介绍
今天,我们正式宣布:继 S3 WAL、EBS/Regional EBS WAL1 之后,AutoMQ 将在 2025 年的 12 月的新版本中全面支持以 AWS FSx 作为新的 WAL 存储选项。AutoMQ 本身是一款完全兼容 Apache Kafka 协议、基于 S3 对象存储构建的新一代 Diskless Kafka,通过自研的「WAL + 对象存储」创新流存储引擎,将写入日志与大规模持久化存储解耦,在保证 Kafka 语义和稳定性的同时,大幅降低存储成本、简化运维,并已在行业内获得广泛认可。随着 FSx WAL 的引入,AWS 上的 AutoMQ 终于补齐了关键的一块拼图:在 AWS 上,你可以在一套真正 Diskless 的 Kafka 方案中,同时兼顾消除跨 AZ 流量成本、多 AZ 级别容灾能力以及接近本地磁盘体验的低延迟。
Diskless Kafka 的延迟挑战
近些年来,随着 S3 API 凭借极致低成本、弹性与共享存储特性,逐渐成为云上数据基础设施的新标准,基于对象存储重构流存储引擎的 Diskless Kafka 方案开始兴起。自 AutoMQ 在 2023 年率先提出基于共享存储的 Kafka 架构以来,Diskless Kafka 已经成为 data streaming 领域的一股重要趋势:在云上,它天然具备计算与存储解耦、按需弹性扩缩容、以及显著的成本优势。尤其是借助共享存储消除跨 AZ 流量费用,在 AWS、GCP 等主流公有云上,多 AZ 部署的 Kafka 集群每月可以节省数千到数万美元的网络成本,这一点已经获得大量云上 Kafka 客户的高度认可,也是推动他们考虑迁移到 Diskless Kafka 方案的核心驱动力之一。
但 Diskless Kafka 也面临一个根本性挑战:如果只是简单抛弃本地磁盘,把所有数据直接同步写入对象存储,就会彻底丧失 Kafka 最重要的能力之一------低延迟。对象存储的设计目标是高可靠与高吞吐,而不是亚毫秒级写入延迟。通常情况下,直接写 S3 这类对象存储的平均写入延迟在 200--500ms 区间,即便使用诸如 S3 Express One Zone(S3 E1Z)这类最新产品,写入延迟依然大约在 150ms 左右。对于微服务链路、撮合引擎、风控决策、实时风控等延迟敏感的金融与交易场景,这样的延迟是远远不能接受的,也极大限制了市面上大多数 "对象存储直写型" Diskless Kafka 的适用范围,使其更多只能用于可观测性、日志采集、准实时事件流分析等对端到端延迟要求不那么严苛的场景。
AutoMQ 在 2023 年提出并实践了一条不同的技术路径:基于「WAL 加速层 + 对象存储」的共享存储架构。通过在对象存储之前引入一层高性能、低延迟的共享存储作为 Write-Ahead Log(WAL),AutoMQ 将写入路径与低成本的对象存储解耦,在保证 Kafka 语义的前提下,将大部分写入与读热点落在低延迟存储上,再以批量方式异步刷新到对象存储,从而实现了真正意义上的低延迟 Diskless Kafka。这种架构有两大关键价值:一是利用云上低延迟共享存储显著提升写入与读取性能;二是通过 WAL 做批量聚合写入,降低 S3 API 调用次数,进一步提升吞吐并控制成本。在 GCP、Azure 等支持 Regional EBS(或等价多 AZ 共享块存储)的云上,基于 Regional EBS 的 WAL + 对象存储架构,被业界普遍认为是当前 Diskless Kafka 的"理想形态"。
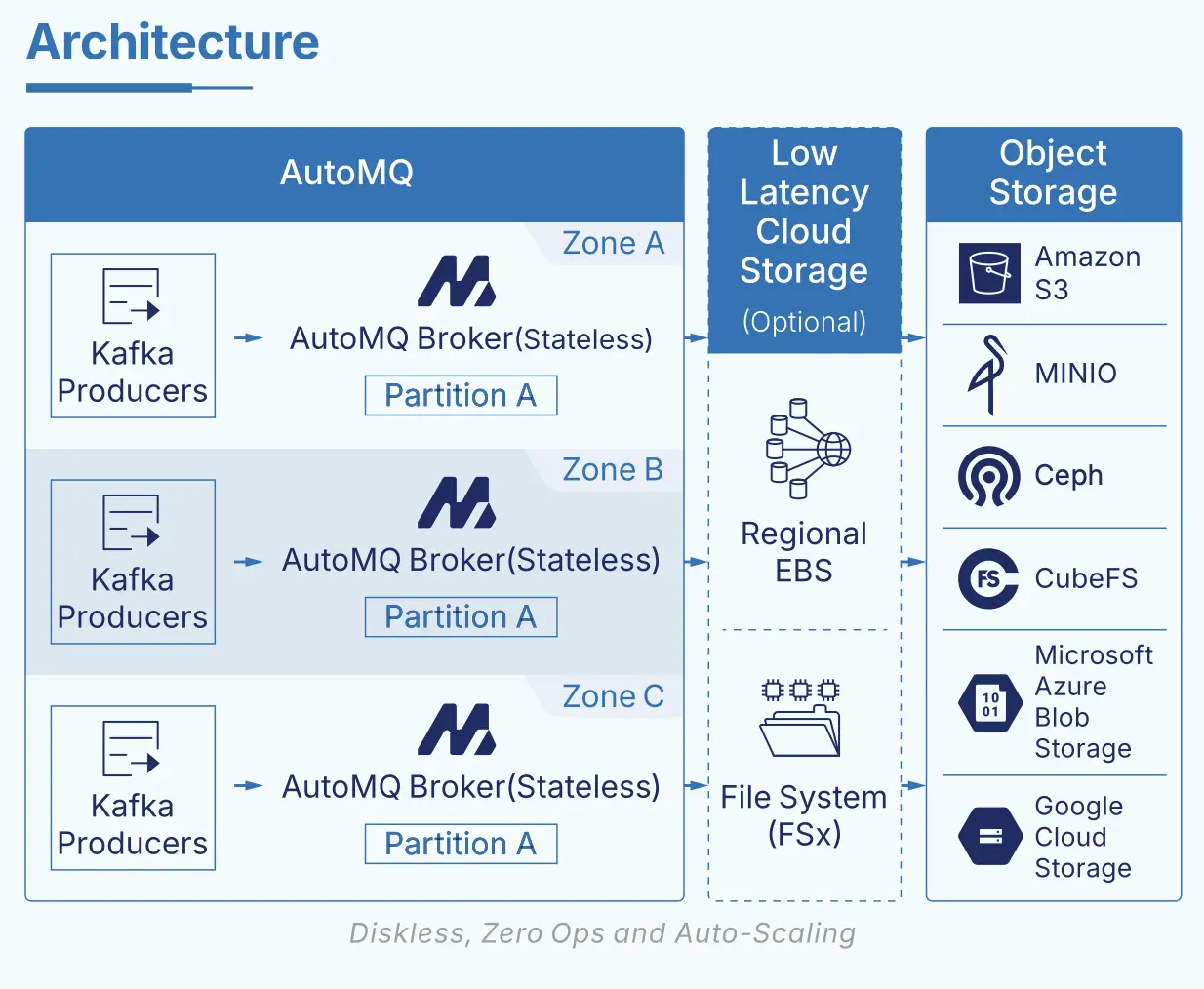
真正的技术难题出现在 AWS 上。与 GCP、Azure 不同,AWS 一直缺乏类似 Regional EBS 这种多 AZ 共享块存储服务,这意味着在 AWS 上构建低延迟的 Diskless Kafka 架构时,我们过去只能在 EBS 和 S3 之间做艰难取舍:
- 使用 EBS 做 WAL,可以获得较好延迟,但仍然逃不开跨 AZ 复制带来的网络成本和复杂性;
- 直接用 S3 做 WAL,可以彻底避免跨 AZ 网络流量成本,但端到端延迟难以满足延迟敏感业务的需求。
这也是为什么在很长一段时间里,Diskless Kafka 在 AWS 上始终存在"要么便宜但不够快,要么够快但不够便宜"的结构性短板。
为了解决这一矛盾,AutoMQ 在调研了 AWS 生态下的多种共享存储服务后,最终选择了 AWS FSx for NetApp ONTAP 作为 WAL 层的关键基础设施。FSx ONTAP 既是一个跨 AZ 高可用的共享文件存储服务,又可以在多 AZ 部署场景下实现低于 10ms 级别的平均写入延迟,同时在计费模型上不叠加跨 AZ 流量费,完美契合 Diskless Kafka 对"低延迟 + 共享存储 + 多 AZ"的复合诉求。借助 AutoMQ 的 WAL 抽象,我们只需要一些固定容量的 FSx 作为高性能 WAL 空间,就可以将写入先持久化到 FSx WAL 上,再批量刷写到 S3,从而在 AWS 上首次实现:
- 保持 Diskless Kafka 的所有优势:计算存储分离、弹性扩缩、S3 级别的低成本;
- 消除跨 AZ 流量成本,支持多 AZ 部署与容灾;
- 同时获得接近本地盘体验的低延迟写入与消费。
这使得 AutoMQ 成为目前 AWS 上少有的、在成本、多 AZ 高可用与低延迟三个维度上几乎没有明显短板的 Diskless Kafka 方案,也真正打开了 Diskless Kafka 在延迟敏感业务场景的应用空间。
FSx 如何消除跨AZ 流量费
要理解 FSx 如何帮助 AutoMQ 消除 Kafka 跨 AZ 流量费,可以先从"我们到底改了 Kafka 的哪一层"入手,再看 FSx 在这个新架构里的具体职责。Apache Kafka 本身可以被拆分为三层:网络层负责处理 KafkaApis 请求;计算层包含事务、压缩、去重、LogCleaner 等核心逻辑,占 Kafka 代码的绝大部分;最底层是存储层,通过 LocalLog 和 LogSegment 将无限长日志落到本地文件系统。AutoMQ 保留了 Kafka 原生的网络层和计算层代码,只在存储层的 LogSegment 这一非常薄的切面上,将本地磁盘替换为基于 "S3 + 低延迟 WAL(FSx)" 的共享存储引擎,并在网络层之上增加了一个 Zone‑routing interceptor。FSx 以区域级共享卷的形式承担持久 WAL 的角色,所有写入首先顺序落到 FSx,再异步下沉到 S3。
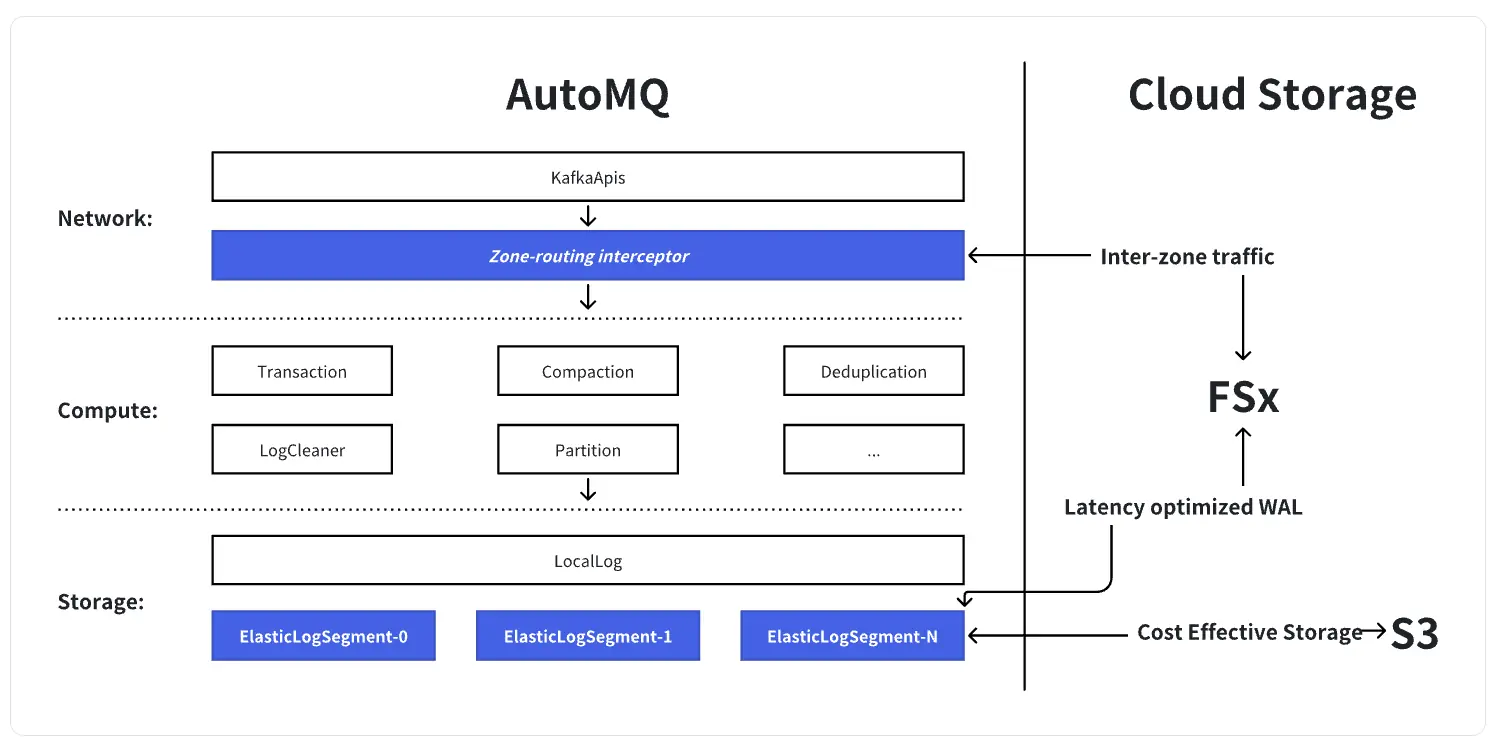
在多 AZ 部署下,传统 Kafka 的跨 AZ 流量主要来自三部分:三副本复制、跨 AZ 消费、以及跨 AZ 写入。AutoMQ 通过单副本 + 云存储(S3/FSx)来承担持久化与多 AZ 可用性,天然消除了集群内三副本带来的复制流量;再结合 rack‑aware 调度,可以让消费者优先就近读取,避免消费侧跨 AZ。剩下最难的一块,是生产者写入导致的跨 AZ 流量。这里 FSx 起到了关键作用:作为共享 WAL,它让不同 AZ 的 Broker 可以"对着同一份日志写",不需要在 Broker 之间再做数据复制;同时,Zone‑routing interceptor 会将跨 AZ 写入"就地代理"到本 AZ 的 Broker,只把极少量控制信息跨 AZ 发送,而真正的大数据块始终在本 AZ 写入 FSx 并最终落到 S3。通过这套设计,AutoMQ 在保留 Kafka 协议兼容和跨 AZ 高可用的前提下,将跨 AZ 数据面流量压缩到接近理论下限。
从结果上看,这个架构让 AutoMQ 在 AWS 上实现了三个目标:
- 通过 FSx 提供的低延迟 WAL,保持接近本地盘的写入与读取体验;
- 通过区域共享存储和 Zone‑routing 机制,将跨 AZ 数据面流量压缩到几乎为零,仅保留少量控制消息;
- 通过 S3 承担主存储,继续享受 Diskless Kafka 在成本和弹性上的全部优势。
更多实现细节可以参考: How does AutoMQ implement a sub-10ms latency Diskless Kafka?
收益
引入 FSx 之后,AutoMQ 在 AWS 上的 Diskless 架构不再需要在"极致低延迟"和"极致低成本"之间做取舍:一方面,继续保持存算分离、消除跨 AZ 数据面流量和基于 S3 的超低存储成本;另一方面,只需少量、固定容量的 FSx 作为区域级低延迟 WAL,就可以把端到端延迟拉回到适配微服务、金融交易等核心实时场景的水平。下面我们分别从性能和成本两个维度来说明这一组合方案带来的收益。
性能解读
从架构上看,AutoMQ + FSx 解决的是"跨 AZ 高可用场景下,如何在不引入跨 AZ 复制流量的前提下继续获得本地盘级别延迟"的问题。我们选择 AWS 提供的 FSx for NetApp ONTAP Multi‑AZ 部署模式:在同一 Region 内由 FSx 在两个 AZ 内托管一对 HA 节点,对外暴露为一个区域级共享文件系统,所有 Broker 都将其挂载为唯一的持久 WAL 设备。基于这层区域级共享 WAL,整个系统在高可用、弹性和网络成本上形成了一个新的平衡点:
- FSx 提供接近本地 EBS 的随机 IO 能力,同时在多个 AZ 之间自动冗余,天然满足跨 AZ 高可用要求;
- AutoMQ Broker 仍然是无状态的计算节点,可以按负载弹性伸缩,而热数据写入全部汇聚到 FSx 上,再异步下沉到 S3;
- 由于数据不再在 Broker 之间复制,跨 AZ 的数据面流量基本被消除,只保留控制面通信。
在这样的前提下,我们在 AWS us-east-1 用一个典型的高吞吐场景来测试端到端性能:
- 环境:6 台 m7g.4xlarge 作为 Broker,FSx ONTAP 采用 Multi‑AZ 双节点部署,二代,配置 1,024 GiB 容量、4,000 预置 IOPS、1,536 MB/s 吞吐;
- 负载模型:4:1 读写比,64 KB 消息,持续 460 MB/s 写入、1,840 MB/s 读取,模拟线上高并发微服务和实时计算任务的混合压力;
- 结果 :写入平均延迟 6.34 ms、P99 17.50 ms;端到端平均延迟 9.40 ms、P99 28.00 ms。
这组数据可以这样理解:在保证跨 AZ 容灾、完全存算分离、以 S3 作为主存储的前提下,AutoMQ 通过一个固定大小的 FSx 层,把 Diskless Kafka 的 平均写入延迟从"几百毫秒量级"拉回到" 10 毫秒以下",接近传统本地盘 Kafka 的体验。这意味着,客户不需要再为"是否能用 Diskless 架构承载核心业务"担心------包括链路复杂的微服务调用、毫秒级敏感的风控决策与订单撮合等场景,都可以在 AutoMQ + FSx 上获得既稳定又可预测的延迟表现。
成本解读
在成本层面,AutoMQ 的核心设计是:用少量 FSx 构建一个可靠的区域级持久 WAL,用海量 S3 承接长期数据,从而形成与传统 Kafka 完全不同的成本结构。
- FSx 只承担高可靠、低延迟的持久 WAL 职责,用来承载最新一段写入日志,而不会用来长时间堆积业务数据;
- S3 负责存放绝大部分历史数据,是集群实际容量扩展的主要载体,主数据始终在 S3 上,整体存储单价稳定在对象存储量级;
- 由于副本冗余集中在 FSx 与 S3 的服务级高可用上,AutoMQ 不再需要在 Broker 之间做日志复制,也不需要跨 AZ 复制数据,从根源上降低了存储和区域间流量开销。
得益于这种分层设计,即便是 10 Gbps 写入、50 节点规模的 AutoMQ 集群,在 FSx 上也只需要不到 100 GB 的 WAL 空间;而在 1 Gbps 写入 / 1 Gbps 消费、TTL 3 天的典型场景下,只需 6 台 m7g.4xlarge 和 2×1536 GB 的 FSx 即可满足性能与可靠性需求。也就是说,虽然 FSx 单位容量价格更高,但我们只需要一小块、基本固定容量的 FSx 用于 WAL,这部分成本与业务 TTL 长短、历史数据规模几乎无关,不会像传统 Kafka 那样随着保留周期拉长而指数式增加副本存储费用。同时,通过架构上取消跨 AZ 日志复制和大部分跨 AZ 数据面流量,AutoMQ 避免了传统 Kafka 在多 AZ 部署中巨额的网络与复制成本,使得整体 TCO 依然由廉价的 S3 存储和按需伸缩的计算实例主导,而不是被大规模高价块存储和跨 AZ 带宽费用绑架。
接下来我们通过下面这个具体的价格例子来说明价格优势(单位:月)。从这组对比数据可以更直观地看出 FSx 在整体成本结构中的价值:在生成端 P99 < 10ms 的同等延迟目标下,传统 Apache Kafka 需要依赖大量高规格实例、三副本存储以及跨 AZ 复制才能勉强达标,单月总成本高达约 22.7 万美元,其中绝大部分支出都被昂贵的块存储和区域间流量吞噬。而 AutoMQ BYOC + FSx 通过固定容量 FSx WAL + S3 的架构,将副本冗余下沉到 FSx/S3 的服务级高可用上,不再在 Broker 之间做日志复制,也几乎不产生跨 AZ 数据面流量,在提供同等级别(甚至更可预测)的亚 10ms 生成延迟的前提下,总成本仅约 1.8 万美元量级,整体节省接近 10×。
与 AutoMQ 开源(S3 直写)的方案相比,引入 FSx 后虽然新增了约 8,000 美元的 FSx 成本,但 S3 API 调用开销显著下降,同时将 P99 从近 900ms 直接拉回到几十毫秒量级,完成了"以极小的额外成本换取接近本地盘体验的低延迟"的升级。这也说明,在 AWS 上选择 AutoMQ + FSx,本质上是用一个可控、线性可预估的 FSx 成本,换取传统 Kafka 难以实现的低延迟、多 AZ 高可用和跨 AZ 流量成本近乎归零的综合收益。

AutoMQ BYOC x FSx: 云市场试用
安装 AutoMQ BYOC 控制面
你可以参考 AutoMQ 官方文档2 从 AWS Marketplace 完成 AutoMQ 控制面的安装。
创建集群
登入 AutoMQ 控制面的 Dashboard,点击 Create Instance 按钮开始创建集群流程。
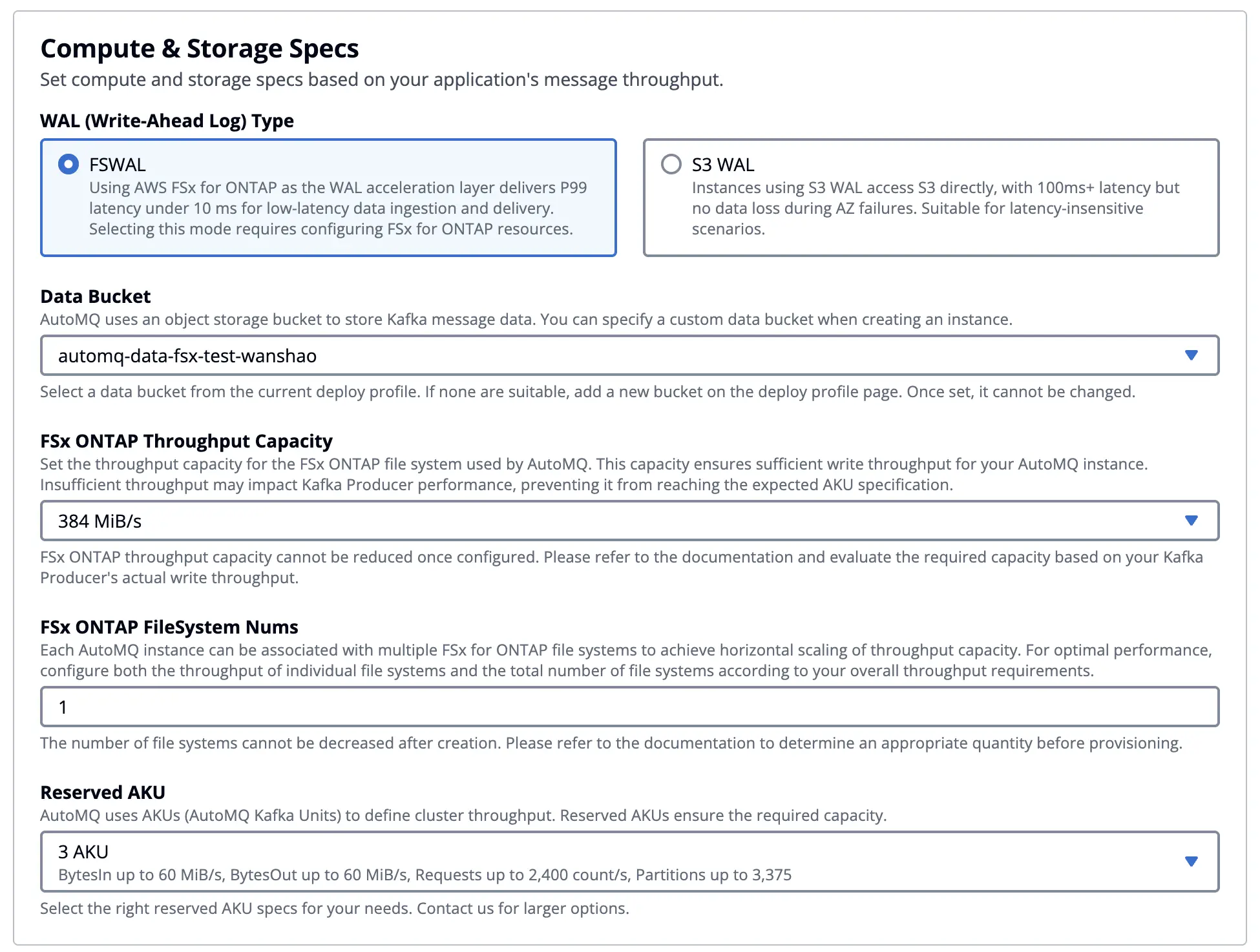
在集群创建步骤 Network Specs 部分选择 3 AZ 部署。在 AWS 上,如果选择单 AZ 部署,我们仍然首先推荐使用 EBS WAL,它具有最佳的性能、成本表现。在多 AZ 部署的时候,考虑到跨 AZ 网络传输成本,你可以选择 S3 WAL 或者 FSx WAL。关于 AutoMQ 选择不同 WAL 时在成本、性能上的差异请参考官方文档3。

选择多 AZ 部署以后,你可以在计算存储规格中勾选FS WAL 然后对集群容量进行配置。
当你选择 EBS WAL 或 S3 WAL 等选项时,集群的容量规划被简化为仅需配置一个参数:AKU(AutoMQ Kafka Unit)。你无需再为如何选择 EC2 实例类型、规格和数量而操心,AutoMQ 会自动为你挑选经过充分压测验证、在性能与成本之间最优的 EC2 实例组合,并确保集群能够稳定满足平台所承诺的吞吐性能指标。例如,在 3 AKU 的配置下,AutoMQ 承诺可提供 60 MB/s 写入、60 MB/s 读取、2,400 RPS,以及不少于 3,375 个分区。通过将底层容量与算力抽象为 AKU,AutoMQ 将传统 Kafka 部署中复杂而易出错的容量规划过程收敛为一个清晰可量化的指标;关于 AKU 的设计理念、基准测试方法和容量换算规则,可参考 AutoMQ 官方文档获取详细说明4。
在本示例中我们选择 FSx WAL,除了配置 AKU 之外,还需要额外选择 Amazon FSx for NetApp ONTAP 的实例规格和数量。AutoMQ 已对不同 FSx ONTAP 实例规格进行了系统化的性能压测与验证,用户无需从 IOPS、带宽、容量等维度自行做复杂规划,只需根据目标写入吞吐量,结合下表即可快速估算所需 FSx 实例数量。在当前配置中,我们选择了 3 AKU(可支持 60 MB/s 的读取与写入),只需搭配 1 个 384 MBps 规格的 FSx 实例即可满足 WAL 写入性能需求。
- FSx 384MBps 规格,提供 150MiB/s Kafka 写入
- FSx 768MBps 规格,提供 300MiB/s Kafka 写入
- FSx 1536MBps 规格,提供 600MiB/s Kafka 写入
读写测试
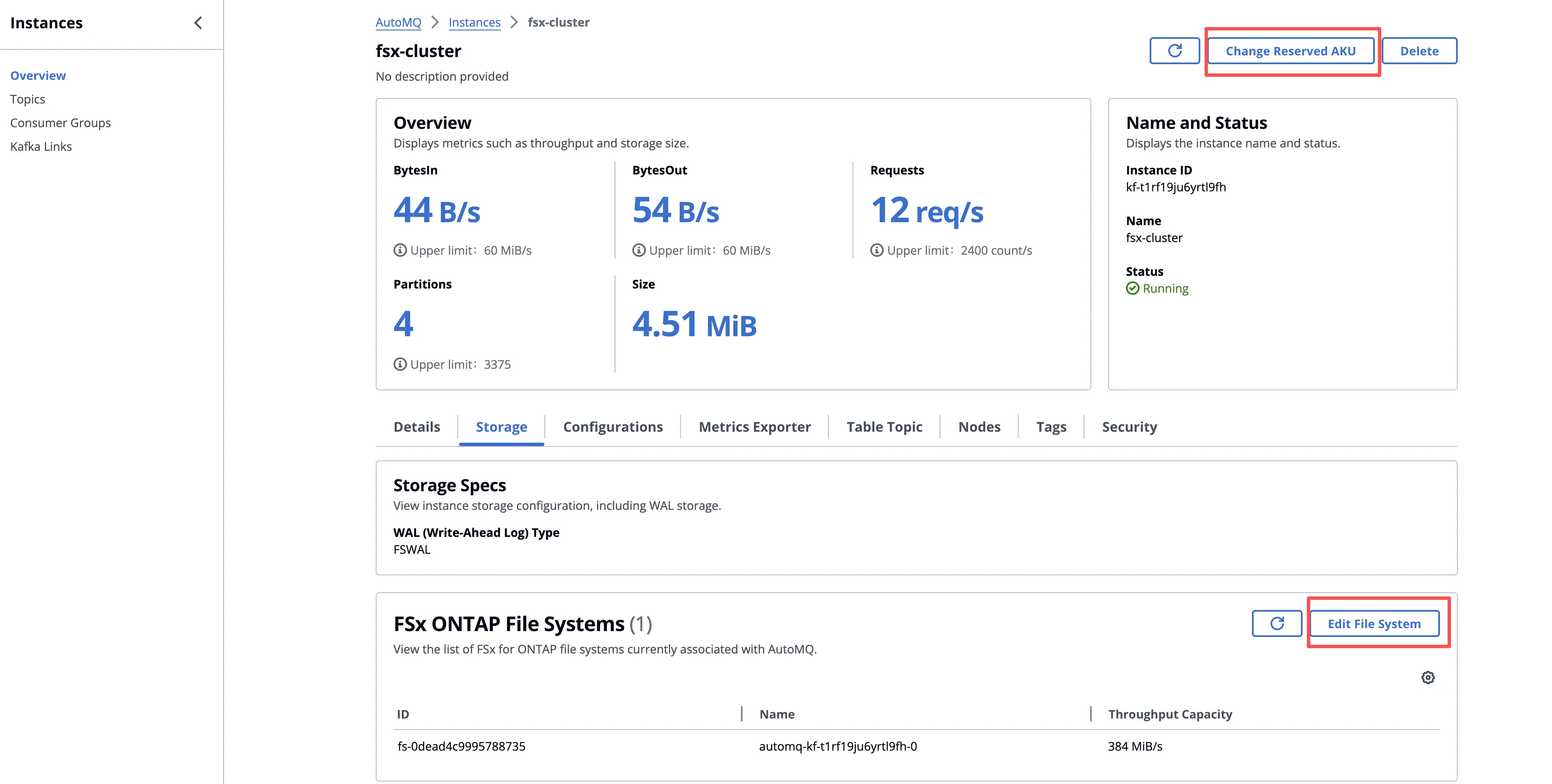
集群创建完成后,你可以在集群详情页面查看集群的基础信息,并按需对集群容量进行弹性调整。
- FSx: 得益于 AutoMQ 存算分离的共享存储架构,主数据全部持久化在对象存储之上,FSx 仅用于加速 WAL 等热路径 I/O。你可以通过增加或减少 FSx 实例数量进行水平扩容,而无需像传统 Kafka 那样进行繁重的分区迁移和数据搬移,从而以业务无感的方式提升或收缩 FSx 可用容量与带宽。
- AKU: 在完成 FSx 实例调整后,你可以进一步调整 AKU 的数量,使集群的最大处理能力与 FSx 能够提供的最大写入能力相匹配,实现计算与存储的解耦伸缩和整体资源利用率的最优化。
在本示例中,我们使用 AutoMQ 基于 OpenMessaging5 封装的 perf 工具6来进行性能测试。我们在同一 VPC 内的一台 EC2 上发起了如下的测试负载。
lua
KAFKA_HEAP_OPTS="-Xmx2g -Xms2g" ./bin/automq-perf-test.sh \
--bootstrap-server 0.kf-t1rf19ju6yrtl9fh.fsx-test-wanshao.automq.private:9092,1.kf-t1rf19ju6yrtl9fh.fsx-test-wanshao.automq.private:9092,2.kf-t1rf19ju6yrtl9fh.fsx-test-wanshao.automq.private:9092 \
--producer-configs batch.size=0 \
--consumer-configs fetch.max.wait.ms=1000 \
--topics 10 \
--partitions-per-topic 128 \
--producers-per-topic 1 \
--groups-per-topic 1 \
--consumers-per-group 1 \
--record-size 52224 \
--send-rate 160 \
--warmup-duration 1 \
--test-duration 5 \
--reset以下是本次示例场景下的读写性能测试结果,供参考。从实际测试数据可以看到,FSx 的写入延迟与原生 Apache Kafka 处于同一量级,能够满足绝大多数对端到端延迟敏感的事件流与实时处理场景的要求。

总结
在这篇文章中,我们展示了 AutoMQ 在 AWS 上引入 FSx 作为 WAL 层之后,如何在保持 Diskless Kafka 架构全部优势的前提下,把端到端延迟拉回到适配核心实时业务的水平:一方面,借助「FSx + S3」的共享存储架构,AutoMQ 实现了真正意义上的存算分离、多 AZ 高可用以及跨 AZ 数据面流量几乎为零;另一方面,通过在 FSx 上构建一个小而高效的区域级 WAL,将写入与读热点全部收敛到低延迟共享存储,再异步下沉到 S3,从根源上重塑了 Kafka 在云上的性能与成本结构。本次示例中,我们也对基于 FSx 的 AutoMQ 进行了简单的性能验证,可以稳定实现亚 10ms 级别的平均写入延迟和几十毫秒量级的端到端延迟,同时继续享受 S3 级别的低成本存储和无状态 Broker 带来的极致弹性伸缩能力。
如果你正在评估如何在 AWS 上为微服务、金融交易、风控决策等延迟敏感业务构建一套真正云原生、低成本、可横向扩展的 Kafka 基础设施,欢迎直接在 AWS Marketplace 8上一键部署并体验 AutoMQ 搭配 FSx 的方案,亲自验证 Sub-10ms Latency Diskless Kafka 在你的生产环境中的表现与价值。
参考资料
2 Guide: Install AutoMQ from AWS Marketplace
5 The OpenMessaging Benchmark Framework