Protobuf 序列化协议深度技术白皮书与 C++ 开发全流程指南
第一章 序列化技术核心原理与框架选型
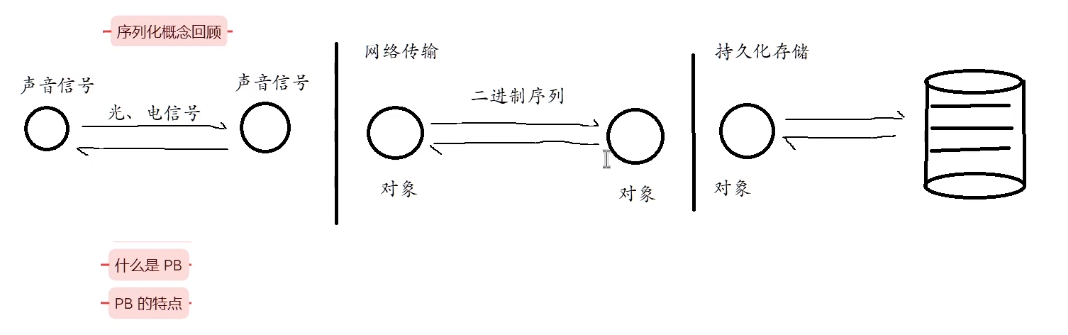
在现代分布式系统、微服务架构以及高性能网络通信领域,对象状态的序列化与反序列化是实现异构系统间数据交换的底层基石。
1.1 序列化与反序列化的定义
序列化(Serialization):指将内存中的结构化对象(Object)转换为字节流(Byte Stream)或特定格式(如 JSON 字符串、XML 文档)的过程。其核心目的在于使内存对象能够跨越进程边界,进入存储介质(磁盘)或网络传输链路。
反序列化(Deserialization):指将序列化后的字节流或格式化数据重新恢复为内存中原始对象的过程。此过程必须保证数据逻辑的完整性与类型的准确性。
1.2 序列化框架的多维度对比
在技术选型时,开发人员需平衡可读性、编码效率、传输性能与跨语言支持。下表详细列出了当前工业界主流序列化框架的特性差异:
| 框架 | 特点 | 性能 | 跨语言 | 应用场景 |
|---|---|---|---|---|
| JSON | 人类直观可读、架构灵活、无模式依赖 | 中 | 是 | Web API、RESTful 服务、配置文件 |
| XML | 严谨的结构化、自描述能力强、冗余度高 | 低 | 是 | 企业级 SOAP 协议、复杂配置管理 |
| Protobuf | 二进制编码、高性能、强类型约束、版本兼容性好 | 高 | 是 | 微服务 RPC 调用、大型分布式系统数据传输 |
| Thrift | 完整的跨语言服务栈、二进制传输协议 | 高 | 是 | Facebook 生态系统、跨语言 RPC 框架 |
| Avro | 动态 Schema 支持、数据头包含模式信息 | 高 | 是 | 大数据处理(Hadoop/Kafka)、动态序列化 |
| Pickle | Python 深度绑定、功能极强但无法跨语言 | 中 | 否 | Python 进程间协作、内部状态缓存 |
如上图所示,在性能轴线与体积轴线上,Protobuf 相比文本协议呈现出显著的优势。这种优势来源于其独特的二进制编码算法及对元数据的剥离。
1.3 Protobuf 的技术定位与应用维度
Protobuf(Protocol Buffers)由 Google 开发,其设计初衷是解决海量请求下的通信效率问题。其核心应用场景涵盖:
- 数据持久化:将复杂的内存对象序列化为极小的二进制块,存入数据库或文件系统。
- 高性能 RPC:作为 gRPC 的默认序列化协议,极大地降低了网络传输的延迟。
- 跨语言交互 :通过统一的
.proto接口描述文件,消除不同编程语言(如 C++ 与 Java)之间的内存布局差异。 - 分布式系统消息传递:如 Kafka 中消息的高效序列化。
第二章 Protobuf 工作机制与环境部署实务
2.1 编译型序列化机制深度解析
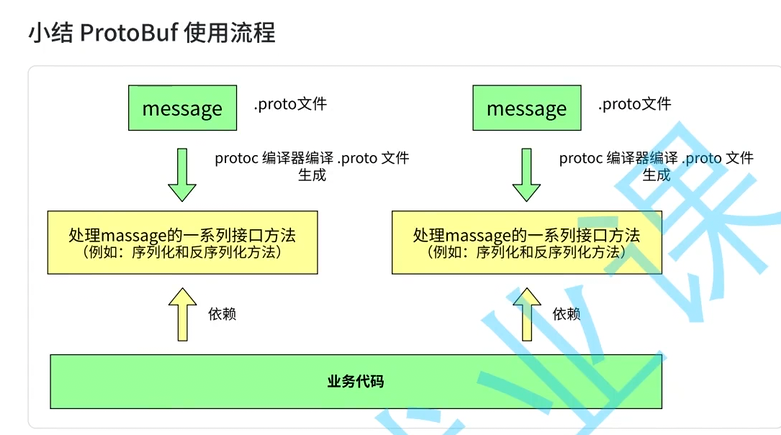
Protobuf 的运行逻辑分为定义、编译、集成三个核心阶段。这种机制的核心在于将协议定义与具体实现分离。

如图所示,开发流程首先从 .proto 文件开始,通过 protoc 编译器将定义的 message 结构翻译为目标语言的源代码。
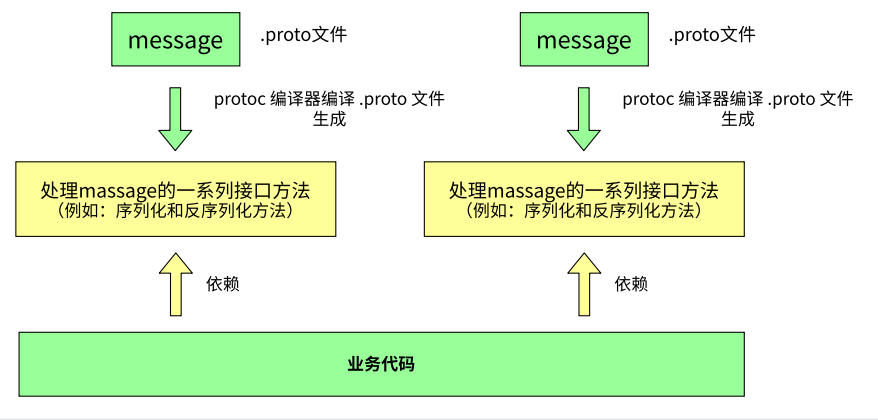
这种生成的代码包含了高效的 Getter/Setter 接口以及序列化引擎,开发人员无需手动解析二进制位。
2.2 Windows 平台下的环境构建流程
在 Windows 操作系统中部署 Protobuf 需要进行路径集成与编译器配置:
-
获取分发包 :访问 GitHub 官方仓库,下载 v21.11 版本的二进制包。
在下载页面中,选择
protoc-21.11-win64.zip以适配 64 位系统架构。
-
解压与目录探索 :解压后的文件夹包含
bin(存放编译器可执行文件)、include(存放核心头文件)等子目录。
编译器程序
protoc.exe位于bin文件夹内。
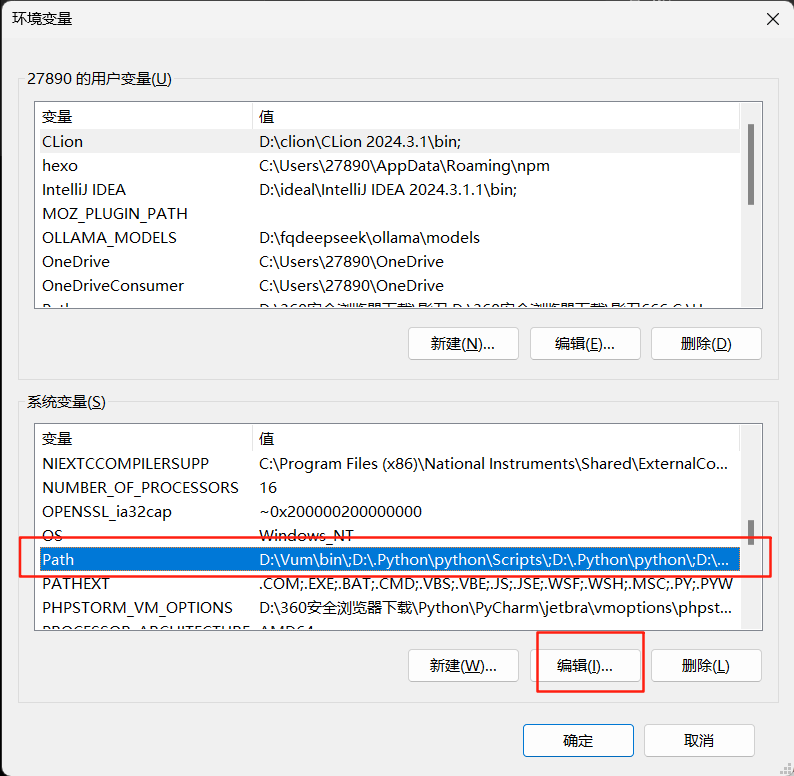
-
系统路径集成 :复制
bin目录的绝对路径(如D:\Protobuf 21.11\bin),并将其添加到操作系统的系统变量Path中。

-
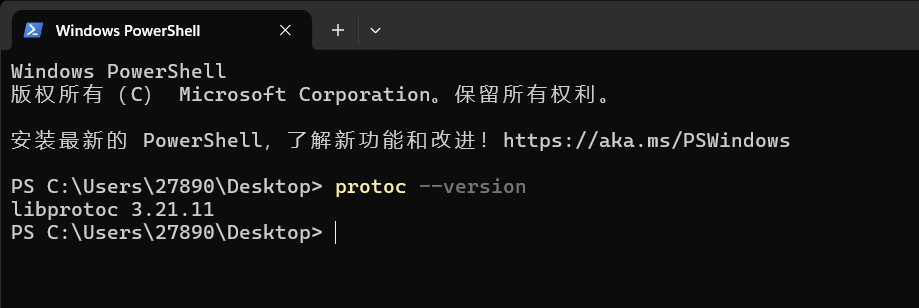
环境有效性校验 :启动终端,运行
protoc --version。若显示libprotoc 21.11,则代表安装成功。
2.3 Ubuntu Linux 平台下的编译安装与链接配置
在 Linux 生产环境中,通常采用源码编译方式以获得更好的系统适配性。
-
前置工具链安装:
bashsudo apt-get install autoconf automake libtool curl make g++ unzip -y
-
获取全量源码包 :下载包含所有语言支持的压缩包。
 bash
bashwget https://github.com/protocolbuffers/protobuf/releases/download/v21.11/protobuf-all-21.11.zip
-
解压与工程配置:
bashunzip protobuf-all-21.11.zip cd protobuf-21.11 ./autogen.sh
通过
--prefix选项定义独立的安装路径,防止系统库污染:bash./configure --prefix=/usr/local/protobuf配置完成后,编译系统将生成对应的
makefile文件。
-
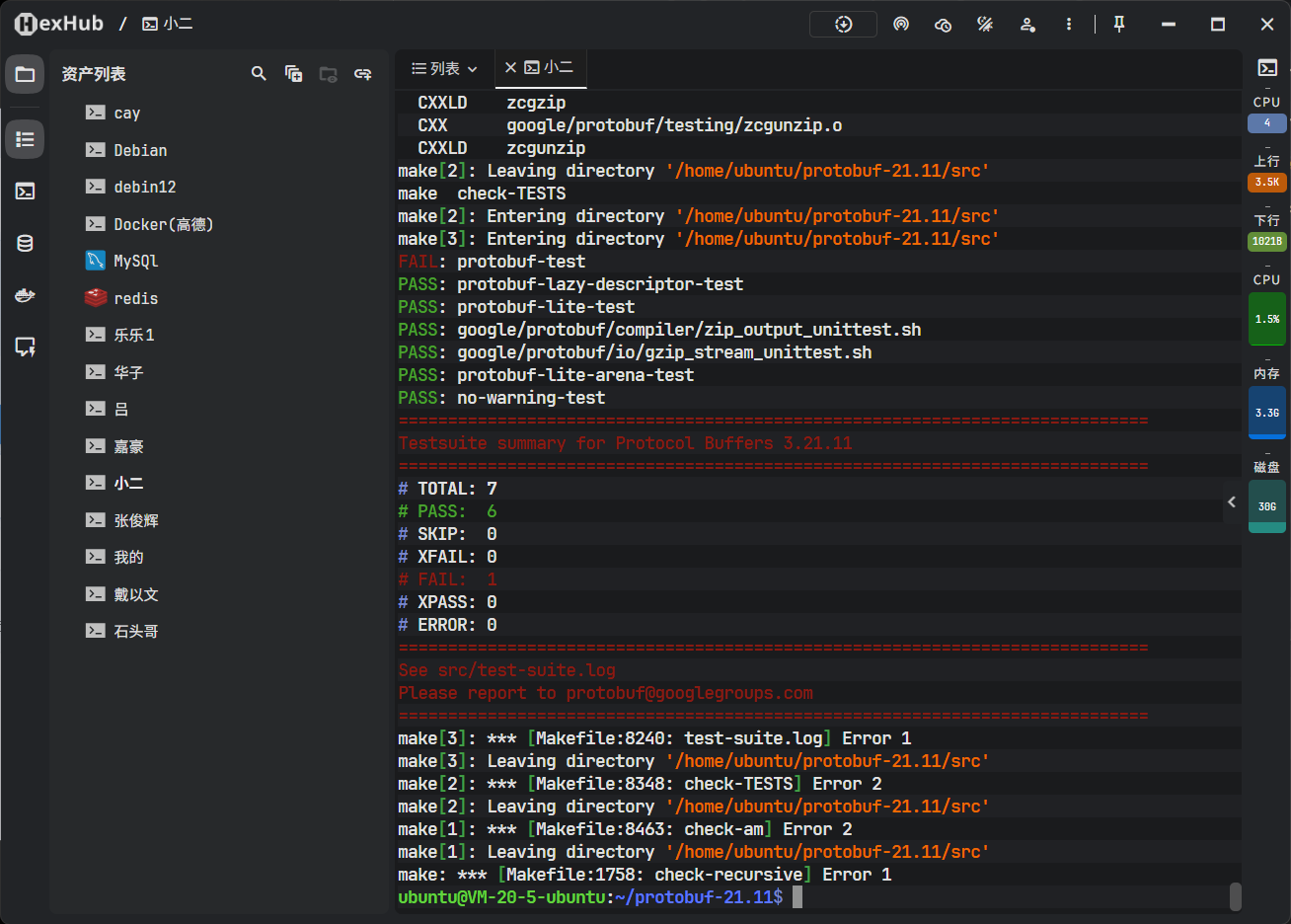
并行编译与自动化测试 :执行
make编译源码,随后运行make check进行回归测试。
最后执行
sudo make install完成文件分发。
-
全局路径持久化 :编辑
/etc/profile文件,配置库搜索路径与包含路径:bashsudo vim /etc/profile # 添加内容如下: export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/protobuf/lib/ export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/protobuf/lib/ export PATH=$PATH:/usr/local/protobuf/bin/ export C_INCLUDE_PATH=$C_INCLUDE_PATH:/usr/local/protobuf/include/ export CPLUS_INCLUDE_PATH=$CPLUS_INCLUDE_PATH:/usr/local/protobuf/include/ export PKG_CONFIG_PATH=/usr/local/protobuf/lib/pkgconfig/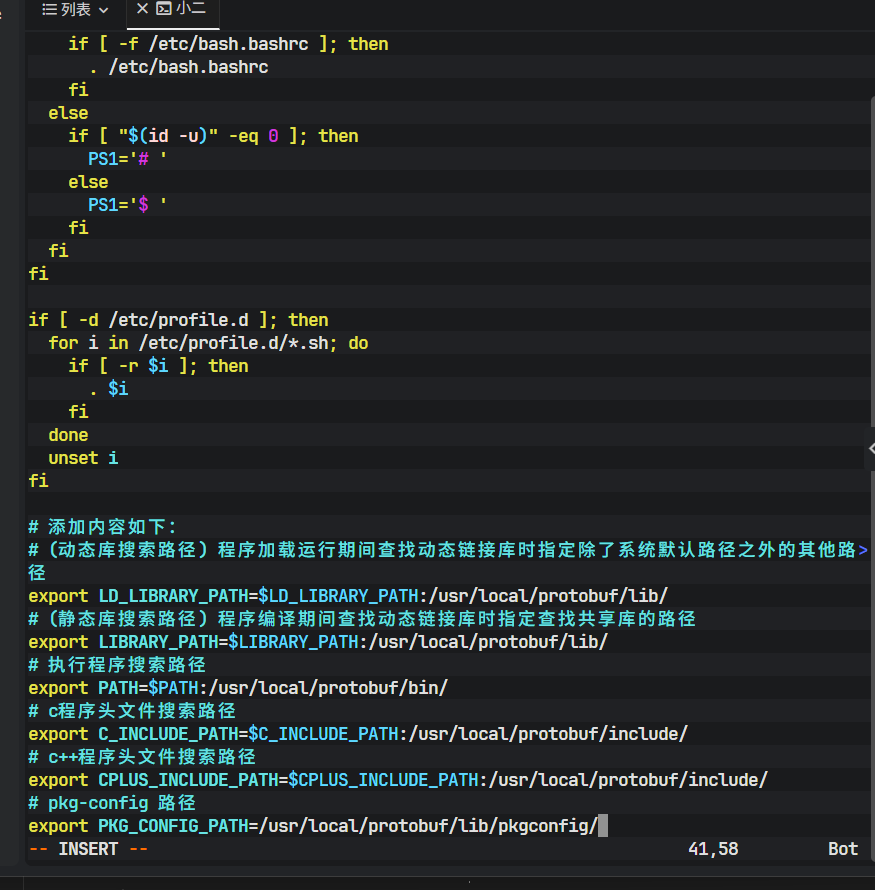
运行
source /etc/profile激活配置。

第三章 Proto3 语法体系与类型映射深度解析
3.1 语法版本声明与命名空间
在编写 .proto 文件时,首行必须通过 syntax 指定版本。
package 声明决定了生成代码中的命名空间(Namespace),是隔离不同业务模块数据结构的唯一手段。
3.2 标量数据类型与编码特征映射
Protobuf 定义了一套通用的标量类型,下表展示了其与 C++ 类型的对应关系及编码机制:
| .proto 类型 | 特性说明 | C++ 类型 | 编码代价 |
|---|---|---|---|
| double | 双精度浮点数 | double | 8 字节定长 |
| float | 单精度浮点数 | float | 4 字节定长 |
| int32 | 变长编码,适用于正数 | int32 | 1-5 字节 |
| sint32 | ZigZag 编码,高效处理负数 | int32 | 1-5 字节 |
| uint32 | 变长编码,无符号 | uint32 | 1-5 字节 |
| fixed32 | 定长编码,适合大数值 | uint32 | 4 字节定长 |
| bool | 布尔逻辑 | bool | 1 字节 |
| string | UTF-8 或 ASCII 字符串 | string | 1 字节长度 + 内容 |
| bytes | 二进制原数据 | string | 1 字节长度 + 内容 |
3.3 字段编号的分配逻辑与物理意义
每个字段后的 = 1, = 2 并非默认值,而是该字段在二进制流中的唯一标签。
- 编号范围:1, 536,870,911,其中 19000, 19999 为预留区间。
- 性能优化:编号 1-15 占用 1 个字节存储(包括 Tag 和类型信息),16-2047 占用 2 个字节。核心、高频访问的字段务必分配 1-15 之间的编号。
第四章 通讯录 1.0 基础序列化工程实践
4.1 编写协议定义文件 contacts.proto
通过以下代码定义最基础的联系人信息结构:
protobuf
syntax="proto3";
// 首行:语法指定行
package contacts; // 命名空间声明
// 联系人 message 的定义
message PeopleInfo
{
// 姓名
string name = 1;
// 年龄
int32 age = 2;
}4.2 调用编译器生成 C++ 源代码
在终端执行如下指令:
bash
protoc --cpp_out=. contacts.proto编译成功后,工作目录下将新增 contacts.pb.h 与 contacts.pb.cc。
若需指定路径,可使用 -I 参数:
bash
protoc -I fast_start/ --cpp_out=fast_start/ contacts.proto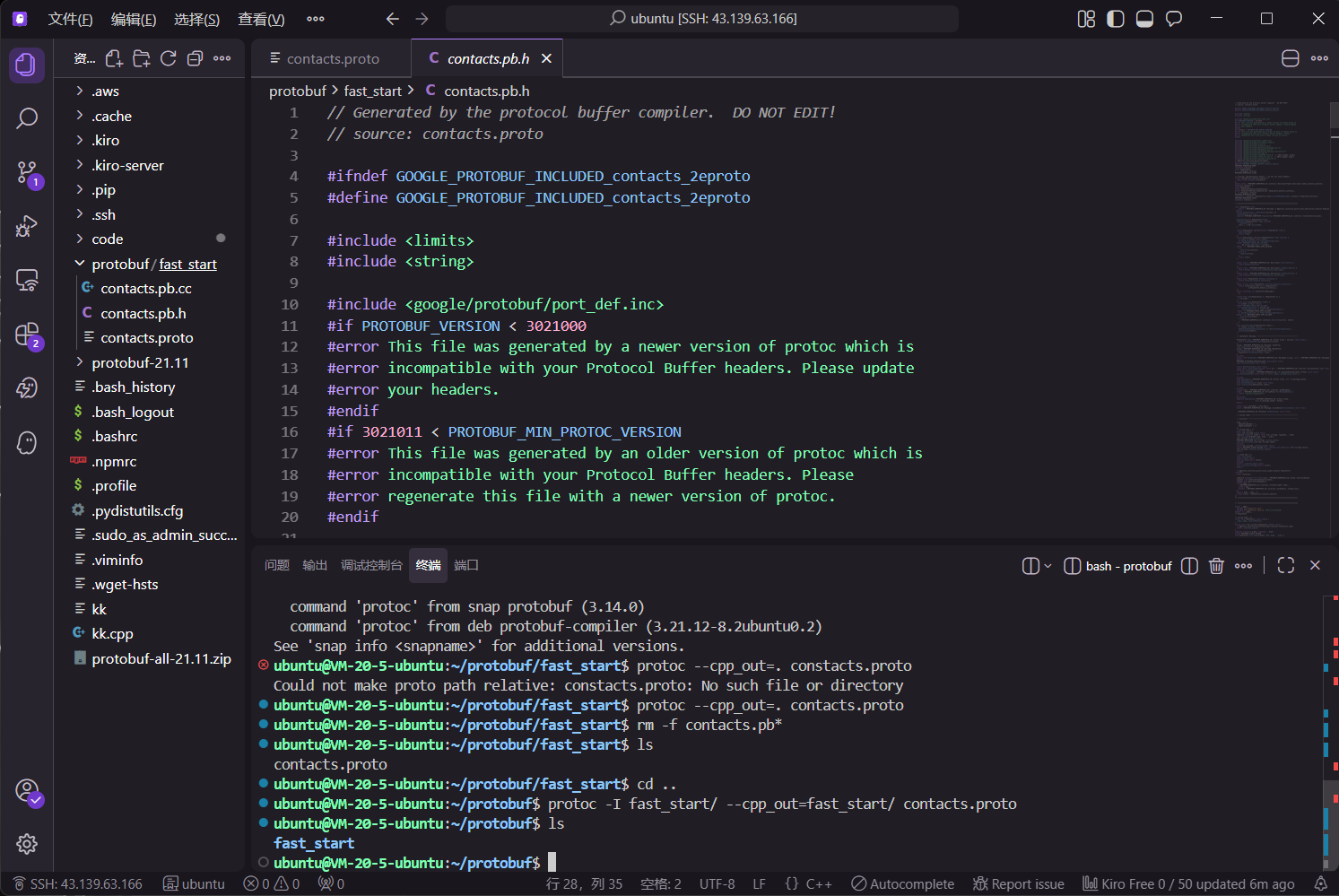
4.3 序列化与反序列化全过程实现
编写业务代码 main.cc,展示如何调用生成的 API 进行数据转换:
cpp
#include <iostream>
#include "contacts.pb.h" // 包含生成的头文件
int main()
{
// 容器,用于接收序列化后的结果
std::string people_str;
{
// 1. 序列化过程:对象 -> 二进制字节序列
contacts::PeopleInfo people; // 实例化生成的类
people.set_name("张三");
people.set_age(20);
if(!people.SerializeToString(&people_str))
{
std::cerr << "序列化失败" << std::endl;
return -1;
}
std::cout << "序列化成功,结果大小:" << people_str.size() << " 字节" << std::endl;
}
{
// 2. 反序列化过程:二进制字节序列 -> 对象
contacts::PeopleInfo people;
if(!people.ParseFromString(people_str))
{
std::cerr << "反序列化失败" << std::endl;
return -1;
}
std::cout << "反序列化成功,结果如下:" << std::endl
<< "姓名:" << people.name() << std::endl
<< "年龄:" << people.age() << std::endl;
}
return 0;
}4.4 编译与运行逻辑
使用 g++ 进行链接编译,必须注意链接 protobuf 动态库并开启 C++11 支持:
bash
g++ -o code main.cc contacts.pb.cc -std=c++11 -lprotobuf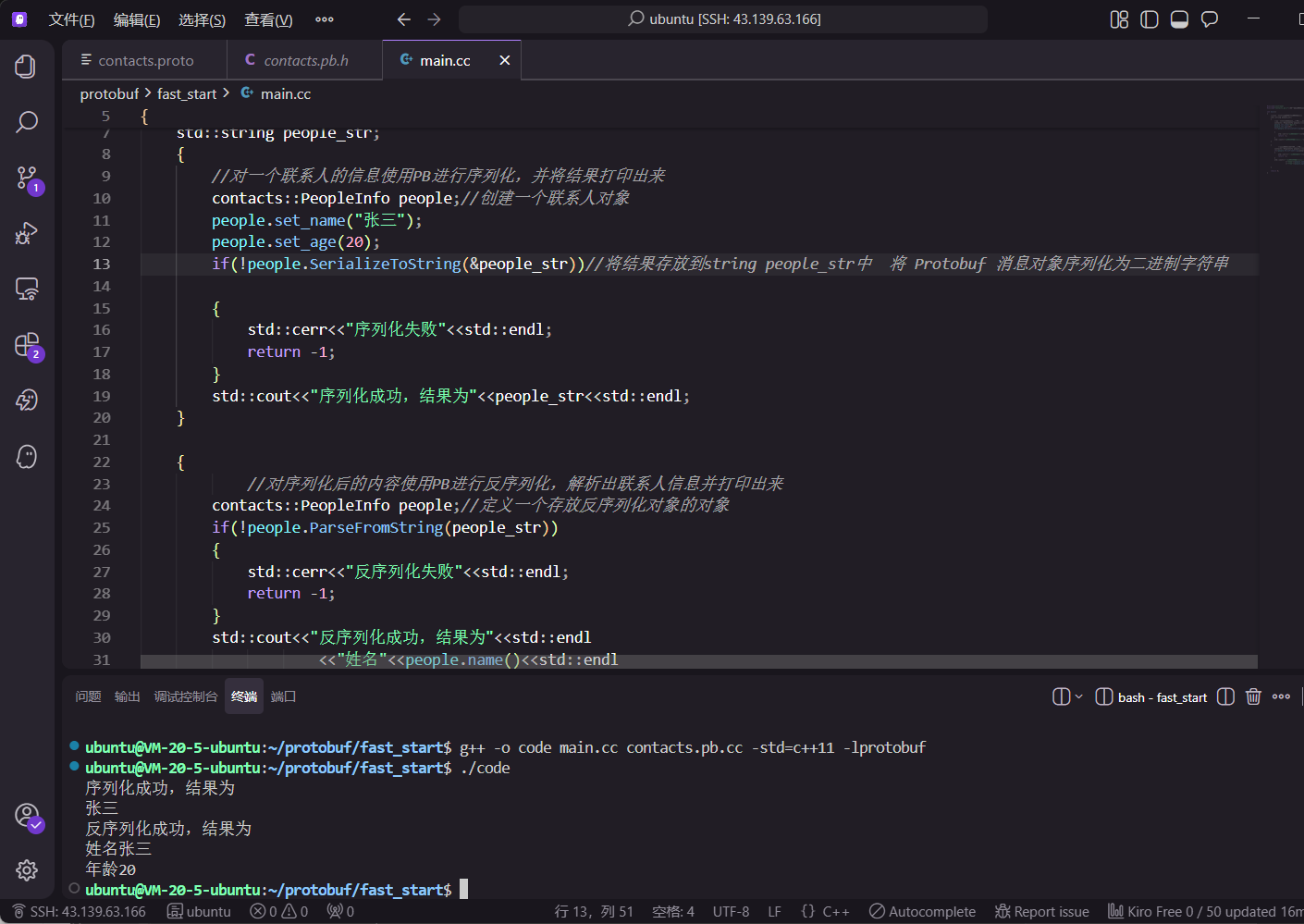
程序成功运行,证明了 Protobuf 将内存对象压缩为紧凑二进制流并完整恢复的能力。
如上图所示,生成的 .pb.cc 承载了底层的内存管理与字段校验逻辑,业务层代码仅需关注接口调用。
第五章 字段规则进阶与消息复杂嵌套
5.1 修饰符规则解析
在 Proto3 中,字段修饰符决定了数据的存在形式:
- singular:默认项。表示该字段可以出现 0 次或 1 次。
- repeated :重复项。表示该字段可出现任意多次,逻辑上映射为 C++ 的
std::vector或类似动态数组结构。
5.2 消息嵌套与 import 机制
在实际工程中,数据结构往往是多维嵌套的。
protobuf
syntax="proto3";
package contacts2;
// 嵌套定义方式
message PeopleInfo
{
string name = 1;
int32 age = 2;
// 内部定义消息类
message Phone
{
string number = 1;
}
// 声明数组类型的电话信息
repeated Phone phone = 3;
}若字段类型定义在外部文件,需使用 import 关键字。
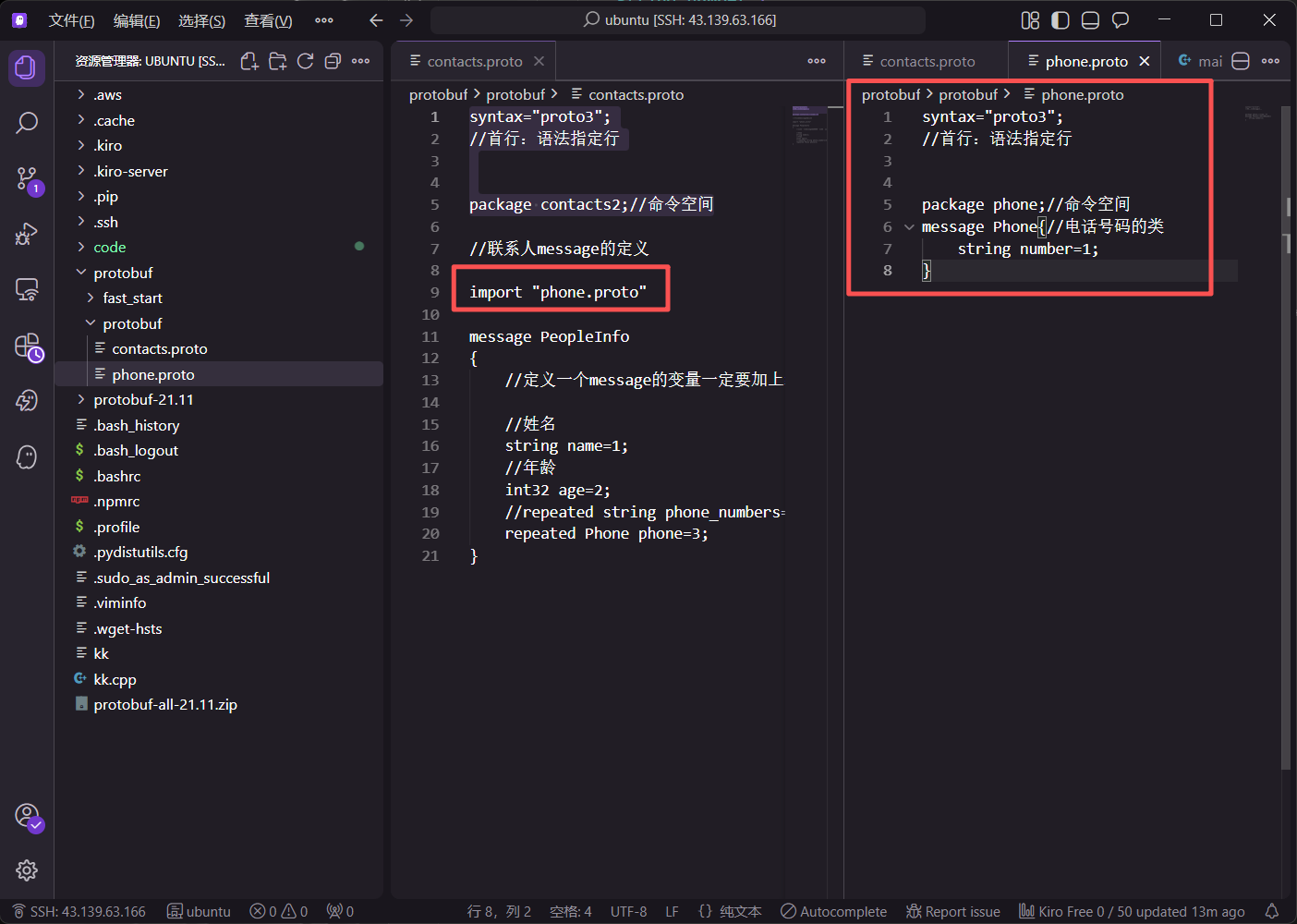
引用外部定义的 Phone 消息时,需结合 package 路径:
protobuf
import "phone.proto";
// ...
repeated phone.Phone phone = 3;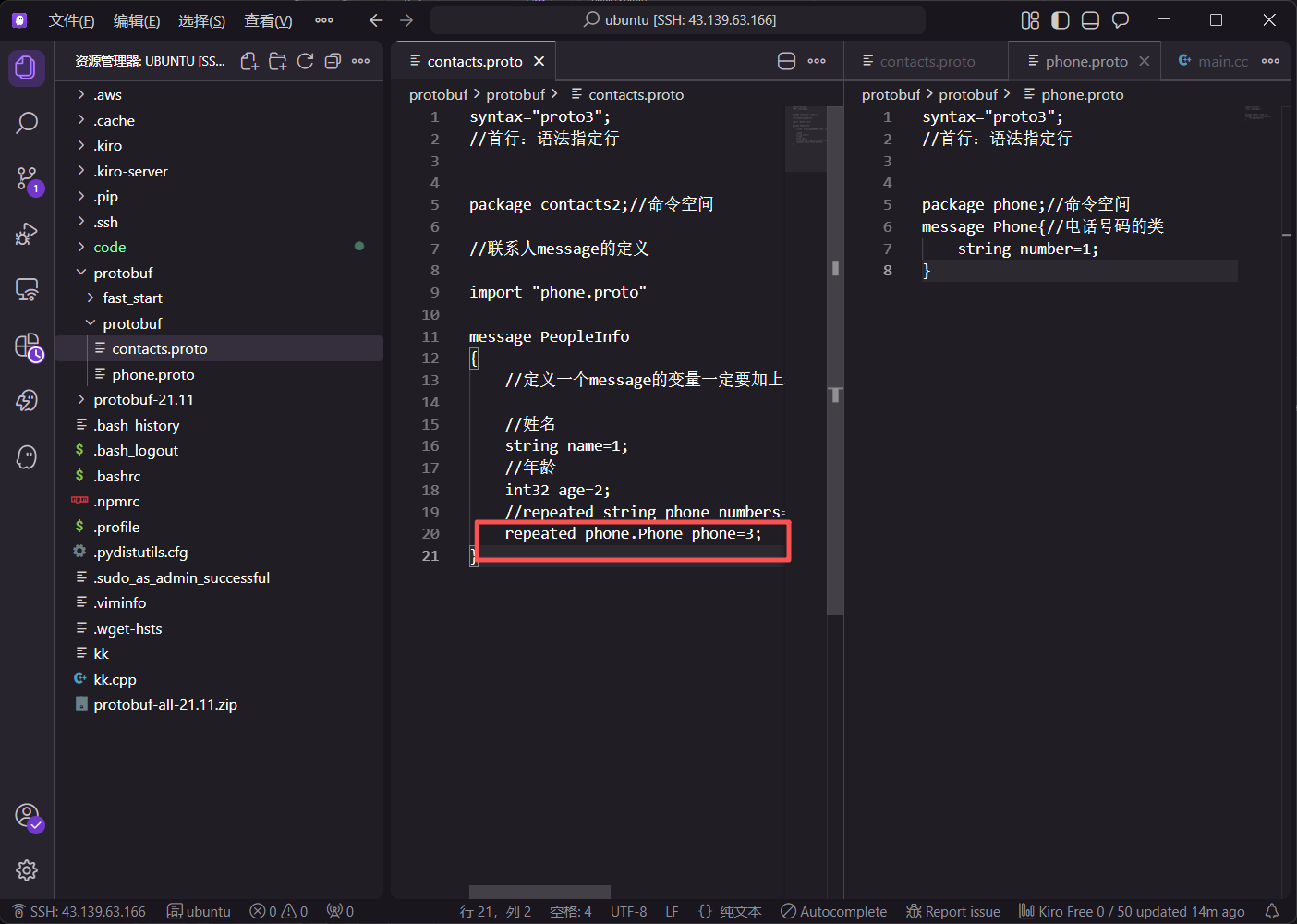
第六章 通讯录 2.0:高性能持久化系统设计
6.1 复合通讯录协议定义
为了支持多个联系人的管理,定义顶层消息 Contacts2:
protobuf
syntax="proto3";
package contacts2;
message PeopleInfo {
string name = 1;
int32 age = 2;
message Phone {
string number = 1;
}
repeated Phone phone = 3;
}
message Contacts2 {
repeated PeopleInfo contacts = 1;
}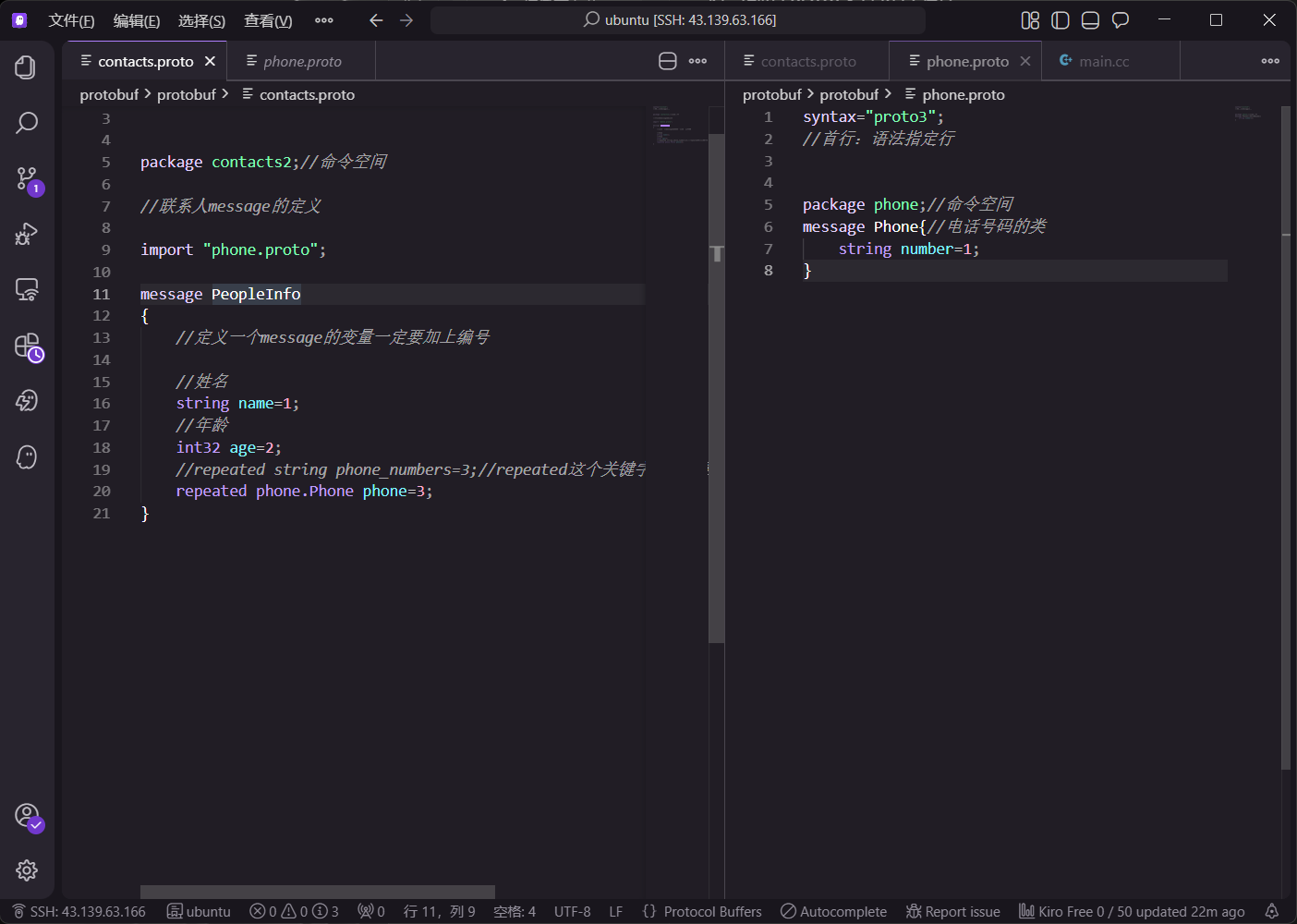
编译成功,出现了.h文件了
执行编译指令后,编译器会为 repeated 字段生成 add_ 前缀的方法,返回一个可操作的新对象指针。

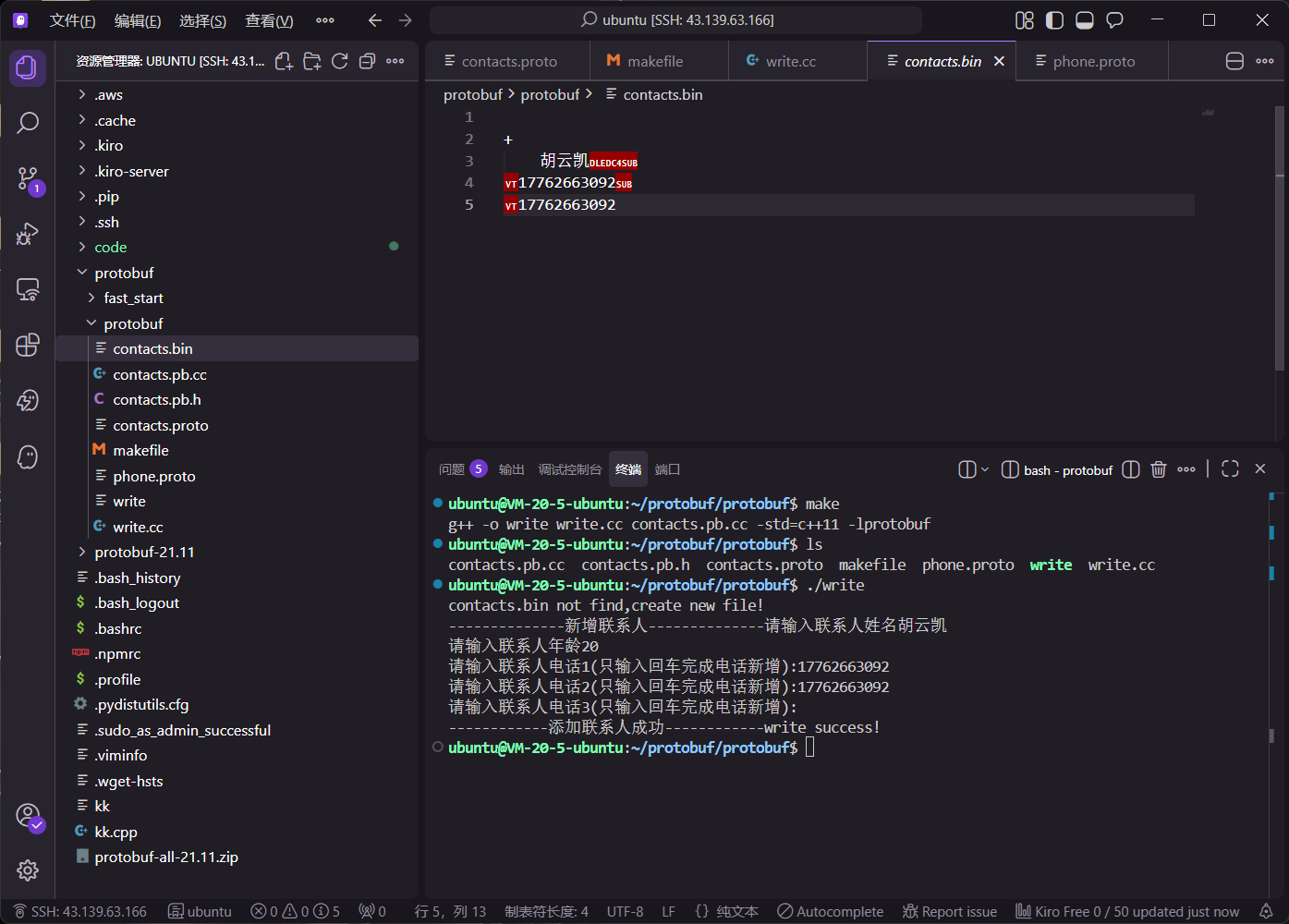
6.2 写入端实现:数据持久化至二进制文件
在 write.cc 中,结合 fstream 库实现通讯录的新增与存储:
cpp
#include <iostream>
#include <fstream>
#include "contacts.pb.h"
using namespace std;
// 新增联系人逻辑
void AddPeopleInfo(contacts2::PeopleInfo* people)
{
cout << "--------------新增联系人--------------" << endl;
cout << "请输入联系人姓名: ";
string name;
getline(cin, name);
people->set_name(name);
cout << "请输入联系人年龄: ";
int age;
cin >> age;
people->set_age(age);
cin.ignore(256, '\n'); // 清除输入缓冲区
for(int i = 0; ; i++)
{
cout << "请输入联系人电话" << i + 1 << "(回车结束): ";
string number;
getline(cin, number);
if(number.empty()) break;
// repeated 字段使用 add_ 方法分配空间
contacts2::PeopleInfo_Phone* phone = people->add_phone();
phone->set_number(number);
}
cout << "------------添加联系人成功------------" << endl;
}
int main()
{
contacts2::Contacts2 contacts;
// 1. 读取历史数据
fstream input("contacts.bin", ios::in | ios::binary);
if(!input) {
cout << "未发现历史文件,将创建新文件" << endl;
} else if(!contacts.ParseFromIstream(&input)) {
cerr << "解析历史文件失败" << endl;
input.close();
return -1;
}
// 2. 添加新数据
AddPeopleInfo(contacts.add_contacts());
// 3. 序列化写回文件
fstream output("contacts.bin", ios::out | ios::trunc | ios::binary);
if(!contacts.SerializeToOstream(&output)) {
cerr << "写入文件失败" << endl;
return -1;
}
cout << "数据已成功保存至 contacts.bin" << endl;
return 0;
}运行后,当前目录将产生一个无法直视读取的 contacts.bin 二进制文件。
6.3 读取端实现:二进制数据流解析
read.cc 负责将二进制内容加载回内存并打印结构化信息:
cpp
#include <iostream>
#include <fstream>
#include "contacts.pb.h"
using namespace std;
void PrintContacts(const contacts2::Contacts2& contacts)
{
for(int i = 0; i < contacts.contacts_size(); i++)
{
const contacts2::PeopleInfo& people = contacts.contacts(i);
cout << "-------------联系人 " << i + 1 << " -------------" << endl;
cout << "姓名: " << people.name() << endl;
cout << "年龄: " << people.age() << endl;
for(int j = 0; j < people.phone_size(); j++)
{
const auto& phone = people.phone(j);
cout << "电话 " << j + 1 << ": " << phone.number() << endl;
}
}
}
int main()
{
contacts2::Contacts2 contacts;
fstream input("contacts.bin", ios::in | ios::binary);
if(!contacts.ParseFromIstream(&input)) {
cerr << "数据反序列化失败" << endl;
return -1;
}
PrintContacts(contacts);
return 0;
}通过 read 程序,原本在二进制文件中杂乱的位信息被重新映射回 C++ 对象模型中。
6.4 工程构建配置 Makefile
为了自动化管理多个程序的编译链路,设计如下 Makefile:
makefile
all: write read
read: read.cc contacts.pb.cc
g++ -o $@ $^ -std=c++11 -lprotobuf
write: write.cc contacts.pb.cc
g++ -o $@ $^ -std=c++11 -lprotobuf
.PHONY: clean
clean:
rm -f write read
第七章 二进制流深度分析与调试工具链
7.1 hexdump 工具的底层观察
利用 Linux 系统的 hexdump 命令,可以观察到 Protobuf 序列化后的物理存储形式。
bash
hexdump -C contacts.bin
在输出中,可见字符串 "张三" 的 UTF-8 编码,而整型数值则被压缩存储。由于采用了 Varint 编码,小整数(如年龄)仅占用一个字节。
7.2 protoc --decode 协议解码技巧
在调试阶段,若无法查看程序源码但持有 .proto 定义,可使用编译器自带的解码功能。
bash
protoc --decode=contacts2.Contacts2 contacts.proto < contacts.bin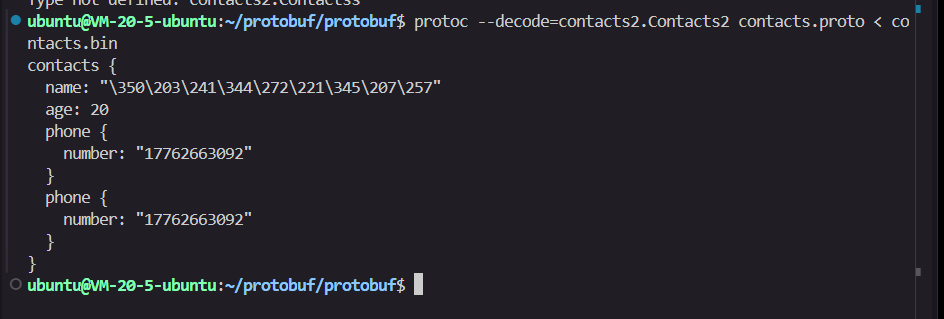
此指令将 contacts.bin 的标准输入根据 Contacts2 类型的逻辑结构进行强行解码。输出结果为人类可读的文本格式。需要注意,中文字符在此模式下常以八进制转义序列显示。
第八章 核心技术点总结
- 强类型约束:Protobuf 通过代码生成机制,将数据交换格式上升为语言层面的强类型类,极大减少了由于字段拼写错误导致的 Bug。
- 空间效率:基于 Varint 变长编码与 Tag-Length-Value (TLV) 存储模式,数据体积远小于 JSON。
- 安全性:二进制格式不具备自描述性(除非持有 .proto 文件),增加了数据被直接破解的难度。
- 工程解耦 :开发者只需关注
.proto文件的契约定义,前后端即可并行开发,自动生成的代码屏蔽了复杂的序列化算法实现细节。