目录
- [1. MongoDB概述与核心概念](#1. MongoDB概述与核心概念)
- [2. 数据模型与BSON数据结构](#2. 数据模型与BSON数据结构)
- [3. WiredTiger存储引擎深度剖析](#3. WiredTiger存储引擎深度剖析)
- [4. 索引原理与优化策略](#4. 索引原理与优化策略)
- [5. 复制集架构与高可用](#5. 复制集架构与高可用)
- [6. 分片集群架构](#6. 分片集群架构)
- [7. 事务与一致性保证](#7. 事务与一致性保证)
- [8. 查询执行引擎](#8. 查询执行引擎)
- [9. Java集成与最佳实践](#9. Java集成与最佳实践)
- [10. 生产环境优化建议](#10. 生产环境优化建议)
1. MongoDB概述与核心概念
1.1 什么是MongoDB
MongoDB是一个基于文档的分布式NoSQL数据库,由C++语言编写。它诞生于2009年,名字来源于"Humongous"(巨大的),寓意能够处理海量数据。
核心特性:
- 面向文档:数据以JSON风格的文档形式存储(BSON格式)
- Schema灵活:无需预先定义表结构,同一集合的文档可以有不同字段
- 水平扩展:原生支持分片(Sharding),轻松应对PB级数据
- 高可用:通过副本集(Replica Set)实现自动故障转移
- 丰富查询:支持聚合管道、地理空间查询、全文检索
- ACID事务:从4.0版本开始支持多文档事务
1.2 MongoDB与关系型数据库对比
| 概念 | MongoDB | 关系型数据库(MySQL) |
|---|---|---|
| 数据模型 | 文档(Document) | 行(Row) |
| 集合 | Collection | Table |
| 字段 | Field | Column |
| 主键 | _id(自动生成ObjectId) | Primary Key |
| 关联 | 嵌入文档或引用 | JOIN |
| Schema | 动态Schema | 固定Schema |
| 扩展方式 | 水平扩展(Sharding) | 垂直扩展为主 |
1.3 适用场景
适合MongoDB的场景:
- 内容管理系统(CMS):文章、博客、评论等非结构化数据
- 实时分析:日志收集、用户行为分析
- 物联网(IoT):传感器数据、时序数据
- 电商系统:商品目录、购物车、订单(字段频繁变化)
- 社交网络:用户资料、动态、好友关系
- 大数据存储:需要水平扩展的海量数据
不适合MongoDB的场景:
- 需要复杂多表JOIN的业务
- 需要严格ACID事务的金融核心系统(虽然支持事务,但性能不如关系型数据库)
- 数据结构高度规范化的场景
1.4 核心术语
MongoDB实例 Database 数据库 Collection 集合1 Collection 集合2 Document 文档1 Document 文档2 Document 文档3 Field: value Field: value Embedded Document
Document(文档):
- MongoDB的基本数据单元,相当于关系型数据库的一行
- 采用BSON格式(Binary JSON)
- 文档大小限制:16MB
Collection(集合):
- 文档的集合,相当于关系型数据库的表
- 无需预定义Schema
- 同一集合的文档可以有完全不同的结构
Database(数据库):
- 集合的容器
- 每个数据库有独立的文件存储
- 系统保留数据库:admin、local、config
2. 数据模型与BSON数据结构
2.1 BSON数据格式
BSON(Binary JSON)是MongoDB存储数据的二进制编码格式,相比JSON有以下优势:
BSON vs JSON:
| 特性 | BSON | JSON |
|---|---|---|
| 编码方式 | 二进制 | 文本 |
| 空间效率 | 较低(包含类型和长度信息) | 较高 |
| 解析速度 | 快(可跳过不需要的字段) | 慢(需要完整解析) |
| 数据类型 | 支持Date、Binary、ObjectId等 | 仅支持基本类型 |
| 可读性 | 不可读 | 可读 |
BSON支持的数据类型:
javascript
{
// 基本类型
"string": "Hello MongoDB",
"integer": 42,
"double": 3.14159,
"boolean": true,
"null": null,
// MongoDB特有类型
"_id": ObjectId("507f1f77bcf86cd799439011"), // 12字节唯一标识符
"date": ISODate("2025-12-22T10:30:00Z"), // 日期时间
"timestamp": Timestamp(1640000000, 1), // 时间戳(用于内部)
// 复合类型
"array": [1, 2, 3, "mixed"],
"embedded_doc": {
"nested_field": "value"
},
// 特殊类型
"binary": BinData(0, "base64data"), // 二进制数据
"regex": /pattern/i, // 正则表达式
"code": function() { return 1; }, // JavaScript代码
"minKey": MinKey(), // 最小值
"maxKey": MaxKey() // 最大值
}2.2 ObjectId详解
ObjectId是MongoDB默认的主键类型,12字节(96位)结构如下:
ObjectId = 4字节时间戳 + 5字节随机值 + 3字节计数器
[ 4字节 ][ 5字节 ][ 3字节 ]
[ Timestamp ][ Random Value ][ Counter ]
[ 时间戳 ][ 机器ID+进程ID ][ 计数器 ]结构分解:
- 时间戳(4字节):Unix时间戳(秒),表示ObjectId的创建时间
- 随机值(5字节):每个进程生成一次,保证不同机器/进程的唯一性
- 计数器(3字节):同一秒内生成的ObjectId递增,初始值随机
特性:
- 全局唯一:无需中心化ID生成器,分布式环境下不会冲突
- 包含时间信息:可以从ObjectId中提取创建时间
- 有序性:ObjectId大致按时间递增(不严格单调)
- 性能高:本地生成,无需网络调用
Java代码示例:
java
import org.bson.types.ObjectId;
import java.util.Date;
// 生成ObjectId
ObjectId id = new ObjectId();
// 获取时间戳
Date timestamp = id.getDate();
// 从字符串解析
ObjectId parsed = new ObjectId("507f1f77bcf86cd799439011");
// 比较大小(可用于范围查询)
ObjectId id1 = new ObjectId();
ObjectId id2 = new ObjectId();
boolean isLater = id2.compareTo(id1) > 0; // id2更晚创建2.3 数据建模策略
MongoDB的数据建模核心在于权衡嵌入(Embedding)和引用(Referencing)。
2.3.1 嵌入式文档(Embedding)
适用场景:
- 一对一关系
- 一对少量关系(1:N,N < 100)
- 数据经常一起读取
- 数据更新频率低
示例:用户与地址
javascript
{
"_id": ObjectId("..."),
"username": "zhangsan",
"email": "zhangsan@example.com",
"addresses": [ // 嵌入式数组
{
"type": "home",
"province": "广东省",
"city": "深圳市",
"detail": "南山区科技园"
},
{
"type": "work",
"province": "广东省",
"city": "深圳市",
"detail": "福田区CBD"
}
],
"created_at": ISODate("2025-01-01T00:00:00Z")
}优势:
- ✅ 单次查询获取所有数据(无需JOIN)
- ✅ 原子性更新(单文档事务)
- ✅ 更好的读性能
劣势:
- ❌ 文档大小限制16MB
- ❌ 嵌入数据过多导致文档膨胀
- ❌ 嵌入数据重复存储
2.3.2 引用式文档(Referencing)
适用场景:
- 一对多关系(N很大)
- 多对多关系
- 数据独立更新频繁
- 数据在多处被引用
示例:博客文章与评论
javascript
// 文章集合(posts)
{
"_id": ObjectId("post001"),
"title": "MongoDB深度解析",
"author": "张三",
"content": "...",
"created_at": ISODate("2025-12-01T00:00:00Z")
}
// 评论集合(comments)
{
"_id": ObjectId("comment001"),
"post_id": ObjectId("post001"), // 引用文章ID
"user_id": ObjectId("user001"), // 引用用户ID
"content": "写得真好!",
"created_at": ISODate("2025-12-02T10:00:00Z")
}优势:
- ✅ 文档大小可控
- ✅ 数据不重复
- ✅ 更新更灵活
劣势:
- ❌ 需要多次查询(类似JOIN)
- ❌ 没有外键约束,需应用层维护一致性
2.3.3 混合模式
实战案例:电商订单建模
javascript
{
"_id": ObjectId("order001"),
"order_no": "2025122201001",
// 冗余用户核心信息(嵌入)
"user": {
"user_id": ObjectId("user001"),
"username": "张三",
"mobile": "13800138000"
},
// 收货地址(嵌入)
"shipping_address": {
"province": "广东省",
"city": "深圳市",
"detail": "南山区科技园",
"mobile": "13800138000"
},
// 订单商品(嵌入快照)
"items": [
{
"product_id": ObjectId("prod001"),
"product_name": "MacBook Pro", // 商品快照
"price": 12999.00, // 下单时价格
"quantity": 1
}
],
"total_amount": 12999.00,
"status": "pending", // 待支付
"created_at": ISODate("2025-12-22T10:30:00Z")
}设计原则:
- 冗余热数据:订单保存商品快照,避免商品信息变更影响历史订单
- 引用主数据:保留product_id,方便关联查询最新商品信息
- 嵌入小集合:收货地址直接嵌入,避免额外查询
2.4 文档设计最佳实践
规则1:根据查询模式设计Schema
javascript
// ❌ 错误:商品评论单独存储,查询商品需要JOIN
// products collection
{ "_id": 1, "name": "iPhone" }
// reviews collection
{ "product_id": 1, "content": "很好用" }
// ✅ 正确:嵌入少量评论,支持单次查询
{
"_id": 1,
"name": "iPhone",
"reviews": [
{ "user": "张三", "content": "很好用", "rating": 5 }
]
}规则2:避免文档无限增长
javascript
// ❌ 错误:日志直接追加到用户文档,导致文档无限膨胀
{
"_id": ObjectId("user001"),
"username": "zhangsan",
"logs": [ // 可能增长到数万条
{ "action": "login", "time": "..." },
{ "action": "view", "time": "..." },
// ... 数万条日志
]
}
// ✅ 正确:日志独立存储,按用户ID索引
// logs collection
{
"_id": ObjectId("..."),
"user_id": ObjectId("user001"),
"action": "login",
"created_at": ISODate("...")
}规则3:合理使用数组
- ✅ 数组元素 < 100时可以嵌入
- ✅ 使用
$slice限制返回的数组元素数量 - ❌ 避免数组元素超过1000(性能急剧下降)
3. WiredTiger存储引擎深度剖析
3.1 存储引擎概述
MongoDB 3.2版本开始使用WiredTiger作为默认存储引擎,取代了早期的MMAPv1。WiredTiger是一个开源的、高性能的存储引擎,专为现代硬件优化。
WiredTiger核心特性:
- 文档级并发控制(MVCC):支持无锁读写
- 数据压缩:支持Snappy、zlib、zstd压缩算法
- Checkpoint机制:定期持久化数据,保证崩溃恢复
- Journal日志:Write-Ahead Logging(WAL),保证数据不丢失
- 缓存管理:独立的缓存层,默认使用50%系统内存
3.2 存储架构
持久化存储 WiredTiger引擎 应用层 Data Files
collection-*.wt Index Files
index-*.wt Journal Files
WiredTigerLog.* Metadata
WiredTiger.wt Cache 缓存层
默认50%系统内存 Eviction 淘汰线程 Checkpoint 检查点线程
每60秒 Journal 日志系统
WAL预写日志 MongoDB Query Layer
3.3 MVCC多版本并发控制
核心思想:
- 每个事务看到的是数据的一个快照(Snapshot)
- 读操作不阻塞写操作,写操作不阻塞读操作
- 通过事务ID和版本号实现隔离
数据结构 :
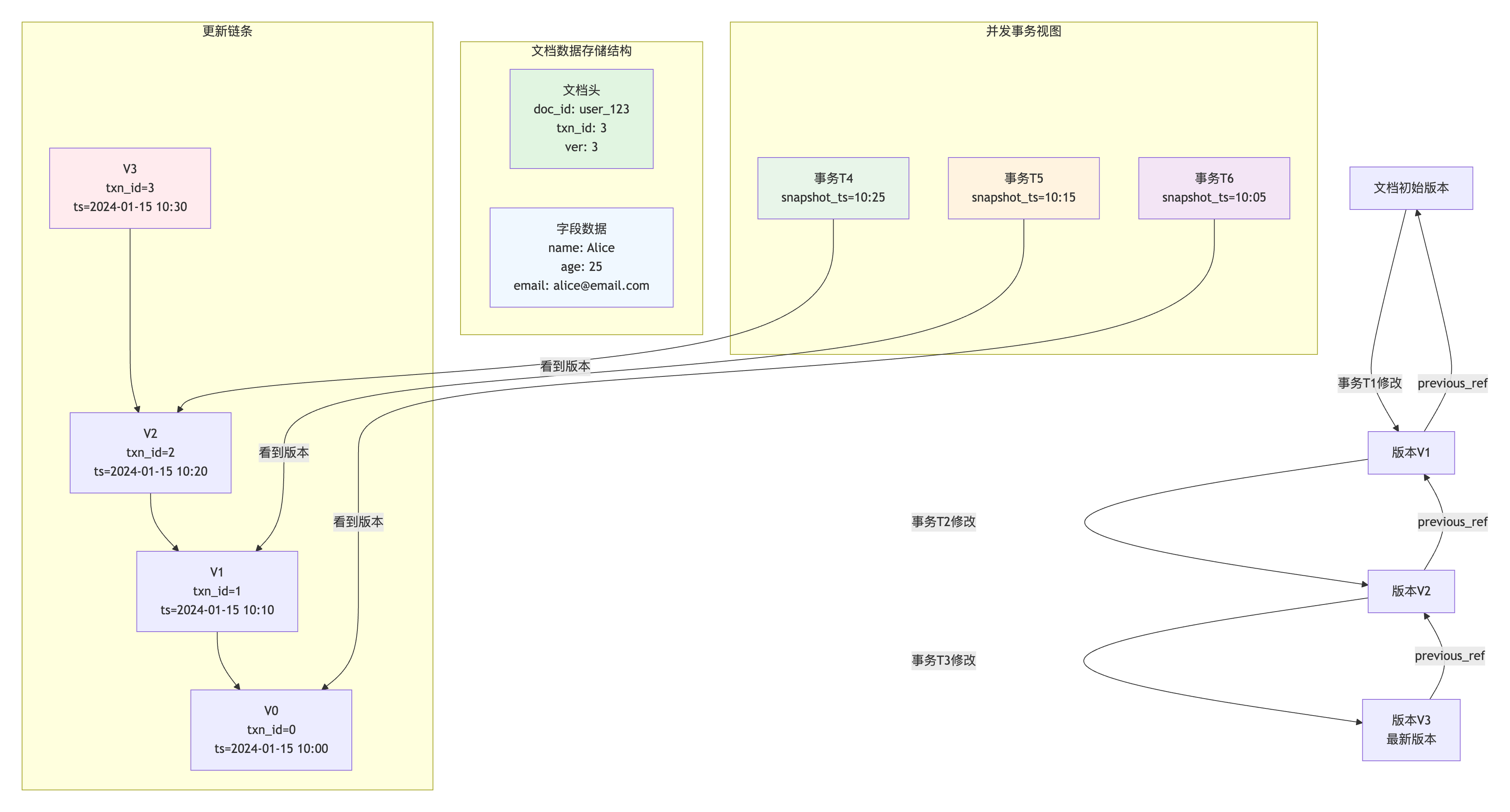
可见性判断:
python
# 伪代码:判断某个版本是否对当前事务可见
def is_visible(doc_version, current_txn):
if doc_version.txn_id <= current_txn.snapshot_id:
if doc_version.txn_id not in current_txn.active_txns:
return True
return False优势:
- ✅ 高并发:读写互不阻塞
- ✅ 一致性读:事务看到的是一致的快照
- ✅ 回滚快:直接丢弃新版本,恢复旧版本
劣势:
- ❌ 空间开销:需要保留历史版本
- ❌ 清理成本:需要定期清理过期版本
3.4 Checkpoint机制
Checkpoint定义 :
将内存中的脏数据(Dirty Pages)批量刷入磁盘的过程,生成数据文件的一致性快照。
触发条件:
- 定时触发:默认每60秒执行一次
- 日志大小触发:Journal日志超过2GB
- 手动触发 :执行
db.fsyncLock()命令
执行流程:
应用 WiredTiger Cache Checkpoint线程 磁盘Data Files 写入数据(更新缓存) 缓存中累积脏页 标记Checkpoint开始点 收集需要刷盘的脏页 后台异步写入 不阻塞读写 批量写入Data Files 更新Metadata元数据 生成一致性快照 loop 每60秒 Checkpoint完成 可安全删除旧Journal 应用 WiredTiger Cache Checkpoint线程 磁盘Data Files
Checkpoint与崩溃恢复:
时间轴:
T0: Checkpoint 1 完成
T1: 写入数据A(Journal记录)
T2: 写入数据B(Journal记录)
T3: Checkpoint 2 开始(标记T3时刻)
T4: 写入数据C(Journal记录)
T5: 【系统崩溃】
T6: 重启恢复
恢复过程:
1. 从Checkpoint 2快照恢复(包含T0-T3的数据)
2. 重放Journal日志(T3-T5的数据A、B、C)
3. 丢弃未提交的事务3.5 Journal预写日志
Journal作用:
- 保证数据持久性(Durability)
- 崩溃后快速恢复
- 避免Checkpoint期间的数据丢失
写入流程:
应用写入 WiredTiger Cache Journal Buffer Journal Files Data Files 1. 写入缓存 2. 写入Journal Buffer 每100ms或缓存满 3. fsync刷盘(持久化) ← 返回成功(保证不丢失) 后台Checkpoint 异步刷Data Files 4. 定期刷盘(每60秒) 应用写入 WiredTiger Cache Journal Buffer Journal Files Data Files
Journal配置:
javascript
// 启动时配置Journal
mongod --dbpath /data/db --journal // 启用Journal(默认)
mongod --dbpath /data/db --nojournal // 禁用Journal(不推荐)
// 调整Journal刷盘频率
db.adminCommand({ setParameter: 1, journalCommitInterval: 100 }) // 默认100ms性能权衡:
| 配置 | 性能 | 持久性 | 适用场景 |
|---|---|---|---|
| Journal启用 + 100ms刷盘 | 中等 | 高(最多丢失100ms数据) | 生产环境(推荐) |
| Journal启用 + 每次写入刷盘 | 低 | 极高(零丢失) | 金融系统 |
| Journal禁用 | 高 | 低(可能丢失Checkpoint间隔数据) | 开发测试环境 |
3.6 缓存管理
WiredTiger Cache配置:
yaml
# mongod.conf
storage:
wiredTiger:
engineConfig:
cacheSizeGB: 4 # 指定缓存大小(GB)
# 默认值:(RAM - 1GB) * 0.5 或 256MB(取较大值)缓存淘汰策略(Eviction):
缓存状态:
├─ 使用率 < 80%:正常运行,无淘汰
├─ 使用率 80%-95%:后台淘汰线程工作
│ └─ 淘汰算法:LRU(Least Recently Used)
│ ├─ 优先淘汰:冷数据、已持久化的干净页
│ └─ 保留:热数据、脏页(需先写Journal)
└─ 使用率 > 95%:应用线程参与淘汰(性能下降)
└─ 触发条件:高并发写入场景脏页刷盘:
python
# 伪代码:脏页刷盘流程
def flush_dirty_pages():
for page in cache.dirty_pages:
if page.last_modify_time < (now - 60s):
# 1. 确保Journal已写入
wait_for_journal_sync(page)
# 2. 写入Data Files
disk.write(page)
# 3. 标记为干净页
page.mark_clean()3.7 数据压缩
压缩算法对比:
| 算法 | 压缩比 | CPU消耗 | 速度 | 适用场景 |
|---|---|---|---|---|
| Snappy | 中等(3:1) | 低 | 快 | 默认(推荐),均衡性能 |
| zlib | 高(5:1) | 高 | 中等 | 存储敏感场景 |
| zstd | 很高(7:1) | 中等 | 快 | MongoDB 4.2+,最佳选择 |
| 无压缩 | 1:1 | 无 | 最快 | CPU敏感场景 |
配置示例:
javascript
// 创建集合时指定压缩算法
db.createCollection("users", {
storageEngine: {
wiredTiger: {
configString: "block_compressor=zstd"
}
}
})
// 索引压缩
db.collection.createIndex(
{ email: 1 },
{ storageEngine: { wiredTiger: { configString: "prefix_compression=true" } } }
)压缩效果:
原始数据大小:100GB
├─ Snappy压缩:~33GB(节省67%)
├─ zlib压缩:~20GB(节省80%)
└─ zstd压缩:~14GB(节省86%)
查询性能影响:
├─ Snappy:几乎无影响(< 5%)
├─ zlib:轻微影响(~10%)
└─ zstd:轻微影响(~8%)4. 索引原理与优化策略
4.1 B树索引结构
MongoDB使用B-Tree(平衡树)作为索引数据结构,与MySQL的B+Tree略有不同。
MongoDB B-Tree特点:
- 数据存储在所有节点(非叶子节点也存数据)
- 支持双向遍历(叶子节点有双向指针)
- 键值对存储 :
(索引键 → 文档指针)
B-Tree vs B+Tree:
| 特性 | MongoDB B-Tree | MySQL B+Tree |
|---|---|---|
| 数据存储位置 | 所有节点 | 仅叶子节点 |
| 叶子节点链表 | 双向链表 | 单向链表 |
| 范围查询效率 | 较低 | 高(叶子节点顺序扫描) |
| 单点查询效率 | 高(可能提前终止) | 中等(必须到叶子节点) |
索引存储结构图:
[50]
/ \
[20, 35] [70, 90]
/ | \ / | \
[10] [25] [40] [60] [80] [95]
↓ ↓ ↓ ↓ ↓ ↓
Doc1 Doc2 Doc3 Doc4 Doc5 Doc6
每个节点存储:
[索引键, 文档位置指针]4.2 索引类型
4.2.1 单字段索引(Single Field Index)
javascript
// 创建单字段索引
db.users.createIndex({ email: 1 }) // 升序
db.users.createIndex({ created_at: -1 }) // 降序
// 使用索引查询
db.users.find({ email: "zhang@example.com" })执行计划分析:
javascript
db.users.find({ email: "zhang@example.com" }).explain("executionStats")
// 输出关键指标
{
"executionStats": {
"executionSuccess": true,
"nReturned": 1, // 返回文档数
"executionTimeMillis": 2, // 执行时间(毫秒)
"totalKeysExamined": 1, // 扫描索引键数
"totalDocsExamined": 1, // 扫描文档数
"executionStages": {
"stage": "FETCH",
"inputStage": {
"stage": "IXSCAN", // 索引扫描
"keyPattern": { "email": 1 },
"indexName": "email_1"
}
}
}
}4.2.2 复合索引(Compound Index)
索引顺序的重要性:
javascript
// 创建复合索引:(status, created_at)
db.orders.createIndex({ status: 1, created_at: -1 })
// ✅ 可以使用索引的查询
db.orders.find({ status: "pending" }) // 使用status前缀
db.orders.find({ status: "pending", created_at: { $gt: date } }) // 使用完整索引
db.orders.find({ status: "pending" }).sort({ created_at: -1 }) // 使用索引排序
// ❌ 无法使用索引的查询
db.orders.find({ created_at: { $gt: date } }) // 跳过status前缀最左前缀原则:
索引:(a, b, c)
支持的查询:
✅ WHERE a = 1
✅ WHERE a = 1 AND b = 2
✅ WHERE a = 1 AND b = 2 AND c = 3
✅ WHERE a = 1 AND c = 3 (部分使用,仅用到a)
不支持的查询:
❌ WHERE b = 2
❌ WHERE c = 3
❌ WHERE b = 2 AND c = 3ESR规则(Equality, Sort, Range):
javascript
// 最优索引设计:等值查询 → 排序字段 → 范围查询
// 查询:WHERE status = 'active' AND age > 18 ORDER BY created_at
// ❌ 错误顺序
db.users.createIndex({ age: 1, status: 1, created_at: -1 })
// ✅ 正确顺序(ESR)
db.users.createIndex({ status: 1, created_at: -1, age: 1 })
// ↑ Equality ↑ Sort ↑ Range4.2.3 多键索引(Multikey Index)
数组字段索引:
javascript
// 文档结构
{
"_id": 1,
"tags": ["mongodb", "database", "nosql"]
}
// 创建多键索引
db.articles.createIndex({ tags: 1 })
// 查询(自动使用索引)
db.articles.find({ tags: "mongodb" }) // 匹配数组中的任意元素
db.articles.find({ tags: { $in: ["mongodb", "redis"] } })多键索引限制:
javascript
// ❌ 禁止:同一个复合索引中包含两个数组字段
db.collection.createIndex({ tags: 1, categories: 1 }) // 报错
// ✅ 允许:一个数组字段 + 一个标量字段
db.collection.createIndex({ tags: 1, status: 1 })4.2.4 文本索引(Text Index)
javascript
// 创建文本索引(支持全文检索)
db.articles.createIndex({ title: "text", content: "text" })
// 全文搜索
db.articles.find({ $text: { $search: "mongodb database" } })
// 权重配置
db.articles.createIndex(
{ title: "text", content: "text" },
{ weights: { title: 10, content: 5 } } // title权重更高
)
// 搜索结果评分
db.articles.find(
{ $text: { $search: "mongodb" } },
{ score: { $meta: "textScore" } }
).sort({ score: { $meta: "textScore" } })4.2.5 地理空间索引(Geospatial Index)
2dsphere索引(球面几何):
javascript
// 创建地理空间索引
db.places.createIndex({ location: "2dsphere" })
// 文档结构(GeoJSON格式)
{
"_id": 1,
"name": "深圳市民中心",
"location": {
"type": "Point",
"coordinates": [114.0579, 22.5455] // [经度, 纬度]
}
}
// 查询附近的地点(5公里内)
db.places.find({
location: {
$near: {
$geometry: {
"type": "Point",
"coordinates": [114.06, 22.54]
},
$maxDistance: 5000 // 单位:米
}
}
})
// 查询多边形区域内的地点
db.places.find({
location: {
$geoWithin: {
$geometry: {
"type": "Polygon",
"coordinates": [[
[114.0, 22.5],
[114.1, 22.5],
[114.1, 22.6],
[114.0, 22.6],
[114.0, 22.5]
]]
}
}
}
})4.2.6 部分索引(Partial Index)
仅索引符合条件的文档:
javascript
// 仅索引status='active'的用户
db.users.createIndex(
{ email: 1 },
{ partialFilterExpression: { status: "active" } }
)
// ✅ 使用索引
db.users.find({ email: "zhang@example.com", status: "active" })
// ❌ 不使用索引(缺少status条件)
db.users.find({ email: "zhang@example.com" })优势:
- ✅ 节省存储空间(仅索引部分数据)
- ✅ 提升索引维护性能
- ✅ 适用于稀疏数据(如:仅索引未删除的文档)
4.2.7 唯一索引(Unique Index)
javascript
// 创建唯一索引
db.users.createIndex({ email: 1 }, { unique: true })
// 插入重复数据会报错
db.users.insert({ email: "zhang@example.com" }) // 成功
db.users.insert({ email: "zhang@example.com" }) // E11000 duplicate key error
// 唯一复合索引
db.users.createIndex({ username: 1, tenant_id: 1 }, { unique: true })注意事项:
- 唯一索引会拒绝重复值(包括
null) - 稀疏唯一索引:
{ unique: true, sparse: true },允许多个文档缺少该字段
4.3 索引优化策略
4.3.1 覆盖索引(Covered Query)
定义:查询的所有字段都包含在索引中,无需回表查询文档。
javascript
// 创建复合索引
db.users.createIndex({ username: 1, email: 1, status: 1 })
// ✅ 覆盖查询(仅从索引获取数据)
db.users.find(
{ username: "zhangsan" },
{ _id: 0, username: 1, email: 1, status: 1 } // 投影仅包含索引字段
)
// 执行计划显示
{
"executionStats": {
"totalDocsExamined": 0, // ← 未扫描任何文档(覆盖索引)
"executionStages": {
"stage": "PROJECTION_COVERED"
}
}
}优化效果:
- 性能提升:3-10倍(避免磁盘随机IO)
- 适用场景:高频查询的核心字段
4.3.2 索引选择性
选择性公式:
选择性 = 唯一值数量 / 文档总数
高选择性(好):email, mobile, order_no (接近1.0)
低选择性(差):status, gender, type (< 0.05)实战案例:
javascript
// 用户表:100万文档
db.users.count() // 1000000
db.users.distinct("email").length // 998000 (选择性:0.998)
db.users.distinct("status").length // 3 (选择性:0.000003)
// ✅ 高选择性字段适合索引
db.users.createIndex({ email: 1 })
// ❌ 低选择性字段不适合单独索引
db.users.createIndex({ status: 1 }) // 浪费空间,效果差
// ✅ 低选择性字段放在复合索引后面
db.users.createIndex({ email: 1, status: 1 })4.3.3 索引碎片整理
问题:频繁删除/更新导致索引碎片,影响性能。
javascript
// 查看索引统计信息
db.users.stats().indexSizes
// 输出:{ "_id_": 10485760, "email_1": 5242880 }
// 重建索引(在线操作,MongoDB 4.2+)
db.users.reIndex() // 阻塞操作,不推荐生产环境
// 推荐:后台重建索引
db.users.dropIndex("email_1")
db.users.createIndex({ email: 1 }, { background: true })4.3.4 索引提示(Index Hint)
强制使用指定索引:
javascript
// 查询优化器可能选错索引
db.orders.find({ user_id: 123, status: "pending" })
// 强制使用user_id索引
db.orders.find({ user_id: 123, status: "pending" }).hint({ user_id: 1 })
// 强制全表扫描(调试用)
db.orders.find({ user_id: 123 }).hint({ $natural: 1 })4.4 索引设计反模式
❌ 反模式1:过度索引
javascript
// 错误:为每个字段都创建索引
db.users.createIndex({ username: 1 })
db.users.createIndex({ email: 1 })
db.users.createIndex({ mobile: 1 })
db.users.createIndex({ status: 1 })
db.users.createIndex({ created_at: 1 })
// ... 10个索引
// 问题:
// 1. 写入性能下降(每次插入需要更新10个索引)
// 2. 占用大量存储空间
// 3. 查询优化器选择困难
// 正确做法:根据查询模式设计2-3个复合索引
db.users.createIndex({ email: 1 }) // 登录查询
db.users.createIndex({ status: 1, created_at: -1 }) // 列表查询❌ 反模式2:忽略索引顺序
javascript
// 查询:WHERE status = 'active' AND age > 18 ORDER BY created_at DESC
// 错误索引
db.users.createIndex({ age: 1, status: 1, created_at: -1 })
// 问题:无法使用索引的status前缀
// 正确索引(ESR规则)
db.users.createIndex({ status: 1, created_at: -1, age: 1 })❌ 反模式3:正则表达式前缀通配
javascript
// ❌ 无法使用索引(前缀通配)
db.users.find({ username: /.*zhang/ })
db.users.find({ email: /$.*@example\.com/ })
// ✅ 可以使用索引(前缀匹配)
db.users.find({ username: /^zhang/ })
db.users.find({ email: /^zhang@example\.com/ })5. 复制集架构与高可用
5.1 复制集概述
**Replica Set(复制集)**是MongoDB实现高可用的核心机制,通过数据冗余和自动故障转移保证服务不中断。
核心组件 :
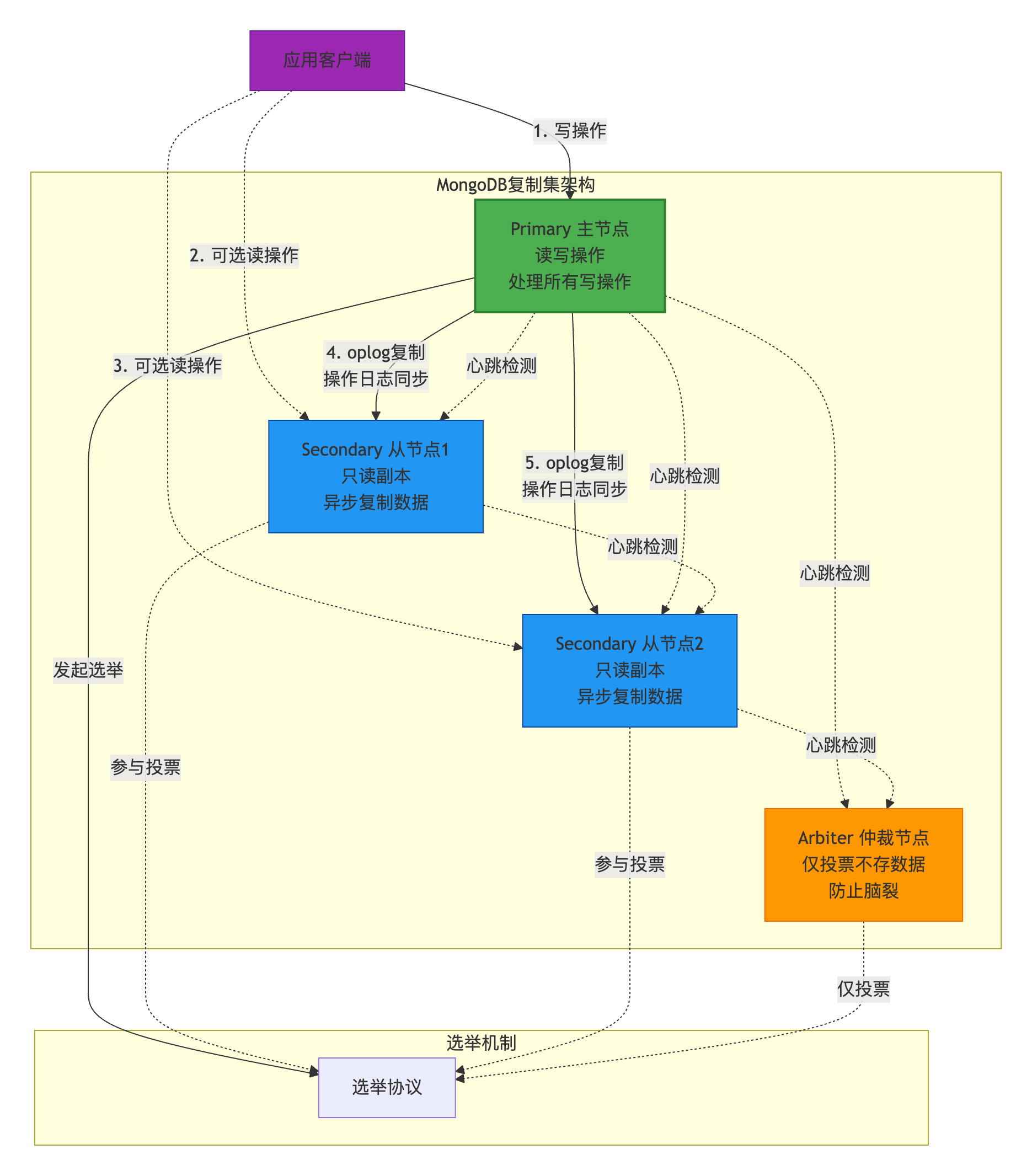
节点类型:
| 节点类型 | 功能 | 数量建议 | 说明 |
|---|---|---|---|
| Primary | 接收所有写操作,唯一的主节点 | 1个 | 自动选举产生 |
| Secondary | 复制主节点数据,可处理读请求 | 2个+ | 可晋升为Primary |
| Arbiter | 仅参与投票,不存储数据 | 0-1个 | 节省成本(不推荐) |
| Hidden | 隐藏节点,不接受读请求 | 可选 | 用于备份或分析 |
| Delayed | 延迟复制节点 | 可选 | 防止误删除数据 |
5.2 Oplog复制机制
Oplog(Operations Log):
- 存储在本地数据库
local.oplog.rs集合中 - 记录主节点的所有写操作
- 固定大小的Capped Collection(循环覆盖)
- 幂等性操作(可重复执行)
Oplog结构:
javascript
{
"ts": Timestamp(1703001234, 1), // 操作时间戳(全局唯一)
"t": NumberLong(3), // 选举任期号
"h": NumberLong("..."), // 操作哈希值
"v": 2, // oplog版本
"op": "i", // 操作类型:i=insert, u=update, d=delete
"ns": "mydb.users", // 命名空间(数据库.集合)
"o": { // 操作内容
"_id": ObjectId("..."),
"username": "zhangsan",
"email": "zhang@example.com"
},
"o2": { // 查询条件(仅update/delete)
"_id": ObjectId("...")
}
}复制流程:
客户端 Primary节点 Secondary节点 1. 写入请求 insertOne(doc) 2. 写入数据 写入本地oplog 3. 返回成功 WriteConcern=1 4. 拉取oplog getMore请求 5. 返回新oplog 6. 回放oplog 应用到本地数据 loop 异步复制(每2秒拉- 取) 复制延迟:通常< 1秒 客户端 Primary节点 Secondary节点
Oplog大小配置:
javascript
// 查看Oplog大小
db.oplog.rs.stats().maxSize // 默认:磁盘空间的5%
// 修改Oplog大小(需重启)
// mongod.conf
replication:
oplogSizeMB: 10240 // 10GBOplog大小建议:
计算公式:
Oplog大小 >= 峰值写入速率 * 预期恢复时间
示例:
- 峰值写入:100MB/小时
- 预期恢复时间:24小时(一天)
- Oplog大小 >= 100 * 24 = 2.4GB
推荐值:
- 小型应用:1-5GB
- 中型应用:10-50GB
- 大型应用:100GB+5.3 选举机制
选举触发条件:
- 复制集初始化
- 主节点故障(心跳超时,默认10秒)
- 新节点加入集群
- 手动触发:
rs.stepDown()
选举规则:
选举优先级(按顺序判断):
1. 节点优先级(priority)
├─ priority = 0:永不成为Primary
└─ priority > 0:数值越大优先级越高
2. 数据新鲜度(oplog时间戳)
└─ 数据越新越有可能当选
3. 多数派投票(Majority)
└─ 得票数 > 总节点数 / 2
4. 网络延迟
└─ 心跳延迟越低越有可能当选选举示例:
javascript
// 配置节点优先级
rs.conf()
{
"members": [
{ "_id": 0, "host": "mongo1:27017", "priority": 2 }, // 优先成为Primary
{ "_id": 1, "host": "mongo2:27017", "priority": 1 },
{ "_id": 2, "host": "mongo3:27017", "priority": 1 }
]
}
// 禁止节点成为Primary
rs.reconfig({
"members": [
{ "_id": 0, "host": "mongo1:27017", "priority": 2 },
{ "_id": 1, "host": "mongo2:27017", "priority": 0 }, // 永不当选
{ "_id": 2, "host": "mongo3:27017", "priority": 1 }
]
})选举时间线:
T0: Primary故障(网络断开)
T10s: Secondary节点检测到心跳超时
T11s: 发起选举投票
T12s: 收集多数派投票
T13s: 新Primary当选
T14s: 客户端重新连接新Primary
总耗时:约 10-15秒(不可用窗口)5.4 读写关注
5.4.1 写关注(Write Concern)
定义:控制写操作的确认级别,权衡性能和数据安全性。
级别选项:
| Write Concern | 含义 | 持久性 | 性能 |
|---|---|---|---|
w: 0 |
不等待确认(fire-and-forget) | 最低 | 最高 |
w: 1 |
等待Primary确认(默认) | 低 | 高 |
w: 2 |
等待1个Secondary确认 | 中 | 中 |
w: "majority" |
等待多数节点确认 | 高 | 低 |
w: 3 |
等待2个Secondary确认 | 很高 | 很低 |
配置示例:
java
// Java Driver配置
MongoClientSettings settings = MongoClientSettings.builder()
.applyConnectionString(new ConnectionString("mongodb://localhost:27017"))
.writeConcern(WriteConcern.MAJORITY) // 多数派写关注
.build();
MongoClient mongoClient = MongoClients.create(settings);
// 单次操作覆盖
collection.insertOne(document, new InsertOneOptions()
.writeConcern(WriteConcern.W2)); // 等待2个节点确认与Journal的组合:
java
// w=1 + j=true:等待Primary写入Journal(推荐)
WriteConcern.JOURNALED
// w=majority + j=true:等待多数节点写入Journal(金融系统)
WriteConcern.MAJORITY.withJournal(true)5.4.2 读关注(Read Concern)
定义:控制读取数据的一致性级别。
级别选项:
| Read Concern | 含义 | 一致性 | 适用场景 |
|---|---|---|---|
local |
读取本节点最新数据(默认) | 最终一致 | 高性能场景 |
available |
读取可用数据(可能未复制) | 弱一致 | 分片集群 |
majority |
读取多数节点确认的数据 | 强一致 | 事务、金融系统 |
linearizable |
线性一致性读(串行化) | 最强一致 | 分布式锁 |
snapshot |
快照读(事务内) | 事务隔离 | 多文档事务 |
示例:
java
// 设置读关注
collection.find()
.readConcern(ReadConcern.MAJORITY)
.into(new ArrayList<>());5.4.3 读偏好(Read Preference)
定义:控制读请求路由到哪个节点。
模式选项:
| 模式 | 行为 | 适用场景 |
|---|---|---|
primary |
仅从Primary读(默认) | 强一致性要求 |
primaryPreferred |
优先Primary,不可用时读Secondary | 高可用场景 |
secondary |
仅从Secondary读 | 分离读写压力 |
secondaryPreferred |
优先Secondary,不可用时读Primary | 读多写少场景 |
nearest |
读取网络延迟最低的节点 | 跨地域部署 |
Java配置:
java
// 配置读偏好
MongoClientSettings settings = MongoClientSettings.builder()
.readPreference(ReadPreference.secondaryPreferred())
.build();
// 单次查询覆盖
collection.find()
.readPreference(ReadPreference.secondary())
.into(new ArrayList<>());
// 带标签的读偏好(读指定机房的Secondary)
ReadPreference.secondary(
TagSet.builder()
.add("datacenter", "east")
.build()
);5.5 复制集部署实战
部署拓扑:
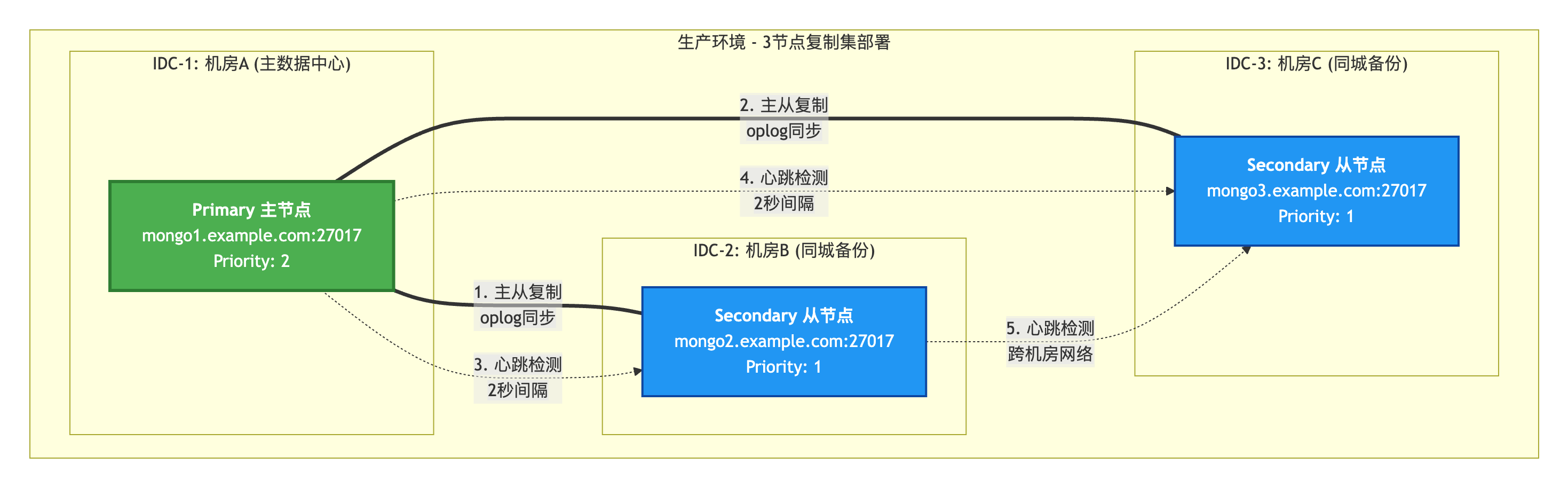
初始化复制集:
bash
# 1. 启动3个MongoDB实例
mongod --replSet rs0 --port 27017 --dbpath /data/mongo1 --bind_ip 0.0.0.0
mongod --replSet rs0 --port 27018 --dbpath /data/mongo2 --bind_ip 0.0.0.0
mongod --replSet rs0 --port 27019 --dbpath /data/mongo3 --bind_ip 0.0.0.0
# 2. 连接到第一个节点
mongosh --port 27017
# 3. 初始化复制集
rs.initiate({
_id: "rs0",
members: [
{ _id: 0, host: "mongo1:27017", priority: 2 },
{ _id: 1, host: "mongo2:27018", priority: 1 },
{ _id: 2, host: "mongo3:27019", priority: 1 }
]
})
# 4. 检查状态
rs.status()
# 5. 添加新节点
rs.add("mongo4:27020")
# 6. 移除节点
rs.remove("mongo4:27020")连接字符串:
java
// Java Driver连接复制集
String connectionString = "mongodb://mongo1:27017,mongo2:27018,mongo3:27019/"
+ "?replicaSet=rs0"
+ "&readPreference=secondaryPreferred"
+ "&w=majority";
MongoClient mongoClient = MongoClients.create(connectionString);6. 分片集群架构
6.1 分片概述
**Sharding(分片)**是MongoDB实现水平扩展的机制,通过将数据分散到多个服务器(Shard)来突破单机存储和性能瓶颈。
适用场景:
✅ 数据量超过单机存储能力(> 500GB)
✅ 读写QPS超过单机性能上限(> 10万/秒)
✅ 需要地理分布式部署
架构组件:
分片层 配置服务器 路由层 客户端层 Shard 1
复制集
数据分片1 Shard 2
复制集
数据分片2 Shard 3
复制集
数据分片3 Config Server
复制集
存储元数据 Mongos
路由节点1 Mongos
路由节点2 应用1 应用2 应用3
组件职责:
| 组件 | 职责 | 数量 |
|---|---|---|
| Mongos | 路由查询到对应分片,聚合结果 | 2个+(无状态,可横向扩展) |
| Config Server | 存储集群元数据(分片键、Chunk分布) | 3个复制集(CSRS) |
| Shard | 存储实际数据,每个Shard是一个复制集 | 2个+(通常3-10个) |
6.2 分片键选择
分片键(Shard Key):决定文档分布到哪个分片的字段,一旦设置不可更改。
选择原则:
- 高基数(High Cardinality):唯一值数量多
- 低频率(Low Frequency):值分布均匀,避免热点
- 非单调递增(Non-Monotonic):避免所有写入集中在最后一个分片
常见分片键模式:
模式1:哈希分片(Hashed Sharding)
javascript
// 启用分片
sh.enableSharding("mydb")
// 创建哈希分片索引
sh.shardCollection("mydb.users", { _id: "hashed" })特点:
- ✅ 数据分布均匀(哈希值随机分布)
- ✅ 写入性能高(无热点)
- ❌ 范围查询性能差(需要scatter-gather)
- ❌ 无法利用排序(哈希后无序)
适用场景:
- 写多读少的日志系统
- 没有明显范围查询需求的场景
模式2:范围分片(Range Sharding)
javascript
// 使用user_id作为分片键
sh.shardCollection("mydb.orders", { user_id: 1 })特点:
- ✅ 范围查询性能好(数据连续存储)
- ✅ 支持排序优化
- ❌ 容易产生热点(如时间戳递增)
- ❌ 需要选择合适的分片键
适用场景:
- 有明确范围查询需求
- 数据有自然分组(如地域、租户)
模式3:复合分片键
javascript
// 组合分片键:tenant_id + created_at
sh.shardCollection("mydb.logs", { tenant_id: 1, created_at: 1 })特点:
- ✅ 第一个字段保证数据分组(租户隔离)
- ✅ 第二个字段支持时间范围查询
- ✅ 避免单一维度热点
适用场景:
- SaaS多租户系统
- 需要租户隔离且有时间查询的场景
6.3 Chunk分裂与均衡
Chunk(块):
- MongoDB将分片键空间划分为多个Chunk
- 默认大小:128MB(MongoDB 6.0+,早期版本64MB)
- 每个Chunk存储一个范围的分片键值
Chunk分裂流程:
初始状态(单Shard):
Shard1: [minKey ────────────────────────────────────── maxKey]
写入数据后Chunk增长:
Shard1: [minKey ─────────────────── Chunk(150MB) ─────────────── maxKey]
↓ 超过阈值,触发分裂
分裂后:
Shard1: [minKey ─── Chunk1(75MB) ─── Chunk2(75MB) ─── maxKey]
均衡器工作(迁移Chunk):
Shard1: [minKey ─── Chunk1(75MB) ─── maxKey]
Shard2: [minKey ─── Chunk2(75MB) ─── maxKey]均衡器(Balancer):
javascript
// 查看均衡器状态
sh.getBalancerState()
// 启用/禁用均衡器
sh.setBalancerState(true)
sh.setBalancerState(false)
// 设置均衡窗口(仅在低峰期运行)
db.settings.update(
{ _id: "balancer" },
{ $set: {
activeWindow: {
start: "23:00", // 晚上11点开始
stop: "06:00" // 早上6点结束
}
}},
{ upsert: true }
)6.4 查询路由
Mongos路由逻辑:
应用 Mongos路由 Config Server Shard 1 Shard 2 查询请求 find({user_id: 123}) 获取Chunk分布 user_id=123在Shard1 路由到Shard1 返回结果 需要查询所有分片 并行查询 并行查询 结果1 结果2 聚合、排序、合并 alt 包含分片键(Targeted Query) 不包含分片键(Scatter-Gather) 返回最终结果 应用 Mongos路由 Config Server Shard 1 Shard 2
查询性能对比:
| 查询类型 | 是否包含分片键 | 路由方式 | 性能 |
|---|---|---|---|
| 精确查询 | ✅ 包含 | Targeted(单分片) | 高 |
| 范围查询 | ✅ 包含 | Targeted(部分分片) | 中 |
| 全表扫描 | ❌ 不包含 | Scatter-Gather(所有分片) | 低 |
优化建议:
javascript
// ✅ 好:包含分片键,路由到单个分片
db.orders.find({ user_id: 123, status: "pending" })
// ❌ 差:不包含分片键,广播到所有分片
db.orders.find({ status: "pending" })
// ✅ 好:聚合操作下推到各分片
db.orders.aggregate([
{ $match: { user_id: 123 } }, // 路由到单分片
{ $group: { _id: "$status", count: { $sum: 1 } } }
])6.5 分片集群部署
部署架构(最小配置):
Config Server 复制集(3节点):
- config1:27019
- config2:27019
- config3:27019
Shard 1 复制集(3节点):
- shard1-1:27018
- shard1-2:27018
- shard1-3:27018
Shard 2 复制集(3节点):
- shard2-1:27018
- shard2-2:27018
- shard2-3:27018
Mongos 路由(2节点):
- mongos1:27017
- mongos2:27017初始化脚本:
bash
# 1. 启动Config Server复制集
mongod --configsvr --replSet configRS --port 27019 --dbpath /data/config1
# ... 启动config2, config3
# 初始化Config Server
mongosh --port 27019
rs.initiate({
_id: "configRS",
configsvr: true,
members: [
{ _id: 0, host: "config1:27019" },
{ _id: 1, host: "config2:27019" },
{ _id: 2, host: "config3:27019" }
]
})
# 2. 启动Shard复制集
mongod --shardsvr --replSet shard1RS --port 27018 --dbpath /data/shard1-1
# ... 启动其他节点并初始化
# 3. 启动Mongos
mongos --configdb configRS/config1:27019,config2:27019,config3:27019 --port 27017
# 4. 添加分片
mongosh --port 27017
sh.addShard("shard1RS/shard1-1:27018,shard1-2:27018,shard1-3:27018")
sh.addShard("shard2RS/shard2-1:27018,shard2-2:27018,shard2-3:27018")
# 5. 启用分片
sh.enableSharding("mydb")
sh.shardCollection("mydb.users", { _id: "hashed" })7. 事务与一致性保证
7.1 事务支持演进
MongoDB事务发展历程:
| 版本 | 事务支持 | 说明 |
|---|---|---|
| < 4.0 | 单文档原子性 | 仅支持单个文档的原子操作 |
| 4.0 (2018) | 复制集多文档事务 | 支持单个复制集内的多文档事务 |
| 4.2 (2019) | 分片集群事务 | 支持跨分片的分布式事务 |
| 5.0+ | 改进性能 | 优化事务性能,降低锁粒度 |
7.2 单文档原子性
原子操作示例:
javascript
// ✅ 单文档更新是原子的
db.users.updateOne(
{ _id: ObjectId("...") },
{
$set: { status: "active" },
$inc: { login_count: 1 },
$currentDate: { last_login: true }
}
)
// ✅ 嵌入式文档更新是原子的
db.orders.updateOne(
{ _id: ObjectId("...") },
{
$push: { items: { product_id: 123, quantity: 2 } },
$inc: { total_amount: 199.00 }
}
)7.3 多文档事务
基本用法:
java
// Java Driver事务示例
try (ClientSession session = mongoClient.startSession()) {
session.startTransaction();
try {
// 1. 扣减库存
collection.updateOne(
session,
eq("_id", productId),
inc("stock", -1)
);
// 2. 创建订单
collection.insertOne(
session,
new Document("order_no", orderNo)
.append("product_id", productId)
.append("status", "pending")
);
// 3. 提交事务
session.commitTransaction();
} catch (Exception e) {
// 4. 回滚事务
session.abortTransaction();
throw e;
}
}事务选项:
java
TransactionOptions options = TransactionOptions.builder()
.readConcern(ReadConcern.SNAPSHOT) // 快照隔离
.writeConcern(WriteConcern.MAJORITY) // 多数派写
.readPreference(ReadPreference.primary()) // 从主节点读
.maxCommitTime(60L, TimeUnit.SECONDS) // 最大提交时间
.build();
session.startTransaction(options);7.4 事务隔离级别
MongoDB事务隔离:
Snapshot Isolation(快照隔离):
- 事务开始时创建一个数据快照
- 事务内的所有读操作看到同一快照
- 写操作对其他事务不可见,直到提交
避免的异常:
✅ 脏读(Dirty Read):不会读到未提交的数据
✅ 不可重复读(Non-Repeatable Read):同一事务内重复读取结果一致
✅ 幻读(Phantom Read):同一事务内范围查询结果一致
不保证:
❌ 写偏序(Write Skew):需要应用层处理示例:转账事务:
java
// 转账事务(避免脏读、幻读)
try (ClientSession session = mongoClient.startSession()) {
session.startTransaction(TransactionOptions.builder()
.readConcern(ReadConcern.SNAPSHOT)
.writeConcern(WriteConcern.MAJORITY)
.build());
try {
// 1. 读取账户余额(快照读)
Document fromAccount = accounts.find(session, eq("user_id", fromUser)).first();
Document toAccount = accounts.find(session, eq("user_id", toUser)).first();
if (fromAccount.getDouble("balance") < amount) {
throw new RuntimeException("余额不足");
}
// 2. 扣减转出账户
accounts.updateOne(
session,
eq("user_id", fromUser),
inc("balance", -amount)
);
// 3. 增加转入账户
accounts.updateOne(
session,
eq("user_id", toUser),
inc("balance", amount)
);
// 4. 提交事务
session.commitTransaction();
} catch (Exception e) {
session.abortTransaction();
throw e;
}
}7.5 事务性能优化
最佳实践:
- 减少事务范围
java
// ❌ 错误:事务包含非必要操作
session.startTransaction();
// 查询用户信息(耗时)
// 调用外部API(耗时)
// 更新订单
session.commitTransaction();
// ✅ 正确:仅包含必须原子执行的操作
// 先查询和调用API
session.startTransaction();
// 仅更新订单
session.commitTransaction();- 避免长事务
java
// 事务超时时间:默认60秒
// 超时后自动回滚
TransactionOptions.builder()
.maxCommitTime(10L, TimeUnit.SECONDS) // 设置10秒超时
.build();- 批量操作
java
// ✅ 使用批量操作减少往返次数
List<WriteModel<Document>> writes = Arrays.asList(
new UpdateOneModel<>(eq("_id", 1), inc("stock", -1)),
new UpdateOneModel<>(eq("_id", 2), inc("stock", -2))
);
collection.bulkWrite(session, writes);- 处理冲突重试
java
// 事务冲突时自动重试
int maxRetries = 3;
for (int i = 0; i < maxRetries; i++) {
try {
session.startTransaction();
// 事务操作...
session.commitTransaction();
break; // 成功则跳出
} catch (MongoCommandException e) {
if (e.hasErrorLabel("TransientTransactionError") && i < maxRetries - 1) {
continue; // 瞬态错误,重试
}
throw e;
}
}7.6 分布式事务原理
两阶段提交(Two-Phase Commit):
客户端 协调者 (Primary Shard) Shard 1 Shard 2 开始事务 Phase 1: Prepare阶段 Prepare请求 Prepare请求 Vote: Yes(已准备好) Vote: Yes(已准备好) Phase 2: Commit阶段 Commit请求 Commit请求 Committed Committed 事务成功 客户端 协调者 (Primary Shard) Shard 1 Shard 2
失败恢复:
场景1:Shard1 Prepare失败
└─> Coordinator发送Abort到所有Shard
└─> 事务回滚
场景2:Shard1 Commit超时
└─> Coordinator重试Commit
└─> 幂等性保证不会重复提交
场景3:Coordinator崩溃
└─> 新Coordinator读取事务日志
└─> 继续完成未完成的事务8. 查询执行引擎
8.1 查询优化器
MongoDB查询优化器(Query Optimizer):
- 基于成本的优化器(Cost-Based Optimizer)
- 自动选择最优执行计划
- 支持多种执行策略(索引扫描、全表扫描、Covered Query等)
执行计划生成流程:
1. 解析查询(Parse Query)
└─> 生成查询树(Query Tree)
2. 生成候选执行计划(Candidate Plans)
├─> 计划1:使用索引A
├─> 计划2:使用索引B
└─> 计划3:全表扫描
3. 试运行(Trial Run)
└─> 执行前N个文档(默认101个)
└─> 计算每个计划的成本
4. 选择最优计划
└─> 缓存执行计划(Plan Cache)
5. 执行查询
└─> 返回结果8.2 Explain分析
Explain模式:
| 模式 | 说明 | 输出内容 |
|---|---|---|
queryPlanner |
仅返回执行计划(不执行) | 索引选择、查询策略 |
executionStats |
执行查询并返回统计信息 | 扫描文档数、耗时 |
allPlansExecution |
返回所有候选计划的统计 | 所有计划的性能对比 |
实战案例:
javascript
// 查询语句
db.users.find({ status: "active", age: { $gt: 18 } })
.sort({ created_at: -1 })
.limit(10)
.explain("executionStats")
// 输出分析(简化版)
{
"executionStats": {
"executionSuccess": true,
"nReturned": 10, // 返回文档数
"executionTimeMillis": 15, // 执行时间(毫秒)
"totalKeysExamined": 150, // 扫描索引键数
"totalDocsExamined": 150, // 扫描文档数
"executionStages": {
"stage": "LIMIT", // 第4步:限制返回10条
"inputStage": {
"stage": "FETCH", // 第3步:回表获取文档
"inputStage": {
"stage": "IXSCAN", // 第1步:索引扫描
"keyPattern": { "status": 1, "created_at": -1 },
"indexName": "status_1_created_at_-1",
"direction": "backward" // 逆序扫描(利用索引排序)
}
}
}
}
}关键指标解读:
性能评估公式:
1. 索引效率 = nReturned / totalKeysExamined
├─> 理想值:1.0(每扫描1个索引键返回1个文档)
└─> 警戒值:< 0.1(扫描了太多无效索引键)
2. 回表效率 = nReturned / totalDocsExamined
├─> 理想值:1.0(每扫描1个文档返回1个结果)
└─> 警戒值:< 0.5(扫描了太多无效文档)
3. 执行阶段(stage):
├─> IXSCAN:索引扫描(好)
├─> FETCH:回表查询(正常)
├─> COLLSCAN:全表扫描(差,需要加索引)
├─> SORT:内存排序(差,应使用索引排序)
└─> PROJECTION_COVERED:覆盖索引(最好)8.3 聚合管道
Aggregation Pipeline(聚合管道):
- MongoDB的数据分析框架
- 类似Unix管道:
db.collection | $match | $group | $sort - 支持复杂的数据转换和统计
核心操作符:
| 操作符 | 功能 | 类比SQL |
|---|---|---|
$match |
过滤文档 | WHERE |
$project |
投影字段 | SELECT |
$group |
分组聚合 | GROUP BY |
$sort |
排序 | ORDER BY |
$limit |
限制结果数 | LIMIT |
$skip |
跳过文档 | OFFSET |
$lookup |
关联查询 | LEFT JOIN |
$unwind |
展开数组 | UNNEST |
实战案例:订单统计:
javascript
db.orders.aggregate([
// 1. 过滤:仅统计已完成订单
{
$match: {
status: "completed",
created_at: { $gte: ISODate("2025-01-01") }
}
},
// 2. 展开:订单商品数组
{
$unwind: "$items"
},
// 3. 分组:按商品ID统计销量
{
$group: {
_id: "$items.product_id",
total_quantity: { $sum: "$items.quantity" },
total_revenue: { $sum: "$items.amount" },
order_count: { $sum: 1 }
}
},
// 4. 排序:按销量降序
{
$sort: { total_quantity: -1 }
},
// 5. 限制:Top 10
{
$limit: 10
},
// 6. 关联:获取商品名称
{
$lookup: {
from: "products",
localField: "_id",
foreignField: "_id",
as: "product_info"
}
},
// 7. 投影:格式化输出
{
$project: {
_id: 0,
product_id: "$_id",
product_name: { $arrayElemAt: ["$product_info.name", 0] },
total_quantity: 1,
total_revenue: 1,
order_count: 1
}
}
])输出结果:
json
[
{
"product_id": ObjectId("..."),
"product_name": "iPhone 15 Pro",
"total_quantity": 1234,
"total_revenue": 12340000.00,
"order_count": 1100
},
...
]8.4 聚合管道优化
优化规则:
- 提前过滤(Early Filtering)
javascript
// ❌ 错误:在最后过滤
db.orders.aggregate([
{ $group: { _id: "$user_id", total: { $sum: "$amount" } } },
{ $match: { total: { $gt: 1000 } } } // 已经聚合了所有数据
])
// ✅ 正确:尽早过滤
db.orders.aggregate([
{ $match: { status: "completed" } }, // 先过滤
{ $group: { _id: "$user_id", total: { $sum: "$amount" } } },
{ $match: { total: { $gt: 1000 } } }
])- 下推索引(Index Push-down)
javascript
// MongoDB自动优化:将$match下推到索引扫描阶段
db.orders.aggregate([
{ $match: { user_id: 123 } }, // 使用索引
{ $group: { _id: "$status", count: { $sum: 1 } } }
])- 避免大文档$lookup
javascript
// ❌ 错误:关联后再过滤
db.orders.aggregate([
{ $lookup: { from: "users", localField: "user_id", foreignField: "_id", as: "user" } },
{ $match: { "user.status": "active" } }
])
// ✅ 正确:先过滤users,再关联
db.orders.aggregate([
{ $lookup: {
from: "users",
let: { user_id: "$user_id" },
pipeline: [
{ $match: {
$expr: { $eq: ["$_id", "$$user_id"] },
status: "active"
}}
],
as: "user"
}}
])- 使用$project减少数据传输
javascript
// ✅ 仅投影需要的字段
db.orders.aggregate([
{ $match: { status: "completed" } },
{ $project: { user_id: 1, amount: 1, _id: 0 } }, // 减少数据传输
{ $group: { _id: "$user_id", total: { $sum: "$amount" } } }
])9. Java集成与最佳实践
9.1 MongoDB Java Driver
依赖配置(Spring Boot 3.x):
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
<version>3.2.0</version>
</dependency>连接配置:
yaml
# application.yml
spring:
data:
mongodb:
uri: mongodb://username:password@mongo1:27017,mongo2:27017,mongo3:27017/mydb?replicaSet=rs0&w=majority
# 或者分开配置
host: mongo1,mongo2,mongo3
port: 27017
database: mydb
username: admin
password: password
authentication-database: admin
# 连接池配置
max-pool-size: 100
min-pool-size: 10
max-wait-time: 5000ms
# 读写配置
read-preference: secondaryPreferred
write-concern: majority9.2 Spring Data MongoDB实战
9.2.1 实体类定义
java
import org.springframework.data.annotation.*;
import org.springframework.data.mongodb.core.index.*;
import org.springframework.data.mongodb.core.mapping.*;
import lombok.Data;
import java.time.LocalDateTime;
@Data
@Document(collection = "users") // 映射到users集合
@CompoundIndex(def = "{'email': 1, 'status': 1}", name = "idx_email_status")
public class User {
@Id // 映射到_id字段
private String id;
@Indexed(unique = true) // 唯一索引
private String email;
@Field("user_name") // 字段名映射
private String username;
private Integer age;
@Indexed
private String status;
@DBRef // 引用其他集合
private Role role;
@CreatedDate // 自动填充创建时间
private LocalDateTime createdAt;
@LastModifiedDate // 自动填充更新时间
private LocalDateTime updatedAt;
@Version // 乐观锁版本号
private Long version;
@Transient // 不持久化到数据库
private String tempField;
}9.2.2 Repository接口
java
import org.springframework.data.mongodb.repository.*;
import org.springframework.data.domain.*;
import java.util.List;
public interface UserRepository extends MongoRepository<User, String> {
// 1. 方法名查询(自动生成查询)
User findByEmail(String email);
List<User> findByStatus(String status);
List<User> findByAgeGreaterThan(Integer age);
List<User> findByStatusAndAgeGreaterThan(String status, Integer age);
// 2. @Query查询(JSON查询语法)
@Query("{ 'email': ?0, 'status': ?1 }")
User findByEmailAndStatus(String email, String status);
// 3. 分页查询
Page<User> findByStatus(String status, Pageable pageable);
// 4. 排序查询
List<User> findByStatusOrderByCreatedAtDesc(String status);
// 5. 聚合查询
@Aggregation(pipeline = {
"{ $match: { 'status': ?0 } }",
"{ $group: { _id: '$role', count: { $sum: 1 } } }",
"{ $sort: { count: -1 } }"
})
List<RoleCountDTO> countUsersByRole(String status);
// 6. 更新查询
@Query("{ 'email': ?0 }")
@Update("{ $set: { 'status': ?1, 'updatedAt': ?2 } }")
long updateStatusByEmail(String email, String status, LocalDateTime updatedAt);
}9.2.3 MongoTemplate使用
java
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.core.query.*;
import org.springframework.data.mongodb.core.aggregation.*;
import org.springframework.stereotype.Service;
import lombok.RequiredArgsConstructor;
import java.util.List;
@Service
@RequiredArgsConstructor
public class UserService {
private final MongoTemplate mongoTemplate;
// 1. 基础查询
public List<User> findActiveUsers() {
Query query = new Query();
query.addCriteria(Criteria.where("status").is("active"));
query.addCriteria(Criteria.where("age").gte(18));
query.with(Sort.by(Sort.Direction.DESC, "createdAt"));
query.limit(10);
return mongoTemplate.find(query, User.class);
}
// 2. 复杂条件查询
public List<User> complexQuery(String keyword, Integer minAge, List<String> statuses) {
Query query = new Query();
// 多条件组合
Criteria criteria = new Criteria();
if (keyword != null) {
criteria.orOperator(
Criteria.where("username").regex(keyword, "i"), // 正则匹配
Criteria.where("email").regex(keyword, "i")
);
}
if (minAge != null) {
criteria.and("age").gte(minAge);
}
if (statuses != null && !statuses.isEmpty()) {
criteria.and("status").in(statuses);
}
query.addCriteria(criteria);
return mongoTemplate.find(query, User.class);
}
// 3. 更新操作
public long updateUserStatus(String userId, String newStatus) {
Query query = new Query(Criteria.where("id").is(userId));
Update update = new Update();
update.set("status", newStatus);
update.set("updatedAt", LocalDateTime.now());
update.inc("version", 1); // 乐观锁版本号+1
return mongoTemplate.updateFirst(query, update, User.class)
.getModifiedCount();
}
// 4. Upsert操作(存在则更新,不存在则插入)
public void upsertUser(User user) {
Query query = new Query(Criteria.where("email").is(user.getEmail()));
Update update = new Update();
update.set("username", user.getUsername());
update.set("age", user.getAge());
update.set("updatedAt", LocalDateTime.now());
mongoTemplate.upsert(query, update, User.class);
}
// 5. 聚合查询
public List<UserStatDTO> getUserStatsByRole() {
Aggregation aggregation = Aggregation.newAggregation(
Aggregation.match(Criteria.where("status").is("active")),
Aggregation.group("role")
.count().as("userCount")
.avg("age").as("avgAge"),
Aggregation.sort(Sort.Direction.DESC, "userCount"),
Aggregation.limit(10)
);
return mongoTemplate.aggregate(aggregation, "users", UserStatDTO.class)
.getMappedResults();
}
// 6. 地理空间查询
public List<Store> findNearbyStores(double longitude, double latitude, double maxDistance) {
Query query = new Query();
query.addCriteria(Criteria.where("location").nearSphere(
new Point(longitude, latitude)
).maxDistance(maxDistance / 6378137)); // 转换为弧度
return mongoTemplate.find(query, Store.class);
}
// 7. 批量操作
public void batchInsert(List<User> users) {
mongoTemplate.insertAll(users); // 批量插入(更高效)
}
public void batchUpdate(List<User> users) {
BulkOperations bulkOps = mongoTemplate.bulkOps(
BulkOperations.BulkMode.ORDERED, // 有序执行
User.class
);
for (User user : users) {
Query query = new Query(Criteria.where("id").is(user.getId()));
Update update = new Update()
.set("status", user.getStatus())
.set("updatedAt", LocalDateTime.now());
bulkOps.updateOne(query, update);
}
bulkOps.execute(); // 批量执行
}
}9.3 事务集成
java
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.stereotype.Service;
import lombok.RequiredArgsConstructor;
@Service
@RequiredArgsConstructor
public class OrderService {
private final MongoTemplate mongoTemplate;
private final ProductRepository productRepository;
private final OrderRepository orderRepository;
/**
* Spring声明式事务
* 要求:MongoDB 4.0+ 复制集 或 4.2+ 分片集群
*/
@Transactional(rollbackFor = Exception.class)
public Order createOrder(String userId, String productId, Integer quantity) {
// 1. 扣减库存
Product product = productRepository.findById(productId)
.orElseThrow(() -> new RuntimeException("商品不存在"));
if (product.getStock() < quantity) {
throw new RuntimeException("库存不足");
}
product.setStock(product.getStock() - quantity);
productRepository.save(product);
// 2. 创建订单
Order order = new Order();
order.setUserId(userId);
order.setProductId(productId);
order.setQuantity(quantity);
order.setAmount(product.getPrice() * quantity);
order.setStatus("pending");
order.setCreatedAt(LocalDateTime.now());
return orderRepository.save(order);
// 事务自动提交,任何异常自动回滚
}
/**
* 编程式事务(更灵活)
*/
public Order createOrderWithProgrammaticTx(String userId, String productId, Integer quantity) {
return mongoTemplate.getMongoDbFactory()
.getMongoDatabase()
.runCommand(new Document("ping", 1)); // 确保连接正常
// 使用SessionCallback
return mongoTemplate.execute(new SessionCallback<Order>() {
@Override
public Order doInSession(ClientSession session) throws MongoException {
session.startTransaction();
try {
// 事务操作...
Order order = new Order();
orderRepository.save(order);
session.commitTransaction();
return order;
} catch (Exception e) {
session.abortTransaction();
throw e;
}
}
});
}
}9.4 性能优化实践
9.4.1 连接池优化
java
import com.mongodb.ConnectionString;
import com.mongodb.MongoClientSettings;
import com.mongodb.client.MongoClient;
import com.mongodb.client.MongoClients;
import com.mongodb.connection.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.concurrent.TimeUnit;
@Configuration
public class MongoConfig {
@Bean
public MongoClient mongoClient() {
ConnectionString connString = new ConnectionString(
"mongodb://mongo1:27017,mongo2:27017,mongo3:27017/mydb?replicaSet=rs0"
);
MongoClientSettings settings = MongoClientSettings.builder()
.applyConnectionString(connString)
// 连接池配置
.applyToConnectionPoolSettings(builder -> builder
.maxSize(100) // 最大连接数
.minSize(10) // 最小连接数
.maxWaitTime(5000, TimeUnit.MILLISECONDS) // 最大等待时间
.maxConnectionIdleTime(60000, TimeUnit.MILLISECONDS) // 连接空闲时间
.maxConnectionLifeTime(300000, TimeUnit.MILLISECONDS)) // 连接最大生命周期
// Socket配置
.applyToSocketSettings(builder -> builder
.connectTimeout(10000, TimeUnit.MILLISECONDS) // 连接超时
.readTimeout(30000, TimeUnit.MILLISECONDS)) // 读超时
// Server配置
.applyToServerSettings(builder -> builder
.heartbeatFrequency(10000, TimeUnit.MILLISECONDS) // 心跳频率
.minHeartbeatFrequency(500, TimeUnit.MILLISECONDS)) // 最小心跳频率
// 读写配置
.readPreference(ReadPreference.secondaryPreferred())
.writeConcern(WriteConcern.MAJORITY)
.readConcern(ReadConcern.LOCAL)
.build();
return MongoClients.create(settings);
}
}9.4.2 批量操作优化
java
@Service
@RequiredArgsConstructor
public class UserBatchService {
private final MongoTemplate mongoTemplate;
/**
* 批量插入(高效)
*/
public void batchInsertOptimized(List<User> users) {
// 方式1:insertAll(推荐)
mongoTemplate.insertAll(users);
// 方式2:BulkOperations(更灵活)
BulkOperations bulkOps = mongoTemplate.bulkOps(
BulkOperations.BulkMode.UNORDERED, // 无序执行(更快)
User.class
);
bulkOps.insert(users);
bulkOps.execute();
}
/**
* 批量更新(高效)
*/
public void batchUpdateOptimized(List<User> users) {
BulkOperations bulkOps = mongoTemplate.bulkOps(
BulkOperations.BulkMode.UNORDERED,
User.class
);
for (User user : users) {
Query query = new Query(Criteria.where("id").is(user.getId()));
Update update = new Update()
.set("status", user.getStatus())
.set("updatedAt", LocalDateTime.now());
bulkOps.updateOne(query, update);
}
BulkWriteResult result = bulkOps.execute();
System.out.println("更新数量: " + result.getModifiedCount());
}
/**
* 分批处理大数据集(避免OOM)
*/
public void processBigDataset(int batchSize) {
Query query = new Query();
long total = mongoTemplate.count(query, User.class);
for (int skip = 0; skip < total; skip += batchSize) {
query.skip(skip).limit(batchSize);
List<User> users = mongoTemplate.find(query, User.class);
// 处理这批数据...
processUsers(users);
}
}
private void processUsers(List<User> users) {
// 业务逻辑...
}
}9.4.3 索引管理
java
import org.springframework.data.mongodb.core.index.*;
import org.springframework.stereotype.Component;
import jakarta.annotation.PostConstruct;
import lombok.RequiredArgsConstructor;
@Component
@RequiredArgsConstructor
public class MongoIndexManager {
private final MongoTemplate mongoTemplate;
@PostConstruct
public void ensureIndexes() {
IndexOperations indexOps = mongoTemplate.indexOps(User.class);
// 1. 创建单字段索引
indexOps.ensureIndex(new Index()
.on("email", Sort.Direction.ASC)
.unique()
.named("idx_email"));
// 2. 创建复合索引
indexOps.ensureIndex(new Index()
.on("status", Sort.Direction.ASC)
.on("createdAt", Sort.Direction.DESC)
.named("idx_status_created"));
// 3. 创建文本索引
indexOps.ensureIndex(new Index()
.on("username", Sort.Direction.ASC)
.on("email", Sort.Direction.ASC)
.text()
.named("idx_text_search"));
// 4. 创建部分索引
indexOps.ensureIndex(new Index()
.on("email", Sort.Direction.ASC)
.partial(PartialIndexFilter.of(Criteria.where("status").is("active")))
.named("idx_email_active"));
// 5. 创建TTL索引(自动删除过期文档)
indexOps.ensureIndex(new Index()
.on("createdAt", Sort.Direction.ASC)
.expire(30, TimeUnit.DAYS) // 30天后自动删除
.named("idx_ttl"));
}
/**
* 查看索引信息
*/
public void printIndexes() {
IndexOperations indexOps = mongoTemplate.indexOps(User.class);
indexOps.getIndexInfo().forEach(indexInfo -> {
System.out.println("索引名称: " + indexInfo.getName());
System.out.println("索引字段: " + indexInfo.getIndexFields());
System.out.println("是否唯一: " + indexInfo.isUnique());
});
}
}10. 生产环境优化建议
10.1 硬件配置
推荐配置(中型应用):
| 组件 | 规格 | 说明 |
|---|---|---|
| CPU | 8核+ | WiredTiger利用多核并发 |
| 内存 | 32GB+ | Cache默认使用50%内存 |
| 磁盘 | SSD(NVMe优先) | 随机IO性能至关重要 |
| 网络 | 万兆网卡 | 减少复制集延迟 |
10.2 操作系统调优
bash
# 1. 禁用THP(Transparent Huge Pages)
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
# 2. 调整文件描述符限制
ulimit -n 64000
# 3. 禁用NUMA(多核服务器)
numactl --interleave=all mongod ...
# 4. 使用XFS文件系统(推荐)
mkfs.xfs /dev/sdb1
mount -o noatime /dev/sdb1 /data/mongodb10.3 MongoDB配置优化
yaml
# mongod.conf(生产环境推荐配置)
storage:
dbPath: /data/mongodb
journal:
enabled: true # 启用Journal
commitIntervalMs: 100 # 100ms刷盘
wiredTiger:
engineConfig:
cacheSizeGB: 16 # 缓存大小(总内存50%)
journalCompressor: snappy # Journal压缩
directoryForIndexes: true # 索引独立目录
collectionConfig:
blockCompressor: zstd # 数据压缩(MongoDB 4.2+)
indexConfig:
prefixCompression: true # 索引前缀压缩
systemLog:
destination: file
path: /var/log/mongodb/mongod.log
logAppend: true
verbosity: 0 # 日志级别(0=INFO)
net:
port: 27017
bindIp: 0.0.0.0 # 生产环境绑定内网IP
maxIncomingConnections: 10000 # 最大连接数
replication:
replSetName: rs0
oplogSizeMB: 51200 # Oplog大小(50GB)
setParameter:
enableLocalhostAuthBypass: false # 禁用本地认证绕过10.4 监控指标
关键监控指标:
| 类别 | 指标 | 告警阈值 |
|---|---|---|
| 性能 | QPS(每秒查询数) | > 10000 |
| 平均响应时间 | > 100ms | |
| 慢查询数量 | > 10/分钟 | |
| 资源 | CPU使用率 | > 80% |
| 内存使用率 | > 90% | |
| 磁盘使用率 | > 85% | |
| 磁盘IO等待 | > 10% | |
| 复制集 | 复制延迟 | > 5秒 |
| Oplog窗口 | < 6小时 | |
| 主节点切换次数 | > 0/天 | |
| 连接 | 活跃连接数 | > 8000 |
| 连接池使用率 | > 90% |
监控工具:
- MongoDB Ops Manager(官方,商业版)
- Prometheus + MongoDB Exporter(开源)
yaml
# docker-compose.yml
services:
mongodb-exporter:
image: percona/mongodb_exporter:latest
command:
- '--mongodb.uri=mongodb://admin:password@mongo1:27017'
- '--collect-all'
ports:
- 9216:9216- Grafana Dashboard(可视化)
10.5 备份策略
备份方式对比:
| 方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| mongodump | 简单易用,跨平台 | 速度慢,锁库 | 小数据量(< 100GB) |
| 文件系统快照 | 速度快,一致性好 | 需要LVM/云快照 | 中大型数据(> 100GB) |
| 复制集延迟节点 | 防止误删除 | 占用资源 | 结合其他方式使用 |
| Ops Manager | 自动化,增量备份 | 需要商业版 | 企业级应用 |
示例:mongodump备份脚本:
bash
#!/bin/bash
# 备份目录
BACKUP_DIR="/data/mongodb_backup"
DATE=$(date +%Y%m%d_%H%M%S)
BACKUP_PATH="${BACKUP_DIR}/${DATE}"
# 执行备份
mongodump \
--host=mongo1:27017,mongo2:27017,mongo3:27017 \
--username=admin \
--password=password \
--authenticationDatabase=admin \
--out="${BACKUP_PATH}" \
--oplog # 备份oplog(时间点恢复)
# 压缩备份
tar -czf "${BACKUP_PATH}.tar.gz" -C "${BACKUP_DIR}" "${DATE}"
rm -rf "${BACKUP_PATH}"
# 删除7天前的备份
find "${BACKUP_DIR}" -name "*.tar.gz" -mtime +7 -delete
echo "备份完成: ${BACKUP_PATH}.tar.gz"恢复示例:
bash
# 解压备份
tar -xzf /data/mongodb_backup/20251222_100000.tar.gz -C /tmp
# 恢复数据
mongorestore \
--host=mongo1:27017 \
--username=admin \
--password=password \
--authenticationDatabase=admin \
--oplogReplay # 重放oplog
/tmp/20251222_10000010.6 安全加固
安全检查清单:
yaml
# 1. 启用认证
security:
authorization: enabled
keyFile: /etc/mongodb/keyfile # 复制集认证密钥
# 2. 启用TLS/SSL
net:
tls:
mode: requireTLS
certificateKeyFile: /etc/mongodb/server.pem
CAFile: /etc/mongodb/ca.pem
# 3. 绑定内网IP(不要用0.0.0.0)
net:
bindIp: 10.0.1.10
# 4. 启用审计日志(企业版)
auditLog:
destination: file
format: JSON
path: /var/log/mongodb/audit.json
# 5. 配置角色权限
db.createUser({
user: "app_user",
pwd: "strong_password",
roles: [
{ role: "readWrite", db: "mydb" },
{ role: "read", db: "mydb_readonly" }
]
})总结
本文深入剖析了MongoDB的核心技术,涵盖以下内容:
- 数据模型:BSON格式、文档设计模式、嵌入vs引用
- 存储引擎:WiredTiger架构、MVCC、Checkpoint、Journal
- 索引优化:B-Tree结构、索引类型、ESR规则、覆盖查询
- 高可用:复制集架构、Oplog复制、选举机制、读写关注
- 水平扩展:分片集群、分片键选择、Chunk管理、查询路由
- 事务:多文档事务、快照隔离、两阶段提交
- 查询优化:执行计划分析、聚合管道优化
- Java集成:Spring Data MongoDB、事务管理、性能优化
- 生产实践:硬件配置、监控告警、备份恢复、安全加固
推荐阅读:
- 官方文档:https://www.mongodb.com/docs/manual/
- 《MongoDB权威指南(第3版)》
- 《MongoDB应用设计模式》
- 源码仓库:https://github.com/mongodb/mongo