引言
一直以来,真正限制大模型落地的,往往不是"能不能用",而是算力 成本和稳定性。尤其是在需要反复测试、对比不同模型和供应商的阶段,算力消耗几乎是硬门槛。
AI Ping 这次的做法比较直接:随着 GLM-4.7 和 MiniMax M2.1 两款旗舰模型上线,平台同步开放了算力激励机制,把"体验成本"压到了接近零。通过模型聚合与加速调度,同一套接口即可调用多家供应商节点,在保证性能的同时,降低了试错成本。
如果你正处在模型选型或 Agent 测试阶段,这个机制的价值其实很明确:
-
可以无压力跑对比测试,而不是只看文档和参数
-
能在真实负载下验证吞吐、延迟和稳定性
-
邀请机制还能获得额外算力额度(20 元/人),适合做持续测试或小规模验证
对于想低成本体验 GLM-4.7 的工程交付能力,或 MiniMax M2.1 的长链 Agent 表现的开发者来说,这是一个几乎没有试错成本的窗口期。
注册入口(含算力额度): https://aiping.cn/#?channel_partner_code=GQCOZLGJ
如果你更在意"能不能跑通、跑稳、跑得久",而不是单次生成效果,这波确实值得亲自试一轮。
一、AI ping平台介绍
在实际工程中,使用大模型往往面临一个被低估的问题:模型本身并不是唯一变量,供应商、网络、负载与调度策略同样决定最终体验。同一模型在不同云厂商上的吞吐、延迟和稳定性,差异往往超过模型之间的差异。
AI Ping 正是围绕这一现实问题而设计的模型聚合与评测平台。
1、平台定位:为工程选型服务,而不是"多接几个模型"
AI Ping 的核心定位并非简单地"接入更多模型",而是把模型能力放在真实工程环境中进行横向对比。平台目前已对接多家主流模型厂商与云服务商,在统一入口下提供:
-
同一模型 × 多供应商 的并行接入
-
统一 OpenAI 兼容接口,避免重复适配 SDK
-
面向工程的关键指标:吞吐、P90 延迟、上下文长度、价格与可靠性
这意味着,开发者在选型阶段关注的不是"模型参数有多大",而是在自己业务负载下,哪种组合最稳定、最划算、最可控。
2、统一调用接口:降低接入与切换成本
在没有聚合平台的情况下,每更换一个模型或供应商,往往需要:
-
重新对接 API
-
调整鉴权方式
-
修改返回结构解析
-
重新做限流与错误处理
AI Ping 通过 OpenAI 兼容接口 把这些成本压缩到最低。对应用侧而言:
-
切换模型 = 改一个
model参数 -
切换供应商 = 修改或交由平台自动路由
-
代码结构保持不变
这在需要快速 A/B 测试模型表现 或根据成本、峰值负载动态调整的工程场景中尤为重要。
3、性能可视化:用数据而不是感觉做决策
AI Ping 将平台内各模型、各供应商的关键性能指标进行持续监测与展示,包括:
-
吞吐量(tokens/s)
-
P90 / P95 延迟
-
上下文支持能力
-
单位输入/输出成本
-
历史稳定性与可用率
这些数据并非一次性 benchmark,而是贴近真实调用环境的持续观测结果。对于需要做模型选型评审、成本评估或 SLA 设计的团队来说,这类数据比单点跑分更有参考价值。
4、多供应商与智能路由:应对不稳定是常态
在高并发或流量波动场景下,模型调用的不稳定往往来自供应商层面,而非模型本身。AI Ping 提供的智能路由能力,可以:
-
在多个可用供应商之间自动切换
-
在高峰或异常时优先选择更稳定、延迟更低的节点
-
降低单点故障对业务的影响
对于长链 Agent 或需要持续运行的后台任务,这种供应商级的容错与调度能力往往比单模型能力更关键。

二、GLM-4.7 模型解析
如果把 GLM-4.7 放进真实项目中观察,它更像是一个**"可控、稳定、偏交付导向"的工程型模型** ,而不是追求极限生成能力的展示型模型。它的优势并不体现在某一个单点指标上,而体现在复杂任务从输入到交付的完整闭环。
1、面向复杂工程的一次性交付能力
GLM-4.7 的核心设计目标之一,是减少多步骤工程任务中的不确定性。在实际使用中,这种特性通常体现在:
-
对复杂需求的拆解更加克制,不容易在中途"发散"
-
对任务边界的理解更明确,生成结果更接近"可直接使用"
-
在前端页面、交互逻辑、配置文件等产物上,完整度高、返工成本低
这使得 GLM-4.7 特别适合用于:
-
项目初始化阶段的整体架构设计
-
前端页面或交互原型的快速生成
-
需要一次性产出完整结果的工程任务
与强调持续输出的模型相比,GLM-4.7 更像是**"一次把事做对"**的工具。
2、可控推理:稳定性优先于生成长度
在多步任务中,模型是否"聪明"往往不如是否"可控"重要。GLM-4.7 在推理层面的一个显著特征是可控思考机制:
-
推理路径相对稳定,不容易在长任务中偏离原始目标
-
对工具调用、接口约束的遵循度更高
-
在需要严格结构输出(如 JSON、配置文件)时出错率较低
在工程实践中,这直接影响:
-
Agent 工作流是否能稳定执行到最后一步
-
工具链(数据库、CI、外部 API)调用是否可预测
-
自动化流程是否需要频繁人工兜底
对于希望降低人工干预成本的团队来说,这是 GLM-4.7 的一个关键优势。
3、编码与 Artifacts 生成的实际表现
在编码能力上,GLM-4.7 并不刻意追求"覆盖所有语言",而是更强调结构正确性与整体完成度:
-
前端组件、页面布局和样式的整体一致性较好
-
对工程目录结构、模块划分有较强的整体意识
-
在生成 Artifacts(如页面、文档、脚手架代码)时,视觉与结构完成度高
这也是为什么在 Agentic Coding 或 前端相关任务 中,GLM-4.7 往往能减少多轮修改。
需要注意的是,在极端偏后端、强类型、性能敏感的场景(如复杂 C++/Rust 底层逻辑),GLM-4.7 并非最激进的选择,但在"端到端交付"任务中表现稳定。
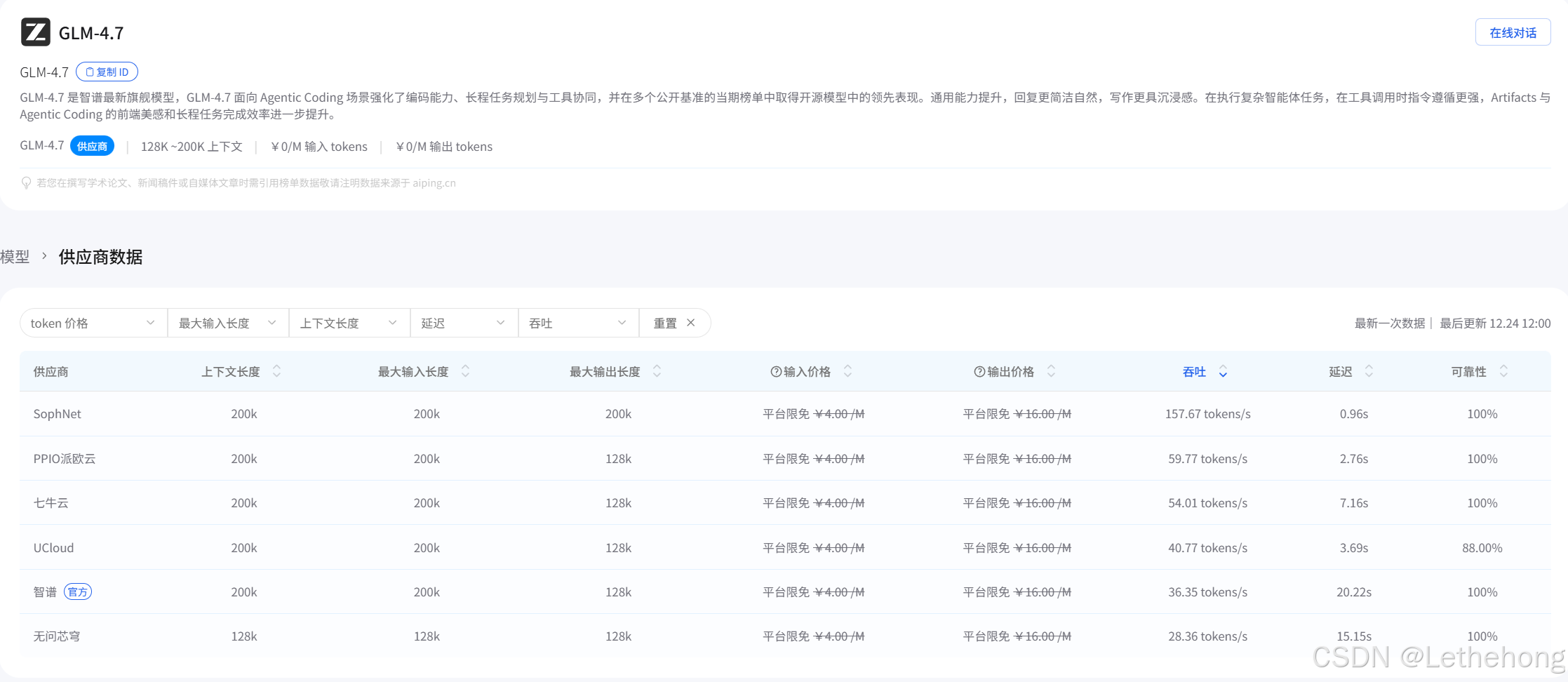
4、性能与调用表现(基于 AI Ping 实测)
根据 AI Ping 平台的实测数据
5、适合使用 GLM-4.7 的典型场景
综合能力与表现,GLM-4.7 更适合以下类型的任务:
-
复杂工程的一次性交付(前端、原型、架构文档)
-
对输出结构、完整性要求高的任务
-
Agent 工作流中的"关键决策节点"
-
需要可控推理、低漂移的自动化流程
如果你的目标是尽快得到一个可用、可维护、结构清晰的结果,而不是持续不断地产出内容,GLM-4.7 往往是更稳妥的选择。
三、MiniMax M2.1 模型解析
如果说 GLM-4.7 更像一个"工程交付型选手",那么 MiniMax M2.1 的定位则非常明确:为长时间运行的 Agent 与持续编码任务服务。它关注的不是单次输出是否"惊艳",而是在多轮、多任务、长上下文条件下,是否还能保持稳定、可控和高效。
1、面向长链 Agent 的设计取向
MiniMax M2.1 的核心优势之一,是对长链 任务与持续运行场景的针对性优化。在实际使用中,这种优势主要体现在:
-
长时间对话中上下文衔接更自然,不易"遗忘"早期约束
-
多轮任务执行过程中,推理路径更收敛,较少出现无关发散
-
连续编码、反复修改同一模块时,状态保持能力较强
这类特性对于构建常驻 Agent(如自动运维、代码巡检、持续数据处理)尤为重要。
2、高效 MoE 架构与持续吞吐能力
MiniMax M2.1 采用高效的 MoE(Mixture of Experts)架构,这在工程层面的直接收益是:
-
低激活参数:单次推理调用消耗更可控
-
更高吞吐:在并发和长时间运行场景下表现稳定
-
更好的性价比:适合需要持续调用的大规模任务
从 AI Ping 平台的实测数据来看,MiniMax M2.1 在部分供应商节点上吞吐接近 90--100 tokens/s ,在同类模型中处于较高水平。这使它在需要长时间持续输出的场景中更具优势。
3、多语言后端工程的实际表现
与偏重前端和整体交付的模型不同,MiniMax M2.1 在多语言后端工程中表现得更加"务实":
-
对 Rust / Go / Java / C++ 等强类型语言的结构理解更稳
-
生成的代码更贴近真实工程约束(包结构、依赖管理、接口定义)
-
在迭代修改同一模块时,前后逻辑衔接度较高
在需要频繁与现有代码库交互、反复增量修改的场景下,这种特性可以显著减少"推倒重来"的情况。
4、长上下文带来的工程价值
MiniMax M2.1 支持 最高 200k 上下文,这一点在工程实践中的意义,往往被低估:
-
可以一次性加载更完整的代码仓库或配置文件
-
减少切片带来的语义断裂
-
在长流程 Agent 中避免频繁"重新讲背景"
对于需要处理大型项目、复杂业务逻辑或跨模块依赖的任务,这种上下文优势会直接转化为效率提升。
5、稳定性与供应商表现(基于 AI Ping)
在 AI Ping 平台的实测中,MiniMax M2.1 在多个供应商节点上表现出:
-
较低的 P90 延迟
-
高吞吐下仍保持 100% 可用率
-
在长时间运行测试中,性能波动相对较小
这使得它非常适合作为:
-
后台 Agent 的默认执行模型
-
高并发、长时间运行任务的主力模型
6、MiniMax M2.1 的使用边界
需要客观看待的是,MiniMax M2.1 并不是为所有场景而生:
-
在强调一次性高质量交付(尤其是前端/UI)的任务中,可能需要更多人工校正
-
对极复杂、强约束的单次决策问题,其优势不如持续型任务明显
因此,将它放在**"持续执行"而非"一次定稿"**的位置,往往能发挥更大价值。
四、注册与快速上手指南
如果只是"注册成功",并不能说明你已经真正用上了模型。真正的上手标准只有一个:在自己的环境里,把模型请求跑通,并能稳定复现结果。下面按照这个目标,给出最短、可执行的路径。
1、注册与获取 API Key
打开 AI Ping 官网(aiping.cn),完成注册并登录。
进入控制台或个人中心,找到 API Key 管理页面。
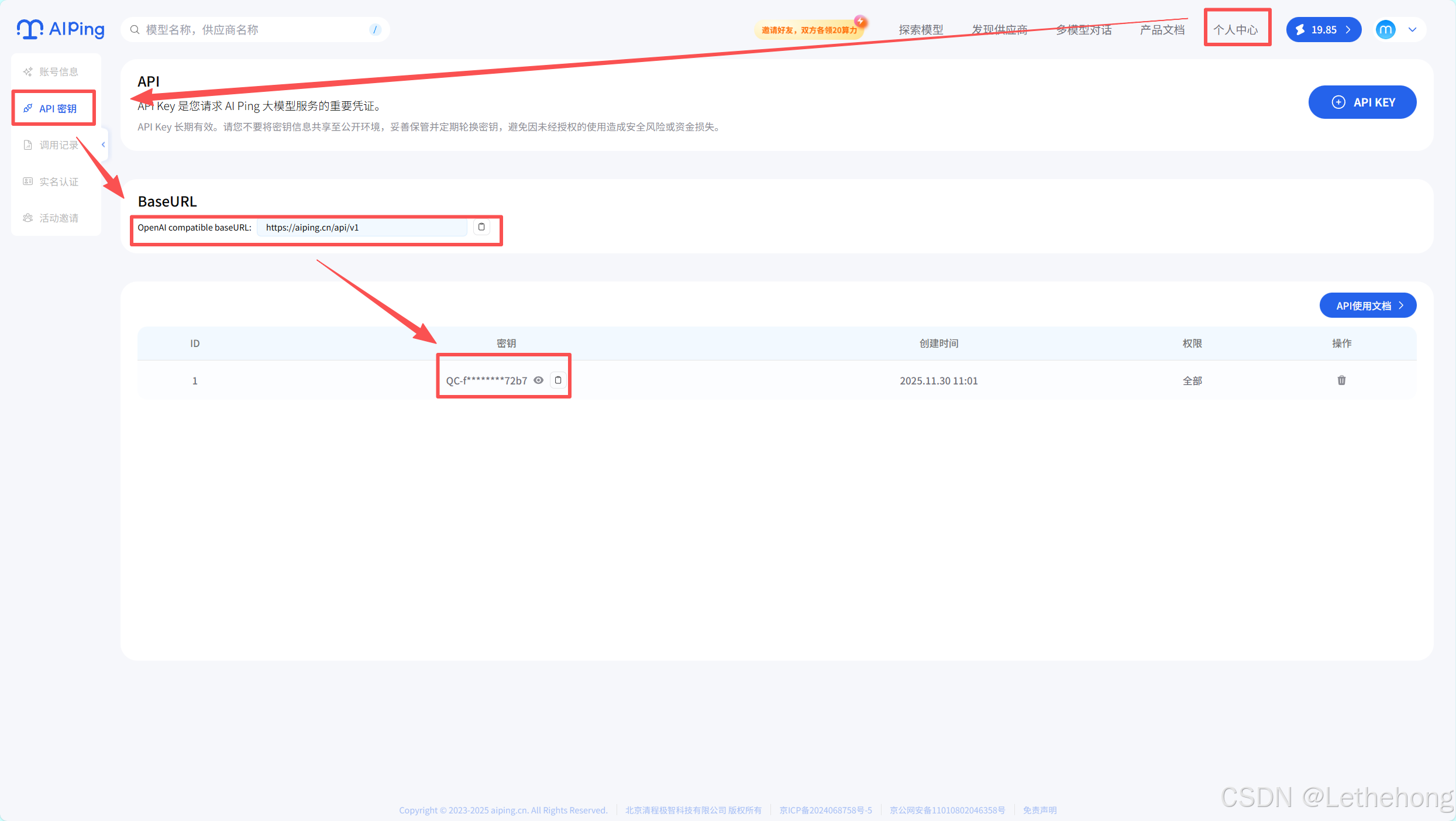
创建并复制 API Key(建议只用于测试环境,生产环境单独创建)。
实际建议:
不要把 Key 直接写在代码里,使用环境变量或配置文件。
如果后续要接入多个项目,提前规划 Key 的用途,方便权限与成本管理。
2、用最小示例验证调用是否成功
AI Ping 提供 OpenAI 兼容接口 ,因此你可以用最熟悉的 SDK 直接测试。以下示例以 Python 为例,目标只有一个:确认请求能通、响应稳定。
from openai import OpenAI
client = OpenAI(
base_url="https://www.aiping.cn/api/v1",
api_key="YOUR_API_KEY"
)
resp = client.chat.completions.create(
model="GLM-4.7", # 或 MiniMax-M2.1
messages=[
{"role": "user", "content": "用三句话说明这个模型适合什么工程场景。"}
]
)
print(resp.choices[0].message.content)如果你能稳定看到返回内容

说明:
-
网络连通正常
-
Key 权限有效
-
模型与默认供应商可用
这一步非常关键,不要跳过。
3、切换模型与对比测试(工程必做)
在 AI Ping 上切换模型不需要改代码结构,只需改一个参数:
model="MiniMax-M2.1"

建议在真实项目前,至少做一次对比测试:
-
同一个 Prompt
-
不同模型(GLM-4.7 / MiniMax M2.1)
-
观察输出稳定性、响应时间与可读性
这样你很快就能感受到两者在"交付 vs 持续执行"上的差异。
4、在本地工具中直接使用(可选但很实用)
Claude Code 中使用 GLM-4.7
如果你习惯在本地用 Claude Code 做工程任务,可以通过环境变量直接把模型切到 AI Ping:
-
设置
ANTHROPIC_BASE_URL为 AI Ping 的 Anthropic 兼容地址 -
把
ANTHROPIC_AUTH_TOKEN替换为你的 API Key -
将默认模型指向
GLM-4.7
这样可以无缝复用原有 工作流,非常适合做复杂工程交付。
现在我们开始code开发,我们需要先前往C盘下面的users里面的administrator文件夹下面进入.claude目录,然后创建json文件添加:
{
"env": {
"ANTHROPIC_BASE_URL": "https://aiping.cn/api/v1/anthropic",
"ANTHROPIC_AUTH_TOKEN": "your API KEY",
"API_TIMEOUT_MS": "3000000",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": 1,
"ANTHROPIC_MODEL": "GLM-4.7",
"ANTHROPIC_SMALL_FAST_MODEL": "GLM-4.7",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "GLM-4.7",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "GLM-4.7",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "GLM-4.7"
}
}
然后在终端输入claude即可
Coze 中使用 MiniMax M2.1
如果你在做 Bot 或 Agent 工作流,Coze 是更合适的入口:
-
在插件市场安装 AI Ping 官方插件
-
在工作流中配置模型为
MiniMax-M2.1 -
设置
stream、temperature与max_tokens -
通过试运行验证长链任务是否稳定
这套方式尤其适合测试 持续运行型 Agent。
点击添加节点,然后单击插件进来,搜索AI Ping找到图中对应的节点进行添加即可。
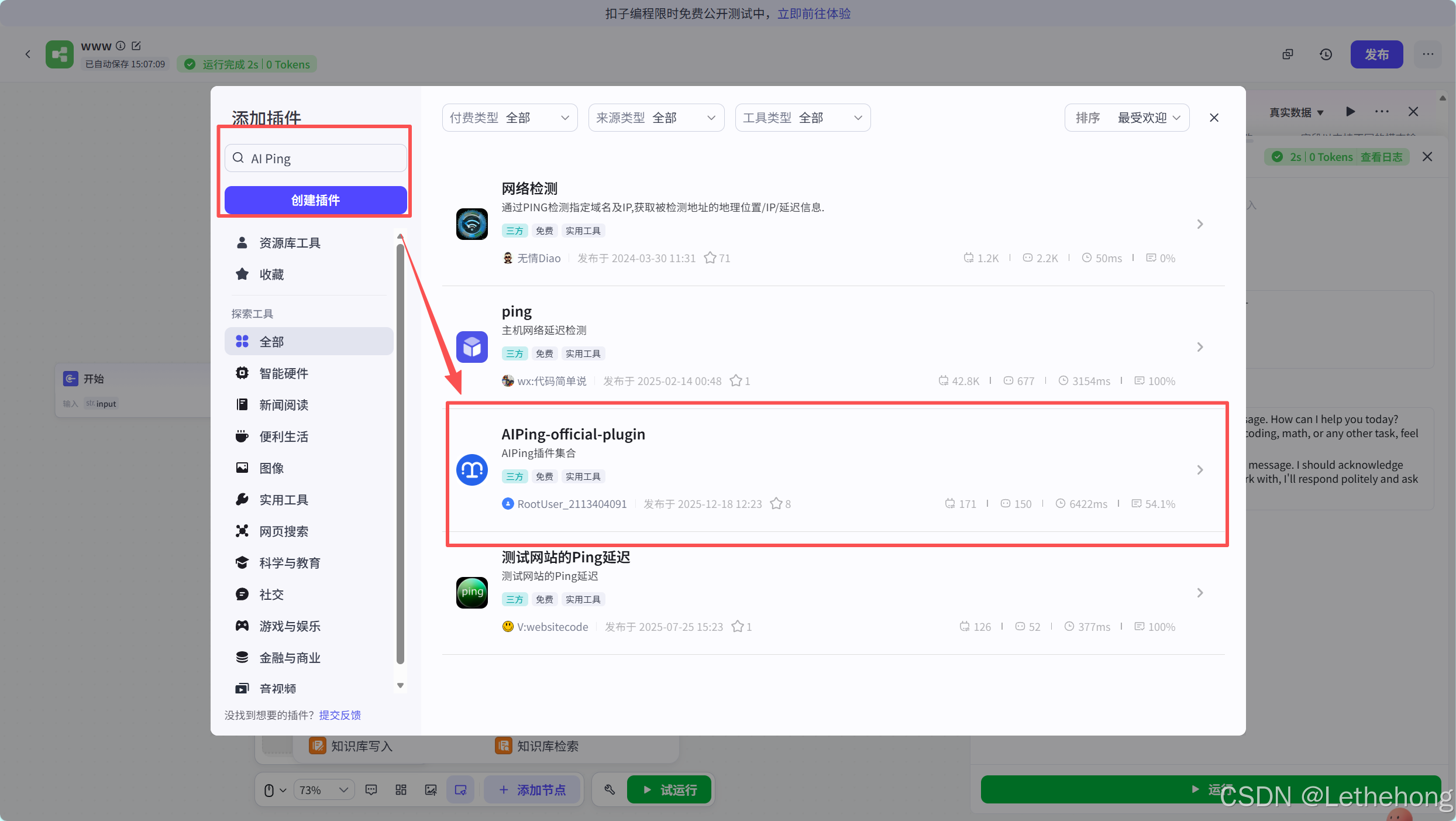
这里进行测试节点是否可用,出现这个提示就说明是可用的哈。
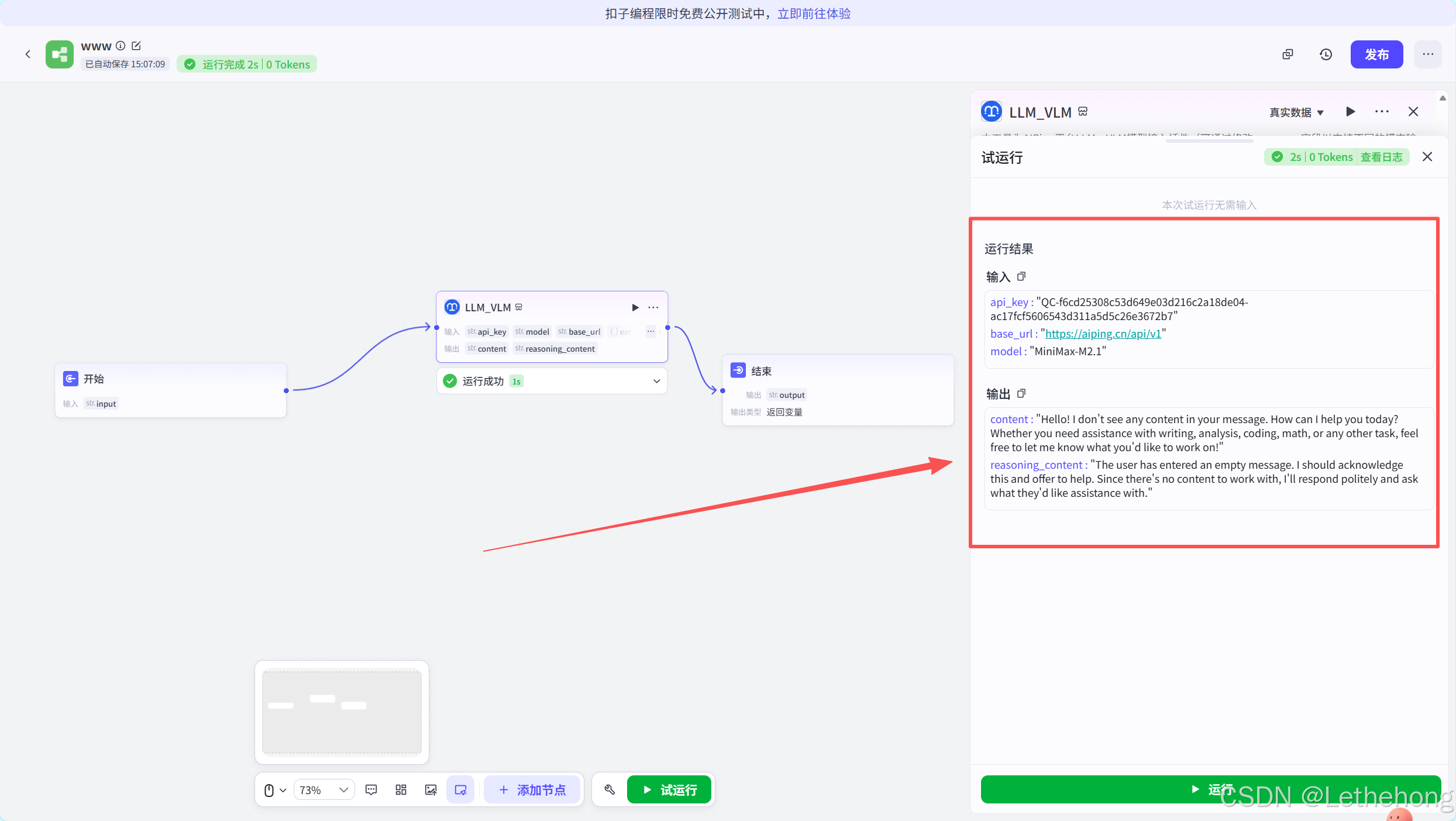
然后进行集中测试。确实够简洁
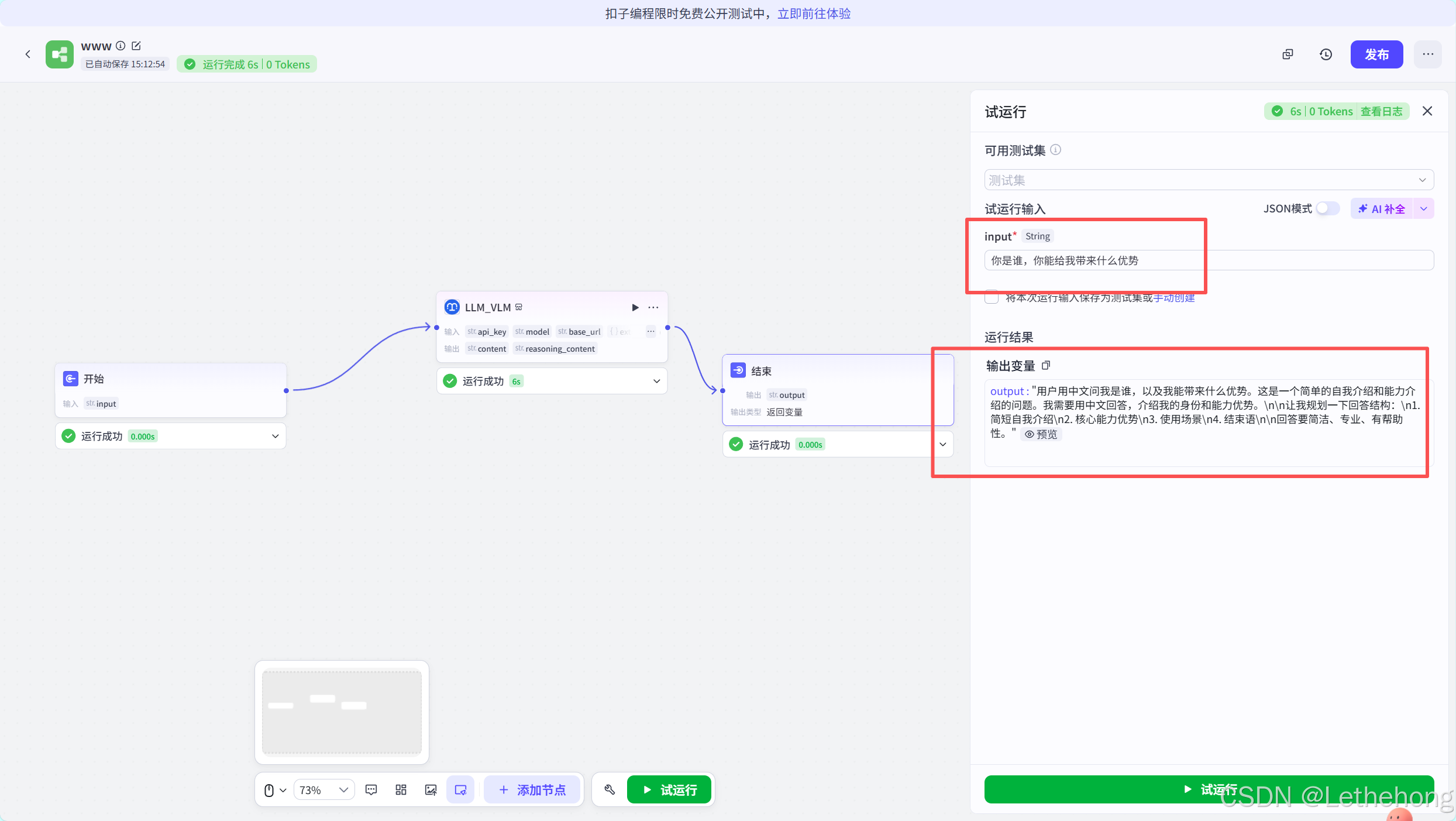

问了一个专业知识就得到了以下
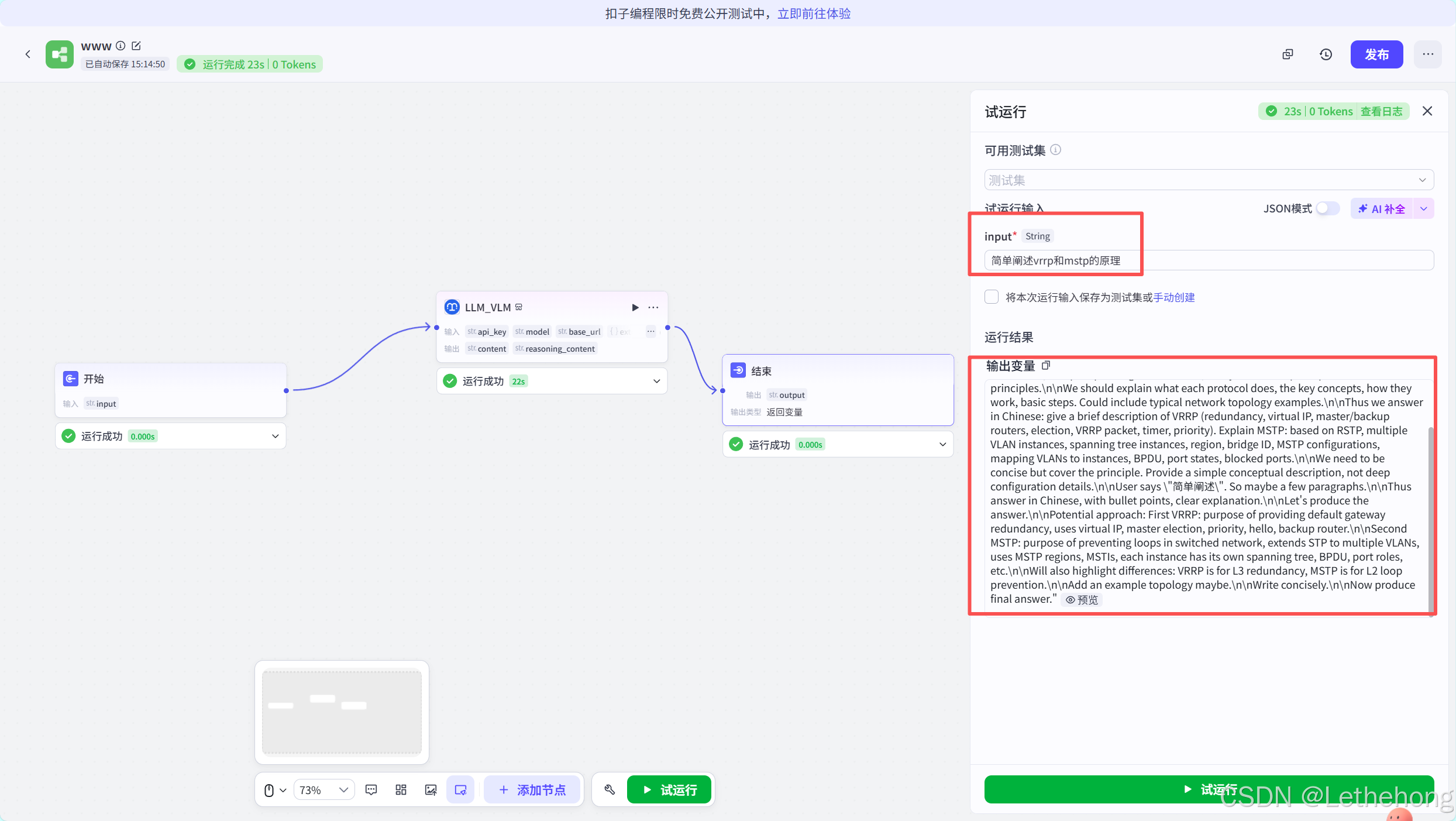
我给大家翻译一下

总结
回到工程本身,其实很难用一句话去评价 GLM-4.7 或 MiniMax M2.1 的"优劣"。它们更像是被放在了不同工程位置上的工具。
-
GLM-4.7 更适合作为"关键节点模型": 用在架构设计、前端原型、一次性交付型任务或 Agent 工作流中的决策阶段,它强调的是可控、完整、低返工率。当你希望一次输出就尽量接近可用结果,而不是反复拉扯时,它往往更稳。
-
MiniMax M2.1 则更像"持续执行引擎": 面向长链 Agent、后台任务、持续编码和多语言后端工程,它的优势在于高吞吐、长上下文与运行稳定性。在需要长时间运行、反复迭代同一任务的场景下,它更容易把成本和性能控制在可预期范围内。
而 AI Ping 的价值,并不在于"让你多用几个模型",而是通过多供应商实测、统一接口和智能路由,把"模型 + 供应商"这个原本隐性的变量显性化。你不再需要凭感觉选型,而是可以基于真实数据,在自己的业务负载下做决定。
如果只能给一个工程层面的建议,那就是: 不要纠结哪个模型更强,先想清楚你的任务是"一次定稿",还是"长期运行"。 前者优先稳定与可控,后者优先效率与持续性。剩下的,就交给平台和数据去验证。
当模型真正跑在你的工程里,而不是停留在评测表格中,结论往往会比任何榜单都清晰。