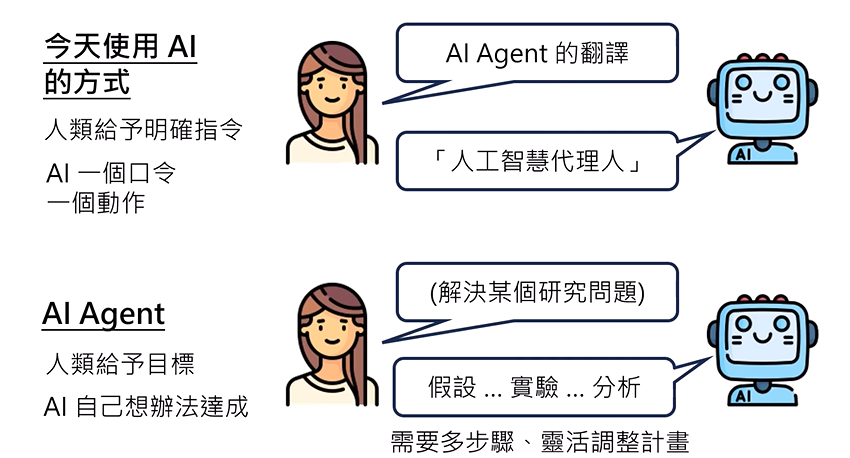
AI Agent初步概念
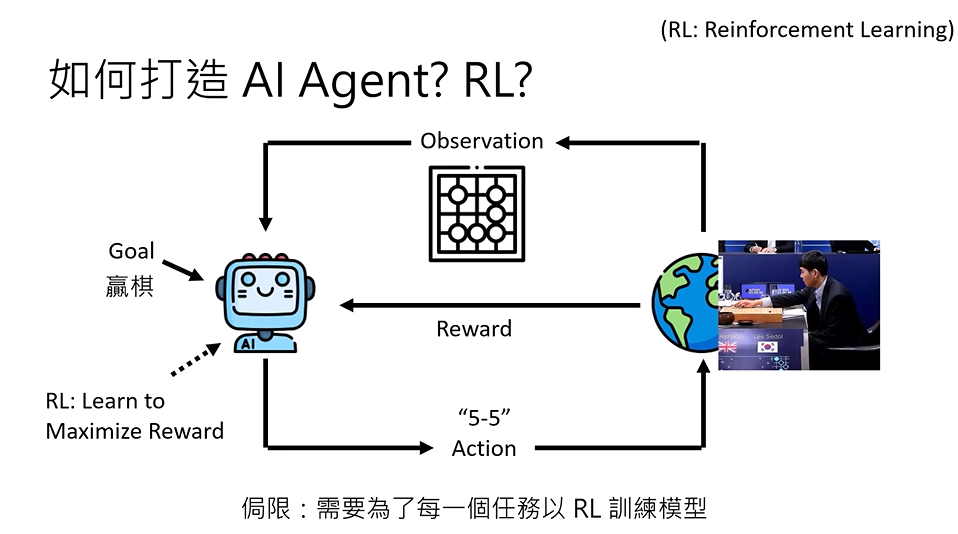
- AI Agent(AlphaGo):这里指 AlphaGo 这个围棋 AI。
- Goal(目标):AI 的任务是 "赢棋"。
- Observation(观测) :AI 获取当前的围棋棋局状态(图中的棋盘),这是 AI 对 "环境"(棋局)的感知。
- Action(动作):AI 根据观测到的棋局,输出下一步的落子决策(比如图中的 "5-5",即棋盘上的坐标位置)。
- 环境(右侧):实际的对弈场景(比如人类棋手或其他 AI),接收 AI 的落子动作后,更新棋局状态,再反馈给 AI。
- Reward(奖励):环境根据 AI 的动作反馈 "奖励信号"(比如赢棋给正奖励、输棋给负奖励)。
- RL 核心逻辑 :AI 通过不断 "观测→动作→获得奖励" 的循环,学习能最大化最终奖励的策略(比如怎么落子更容易赢)。
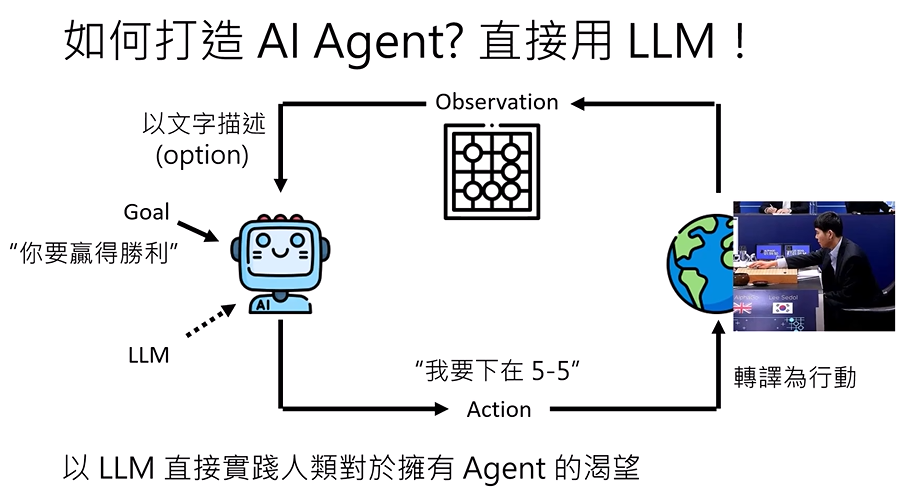
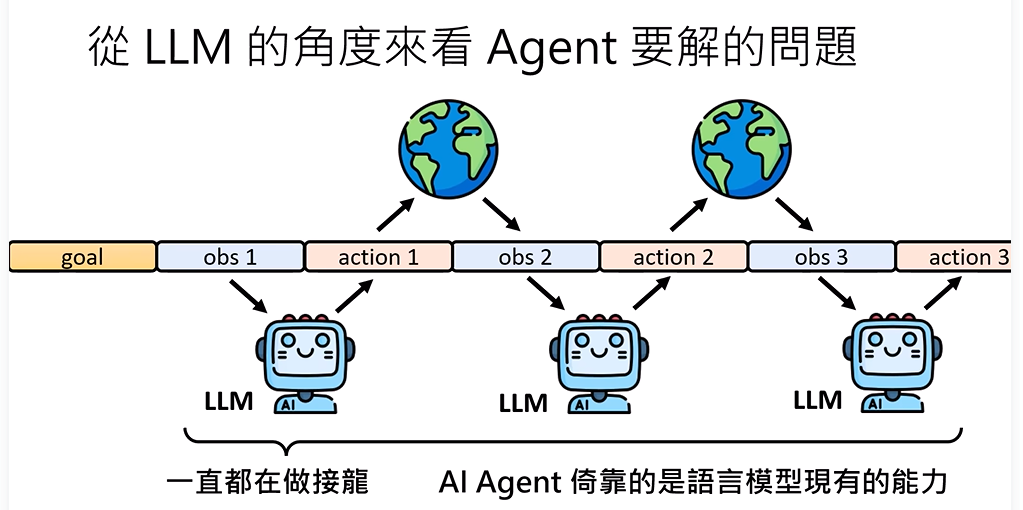
先获得一个目标(goal),然后观察,根据观察(obs1)进行行动(action1),再观察(obs2),再行动(action2)
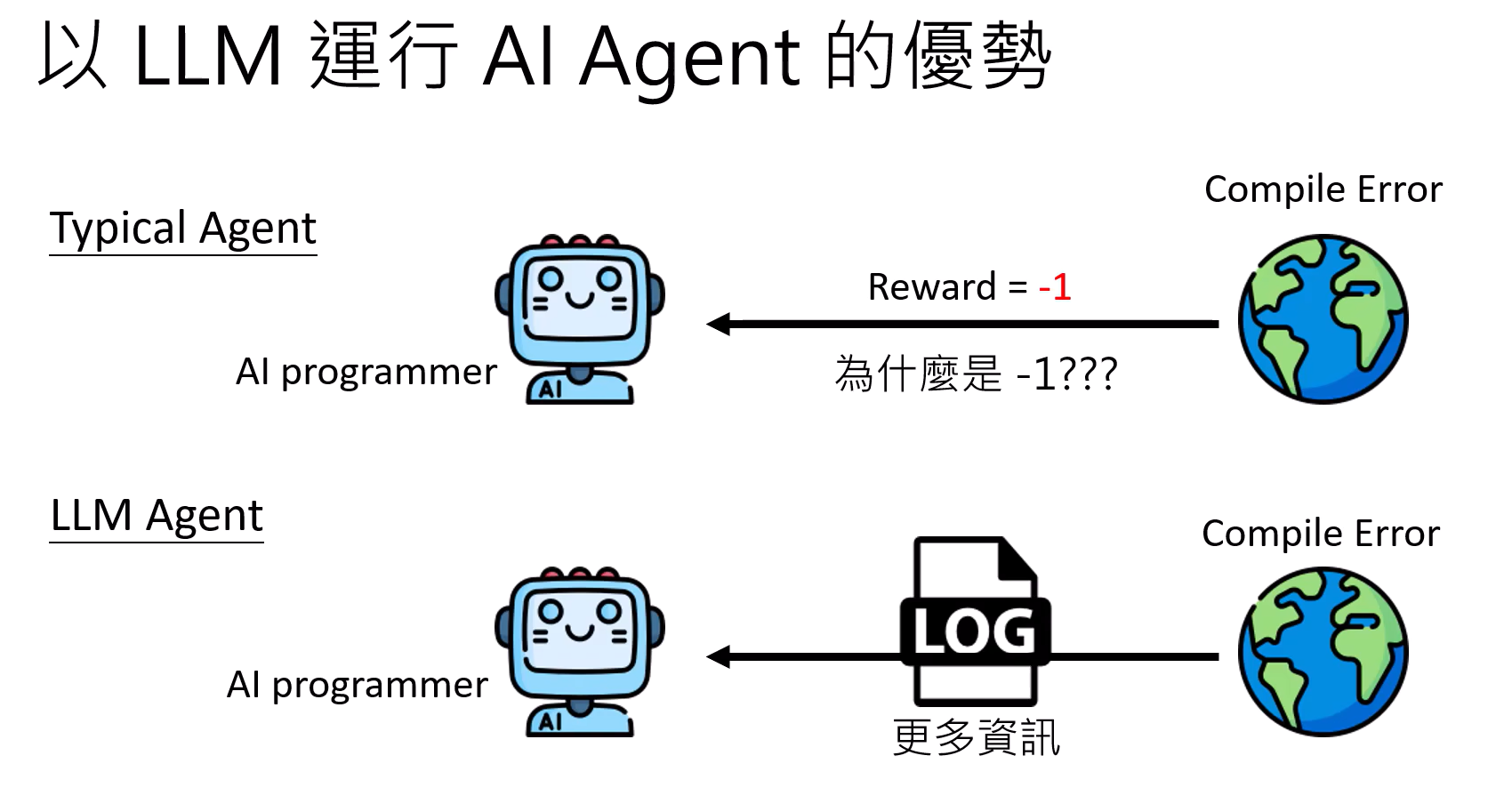
以LLM运行AI Agent的优势:反馈可以直接是一个log
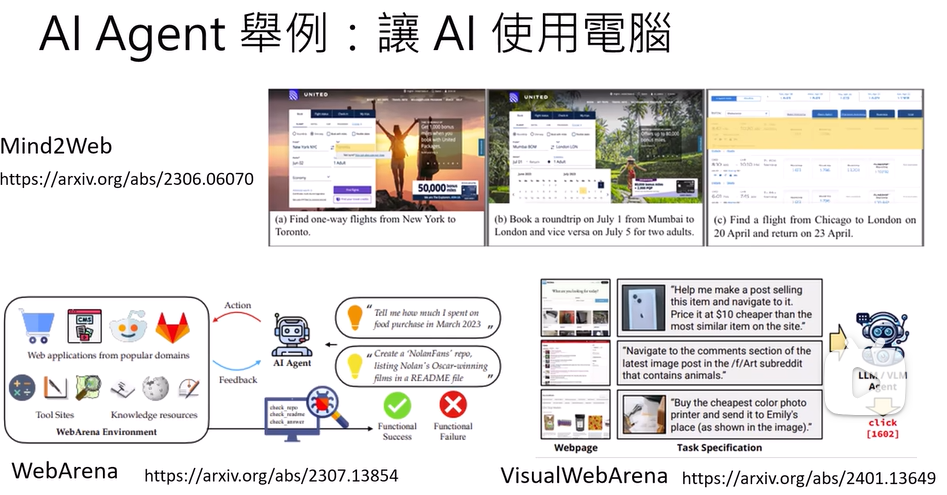
AI Agent应用举例:
让AI使用电脑
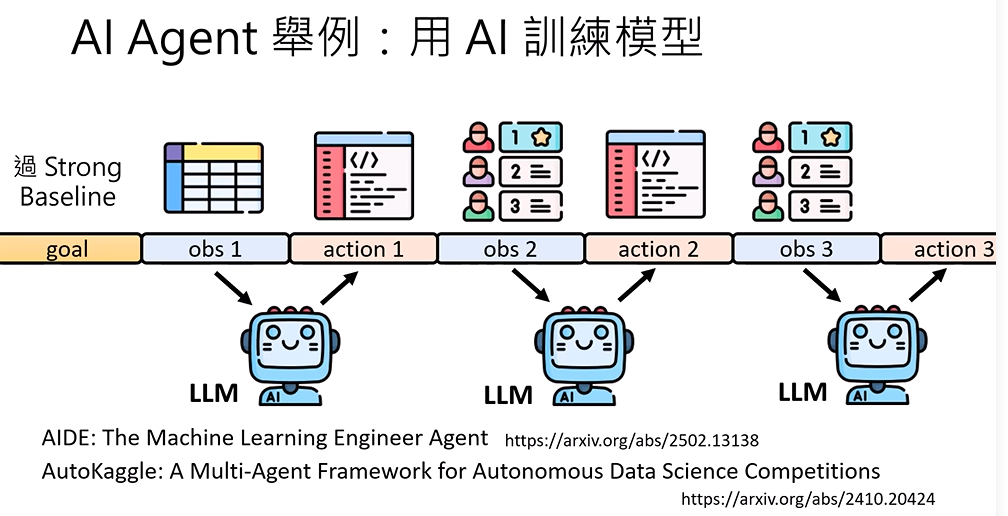
用AI训练模型
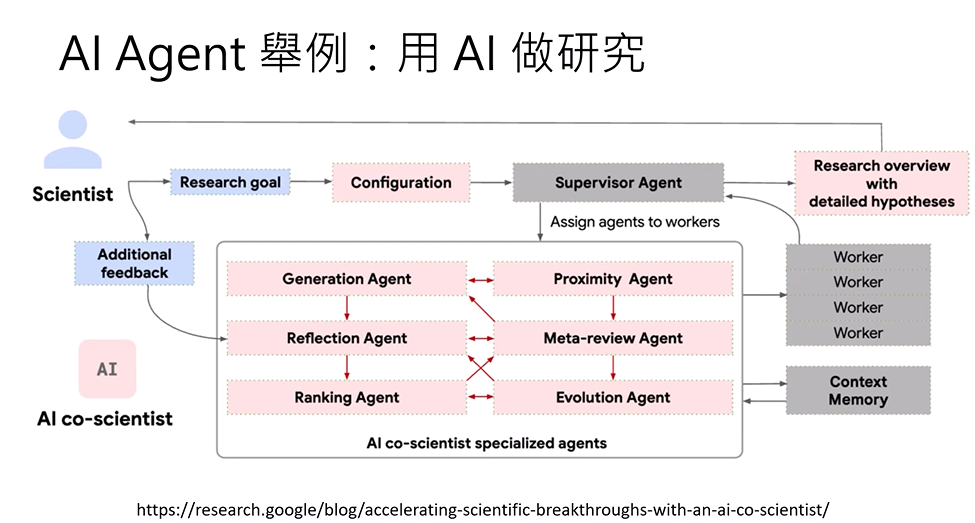
用AI做研究
Agent运行
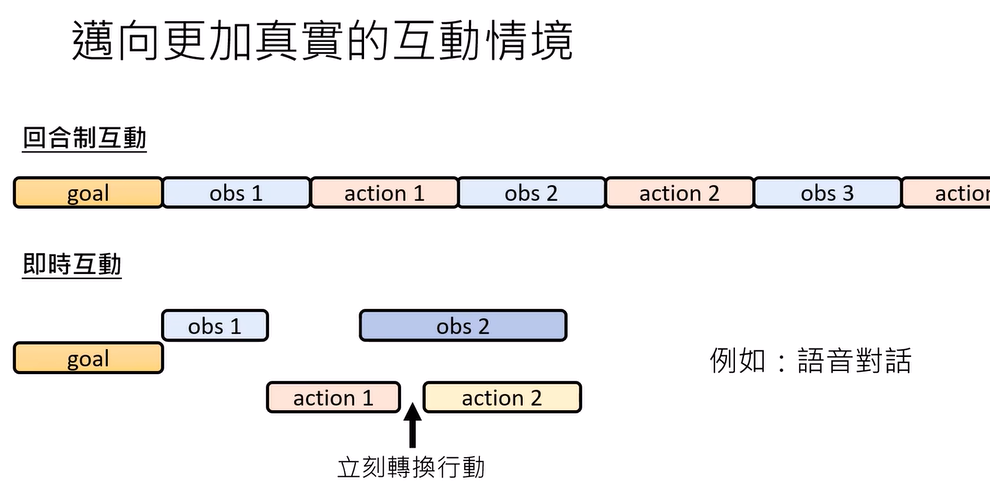
通向更加真实的互动情境:
回合制互动和即时互动(立刻转换行动)
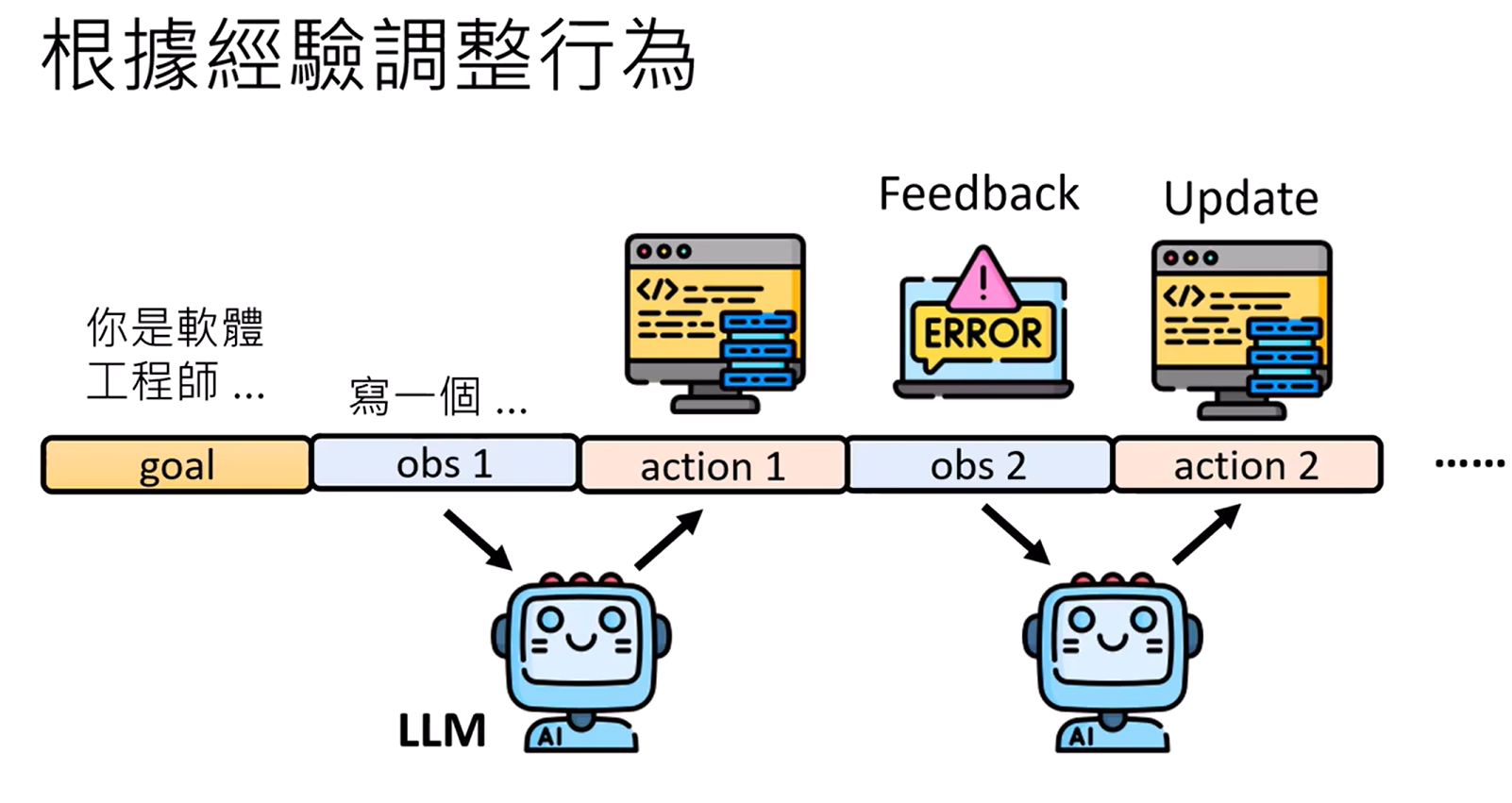
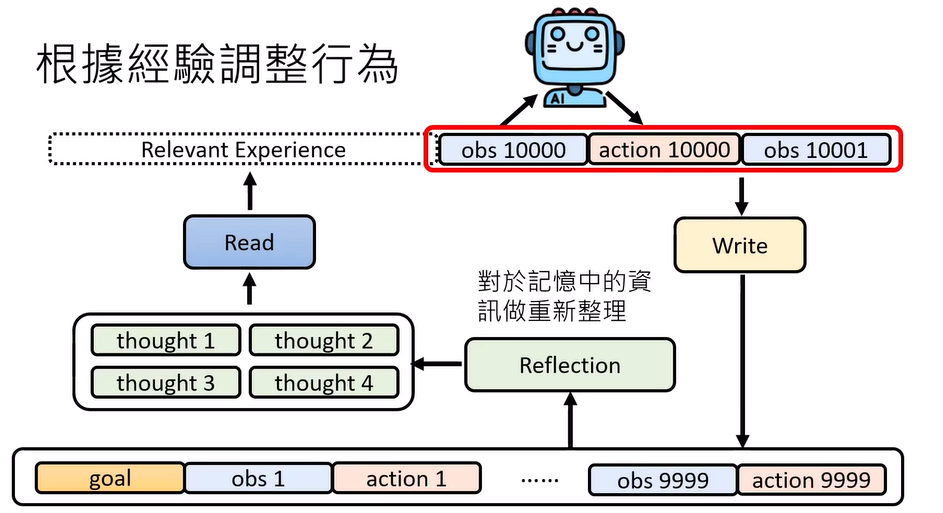
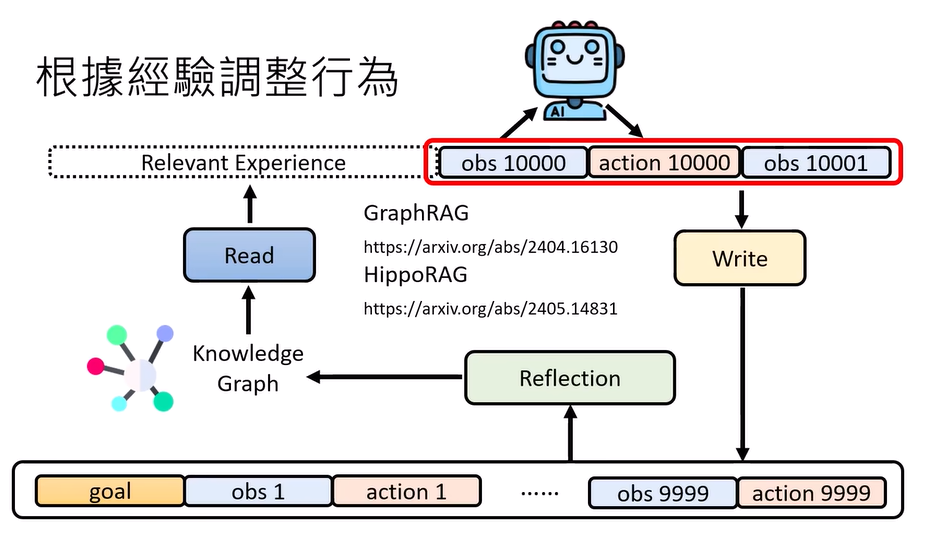
根据经验调整行为:
直接将错误报告给agent,然后行为就会更新
经验过多会导致混乱,所以就存成memory,再从中提取经验
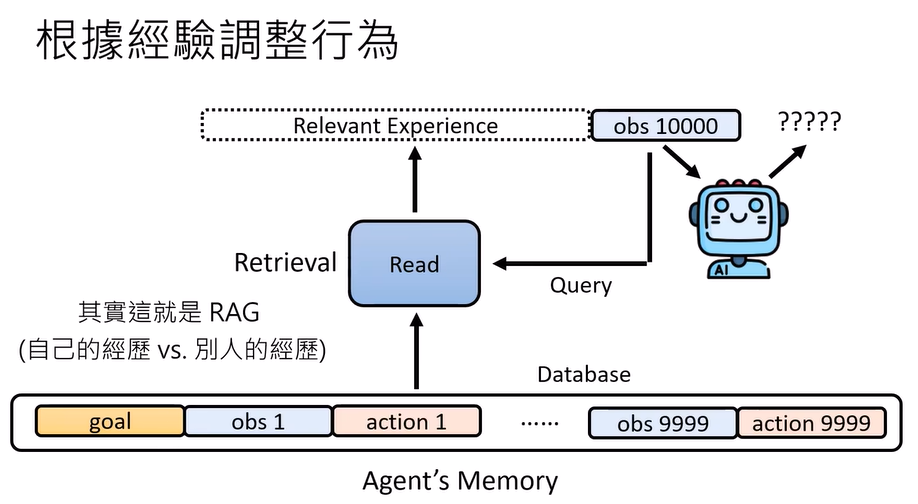
read:从记忆中读
write:判断是否有必要记下来
reflection:重新整理过去的记忆,可以产生新的想法thought/knowledge graph


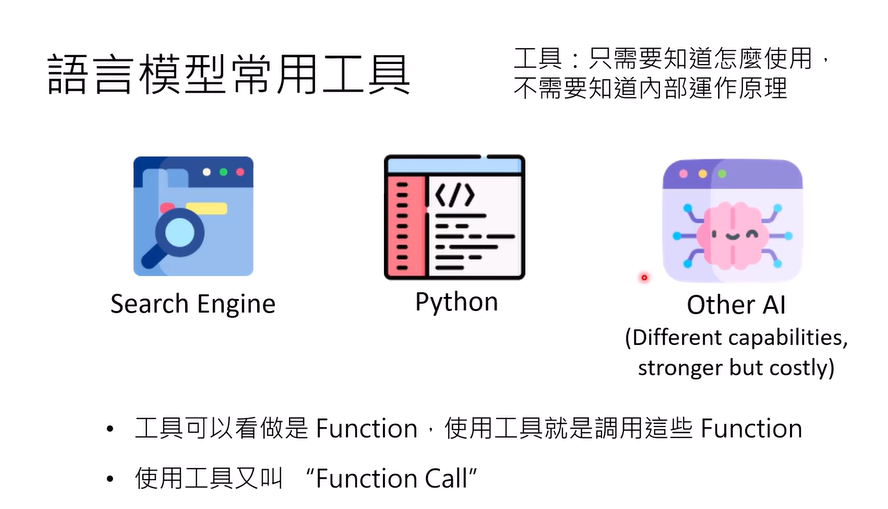
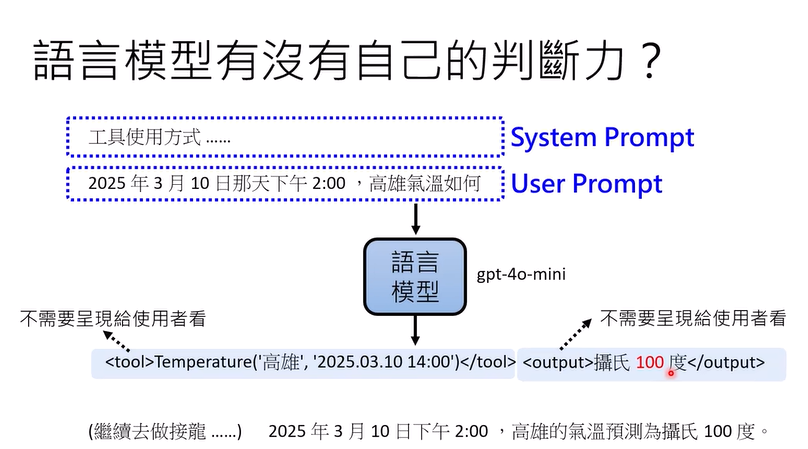
Function Call:使用工具
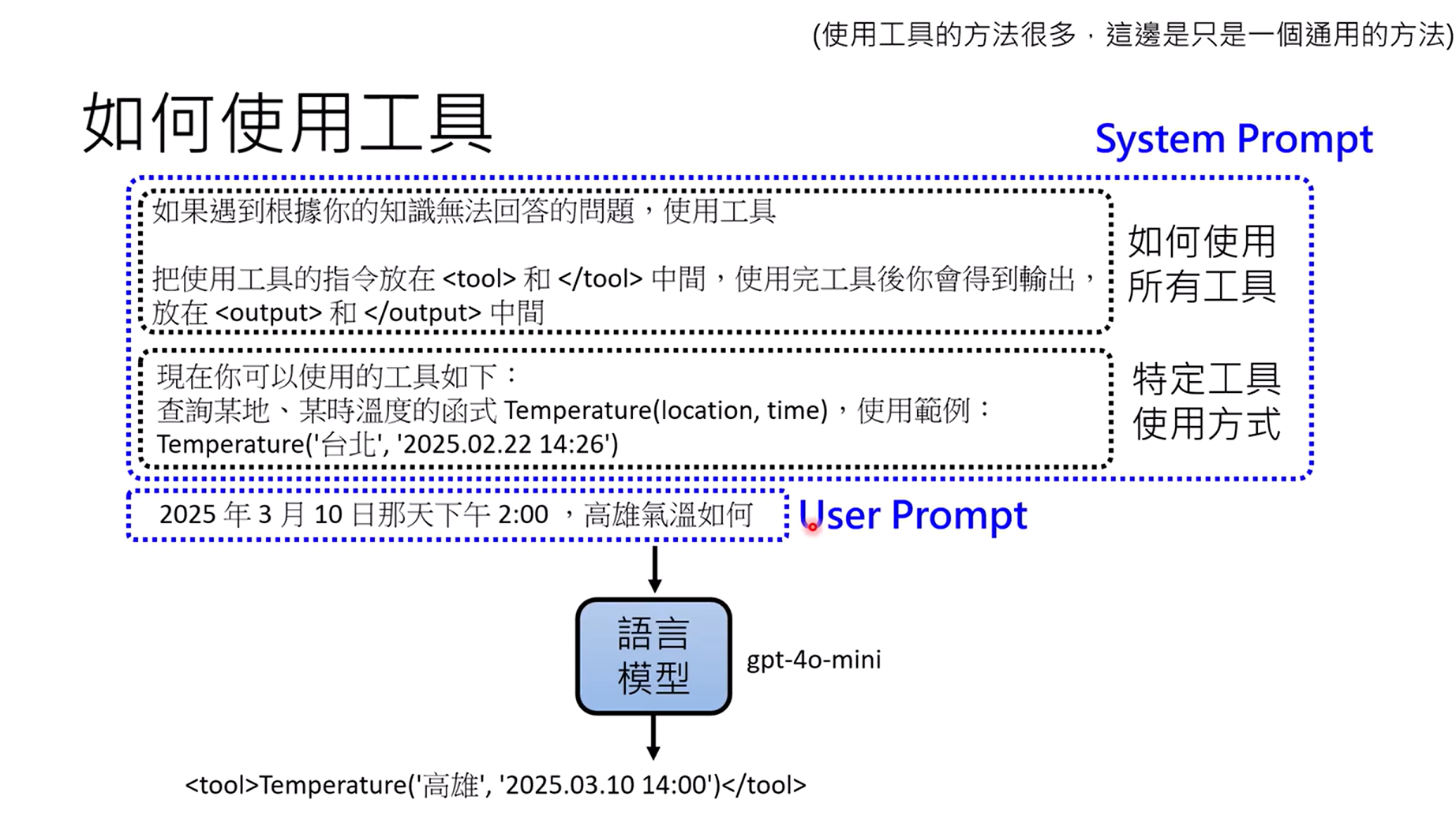
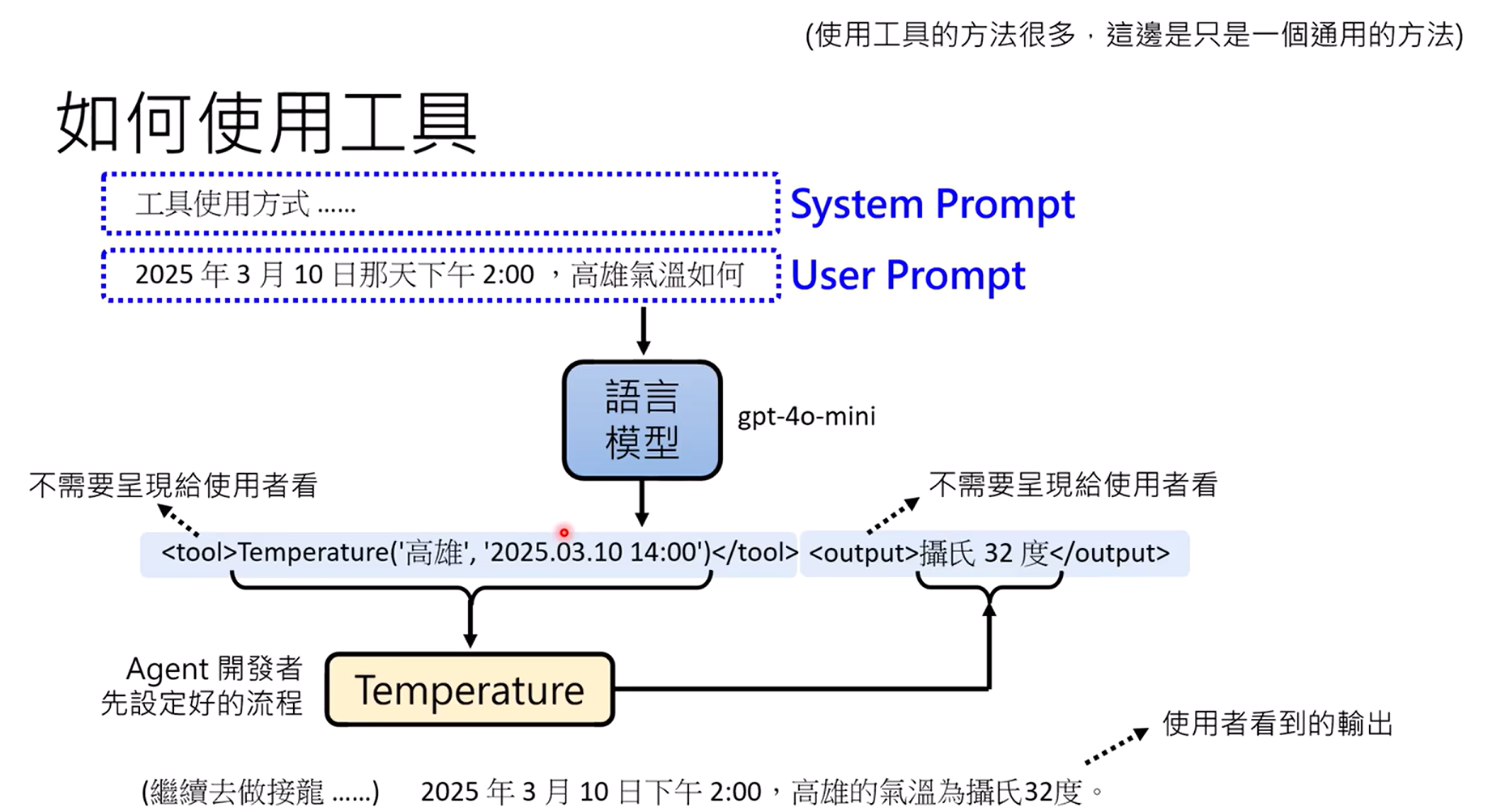
如何使用工具:system prompt和user prompt

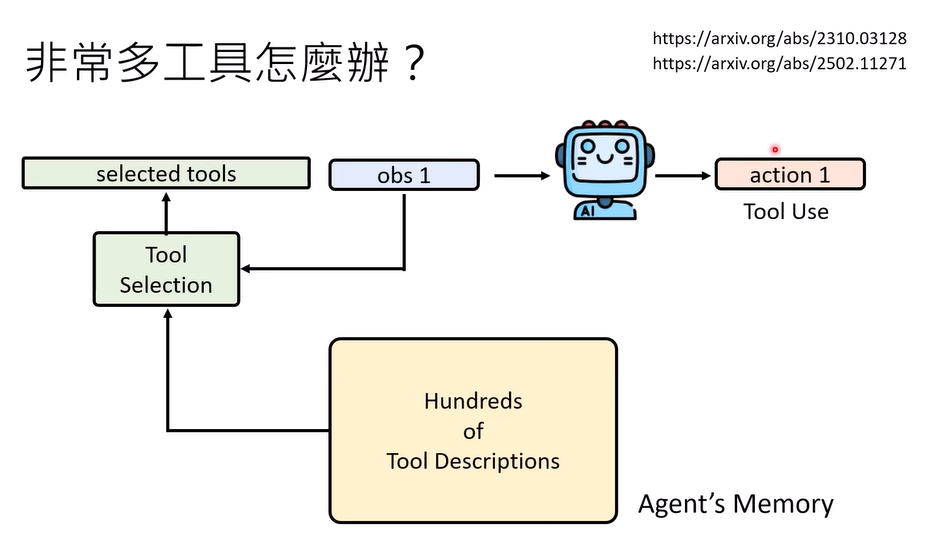
非常多工具怎么办:几百个工具描述,然后选择
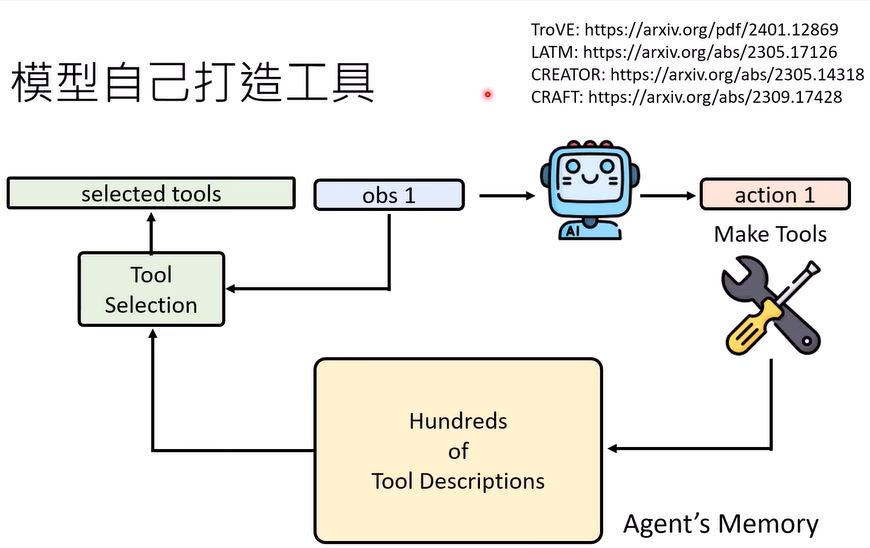
模型打造工具
工具犯错:语言模型有一定的判断力

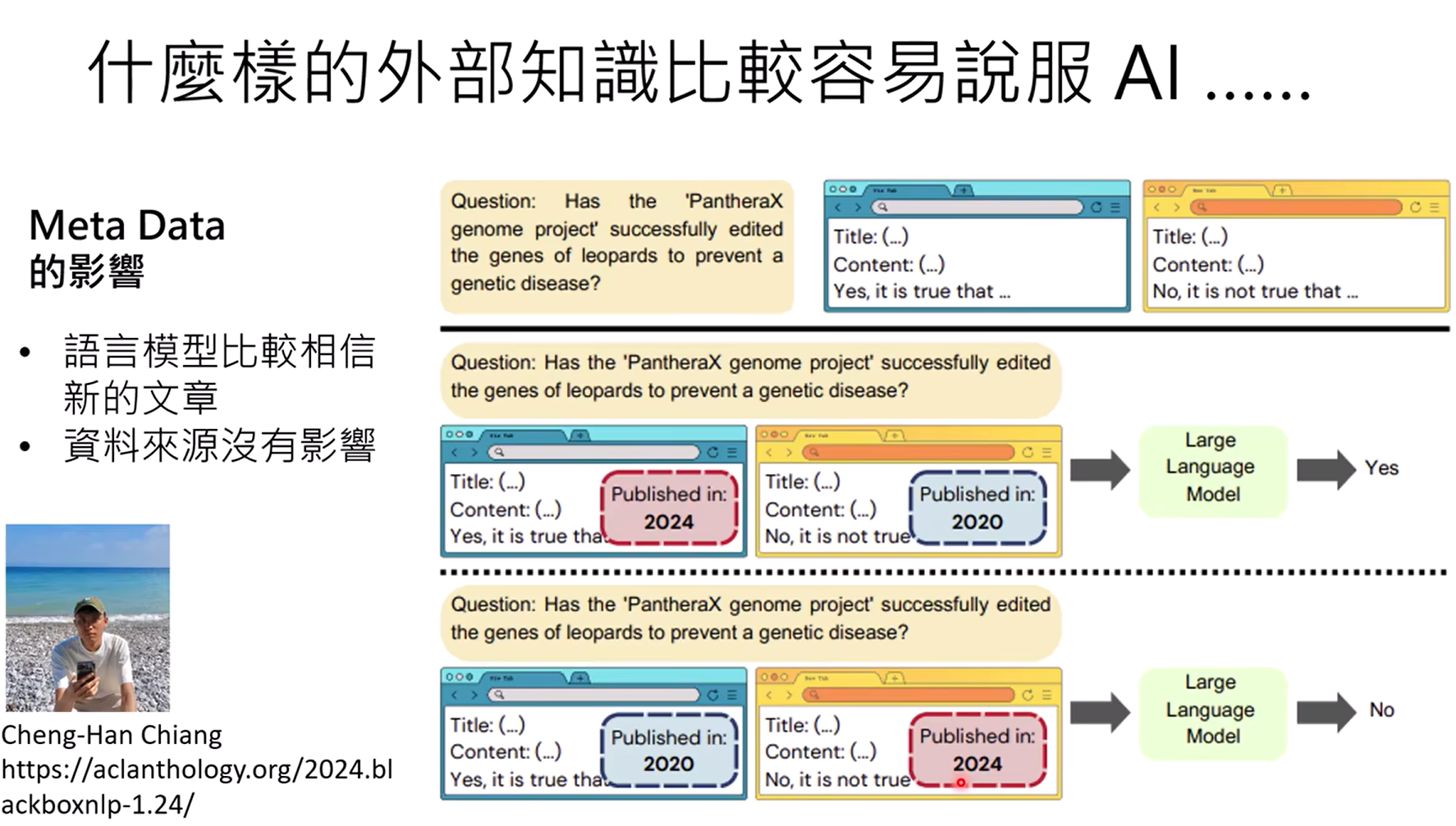
什么样的外部知识比较容易说服AI
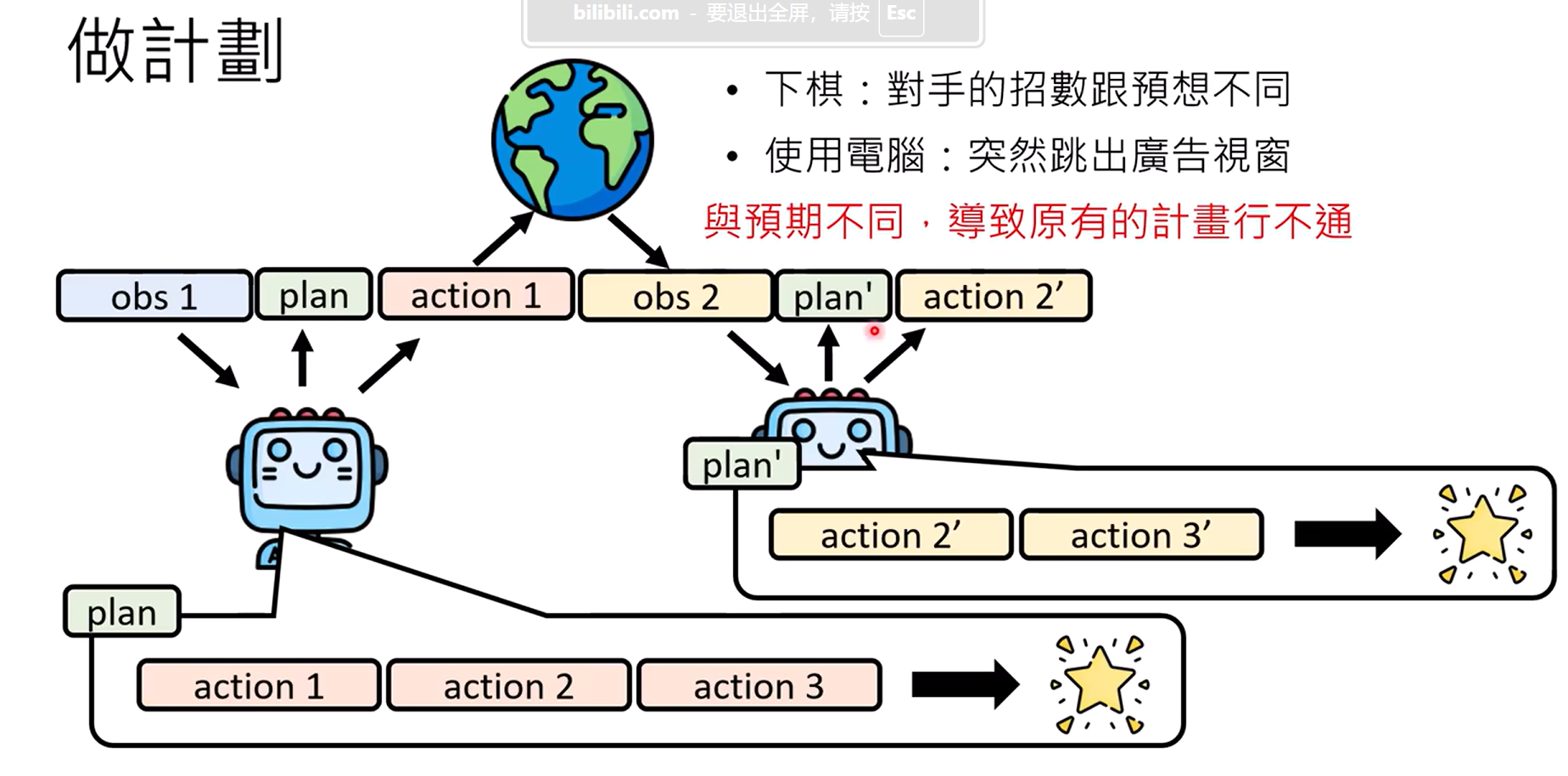
做计划