文章目录
- [主流AI绘画工具技术对比:Stable Diffusion 3与Midjourney V6的架构差异解析](#主流AI绘画工具技术对比:Stable Diffusion 3与Midjourney V6的架构差异解析)
-
- [一、 引言:殊途同归的视觉创造革命](#一、 引言:殊途同归的视觉创造革命)
- [二、 核心架构技术解析](#二、 核心架构技术解析)
-
- [2.1 Stable Diffusion 3:拥抱Transformer的开源先锋](#2.1 Stable Diffusion 3:拥抱Transformer的开源先锋)
-
- 关键技术突破一:多模态扩散Transformer(MMDiT)
- [关键技术突破二:重新加权的整流流(Rectified Flow)](#关键技术突破二:重新加权的整流流(Rectified Flow))
- 模型规模与可扩展性
- [2.2 Midjourney V6:闭源优化的审美大师](#2.2 Midjourney V6:闭源优化的审美大师)
- [三、 架构哲学对比:开放与专精的路线分歧](#三、 架构哲学对比:开放与专精的路线分歧)
- [四、 性能表现与实用能力对比](#四、 性能表现与实用能力对比)
-
- [4.1 图像质量与审美风格](#4.1 图像质量与审美风格)
- [4.2 提示词理解与交互方式](#4.2 提示词理解与交互方式)
- [4.3 专业领域应用对比:以时装设计为例](#4.3 专业领域应用对比:以时装设计为例)
- [五、 实际部署与开发集成](#五、 实际部署与开发集成)
-
- [5.1 Stable Diffusion 3的部署与扩展](#5.1 Stable Diffusion 3的部署与扩展)
- [5.2 Midjourney V6的交互模式](#5.2 Midjourney V6的交互模式)
- [六、 技术发展趋势与未来展望](#六、 技术发展趋势与未来展望)
-
- [6.1 模型架构的融合趋势](#6.1 模型架构的融合趋势)
- [6.2 应用场景的专业化细分](#6.2 应用场景的专业化细分)
- [6.3 实时生成与交互创作](#6.3 实时生成与交互创作)
- [七、 结论与选型建议](#七、 结论与选型建议)
主流AI绘画工具技术对比:Stable Diffusion 3与Midjourney V6的架构差异解析
在AI绘画领域,Stable Diffusion 3 和 Midjourney V6 无疑是当前最受瞩目的两款"明星模型"。它们都代表了文生图技术的顶尖水平,但在技术路径、架构哲学和适用场景上却存在显著差异。本文将深入解析这两大工具的技术架构差异,从底层原理到实际应用,为开发者和创作者提供全面的技术视角和选型指南。

一、 引言:殊途同归的视觉创造革命
无论是开源社区的宠儿Stable Diffusion 3,还是凭借卓越审美俘获用户的Midjourney V6,它们共同的目标是将人类的语言描述转化为高质量的视觉图像。然而,"开源"与"闭源"、"可控性"与"审美性"、"技术民主"与"体验优先" 的路线分野,决定了它们从模型架构到使用方式的根本不同。
这种差异不仅体现在技术细节上,更深刻影响了整个AI绘画生态的发展。SD3以其开放性和可扩展性,推动了技术的快速迭代和行业应用的深度融合;而Midjourney V6则通过极致的用户体验和审美输出,定义了大众对AI绘画能力的认知边界。
二、 核心架构技术解析
2.1 Stable Diffusion 3:拥抱Transformer的开源先锋
SD3标志着Stability AI在技术架构上的一次重大革新。它摒弃了传统U-Net主干,转向了更具扩展性的 Diffusion Transformer (DiT) 架构。
关键技术突破一:多模态扩散Transformer(MMDiT)
SD3的核心创新在于提出了MMDiT架构 ,专门针对文本到图像生成任务进行了优化。由于需要同时处理文本和图像两种截然不同的信息模态,SD3为每种模态使用了两组独立的权重。这相当于为文本和图像分别设置了独立的Transformer,但在执行注意力机制时,会将两种信息的数据序列合并,让它们在各自领域内独立工作的同时,能够相互参考和融合。
这种设计的优势显而易见:图像和文本信息之间可以更有效地流动和交互,从而显著提升模型对提示词的理解和文本渲染能力。这也解释了为何SD3在生成含文字图像方面表现尤为突出。
python
# 概念性代码:MMDiT中多模态注意力机制的简化示意
# 注意:此为原理示意,非实际可运行代码
class MultimodalAttention(nn.Module):
"""
简化的多模态注意力机制示意
图像token和文本token拥有独立权重,但在注意力计算中交互
"""
def __init__(self, dim, num_heads):
super().__init__()
# 为图像和文本模态分别设置独立的权重矩阵
self.image_qkv = nn.Linear(dim, dim * 3) # 图像QKV投影
self.text_qkv = nn.Linear(dim, dim * 3) # 文本QKV投影
self.num_heads = num_heads
self.dim = dim
def forward(self, image_tokens, text_tokens):
batch_size = image_tokens.size(0)
# 分别处理图像和文本的QKV
image_qkv = self.image_qkv(image_tokens)
text_qkv = self.text_qkv(text_tokens)
# 合并两种模态的序列以进行交叉注意力计算
combined_tokens = torch.cat([image_tokens, text_tokens], dim=1)
combined_qkv = torch.cat([image_qkv, text_qkv], dim=1)
# 拆分Q、K、V
q, k, v = combined_qkv.chunk(3, dim=-1)
# 注意力计算(简化版)
attn_output = self.compute_attention(q, k, v)
# 分离图像和文本输出
image_output = attn_output[:, :image_tokens.size(1), :]
text_output = attn_output[:, image_tokens.size(1):, :]
return image_output, text_output关键技术突破二:重新加权的整流流(Rectified Flow)
SD3采用了整流流(Rectified Flow, RF) 训练策略。RF将训练数据和噪声沿着直线轨迹连接起来,使推理路径更加直接,从而能够以更少的步骤完成图像生成。
更关键的是,SD3在训练流程中引入了一种创新的轨迹采样计划,特别增加了对轨迹中间部分的权重,这些部分的预测任务更具挑战性。这种重新加权的RF方法确保了即使采样步骤增加,生成性能也不会下降,反而能持续提升。
模型规模与可扩展性
SD3提供了从8亿到80亿参数的多个版本,以适应不同的硬件条件和应用场景。这种阶梯式的模型配置体现了开源模型的灵活性。其中,SD3 Medium作为20亿参数的版本,在图像细节捕捉、复杂提示理解及文字拼写能力上表现突出。
技术报告显示,随着模型大小和训练步骤的增加,验证损失呈现出平滑的下降趋势,且扩展趋势没有出现饱和迹象,这意味着未来SD3的性能还有继续提高的空间。
2.2 Midjourney V6:闭源优化的审美大师
与SD3的激进革新不同,Midjourney V6选择在经过验证的U-Net扩散架构上进行深度优化,专注于提升图像质量和用户体验。
专有架构优化
Midjourney V6基于改进的U-Net扩散架构,引入了专有的注意力机制优化 和多尺度特征融合技术。虽然具体技术细节未公开,但可以推测其在艺术风格学习和提示词理解方面进行了特殊优化。
Midjourney团队在Discord上透露,V6是"团队从头开始训练的第三个模型",开发过程持续了9个月。这表明V6并非简单的迭代更新,而是经过了彻底的重设计和训练。
五大核心升级
Midjourney官方总结了V6的五大升级:
- 更精确且更长的提示响应:V6能够理解更复杂、更详细的提示词
- 改进的连贯性和模型知识:图像内部逻辑更一致,常识错误减少
- 图像生成和混合(remix)优化:改进了图像混合功能
- 基础文字绘制功能:首次支持在图像中生成简单文字(需用引号标注)
- 增强的放大器功能:新增"subtle"和"creative"两种放大模式,分辨率提升两倍
其中,文字绘制功能的加入是V6最受关注的升级之一。用户只需将想要绘制的文字加上引号(如"Hello World!"),V6就能在图像中尝试生成这些文字。虽然这项功能仍处于初级阶段,但代表了Midjourney在提示词遵循方面的重要进步。
三、 架构哲学对比:开放与专精的路线分歧
下表从多个维度对比了SD3与Midjourney V6的架构哲学差异:
| 对比维度 | Stable Diffusion 3 | Midjourney V6 |
|---|---|---|
| 核心架构 | 多模态扩散Transformer(MMDiT) | 专有优化U-Net扩散模型 |
| 训练策略 | 重新加权的整流流(RF) | 未公开的专有训练方法 |
| 文本理解 | 三编码器策略(两个CLIP + T5) | 未公开,但支持更长、更精确的提示 |
| 可控性 | 高,支持多种插件和扩展(ControlNet、LoRA等) | 有限,主要通过提示词和参数控制 |
| 部署方式 | 本地部署、云API、开源代码 | 仅限Discord平台,云端服务 |
| 透明度 | 高度透明,发布技术报告和模型权重 | 闭源,仅提供API和用户界面 |
| 生态定位 | 技术民主化,开发者友好 | 用户体验优先,创作者友好 |
从技术路线上看,SD3选择了**"架构革新+完全开源"** 的道路,通过引入Transformer架构和开放整个技术栈,寻求技术上的突破和生态的繁荣。而Midjourney V6则坚持**"渐进优化+体验闭环"** 的策略,在不公开技术细节的前提下,专注于提升生成质量和用户体验。
这两种路径各有利弊。SD3的开放性带来了无与伦比的灵活性和扩展性,但也伴随着较高的技术门槛和部署复杂度。Midjourney V6则提供了"开箱即用"的优质体验,但用户受限于平台功能,无法进行深度定制或本地部署。
四、 性能表现与实用能力对比
4.1 图像质量与审美风格
在图像质量方面,两款模型都达到了前所未有的高度,但侧重点不同。
Midjourney V6 在审美一致性 和艺术风格方面表现突出。用户普遍反馈V6在细节密度、材质质感、光影表现和结构真实性上都有"巨幅提升"。特别是在人物刻画、风景渲染和静物表现上,V6展现出了接近摄影级别的真实感。其独特的"美学优化"使得即使简单的提示词也能产生视觉上令人愉悦的结果。
Stable Diffusion 3 则在提示词遵循 和文本渲染方面建立了新标杆。根据技术报告,通过人类评价测试,SD3在字体设计和对提示的精准响应方面,超过了DALL·E 3、Midjourney v6和Ideogram v1。这意味着对于需要精确控制图像内容、特别是包含文字元素的场景,SD3可能更为可靠。

4.2 提示词理解与交互方式
两款模型对提示词的处理方式反映了它们不同的设计理念。
Midjourney V6需要用户重新学习提示策略。创始人David Holz明确表示"V6的提示与V5有很大不同,你需要重新学习如何提示"。V6更倾向于自然语言描述,建议用户避免使用无关紧要的词如"award winning"、"photorealistic"、"4k"等。有效的V6提示词更像是详细的场景描述,采用"场景+主体+细节+美学风格"的结构。
python
# Midjourney V6风格的有效提示词示例
prompt = """
三个不同的美女朋友坐在沙滩上面向镜头微笑。
中间的是一个开朗的金发白人女性,穿着短裤和红色色背心。
左边的朋友是一个黑发美国女孩,穿着比基尼和透明的裙子。
右边的朋友是一个红发英国女孩,穿着比基尼。
背景可以看到海,海上有船和飞翔的海鸥。
Agfa Vista 200拍摄的中景镜头。
"""相比之下,SD3保持了更传统的提示词处理方式,但通过其强大的多模态理解能力,能够更精确地响应技术性描述。对于需要精确控制材料属性、物理特性或专业参数的场景(如工业设计、时装设计),SD3表现更佳。
4.3 专业领域应用对比:以时装设计为例
在时装设计领域,两款模型的差异尤为明显。阿里巴巴的一篇分析文章详细对比了它们在不同方面的表现:
| 能力维度 | Midjourney V6 | Stable Diffusion 3 |
|---|---|---|
| 面料纹理还原 | 宏观感知保真度高;微观纹理常被同质化或风格化 | 基于高分辨率面料扫描训练;可靠还原纤维级细节 |
| 垂坠物理一致性 | 风格连贯性强,但垂坠遵循构图逻辑多于重力/结构逻辑 | 整合了隐式布料模拟线索;褶皱源自锚点,符合生物力学约束 |
| 材料提示控制 | 依赖风格修饰词和品牌参考;纤维构成或表面处理细节有限 | 精确响应技术描述符:重量、纤维成分、机械性能等 |
| 变体一致性 | 审美变化大---适合灵感,不利于迭代 | 使用种子锁定+特定面料库LoRA微调时再现性更高 |
| 设计工作流集成 | 仅限云端;与Adobe Suite或CLO3D无原生集成 | 本地或API运行;支持直接导出带深度图、法线图的.png文件 |
一位伦敦女装设计师的实际工作流测试显示,当使用Midjourney V6生成一件单肩垂坠连衣裙时,结果"令人惊叹---优雅、富有氛围感、达到杂志水准",但当她将图像导入CLO3D进行版型验证时,发现了不一致之处:褶皱密度与面料克重不相关,下摆弧度暗示的弹性超过了面料实际特性。
而使用Stable Diffusion 3配合ControlNet(使用基础人台姿势的深度图)时,输出既保持了艺术品质,又增加了可验证的物理属性:褶皱间距与实验室测量值匹配,下摆展开与ASTM D1388垂坠测试标准一致,肩部接缝显示了真实的压缩致薄现象---这对版型师调整缝份和衬布至关重要。
五、 实际部署与开发集成
5.1 Stable Diffusion 3的部署与扩展
SD3提供了灵活的部署选项,从消费级硬件到企业级服务器都能找到合适的配置。
本地部署示例:
python
# 使用Stability AI官方SDK进行图像生成
from stability_sdk import client
# 初始化API客户端
stability_api = client.StabilityInference(
key='YOUR_API_KEY',
engine='stable-diffusion-v3' # 指定使用SD3引擎
)
# 基础生成调用
answers = stability_api.generate(
prompt="cyberpunk cat wearing neon goggles",
width=1024,
height=1024,
sampler='k_euler_ancestral', # 采样器选择
steps=30 # 采样步骤
)
# 处理并保存生成的图像
for resp in answers:
for artifact in resp.artifacts:
if artifact.finish_reason == client.FINISH_REASON_SUCCESS:
with open(f"./generated_{artifact.seed}.png", "wb") as f:
f.write(artifact.binary)ComfyUI工作流集成:
对于高级用户,SD3可以通过ComfyUI等可视化工具进行更精细的控制。典型的工作流包括文本编码器 → SD3基础模型 → 高分辨率修复 → 面部细化等节点。用户还可以通过安装自定义节点包来扩展功能,如使用LCM-LoRA加速采样。
性能优化技巧包括:
- 将VAE设置为taesd3可减少30%显存占用
- 对连续帧生成启用--medvram模式
- 使用Tiled Diffusion插件处理超大尺寸图像
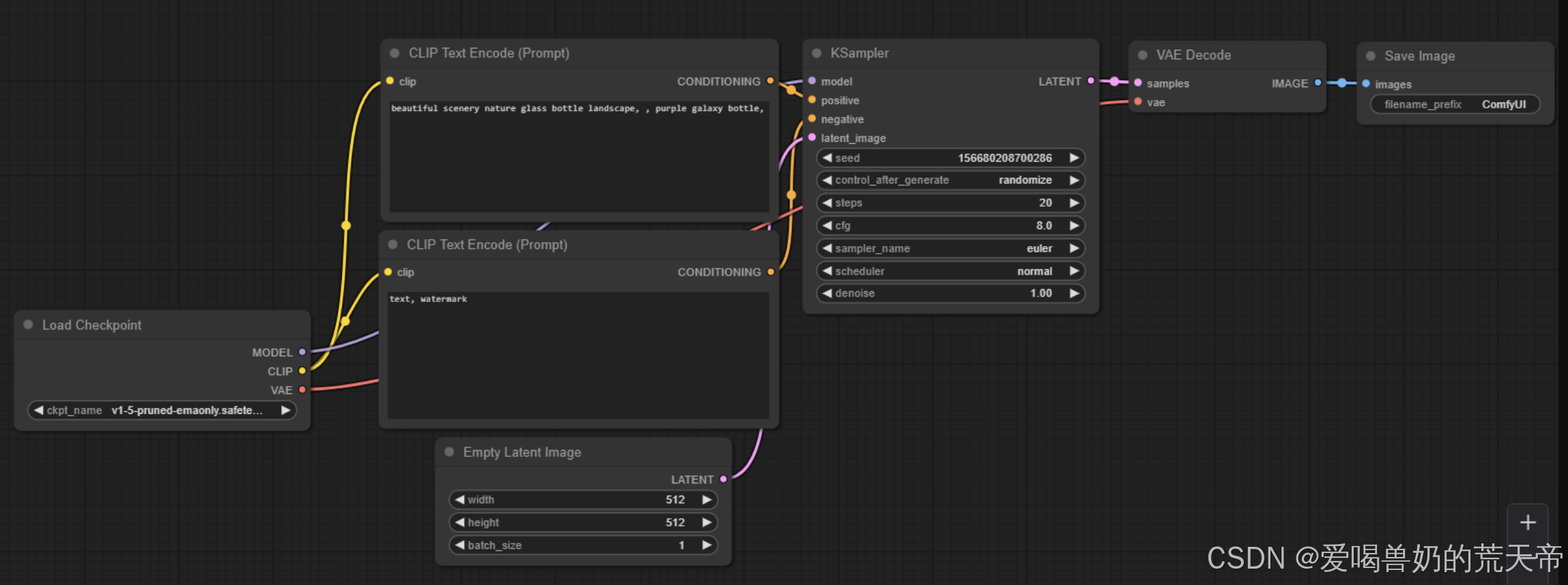
5.2 Midjourney V6的交互模式
与SD3的开发友好型部署不同,Midjourney V6完全通过Discord平台提供交互服务。用户可通过三种方式使用V6:
- 在Midjourney Discord服务器中键入斜杠命令"/settings",然后选择V6
- 在给Midjourney机器人的直接消息中键入命令,使用顶部下拉菜单选择V6
- 在提示词后手动输入"--v 6.0"参数
这种集中化的服务模式确保了所有用户获得一致的体验,也使Midjourney团队能够快速迭代和优化模型,但代价是用户无法进行本地化定制或与自有系统深度集成。
六、 技术发展趋势与未来展望
6.1 模型架构的融合趋势
从技术发展角度看,SD3采用的Transformer架构代表了文生图模型的未来方向。DiT架构的扩展性优势已经在Sora等视频生成模型中得到了验证。预计未来会有更多模型采用类似架构,特别是在需要处理多模态输入或长序列数据的场景中。
同时,Midjourney可能在未来版本中借鉴一些开源架构的优点,同时保持其专有优化和用户体验优势。两条技术路线可能会在竞争中相互借鉴、融合发展。
6.2 应用场景的专业化细分
随着技术成熟,AI绘画工具将越来越向专业化方向发展。SD3的开源特性使其更容易针对特定领域进行微调和优化,比如:
- 时尚设计(面料、垂坠模拟)
- 工业设计(材料、结构精确性)
- 建筑设计(尺寸、比例准确性)
- 教育内容(图文结合、知识准确性)
Midjourney则可能继续强化其在创意产业和大众市场的优势,专注于提升艺术表现力和用户体验,可能向动画、游戏美术等专业创作领域延伸。
6.3 实时生成与交互创作
两家公司都在探索生成速度的优化。SD3.5-Flash等变体通过创新的少步蒸馏算法,致力于在消费级设备上实现高效图像生成。而Midjourney也在不断优化V6的生成速度,在发布后不久就将速度提高了2.7倍。
未来,我们可能会看到更接近实时的AI绘画体验,以及更自然的交互式创作流程,使AI真正成为创作者思维的延伸。
七、 结论与选型建议
Stable Diffusion 3和Midjourney V6代表了AI绘画领域的两种成功范式,它们的架构差异根植于不同的产品哲学和目标用户。
选择Stable Diffusion 3,如果:
- 你需要对生成过程进行精细控制或自定义
- 你的应用涉及专业领域,需要精确的材料、物理属性还原
- 你希望将AI绘画能力集成到自有产品或工作流中
- 你有技术团队能够处理本地部署和优化
- 你的项目需要生成包含准确文字的图像
选择Midjourney V6,如果:
- 你优先考虑图像的美学质量和视觉冲击力
- 你需要快速获得高质量结果,无需复杂设置
- 你的使用场景更偏创意艺术而非技术制图
- 你不具备深度学习部署的技术资源或意愿
- 你重视社区氛围和即时反馈的创作体验
从行业影响看,SD3通过开源策略推动了整个生态的技术进步和应用创新,其架构思想已经影响了众多后续模型。而Midjourney V6则通过卓越的产品体验定义了AI绘画的质量标杆,激发了公众对这一技术的热情和想象。
无论选择哪条路径,我们都处在一个视觉创造民主化的历史时刻。这两大工具的竞争与发展,最终将使所有用户受益,推动AI绘画技术向更强大、更易用、更智能的方向演进。作为开发者或创作者,理解它们背后的技术差异,能帮助我们更好地利用这些强大工具,释放创造潜力。
技术永不止步:值得注意的是,就在近期,Stability AI又发布了SD3.5-Flash,通过"时间步共享"和"分时间步微调"等算法创新,进一步优化了少步生成的质量和设备兼容性。而Midjourney团队也必定在筹备下一次重大更新。在这个快速发展的领域,今天的前沿技术,明天可能就成为基础能力。保持学习、持续探索,才是应对技术变革的最佳策略。
扩展阅读与资源:
- Stable Diffusion 3技术报告 - 官方技术细节
- ComfyUI SD3工作流指南 - 可视化节点编辑器高级用法
- Midjourney官方文档 - 最新功能和使用技巧
- AI绘画模型技术深度解析 - 三大架构全面对比