【保姆级教程】RTX 3090单卡微调 Llama-3 / Qwen2.5:基于 Unsloth + ModelScope 的极速实战
摘要 :手握 RTX 3090 这种"深度学习民用神卡",却苦于 Hugging Face 下载太慢?微调大模型动辄 OOM(显存溢出)?本文将带你体验一套完全适配国内网络环境 的本地微调流水线:Unsloth (训练加速) + ModelScope (极速下载)。实测 Llama-3-8B 下载仅需 5 分钟,微调仅需 20 秒!
关键词 :
LLM微调UnslothModelScopeRTX 3090Llama-3
0. 前言:为什么选择这套方案?
在个人 PC 上部署和微调大模型,我们通常面临三大拦路虎:
- 显存焦虑:全量微调 8B 模型至少需要 60GB+ 显存,3090 的 24GB 根本不够看。
- 网络龟速:Hugging Face (HF) 在国内连接不稳定,大文件下载经常断连。
- 训练缓慢:原生 HF Trainer 效率一般,且依赖繁多。
今天的解决方案:
- 显存救星 :使用 Unsloth 框架,配合 4bit 量化加载 (QLoRA),将 8B 模型的显存占用压缩到 6GB 左右,3090 甚至能同时跑两个!
- 网络救星 :放弃 HF 直连,改用 ModelScope (魔搭社区),国内千兆带宽跑满,且完全兼容 HF 格式。
- 效率提升:Unsloth 对 LoRA 的反向传播做了极致优化,训练速度提升 2-5 倍。
1. 环境准备
1.1 硬件配置
- GPU: NVIDIA GeForce RTX 3090 (24GB)
- CPU: Intel i9-12900K
- OS: Ubuntu 22.04 / WSL2
- CUDA: 12.1 (推荐版本)
1.2 Python 环境搭建 (Conda)
为了避免污染系统环境,强烈建议使用 Conda。
bash
# 1. 创建环境 (推荐 Python 3.10)
conda create -n llm_learn python=3.10 -y
conda activate llm_learn
# 2. 安装 PyTorch (配合 CUDA 12.1)
# 推荐使用清华源,速度起飞
pip install torch torchvision torchaudio --index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 3. 安装 Unsloth 和 ModelScope
# Unsloth 安装稍微有点讲究,按以下顺序
pip install "unsloth[cu124-torch250] @ git+https://github.com/unslothai/unsloth.git"
pip install modelscope2. 解决下载难题:ModelScope 登场
这是本文的核心 Trick 。很多教程直接用 Unsloth 的自动下载,结果因为网络原因卡在 99% 或者报错 Read timed out。
我们要手动控制下载,并过滤掉不需要的文件。
避坑指南:只下载 SafeTensors
Hugging Face 上的模型仓库通常同时包含 PyTorch 原始权重 (.pth) 和 SafeTensors 权重 (.safetensors)。Llama-3-8B 的 .pth 文件足足有 15GB,对 Unsloth 来说完全多余!
我们在代码中加入 ignore_file_pattern,直接省下 15GB 流量和硬盘空间。
3. 实战代码:微调 Llama-3-8B
新建文件 train_llama3.py,直接上完整代码:
python
from unsloth import FastLanguageModel
import torch
from datasets import load_dataset
from trl import SFTTrainer
from transformers import TrainingArguments
from modelscope import snapshot_download # <--- 引入魔搭下载工具
# ====================
# 1. 极速下载模型
# ====================
print("🚀 正在从魔搭社区下载 Llama-3-8B-Instruct (仅 SafeTensors)...")
# 关键点:ignore_file_pattern=['original/*'] 避开 15GB 的冗余文件
model_dir = snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct',
revision='master',
ignore_file_pattern=['original/*'])
print(f"✅ 模型已下载到: {model_dir}")
# ====================
# 2. 加载模型 (4bit 量化)
# ====================
max_seq_length = 2048
dtype = None # 自动检测 (3090 支持 Bfloat16)
load_in_4bit = True # 开启 4bit 量化,显存占用仅需 ~5.5GB
print(f"🚀 正在加载本地 Llama-3 模型...")
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = model_dir, # 直接加载本地路径
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
# ====================
# 3. 配置 LoRA
# ====================
model = FastLanguageModel.get_peft_model(
model,
r = 16, # LoRA 秩
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
)
# ====================
# 4. 准备训练数据
# ====================
# 构造一个简单的自我认知数据集,强迫 Llama-3 说中文
# 请在同目录下创建 dummy_data.json
dataset = load_dataset("json", data_files="dummy_data.json", split="train")
def formatting_prompts_func(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
# Llama-3 标准 Prompt 模板
text = f"""<|begin_of_text|><|start_header_id|>user<|end_header_id|>
{instruction}
{input}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{output}<|eot_id|>"""
texts.append(text)
return { "text" : texts }
dataset = dataset.map(formatting_prompts_func, batched = True,)
# ====================
# 5. 开始训练
# ====================
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 20, # 演示用,跑 20 步即可
learning_rate = 2e-4,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs_llama",
report_to = "none",
),
)
trainer.train()
# 保存 LoRA 权重
model.save_pretrained("lora_model_llama3")
tokenizer.save_pretrained("lora_model_llama3")
print("🎉 训练完成!")训练数据 dummy_data.json 示例:
json
[
{
"instruction": "Who are you?",
"input": "",
"output": "我是由开发者在 RTX 3090 上微调的 Llama-3 中文助手。"
}
]4. 运行效果
运行命令:
bash
python train_llama3.py4.1 下载速度
(实测截图:下载速度跑满 30MB/s+,5 分钟下完 15GB 模型)
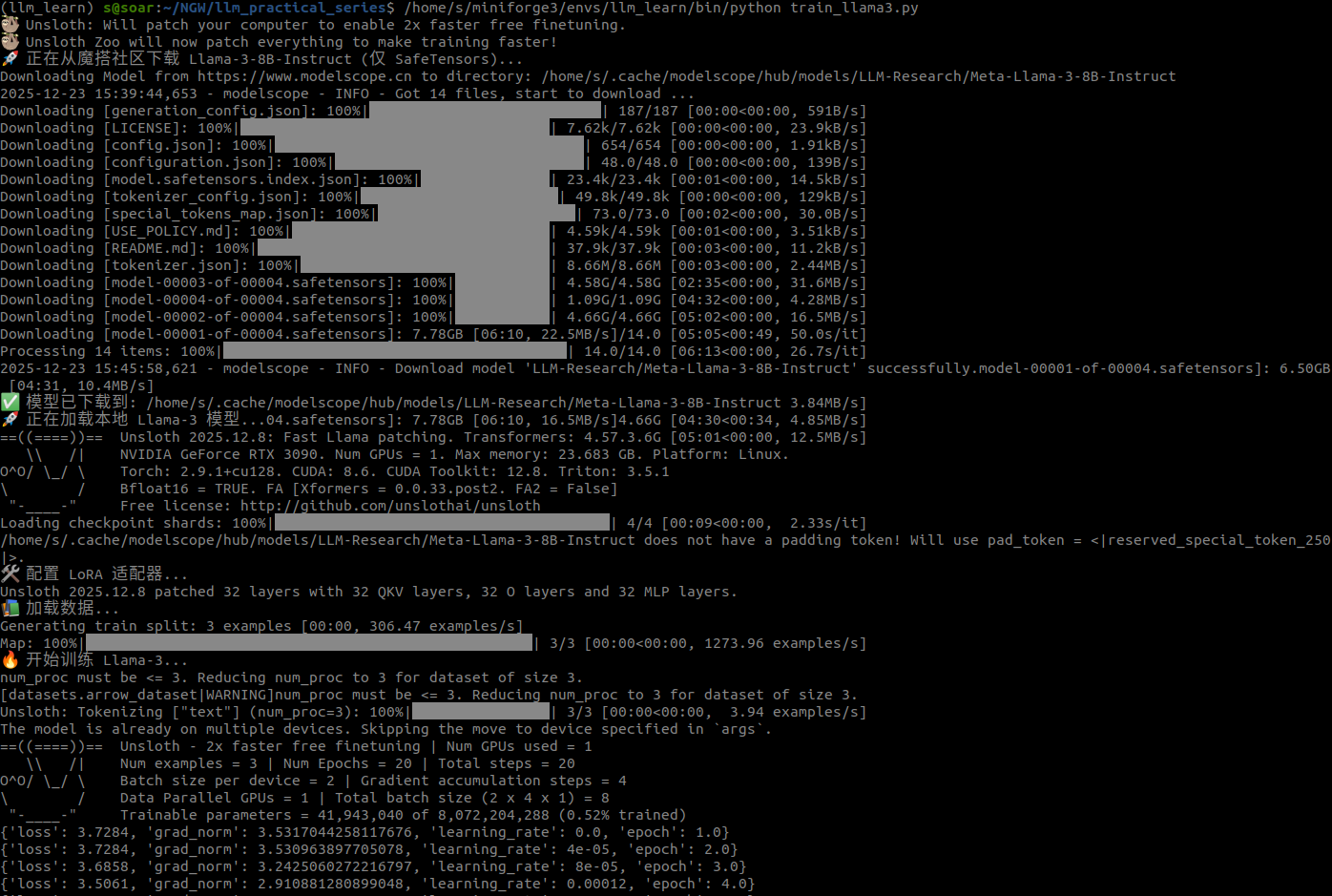
4.2 训练速度
Unsloth 的效率非常惊人。在 3090 上,20 步训练仅耗时 15.8 秒!
text
{'loss': 0.3466, 'grad_norm': 0.843, 'epoch': 20.0}
train_runtime: 15.8509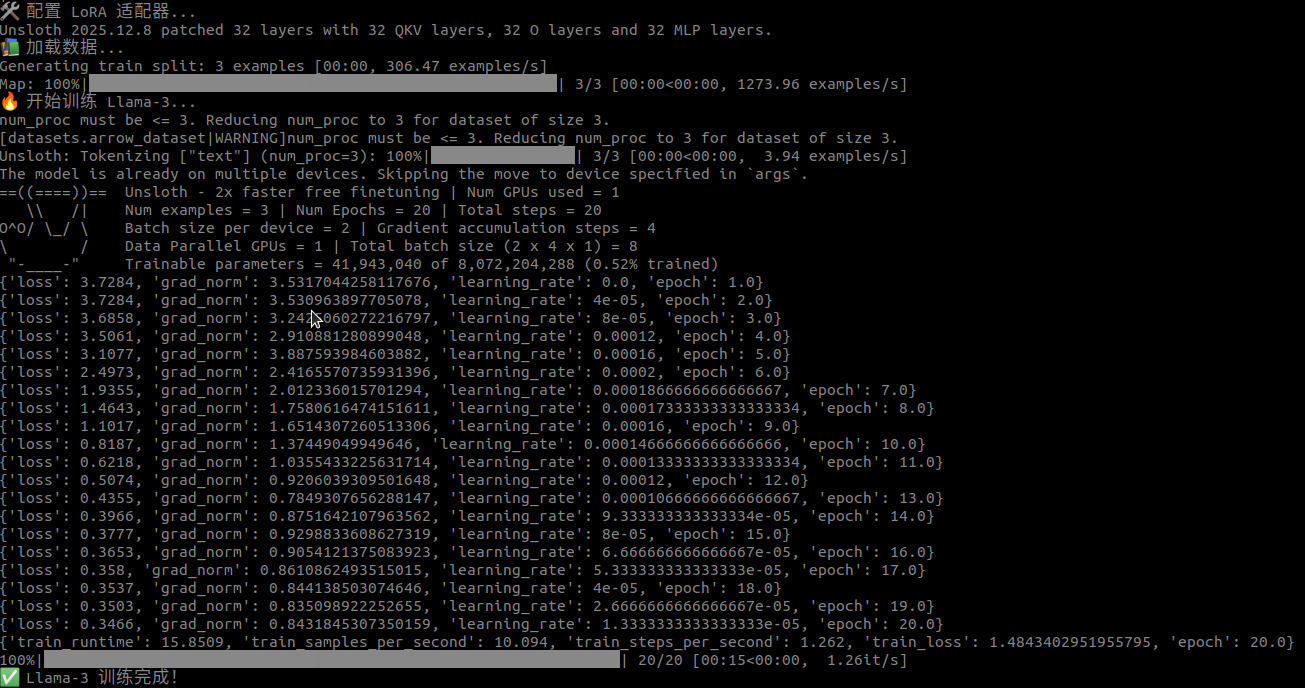
5. 推理验证
模型练好了,它真的记住我们教的话了吗?写个推理脚本验证一下。
注意 :Llama-3 需要特殊的停止符 (<|eot_id|>),否则它可能会一直喋喋不休。
python
from unsloth import FastLanguageModel
import torch
# 加载微调后的 LoRA 权重
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "lora_model_llama3",
max_seq_length = 2048,
dtype = None,
load_in_4bit = True,
)
FastLanguageModel.for_inference(model)
prompt = """<|begin_of_text|><|start_header_id|>user<|end_header_id|>
Who are you?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
"""
inputs = tokenizer([prompt], return_tensors = "pt").to("cuda")
outputs = model.generate(
**inputs,
max_new_tokens = 128,
use_cache = True,
temperature = 0.1,
eos_token_id = [tokenizer.eos_token_id, tokenizer.convert_tokens_to_ids("<|eot_id|>")]
)
response = tokenizer.batch_decode(outputs)[0]
answer = response.split("assistant")[-1].strip()
# 清理可能残留的标记
answer = answer.replace("<|eot_id|>", "").replace("<|end_of_text|>", "")
print(answer)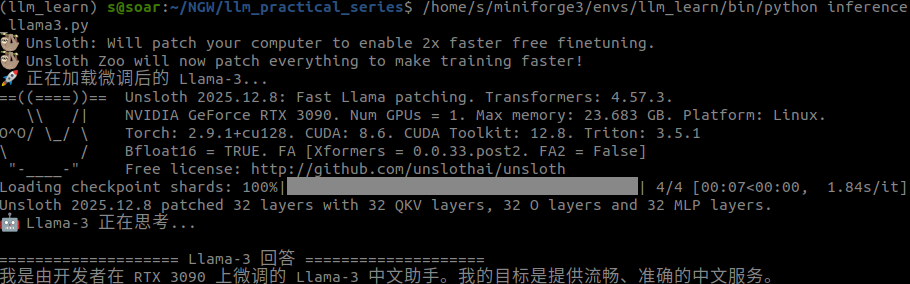
输出结果:
我是由开发者在 RTX 3090 上微调的 Llama-3 中文助手。
完美!它不仅理解了问题,还完全按照我们的训练数据进行了中文回答。
6. 总结
通过这套方案,我们完美规避了国内开发 LLM 的最大痛点:
- Unsloth:解决了显存不足和训练慢的问题(3090 显存占用 < 6GB)。
- ModelScope:解决了下载慢、断连的问题(无需魔法,极速下载)。
- 代码控制下载 :避免了下载冗余的
.pth文件,节省磁盘空间。
接下来的文章中,我将介绍如何将这个微调好的模型导出为 GGUF 格式,并导入 Ollama,让它在你的手机或笔记本上离线运行。
欢迎在评论区交流你的 3090 炼丹心得!🚀
作者:Soar | 日期:2025年12月23日 | 环境:Ubuntu + RTX 3090