在 openJiuwen 里把在线小工具搬回本地
今天我们只解决一件事:把你平时散落在各种网页里的小工具(JSON 格式化、时间戳转换、编码/解码)做成 openJiuwen 的插件,然后让智能体在对话里自动调用。做完以后,你不用再开一堆网站、复制粘贴、看广告,也不用纠结"我该用哪个在线工具"。
我会按"先跑通再优化"的顺序来,先确认平台启动没问题,再做一个最小能用的智能体,然后把插件做成"输入清楚、输出稳定、失败可解释"的工具,最后把插件挂到智能体上,用一段提示词把触发条件和兜底写死。过程中我会把我踩过的坑直接写出来,省得你重复掉坑里。
openJiuwen 相关链接(需要安装的同学去看官方步骤,我这里不展开安装过程):
https://gitcode.com/openJiuwen?utm_source=csdn
https://openJiuwen.com?utm_source=csdn
适用场景与不适用场景
什么时候用插件最划算
我一般看三个信号,满足得越多越值得做成插件。
你每天都在重复用同一种在线小工具,而且输入输出很固定;你希望智能体自己去做,而不是你手动复制粘贴处理完再塞回对话;你还想把团队常用的小能力沉淀下来,让新人直接用,不要靠口口相传。
哪些情况别用插件
有些场景我会直接劝退,不是插件不好,是它不值这个成本。
只用一次的小脚本,直接本地写完就结束,别为了"平台化"折腾;输入里带明确敏感信息(密钥、身份证号、客户数据),能不进智能体就不进,最稳的是离线处理;输出没有判断标准也别急着封装,插件最怕"看起来对但其实不对",最后你自己也不敢用。
前置条件与启动确认
访问入口与启动成功的标准
在浏览器打开 http://localhost:3000/。你能看到 openJiuwen 的首页/工作台,并且点得进"智能体管理"和"插件管理",就算启动成功。
如果你这里遇到浏览器提示证书/不安全链接,先别慌:本地服务常见。你只需要确保访问的是你本机的地址,不要把端口暴露到公网。
看到入口、点得进去,就算启动确认完成。
创建智能体(先跑通最小闭环)
创建一个"工具助手"智能体
你先别急着做一堆插件,先把最小闭环跑通:智能体能正常对话、能保存配置、后面才有资格谈"工具调用"。
打开智能体列表,直接从空白创建。名称和描述别写虚的,把边界写死就行,比如"只做格式化/转换,不写长文"。如果平台要求选模型/能力,先选你账号里能直接用的默认项,这一步只求跑通,不求最优。保存后进调试区,随便问一句,确认能正常回复。
完成标准很简单:你刷新页面回来还能找到这个智能体,并且它的配置没有丢。
创建完成后回到列表能看到它,说明第一步没白忙。
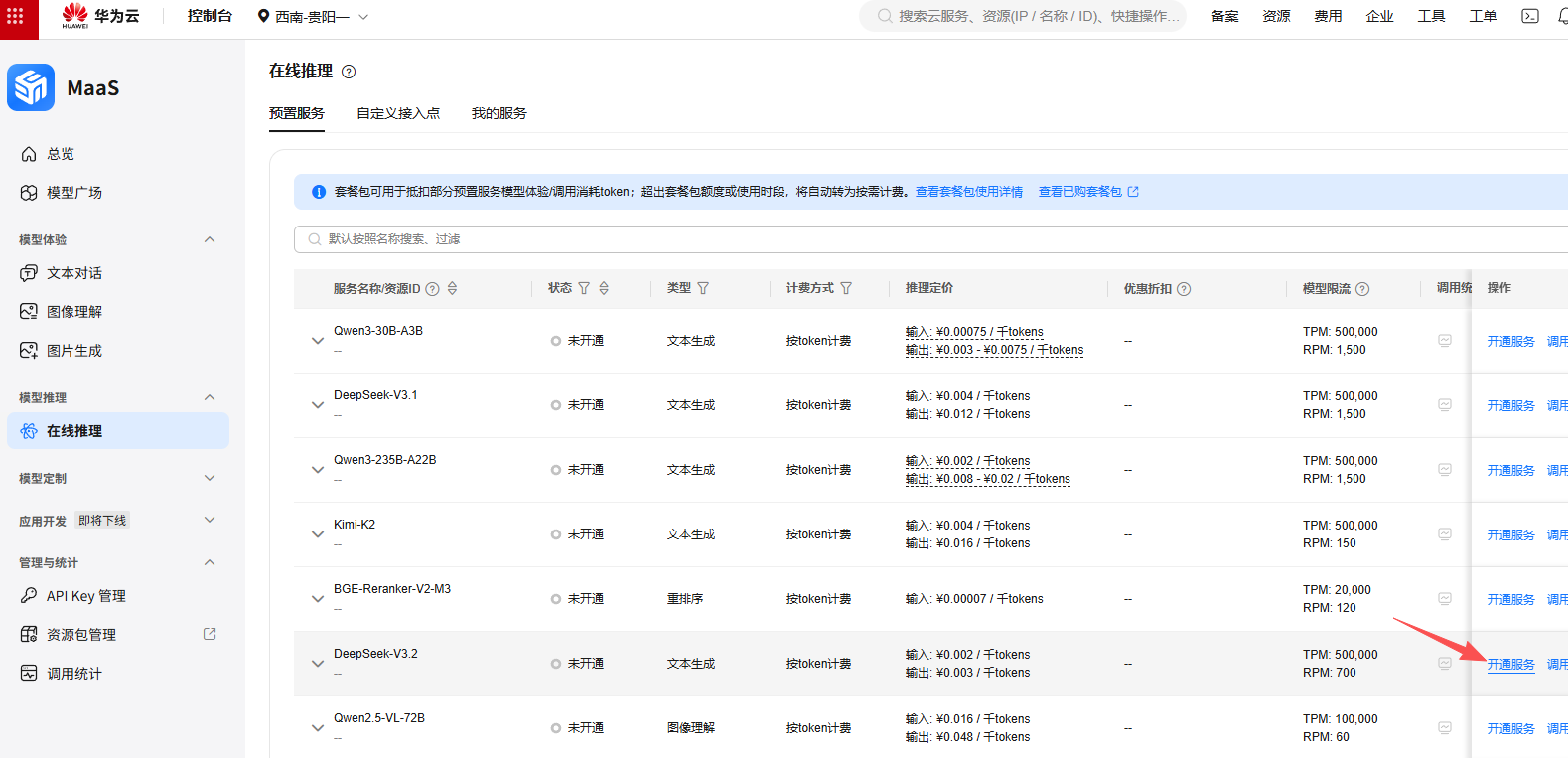
接下来,我们去开通模型。如图所示:
命名与边界(我个人的偏好)
我会把"智能体名"和"插件名"都写成可搜索的关键词,不搞花哨昵称。原因很现实:后面插件多了,你靠搜索找工具,不靠记忆力。
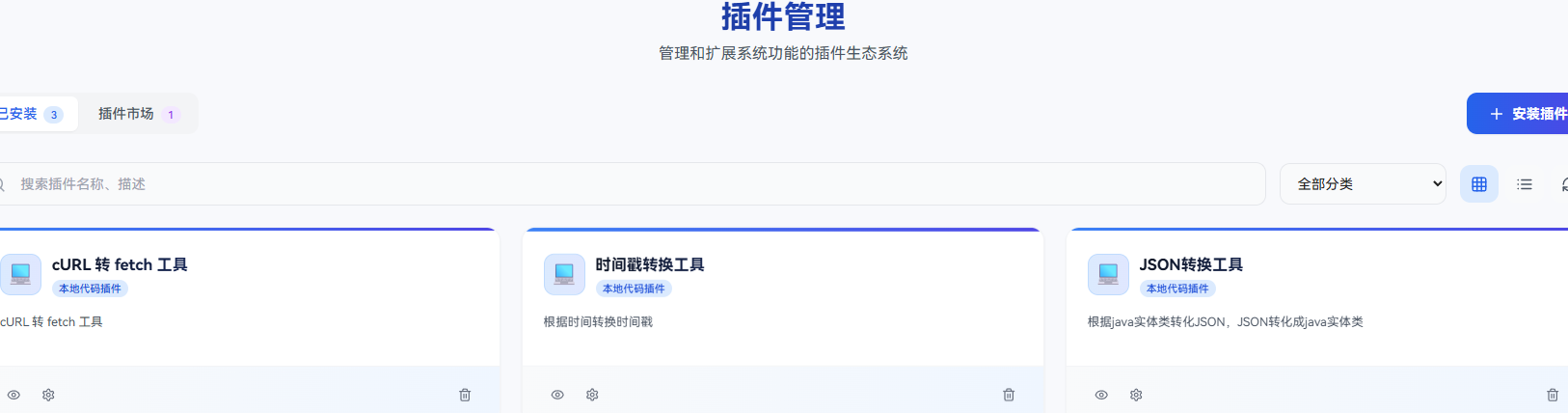
创建插件(把能力做成可调用的工具)
从入口到保存(能照着点)
先进入插件管理中心(在左侧导航)。点安装插件,先把名称和描述填好,最后再配置输入参数和输出结构。保存后不要急着去智能体里集成,先在插件侧把"测试调用"跑一遍。别跳过这一步,不然你后面会在智能体里瞎排查半小时,最后发现是插件本身就没稳定输出。
完成标准:插件列表里能搜到你的插件;同样输入重复测试三次,输出结构都一致。
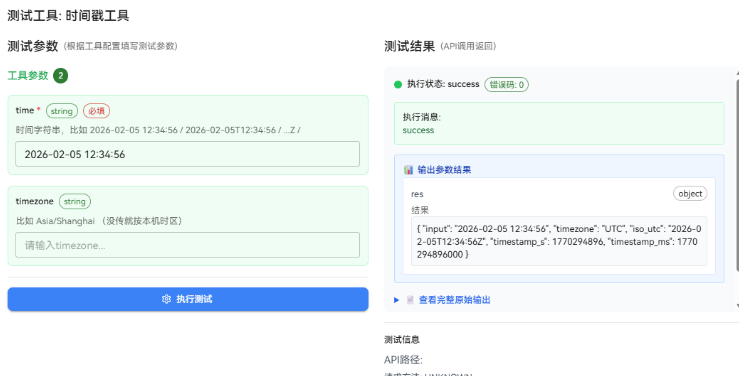
如果你找不到"测试",那就至少保证插件有一个可直接触发的调试方式,否则集成阶段会很难受。
插件要写到什么程度才算"可用"
插件不是"能跑就行",我给自己的最低标准是三句话:
输入要讲人话:参数名字清楚,单位/格式明确,缺参就报错别瞎猜。输出要稳定:结构固定,核心字段不飘,不然智能体拿不到。失败要可解释:直接告诉我哪里不对、下一步怎么改。
插件设计的最小字段
工具名称要一眼看懂用途,比如 timestamp_convert 这种;工具描述要写清楚"什么时候该用它",不然智能体会乱触发;输入参数要把类型、是否必填、示例值、单位/格式说明写齐;输出结构要把成功和失败都定义成固定形状。
我吃过一次亏:只写了"返回字符串",结果智能体拿到输出后不知道哪个字段是结果,最后又让我自己手动看日志。那一刻我就明白了------输出不结构化,等于没做。
三个可复用插件示例
JSON 转换工具
目标很单纯:把一段 JSON 字符串变成"可读、可复制、格式统一"的输出;如果不是合法 JSON,就明确报错,不要悄悄吞掉。
前置条件我只卡两点:插件返回必须是结构化 JSON;智能体侧只读 result,别让它去"自己理解一段文本",那会把你带沟里。
不通时我会先看两件事:输入是不是"看起来像 JSON",但其实带了中文引号/多了尾逗号;以及你在对话里粘贴的内容到底有没有被平台自动转义(这东西最烦,明明你没动它,它自己动了)。
进退决策:如果用户贴的是一段"像 JSON 但又不像"的内容,先让他把原始文本完整贴出来(不要你自己补逗号/补引号),否则你越修越乱。
我的源代码如下(供你复制):
python
import json
from dataclasses import dataclass
from datetime import datetime, timezone
from typing import Any, Dict, Optional
try:
from zoneinfo import ZoneInfo
except Exception:
ZoneInfo = None
def _read_text(path: Optional[str], text: Optional[str]) -> str:
if text is not None:
return text
if path is not None:
with open(path, "r", encoding="utf-8") as f:
return f.read()
raise ValueError("missing input text")
def _parse_datetime(s: str, tz_name: Optional[str]) -> datetime:
raw = s.strip()
if not raw:
raise ValueError("empty input")
if raw.lower() in {"now", "today"}:
dt = datetime.now().astimezone()
return dt
tz = None
if tz_name:
if ZoneInfo is None:
raise ValueError("zoneinfo unavailable, cannot use --timezone")
tz = ZoneInfo(tz_name)
t = raw
if t.endswith("Z"):
t = t[:-1] + "+00:00"
if " " in t and "T" not in t:
t = t.replace(" ", "T", 1)
try:
dt = datetime.fromisoformat(t)
if dt.tzinfo is None:
if tz is not None:
dt = dt.replace(tzinfo=tz)
else:
dt = dt.replace(tzinfo=datetime.now().astimezone().tzinfo)
return dt
except Exception:
pass
fmts = [
"%Y-%m-%d",
"%Y/%m/%d",
"%Y-%m-%dT%H:%M:%S",
"%Y-%m-%dT%H:%M:%S.%f",
"%Y/%m/%dT%H:%M:%S",
"%Y/%m/%dT%H:%M:%S.%f",
]
last_err: Optional[Exception] = None
for fmt in fmts:
try:
dt0 = datetime.strptime(t, fmt)
if tz is not None:
return dt0.replace(tzinfo=tz)
return dt0.replace(tzinfo=datetime.now().astimezone().tzinfo)
except Exception as e:
last_err = e
raise ValueError(f"cannot parse datetime: {raw}") from last_err
def convert_time_to_timestamp(text: str, tz_name: Optional[str]) -> str:
dt = _parse_datetime(text, tz_name)
utc_dt = dt.astimezone(timezone.utc)
ts_s = int(utc_dt.timestamp())
ts_ms = int(utc_dt.timestamp() * 1000)
result = {
"ok": True,
"result": {
"input": text.strip(),
"timezone": str(dt.tzinfo) if dt.tzinfo else None,
"iso_utc": utc_dt.isoformat().replace("+00:00", "Z"),
"timestamp_s": ts_s,
"timestamp_ms": ts_ms,
},
}
return json.dumps(result, ensure_ascii=False, indent=2)
def convert_time_to_timestamp_obj(text: str, tz_name: Optional[str]) -> Dict[str, Any]:
dt = _parse_datetime(text, tz_name)
utc_dt = dt.astimezone(timezone.utc)
ts_s = int(utc_dt.timestamp())
ts_ms = int(utc_dt.timestamp() * 1000)
return {
"input": text.strip(),
"timezone": str(dt.tzinfo) if dt.tzinfo else None,
"iso_utc": utc_dt.isoformat().replace("+00:00", "Z"),
"timestamp_s": ts_s,
"timestamp_ms": ts_ms,
}
@dataclass
class Args:
params: Dict[str, Any]
def main(args: Args) -> Dict[str, Any]:
time_text = args.params.get("time")
if time_text is None:
raise ValueError("missing params['time']")
tz_name = args.params.get("timezone")
tz_name = None if tz_name is None else str(tz_name)
return {"res": convert_time_to_timestamp_obj(str(time_text), tz_name)}时间戳转换工具
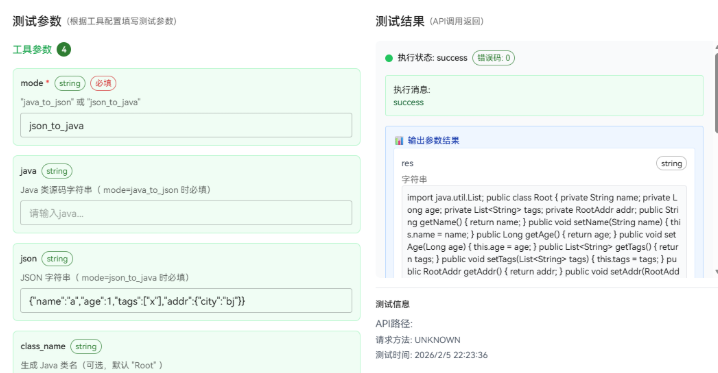
这个工具我建议做得"偏保守":别自动猜太多,能让用户明确单位最好;如果你非要自动识别,那就把规则写死,并在输出里把识别结果返回出来。
我第一次做这个插件的时候,真的被"秒/毫秒"坑到怀疑人生:我拿着一个 13 位时间戳当秒去算,结果直接回到 1970 年,我盯着输出愣了半天......后来才反应过来是单位错了。很蠢,但也很常见。
这里也只卡两个前提:你决定好一个固定规则,要么强制 unit,要么按位数识别(别两套混着来);你明确输出的时区口径,最稳的是同时给 iso 和 local,少扯皮。
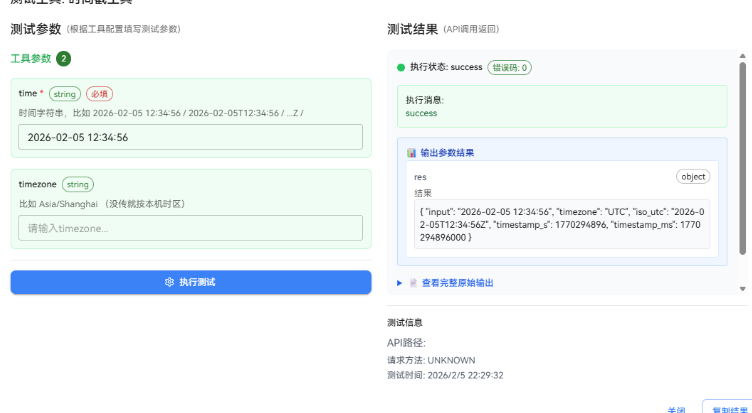
不通时我就看两眼:你到底拿到的是秒还是毫秒(看位数最直接);时区口径是不是固定(所以我才建议同时输出 iso 与 local)。
工具源码如下:
python
import json
from dataclasses import dataclass
from datetime import datetime, timezone
from typing import Any, Dict, Optional
try:
from zoneinfo import ZoneInfo
except Exception:
ZoneInfo = None
def _read_text(path: Optional[str], text: Optional[str]) -> str:
if text is not None:
return text
if path is not None:
with open(path, "r", encoding="utf-8") as f:
return f.read()
raise ValueError("missing input text")
def _parse_datetime(s: str, tz_name: Optional[str]) -> datetime:
raw = s.strip()
if not raw:
raise ValueError("empty input")
if raw.lower() in {"now", "today"}:
dt = datetime.now().astimezone()
return dt
tz = None
if tz_name:
if ZoneInfo is None:
raise ValueError("zoneinfo unavailable, cannot use --timezone")
tz = ZoneInfo(tz_name)
t = raw
if t.endswith("Z"):
t = t[:-1] + "+00:00"
if " " in t and "T" not in t:
t = t.replace(" ", "T", 1)
try:
dt = datetime.fromisoformat(t)
if dt.tzinfo is None:
if tz is not None:
dt = dt.replace(tzinfo=tz)
else:
dt = dt.replace(tzinfo=datetime.now().astimezone().tzinfo)
return dt
except Exception:
pass
fmts = [
"%Y-%m-%d",
"%Y/%m/%d",
"%Y-%m-%dT%H:%M:%S",
"%Y-%m-%dT%H:%M:%S.%f",
"%Y/%m/%dT%H:%M:%S",
"%Y/%m/%dT%H:%M:%S.%f",
]
last_err: Optional[Exception] = None
for fmt in fmts:
try:
dt0 = datetime.strptime(t, fmt)
if tz is not None:
return dt0.replace(tzinfo=tz)
return dt0.replace(tzinfo=datetime.now().astimezone().tzinfo)
except Exception as e:
last_err = e
raise ValueError(f"cannot parse datetime: {raw}") from last_err
def convert_time_to_timestamp(text: str, tz_name: Optional[str]) -> str:
dt = _parse_datetime(text, tz_name)
utc_dt = dt.astimezone(timezone.utc)
ts_s = int(utc_dt.timestamp())
ts_ms = int(utc_dt.timestamp() * 1000)
result = {
"ok": True,
"result": {
"input": text.strip(),
"timezone": str(dt.tzinfo) if dt.tzinfo else None,
"iso_utc": utc_dt.isoformat().replace("+00:00", "Z"),
"timestamp_s": ts_s,
"timestamp_ms": ts_ms,
},
}
return json.dumps(result, ensure_ascii=False, indent=2)
def convert_time_to_timestamp_obj(text: str, tz_name: Optional[str]) -> Dict[str, Any]:
dt = _parse_datetime(text, tz_name)
utc_dt = dt.astimezone(timezone.utc)
ts_s = int(utc_dt.timestamp())
ts_ms = int(utc_dt.timestamp() * 1000)
return {
"input": text.strip(),
"timezone": str(dt.tzinfo) if dt.tzinfo else None,
"iso_utc": utc_dt.isoformat().replace("+00:00", "Z"),
"timestamp_s": ts_s,
"timestamp_ms": ts_ms,
}
@dataclass
class Args:
params: Dict[str, Any]
def main(args: Args) -> Dict[str, Any]:
time_text = args.params.get("time")
if time_text is None:
raise ValueError("missing params['time']")
tz_name = args.params.get("timezone")
tz_name = None if tz_name is None else str(tz_name)
return {"res": convert_time_to_timestamp_obj(str(time_text), tz_name)}cURL 转 fetch 工具(Node.js)
这个工具我更愿意给程序员用:你把一条 cURL 命令丢进来,它帮你拆出 url、method、headers、body,并生成一段可以直接复制的 fetch 代码。比"编码/解码"更像日常真会用到的东西。
我之前最烦的一件事就是:同事甩给我一条 cURL,我要把 header、method、body 手动搬到代码里。搬错一个冒号或者漏了引号,半天找不到问题。后来我就干脆做了这个工具,至少"搬运"这步不再靠眼睛对。
输入建议:只要一个字段就够了,curl=...(整条命令原样粘贴)。
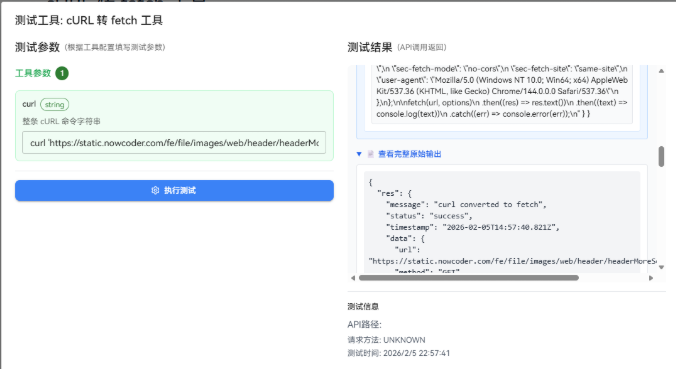
判断标准:headers 里能看见你在 cURL 里传的 -H;body 能看见 -d;method 没写 -X 但有 -d 时默认按 POST 走。
不通时我先看两点:是不是粘贴时把引号弄丢了;是不是 cURL 写法太花(带了很多你其实用不到的参数)。这工具我做得比较克制,只解析常见的 -X/-H/-d/--url,其他参数你真需要再扩展。
源码如下:
typescript
function tokenize(cmd) {
const s = String(cmd || "")
.replace(/\\\s*\r?\n/g, " ")
.trim();
const out = [];
let buf = "";
let quote = null;
let esc = false;
for (let i = 0; i < s.length; i++) {
const ch = s[i];
if (esc) {
buf += ch;
esc = false;
continue;
}
if (quote === null && ch === "\\") {
esc = true;
continue;
}
if (quote !== null) {
if (ch === quote) {
quote = null;
continue;
}
buf += ch;
continue;
}
if (ch === "'" || ch === "\"") {
quote = ch;
continue;
}
if (/\s/.test(ch)) {
if (buf.length) out.push(buf);
buf = "";
continue;
}
buf += ch;
}
if (buf.length) out.push(buf);
return out;
}
function parseCurl(cmd) {
const tokens = tokenize(cmd);
const t = tokens[0] === "curl" ? tokens.slice(1) : tokens.slice();
let url = null;
let method = null;
const headers = {};
const dataParts = [];
const clean = (s) => String(s || "").trim().replace(/^`+|`+$/g, "");
const appendHeader = (k, v) => {
const key = String(k || "").trim();
const val = String(v || "").trim();
if (!key) return;
if (headers[key]) headers[key] = `${headers[key]}; ${val}`;
else headers[key] = val;
};
const takeNext = (i) => {
if (i + 1 >= t.length) throw new Error("curl 参数缺少值");
return t[i + 1];
};
for (let i = 0; i < t.length; i++) {
const a = t[i];
if (a === "\\") continue;
if (a === "-X" || a === "--request") {
method = String(takeNext(i)).toUpperCase();
i++;
continue;
}
if (a === "-H" || a === "--header") {
const hv = clean(takeNext(i));
i++;
const idx = hv.indexOf(":");
if (idx > 0) {
const k = hv.slice(0, idx).trim();
const v = hv.slice(idx + 1).trim();
appendHeader(k, v);
}
continue;
}
if (a === "-b" || a === "--cookie") {
const cookie = clean(takeNext(i));
i++;
appendHeader("Cookie", cookie);
continue;
}
if (a === "-d" || a === "--data" || a === "--data-raw" || a === "--data-binary" || a === "--data-ascii") {
const dv = clean(takeNext(i));
i++;
dataParts.push(dv);
continue;
}
if (a === "--url") {
url = clean(takeNext(i));
i++;
continue;
}
const aa = clean(a);
if (aa.startsWith("http://") || aa.startsWith("https://")) {
url = aa;
continue;
}
}
if (!method) method = dataParts.length ? "POST" : "GET";
const body = dataParts.length ? dataParts.join("&") : null;
const headersJson = JSON.stringify(headers, null, 2);
const urlLiteral = JSON.stringify(url || "");
const methodLiteral = JSON.stringify(method);
let fetchCode = "";
fetchCode += `const url = ${urlLiteral};\n`;
fetchCode += `const options = {\n`;
fetchCode += ` method: ${methodLiteral},\n`;
if (Object.keys(headers).length) {
fetchCode += ` headers: ${headersJson.replace(/\n/g, "\n ")},\n`;
}
if (body !== null) {
fetchCode += ` body: ${JSON.stringify(body)},\n`;
}
fetchCode += `};\n\n`;
fetchCode += `fetch(url, options)\n`;
fetchCode += ` .then((res) => res.text())\n`;
fetchCode += ` .then((text) => console.log(text))\n`;
fetchCode += ` .catch((err) => console.error(err));\n`;
return {
url,
method,
headers,
body,
fetch: fetchCode,
};
}
function main(args) {
/**
* 主要处理函数
*/
const params = (args && args.params) || {};
const curl = params.curl || params.command || "";
if (!curl) {
return {
res: null,
is_success: false,
message: "missing params.curl (or params.command)",
timestamp: new Date().toISOString(),
};
}
const parsed = parseCurl(String(curl));
return {
res: {
message: "curl converted to fetch",
status: "success",
timestamp: new Date().toISOString(),
data: parsed,
},
is_success: true,
};
}
module.exports = { main };
if (require.main === module) {
const cmd = process.argv.slice(2).join(" ").trim();
const input = cmd || "curl https://example.com";
console.log(main({ params: { curl: input } }));
}集成到智能体(让提示词驱动调用)
把插件绑定到智能体
进智能体配置页,找到"插件"相关区域,把你刚创建的插件选上并保存。然后回到调试区,先手动问一个会触发的例子,确认能调用成功。
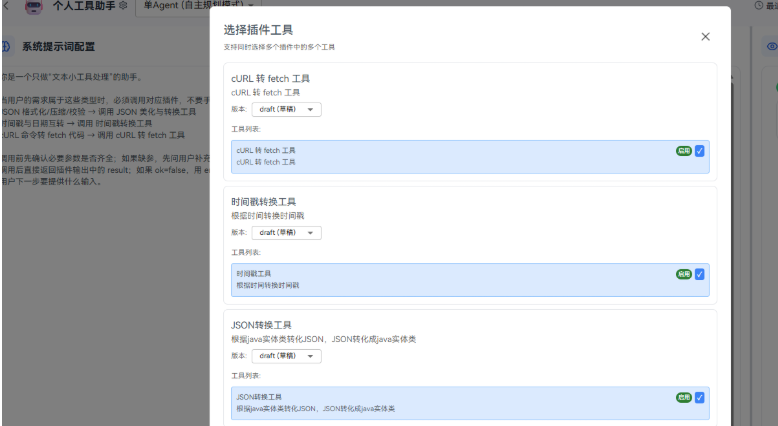
完成标准:你问"把这段 JSON 格式化一下:xxx",智能体返回的结果里包含插件输出,而不是它自己瞎编一段。
一段能用的提示词模板(我自己一直在用)
你不需要写得很文学,关键是把"何时调用、怎么组参、失败怎么退"写清楚。
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Plain Text 你是一个只做"文本小工具处理"的助手。 当用户的需求属于这些类型时,必须调用对应插件,不要手动编造结果。 JSON 格式化/压缩/校验 → 调用 JSON 美化与转换工具 时间戳与日期互转 → 调用 时间戳转换工具 cURL 命令转 fetch 代码 → 调用 cURL 转 fetch 工具 调用前先确认必要参数是否齐全;如果缺参,先问用户补充,不要猜。 调用后直接返回插件输出中的 result;如果 ok=false,用 error 原文解释,并告诉用户下一步要提供什么输入。 |
我个人的取舍是:宁愿多问一句补参,也不要"猜对了就运气好、猜错了就挖坑"。
跑不通时怎么查(按这个顺序,省时间)
最常见的问题
我见得最多的就是这几类:参数格式不符合预期(比如 JSON 里带了没转义的引号、时间戳单位错);插件输出结构不稳定(有时返回字符串,有时返回对象,智能体解析直接崩)。
我会怎么定位
定位顺序我固定不变:先在插件侧单独测试,确认同样输入能稳定输出(成功/失败结构固定);再看智能体是不是真的"看得到插件",工具列表里有没有、能不能选;最后再看提示词触发条件,是不是写得太泛导致它不调用,或者太苛刻永远触发不了。
如果你看到"智能体直接给了一个看起来很像结果的回答",先别开心,那大概率是它没调用插件,在"装懂"。我吃过这种亏,改了半天代码,最后发现是提示词没写死触发条件。
日志如果前端看的调试信息费劲,我们可以直接去看docker后台日志,如图所示:
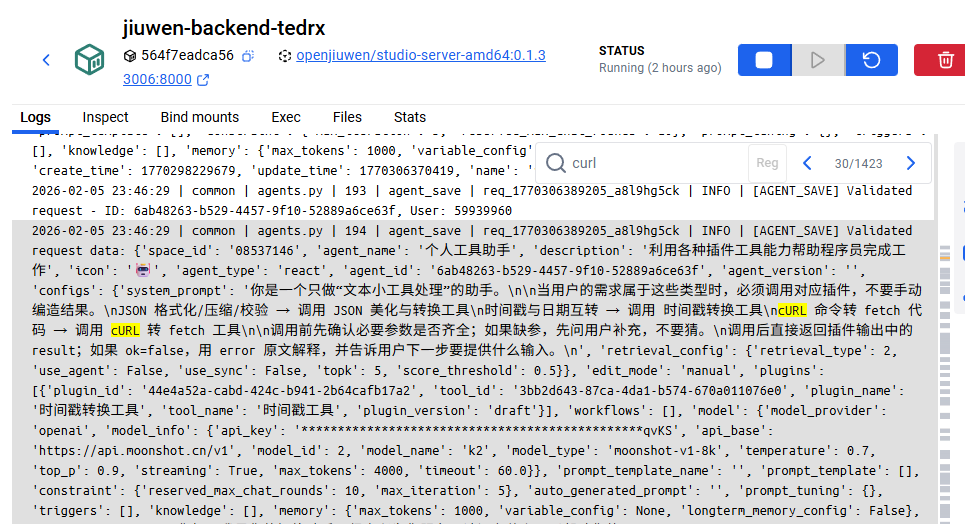
扩展思路
把常用在线工具逐步替换成团队插件库
我比较推荐的做法是:先把使用频率最高的三五个工具沉淀成插件,大家真的用起来了,再考虑做插件分类、统一命名、版本管理。别一上来就"我要做一个插件商店",很容易烂尾。
你可以怎么验收(我自己用的口径)
验收我就按这几句来卡:新建智能体后刷新页面,配置不丢;插件侧用同一输入连续测几次,输出结构一致(成功/失败都一致);智能体里输入一条明确指令,能触发插件调用,不靠模型"装懂";再故意给一个错误输入,智能体能把 error 原样说清楚,并提示下一步要补什么。
结语
插件这件事别想得太大:先把你每天最常用的那一个在线工具搬回本地,做成"输入清楚、输出稳定、失败可解释"的小能力,让智能体在对话里按规则调用。等你真的用顺手了,再慢慢扩到第二个、第三个。
你最后要的不是"插件数量",而是一个可复用的习惯:先在插件侧把输出跑稳,再绑定到智能体里把触发条件写死;遇到不确定宁愿多问一句补参,也别靠猜。做到这一步,你的日常效率就已经开始明显提升了。