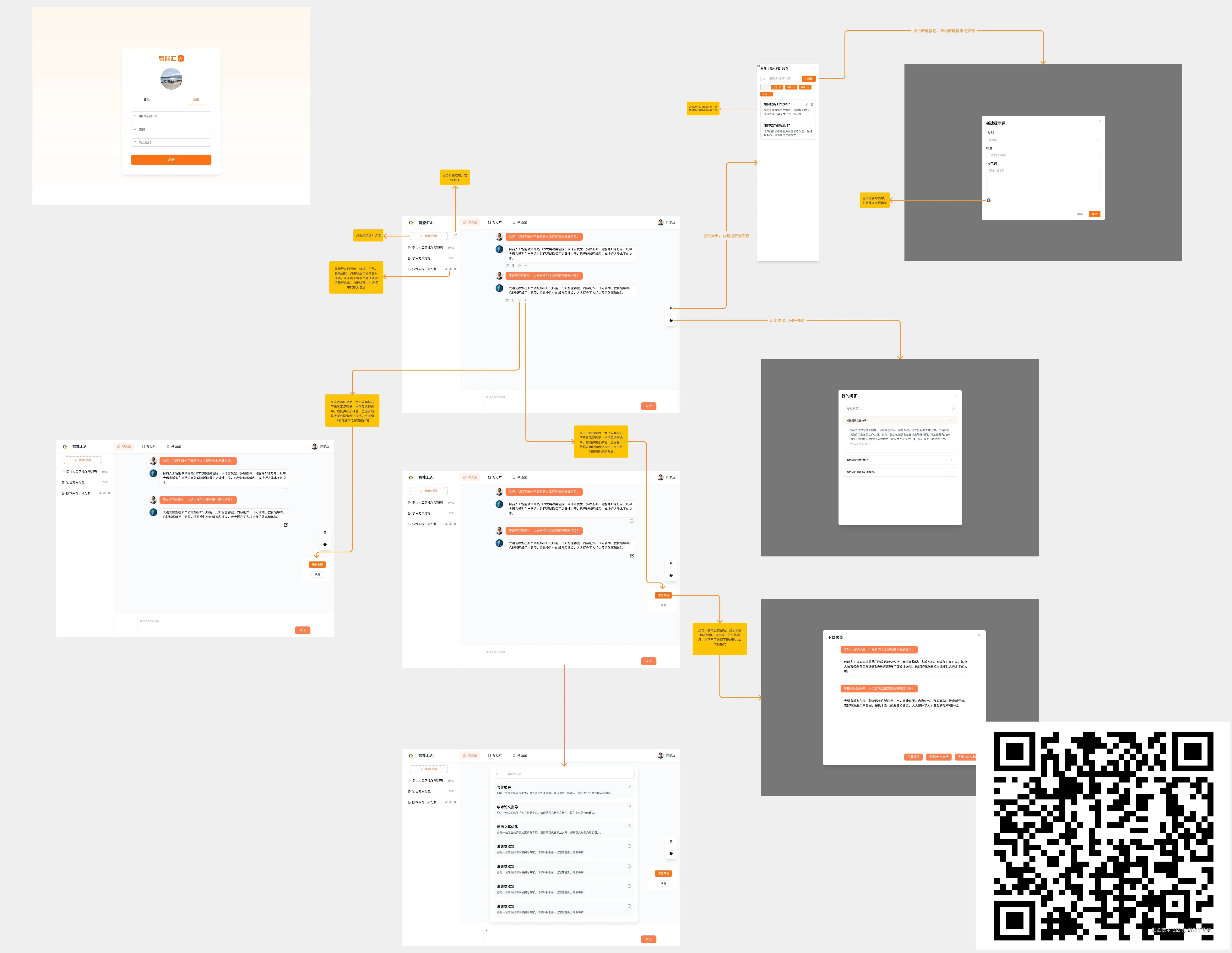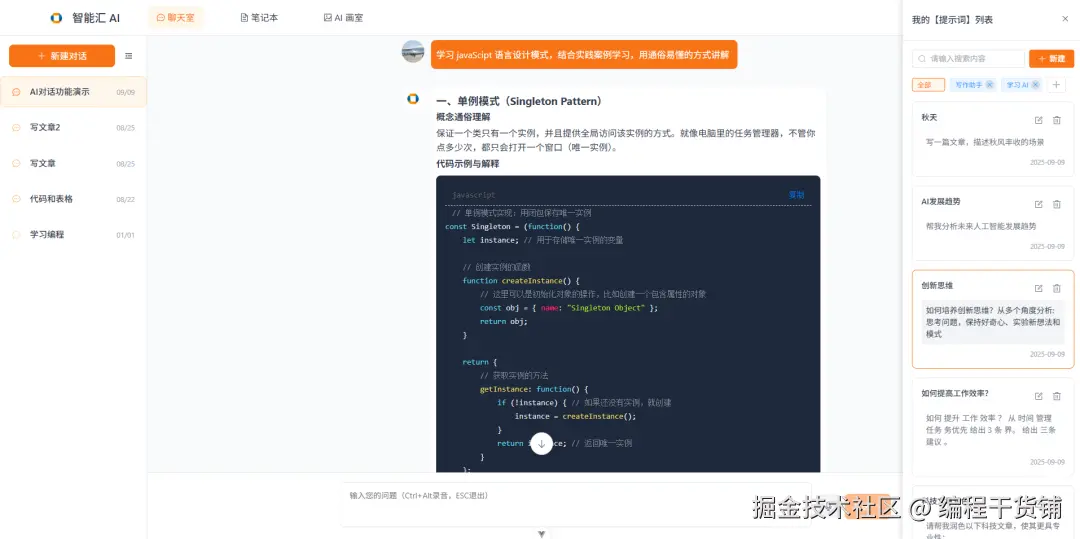
一个 AI 聊天功能,背后至少 8 个你没想到的工程细节
很多人第一次做 AI 项目,都会有一个错觉。
"不就是接个大模型 API,做个输入框,再把结果展示出来吗?"
但只要你真的做过一个像样的 AI 聊天功能 ,你就会发现:真正的难点,80% 都不在模型本身。
一个"看起来很简单"的聊天窗口,背后其实是一整套工程系统。
今天我就拆给你看------一个 AI 聊天功能,至少隐藏着 8 个你平时根本注意不到的工程细节。
一、你以为的 AI 聊天:三步搞定
大多数人脑子里的 AI 聊天是这样的:
- 输入一句话
- 调用大模型接口
- 把返回结果展示出来
如果只是 Demo,这确实够了。但如果你想做的是一个能长期使用、能写进简历、甚至能上线的 AI 产品------那从这一刻开始,事情就完全不一样了。
二、工程细节 1:聊天"流式输出",不是一句话返回
真正好用的 AI 聊天,一定是边生成、边显示的。
为什么?
- 用户不想等 10 秒看一整段文字
- "打字机效果"本身就是体验的一部分
但这意味着什么?
- 后端要支持 流式响应
- 前端要实时接收、拼接内容
- 中途还要能中断生成
👉 很多新手卡在这一步,才第一次意识到:AI 项目不是普通的 HTTP 请求。
三、工程细节 2:历史对话不是"简单数组"
你以为的历史记录:
用户:你好 AI:你好,有什么可以帮你?真实项目里的历史记录要考虑:
- 每一轮对话的角色(system / user / assistant)
- 上下文长度限制
- 是否要裁剪旧消息
- 不同模型的上下文策略
如果你不做这些控制,结果只有一个:👉 要么效果越来越差,要么成本越来越高。
四、工程细节 3:Prompt 不是写一句话就完事
很多人对 Prompt 的理解还停留在:
"写清楚一点就行"
但在真实工程里,Prompt 往往需要:
- 模板化管理
- 支持动态变量
- 不同场景使用不同 Prompt
- 后期可配置、可调整
这也是为什么,成熟的 AI 产品一定有「提示词管理系统」,而不是写死在代码里。
五、工程细节 4:Token 消耗,直接决定你会不会"亏钱"
当你开始正式用 AI 接口,你会很快发现一个残酷现实:
Token = 成本
一个 AI 聊天功能,必须考虑:
- 单次对话 token 上限
- 历史上下文如何裁剪
- 是否限制用户输入长度
- 不同模型的成本差异
很多"看起来跑得很爽"的 Demo,一上线就发现------根本烧不起钱。
六、工程细节 5:用户系统和登录,决定你是不是"玩具"
没有登录的 AI 聊天,永远只是个演示页面。
一旦你引入登录,就会连锁引出一堆工程问题:
- Token 鉴权
- 用户隔离
- 每个用户的聊天记录归属
- 权限与接口保护
👉 到这一步,AI 项目已经不再是"前端玩具",而是一个真正的 Web 应用系统。
七、工程细节 6:数据存储,远比你想的复杂
你需要存的,从来不只是"聊天内容":
- 对话列表
- 消息顺序
- 使用的模型
- Prompt 版本
- 创建时间、更新时间
这背后是:
- 数据表设计
- 索引策略
- 查询性能
- 后期扩展能力
很多人第一次做到这里才发现:AI 项目,本质上也是数据驱动产品。
八、工程细节 7:异常处理,决定体验"像不像人"
真实用户一定会遇到:
- 模型超时
- 接口报错
- 内容生成中断
- 网络异常
如果你不处理,用户看到的只会是:
"请求失败"
而成熟的 AI 聊天,会做到:
- 友好的错误提示
- 可重新生成
- 可继续对话
- 状态可恢复
这些,都是工程能力,而不是模型能力。
九、工程细节 8:这不是一个功能,而是一整套系统
当你把上面这些拼在一起,你会发现:
一个 AI 聊天功能,至少涉及:
- 前端状态管理
- 后端接口设计
- 实时通信
- 数据库设计
- 权限与安全
- 成本与性能控制
👉 它从来不是"调个 API"那么简单。
十、写在最后:这才是 AI 项目的真正分水岭
很多人学 AI,卡在一个阶段:
会用,但做不出来;能演示,但无法上线。
真正拉开差距的,从来不是你会不会调用模型,而是你有没有能力,把 AI 做成一个完整的工程产品。
当你真正做过一次完整的 AI 聊天系统之后,你对"AI 项目""前端能力""工程化"的理解,都会被彻底重塑。
如果你在读到这里时,心里冒出过类似的想法: "原来一个 AI 聊天功能要考虑这么多东西。" 那说明你已经站在从 Demo 走向真实项目 的门槛上了。真正的提升,往往不是多看几个 API 文档,而是完整做一次:从工程结构、到后端、到 AI 能力整合的 全流程实战。至少,你会清楚知道------自己还缺的,究竟是哪一块。
从0到1打造一款具备Ai聊天,AI写作,文生图,语音合成,语音识别功能的多模态全栈项目: