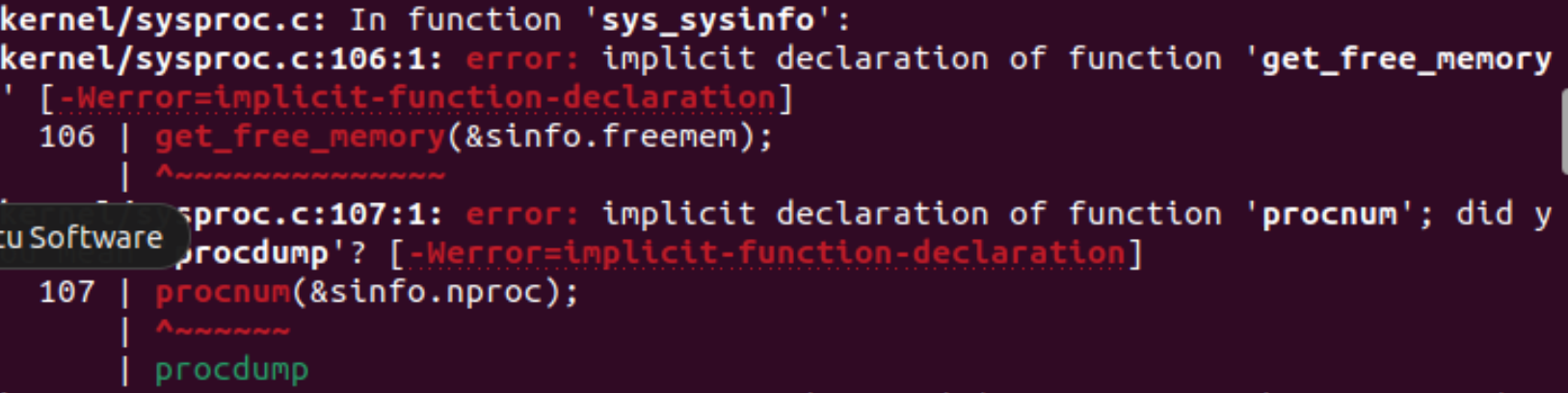
函数在使用前未声明
我们在sysproc.c调用这两个函数,但是没有声明 这个文件的头文件包括proc.h 在这个里加上函数声明
c
void get_free_memory(uint64 *freemem);
void procnum(uint64 *nproc); 通过测试!