2025年12月,第39届神经信息处理系统大会(NeurIPS:Annual Conference on Neural Information Processing System)在美国加利福尼亚州圣迭戈顺利召开。NeurIPS是机器学习领域的顶级会议,与ICML、ICLR并称为机器学习领域三大会议。阿里云 PAI 团队与中国科学院大学前沿交叉科学学院等单位合作的研究成果------轻量级动态数据调度方案 Skrull,论文被 NeurIPS2025 会议接收。
长上下文微调(Long-SFT)对提升大模型处理长文本的能力至关重要,但混合长短序列的训练数据给现有系统带来效率瓶颈。Skrull 通过在线平衡长短序列的计算负载,在几乎零调度开销下显著提升 Long-SFT 的训练效率。实测表明,Skrull 相比基线平均提速 3.76 倍,最高达 7.54 倍,为高效长上下文训练提供了实用的系统优化思路 。 
一、研究背景
长文本能力是语言模型的核心能力之一,对诸多下游任务都至关重要。续训练(Continue Pre-Training)和长文本微调(Long Context Fine-Tuning)是扩展大语言模型长文本能力的重要一环。通常情况下,这些训练场景通常会在精心挑选的数据集中进行,在数据长度分布上会有显著的特点,如展现出极度的长尾效应(数据集中短数据占绝大多数,同时存在超长的训练数据)或者是双峰分布的特征(短序列和长序列同时在数据集中占大多数)。这种特殊的数据分布特征给现有的训练系统带来了广泛的性能问题。继 PAI 团队论文【ICML 2025】Chunkflow后,Skrull在上下文并行(Context Parallelism)以及负载均衡的角度继续优化系统训练性能。
二、论文思路
针对这种特殊数据集长度分布的训练数据集,原始的序列并行方案很难达到最优性能。首先,训练数据中长度值差异显著。单一的上下文并行方案在处理这类场景面临困难。长序列需要更大的上下文并行维度以减少显存压力,但会给短序列处理时带来更多的通信代价以及性能劣化。特别地,在长文本微调场景中,训练数据中的短文本通常是占绝大多数的。因此,如何在维持长文本处理能力的同时,高效地处理较短数据成为了提升该场景训练系统性能的关键问题。Skrull论文中提供了一个高效且鲁棒的解决方案。
为了保持长文本处理能力同时提升短文本的训练效率,Skrull在每个iteration动态地将训练数据分为两组(分布式计算的数据组和局部计算的数据组)。分布式计算组如同上下文并行的机制一样,将训练数据切分到不同的GPU上计算,并通过通信传输attention计算所需的Key/Value Cache。局部计算的数据将被完整分配到上下文并行组的某个GPU上,以避免额外的通信和提升计算效率。于此同时,由于两组计算没有依赖性,分布式计算的通信时间可以与局部计算重叠,进一步提升性能。
同时,负载均衡成为提升系统性能的重要环节。局部计算的数据数量和长度同样表现出显著差异。尤其是attention机制中,计算量(FLOPs)与数据长度的二次方增长的趋势与显存占用的一次方增长趋势的差异,使得在追求负载均衡的同时难以对峰值显存做出有效控制,增加了显存溢出的风险。 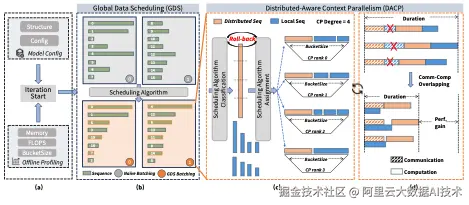
因此,为了拿到最大收益,我们需要规划出最高效的数据分组以及数据分配方案。理论上,我们可以根据性能建模将该问题形式化成优化问题。但是为了实际的效果以及训练时表现的鲁棒性,Skrull系统使用启发式的方案来完成上述数据的分组与分配。我们观察到,尽可能多的将训练数据用作局部计算能减少通信量和提升运算效率,但不恰当的分组也增大了显存溢出的风险。同时,我们需要时刻保持计算的负载均衡。我们可以通过统计每个GPU实际负载(FLOPs)来判断负载均衡情况,从而指导局部计算数据的分配。前两点设计,虽然最大化了性能收益,但都共同增加了显存溢出风险。因此,我们设计了回滚机制来排除这种风险。因为训练显存占用与序列长度的线性关系,我们在确定模型和训练策略的基础上,很容易就可以推算出单个GPU最长可容纳的序列总长度,即为BucketSize。我们将BucketSize作为数据分配的硬约束,当分配序列超出时,我们将会强制回滚操作,保证了训练的稳定性。
我们上述的优化都是在一个微批次中进行。事实上,我们可以在Global batch内就做这种数据调度以获取更大的性能提升空间,同时不影响模型训练的优化轨迹。同理,我们通过排序并间隔取长短序列的方式,使得其在数据并行维度更加负载均衡、并将长短序列均匀分配到不同微批次中。
三、实验数据
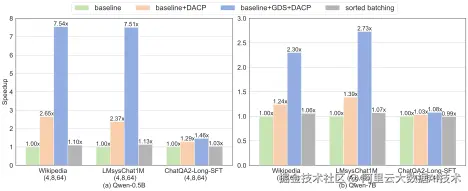
在多种尺寸的Qwen系列模型中验证系统收益。选取了三个数据集,分别代表常见的长尾和双峰分布。(注:前两个数据集不是专用于长文本微调场景但是其数据分布与该场景极为相似)。下图展示了在不同配置下Qwen-0.5B和Qwen-7B相对于DeepSpeed(Zero-2)和简单排序(sorted batching)均取得了显著的加速。
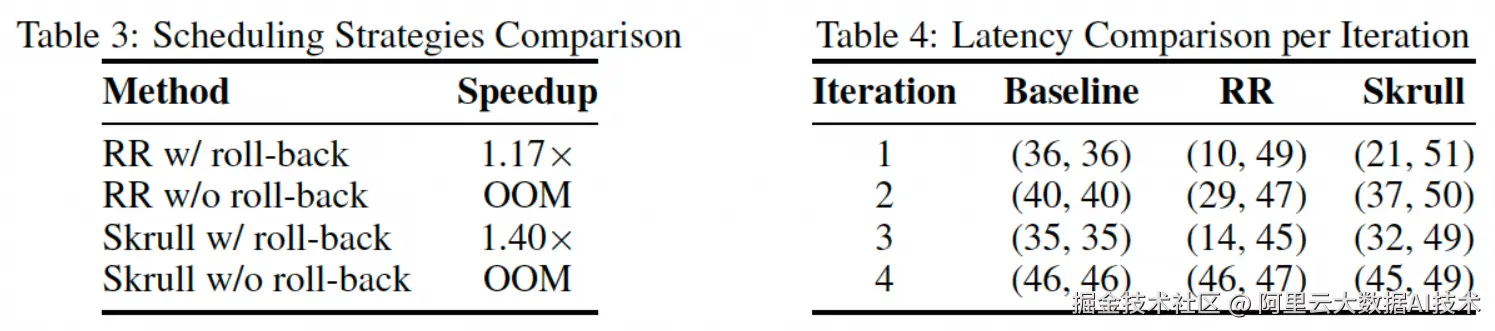
同时,我们测试了不同BatchSize和BucketSize设定对于性能的影响、更大尺寸模型以及高效微调方法Lora的兼容性(如下图所示)。进一步的消融实验和分析(如下表所示)展示出Skrull的启发式策略以及回滚机制对于性能提升的重要性。 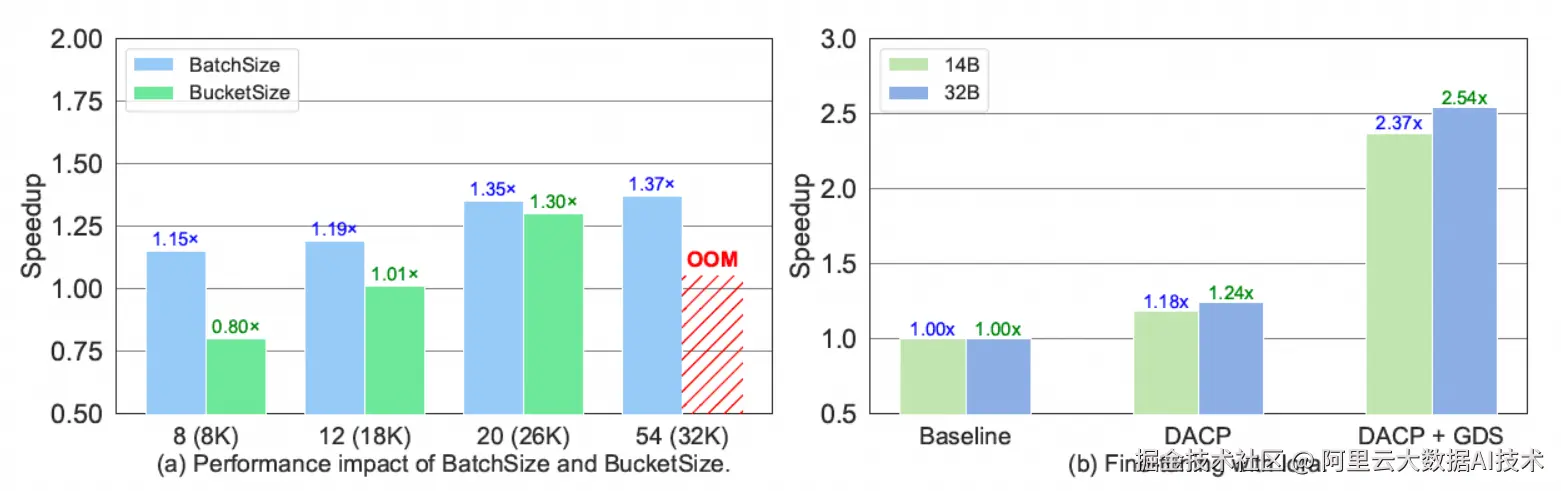
四、更多论文相关信息
论文标题: Skrull: Towards Efficient Long Context Fine-tuning through Dynamic Data Scheduling
论文作者: Hongtao Xu,Wenting Shen,Yuanxin Wei,Ang Wang,Guo Runfan,TianxingWang,Yong Li,Mingzhen Li,Weile Jia
论文链接: arxiv.org/abs/2505.19...