GPT(Generative Pre-Trained Transformer):
-
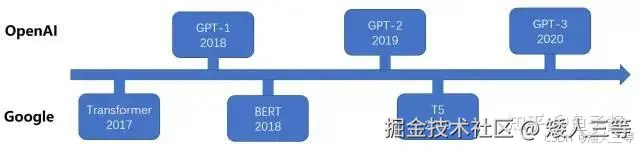
GPT 系列是 OpenAI 的一系列预训练模型,GPT 的目标是通过 Transformer,使用预训练技术得到通用的语言模型(目前已经公布论文的有 GPT-1、GPT-2、GPT-3)
-
核心架构:仅解码器(单向自回归)
-
核心能力:连贯文本生成
-
典型使用场景:对话系统、内容创作、代码补全、故事续写、多轮交互
-
gpt 不同版本的参数对比:
- batch size一般是指sequence的数量,GPT里的batch size是指sequence_num * sequence_length
- GPT-3 开始以 tokens 数进行展现,GPT-2 还是序列数量 512,统一度量的话就是512*1024 = 0.5M tokens
核心架构(gpt1/2Max/3Max) 预训练任务 训练数据 序列长度(token) 优化器 学习率 12 /48/96层解码器 见下方 见下方 512/1024/2048 Adam,β1=0.9,β2=0.999,ε=1e - 8(见下方) 见下方 总参数量 隐藏层维度d_model 注意力头 Feed Forward 维度(d_ff) Dropout 训练轮数(N:None)/批量大小(token) 1.17/15/1750 亿 768/1600/12288 12/25/96 3072/6400/49152(4×d_model) 0.1(嵌入 / 注意力 / 前馈层均用) 100-N-N/64-512-N
1 GPT-1
-
具体参数补充:
-
学习率调度:Warmup + 余弦退火 (Cosine Annealing)
- 初始学习率为 0,训练初期采用线性warmup,逐步从0增加到初始学习率 2.5 × 1 0 的-4 次方(前 2k 步)
- 退火阶段:达到初始学习率后,使用余弦退火 schedule 逐渐降低学习率
- 同 Transformer 一样有线性增加热身的过程,但具体的衰减方式和热身步数不同
- ① 预热阶段:前 k 步,学习率从 0 线性升到预设最大值(比如 1e-4),防止初始梯度爆炸
- ② 衰减阶段:预热结束后,学习率随步数反比例线性下降(lr ∝ 1/√步数),越往后降得越慢
- 同 Transformer 一样有线性增加热身的过程,但具体的衰减方式和热身步数不同
-
L2 正则化:权重 w = 0.01
-
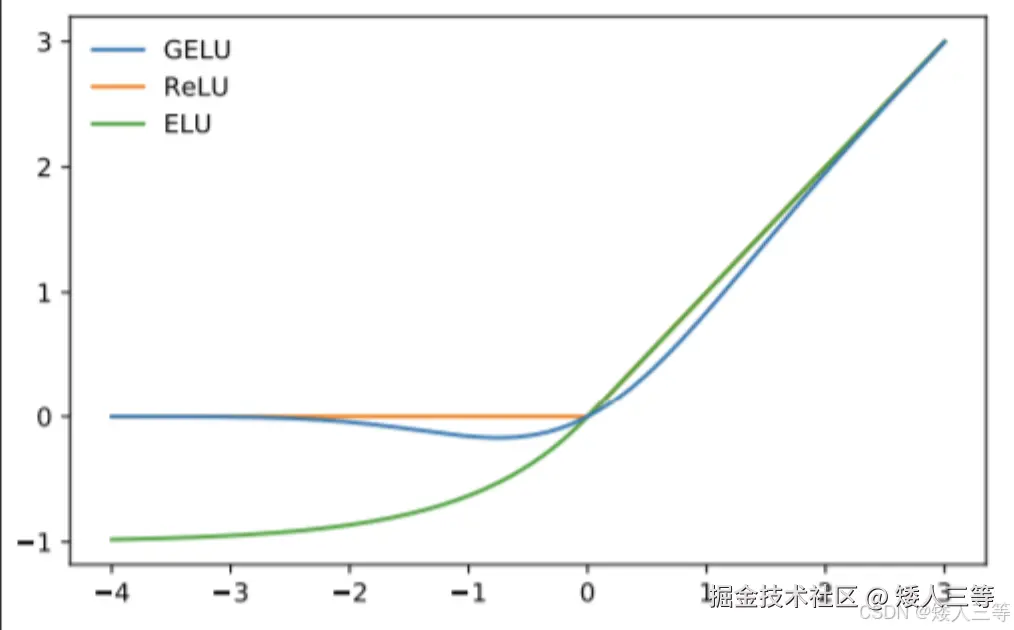
激活函数:GELU(Gaussian Error Linear Unit,「柔和版的 ReLU」,不生硬截断)。
-
ReLU:输入>0 就输出本身,≤0 就输出 0(像一刀切,容易让部分神经元 "躺平")
-
GELU:输入越大,输出越接近本身;输入越小,输出越接近 0,但不是直接切 0,是慢慢趋近 0(像温柔减速,更贴合语言的模糊性规律)
-
-
位置嵌入:采用可学习的位置嵌入矩阵,而非原始 Transformer 中的正弦嵌入(类比 bert)。
-
预训练任务:因果语言建模(CLM),预测下一个 token;下游采用 "预训练 + 监督微调"
-
训练数据:BooksCorpus(7000 本未出版书籍,约 8 亿 token,8GB)
-
-
模型结构:

- 与 transform 结构对比:
- GPT-1 保留了 Decoder 的Masked Multi-Attention 层和 Feed Forward 层(也就是Decoder 部分那个带有掩码矩阵的部分,Bert使用的是 Eecoder 部分)。
- 注:GPT 中采用了 Masked Multi-Head Attention,而 Masked Multi-Head Attention 只利用上文对当前位置的值进行预测,所以 GPT-1 被认为是单向的语言模型。
- 扩大了网络的规模
- GPT-1 保留了 Decoder 的Masked Multi-Attention 层和 Feed Forward 层(也就是Decoder 部分那个带有掩码矩阵的部分,Bert使用的是 Eecoder 部分)。
- 补:Layer Norm(层归一化):指的是 Add&Norm 部分中的 Norm 部分
- 与 transform 结构对比:
-
训练步骤:
- 第一个阶段是利用语言模型进行预训练(无监督形式)
- 自回归语言建模:简单理解就是:顺着前文写后文,依次填词
- 第二阶段通过 Fine-tuning 的模式解决下游任务(监督模式下)
- 第一个阶段是利用语言模型进行预训练(无监督形式)
-
Gpt1使用的是 BooksCorpus 数据集,首先使用 ftfy 库清理原始文本,标准化标点符号和空白字符,然后使用 spaCy 分词器,使用 Byte-Pair Encoding (BPE) 进行子词分解,词汇表大小为 40,000
-
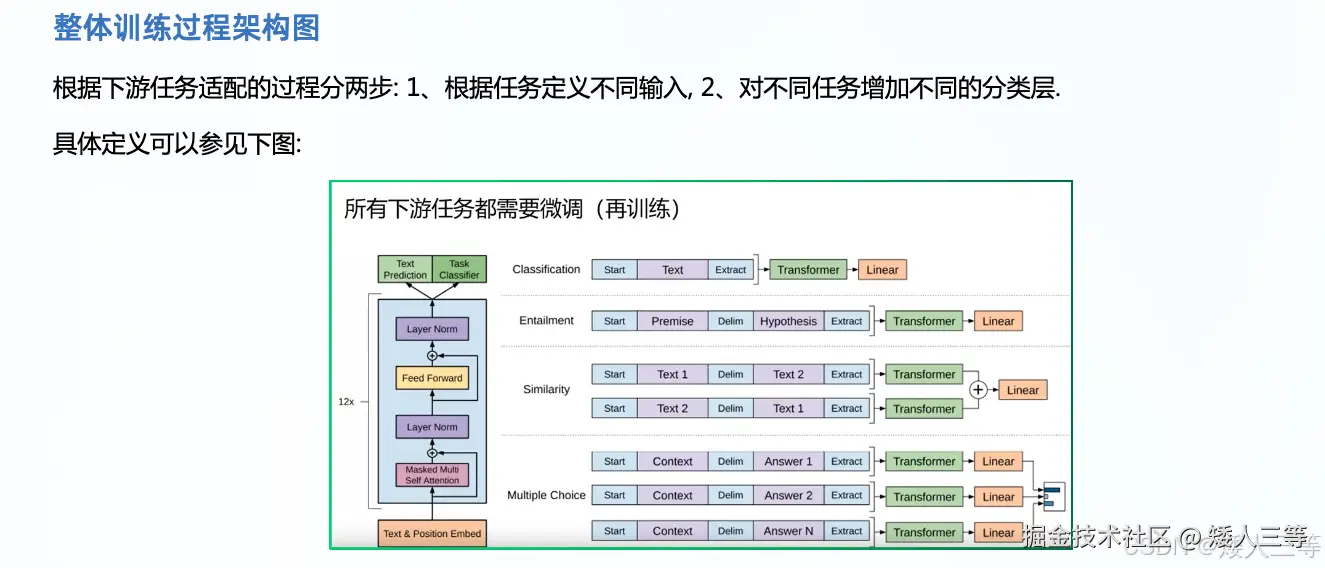
不同下游任务的输入转换(见上图):
-
分类任务。只需要在输入序列前后分别加上开始(Start)和结束(Extract)标记,即 ⟨ s ⟩和⟨ e ⟩
-
句子关系任务。除了开始和结束标记,在两个句子中间还需要加上分隔符(Delim):$用于分隔子序列,例如前提句和假设句,问题和答案。
-
文本相似性任务。与句子关系判断任务相似,不同的是需要生成两个文本表示
-
多项选择任务。文本相似任务的扩展,两个文本扩展为多个文本。
-
注:这些符号在预训练时是不存在的,下游任务需要的时候可以这样使用。
-
在预训练阶段,GPT采用语言模型损失(Language Modeling Loss),即交叉熵损失(Cross Entropy Loss),下方会解释交叉熵损失和最大似然的一些关系
-
-
Zero-shot:模型在预训练的时候,只学习过通用的语言 / 知识,没有专门学习过某个下游任务的标注数据(也就是没做过这个任务的 "练习题"),但直接让模型去完成这个下游任务
-
GPT-1 目标是服务于单序列文本的生成式任务,所以舍弃了关于 Encoder 部分以及包括 Decoder 的 Encoder-Dcoder Attention 层 (也就是 Decoder中 的 Multi-Head Atteion)。
- GPT - 1 的目标是单序列文本的生成式任务,不需要依赖 Encoder 的输出,因此它删除了编码器 - 解码器注意力层,仅保留了掩码多头自注意力层和前馈神经网络层。其中掩码多头自注意力机制能确保模型在预测当前 token 时,只能依赖前文的 token 信息,无法获取后文信息,这和 GPT - 1 自回归的生成方式相匹配。
- 比如预测句子中 "甜" 这个词时,GPT - 1 只能依据前面 "我爱吃" 这样的前文内容来推断。
2 GPT-2(包含多个版本): 优化训练稳定性(Pre - Norm)
-
具体参数补充:
- 学习率调度:初始 6e - 5,余弦退火衰减。(单阶段,无预热)
- 无预热步骤:训练第一步即采用 6e-5 初始学习率
- 核心策略:单次余弦退火衰减
- 操作:学习率随训练步数按余弦公式下降,公式为 lr = 6e-5 × 0.5×(1+cos (π× 当前步数 / 总步数)),最终衰减至 0,训练至损失收敛
- 预训练任务:因果语言建模(CLM),聚焦零样本能力,弱化微调依赖
- 训练数据:WebText(Reddit 高质量链接网页,800 万文档,40GB,约 80 亿 token)
- 学习率调度:初始 6e - 5,余弦退火衰减。(单阶段,无预热)
-
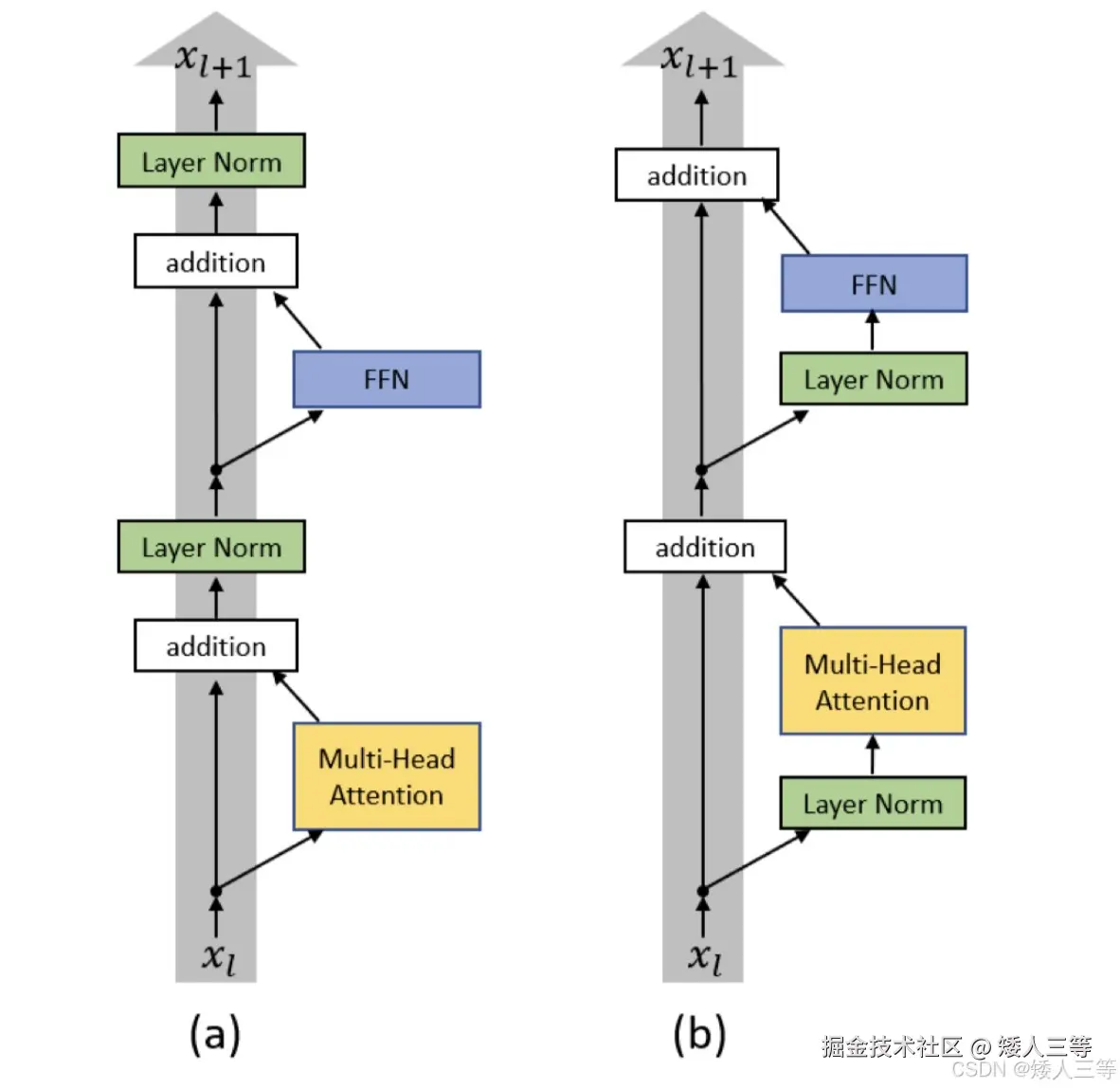
模型改动:加入了两个 Layer normalization(归一化层):
-
一个加在每个 sub-block(比如自注意力和前馈网络)输入的地方
- block:指的是一个功能模块包,比如:在原始 Transformer 的 Decoder Block 里,是有三个这样的打包组合:
- Masked Multi-Head Attention + Add&Norm
- Encoder-Decoder Attention + Add&Norm
- Feed Forward + Add&Norm
- 这三个部分按顺序组合起来,就是一个完整的 Decoder Block
- block:指的是一个功能模块包,比如:在原始 Transformer 的 Decoder Block 里,是有三个这样的打包组合:
-
一个加在最后一个 self-attention block 的后面。
-
gpt1 和 gpt2 的区别更通俗的讲就是:
- GPT-1 :Post-Norm,层归一化放置在残差连接之后。
- GPT-2 :Pre-Norm ,层归一化放置在残差连接之前。
- 考虑到模型深度对残差路径的累积问题,GPT-2 采用了修正的初始化方法。
- 在初始化时将残差层的权重缩放到 1/ √n 倍, n为残差层的数量
- 考虑到模型深度对残差路径的累积问题,GPT-2 采用了修正的初始化方法。
-
-
数据处理:GPT-2 使用了 WebText 数据集进行训练。WebText 的文本来源是 4500 万个经过 Reddit 用户过滤后的网页链接(至少有 3 karma,karma 可以当成点赞),经过去重和清理后,最终包含 800 万篇文档,总计约 40GB 的文本(GPT-1 数据集的大小约为 1GB)。
- 为了避免评估数据的"泄漏",数据集还特意去除了常见的数据来源(比如维基百科)。
- 同时,因为数据集的变化,词汇表从 40,000 扩展到了 50,257。
- 值得一提的是,GPT-2 采用了字节级的 BPE (Byte-level Byte Pair Encoding) 进行分词(GPT-1 使用的是常规的 BPE)。
- vocabulary 的大小扩展到了 50257
-
GPT-2 是 GPT-1 的改进版本,其模型结构和 GPT-1 相比几乎没有什么变化,只是让模型变得更大更宽,并且取消了 Fine-tuning 的步骤。
- 也就是说 GPT-2 采用了一阶段的模型(预训练)代替了二阶段的模型(预训练+微调),并且在语言模型(文本摘要)等相关领取取得了不错的效果。
- 预训练阶段,GPT-2 采用了多任务的方式,不单单只在一个任务上进行学习,而是多个不同的任务是共享主体 Transformer 参数的,这样能进一步的提升模型的泛化能力,因此在即使没有 Fine-turning 的情况下依旧有非常不错的表现。
3 GPT-3(包含多个版本):架构一致,按缩放定律扩大规模
- 具体参数补充:
- 学习率调度:初始 3e - 4,余弦退火衰减((两阶段,无额外分阶段))。
- 阶段 1:预热(Warm-up)
- 基准:按训练 token 量调度,而非步数
- 操作:学习率从 0 线性升温至 3e-4,预热覆盖前 3.75 亿 token,适配超大模型初始化,杜绝梯度爆炸
- 阶段 2:余弦退火衰减
- 起点:3.75 亿 token 预热结束后
- 操作:学习率按余弦曲线平滑下降,最终衰减至 3e-5(初始学习率的 1/10),而非 0,避免后期学习率过低导致收敛停滞
- 阶段 1:预热(Warm-up)
- 预训练任务:因果语言建模(CLM),主打上下文学习(少样本 / 零样本),无需梯度更新适配任务
- 训练数据:混合语料(Common Crawl、WebText、书籍、维基百科等,约 3000 亿 token,经去重筛选)总计570GB
- Common Crawl(过滤后,占60%)
- WebText2(占22%)
- Books1 & Books2(各占8%)
- Wikipedia(占3%)
- GPT-3 的训练数据集来自 Common Crawl、WebText2、Books1、Books2 和 Wikipedia,更细致的数据处理:
- 自动过滤与 Pareto: 用高质量语料训分类器打分,再用 Pareto 分布做概率采样,最后按非等比例权重重新分配训练优先级
- 选高质量的正负样本,训练分类模型,给文本质量打分
- Pareto 分布辅助采样:帕累托分布是 "少数高分文档大概率保留,低分文档小概率保留" 的分布 ------α=9 时,90% 以上的高质量文档会留下,同时保留约 10% 低质量文档,避免语料单一、模型泛化差
- 重新采样:非等比例分配训练权重
- 设定采样权重:按数据集质量定优先级:如 WebText2(22%)、Wikipedia(6%)权重高于 Common Crawl(60%,虽占比高但质量一般)
- 计算训练轮次:3000 亿 token 训练量下,WebText2 约学 2.9 轮,Wikipedia 约 3.4 轮,Common Crawl 仅 0.44 轮
- 模糊去重:用 MinHash+LSH(局部敏感哈希)算法,把文档映射成 "哈希签名",通过签名相似度判断文档相似度,而非逐字比对(效率低)
- 目标:
- 去内部冗余:比如 Common Crawl 里多个网页抄同一篇文章,只留 1 份
- 去跨源冗余:比如 Common Crawl 和 Wikipedia 有重复段落,统一剔除
- 防测试污染:对比测试集,删除 13 - gram 重叠的内容,保证测试结果真实
- GPT - 3 实操步骤(用 Spark 实现高效去重)
- 特征提取:和分类器用一样的 Spark 分词 + HashingTF 特征,保证一致性
- 生成哈希签名:用 Spark 的 MinHashLSH 实现,生成 10 个哈希值(10 hashes),代表文档的 "模糊指纹"
- 相似度匹配:计算文档间哈希签名的相似度,超过阈值(如 0.8)则判定为重复
- 去重执行:保留相似度最高的 1 份文档,删除其余重复 / 高度相似文档,最终 WebText2 等高质量数据集去重后约减少 10% 数据
- 目标:
- 自动过滤与 Pareto: 用高质量语料训分类器打分,再用 Pareto 分布做概率采样,最后按非等比例权重重新分配训练优先级
- 学习率调度:初始 3e - 4,余弦退火衰减((两阶段,无额外分阶段))。
- 改动:
- 交替使用密集(Dense)和局部带状稀疏注意力(Locally Banded Sparse Attention)
- 密集注意力: 相当于你读一本书时,每读一句话,都要和书里所有句子做关联
- 局部带状稀疏注意力:相当于你读一本书时,只重点看当前句子前后几页的内容
- GPT - 3 的 Transformer 解码器层是交替排布这两种注意力的(比如一层密集、一层稀疏,再一层密集、一层稀疏......),不是所有层都用全密集或全稀疏。
- 少样本学习:
- GPT-3 创新在于示例样本的引入,推理时,通过在提示(Prompt)中加入少量样本来"告诉"模型要完成的具体任务,不对模型进行任何参数更新。相较于需要额外微调(fine-tuning)的做法,极大减少了特定任务的数据量需求。
- 具体操作:使用 K 样本作为条件(Conditioning),在推理时,对于评估集中(test set)的每一个测试样本,模型都会:
- 从对应任务的训练集中随机选出 K 个示例样本。
- 将这 K 条示例样本(上下文 + 正确答案)与当前测试样本的上下文拼接在一起,作为模型的输入(Prompt)。让模型根据提示(Prompt)来生成答案。
- 注:对于 GPT-3 来说,Few-shot 方式在特定场景下不及 SOTA(State-of-the-Art)的微调模型。
- 具体任务:论文中提到了两大类常见任务:
- 选择题(Multiple Choice) 和 自由生成(Free-form Completion),它们的核心流程都是"将示例样本与测试样本合并到 Prompt 中"。
- In-Context Learning: 简单来说,就是模型在不更新自身参数的情况下,通过在模型输入中带入新任务的描述与少量的样本,就能让模型"学习"到新任务的特征,并且对新任务中的样本产生不错的预测效果。这种能力可以当做是一种小样本学习能力
- 是 GPT3 的核心能力,核心一句话:推理时不给模型微调(不更新参数),只在 prompt 里加任务示例 / 指令,让模型靠上下文 "临时悟" 任务规则,直接输出结果
- ICL 与微调的区别:
- ICL通过提示(Prompt)完成任务,而微调是通过训练更新参数来适应任务。
- 一个不更新参数,一个更新参数。
- 一个是 eval,一个是 train。
- In-Context Learning (ICL,上下文学习能力)如何体现:
- Zero-Shot Learning(零样本学习):仅通过自然语言(Prompt)描述任务,不提供任何样本。
- One-Shot Learning(单样本学习):除了任务描述外,提供一个样本。
- Few-Shot Learning(小样本学习):除了任务描述外,提供多个样本(按论文的叙述是几十个:"a few dozen examples")。
- 交替使用密集(Dense)和局部带状稀疏注意力(Locally Banded Sparse Attention)
4 补充
4.1 关于最大似然和交叉熵损失函数的区别:
- 最大似然估计(MLE)是一种估计方法:它的公式是用来计算 "什么样的模型参数,能让真实的文本出现的概率最大",是从 "概率" 的角度出发的
- 比如:你手里有一个硬币,扔了 10 次,有 8 次正面、2 次反面,最大似然就是找到这个硬币的 "正面概率" ------ 最符合这 10 次扔硬币结果的那个概率,显然是 80%,这个概率就是最大似然的结果
- 交叉熵损失是一种损失计算的公式:它的公式是用来计算 "模型的预测和真实值的差距",是从 "误差" 的角度出发的:
- 用来计算「模型猜的概率」和「真实情况」之间的差距的,比如模型猜这个硬币的正面概率是 70%,和真实的 80% 有差距,交叉熵就会给出一个数值来表示这个差距;如果模型猜的是 80%,交叉熵的数值就会很小
- 对于 GPT 的单步生成,真实的词是y,模型预测的词的概率分布是P(y|x)(x 是前文)
- 最大似然估计的目标,是找到模型参数,让P(y|x)的数值尽可能大(让真实词出现的概率最大)
- 而在这个任务里,交叉熵损失的公式,刚好就等于 -log(P(y|x))(负的真实词概率的对数)
- 那要让P(y|x)最大,就等价于让 -log(P(y|x))最小,而-log(P(y|x))就是这个任务里的交叉熵损失
- 在端到端的 AI 模型里,只要是用交叉熵损失做训练的分类 / 生成任务,本质上都是在做最大似然估计,因为两者在这些任务里是数学等价的,只是我们的说法不同:
- 我们会说 "用交叉熵损失训练模型",这是从 "损失计算、梯度下降" 的工程角度来说的
- 我们会说 "这个模型的训练是基于最大似然估计",这是从 "统计目标" 的理论角度来说的
- 注:交叉熵的核心公式(思想)是固定的,只是在不同的任务里,因为真实概率分布 P 的形式不一样,所以计算的时候会做简化,看起来像是不一样的公式,但本质都是在计算真实分布和预测分布的差距
4.2 其他
-
NLP预训练方式:一种是完形填空的方式(BERT),一种是上下文方式(GPT)。
- 用相关专业名词解释,分别为自编码(Autoencoder,简称AE)和自回归(Autoregressive,简称AR)语言建模,并以此与上面所说的Transformer架构联系起来,Transformer encoder是一个AE模型,Transformer decoder则是一个AR模型。
-
实际训练过程中用到的一些技术补充:
-
稳健训练方面:
-
线性预热(有封装)
- 训练刚开始,学习率从 0 慢慢、线性地升到预设最大值(比如 GPT3 从 0 升到 3e-4),预热完再正常衰减
- 预热步数(warmup_steps):比如 GPT1 是 2000 步,GPT3 是按 3.75 亿 token 换算成步数
- 目标学习率(lr₀):预热结束后要达到的学习率,比如 GPT1 是 2.5e-4
- 每一步的 lr = lr₀ × (当前预热步数 / 总预热步数)
- 训练刚开始,学习率从 0 慢慢、线性地升到预设最大值(比如 GPT3 从 0 升到 3e-4),预热完再正常衰减
-
梯度裁剪:防止梯度爆炸(有封装)
- 设定一个梯度最大阈值(比如 GPT3 设 L2 范数 1.0),每次计算完梯度,先判断:如果梯度的总范数超过阈值,就按比例把梯度 "缩小" 到阈值内,再用裁剪后的梯度更新参数
- 计算当前梯度的全局 L2 范数(norm)
- 若 norm ≤ 阈值:不裁剪,梯度原样用
- 若 norm > 阈值:按「阈值 /norm」的比例缩小所有梯度
- 设定一个梯度最大阈值(比如 GPT3 设 L2 范数 1.0),每次计算完梯度,先判断:如果梯度的总范数超过阈值,就按比例把梯度 "缩小" 到阈值内,再用裁剪后的梯度更新参数
-
权重衰减(Weight Decay 稳健)
- 通俗理解:给模型参数 "减重",防止参数太大导致过拟合
- 操作:更新参数时,给参数乘一个小于 1 的系数(比如 GPT3 用 0.1),让参数慢慢变小,避免冗余
- 注意:不是正则化,但效果类似,GPT3 专门用它防过拟合,GPT1/2 没用到(规模小不需要)
-
残差连接 + 层归一化(Residual Connection + Layer Norm 稳健)
- 见上方
-
-
优化训练效果类(让模型学得更好)
- 余弦退火
- 让学习率像余弦函数曲线一样,从高到低平滑下降,不是陡降
- 具体操作(有封装):
- 用余弦函数计算每一步的学习率系数,再乘初始学习率,得到当前步实际学习率
- 当前步学习率 = lr₀(初始学习率) × 系数
- 系数 = 0.5 × 1 + cos ( π × t / T)
- T 是总步数,t 是当前步数
- 学习率重启(Cosine Annealing with Restarts)
- 是余弦退火的升级版:退火到一定程度后,把学习率回升一点,再继续退火,像 "温火慢炖",让模型在局部最优解里再找找更好的解
- 注意:GPT1/2/3 没用,但后续大模型(比如 LLaMA)常用
- 标签平滑(Label Smoothing)
- 通俗理解:不让模型 "绝对自信",更稳健
- 操作:语言模型是预测下一个 token,原本标签是 "1(正确 token)" 和 "0(错误 token)",标签平滑后,正确 token 标 0.9,错误 token 标 0.1 / 总错误数,让模型不把答案学死,泛化更强
- 余弦退火
-
防止过拟合,优化泛化能力的方法:
- Dropout
- 训练时随机让一部分神经元 "休息"(输出置 0),防止神经元过度依赖彼此,避免死记硬背
- 注意:推理时不用 Dropout,所有神经元都工作
- 数据增强(Data Augmentation)
- 通俗理解:给训练数据 "加花样",让模型见得多,学得活
- 适配语言模型:比如随机替换同义词、随机删除无关词、句子顺序微调,不用新增数据,就能扩充训练样本
- 早停(Early Stopping)
- 通俗理解:见好就收,防止训练太久过拟合
- 操作:训练时当验证集损失连续多轮不下降反而上升,就提前停止训练,不用训到预设轮数
- Dropout
-
提效率类(提升训练速度 / 省算力,和批量累积 / 混合精度对应)
- 模型并行 + 数据并行(Model Parallel + Data Parallel)
- 核心解决:大模型(比如 GPT3 1750 亿参数)单张显卡装不下、算不动
- 数据并行:把数据拆成多份,多张显卡各算一份数据的梯度,最后汇总更新参数(提速)
- 模型并行:把模型拆成多部分(比如把 Transformer 层拆成几段),多张显卡各装一部分,协同计算(装下大模型)
- 关键:GPT3 就是靠这两种并行结合,才能训练 1750 亿参数
- 梯度检查点(Gradient Checkpointing)
- 通俗理解:"以时间换空间",省显存优先
- 操作:训练时不保存所有中间层结果(占显存),反向传播时再重新计算需要的中间层,牺牲一点时间,换更多显存装模型
- 适用:超大模型必备,比如 GPT3 训练时大量用它省显存
- 批量累积(Gradient Accumulation):在硬件受限时,通过多次前向传播和反向传播累积梯度
- 核心目的:解决「算力不够」------ 想要大批次(批次越大训练越稳),但显卡显存装不下大批次数据
- 操作:把 1 个大批次拆成多个小批次,逐个算小批次的梯度,不着急更新参数,先把梯度累加起来;等小批次都算完(梯度累积够 1 个大批次),再用累加的梯度更新 1 次参数
- 通俗类比:想搬 100 块砖(大批次),一次搬不动,分 5 次搬 20 块(小批次),凑够 100 块再统一堆好
- 混合精度训练:使用FP16和FP32混合精度以加速训练(有封装)
- 核心目的:提效率、省显存,让大模型能在有限算力下训练
- 模型训练默认用 32 位浮点数(FP32),精度高但占显存、计算慢;16 位浮点数(FP16)占显存少、计算快,但精度低,容易训练不稳定
- 操作:训练时大部分计算用 FP16(省显存提速),关键部分(比如梯度更新、参数保存)用 FP32(保精度稳训练),两者结合,兼顾效率和稳定性
- 模型并行 + 数据并行(Model Parallel + Data Parallel)
-
4.3 参考资料