AI 应用上线后的第一天,往往不是"用户夸它聪明",而是告警把你叫醒:延迟突然飙升、工具调用失败率上升、某个模型版本输出不稳定、成本曲线像心电图一样抖动、敏感信息被错误地带出到回复里。传统互联网系统的 SRE 关注"服务可用性",而 AI 应用的 SRE 还要额外面对"生成的不确定性"和"推理资源的昂贵性"。因此,想把 AI 做成长期可运营的产品,你需要一套从架构到指标、从发布到回滚、从安全到调优的闭环体系。
本文用 SRE 视角把这些关键概念连成一条线: Vibe Coding 如何在 IDE 里缩短迭代反馈; AI 模型 如何通过 模型部署 实现可预测的性能与成本; MCP 如何把工具接入变成可治理的能力层; 智能体 如何被 工作流 约束并可观测; Mass 平台 如何承载发布、评测、监控、配额、安全;最后把 AIGC 产出与 调优 飞轮、 应用 与 API 设计统一到一套可持续运行的系统里。
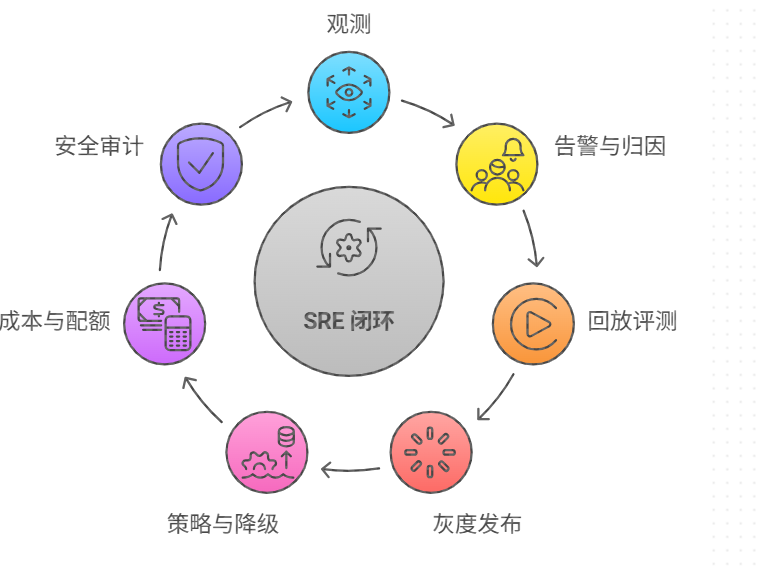
一、SRE 目标重新定义:AI 应用的"好"不只是一句答得漂亮
对 AI 应用来说,SRE 的核心不是"永不宕机",而是"在可控风险与可控成本下持续交付业务价值"。这会把目标从单一的可用性,扩展成四个同等重要的维度:
1.延迟(Latency):用户等待时间、端到端链路耗时、尾延迟(P95/P99)
2.可靠性(Reliability):成功率、正确率代理指标、工具调用成功率、可回放一致性
3.成本(Cost):每次请求 token、GPU 时长、检索与工具调用成本、单位业务产出成本
4.安全(Security):权限与审计、脱敏与合规、越权拦截、数据边界与供应链风险
这四个维度彼此制衡:更强模型可能更贵、更慢;更严格校验可能更慢但更安全;更激进缓存可能更快但有一致性风险。SRE 的职责是把权衡显性化:用指标、预算、分级策略把这些冲突纳入治理。
二、用"AI 版 SLO"把不确定性变成可管理的工程约束
传统 SRE 常用 SLI/SLO(指标/目标)与错误预算来治理发布节奏。AI 应用也需要 SLO,只是指标要更贴近 AI 形态。
延迟类 SLI (建议至少三条)
- E2E latency P95/P99 :从 API 收到请求到最终回复完成
- Model latency P95 :纯推理耗时(含排队/批处理)
- Tool-call latency P95 :工具调用耗时(数据库、内部 API、第三方 API)
- 可靠性类 SLITask success rate :任务型 API 的成功完成率
- Tool-call success rate :工具调用成功率、重试后成功率
- Schema validity rate :结构化输出(JSON/表格)通过校验的比例
- Grounded rate :回复中引用证据的比例(或无证据时的拒答比例)
- 成本类 SLITokens per request :输入/输出 token
- GPU-seconds per request :推理资源消耗
- Cost per successful task :单位成功任务成本(比"每请求成本"更贴业务)
- 安全类 SLIPII leak rate :敏感信息外泄检测命中率(应趋近 0)
- Unauthorized tool attempts :越权工具调用尝试次数
- Audit completeness :审计链路完整率(是否能回放每一步证据与调用)
有了这些指标,SLO 才能落地为策略:例如 P99 延迟超过阈值就触发降级;工具调用失败率上升就切换备用工具或只读模式;成本接近预算就启用更小模型或缩短上下文。
三、模型部署:把"推理不稳定"变成"可预测资源与性能"
模型部署 是 AI SRE 的地基。你需要把推理从"能跑"升级为"像服务一样可运营"。关键点包括:
1.并发与队列:用"排队可控"换"系统不崩" 高峰期请求会突增,推理资源(尤其 GPU)又无法像 CPU 服务那样线性扩容。正确做法通常是:
- 将推理服务前置队列与限流:宁可排队或返回"稍后重试",也不要把 GPU 打满导致全体超时
- 对不同业务优先级做配额:重要请求优先,低价值请求降级
- 对可批处理的请求做批推理:以吞吐换成本
2.缓存与复用:把重复消耗打掉 AI 的大量成本来自"重复上下文"。常见可缓存点:系统提示词与固定背景的 token 复用
- 检索结果缓存(短 TTL,带版本号)
- 工具查询结果缓存(按权限域隔离)
- 对高频问答走 AIGC 内容缓存(同时加失效策略)
3.多模型分层:让最贵的模型只做最值钱的事 你可以把模型按职责拆开:小模型:路由、分类、意图识别、风险检测
- 中模型:结构化抽取、字段填充、模板化生成
- 大模型:复杂推理、跨域综合、生成最终自然语言表达
4.降级与回退:在失败时给出"受控的差"推理超时:返回部分结果或转为异步任务
- 大模型不可用:切到中模型 + 更强约束模板
- 检索失败:拒答并提示补充信息,而不是编造
这些机制的共同目标是:把尾延迟、成本尖峰、偶发错误从"事故"变成"策略下的可接受行为"。
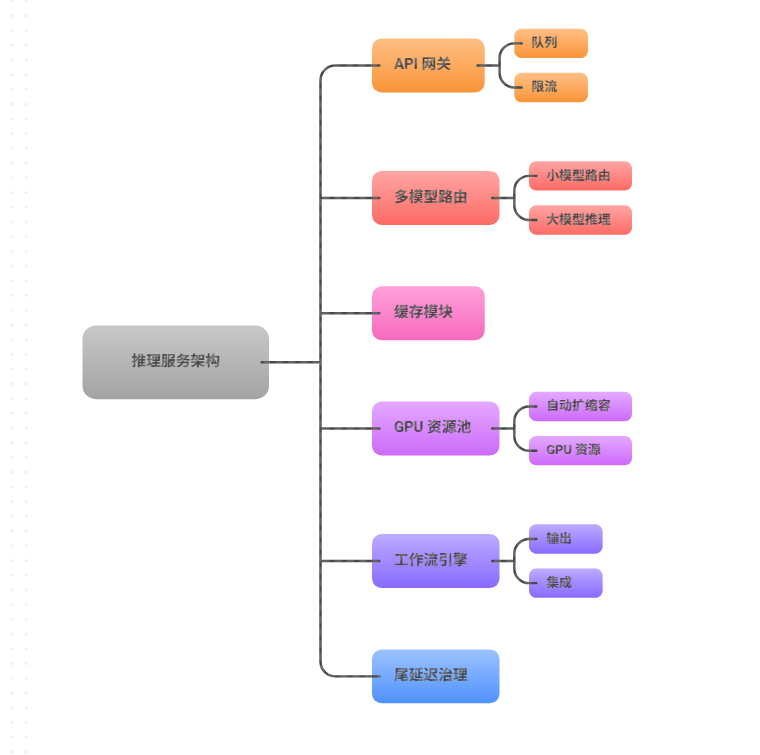
四、从"聊天"到"任务":API 设计决定可观测性与可靠性上限
要做 SRE,首先要让系统"可测量"。如果你的 API 只是 POST /chat 返回一段文本,那么你很难回答这些问题:
- 这次输出是基于哪些证据?
- 调了哪些工具?哪个工具慢?哪个工具错?
- 是模型问题还是数据问题?
- 重试会不会产生重复副作用?
- 安全审计如何回放?
- 因此更推荐把 AI 做成"任务 API"(哪怕你前端仍然以聊天形式呈现):创建任务:输入意图、上下文、权限域、业务对象
- 执行过程:每个工作流节点产生事件(检索、计划、工具调用、校验)
- 结果输出:结构化结果 + 证据引用 + 执行摘要
- 幂等与重试:同一业务动作必须可幂等(例如短信发送、工单创建)
这样你才能真正建立 SRE 的可观测体系:链路追踪、错误归因、回放对比、容量规划。
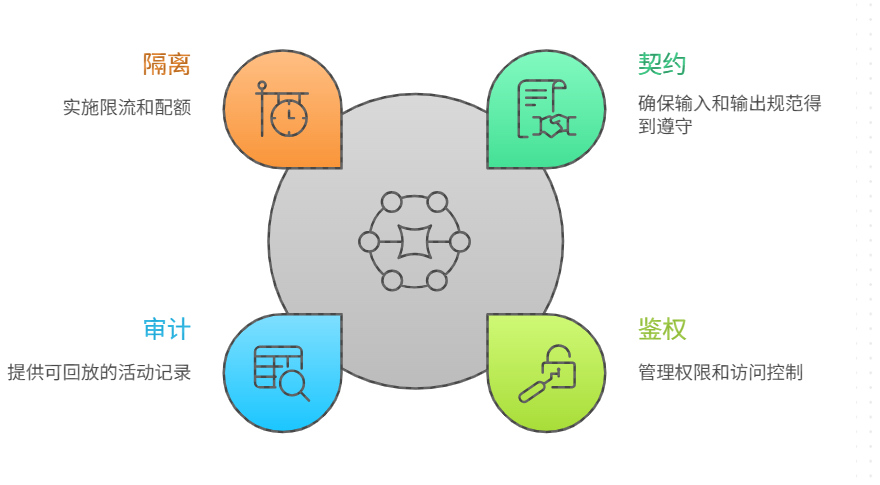
五、MCP:把工具层变成"可治理的生产依赖"
AI 应用一旦进入生产,"工具调用"就会成为可靠性的主要来源之一:数据库、内部服务、第三方 API 都会失败。更糟的是,模型可能在错误时"编一个像真的结果"。所以你必须把工具层纳入统一治理。
MCP 的工程意义在于:把工具接入标准化,让工具成为"可审计、可限流、可校验、可替换"的能力集合。SRE 角度最关键的四点是:
- 契约 :参数类型、必填项、返回结构固定,便于校验与回放
- 鉴权 :工具调用绑定用户/租户/角色,权限域明确
- 审计 :每次调用记录输入、输出、耗时、错误,关联 trace_id
- 隔离 :按工具、按租户限流;高风险工具强制审批或只读默认
工具层一旦标准化,你就能做更强的可靠性设计:工具 A 慢就切工具 B;工具失败就走只读路径;同一工具的错误码可统一归类进告警。
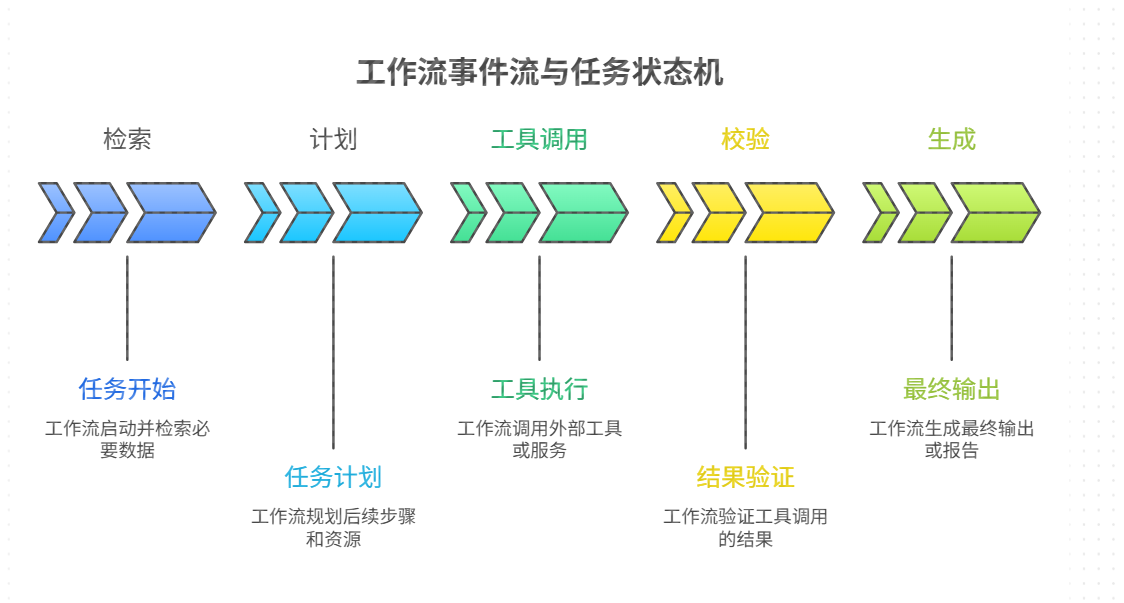
六、智能体与工作流:把"多步推理"做成可回放的执行链路
智能体 最吸引人的地方是能自动拆解任务并多步执行,但这也是风险源:步骤越多,失败概率越高,副作用越大。解决方法不是"让模型更谨慎"这么简单,而是用 工作流 把多步执行工程化:
1.节点化:每一步都可观测、可重试、可替换
- 检索节点失败不影响其他节点回放
- 工具节点可设置超时、重试、幂等
- 校验节点可作为"安全阀",拦截越权与不合规
2.状态化:任务有状态机而非一次性输出running / blocked / need_approval / failed / succeeded
- 让系统可以暂停、恢复、人工介入,而不是一次失败全盘崩
3.证据化:输出必须绑定依据AIGC 回复中引用检索片段或工具结果
- 没证据就拒答或请求补充信息
4.策略化:不同风险等级走不同轨道低风险:全自动(只读查询、总结)
- 中风险:自动执行但强校验(生成报表、建议)
- 高风险:强制审批(发消息、改状态、下单)
通过工作流,你把"不可控的智能体"变成"可运营的执行系统"。
七、安全:把"模型能看到什么、能做什么"制度化
AI 的安全并不只是"别注入提示词",而是覆盖数据、权限、动作、供应链的系统性问题。SRE 视角下,安全要可落地、可度量、可审计。
1.数据边界:最小暴露原则
- 上下文只提供完成任务所需的信息
- 检索返回结果要脱敏(例如手机号只留后四位)
- 不同租户、不同角色的知识库与工具调用必须隔离
2,权限模型:工具调用等价于"生产操作"每个工具定义清晰的权限域与资源范围
- 默认只读,高风险写入必须审批
- 所有写操作必须幂等、可回滚或可补偿
3,审计与取证:可以回答"为什么这样做"记录:输入、证据、计划、调用、输出
- 可回放:能用同样输入重现决策路径
- 可追责:关联用户身份、工单、审批链路
4,对抗与滥用:把异常当作常态去设计提示注入、越权诱导、数据探测、批量刷成本
- 用网关层限流、异常检测、策略拦截与封禁
安全做得好,会直接提升可靠性:因为系统不再依赖模型"自觉拒绝",而是用工程控制实现"做不到"。
八、成本:把 token 当作"新的 CPU",用 FinOps 思路管理
AI 系统的成本往往不是"慢慢增长",而是"规模化后爆炸"。SRE 需要把成本纳入日常运营。
1.成本分摊:按业务动作而非按请求 不要只看"每次请求多少钱",要看"每次成功任务多少钱"。例如:
- 生成日报(成功)成本 X
- 发送补偿短信(成功)成本 Y 这样你才能比较不同工作流/模型组合的真实产出效率。
2.成本预算与配额:把花钱变成可控策略按租户/团队/月设置预算
- 超预算自动降级:缩短上下文、降低输出长度、切小模型、减少检索召回数
- 对低价值场景启用缓存或直接走模板
3.成本优化的四个抓手减少无效上下文:只给必要信息
- 提高检索质量:减少"检索失败导致模型胡写"的返工
- 分层模型:大模型只做关键推理
- 增加结构化与校验:减少重试与返工
成本治理最终要落到平台与工具:否则只能靠人肉节流。
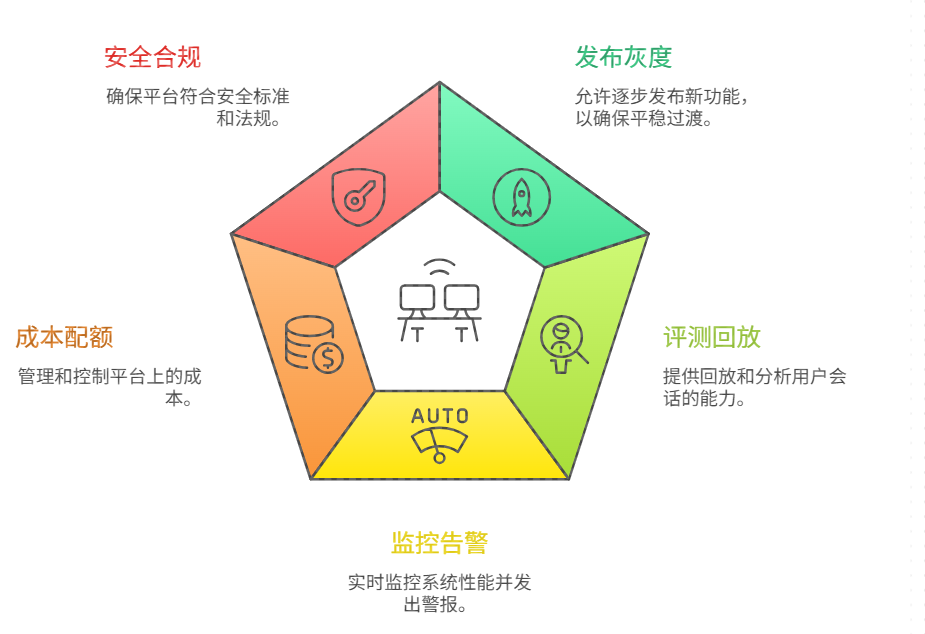
九、Mass 平台:让发布、监控、评测、回滚、配额形成统一闭环
当你拥有多个 AI 模型 、多个智能体、多个工作流版本时,SRE 不能靠"手工改配置"。 Mass 平台 应当承担"AI 生产系统的控制面",至少包括:
- 发布与灰度 :模型版本、提示词版本、检索配置、工作流版本可独立发布;支持小流量验证
- 在线评测与回放 :用真实流量样本对比新旧版本,输出质量/成本/延迟差异
- 监控告警与定位 :按节点、按工具、按模型拆分指标;支持 trace 级别回放
- 成本与配额 :预算、限额、优先级队列、自动降级策略
- 安全与合规 :敏感信息检测、审计导出、越权拦截、策略中心
平台化的意义在于把"系统性能力"从应用里抽出来,让团队能把精力放在业务本身。
十、AIGC 质量治理:用"可控生成"替代"自由发挥"
从 SRE 角度看, AIGC 的质量治理与传统内容生产不同:你要的不只是"读起来不错",还要"可验证、可一致、可追责"。常见治理手段:
- 输出结构化:先产出结构化骨架(要点、结论、引用),再生成自然语言
- 强制引用证据:回复中每条关键结论都绑定证据来源
- 合规过滤与脱敏:在生成前后做双重检测
- 质量门禁:灰度发布前跑评测集,低于阈值不放量
- 线上抽检与回放:从真实请求中抽样,形成失败样本
AIGC 一旦与工作流、工具调用绑定,就从"文本生成"变成"生产工艺"。
十一、调优:用失败样本驱动的飞轮,把改动变成可回归的工程迭代
很多团队调优停留在"改提示词"。但在 SRE 体系里,调优应该像性能优化一样:可复现、可度量、可回归。
一套可持续的 调优 飞轮通常是:
- 采集失败:幻觉、引用缺失、工具调用错误、越权尝试、成本异常、尾延迟异常
- 标注归因:是检索问题、模型问题、工具问题、工作流设计问题、还是权限配置问题
- 回放评测:新旧版本对比质量/成本/延迟与安全指标
- 灰度发布:小流量验证,指标达标再放量
- 沉淀基线:把成功策略固化到平台策略与工作流模板
配合 IDE 与 Vibe Coding ,这套飞轮会跑得更快:你在 IDE 里复现、修改、跑评测、看差异,然后再发布到平台做灰度。
十二、把一切落到一个端到端闭环:一次请求如何被系统"托住"
最后用一次典型请求把链路串起来。假设用户发起任务:"汇总本周工单热点,给出整改建议,并生成周报链接"。
端到端闭环可能是:
- API 网关接入:鉴权、限流、配额检查(成本预算)
- 任务创建:生成 task_id,进入工作流状态机
- 检索节点:从知识库与工单系统取证(脱敏、按权限过滤)
- 计划节点:模型生成结构化计划(要调用哪些工具、要输出哪些字段)
- 工具节点:通过 MCP 调用工单查询 API、报表生成 API
- 校验节点:检查引用完整性、建议是否越权、是否触发敏感规则
- AIGC 节点:生成可读周报文本,同时附上引用证据与链接
- 监控与审计:全链路 trace、token、耗时、失败原因写入平台
- 调优沉淀:如果失败或成本异常,自动进入失败样本仓库用于回放评测
这样你的系统在面对抖动时有降级、面对错误时可定位、面对成本有预算控制、面对安全有审计与拦截。SRE 的价值就在这里:不是让 AI 永远正确,而是让它的错误"可控、可追踪、可改进"。