文章目录
- 智能体(Agent)架构设计模式:基于实际项目的模块拆解
-
- 引言:从单一模型到自治系统的范式转变
- [一、 智能体的本质与设计挑战](#一、 智能体的本质与设计挑战)
-
- [1.1 智能体的核心定义](#1.1 智能体的核心定义)
- [1.2 实际项目中的核心挑战](#1.2 实际项目中的核心挑战)
- [二、 智能体核心模块深度拆解](#二、 智能体核心模块深度拆解)
-
- [2.1 感知与理解模块:从原始输入到结构化意图](#2.1 感知与理解模块:从原始输入到结构化意图)
- [2.2 规划与决策模块:从目标到可执行计划](#2.2 规划与决策模块:从目标到可执行计划)
- [2.3 工具与执行模块:安全可控的行动能力](#2.3 工具与执行模块:安全可控的行动能力)
- [2.4 记忆与状态管理模块:保持连续性与一致性](#2.4 记忆与状态管理模块:保持连续性与一致性)
- [2.5 反思与学习模块:从经验中持续改进](#2.5 反思与学习模块:从经验中持续改进)
- [三、 四种智能体架构设计模式](#三、 四种智能体架构设计模式)
-
- [3.1 单智能体自治模式(Autonomous Agent)](#3.1 单智能体自治模式(Autonomous Agent))
- [3.2 监督执行模式(Supervised Execution)](#3.2 监督执行模式(Supervised Execution))
- [3.3 多智能体协作模式(Multi-Agent Collaboration)](#3.3 多智能体协作模式(Multi-Agent Collaboration))
- [3.4 流水线编排模式(Pipeline Orchestration)](#3.4 流水线编排模式(Pipeline Orchestration))
- [四、 智能体系统的工程实践要点](#四、 智能体系统的工程实践要点)
-
- [4.1 测试与评估体系](#4.1 测试与评估体系)
- [4.2 部署与运维考虑](#4.2 部署与运维考虑)
- [五、 架构选择指南与项目启动建议](#五、 架构选择指南与项目启动建议)
-
- [5.1 如何选择适合的架构模式?](#5.1 如何选择适合的架构模式?)
- [5.2 项目启动实用建议](#5.2 项目启动实用建议)
- 结语:智能体架构的未来演进
智能体(Agent)架构设计模式:基于实际项目的模块拆解
引言:从单一模型到自治系统的范式转变
随着大语言模型能力的飞速提升,AI应用的范式正在发生根本性转变。我们正从"输入-输出 "的简单交互模式,迈向"目标-规划-执行-反思 "的完整行动循环。智能体(Agent)正是这一转变的核心载体------它不再是等待指令的工具,而是能够理解意图、制定计划、调用资源、完成任务的自治系统。
本文将深入剖析智能体的架构设计模式,基于金融分析、客户服务和研发辅助等实际项目经验,拆解其核心模块,探索从原型到生产系统的工程化路径。我们将看到,一个健壮的智能体系统远不止是"大模型+API调用",而是一个精心设计的复杂系统架构。

一、 智能体的本质与设计挑战
1.1 智能体的核心定义
在AI语境下,智能体是能够感知环境、自主决策并执行行动以实现目标的软件实体。与传统程序的关键区别在于:
- 目标导向:接受高层次目标而非详细指令
- 环境感知:主动获取信息,理解上下文状态
- 自主规划:将抽象目标分解为具体步骤
- 工具使用:调用外部资源完成行动
- 学习适应:从经验中优化未来行为
1.2 实际项目中的核心挑战
基于我们在多个行业项目的实践经验,构建生产级智能体面临六大挑战:
| 挑战维度 | 具体表现 | 影响程度 |
|---|---|---|
| 可靠性 | 行动不可预测,幻觉导致错误决策 | 高 - 直接影响可用性 |
| 可控性 | 智能体偏离预期行为,执行未授权操作 | 高 - 涉及安全风险 |
| 效率 | 过度规划,陷入循环,响应缓慢 | 中 - 影响用户体验 |
| 可观测性 | 决策过程不透明,问题难以调试 | 中 - 增加运维成本 |
| 集成复杂度 | 与现有系统对接困难,数据流混乱 | 高 - 决定部署成本 |
| 评估难度 | 缺乏标准化评估指标,迭代无依据 | 中 - 影响长期演进 |
正是这些挑战,决定了智能体不能是简单的提示词工程,而需要系统性的架构设计。
二、 智能体核心模块深度拆解
一个完整的智能体系统通常包含五大核心模块,我们结合金融投资分析智能体的实际案例,逐一解析其设计要点。
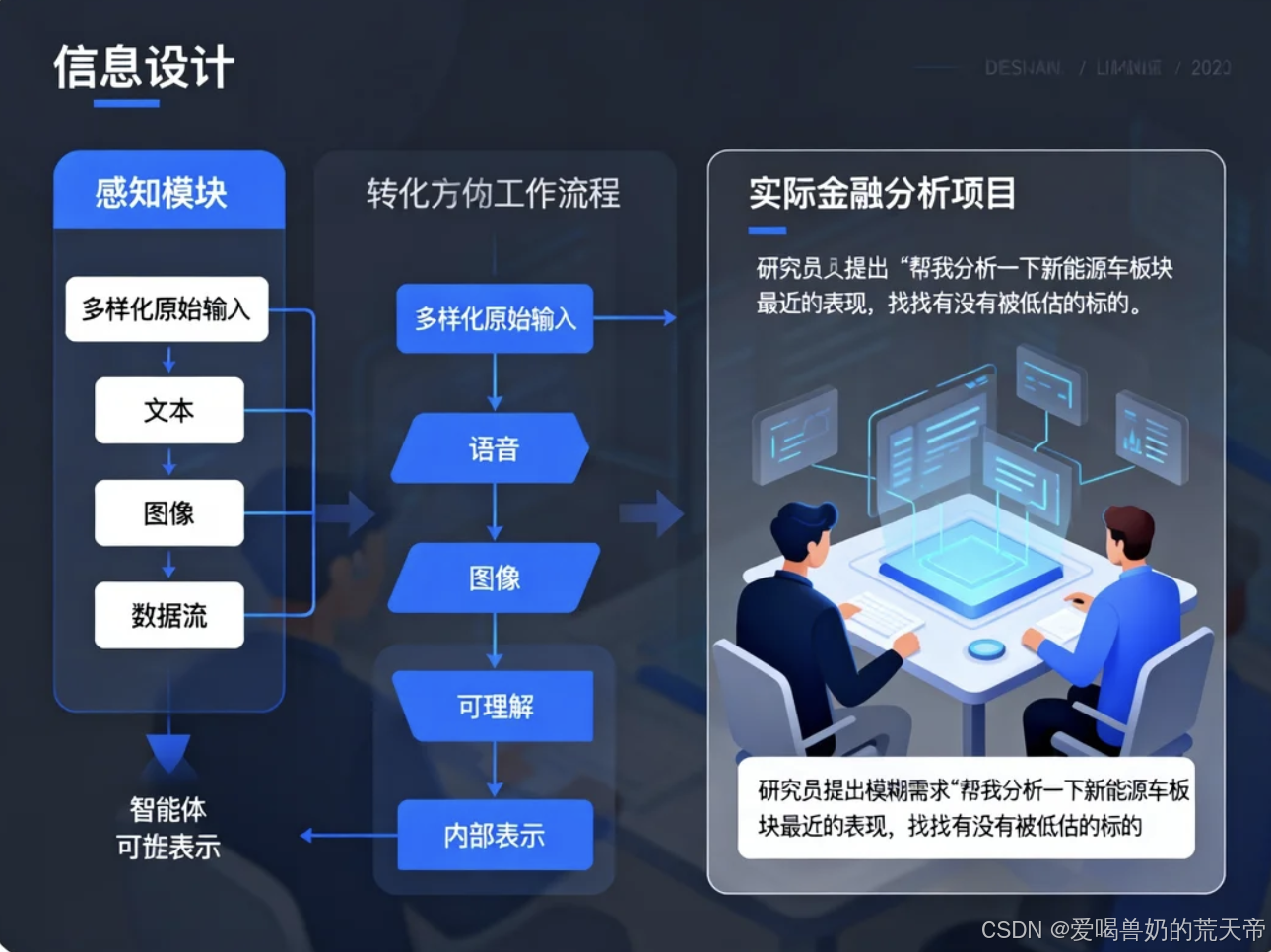
2.1 感知与理解模块:从原始输入到结构化意图
感知模块负责将多样化的原始输入(文本、语音、图像、数据流)转化为智能体可以理解的内部表示。在实际金融分析项目中,我们面临的是研究员模糊的需求:"帮我分析一下新能源车板块最近的表现,找找有没有被低估的标的。"
python
# 简化版的多模态感知与理解管道
class PerceptionModule:
def __init__(self, llm, specialized_parsers):
self.llm = llm
self.parsers = specialized_parsers # 不同输入类型的专用解析器
async def process_input(self, raw_input, input_type="text", context=None):
"""处理各种类型的输入,提取结构化意图"""
# 步骤1:输入规范化
normalized = self._normalize_input(raw_input, input_type)
# 步骤2:多层级意图解析
intent_structure = {
"primary_goal": None, # 主要目标
"constraints": [], # 约束条件
"implicit_needs": [], # 隐含需求
"output_format": None # 期望输出格式
}
# 使用LLM结合领域知识进行意图解析
prompt = self._build_intent_parsing_prompt(normalized, context)
llm_response = await self.llm.generate_structured(prompt)
# 步骤3:意图验证与澄清(针对模糊输入)
if self._needs_clarification(llm_response):
clarification = await self._request_clarification(llm_response)
intent_structure = self._update_with_clarification(
intent_structure, clarification
)
return intent_structure
def _normalize_input(self, raw_input, input_type):
"""根据输入类型调用相应解析器"""
if input_type in self.parsers:
return self.parsers[input_type].parse(raw_input)
# 默认文本处理
return {"type": "text", "content": raw_input, "metadata": {}}设计要点:
- 分层意图识别:区分表层请求和深层需求
- 上下文感知:结合对话历史、用户画像、环境状态
- 多轮澄清机制:对模糊需求主动询问,而非盲目猜测
- 领域知识注入:在金融场景中,需要理解行业术语、指标含义
在金融分析案例中,对研究员输入的完整解析结果是:
json
{
"primary_goal": "identify_undervalued_stocks",
"domain": "new_energy_vehicle",
"time_frame": "recent_performance",
"constraints": ["consider_policy_impact", "exclude_high_debt_companies"],
"implicit_needs": ["risk_assessment", "comparative_analysis"],
"output_format": "investment_memo"
}2.2 规划与决策模块:从目标到可执行计划
规划模块将高层目标转化为具体的行动序列。这里的关键不是生成"完美计划",而是生成弹性、可监控、可中断的计划。
python
class PlanningModule:
def __init__(self, llm, planner_type="hierarchical"):
self.llm = llm
self.planner_type = planner_type
self.plan_schema = self._define_plan_schema()
async def generate_plan(self, intent_structure, available_tools):
"""基于意图和可用工具生成执行计划"""
# 初始计划生成
initial_plan = await self._llm_planning(intent_structure, available_tools)
# 计划验证与优化
validated_plan = self._validate_plan(initial_plan, constraints=intent_structure.get("constraints", []))
# 风险评估与备选方案
risk_assessment = self._assess_plan_risk(validated_plan)
if risk_assessment["high_risk_steps"]:
alternative_plans = await self._generate_alternatives(validated_plan)
validated_plan["alternatives"] = alternative_plans
return validated_plan
def _define_plan_schema(self):
"""定义计划的结构化表示"""
return {
"goal": "明确描述最终目标",
"steps": [
{
"id": "步骤唯一标识",
"action": "要执行的操作",
"tool": "使用的工具",
"parameters": "工具参数",
"dependencies": ["依赖的前置步骤"],
"expected_output": "预期输出",
"timeout": "超时设置",
"retry_policy": "重试策略"
}
],
"checkpoints": [
{"step_id": "检查点步骤", "validation": "验证逻辑"}
],
"rollback_strategy": "失败回滚策略"
}金融分析案例的实际计划:
json
{
"goal": "生成新能源汽车板块投资分析报告,识别被低估股票",
"steps": [
{
"id": "s1",
"action": "collect_market_data",
"tool": "wind_api_client",
"parameters": {"sector": "new_energy_vehicle", "metrics": ["pe_ratio", "pb_ratio", "revenue_growth"], "period": "2023Q1-2024Q1"},
"expected_output": "raw_financial_data",
"timeout": 30
},
{
"id": "s2",
"action": "analyze_policy_impact",
"tool": "policy_analyzer",
"parameters": {"sector": "new_energy_vehicle", "region": "china"},
"dependencies": ["s1"],
"expected_output": "policy_impact_assessment"
}
],
"checkpoints": [
{"step_id": "s1", "validation": "validate_data_completeness"},
{"step_id": "s3", "validation": "check_analysis_quality"}
]
}2.3 工具与执行模块:安全可控的行动能力
工具模块是智能体与外部世界交互的接口。设计良好的工具系统需要平衡能力与安全、灵活性与可控性。
python
class ToolExecutionModule:
def __init__(self, tool_registry, safety_checker, audit_logger):
self.tools = tool_registry
self.safety = safety_checker
self.audit = audit_logger
async def execute_step(self, step, context):
"""执行单个计划步骤"""
# 1. 工具查找与验证
tool = self.tools.get_tool(step["tool"])
if not tool:
raise ToolNotFoundError(f"工具未找到: {step['tool']}")
# 2. 安全性检查(策略执行点)
safety_check = await self.safety.check(
tool=tool.name,
parameters=step["parameters"],
user_context=context.user,
environment=context.env
)
if not safety_check.allowed:
return {
"success": False,
"error": f"安全策略拒绝执行: {safety_check.reason}",
"suggestion": safety_check.alternative_suggestion
}
# 3. 参数验证与转换
validated_params = tool.validate_parameters(step["parameters"])
# 4. 执行工具
try:
start_time = time.time()
result = await tool.execute(validated_params, context)
exec_time = time.time() - start_time
# 5. 结果验证
is_valid = tool.validate_output(result, step.get("expected_output"))
# 6. 审计日志
await self.audit.log_execution({
"tool": tool.name,
"parameters": validated_params,
"result": result if not tool.sensitive else "[REDACTED]",
"success": is_valid,
"execution_time": exec_time,
"context": context.snapshot()
})
return {
"success": is_valid,
"result": result,
"execution_metadata": {
"time": exec_time,
"tool_version": tool.version
}
}
except ToolExecutionError as e:
# 错误处理与恢复
recovery_action = await self._handle_execution_error(e, step, context)
return {"success": False, "error": str(e), "recovery": recovery_action}工具系统设计要点:
- 工具抽象层:统一接口,支持不同类型工具(API、数据库查询、本地函数)
- 策略网关(Policy Gateway):集中实施安全策略、权限控制、资源配额
- 结果规范化:将不同工具的结果转为统一格式,便于后续处理
- 故障恢复机制:定义清晰的错误分类和恢复策略
- 性能监控:跟踪工具调用延迟、成功率、资源消耗
2.4 记忆与状态管理模块:保持连续性与一致性
智能体的记忆系统是其连续性和一致性的基础。我们借鉴人类记忆的层次结构,设计了三级记忆系统:
python
class HierarchicalMemory:
def __init__(self):
# 三级记忆结构
self.sensory_buffer = SensoryBuffer(max_size=10, ttl=60) # 感官缓存:原始输入,短期保存
self.working_memory = WorkingMemory(max_size=100) # 工作记忆:当前任务相关信息
self.long_term_memory = LongTermMemory() # 长期记忆:知识、经验、用户画像
# 记忆索引与检索
self.index = VectorIndex(dimension=768) # 向量索引,用于语义搜索
self.metadata_index = MetadataIndex() # 元数据索引,用于精确查询
async def store(self, experience, memory_type="working"):
"""存储新的经验到相应记忆"""
# 信息提取与增强
enriched = await self._enrich_experience(experience)
# 多维度索引
self.index.add_embedding(enriched.embedding, enriched.id)
self.metadata_index.add(enriched.metadata, enriched.id)
# 分层存储
if memory_type == "sensory":
self.sensory_buffer.add(enriched)
elif memory_type == "working":
self.working_memory.add(enriched)
else:
await self.long_term_memory.commit(enriched)
# 触发记忆巩固(工作记忆到长期记忆的转换)
if memory_type == "working":
await self._consolidate_if_needed(enriched)
async def retrieve(self, query, context=None, memory_type="auto"):
"""从记忆中检索相关信息"""
# 多策略检索
results = []
# 1. 向量相似度检索
vector_results = await self.index.similarity_search(query, k=5)
results.extend(vector_results)
# 2. 元数据过滤检索
if context and context.get("filters"):
metadata_results = self.metadata_index.search(context["filters"])
results.extend(metadata_results)
# 3. 时间相关性检索(近期记忆权重更高)
temporal_results = self._temporal_search(query)
results.extend(temporal_results)
# 结果去重、排序与融合
final_results = self._rerank_and_fuse(results, query, context)
return final_results记忆系统关键设计:
-
记忆分类:
- 情景记忆:特定任务的具体经历
- 语义记忆:领域知识、事实信息
- 程序性记忆:工具使用模式、有效工作流
-
记忆巩固机制:
- 重要经验从工作记忆转入长期记忆
- 定期回顾与强化重要记忆
- 无关信息的主动遗忘
-
记忆检索策略:
- 基于当前上下文的相关性检索
- 失败案例的特别标记与检索
- 成功模式的模式识别与重用
2.5 反思与学习模块:从经验中持续改进
反思模块使智能体能够评估自身表现,从成功和失败中学习,实现持续改进。
python
class ReflectionModule:
def __init__(self, llm, evaluators):
self.llm = llm
self.evaluators = evaluators # 不同维度的评估器
async def reflect_on_episode(self, episode_record):
"""对完整任务执行过程进行反思"""
reflections = []
# 1. 结果评估
outcome_evaluation = await self._evaluate_outcome(episode_record)
# 2. 过程分析
process_analysis = await self._analyze_process(episode_record)
# 3. 关键决策点审查
decision_review = await self._review_decisions(episode_record)
# 4. 根本原因分析(针对失败)
if not outcome_evaluation["success"]:
root_cause = await self._root_cause_analysis(episode_record)
reflections.append({"type": "root_cause", "insight": root_cause})
# 5. 学习点提取
learnings = await self._extract_learnings(
outcome_evaluation,
process_analysis,
decision_review
)
# 6. 行为调整建议
adjustments = await self._suggest_adjustments(learnings)
return {
"episode_id": episode_record.id,
"timestamp": episode_record.end_time,
"outcome_evaluation": outcome_evaluation,
"key_learnings": learnings,
"suggested_adjustments": adjustments,
"confidence_change": self._calculate_confidence_change(episode_record)
}
async def _extract_learnings(self, *analyses):
"""从多维度分析中提取学习点"""
learning_categories = {
"tool_usage": "工具使用模式",
"planning_strategy": "规划策略",
"error_recovery": "错误恢复方法",
"efficiency_improvement": "效率提升机会",
"knowledge_gaps": "知识缺口识别"
}
learnings = []
for category in learning_categories:
category_learnings = await self._extract_category_learnings(
category, *analyses
)
if category_learnings:
learnings.append({
"category": category,
"description": category_learnings,
"priority": self._prioritize_learning(category_learnings)
})
return learnings三、 四种智能体架构设计模式
基于实际项目经验,我们总结了四种成熟的智能体架构模式,每种模式适用于不同的应用场景。
3.1 单智能体自治模式(Autonomous Agent)
适用场景:任务明确、范围有限、需要快速响应的场景
- 个人助手(日程安排、邮件处理)
- 简单数据分析与报告生成
- 基础客户咨询应答
架构特点:
┌─────────────────────────────────────────┐
│ 用户接口层 │
├─────────────────────────────────────────┤
│ 单智能体核心 │
│ ┌─────────┬─────────┬────────────┐ │
│ │ 感知模块│ 规划模块│ 执行模块 │ │
│ └─────────┴─────────┴────────────┘ │
├─────────────────────────────────────────┤
│ 共享记忆系统 │
├─────────────────────────────────────────┤
│ 工具集合 │
└─────────────────────────────────────────┘设计要点:
- 轻量级设计,最小化模块间通信开销
- 有限的工具集,专注核心能力
- 简化的记忆系统,主要维护对话上下文
- 快速失败机制,避免复杂错误处理
3.2 监督执行模式(Supervised Execution)
适用场景:高风险、高价值、需要人工监督的场景
- 金融交易审批与执行
- 医疗诊断辅助决策
- 法律文件审查与生成
架构特点:
┌─────────────────────────────────────────┐
│ 人工监督界面 │
│ ▲ │ │
│ │批准/否决 │执行结果 │
│ │ ▼ │
├──────┼──────────────────────────────────┤
│ │ 智能体核心 │
│ │ ┌─────────┬─────────┐ │
│ │ │ 规划模块│ 执行模块│ │
│ │ └─────────┴─────────┘ │
│ └───────────┼─────────────────────┤
│ │计划与建议 │
├─────────────────────────────────────────┤
│ 审核日志与追溯系统 │
└─────────────────────────────────────────┘设计要点:
- 关键决策点设置人工检查点(checkpoint)
- 完整的执行追溯与审计日志
- 解释生成机制:智能体需解释建议的推理过程
- 人工反馈的闭环学习:将人工修正转化为训练数据
3.3 多智能体协作模式(Multi-Agent Collaboration)
适用场景:复杂问题分解、需要多领域专家知识的场景
- 综合商业分析(市场、财务、竞争多维度)
- 软件开发项目(需求、设计、编码、测试)
- 科研问题探索(文献调研、实验设计、数据分析)
架构特点:
┌─────────────────────────────────────────┐
│ 协作协调器 │
│ ┌──────┬──────┬──────┬──────┐ │
│ │任务分解│角色分配│冲突解决│进度监控│ │
│ └──────┴──────┴──────┴──────┘ │
├─────────────────────────────────────────┤
│ 专家智能体集群 │
│ ┌──────┐ ┌──────┐ ┌──────┐ │
│ │市场专家│ │财务专家│ │技术专家│ │
│ └──────┘ └──────┘ └──────┘ │
│ │ │ │ │
├──────┼──────────┼──────────┼────────────┤
│ 共享工作区与通信总线 │
├─────────────────────────────────────────┤
│ 领域专用工具库 │
└─────────────────────────────────────────┘金融分析多智能体案例:
- 数据收集智能体:负责从各类数据源获取原始数据
- 政策分析智能体:解读行业政策,评估影响程度
- 财务分析智能体:计算财务指标,识别异常模式
- 风险评估智能体:评估投资风险,生成风险矩阵
- 报告合成智能体:整合各方分析,生成最终报告
设计要点:
- 清晰的智能体角色与职责划分
- 高效的通信协议与消息格式
- 冲突检测与解决机制
- 整体进度协调与资源分配
3.4 流水线编排模式(Pipeline Orchestration)
适用场景:流程标准化、可预测、大规模并行的场景
- 内容审核流水线(文本、图像、视频多模态审核)
- 客户工单处理(分类、分配、解决、反馈)
- 制造业质检流程(图像采集、缺陷检测、分类、报告)
架构特点:
┌─────────────────────────────────────────┐
│ 流程编排引擎 │
│ ┌──────────────────────────────┐ │
│ │ 1. 输入标准化 → 2. 分类 │ │
│ │ │ │
│ │ 3. 专业处理 → 4. 质量检查 │ │
│ │ │ │
│ │ 5. 结果整合 → 6. 输出交付 │ │
│ └──────────────────────────────┘ │
├─────────────────────────────────────────┤
│ 模块化处理节点 │
│ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ │
│ │节点A│ │节点B│ │节点C│ │节点D│ │
│ └─────┘ └─────┘ └─────┘ └─────┘ │
├─────────────────────────────────────────┤
│ 状态管理与监控 │
└─────────────────────────────────────────┘设计要点:
- 每个处理节点职责单一,可独立测试
- 标准化的数据接口与通信协议
- 弹性伸缩能力,根据负载动态调整节点数量
- 完善的监控与告警机制
四、 智能体系统的工程实践要点
4.1 测试与评估体系
智能体系统的复杂性要求建立多层次的测试体系:
- 单元测试:测试单个工具、模块的功能正确性
- 集成测试:测试模块间协作,特别是规划-执行循环
- 场景测试:针对典型用户场景的端到端测试
- 压力测试:高并发、长会话、边缘输入的稳定性测试
- 对抗测试:故意提供误导信息,测试系统的鲁棒性
评估指标应包括:
- 任务完成率:智能体独立完成任务的比例
- 人工干预频率:需要人工介入的频率
- 平均步骤数:完成任务的平均步骤数(衡量效率)
- 工具使用准确率:正确选择并使用工具的比例
- 用户满意度:主观评价指标
4.2 部署与运维考虑
-
渐进式部署策略:
- 影子模式:智能体决策不实际执行,与人类决策对比
- 金丝雀发布:先对小部分用户开放,收集反馈
- 特性开关:快速启用/禁用特定功能
-
监控与可观测性:
python# 智能体关键指标监控 AGENT_METRICS = [ "planning_time", # 规划耗时 "execution_time", # 执行耗时 "steps_per_task", # 任务平均步骤数 "tool_success_rate", # 工具调用成功率 "user_feedback_score" # 用户反馈评分 ] # 分布式追踪集成 def trace_agent_execution(agent_id, session_id): """记录智能体执行的完整追踪""" with tracer.start_as_current_span("agent_execution") as span: span.set_attribute("agent.id", agent_id) span.set_attribute("session.id", session_id) # 记录关键事件 span.add_event("planning_started") # ... 执行过程 span.add_event("execution_completed") return span -
版本管理与回滚:
- 智能体配置、提示词、工具集的版本控制
- 快速回滚到稳定版本的能力
- A/B测试框架支持不同版本的并行测试
五、 架构选择指南与项目启动建议
5.1 如何选择适合的架构模式?
| 考虑维度 | 单智能体自治 | 监督执行 | 多智能体协作 | 流水线编排 |
|---|---|---|---|---|
| 任务复杂度 | 低 | 中-高 | 高 | 中 |
| 风险容忍度 | 中-高 | 低 | 中 | 中-低 |
| 开发资源 | 少 | 中 | 多 | 中 |
| 响应时间要求 | 高(秒级) | 中(分钟级) | 低(小时级) | 高(秒级) |
| 可解释性要求 | 低 | 高 | 中 | 低 |
| 典型领域 | 个人助理、客服 | 金融、医疗、法律 | 研究、分析、开发 | 审核、质检、处理 |
5.2 项目启动实用建议
-
从简单开始,逐步复杂化:
- 第一阶段:实现基于固定模板的简单任务
- 第二阶段:引入有限的自适应规划能力
- 第三阶段:增加多工具协调和复杂决策
-
建立反馈闭环:
用户交互 → 行为记录 → 人工标注 → 模型微调 → 部署更新 ↓ ↑ 质量评估 ←── 对比测试 ←── 新版本训练 -
安全与治理先行:
- 在项目早期定义清晰的安全边界
- 实施最小权限原则的工具访问控制
- 建立审计和追溯机制
-
团队技能建设:
- 传统软件工程 + 机器学习 + 领域知识的复合团队
- 建立共享的测试环境和评估基准
- 定期进行架构审查和技术分享
结语:智能体架构的未来演进
智能体技术正从实验室原型快速走向生产系统,其架构设计也在不断演进。未来的发展趋势可能包括:
- 更细粒度的模块化:将规划、反思等能力进一步分解为可插拔的微模块
- 跨智能体标准化:不同厂商智能体之间的互操作协议
- 混合架构模式:结合集中式与分布式优点的混合架构
- 自主进化的架构:智能体能够根据任务特性自我调整架构
无论技术如何演进,智能体架构设计的核心原则不变:在自治能力 与可控性 、灵活性 与可靠性 、复杂性 与可维护性之间找到恰当的平衡点。通过模块化设计、清晰接口、分层抽象和持续测试,我们可以构建出既强大又可靠的智能体系统,真正实现AI从"工具"到"同事"的转变。
构建智能体系统是一场马拉松,而非短跑。它需要耐心迭代、持续学习和对失败的正确态度。每一次智能体的错误决策,都是优化架构的宝贵机会;每一次用户的困惑反馈,都是改进设计的明确指引。在这个过程中,我们不仅是在构建更智能的系统,也是在探索人机协作的全新范式。